Docker. Start

My colleagues and I felt about the same emotions when I started working with Docker. In the vast majority of cases, this stemmed from a lack of understanding of the basic mechanisms, so its behavior seemed unpredictable to us. Now the passions have subsided and outbreaks of hatred are happening less and less. Moreover, we gradually evaluate its merits in practice and we begin to like it ... To reduce the degree of primary rejection and maximize the effect of use, you must definitely look into the Docker’s kitchen and look around carefully.
Let's start with what we need Docker for:
- isolated launch of applications in containers
- simplification of development, testing and deployment of applications
- no need to configure the environment to run - it comes with the application - in the container
- Simplifies application scalability and management with container orchestration systems.
Prehistory
You can use virtual machines to isolate processes running on the same host and run applications designed for different platforms. Virtual machines share the physical resources of a host:
- CPU,
- memory,
- disk space,
- network interfaces.
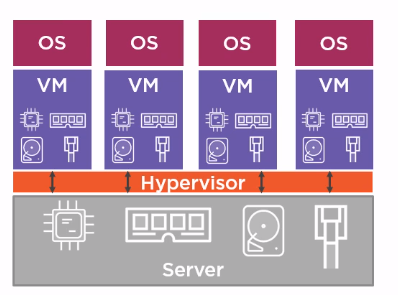
On each VM, install the desired OS and run the application. The disadvantage of this approach is that a significant part of the host’s resources is spent not on the payload (application work), but on the operation of several OSs.
Containers
An alternative approach to isolating applications is containers. The concept of containers is not new and has long been known in Linux. The idea is to isolate an isolated area within one OS and run the application in it. In this case, we are talking about OS-level virtualization. Unlike VMs, containers use their OS slice in isolation:
- file system
- process tree
- network interfaces
- and etc.
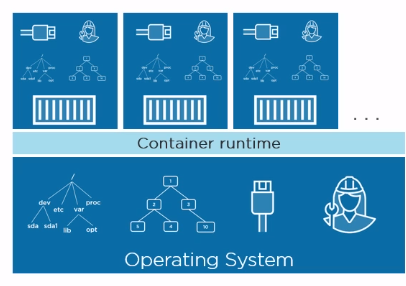
T.O. an application running in a container thinks that it is one in the entire OS. Isolation is achieved through the use of Linux mechanisms such as namespaces and control groups . In simple terms, namespaces provide isolation within the OS, and control groups set limits on the container's consumption of host resources in order to balance the distribution of resources between running containers.
T.O. the containers themselves are not new, just the Docker project, firstly, hid the complex mechanisms of namespaces, control groups, and secondly, it is surrounded by an ecosystem that provides convenient use of containers at all stages of software development.
The images
In the first approximation, an image can be considered as a set of files. The image includes everything you need to run and run the application on a bare machine with docker: OS, runtime, and an application ready for deployment.
But with such a consideration, the question arises: if we want to use several images on one host, it will be irrational both from the point of view of loading and from the point of view of storage, so that each image drags everything necessary for its work, because most files will be repeated, and to differ - only the application being launched and, possibly, the runtime environment. The structure of the image allows you to avoid duplication of files.
An image consists of layers, each of which is an immutable file system, and in a simple set of files and directories. The image as a whole is a unified file system (Union File System), which can be considered as a result of merging file systems layers. The combined file system can handle conflicts, for example, when files and directories with the same name are present in different layers. Each next layer adds or removes some files from previous layers. In this context, “deletes” can be considered as “obscures”, i.e. the file in the underlying layer remains, but it will not be visible in the combined file system.
You can draw an analogy with Git: layers are like separate commits, and the image as a whole is the result of the squash operation. As we will see later, the parallels with Git do not end there. There are various implementations of a federated file system, one of which is AUFS.
For example, consider the image of an arbitrary .NET application MyApplication: the first layer is the Linux kernel, followed by the layers of the OS, the runtime, and the application itself.

The layers are read only and if in the MyApplication layer you need to change the file located in the dotnet layer, the file is first copied to the desired layer, and then it changes in it, remaining in the original layer in its original form.
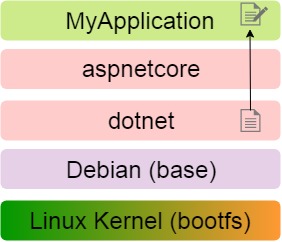
The immutability of layers allows you to use them with all the images on the host. Let's say MyApplication is a web application that uses a database and also interacts with a NodeJS server.
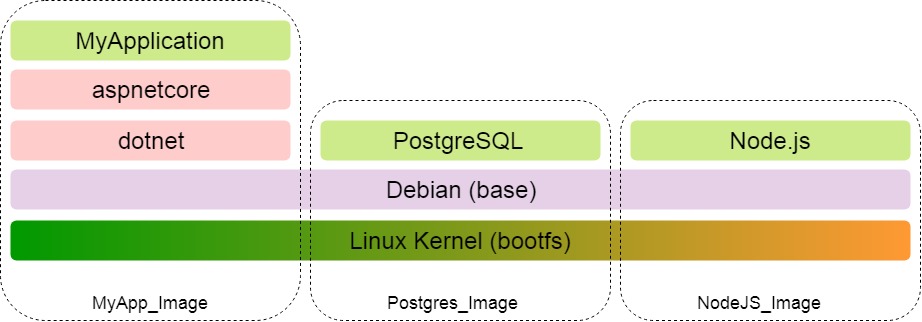
Sharing is also evident when downloading an image. The first to load the manifest, which describes which layers are included in the image. Next, only those layers from the manifest are downloaded that are not yet locally. T.O. if for MyApplication we have already downloaded the kernel and OS, then for PostgreSQL and Node.js these layers will not be loaded.
To summarize:
- An image is a set of files necessary for an application to run on a bare machine with Docker installed.
- An image consists of immutable layers, each of which adds / removes / modifies files from the previous layer.
- The immutability of the layers allows them to be used together in different images.
Docker containers
The docker container is built on the basis of the image. The essence of converting an image to a container is to add a top layer for which recording is allowed. Application results (files) are written in this layer.

For example, we created a container based on the image with the PostgreSQL server and launched it. When we create the database, the corresponding files appear in the top layer of the container - the recording layer.

You can carry out the reverse operation: make an image from the container. The top layer of the container differs from the rest only in write permission, otherwise it is a regular layer - a set of files and directories. By making the top layer read only, we will convert the container to an image.

Now I can transfer the image to another machine and run. At the same time, you can see the databases created in the previous step on the PostgreSQL server. When changes are made during the operation of the container, the database file will be copied from the immutable data layer to the recording layer and there it has already been changed.

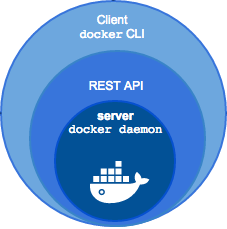
Docker
When we install the docker on the local machine, we get a client (CLI) and an http server that works as a daemon. The server provides a REST API, and the console simply converts the entered commands into http requests.
Registry
Registry is a repository of images. The most famous is DockerHub. It resembles GitHub, only contains images, not source code. DockerHub also has repositories, public and private, you can download images (pull), upload image changes (push). Once downloaded images and containers collected on their basis are stored locally until they are deleted manually.

There is the possibility of creating your own image storage, then, if necessary, Docker will look for images there that are not yet locally. I must say that when using Docker, the image storage becomes the most important link in CI / CD: the developer commits to the repository, tests are launched. If the tests were successful, then based on the commit, the existing one is updated or a new image is assembled with a subsequent deployment. And in the registry, not whole images are updated, but only the necessary layers.
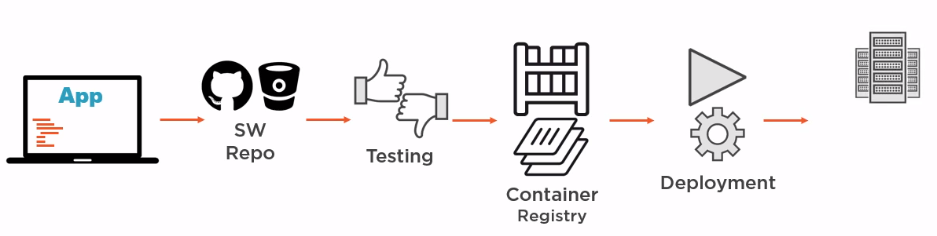
It is important not to limit the perception of the image as a kind of box in which the application is simply delivered to the destination and then launched. The application can also be built inside the image(it’s more correct to say inside the container, but more on that later). In the diagram above, the server that builds the images can only have Docker installed, and not the various environments, platforms, and applications needed to build different components of our application.
Dockerfile
Dockerfile is a set of instructions on the basis of which a new image is built. Each instruction adds a new layer to the image. For example, consider the Dockerfile, on the basis of which an image of the previously considered .NET application MyApplication could be created:
FROM microsoft/aspnetcore
WORKDIR /app
COPY bin/Debug/publish .
ENTRYPOINT["dotnet", "MyApplication.dll"]
Let's consider each instruction separately:
- we determine the basic image, on the basis of which we will build our own. In this case, we take microsoft / aspnetcore - the official image from Microsoft, which can be found on DockerHub
- set the working directory inside the image
- copy the pre-shared MyApplication application to the working directory inside the image. First, the source directory is written - the path relative to the context specified in the command
docker build, and the second argument is the target directory inside the image, in this case, the dot indicates the working directory - configure the container as executable: in our case, the command will be executed to start the container
dotnet MyApplication.dll
If we execute the command in the directory with Dockerfile
docker build, then we will get an image based on microsoft / aspnetcore, to which three more layers will be added. 
Consider another Dockerfile, which demonstrates the excellent Docker feature for lightweight images. A similar file is generated by VisualStudio 2017 for a project with container support and it allows you to collect an image from the application source code.
FROM microsoft/aspnetcore-build:2.0 AS publish
WORKDIR /src
COPY . .
RUN dotnet restore
RUN dotnet publish -o /publish
FROM microsoft/aspnetcore:2.0
WORKDIR /app
COPY --from=publish /publish .
ENTRYPOINT ["dotnet", "MyApplication.dll"]
The instructions in the file are divided into two sections:
- Defining an image to build the application: microsoft / aspnetcore-build. This image is designed to build, publish and run .NET applications and, according to DockerHub with a tag of 2.0, has a size of 699 MB . Next, the source files of the application are copied into the image and commands are executed inside it
dotnet restoreand thedotnet buildresults are placed in the / publish directory inside the image. - The base image is determined, in this case it is microsoft / aspnetcore, which contains only the runtime and, according to DockerHub with the 2.0 tag, has a size of only 141 MB . Next, the working directory is determined and the result of the previous stage is copied into it (its name is indicated in the argument
--from), the command to launch the container is determined, and that's it - the image is ready.
As a result, initially having the source code of the application, on the basis of a heavy image with the SDK, the application was duplicated, and then the result is placed on top of a light image containing only the runtime!
In conclusion, I want to note that for the sake of simplicity I intentionally operated on the concept of an image, considering working with the Dockerfile. In fact, the changes made by each instruction occur, of course, not in the image (after all, it only has immutable layers), but in the container. The mechanism is this: a container is created from the base image (a layer for recording is added to it), the instruction in this layer is executed (it can add files to the layer for recording:
COPYor not :) ENTRYPOINT, the command is calleddocker commitand the image is obtained. The process of creating a container and commit to an image is repeated for each instruction in the file. As a result, in the process of forming the final image, as many intermediate images and containers are created as there are instructions in the file. All of them are automatically deleted after the assembly of the final image.Conclusion
Of course, Docker is not a panacea and its use should be justified and motivated not only by the desire to use modern technology, which many talk about. At the same time, I am sure that Docker, applied competently and to the place, can bring many benefits at all stages of software development and make life easier for all participants in the process.
I hope I could reveal the basic points and interest in further study of the issue. Of course, for mastering Docker this article alone is not enough, but I hope it will become one of the elements of the puzzle for understanding the general picture of what is happening in the world of containers running Docker.
References
- Docker Documentation
- Namespaces mechanism
- Control groups mechanism
- Docker Article