Apache Kafka: review
- Transfer
Hello, Habr!
Today we offer you a relatively brief, but at the same time sensible and informative article about the device and applications of Apache Kafka. We hope to translate and release the book of Neha Narkhede et. al until the end of summer.

Enjoy reading!
Introduction
Today there is a lot of talk about Kafka. Many leading IT companies are already actively and successfully using this tool. But what is Kafka?
Kafka was developed at LinkedIn in 2011 and has since been greatly improved. Today, Kafka is an entire platform that provides redundancy sufficient to store absurdly huge amounts of data. It provides a message bus with tremendous bandwidth, on which you can process in real time absolutely all the data passing through it.
All this is cool, however, if we reduce Kafka to the dry residue, we get a distributed horizontally scalable fault-tolerant commit log .
Sounds wisely. Let's look at each of these terms and see what it means. And then we will examine in detail how all this works.
Distributed
Distributed is a system that works in a segmented form immediately on many machines that make up a single cluster; therefore, for the end user, they look like a single node. The distribution of Kafka lies in the fact that the storage, receipt and distribution of messages from him is organized on different nodes (the so-called "brokers").
The most important advantages of this approach are high availability and fault tolerance.
Horizontally scalable
Let's first decide what vertical scalability is. Suppose we have a traditional database server, and it gradually ceases to cope with the growing load. To cope with this problem, you can simply increase the resources (CPU, RAM, SSD) on the server. This is vertical scaling - additional resources are hung on the machine. With this “scaling up” there are two serious drawbacks:
Horizontal scalability solves exactly the same problem, we just connect more and more machines to the business. When adding a new machine, no downtime occurs, while the number of machines that can be added to the cluster is unlimited. The catch is that not all systems support horizontal scalability, many systems are not designed to work with clusters, and those that are designed are usually very difficult to operate.

After a certain threshold, horizontal scaling becomes much cheaper than vertical.
Fault tolerance
For distributed systems, the so-called single point of failure is typical. If the only server in your database fails for some reason, you are hit.
Distributed systems are designed so that their configuration can be adjusted by adapting to failures. A five-node Kafka cluster remains operational, even if two nodes fall. It should be noted that to ensure fault tolerance, you must partially sacrifice performance, because the better your system tolerates failures, the lower its performance.
The commit
log The commit log (also called the "write-ahead log", "transaction log") is a long-term ordered data structure, and data can only be added to such a structure. Entries from this log can neither be changed nor deleted. Information is read from left to right; in this way, the correct order of the elements is guaranteed.
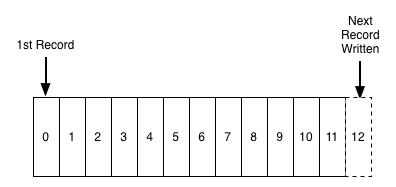
Commit Log Schema
In essence, Kafka stores all its messages on disk (more on this below), and when organizing messages in the form of the structure described above, you can use sequential read from disk.
These two points dramatically increase productivity, since it is completely independent of the size of the data. Kafka works equally well, whether you have 100KB or 100TB of data on your server.
How does it all work?
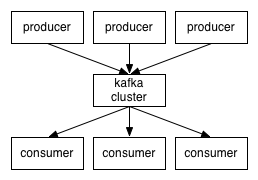
Applications ( generators ) send messages ( records ) to the Kafka node ( broker ), and these messages are processed by other applications, the so-called consumers . These messages are saved in the topic , and consumers subscribe to the topic to receive new messages.
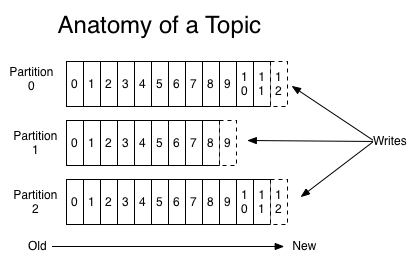
Themes can grow, so larger topics are divided into smaller sections to improve performance and scalability. (example:Let's say you saved user login requests; in this case, you can distribute them by the first character in the username )
Kafka guarantees that all messages within the section will be ordered exactly in the order in which they arrived. A specific message can be found by its offset, which can be considered a regular index in the array, a sequence number that increases by one for each new message in this section.
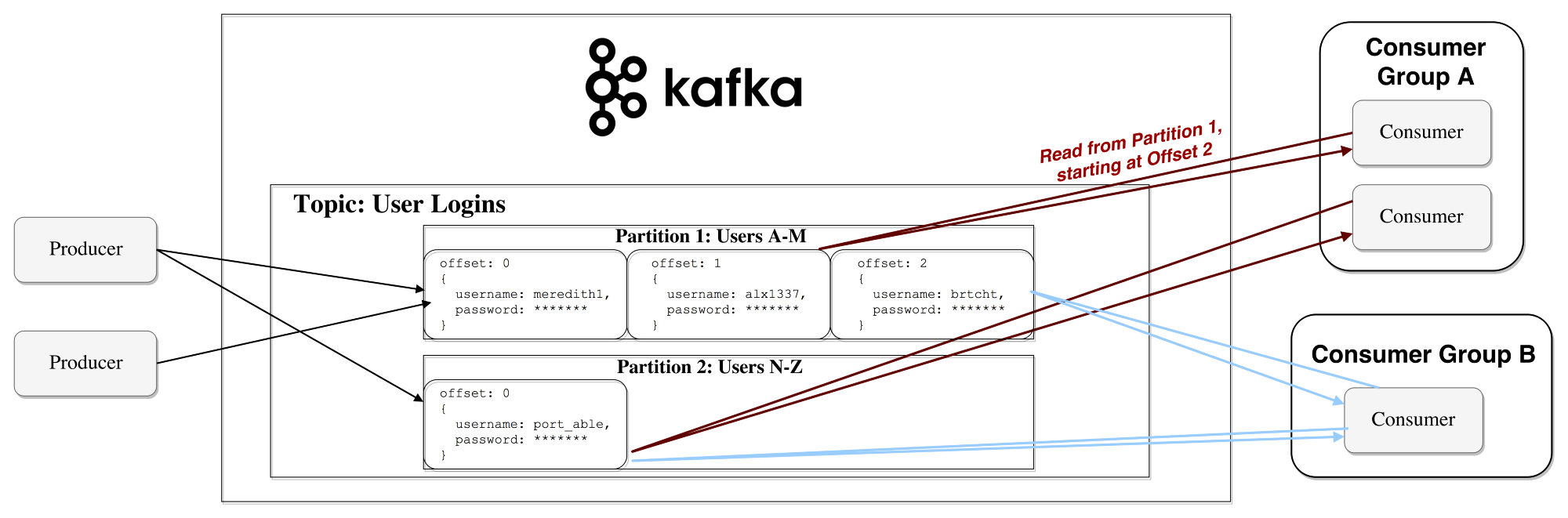
Kafka adheres to the principle of “stupid broker - smart consumer”. Thus, Kafka does not track which records are read by the consumer and then deleted, but simply stores them for a specified period of time (for example, a day), or until a certain threshold is reached. Consumers themselves interview Kafka for new messages and indicate which records they need to read. Thus, they can increase or decrease the offset, moving to the desired record; however, events can be replayed or re-processed.
It should be noted that in fact it is not about single consumers, but about groups, in each of which there is one or more consumer processes. In order to prevent a situation where two processes could read the same message twice, each section is bound to only one consumer process within the group.
This is how the data stream
works. Long-term storage on disk
As mentioned above, Kafka actually stores its records on disk and does not store anything in RAM. Yes, the question is possible, is there even a drop of sense in this? But Kafka has many optimizations that make this possible:
Thanks to all these optimizations, Kafka delivers messages almost as fast as the network itself.
Distributing and replicating data
Now let's discuss how Kafka achieves fault tolerance and how it distributes data between nodes.
Data replication
Data from a segment is replicated to many brokers so that data is saved if one of the brokers fails.
In any case, one of the brokers always “owns” the section: this broker is the one on which the applications read and write to the section. This broker is called the " section leader ." It replicates the received data to N other brokers, the so-called followers. The slaves also store data, and any of them can be selected as the master if the current master fails.
In this way, guarantees can be configured to ensure that any message that is successfully published is not lost. When it’s possible to change the replication rate, you can partially sacrifice performance for increased protection and data durability (depending on how critical they are).

Thus, if one of the leaders ever refuses, a follower can take his place.
However, it is logical to ask:
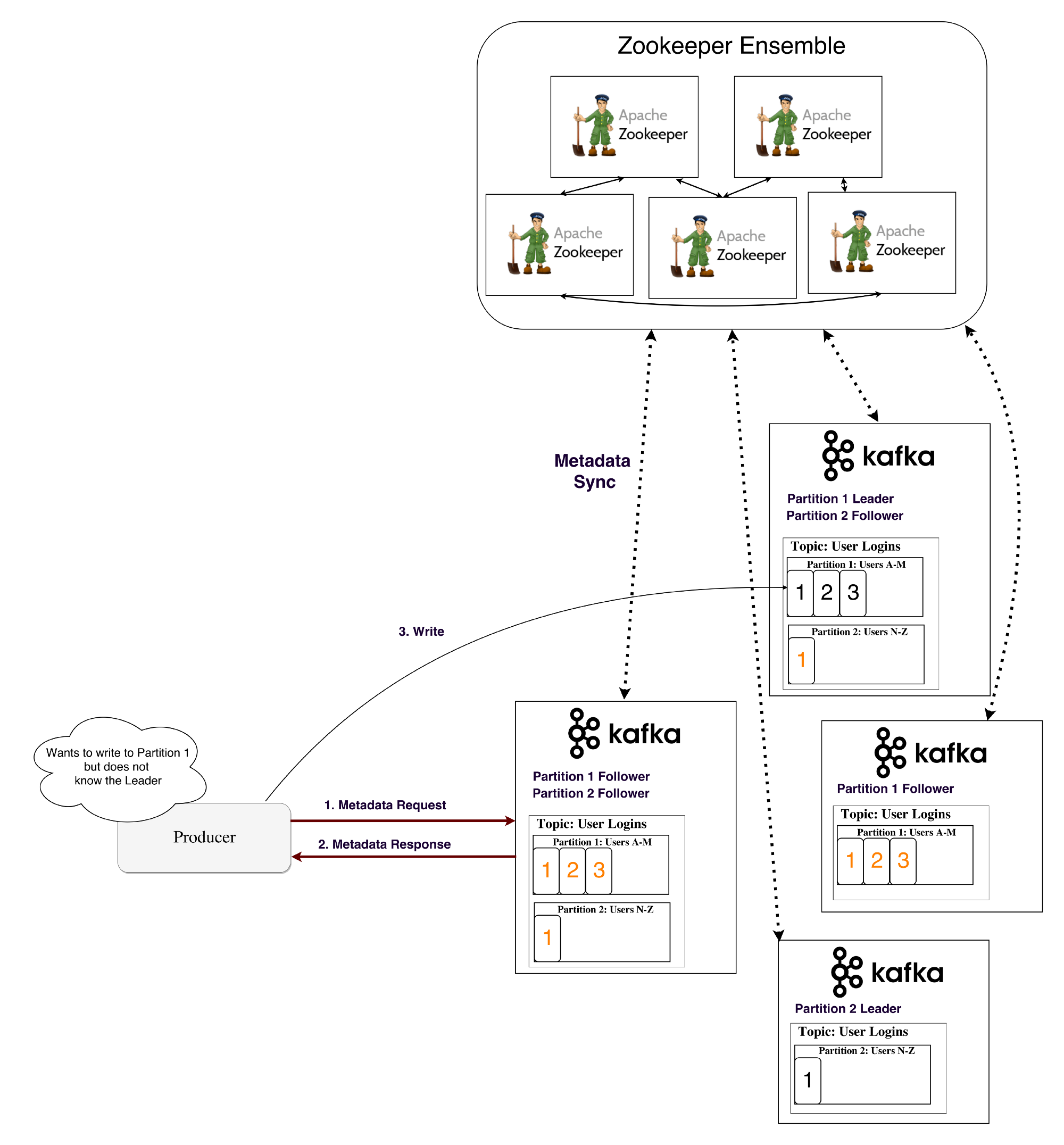
Kafka uses a service called Zookeeper to store such metadata .
What is a zookeeper?
Zookeeper is a distributed repository of keys and values. It is highly optimized for reading, but writing to it is slower. Most often, Zookeeper is used to store metadata and process clustering mechanisms (heart rate, distributed update / configuration operations, etc.).
Thus, customers of this service (Kafka brokers) can subscribe to it - and will receive information about any changes that may occur. This is how brokers find out when the leader in a section changes. Zookeeper is exceptionally fault tolerant (as it should be), since Kafka is highly dependent on it.
It is used to store all kinds of metadata, in particular:
How does the generator / consumer determine the lead broker in this section?
Previously, the Generator and Consumers directly connected to Zookeeper and learned from him this (as well as other) information. Now Kafka is moving away from such a bundle and, starting from versions 0.8 and 0.9, respectively, clients, firstly, choose metadata directly from Kafka brokers, and brokers turn to Zookeeper.
Stream of metadata
Streams The
stream processor in Kafka is responsible for all of the following work: it receives continuous streams of data from the input ones, somehow processes this input and feeds the data stream to the output topics (or to external services, databases, to the trash, yes, anywhere ...)
Simple processing can be performed directly on the generator / consumer API, however, more complex conversions - for example, combining streams in Kafka are performed using the integrated Streams API library .
This API is intended for use within your own code base; it does not work on a broker. Functionally, it is similar to the consumer API; it facilitates the horizontal scaling of thread processing and its distribution between several applications (similar to consumer groups).
Stateless processing Stateless
processing is a stream of deterministic processing that is independent of any external factors. As an example, consider this simple data conversion: attach information to a string
Stream-table dualism
It is important to understand that streams and tables are essentially the same thing. A stream can be interpreted as a table, and a table as a stream.
Stream as a table
If you pay attention to how synchronous database replication is performed, it is obvious that we are talking about stream replication , where any changes in the tables are sent to the copy server (replica). The Kafka stream can be interpreted in exactly the same way as the stream of updates for the data, which are aggregated and give the final result appearing in the table. Such streams are stored in the local RocksDB (by default) and are called KTable .
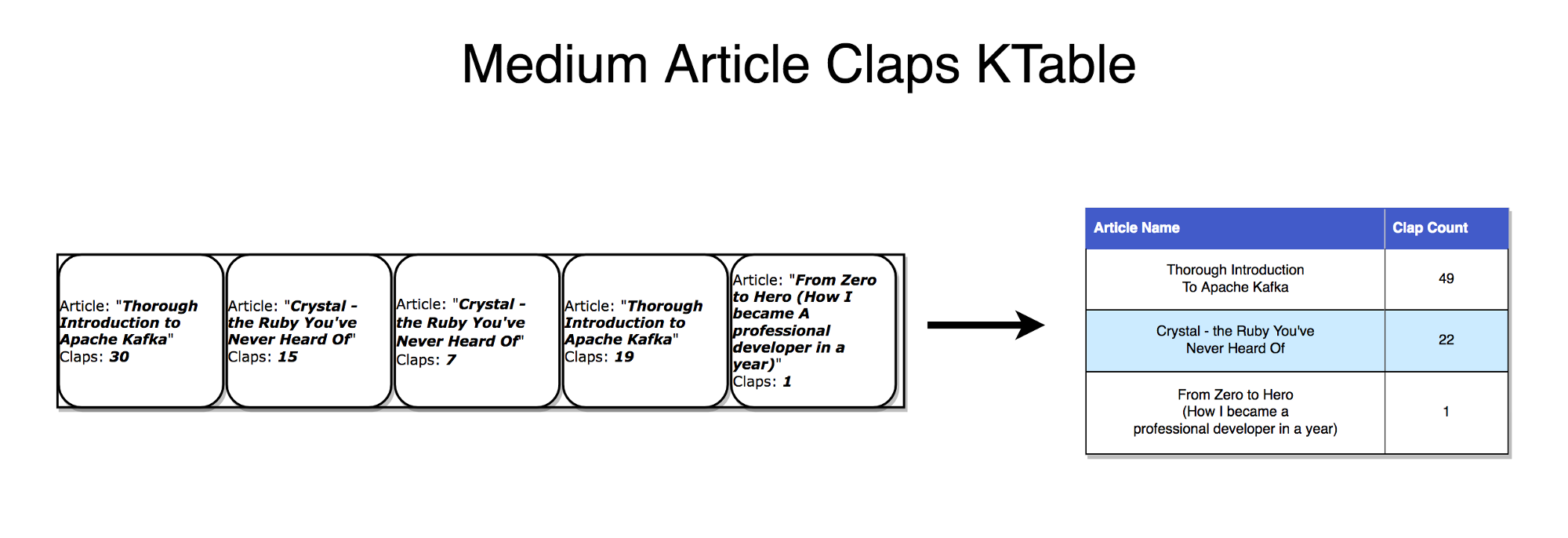
Table as stream
The table can be considered a snapshot reflecting the last value for each key in the stream. Similarly, a table can be compiled from streaming records, and a stream with a change log can be formed from table updates.
With each update, you can take a snapshot of the stream (recording)
Stateful processing
Some simple operations, for example,
The problem with maintaining state in streaming processors is that these processors sometimes fail! Where to store this state to ensure fault tolerance?
A simplified approach is to simply store all the state in a remote database and connect to this repository over the network. The problem is that then the locality of the data is lost, and the data itself is repeatedly redirected over the network - both factors significantly slow down your application. A more subtle, but important problem is that the activity of your streaming processing job will depend heavily on the remote database - that is, this task will be self-sufficient (all your processing may fail if another command makes any changes to the database) .
So which approach is better?
Again, remember the dualism of tables and threads. Thanks to this property, streams can be converted to tables located exactly where the processing takes place. At the same time, we get a mechanism that ensures fault tolerance - we store streams on the Kafka broker.
A stream processor can save its state in a local table (for example, in RocksDB), which the input stream will update (possibly after some arbitrary transformations). If this process fails, then we can restore the corresponding data by repeatedly reproducing the stream.
You can even ensure that the remote database generates a stream and, in fact, broadcasts the change log, based on which you will rebuild the table on the local machine.

Stateful processing, connecting KStream with KTable
KSQL
As a rule, you have to write code for processing threads in one of the languages for the JVM, since it is the only official Kafka Streams API client that works with it.

KSQL installation sample
KSQL is a new feature that allows you to write simple stream jobs in a familiar language that resembles SQL.
We configure the KSQL server and interactively query it through the CLI to control processing. It works exactly with the same abstractions (KStream and KTable), guarantees the same advantages as the Streams API (scalability, fault tolerance) and greatly simplifies the work with streams.
Perhaps all this does not sound inspiring, but in practice it is very useful for testing the material. Moreover, this model allows you to join the stream processing even for those who are not involved in the development as such (for example, product owners). I recommend watching a short introductory video - see for yourself how simple everything is here.
Alternatives to Stream Processing
Kafka Streams are the perfect combination of strength and simplicity. Perhaps Kafka is the best tool for performing streaming tasks available on the market, and integrating with Kafka is much easier than with alternative streaming processing tools ( Storm , Samza , Spark , Wallaroo ).
The problem with most other streaming tools is that they are difficult to deploy (and hard to handle). A batch processing framework such as Spark requires:
Unfortunately, when trying to solve all these problems within the framework of one framework, this framework turns out to be too invasive. The framework tries to control all kinds of aspects of deploying, configuring, monitoring, and packaging the code.
Kafka Streams allows you to formulate your own deployment strategy when you need it, and work with a tool to your taste: Kubernetes , Mesos , Nomad , Docker Swarm , etc.
Kafka Streams is designed primarily for you to organize stream processing in your application, however, without the operational difficulties associated with supporting the next cluster. The only potential drawback of such a tool is its close connection with Kafka, however, in the current reality, when stream processing is mainly performed using Kafka, this small drawback is not so terrible.
When to use Kafka?
As mentioned above, Kafka allows you to send a huge amount of messages through a centralized environment, and then store them without worrying about performance or fearing that data will be lost.
Thus, Kafka will perfectly fit in the very center of your system and will work as a connecting link ensuring the interaction of all your applications. Kafka can be a central element of an event-driven architecture, allowing you to properly unhook applications from each other.
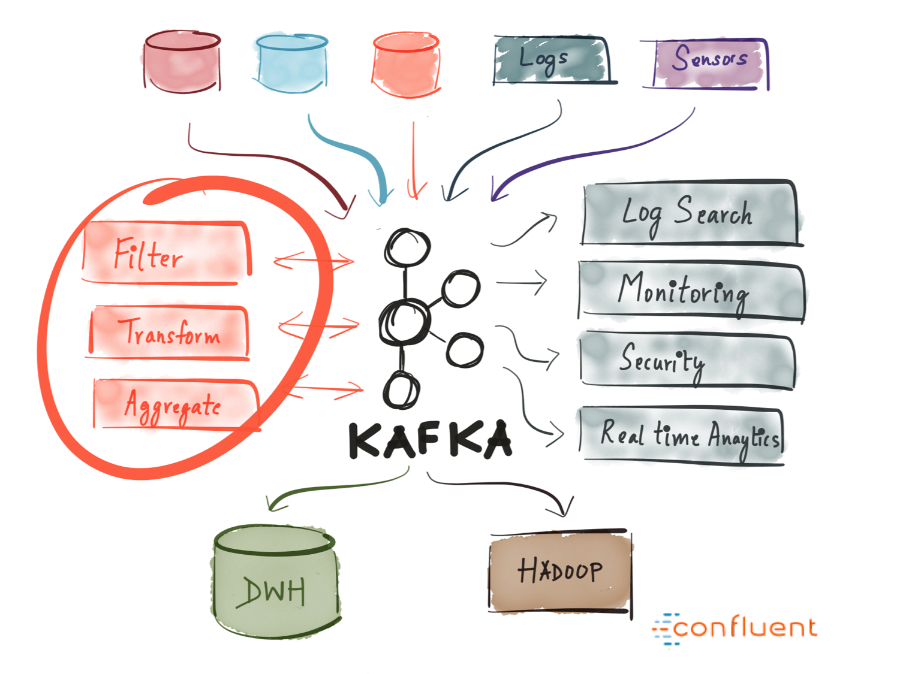
Kafka makes it easy to differentiate communication between different (micro) services. By working with the Streams API, it has become easier than ever to write business logic that enriches data from a Kafka theme before services begin to consume it. It offers tremendous opportunities - so I highly recommend exploring how Kafka is used in different companies.
Summary
Apache Kafka is a distributed streaming platform that processes trillions of events per day. Kafka guarantees minimum delays, high throughput, provides fault-tolerant pipelines operating on the principle of "publication / subscription" and allows you to process event streams.
In this article, we got acquainted with the basic semantics of Kafka (learned what a generator, broker, consumer, theme is), learned about some optimization options (page cache), learned what kind of fault tolerance Kafka guarantees when replicating data, and briefly discussed its powerful streaming capabilities.
Today we offer you a relatively brief, but at the same time sensible and informative article about the device and applications of Apache Kafka. We hope to translate and release the book of Neha Narkhede et. al until the end of summer.
Enjoy reading!
Introduction
Today there is a lot of talk about Kafka. Many leading IT companies are already actively and successfully using this tool. But what is Kafka?
Kafka was developed at LinkedIn in 2011 and has since been greatly improved. Today, Kafka is an entire platform that provides redundancy sufficient to store absurdly huge amounts of data. It provides a message bus with tremendous bandwidth, on which you can process in real time absolutely all the data passing through it.
All this is cool, however, if we reduce Kafka to the dry residue, we get a distributed horizontally scalable fault-tolerant commit log .
Sounds wisely. Let's look at each of these terms and see what it means. And then we will examine in detail how all this works.
Distributed
Distributed is a system that works in a segmented form immediately on many machines that make up a single cluster; therefore, for the end user, they look like a single node. The distribution of Kafka lies in the fact that the storage, receipt and distribution of messages from him is organized on different nodes (the so-called "brokers").
The most important advantages of this approach are high availability and fault tolerance.
Horizontally scalable
Let's first decide what vertical scalability is. Suppose we have a traditional database server, and it gradually ceases to cope with the growing load. To cope with this problem, you can simply increase the resources (CPU, RAM, SSD) on the server. This is vertical scaling - additional resources are hung on the machine. With this “scaling up” there are two serious drawbacks:
- There are certain limits associated with the capabilities of the equipment. You cannot endlessly grow.
- Such work is usually associated with downtime, and large companies cannot afford downtime.
Horizontal scalability solves exactly the same problem, we just connect more and more machines to the business. When adding a new machine, no downtime occurs, while the number of machines that can be added to the cluster is unlimited. The catch is that not all systems support horizontal scalability, many systems are not designed to work with clusters, and those that are designed are usually very difficult to operate.
After a certain threshold, horizontal scaling becomes much cheaper than vertical.
Fault tolerance
For distributed systems, the so-called single point of failure is typical. If the only server in your database fails for some reason, you are hit.
Distributed systems are designed so that their configuration can be adjusted by adapting to failures. A five-node Kafka cluster remains operational, even if two nodes fall. It should be noted that to ensure fault tolerance, you must partially sacrifice performance, because the better your system tolerates failures, the lower its performance.
The commit
log The commit log (also called the "write-ahead log", "transaction log") is a long-term ordered data structure, and data can only be added to such a structure. Entries from this log can neither be changed nor deleted. Information is read from left to right; in this way, the correct order of the elements is guaranteed.
Commit Log Schema
- Do you mean that the data structure in Kafka is so simple?In many ways, yes. This structure forms the very core of Kafka and is absolutely invaluable because it provides orderliness, and orderliness - a deterministic processing. Both of these problems in distributed systems are difficult to solve.
In essence, Kafka stores all its messages on disk (more on this below), and when organizing messages in the form of the structure described above, you can use sequential read from disk.
- Read and write operations are performed for a constant time O (1) (if the record ID is known), which, compared to O (log N) operations on a disk in a different structure, incredibly saves time, since each head-raising operation is expensive.
- Read and write operations do not affect each other (the read operation does not block the write operation and vice versa, which cannot be said about operations with balanced trees).
These two points dramatically increase productivity, since it is completely independent of the size of the data. Kafka works equally well, whether you have 100KB or 100TB of data on your server.
How does it all work?
Applications ( generators ) send messages ( records ) to the Kafka node ( broker ), and these messages are processed by other applications, the so-called consumers . These messages are saved in the topic , and consumers subscribe to the topic to receive new messages.
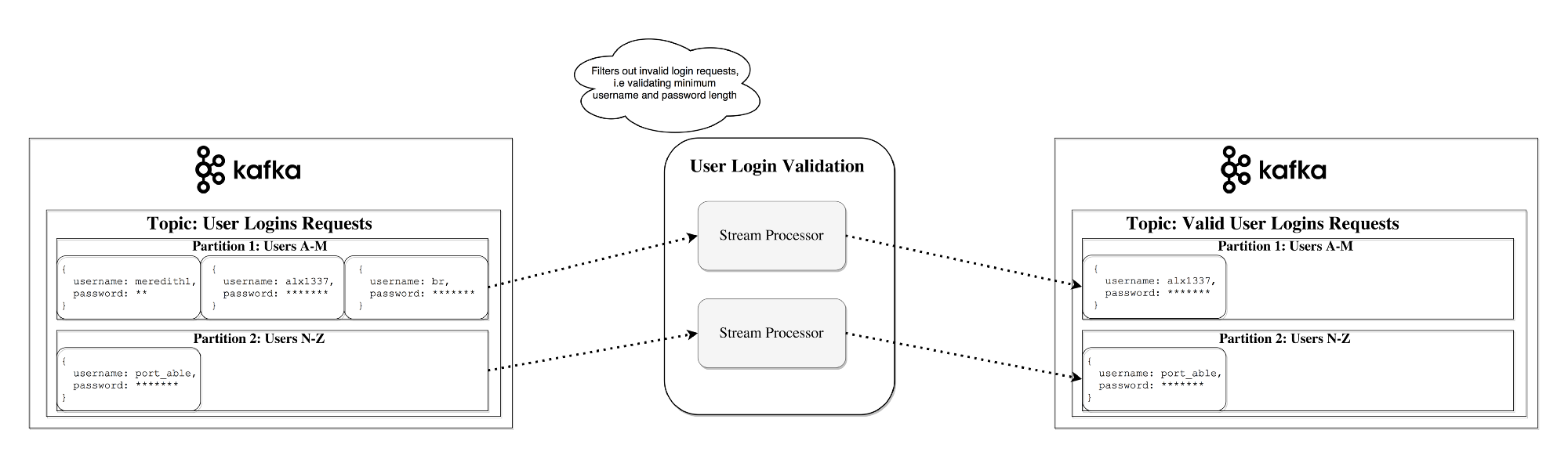
Themes can grow, so larger topics are divided into smaller sections to improve performance and scalability. (example:Let's say you saved user login requests; in this case, you can distribute them by the first character in the username )
Kafka guarantees that all messages within the section will be ordered exactly in the order in which they arrived. A specific message can be found by its offset, which can be considered a regular index in the array, a sequence number that increases by one for each new message in this section.
Kafka adheres to the principle of “stupid broker - smart consumer”. Thus, Kafka does not track which records are read by the consumer and then deleted, but simply stores them for a specified period of time (for example, a day), or until a certain threshold is reached. Consumers themselves interview Kafka for new messages and indicate which records they need to read. Thus, they can increase or decrease the offset, moving to the desired record; however, events can be replayed or re-processed.
It should be noted that in fact it is not about single consumers, but about groups, in each of which there is one or more consumer processes. In order to prevent a situation where two processes could read the same message twice, each section is bound to only one consumer process within the group.
This is how the data stream
works. Long-term storage on disk
As mentioned above, Kafka actually stores its records on disk and does not store anything in RAM. Yes, the question is possible, is there even a drop of sense in this? But Kafka has many optimizations that make this possible:
- Kafka has a protocol that groups messages together. Therefore, when network requests, messages are grouped, which reduces network costs, and the server, in turn, saves a batch of messages in one sitting, after which consumers can immediately choose large linear sequences of such messages.
- Linear read and write operations to disk are fast. There is a known problem: modern drives work relatively slowly due to the need for a head-feed, however, with large linear operations this problem disappears.
- These linear operations are greatly optimized by the operating system by reading ahead of time (large groups of blocks are selected in advance) and lagging recordings (small logical write operations are combined into large physical write operations).
- Modern operating systems cache the disk in free RAM. This technique is called page cache .
- Since Kafka saves messages in a standardized binary format that does not change throughout the chain (generator-> broker-> consumer), zero copy optimization is appropriate here. In this case, the OS copies the data from the page cache directly to the socket, practically bypassing the broker application related to Kafka.
Thanks to all these optimizations, Kafka delivers messages almost as fast as the network itself.
Distributing and replicating data
Now let's discuss how Kafka achieves fault tolerance and how it distributes data between nodes.
Data replication
Data from a segment is replicated to many brokers so that data is saved if one of the brokers fails.
In any case, one of the brokers always “owns” the section: this broker is the one on which the applications read and write to the section. This broker is called the " section leader ." It replicates the received data to N other brokers, the so-called followers. The slaves also store data, and any of them can be selected as the master if the current master fails.
In this way, guarantees can be configured to ensure that any message that is successfully published is not lost. When it’s possible to change the replication rate, you can partially sacrifice performance for increased protection and data durability (depending on how critical they are).
Thus, if one of the leaders ever refuses, a follower can take his place.
However, it is logical to ask:
- How does the generator / consumer find out which broker is the leader of this section?So that the generator / consumer can write / read information in this section, the application needs to know which of the brokers is the leader here, right? This information needs to be taken somewhere.
Kafka uses a service called Zookeeper to store such metadata .
What is a zookeeper?
Zookeeper is a distributed repository of keys and values. It is highly optimized for reading, but writing to it is slower. Most often, Zookeeper is used to store metadata and process clustering mechanisms (heart rate, distributed update / configuration operations, etc.).
Thus, customers of this service (Kafka brokers) can subscribe to it - and will receive information about any changes that may occur. This is how brokers find out when the leader in a section changes. Zookeeper is exceptionally fault tolerant (as it should be), since Kafka is highly dependent on it.
It is used to store all kinds of metadata, in particular:
- The bias of consumer groups within the section (although modern customers store biases in a separate Kafka topic)
- ACLs (access control lists) - used to restrict access / authorization
- Generator and consumer quotas - maximum message limits per second
- Leading sections and their level of performance
How does the generator / consumer determine the lead broker in this section?
Previously, the Generator and Consumers directly connected to Zookeeper and learned from him this (as well as other) information. Now Kafka is moving away from such a bundle and, starting from versions 0.8 and 0.9, respectively, clients, firstly, choose metadata directly from Kafka brokers, and brokers turn to Zookeeper.
Stream of metadata
Streams The
stream processor in Kafka is responsible for all of the following work: it receives continuous streams of data from the input ones, somehow processes this input and feeds the data stream to the output topics (or to external services, databases, to the trash, yes, anywhere ...)
Simple processing can be performed directly on the generator / consumer API, however, more complex conversions - for example, combining streams in Kafka are performed using the integrated Streams API library .
This API is intended for use within your own code base; it does not work on a broker. Functionally, it is similar to the consumer API; it facilitates the horizontal scaling of thread processing and its distribution between several applications (similar to consumer groups).
Stateless processing Stateless
processing is a stream of deterministic processing that is independent of any external factors. As an example, consider this simple data conversion: attach information to a string
"Hello" -> "Hello, World!"Stream-table dualism
It is important to understand that streams and tables are essentially the same thing. A stream can be interpreted as a table, and a table as a stream.
Stream as a table
If you pay attention to how synchronous database replication is performed, it is obvious that we are talking about stream replication , where any changes in the tables are sent to the copy server (replica). The Kafka stream can be interpreted in exactly the same way as the stream of updates for the data, which are aggregated and give the final result appearing in the table. Such streams are stored in the local RocksDB (by default) and are called KTable .
Table as stream
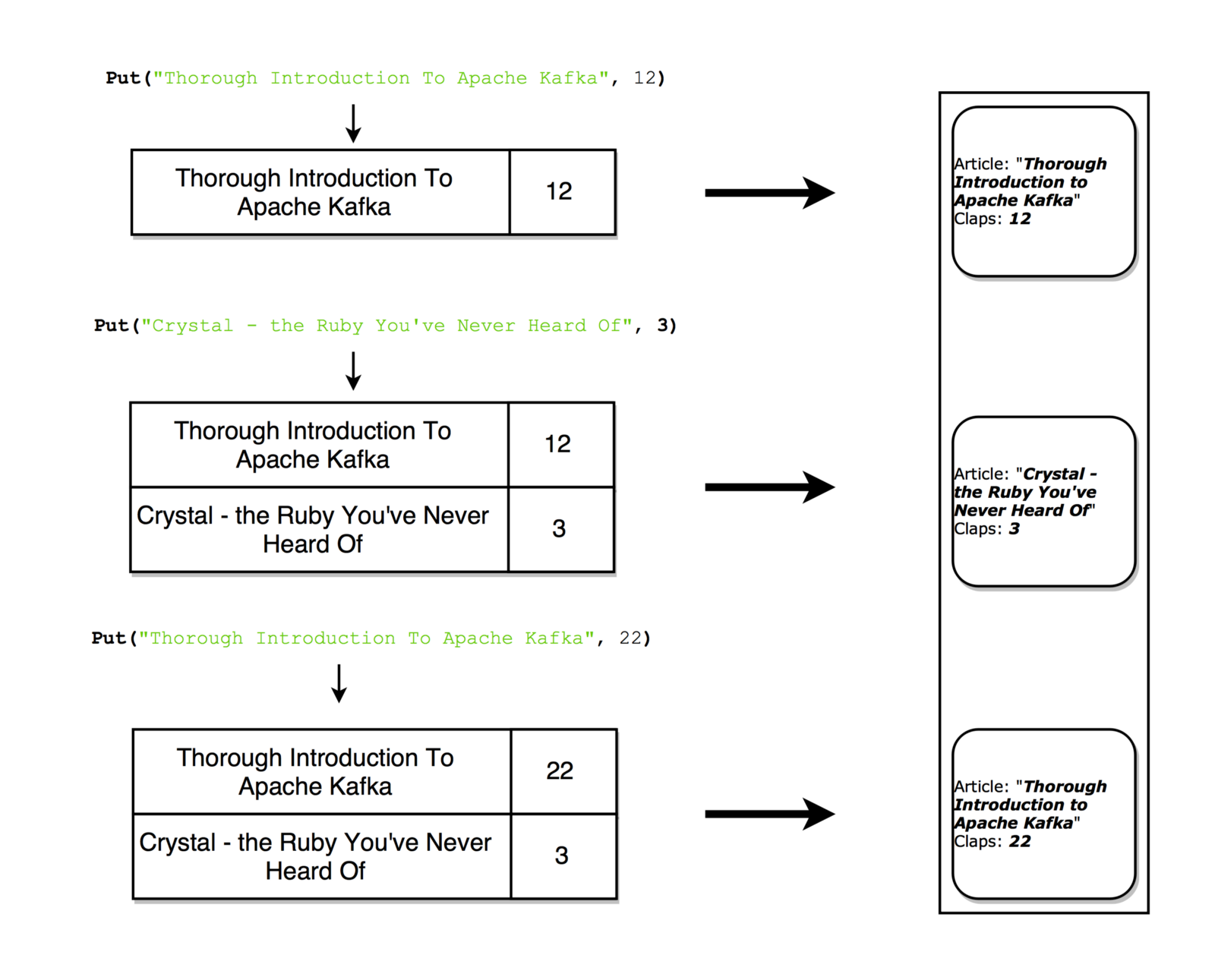
The table can be considered a snapshot reflecting the last value for each key in the stream. Similarly, a table can be compiled from streaming records, and a stream with a change log can be formed from table updates.
With each update, you can take a snapshot of the stream (recording)
Stateful processing
Some simple operations, for example,
map()or filter(), are performed without state preservation, and we do not have to store any data regarding their processing. However, in practice, most operations are performed with state preservation (for example count()), so you naturally have to store the current state.The problem with maintaining state in streaming processors is that these processors sometimes fail! Where to store this state to ensure fault tolerance?
A simplified approach is to simply store all the state in a remote database and connect to this repository over the network. The problem is that then the locality of the data is lost, and the data itself is repeatedly redirected over the network - both factors significantly slow down your application. A more subtle, but important problem is that the activity of your streaming processing job will depend heavily on the remote database - that is, this task will be self-sufficient (all your processing may fail if another command makes any changes to the database) .
So which approach is better?
Again, remember the dualism of tables and threads. Thanks to this property, streams can be converted to tables located exactly where the processing takes place. At the same time, we get a mechanism that ensures fault tolerance - we store streams on the Kafka broker.
A stream processor can save its state in a local table (for example, in RocksDB), which the input stream will update (possibly after some arbitrary transformations). If this process fails, then we can restore the corresponding data by repeatedly reproducing the stream.
You can even ensure that the remote database generates a stream and, in fact, broadcasts the change log, based on which you will rebuild the table on the local machine.
Stateful processing, connecting KStream with KTable
KSQL
As a rule, you have to write code for processing threads in one of the languages for the JVM, since it is the only official Kafka Streams API client that works with it.
KSQL installation sample
KSQL is a new feature that allows you to write simple stream jobs in a familiar language that resembles SQL.
We configure the KSQL server and interactively query it through the CLI to control processing. It works exactly with the same abstractions (KStream and KTable), guarantees the same advantages as the Streams API (scalability, fault tolerance) and greatly simplifies the work with streams.
Perhaps all this does not sound inspiring, but in practice it is very useful for testing the material. Moreover, this model allows you to join the stream processing even for those who are not involved in the development as such (for example, product owners). I recommend watching a short introductory video - see for yourself how simple everything is here.
Alternatives to Stream Processing
Kafka Streams are the perfect combination of strength and simplicity. Perhaps Kafka is the best tool for performing streaming tasks available on the market, and integrating with Kafka is much easier than with alternative streaming processing tools ( Storm , Samza , Spark , Wallaroo ).
The problem with most other streaming tools is that they are difficult to deploy (and hard to handle). A batch processing framework such as Spark requires:
- Manage a large number of tasks on a pool of machines and efficiently distribute them in a cluster.
- This requires dynamically packaging the code and physically deploying it to the nodes where it will be executed (plus configuration, libraries, etc.)
Unfortunately, when trying to solve all these problems within the framework of one framework, this framework turns out to be too invasive. The framework tries to control all kinds of aspects of deploying, configuring, monitoring, and packaging the code.
Kafka Streams allows you to formulate your own deployment strategy when you need it, and work with a tool to your taste: Kubernetes , Mesos , Nomad , Docker Swarm , etc.
Kafka Streams is designed primarily for you to organize stream processing in your application, however, without the operational difficulties associated with supporting the next cluster. The only potential drawback of such a tool is its close connection with Kafka, however, in the current reality, when stream processing is mainly performed using Kafka, this small drawback is not so terrible.
When to use Kafka?
As mentioned above, Kafka allows you to send a huge amount of messages through a centralized environment, and then store them without worrying about performance or fearing that data will be lost.
Thus, Kafka will perfectly fit in the very center of your system and will work as a connecting link ensuring the interaction of all your applications. Kafka can be a central element of an event-driven architecture, allowing you to properly unhook applications from each other.
Kafka makes it easy to differentiate communication between different (micro) services. By working with the Streams API, it has become easier than ever to write business logic that enriches data from a Kafka theme before services begin to consume it. It offers tremendous opportunities - so I highly recommend exploring how Kafka is used in different companies.
Summary
Apache Kafka is a distributed streaming platform that processes trillions of events per day. Kafka guarantees minimum delays, high throughput, provides fault-tolerant pipelines operating on the principle of "publication / subscription" and allows you to process event streams.
In this article, we got acquainted with the basic semantics of Kafka (learned what a generator, broker, consumer, theme is), learned about some optimization options (page cache), learned what kind of fault tolerance Kafka guarantees when replicating data, and briefly discussed its powerful streaming capabilities.