BaselineTopology concept in Apache Ignite 2.4

At the time the Ignite project appeared in the Apache Software Foundation, it was positioned as a pure in-memory solution: a distributed cache that lifts data from a traditional DBMS into memory in order to gain access time. But already in release 2.1 there was a module of built-in persistence ( Native Persistence ), which allows you to classify Ignite as a complete distributed database. Since then, Ignite has ceased to depend on external systems for ensuring persistent data storage, and the bundle of the configuration and administration rake that users have stepped on more than once has disappeared.
However, persistent mode begets its own scripts and new questions. How to prevent unsolvable data conflicts in a split-brain situation? Can we refuse to re-balance partitions if the node output now does not mean that the data on it is lost? How to automate additional actions like activating a cluster ? BaselineTopology to help us.
BaselineTopology: first acquaintance
Conceptually, a cluster in in-memory mode is simple: there are no dedicated nodes, all are equal, you can assign a cache partition to each, send a computational task, or deploy a service. If the node leaves the topology, then user requests will be served by other nodes, and the data of the exited node will no longer be available.
Using cluster groups and user attributes, the user can distribute nodes into classes based on the selected characteristics. However, restarting any node makes it “forget” what happened to it before the restart. The cache data will be re-flashed in the cluster, the computational tasks will be re-executed, and the services will be redeployed. Since nodes do not store state, they are completely interchangeable.
In persistence mode, the nodes retain their state even after a restart: during the start process, the node data is read from the disk, and its state is restored. Therefore, rebooting the node does not make it necessary to completely copy data from other nodes in the cluster (a process known as rebalancing): data at the time of the fall will be restored from the local disk. This opens up opportunities for very attractive optimization of network interaction, and as a result, the productivity of the entire cluster will increase. So, we need to somehow distinguish between many nodes that are able to maintain their state after a restart from all the others. This task is served by BaselineTopology.
It is worth noting that the user can use persistent caches simultaneously with in-memory caches. The latter will continue to live the same life as before: consider all nodes equal and interchangeable, start redistributing partitions when nodes exit to maintain the number of data copies - BaselineTopology will only regulate the behavior of persistent caches.
BaselineTopology (hereinafter BLT) at the highest level is simply a collection of node identifiers that have been configured to store data. How to create a BLT in a cluster and manage it, we'll figure it out a bit later, but now let's see what kind of concept is useful in real life.
Persisted Data: No Drive
The problem of distributed systems, known as the split brain, is already complex when using persistence becomes even more insidious.
A simple example: we have a cluster and a replicated cache.
The standard approach to providing fault tolerance is to maintain the redundancy of a resource. Ignite takes this approach to ensure data storage reliability: depending on the configuration, the cache can store more than one copy of the key on different nodes of the cluster. The replicated cache stores one copy on each node; the partitioned cache stores a fixed number of copies.
You can learn more about this function from the documentation .
We perform simple manipulations on it in the following sequence:
- Stop the cluster and start node group A.
- Update any keys in the cache.
- Stop group A and start group B.
- We apply other updates for the same keys.
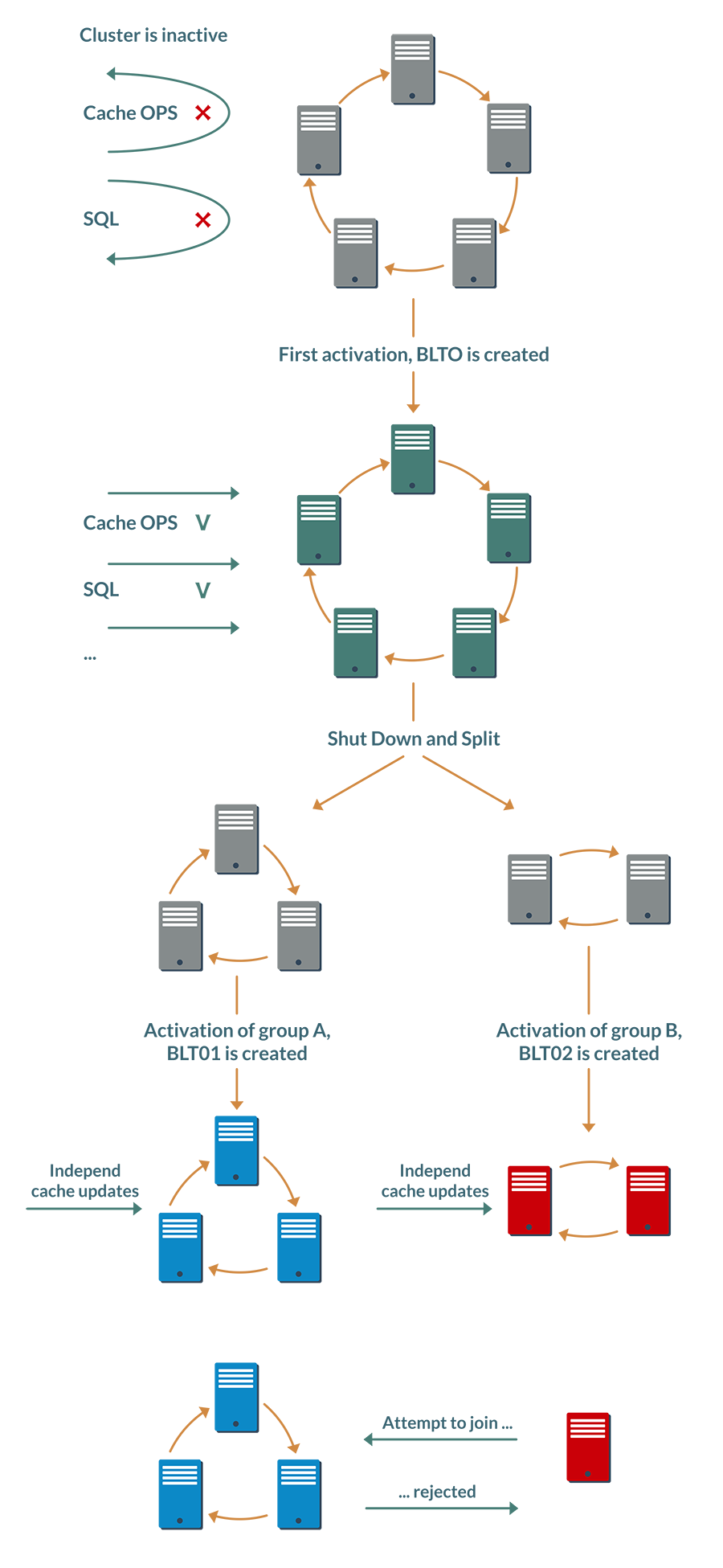
Since Ignite works in database mode, when the nodes of the second group are stopped, the updates will not be lost: they will become available as soon as we start the second group again. So after restoring the initial state of the cluster, different nodes can have different values for the same key.
Without much frenzy, just stopping and starting the nodes, we were able to bring the data in the cluster to an undefined state, which is automatically impossible to resolve.
Preventing this situation is just one of the tasks of BLT.
The idea is that in persistence mode, the launch of the cluster goes through an additional stage, activation.
At the very first activation, the first BaselineTopology is created and saved on the disk, which contains information about all the nodes present in the cluster at the time of activation.
This information also includes a hash calculated based on the identifiers of online nodes. If during subsequent activation some nodes are absent in the topology (for example, the cluster rebooted and one node was taken out for servicing), then the hash is re-calculated, and the previous value is saved in the activation history inside the same BLT.
Thus, BaselineTopology maintains a chain of hashes describing the composition of the cluster at the time of each activation.
At stages 1 and 3, after starting the node groups, the user will have to explicitly activate an incomplete cluster, and each online node will update BLT locally, adding a new hash to it. All nodes of each group will be able to calculate the same hashes, but in different groups they will be different.
You could already guess what will happen next. If a node tries to join a “foreign” group, it will be determined that the node is activated regardless of the nodes of this group and it will be denied access.
It is worth noting that this validation mechanism does not provide complete protection against conflicts in a Split-Brain situation. If the cluster is divided into two halves in such a way that at least one copy of the partition remains in each half, and the halves are not reactivated, then a situation is possible when conflicting changes in the same data arrive in half. BLT does not refute the CAP theorem , but protects against conflicts with obvious administrative errors.
Buns
In addition to preventing conflicts in the data, BLT allows you to implement a couple of optional, but nice options.
Bun No. 1 - minus one manual action. The activation mentioned above had to be performed manually after each reboot of the cluster; automation tools "out of the box" were absent. In the presence of BLT, the cluster can independently decide on activation.
Although the Ignite cluster is an elastic system, and nodes can be added and displayed dynamically, BTL proceeds from the concept that in database mode the user maintains a stable cluster composition.
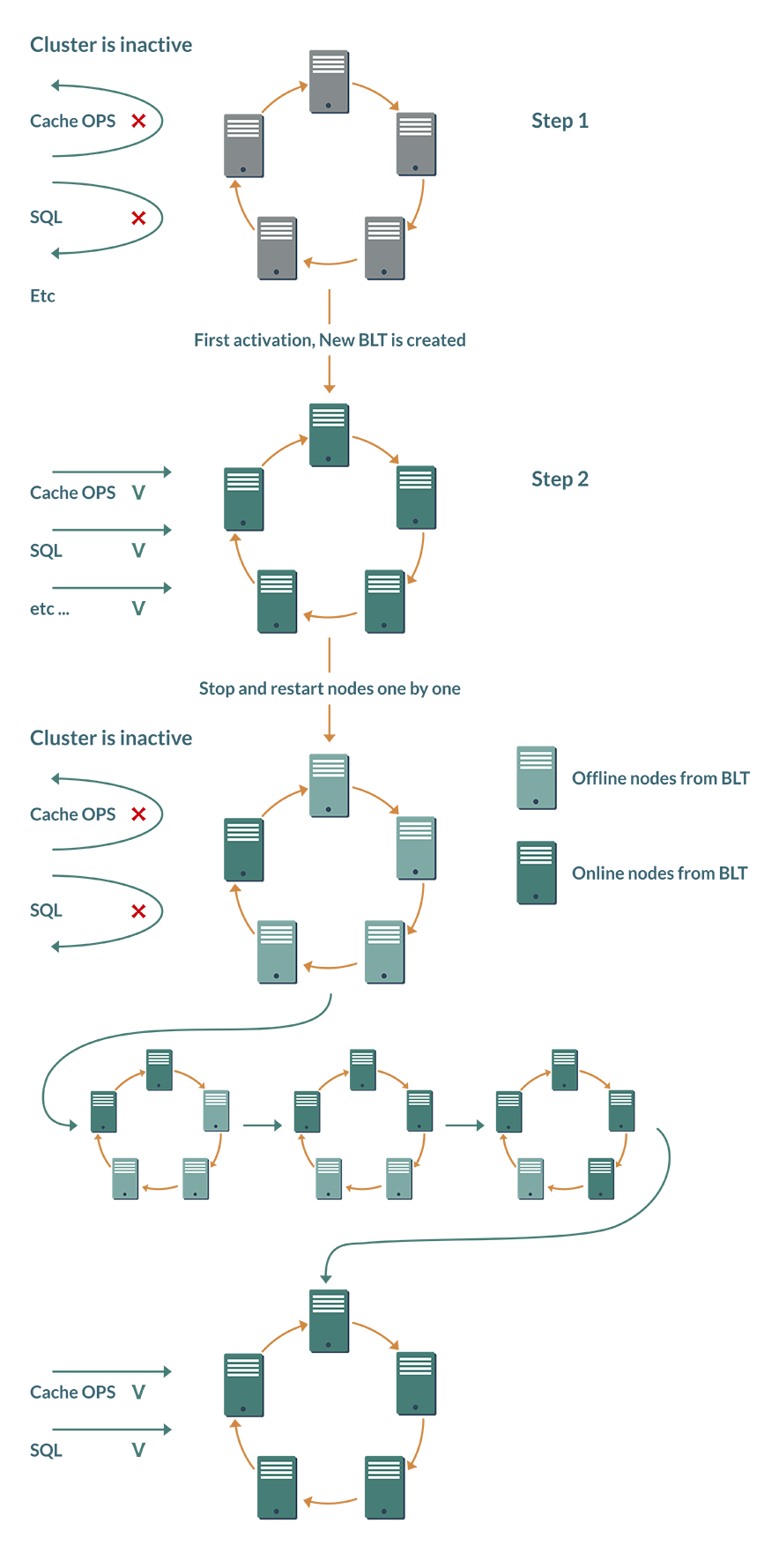
When a cluster is first activated, a freshly created BaselineTopology remembers which nodes should be present in the topology. After a reboot, each node checks the status of the other BLT nodes. As soon as all nodes are online, the cluster is activated automatically.
Bun No. 2 - saving on networking. The idea, again, is based on the assumption that the topology will remain stable for a long time. Previously, a node leaving the topology even for 10 minutes led to the launch of rebalancing the cache partitions to maintain the number of backups. But why waste network resources and slow down the cluster if problems with the node are resolved within minutes, and it will be online again. BaselineTopology optimizes this behavior.
Now the default cluster assumes that the problem node will soon return to service. Some of the caches during this time will work with fewer backups, but this will not lead to interruption or slowdown of the service.
BaselineTopology Management
Well, we already know one way: BaselineTopology is automatically created at the very first activation of the cluster. In this case, all server nodes that were online at the time of activation will be included in the BLT.
Manual administration of BLT is carried out using the control script from the Ignite distribution, more about which can be found on the documentation page on cluster activation.
The script provides a very simple API and supports only three operations: adding a node, deleting a node and installing a new BaselineTopology.
Moreover, if adding nodes is a fairly simple operation without special tricks, then removing the active node from BLT is a more subtle task. Its execution under load is fraught with racing, in the worst case - freezing of the entire cluster. Therefore, removal is accompanied by an additional condition: the deleted node must be offline. When you try to delete an online node, the control script will return an error and the operation will not start.
Therefore, when deleting a node from the BLT, one manual operation is still required: stopping the node. However, this use case will clearly not be the main one, so the additional labor costs are not too great.
The Java interface for managing BLT is even simpler and provides just one method to install BaselineTopology from a list of nodes.
An example of modifying BaselineTopology using the Java API:
Ignite ignite = /* ... */;
IgniteCluster cluster = ignite.cluster();
// Получаем BaselineTopology.
Collection curBaselineTop = cluster.baselineTopology();
for (ClusterNode node : cluster.topology(cluster.currentTopologyVersion())) {
// Если мы хотем, чтобы данный узел был в BaselineTopology
// (shouldAdd(ClusterNode) - пользовательская функция)
if (shouldAdd(node)
curTop.add(node);
}
// Обновляем BaselineTopology
cluster.setBaselineTopology(curTop); Conclusion
Ensuring data integrity is the most important task that any data warehouse must solve. In the case of distributed DBMSs, which include Apache Ignite, the solution to this problem becomes significantly more complicated.
BaselineTopology concept allows you to close some of the real scenarios in which data integrity may be compromised.
Ignite's other priority is performance, and here BLT also allows you to significantly save resources and improve system response time.
Native Persistence functionality appeared in the project quite recently, and, without a doubt, it will develop, become more reliable, more productive and more convenient to use. And with it, the BaselineTopology concept will also develop.