Javascript multithreaded computing, or how the phone won the laptop race
Hi, Habr!
We continue the battle for Javascript performance using the example of creating pivot tables. The last time , we have implemented a number of optimizations, and remained the last real opportunity to accelerate the calculation - move to multi-threaded computing. In Javascript, workers have long existed , the implementation of which is not without flaws, but it is stated that they use real operating system threads - so why not try? Suddenly, it turned out that in order to parallelize a simple, in essence, algorithm, we had to rewrite syntacys of aggregate formulas, since the old ones did not have the additivity property (more detailed under the cut), but ultimately everything turned out.
The processing of 1 million facts on two devices was tested:
From the graphs it follows several conclusions.
You can play with the tests yourself - the application is here , the test data generator is included, the calculation time is displayed.
Let me remind you what is our algorithm. An unstructured fact store is used as the source data; a data scheme is not created. JSON is sent to the input, containing interleaved operations and directories. We define calculations at 2 levels - a formula at the level of an individual fact (essentially a calculated attribute), and an aggregate formula at the row level of the pivot table. Then we apply a filter, and build a pivot table in one pass through the array of facts. In this single cycle, grouping is performed, aggregates are calculated, reference data is extracted, and the width of the columns is determined.
Data is stored in IndexedDB in blocks, each worker is allocated its own range of blocks, the main thread starts the workers, periodically receives status from them (the number of records processed), and, waiting for all to stop, it reduces the result. In the control example, the time for converting the result is negligible, but on other data, of course, there may be options. In order for the result to be reduced correctly, all aggregate formulas must have additivity, that is, they could be applied to both single facts and already counted blocks.
I did not understand before why Excel, adult OLAP systems and RDBMSs do not allow writing their own aggregate function in a scripting language, but contain only a set of predefined types like sum (), avg () and so on. For example, for a long time in Excel, there was not even a count_distinct function, and even now not all DBMSs have it. It turns out that if the user is allowed to determine his aggregate functions, not all of them will be additive, which means that the calculation cannot be parallelized, which is deadly for an industrial system. Let's show it on the example of 3 array aggregation functions:
The first function is additive, since it can be applied to itself, that is:
accumulator + (accumulator + currentValue) .
The second function cannot be parallelized at all, you need to work with the third one, because applying it in the forehead to the block:
accumulator + (accumulator + currentValue ** 2) ** 2 - will give an incorrect result, but if you parse the expression and understand that this is all - just the sum of squares - additivity is achieved. In our algorithm, accumulator is not just a scalar, but an array representing the current row of the pivot table, and currentValue is, respectively, an array of attribute values of the current fact (including those calculated), with the result that the risk of additivity breaks.
Let me remind you that in the first versionapplications in aggregate formulas used the fact (colname) and row (colname) functions (the first one returns the attribute of the current fact, the second - the intermediate calculated value of the pivot table column), and already the summing, counting, etc. expressions were compiled. However, the user is tempted to use in one aggregate formula, for example, several attributes of the fact, which is unacceptable if we want multithreading. I was too lazy to do the parsing of formulas - you can think of a little - and I made the simplest decision - to forbid using fact attributes directly in an aggregate formula, but only wrapping them in predefined aggregate primitives, so our pivot table will be described with such formulas:
Re-computing does not occur - the results of the calculation of aggregate primitives are cached. The primitives sum (), count (), mul (), min (), max (), last (), first () are available. The last function selectlast () pulls the directory prop from another fact, that is, in effect, it implements the join store itself to itself, but is calculated in a common cycle, that is, without loss of performance. As for the functions mode () , median () , count_distinct (), they are not additive, do not scale linearly, until the end of the calculation they will need to store all values in a separate structure (memory consumption), and therefore will be implemented later.
Probably, we can finish Javascript overclocking on this; we still didn’t quite catch up with Excel, although we came very close. Theoretically, you can still look in the direction of GPU-computing, for which you have to completely rewrite the algorithm ( there is a precedent ), but, in principle, it turned out pretty well. I wish you pleasant programming and fresh ideas!
We continue the battle for Javascript performance using the example of creating pivot tables. The last time , we have implemented a number of optimizations, and remained the last real opportunity to accelerate the calculation - move to multi-threaded computing. In Javascript, workers have long existed , the implementation of which is not without flaws, but it is stated that they use real operating system threads - so why not try? Suddenly, it turned out that in order to parallelize a simple, in essence, algorithm, we had to rewrite syntacys of aggregate formulas, since the old ones did not have the additivity property (more detailed under the cut), but ultimately everything turned out.
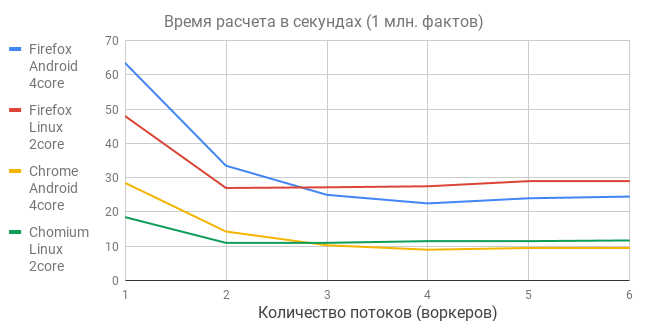
The processing of 1 million facts on two devices was tested:
- Linux netbook Linux 4.15, 2 x Intel Celeron CPU N2830 @ 2.16 GHz
- Android phone 7.0,4 x ARM Cortex-A53 @ 1.44 GHz
From the graphs it follows several conclusions.
- The gain from multithreading turned out to be quite modest, much less than expected, because there are no miracles - software multithreading requires hardware multiprocessing, and in our devices there are few cores.
- The optimal size of the pool of workers is the same as the number of cores. That is why the phone, consistently losing all single-threaded tests, suddenly took the lead, showing the best result - a million facts in 9 seconds.
- The one-pass algorithm is scaled linearly — as the amount of input data increases by an order of magnitude — the calculation time increases by the same order. I checked on the phone - 10 million facts paid off in 80 seconds, 100 million facts in 1000 seconds. Nothing hung and fell. About 15 years ago for tables of this size they usually bought Oracle.
- Since business applications are actively moving to WEB and mobile phones - multi-core personal devices are absolutely justified, and multi-threaded programming is just a must have, even for the frontend.
You can play with the tests yourself - the application is here , the test data generator is included, the calculation time is displayed.
Algorithm features
Let me remind you what is our algorithm. An unstructured fact store is used as the source data; a data scheme is not created. JSON is sent to the input, containing interleaved operations and directories. We define calculations at 2 levels - a formula at the level of an individual fact (essentially a calculated attribute), and an aggregate formula at the row level of the pivot table. Then we apply a filter, and build a pivot table in one pass through the array of facts. In this single cycle, grouping is performed, aggregates are calculated, reference data is extracted, and the width of the columns is determined.
Data is stored in IndexedDB in blocks, each worker is allocated its own range of blocks, the main thread starts the workers, periodically receives status from them (the number of records processed), and, waiting for all to stop, it reduces the result. In the control example, the time for converting the result is negligible, but on other data, of course, there may be options. In order for the result to be reduced correctly, all aggregate formulas must have additivity, that is, they could be applied to both single facts and already counted blocks.
Aggregate formulas
I did not understand before why Excel, adult OLAP systems and RDBMSs do not allow writing their own aggregate function in a scripting language, but contain only a set of predefined types like sum (), avg () and so on. For example, for a long time in Excel, there was not even a count_distinct function, and even now not all DBMSs have it. It turns out that if the user is allowed to determine his aggregate functions, not all of them will be additive, which means that the calculation cannot be parallelized, which is deadly for an industrial system. Let's show it on the example of 3 array aggregation functions:
console.log([1, 2, 3, 4].reduce(
(accumulator, currentValue) => accumulator + currentValue
));
console.log([1, 2, 3, 4].reduce(
(accumulator, currentValue) => (accumulator + currentValue) ** 2
));
console.log([1, 2, 3, 4].reduce(
(accumulator, currentValue) => accumulator + currentValue ** 2
));
The first function is additive, since it can be applied to itself, that is:
accumulator + (accumulator + currentValue) .
The second function cannot be parallelized at all, you need to work with the third one, because applying it in the forehead to the block:
accumulator + (accumulator + currentValue ** 2) ** 2 - will give an incorrect result, but if you parse the expression and understand that this is all - just the sum of squares - additivity is achieved. In our algorithm, accumulator is not just a scalar, but an array representing the current row of the pivot table, and currentValue is, respectively, an array of attribute values of the current fact (including those calculated), with the result that the risk of additivity breaks.
Let me remind you that in the first versionapplications in aggregate formulas used the fact (colname) and row (colname) functions (the first one returns the attribute of the current fact, the second - the intermediate calculated value of the pivot table column), and already the summing, counting, etc. expressions were compiled. However, the user is tempted to use in one aggregate formula, for example, several attributes of the fact, which is unacceptable if we want multithreading. I was too lazy to do the parsing of formulas - you can think of a little - and I made the simplest decision - to forbid using fact attributes directly in an aggregate formula, but only wrapping them in predefined aggregate primitives, so our pivot table will be described with such formulas:
"quantity-sum": "sum('quantity')",
"amount-sum": "round(sum('amount'), 2)",
"price-max": "max('price')",
"price-min": "min('price')",
"price-last": "last('price')",
"price-avg": "round(sum('price') / count(), 2)",
"price-weight": "round(sum('amount') / sum('quantity'), 2)",
"EAN-code": "selectlast('EAN-code', \"fact('product') == row('product')\")"Re-computing does not occur - the results of the calculation of aggregate primitives are cached. The primitives sum (), count (), mul (), min (), max (), last (), first () are available. The last function selectlast () pulls the directory prop from another fact, that is, in effect, it implements the join store itself to itself, but is calculated in a common cycle, that is, without loss of performance. As for the functions mode () , median () , count_distinct (), they are not additive, do not scale linearly, until the end of the calculation they will need to store all values in a separate structure (memory consumption), and therefore will be implemented later.
Summary
Probably, we can finish Javascript overclocking on this; we still didn’t quite catch up with Excel, although we came very close. Theoretically, you can still look in the direction of GPU-computing, for which you have to completely rewrite the algorithm ( there is a precedent ), but, in principle, it turned out pretty well. I wish you pleasant programming and fresh ideas!