Tutorial: toon circuits in Unreal Engine 4
- Transfer
- Tutorial

When talking about "toon-contours", they mean any technique that renders lines around objects. Like cel shading, outlines help the game look more stylized. They can create the feeling that objects are painted with paints or ink. Examples of this style can be seen in games such as Okami , Borderlands and Dragon Ball FighterZ .
In this tutorial you will learn the following:
- Create contours using an inverted mesh
- Create paths using post-processing and convolution
- Create and use material functions
- Sample neighboring pixels
Note: this tutorial assumes that you already know the basics of Unreal Engine. If you are new to Unreal Engine, then I recommend exploring my series of ten-part tutorials of Unreal Engine for beginners .
If you are not familiar with post-processing materials, then you should first study my tutorial on cel shading . In this article, we will use some of the concepts outlined in the cel shading tutorial.
Getting to work
To get started, download the materials from this tutorial. Unzip them, go to ToonOutlineStarter and open ToonOutline.uproject . You will see the following scene:

First, we will create the contours using an inverted mesh .
Inverted Mesh Contours
The principle for implementing this method is to duplicate the target mesh. The duplicate is then assigned a solid color (usually black) and its size is increased so that it is slightly larger than the original mesh. This way we will create a silhouette.

If you use just a duplicate, then it completely overlaps the original mesh.

To fix this, we can invert the normals of the duplicate. When enabled option backface culling (cut-off rear faces), we will not see the external and internal faces.

This will allow the original mesh to shine through the duplicate. And since the duplicate is larger than the original mesh, we get the outline.

Benefits:
- You will always have clear lines, because the outline consists of polygons.
- The appearance and thickness of the contour is easily adjusted by moving the vertices
- With distance, the contours become smaller (this may be a drawback).
Disadvantages:
- Normally, you cannot create contours of parts inside a mesh this way.
- Since the outline consists of polygons, they are prone to clipping. This can be seen in the above example, where the duplicate intersects with the ground.
- With this method, speed reduction is possible. It depends on how many polygons are in the mesh. Since we use duplicates, we essentially double the number of polygons.
- Such contours perform better on smooth and convex meshes. Sharp edges and concave areas will create holes in the outline. This can be seen in the image below.

Creating an inverted mesh is better in the 3D modeling program, this gives more control over the silhouette. When working with skeletal meshes, this also allows you to skin a duplicate with the original skeleton. Thanks to this, the duplicate will be able to move with the original mesh.
For this tutorial, we will not create a mesh in a 3D editor. but in Unreal. The method is slightly different, but the concept remains the same.
First we need to create duplicate material.
Creating Inverted Mesh Material
For this method, we mask the polygons with faces outward, and as a result we will have polygons with faces inward.
Note: due to masking, this method is slightly more expensive than manually creating a mesh.
Browse to the Materials folder and open M_Inverted . Then go to the Details panel and change the following options:
- Blend Mode : select Masked for it . This will allow us to mark areas as visible or invisible. The threshold value can be changed by editing the Opacity Mask Clip Value .
- Shading Model: Select Unlit . Because of this, the mesh will not be affected by lighting.
- Two Sided: Select Enabled . By default, Unreal cuts back edges. Enabling this option disables clipping of the back faces. If you leave clipping of the back faces turned on, then we will not be able to see polygons with faces inward.

Next, create a Vector Parameter and name it OutlineColor . It will control the color of the outline. Combine it with Emissive Color .
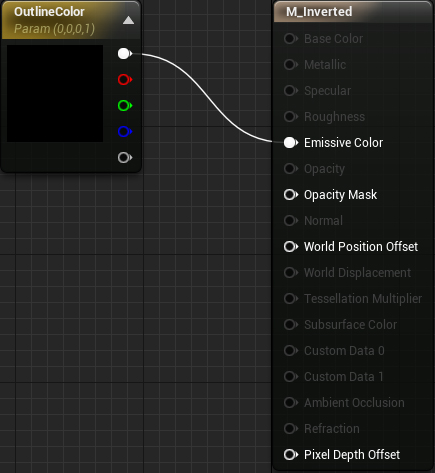
To mask polygons with faces outward, create TwoSidedSign and multiply it by -1 . Join the result with the Opacity Mask .
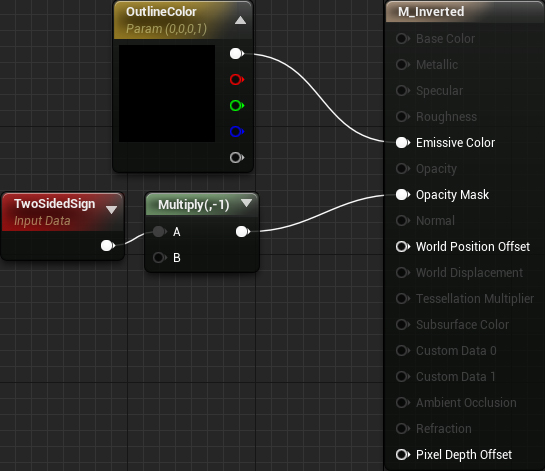
TwoSidedSign prints 1 for the front faces and -1 for the back faces. This means that the front faces will be visible, and the rear - invisible. However, we need the opposite effect. To do this, we change signs by multiplying by -1 . Now the front faces will give -1 as the output , and the back ones 1 .
Finally, we need a way to control the thickness of the contour. To do this, add the selected nodes:
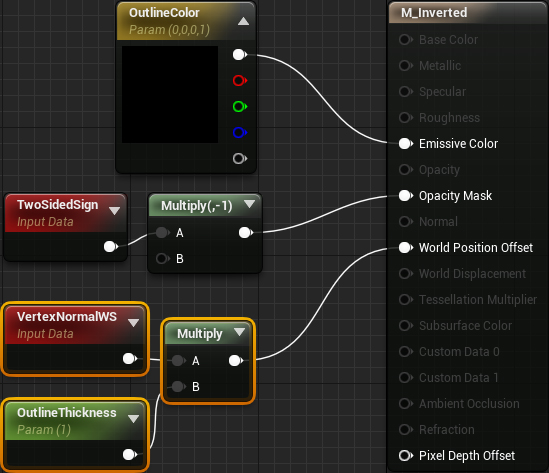
In the Unreal engine, we can change the position of each vertex using the World Position Offset . Multiplying the vertex normal by OutlineThickness , we make the mesh thicker. Here is a demo using the original mesh:

On this we have finished preparing the material. Click Apply and close M_Inverted .
Now we need to duplicate the mesh and apply the newly created material.
Mesh duplication
Go to the Blueprints folder and open BP_Viking . Add the Static Mesh component as a child of the Mesh and name it Outline .

Select Outline and set Static Mesh to SM_Viking . Then select its material value MI_Inverted .
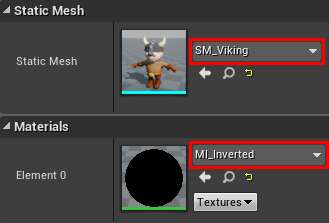
MI_Inverted is an instance of M_Inverted . It will allow us to change the OutlineColor and OutlineThickness parameters without recompiling.
Click Compile and close BP_Viking . Now the viking will have an outline. We can change the color and thickness of the path by opening MI_Inverted and adjusting its parameters.
And we are done with this method! Try creating an inverted mesh in a 3D editor, and then transfer it to Unreal.
If you want to create contours differently, then you can use post-processing for this .
Creating Post Processing Circuits
You can create post-processing contours using edge recognition . This is a technique that recognizes gaps in image areas. Here are some types of gaps you can look for:
Benefits:
- The method is easily applicable to the whole scene.
- Constant computational overhead, since a shader is always executed for each pixel
- The line thickness always remains the same regardless of the distance (this may be a drawback).
- Lines are not clipped by geometry, as this is a post-processing effect.
Disadvantages:
- Typically, recognition of all edges requires multiple edge recognizers. This reduces speed.
- The method is subject to noise. This means that edges will appear in areas where there is a lot of variation.
Typically, edge recognition is performed by folding each pixel.
What is a convolution?
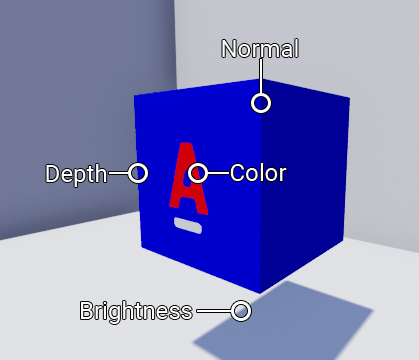
In the field of image processing, convolution is an operation on two groups of numbers to calculate one number. First we take a grid of numbers (known as the kernel ) and place the center above each pixel. The following is an example of how the core moves over two lines of the image:

For each pixel, each core element is multiplied by the corresponding pixel. To demonstrate this, let's take a pixel from the upper left edge of the mouth. Also, to simplify the calculations, we convert the image to grayscale.

First, we arrange the core (we take the same one that was used above) so that the target pixel is in the center. Then we multiply each element of the kernel by the pixel on which it is superimposed.
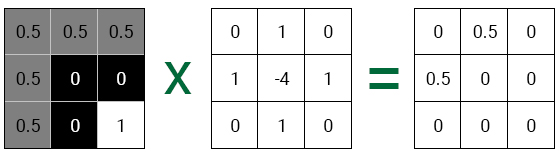
Finally, add the results together. This will be the new value for the center pixel. In our case, the new value is 0.5 + 0.5 or 1 . Here's what the image looks like after convolution for each pixel:

The effect obtained depends on the core used. The core of the above examples is used to recognize edges. Here are some examples of other edges:
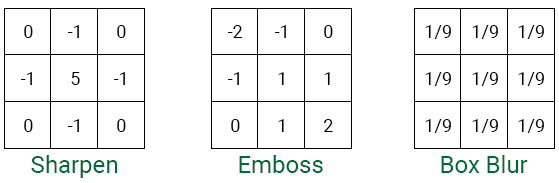
Note: You may notice that they are used as filters in image editors. In fact, many operations with filters in image editors are performed using convolutions. In Photoshop, you can even perform convolutions based on your own kernels!
To recognize image edges, you can use Laplace edge recognition.
Laplace edge recognition
First, what will be the core for Laplace edge recognition? In fact, we already saw this core in the examples of the previous section!
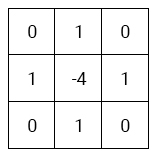
This core performs edge recognition because the Laplacian measures steepness changes. Areas with large changes deviate from zero and report that this is an edge.
So that you understand this, let's look at the Laplacians in one dimension. The core for it will be as follows:

First, place the core above the edge pixel, and then convolution.
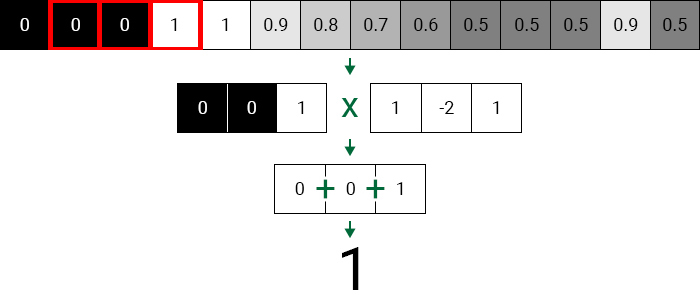
This will give us a value of 1 , which shows that there has been a big change. That is, the target pixel is likely to be an edge.
Next, let's roll up the area with less variability.

Even though the pixels have different values, the gradient is linear. That is, there is no change in slope and the target pixel is not an edge.
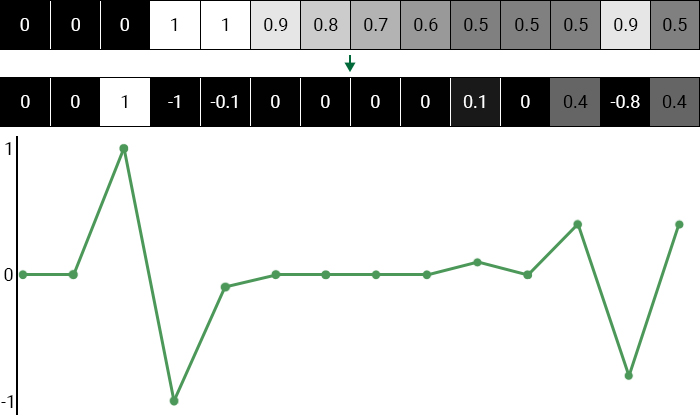
Below is the image after the convolution and a graph of all values. You may notice that the pixels on the edge deviate more strongly from zero.
Yes, we have covered quite a bit of theory, but don’t worry, the interesting part will begin. In the next section, we will create post-processing material that will perform Laplace edge recognition in the depth buffer.
Building a Laplace Rib Recognizer
Go to the Maps folder and open PostProcess . You will see a black screen. This happened because the card contains Post Process Volume, which uses empty postprocessing material.
It is this material that we will modify to build an edge recognizer. The first step is that we need to figure out how to sample neighboring pixels.
To get the position of the current pixel, we can use TextureCoordinate . For example, if the current pixel is in the middle, then it will return (0.5, 0.5) . This two-component vector is called UV .
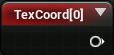
To sample another pixel, we just need to add an offset to the TextureCoordinate. For a 100 × 100 image, each pixel in UV space has a size of 0.01 . To sample the pixel on the right, you need to add 0.01 along the X axis .
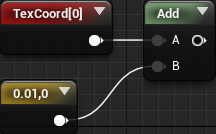
However, there is a problem. When you change the resolution of the image, the pixel size also changes. If you use the same offset (0.01, 0) for a 200 × 200 image, then two pixels to the right will be sampled .
To fix this, we can use the SceneTexelSize node , which returns the size of the pixel. To apply it, you need to do something like this:

Since we are going to sample a few pixels, we need to create it several times.

Obviously, the graph will quickly become confusing. Fortunately, we can use the functions of materials to keep the graph legible.
Note: the material function is similar to the functions that are used in Blueprints or in C ++.
In the next section, we insert duplicate nodes into the function and create an input for the offset.
Create pixel sampling function
To get started, go to the Materials \ PostProcess folder . To create a material function, click on Add New and select Materials & Textures \ Material Function .

Rename it to MF_GetPixelDepth and open it. There will be one FunctionOutput node in the graph . This is where we will attach the value of the sampled pixel.
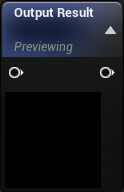
First, we need to create an input that will receive an offset. To do this, create a FunctionInput .
When we continue to use the function, it will be the input contact.
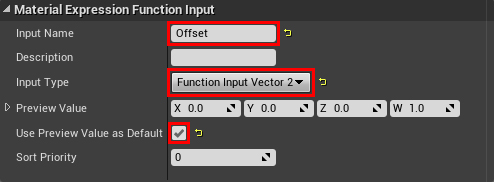
Now we need to set some parameters for login. Select FunctionInput and go to the Details panel. Change the following options:
- InputName: Offset
- InputType: Function Input Vector 2. Since the depth buffer is a 2D image, the offset must be of type Vector 2 .
- Use Preview Value as Default: Enabled. If you do not pass an input value, the function will use the value from the Preview Value .
Next, we need to multiply the offset by the pixel size. Then you need to add the result to TextureCoordinate. To do this, add the highlighted nodes:
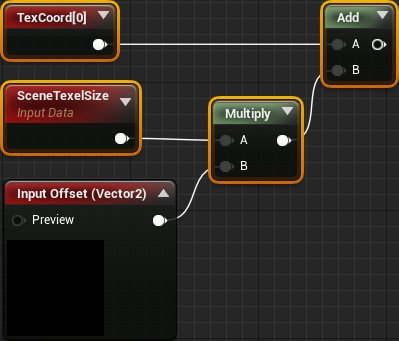
Finally, we need to sample using the UV depth buffer. Add SceneDepth and connect everything as follows:

Note: You can also use SceneTexture with a SceneDepth value instead .
Summarize:
- Offset gets Vector 2 and multiplies it by SceneTexelSize . This gives us a shift in the UV space.
- Add an offset to TextureCoordinate to get a pixel at a distance (x, y) of the pixels from the current one.
- SceneDepth will use the passed UVs to sample the corresponding pixel and then output it.
And on this work with the function of the material is completed. Click on Apply and close MF_GetPixelDepth .
Note: In the Stats panel, you can see an error informing that only translucent materials or post-processing materials can read from the depth of the scene. You can safely ignore this error. Since we will use the function in the post-processing material, everything will work.
Next, we need to use the function to convolve the depth buffer.
Convolution
First we need to create offsets for each pixel. Since the angles of the nucleus are always zero, we can skip them. That is, we have left, right, top and bottom pixels.
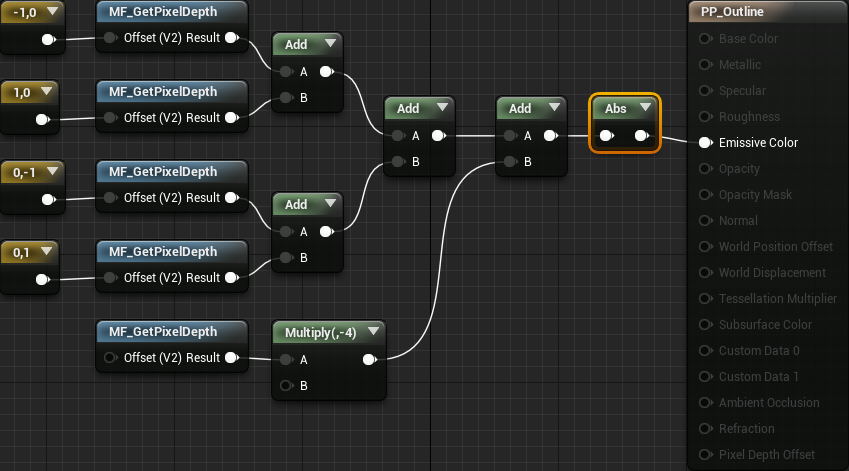
Open PP_Outline and create four Constant2Vector nodes . Give them the following options:
- (-10)
- (10)
- (0, -1)
- (0, 1)

Next, we need to sample five pixels in the core. Create five MaterialFunctionCall nodes and select MF_GetPixelDepth for each . Then connect each offset to its own function.
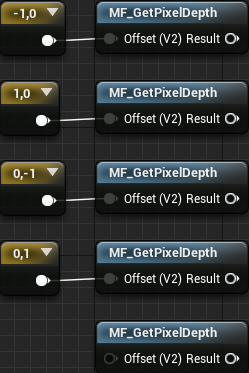
So we get the depth values for each pixel.
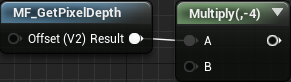
The next is the multiplication stage. Since the factor for neighboring pixels is 1 , we can skip multiplication. However, we still need to multiply the center pixel (bottom function) by -4 .
Next, we need to summarize all the values. Create four Add nodes and connect them as follows:
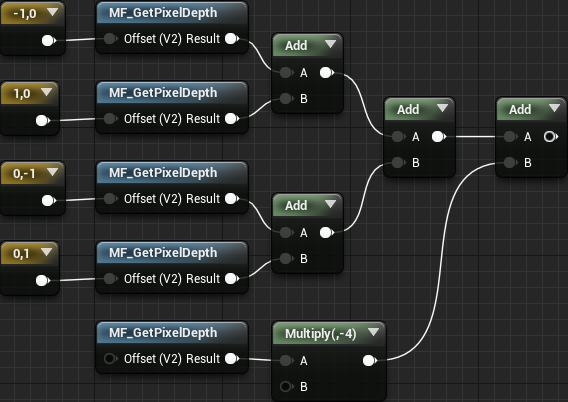
If you remember the graph of pixel values, you will notice that some of them are negative. If you use the material as is, the negative pixels will be displayed in black, because they are less than zero. To fix this, we can get an absolute value that converts all input to a positive value. Add Abs and put it together like this:
Summarize:
- Nodes MF_GetPixelDepth receive the depth value of the central, left, right, upper and lower pixels
- Multiply each pixel by its corresponding kernel value. In our case, it is enough to multiply only the central pixel.
- We calculate the sum of all pixels
- We get the absolute value of the sum. This will prevent pixels with negative values from being displayed in black.
Click on Apply and return to the main editor. Lines now appear in the entire image!

However, here we have some problems. Firstly, there are ribs in which the difference in depth is insignificant. Secondly, in the background there are circular lines, because it is a sphere. This is not a problem if you restrict edge recognition to meshes only. However, if you want to create lines in the whole scene, then these circles are undesirable.
You can use threshold values to correct this.
Threshold implementation
First, we will correct the lines that appear due to minor differences in depths. Return to the material editor and create the diagram below. Set Threshold to 4 .
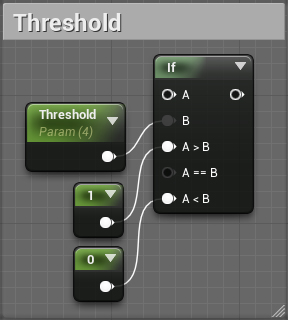
Later, we will combine the results from the recognition of edges A . It will output a value of 1 (denoting an edge) if the pixel value is above 4 . Otherwise, it will output 0 (no edge).
Next we get rid of the lines in the background. Create the circuit shown below. Set DepthCutoff to 9000 .

In this case, the value 0 will be transmitted to the output (no edges) if the depth of the current pixel is more than 9000 . Otherwise, the value from A <B will be transmitted to the output .
Finally, connect everything as follows:

Now the lines will be displayed only when the pixel value is greater than 4 ( Threshold ) and its depth is less than 9000 ( DepthCutoff ).
Click on Apply and return to the main editor. There are no more small lines and lines in the background!

Note: You can create an instance of PP_Outline material to control Threshold and DepthCutoff .
Edge recognition works quite well. But what if we need thicker lines? To do this, we need to increase the size of the kernel.
Create thicker lines
In general, the larger the kernel, the more it affects the speed, because we need to sample more pixels. But is there a way to increase the core while maintaining the same speed as with the 3 × 3 core? Here we need an extended convolution .
With expanded convolution, we simply propagate offsets further. To do this, we multiply each offset by a scalar called the expansion coefficient . It determines the distance between the elements of the core.

As you can see, this allows us to increase the size of the kernel, while sampling the same number of pixels.
Now let's implement the extended convolution. Return to the material editor and create a ScalarParameter called DilationRate . Set it to 3 . Then multiply each offset by DilationRate .

So we move each offset 3 pixels from the center pixel.
Click on Apply and return to the main editor. You will see that the lines have become much thicker. Here is a comparison of lines with different expansion coefficients:

If you are not making a game in the style of line art, then most likely you need the original scene to be visible. In the last section, we add lines to the image of the original scene.
Adding Lines to the Original Image
Return to the material editor and create the diagram below. The order is important here!
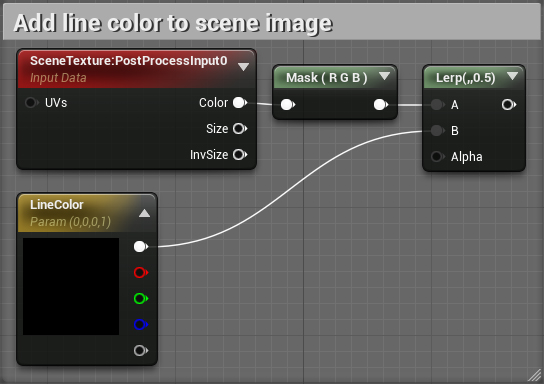
Next, connect everything as follows:

Now Lerp will display the scene image if alpha reaches zero (black color). Otherwise, it outputs LineColor .
Click on Apply and close PP_Outline . Now the source scene has contours!
Where to go next?
The finished project can be downloaded here .
If you want to work with edge recognition, try creating a recognition that works with the normal buffer. This will give you some edges that do not appear in the edge recognizer in depths. Then you can combine both types of edge recognition together.
Convolution is an extensive topic that is actively used, including in artificial intelligence and sound processing. I recommend to study the convolution, creating other effects, for example, sharpening and blurring. For some of them, just changing the kernel values is enough! See an interactive explanation of the convolutions in Images Kernels explained visually . It also describes kernels for some other effects.
I also highly recommend watching the Guilty Gear Xrd graphic presentation from the GDC . For external lines, this game also uses an inverted mesh method. However, for the internal lines, the developers created a simple but ingenious technique using textures and UV.