MobileNet: smaller, faster, more accurate
If five years ago a neural network was considered a “heavyweight” algorithm requiring hardware specifically designed for high-load computing, today it’s no surprise to see deep networks running directly on a mobile phone.
Nowadays, networks recognize your face to unlock your phone, style photos of famous artists and determine if there is a hot dog in the frame .
In this article, we’ll talk about MobileNet, an advanced convolution network architecture that can do all this and much more.
The article will consist of three parts. In the first, we look at the structure of the network, as well as at the tricks that the authors of the original scientific work

proposed to optimize the speed of the algorithm. In the second part, we'll talk about the next version of MobileNetV2, an article about which Google researchers published just a couple of months ago. In the end, we discuss practical results achievable with this architecture.
In the last post, we examined the Xception architecture, which allowed us to significantly reduce the number of parameters in the convolution network with an Inception-like architecture by replacing conventional convolutions with the so-called depthwise separable convolutions. Let me briefly remind you what it is.
Normal convolution is a filter where
where  Is the size of the convolution kernel, and
Is the size of the convolution kernel, and  - the number of channels at the input. The total computational complexity of the convolutional layer is
- the number of channels at the input. The total computational complexity of the convolutional layer is where
where  Is the height and width of the layer (we believe that the spatial dimensions of the input and output tensors coincide), and
Is the height and width of the layer (we believe that the spatial dimensions of the input and output tensors coincide), and  - the number of channels at the output.
- the number of channels at the output.
The idea of depthwise separable convolution is to decompose a similar layer into a depthwise convolution, which is a channel filter, and a 1x1 convolution (also called pointwise convolution). The total number of operations for applying such a layer is .
.
By and large, that's all you need to know to successfully build MobileNet.
On the left is a conventional convolutional network block, and on the right is the MobileNet base block.
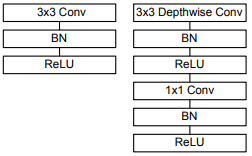
The convolutional part of the network we are interested in consists of one ordinary convolutional layer with 3x3 convolution at the beginning and thirteen blocks shown on the right in the figure, with a gradually increasing number of filters and decreasing spatial dimension of the tensor.
A feature of this architecture is the lack of max pooling layers. Instead, convolution with a stride parameter of 2 is used to reduce the spatial dimension. The
two HyperNet architecture parameters are (width factor) and
(width factor) and  (depth factor or resolution factor).
(depth factor or resolution factor).
The width factor is responsible for the number of channels in each layer. For instance, gives us the architecture described in the article, and
gives us the architecture described in the article, and  - architecture with four times the number of channels at the output of each block.
- architecture with four times the number of channels at the output of each block.
The resolution factor is responsible for the spatial dimensions of the input tensors. For instance, means that the height and width of the feature map fed to the input of each layer will be halved.
means that the height and width of the feature map fed to the input of each layer will be halved.
Both parameters allow you to vary the size of the network: reducing and , we reduce the accuracy of recognition, but at the same time we increase the speed of work and reduce the consumed memory.
The advent of MobileNet in itself made a revolution in computer vision on mobile platforms, but a few days ago Google made it publicly available MobileNetV2, the next generation of neural networks of this family, which can achieve approximately the same recognition accuracy with even greater speed.
The main building block of this network is generally similar to the previous generation, but has a number of key features.
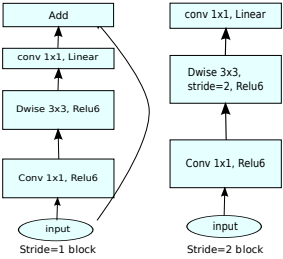
As in MobileNetV1, there are convolution blocks with a step of 1 (in the figure on the left) and with a step of 2 (in the figure on the right). Blocks with step 2 are designed to reduce the spatial dimension of the tensor and, unlike the block with step 1, do not have residual connections.
The MobileNet block, called by the authors as an expansion convolution block (in the original expansion convolution block or bottleneck convolution block with expansion layer ), consists of three layers:
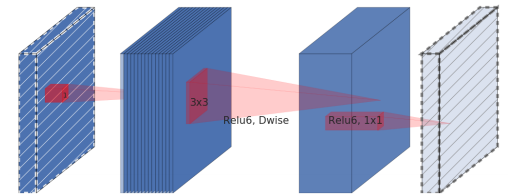
In fact, it is the third layer in this block, called the bottleneck layer , that is the main difference between the second generation of MobileNet and the first.
Now that we know how MobileNet works internally, let's see how well it works.
Compare several network architectures. Take for example the Xception, which was the last post, the deep and old VGG16, as well as several variations of MobileNet.
The biggest achievement of these experiments seems to me that now networks capable of working on mobile devices show accuracy higher than that of VGG16.
Also, an article about MobileNetV2 shows very interesting results on other tasks. In particular, the authors demonstrate that the SSDLite architecture for the object detection task, which uses MobileNetV2 in the convolution part, surpasses the well-known YOLOv2 real-time detector in accuracy on the MS COCO dataset , while showing 20 times faster and 10 times smaller size (in in particular, on a Google Pixel smartphone, MobileNetV2 allows you to do object detection with 5 FPS).

With MobileNetV2, mobile developers received almost unlimited computer vision tools - in addition to relatively simple models for classifying images, we can now use object detection and semantic segmentation algorithms directly on the mobile device.
At the same time, using MobileNet using Keras and TensorFlow is so simple that, in principle, developers can do this without even delving into the internal structure of the algorithms, as a well-known comic book will.
proposed to optimize the speed of the algorithm. In the second part, we'll talk about the next version of MobileNetV2, an article about which Google researchers published just a couple of months ago. In the end, we discuss practical results achievable with this architecture.
In previous series
In the last post, we examined the Xception architecture, which allowed us to significantly reduce the number of parameters in the convolution network with an Inception-like architecture by replacing conventional convolutions with the so-called depthwise separable convolutions. Let me briefly remind you what it is.
Normal convolution is a filter
where Is the size of the convolution kernel, and - the number of channels at the input. The total computational complexity of the convolutional layer iswhere Is the height and width of the layer (we believe that the spatial dimensions of the input and output tensors coincide), and - the number of channels at the output. The idea of depthwise separable convolution is to decompose a similar layer into a depthwise convolution, which is a channel filter, and a 1x1 convolution (also called pointwise convolution). The total number of operations for applying such a layer is
. By and large, that's all you need to know to successfully build MobileNet.
MobileNet Structure
On the left is a conventional convolutional network block, and on the right is the MobileNet base block.
The convolutional part of the network we are interested in consists of one ordinary convolutional layer with 3x3 convolution at the beginning and thirteen blocks shown on the right in the figure, with a gradually increasing number of filters and decreasing spatial dimension of the tensor.
A feature of this architecture is the lack of max pooling layers. Instead, convolution with a stride parameter of 2 is used to reduce the spatial dimension. The
two HyperNet architecture parameters are
(width factor) and (depth factor or resolution factor). The width factor is responsible for the number of channels in each layer. For instance,
gives us the architecture described in the article, and - architecture with four times the number of channels at the output of each block. The resolution factor is responsible for the spatial dimensions of the input tensors. For instance,
means that the height and width of the feature map fed to the input of each layer will be halved. Both parameters allow you to vary the size of the network: reducing
and , we reduce the accuracy of recognition, but at the same time we increase the speed of work and reduce the consumed memory.MobileNetV2
The advent of MobileNet in itself made a revolution in computer vision on mobile platforms, but a few days ago Google made it publicly available MobileNetV2, the next generation of neural networks of this family, which can achieve approximately the same recognition accuracy with even greater speed.
What does MobileNetV2 look like?
The main building block of this network is generally similar to the previous generation, but has a number of key features.
As in MobileNetV1, there are convolution blocks with a step of 1 (in the figure on the left) and with a step of 2 (in the figure on the right). Blocks with step 2 are designed to reduce the spatial dimension of the tensor and, unlike the block with step 1, do not have residual connections.
The MobileNet block, called by the authors as an expansion convolution block (in the original expansion convolution block or bottleneck convolution block with expansion layer ), consists of three layers:
- First comes a pointwise convolution with a lot of channels, called expansion layer .
At the input, this layer takes the dimension tensor , and the output gives a tensor
, and the output gives a tensor  where
where  - A new hyperparameter called the expansion level (in the original expansion factor). The authors recommend setting this hyperparameter to a value from 5 to 10, where smaller values work better for smaller networks, and larger ones for larger ones (in the article itself, in all experiments
- A new hyperparameter called the expansion level (in the original expansion factor). The authors recommend setting this hyperparameter to a value from 5 to 10, where smaller values work better for smaller networks, and larger ones for larger ones (in the article itself, in all experiments )
)
This layer creates a mapping of the input tensor in the space of large dimension. The authors call this mapping “target diversity” (in the original “manifold of interest” ) - Then comes depthwise convolution with ReLU6 activation. This layer, together with the previous one, in essence forms the already familiar building block MobileNetV1.
At the input, this layer takes the dimension tensor, and the output gives a tensor  where
where  - step of convolution (stride), because as we recall, depthwise convolution does not change the number of channels.
- step of convolution (stride), because as we recall, depthwise convolution does not change the number of channels. - At the end there is a 1x1 convolution with a linear activation function, reducing the number of channels. The authors of the article hypothesize that the “target manifold” of high dimension obtained after the previous steps can be “put” into a subspace of smaller dimension without loss of useful information, which, in fact, is done at this step (as can be seen from the experimental results, this hypothesis is completely justified).
At the input, such a layer takes a dimension tensor, and the output gives a tensor  where - the number of channels at the output of the block.
where - the number of channels at the output of the block.
In fact, it is the third layer in this block, called the bottleneck layer , that is the main difference between the second generation of MobileNet and the first.
Now that we know how MobileNet works internally, let's see how well it works.
Practical results
Compare several network architectures. Take for example the Xception, which was the last post, the deep and old VGG16, as well as several variations of MobileNet.
| Network architecture | Number of parameters | Top-1 accuracy | Top-5 accuracy |
|---|---|---|---|
| Xception | 22.91M | 0.790 | 0.945 |
| VGG16 | 138.35M | 0.715 | 0.901 |
| MobileNetV1 (alpha = 1, rho = 1) | 4.20M | 0.709 | 0.899 |
| MobileNetV1 (alpha = 0.75, rho = 0.85) | 2.59M | 0.672 | 0.873 |
| MobileNetV1 (alpha = 0.25, rho = 0.57) | 0.47M | 0.415 | 0.663 |
| MobileNetV2 (alpha = 1.4, rho = 1) | 6.06M | 0.750 | 0.925 |
| MobileNetV2 (alpha = 1, rho = 1) | 3.47M | 0.718 | 0.910 |
| MobileNetV2 (alpha = 0.35, rho = 0.43) | 1.66M | 0.455 | 0.704 |
The biggest achievement of these experiments seems to me that now networks capable of working on mobile devices show accuracy higher than that of VGG16.
Also, an article about MobileNetV2 shows very interesting results on other tasks. In particular, the authors demonstrate that the SSDLite architecture for the object detection task, which uses MobileNetV2 in the convolution part, surpasses the well-known YOLOv2 real-time detector in accuracy on the MS COCO dataset , while showing 20 times faster and 10 times smaller size (in in particular, on a Google Pixel smartphone, MobileNetV2 allows you to do object detection with 5 FPS).
What's next?
With MobileNetV2, mobile developers received almost unlimited computer vision tools - in addition to relatively simple models for classifying images, we can now use object detection and semantic segmentation algorithms directly on the mobile device.
At the same time, using MobileNet using Keras and TensorFlow is so simple that, in principle, developers can do this without even delving into the internal structure of the algorithms, as a well-known comic book will.