Reuse Reality
- Transfer
They say that you do not need to reinvent the wheel. At first glance, this seems obvious. If you took the time to develop, then why do it again, can you reuse the old solution? It would seem that from all sides a good option. But not so simple. As an old gray-haired programmer , I have seen organizations fall victim to this error over and over again, investing in pre-design and development, but never achieving the promised massive ROI through reuse. In fact, I believe that our overly optimistic assessment of the benefits and ease of reuse is one of the most common and dangerous pitfalls in software development.
I believe the root of the problem is that Daniel Kahnemanformulated as a rule, "What you see is . " In a nutshell, it explains the person’s tight restrictions on quick decision making, using only the available data and some basic heuristics. Slowing down thinking takes time and discipline - so instead we try to replace complex problems that we do not fully understand with simple ones.
In the case of repeated use, intuition simply and convincingly represents an analogy of software that is difficult to access in the physical world as a “wheel”, which should not be reinvented. This is a convenient mental model that we often come back to when making decisions about reuse. The problem is that this idea of reuse is wrongor at least depressingly incomplete. Let's see why ...
(A brief caution: I'm talking about large-scale reuse, not the level of methods and functions. I am not going to apply the DRY principle at lower levels of detail. I also present reuse as an application of certain services, libraries, etc. created inside the company and not outside. I do not recommend creating your own JS MVC framework! Okay, now back to the originally planned article ...)
Imagine a system A that contains some logic C inside. Soon a new system B must be built, and it also needs the same basic logic C.

Of course, if we simply extract C from system A, then we can use it in system B without the need for re-implementation. Thus, the savings are time for developing C - it needed to be implemented only once, and not again for B.

In the future, even more systems will find the need for the same common code, so that the benefits of this allocation and reuse will grow almost linearly. For each new system that reuses C instead of independent implementation, we get additional savings equal to the time
spent on C. Again, the logic here is simple and seemingly iron - why develop multiple C instances if you can just develop it once, and then reused. The problem is that the picture is more complex - and what seems like an easy springboard for an ROI can turn into an expensive straitjacket. Here are a few options on how our basic intuition about reuse can fool us ...
The first problem is allocation . Intuition said that C can be reached as if a designer detail - beautiful and easy. However, the reality of unraveling the general code may be different: you try to pull one pasta out of a bowl - and you find that the whole dish is just one big pasta. Of course, everything is usually not so bad, but the code has a lot of hidden dependencies and connections, so the initial idea of the C region grows as you begin to unwind it. Almost never is as easy as you expected.
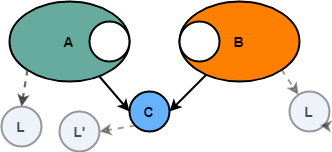
In addition, almost always C needs other things to work (for example, in other libraries, utility functions, etc.). In some cases, these are common dependencies (i.e., both A and C need them), and in some cases not. In any case, a simple picture of A, B and C may not look so simple anymore. For this example, suppose A, B, and C use the common library L.
Another problem is change : different C users will often have slightly different requirements for what it should do. For example, in C there may be some function that should behave a little differently if A calls it, than if B. calls it. The general solution for such cases is parameterization: this function takes some parameter that allows it to understand how it behaves keep in mind the one who caused it. This may work, but increases the complexity of C, and the logic is also cluttered, because the code is filled with blocks like "If the call is from A, then run such a logic block."

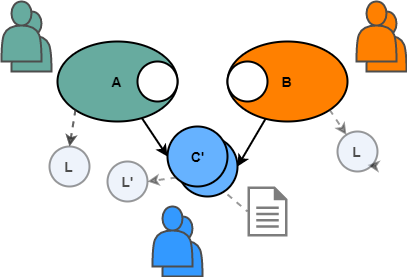
Even if C is really perfect for A and B, anyway, the changes will almost certainly have to be made with the advent of new systems, say D and E. They could use C as is, but then they themselves will need to refine, a little or more. Again, each new fixture of C presents additional complexity - and what was previously easy to understand in it, now becomes much more difficult, as C turns into something more, satisfying the needs of D, E, F, and so on. Which leads to the next problem ...
As complexity grows, it becomes more difficult for a developer to understand what C does and how to use it. For example, developer A may not understand any parameter for function C, since it applies only to systems E and F. In most cases, some level is necessary.API documentation (possibly Swagger , Javadoc or more) to explain entry and exit, exceptional conditions and other SLA / expectations. Although the documentation itself is a good thing, it is not without its problems (for example, it needs to be kept up to date, etc.).

Another consequence of increased complexity is that it becomes more difficult to maintain quality . C now serves many hosts, so there are many borderline cases for tests. In addition, since C is now used by many other systems, the impact of any particular bug is amplified, as it can surface in any or all systems. Often, when making any change to C, it is not enough to test only the common component / service, and a certain level of regression testing is also required for A, B, D and all other dependent systems (it does not matter if the change C is used in this system or not!).
Again, since we are talking about reuse on a non-trivial scale, it is likely that C will have to be developed by a separate development team, which may lead toloss of autonomy . Individual groups usually have their own release schedules, and sometimes their own development processes. The obvious conclusion is that if team A needs some improvement in C, then it will probably have to work through process C, that is, champion A must provide requirements, assert his priority and help with testing. In other words, team A no longer controls their own destiny regarding the functionality that C implements - it depends on the team that supplies C.

Finally, when updating C, by definition, different versions appear. Various problems may arise depending on the nature of the reuse. In case of repeated use at the assembly stage (for example, in the library), different systems (A, B, etc.) can stay with their working versions and choose the right moment for updating. The disadvantage is that there are different versions of C and there is a chance that one error will have to be fixed in all versions. In case of repeated use at runtime (for example, a microservice), C must either support several versions of its API in one instance, or simply upgrade without looking at backward compatibility and, thus, force A and B to update too. In any case, the requirements for the reliability and rigor of processes and organizations to support such reuse significantly increase.
In summary, my point is not that large-scale reuse should be avoided, but that it is not as easy as intuition says. Reuse is really difficult, and although it can still provide benefits that outweigh the disadvantages, these disadvantages should be realistic and considered in advance.
Even after careful analysis, if large-scale reuse isright, you need to decide how to do it. Experience suggests being careful with addiction arrows. Reuse when the “reuse” is under control is almost always easier to implement and easier to manage than reuse when the reused resource accesses the system. In the example above, if C was a library or microservice, then A and B would gain control. In my opinion, this speeds up implementation and reduces the level of management / coordination in the long run.
Turning C into a framework or platform toggles dependency arrows and complicates control. Now A and B owe C. This type of reuse is not only more difficult to implement (and do it right), but it will further lead to a stronger lock (i.e., A and B are completely dependent on C). Popular wisdom says that "a library is a tool, a framework is a way of life."

Finally, I would like to know your opinion or experience with large-scale reuse. When does it work, and when does it fail?
I believe the root of the problem is that Daniel Kahnemanformulated as a rule, "What you see is . " In a nutshell, it explains the person’s tight restrictions on quick decision making, using only the available data and some basic heuristics. Slowing down thinking takes time and discipline - so instead we try to replace complex problems that we do not fully understand with simple ones.
In the case of repeated use, intuition simply and convincingly represents an analogy of software that is difficult to access in the physical world as a “wheel”, which should not be reinvented. This is a convenient mental model that we often come back to when making decisions about reuse. The problem is that this idea of reuse is wrongor at least depressingly incomplete. Let's see why ...
(A brief caution: I'm talking about large-scale reuse, not the level of methods and functions. I am not going to apply the DRY principle at lower levels of detail. I also present reuse as an application of certain services, libraries, etc. created inside the company and not outside. I do not recommend creating your own JS MVC framework! Okay, now back to the originally planned article ...)
Intuition
Imagine a system A that contains some logic C inside. Soon a new system B must be built, and it also needs the same basic logic C.
Of course, if we simply extract C from system A, then we can use it in system B without the need for re-implementation. Thus, the savings are time for developing C - it needed to be implemented only once, and not again for B.
In the future, even more systems will find the need for the same common code, so that the benefits of this allocation and reuse will grow almost linearly. For each new system that reuses C instead of independent implementation, we get additional savings equal to the time
spent on C. Again, the logic here is simple and seemingly iron - why develop multiple C instances if you can just develop it once, and then reused. The problem is that the picture is more complex - and what seems like an easy springboard for an ROI can turn into an expensive straitjacket. Here are a few options on how our basic intuition about reuse can fool us ...
Reality
The first problem is allocation . Intuition said that C can be reached as if a designer detail - beautiful and easy. However, the reality of unraveling the general code may be different: you try to pull one pasta out of a bowl - and you find that the whole dish is just one big pasta. Of course, everything is usually not so bad, but the code has a lot of hidden dependencies and connections, so the initial idea of the C region grows as you begin to unwind it. Almost never is as easy as you expected.
In addition, almost always C needs other things to work (for example, in other libraries, utility functions, etc.). In some cases, these are common dependencies (i.e., both A and C need them), and in some cases not. In any case, a simple picture of A, B and C may not look so simple anymore. For this example, suppose A, B, and C use the common library L.
Another problem is change : different C users will often have slightly different requirements for what it should do. For example, in C there may be some function that should behave a little differently if A calls it, than if B. calls it. The general solution for such cases is parameterization: this function takes some parameter that allows it to understand how it behaves keep in mind the one who caused it. This may work, but increases the complexity of C, and the logic is also cluttered, because the code is filled with blocks like "If the call is from A, then run such a logic block."
Even if C is really perfect for A and B, anyway, the changes will almost certainly have to be made with the advent of new systems, say D and E. They could use C as is, but then they themselves will need to refine, a little or more. Again, each new fixture of C presents additional complexity - and what was previously easy to understand in it, now becomes much more difficult, as C turns into something more, satisfying the needs of D, E, F, and so on. Which leads to the next problem ...
As complexity grows, it becomes more difficult for a developer to understand what C does and how to use it. For example, developer A may not understand any parameter for function C, since it applies only to systems E and F. In most cases, some level is necessary.API documentation (possibly Swagger , Javadoc or more) to explain entry and exit, exceptional conditions and other SLA / expectations. Although the documentation itself is a good thing, it is not without its problems (for example, it needs to be kept up to date, etc.).
Another consequence of increased complexity is that it becomes more difficult to maintain quality . C now serves many hosts, so there are many borderline cases for tests. In addition, since C is now used by many other systems, the impact of any particular bug is amplified, as it can surface in any or all systems. Often, when making any change to C, it is not enough to test only the common component / service, and a certain level of regression testing is also required for A, B, D and all other dependent systems (it does not matter if the change C is used in this system or not!).
Again, since we are talking about reuse on a non-trivial scale, it is likely that C will have to be developed by a separate development team, which may lead toloss of autonomy . Individual groups usually have their own release schedules, and sometimes their own development processes. The obvious conclusion is that if team A needs some improvement in C, then it will probably have to work through process C, that is, champion A must provide requirements, assert his priority and help with testing. In other words, team A no longer controls their own destiny regarding the functionality that C implements - it depends on the team that supplies C.
Finally, when updating C, by definition, different versions appear. Various problems may arise depending on the nature of the reuse. In case of repeated use at the assembly stage (for example, in the library), different systems (A, B, etc.) can stay with their working versions and choose the right moment for updating. The disadvantage is that there are different versions of C and there is a chance that one error will have to be fixed in all versions. In case of repeated use at runtime (for example, a microservice), C must either support several versions of its API in one instance, or simply upgrade without looking at backward compatibility and, thus, force A and B to update too. In any case, the requirements for the reliability and rigor of processes and organizations to support such reuse significantly increase.
Conclusion
In summary, my point is not that large-scale reuse should be avoided, but that it is not as easy as intuition says. Reuse is really difficult, and although it can still provide benefits that outweigh the disadvantages, these disadvantages should be realistic and considered in advance.
Even after careful analysis, if large-scale reuse isright, you need to decide how to do it. Experience suggests being careful with addiction arrows. Reuse when the “reuse” is under control is almost always easier to implement and easier to manage than reuse when the reused resource accesses the system. In the example above, if C was a library or microservice, then A and B would gain control. In my opinion, this speeds up implementation and reduces the level of management / coordination in the long run.
Turning C into a framework or platform toggles dependency arrows and complicates control. Now A and B owe C. This type of reuse is not only more difficult to implement (and do it right), but it will further lead to a stronger lock (i.e., A and B are completely dependent on C). Popular wisdom says that "a library is a tool, a framework is a way of life."
Finally, I would like to know your opinion or experience with large-scale reuse. When does it work, and when does it fail?