DZ Online Tech: Postgres Professional
Hey.
Last year, I started filming a series of programs / interviews on the topic of digital business transformation ( they’re here for those who are interested - sign up ). These programs were at the intersection of IT and business, but, nevertheless, more about business.
In the process, it became clear that there are many that have significant depth from a programmer point of view. And this year we started filming a series of interviews under the common label “DZ Online Tech” - now with the emphasis on what's under the hood. Well, since everyone is too lazy to watch the video, of course, these interviews are decrypted, and today I publish the first one - with Ivan Panchenko from Postgres Professional.
Who cares about the original - here it is:
(Well, by the way, I cannot swear that all issues will be decrypted, so if you like it, sign up on YouTube, everything comes there earlier and guaranteed.)
For those who like to read, decryption:
Good afternoon, Ivan. Postgres is widely accepted as an import substitution tool. And the most famous driver for its application is the idea of “let's replace some Western DBMS with Postgres”. Moreover, it is known that he has a lot of his own values. I would like to go through them briefly. If we choose, without looking “import - not import”, but from scratch — why?
Good afternoon. Firstly, most Postgres do not choose because of import substitution. It is clear that there really are government measures and restrictions on the import of foreign software. Postgres Pro is in the registry, so it is suitable for import substitution. In fact, it is a global trend to choose Postgres more and more. We see only its reflection. It is possible that what was expressed in import substitution is, in fact, a consequence of some deeper, more fundamental processes.
Postgres is ripe. This is a good alternative to older commercial databases. All over the world now they understand that Postgres is a product of the same class as whales: Oracle, Microsoft SQL Server and DB2, the last of which they have almost forgotten, but nevertheless, this is a good product.
But, one way or another, DB2 is gradually floating away from the market somewhere, and Oracle, Microsoft SQL is on it. And Postgres is something third that now floats into the market on a global scale. I must say that it floats quite a long time ago - 10 years ago, when good support for Windows appeared in Postgres. When replication appeared in him, they began to perceive him; they started talking about him as a database for business, industry, and something serious.
You still say in the picture "there were two good ones, there is another good one." But there are surely things that put him forward and make him prefer others.
Yes, there are several such things. Firstly, Postgres is an open source product with a specific license. He also has commercial clones. One of them is ours. But the fact that it comes from an open source product is in itself a great advantage.
The second topic is that Postgres is a highly extensible database. This was also a driver of its development.
I must say that the degree of Postgres extensibility is exactly the place where our Russian contribution is most noticeable. The last 15-17 years, our team is mainly engaged in extensibility mechanisms.
For example, at Rambler in 2000, where I first worked with my current company colleagues, we used Postgres extensibility to increase the performance of the Rambler news service by 30 times. How? We are C programmers who can read documentation. These two things allowed us to create a new type of index for quick searching through arrays, which is beyond the scope of the classical relational model, but useful.
In particular, in Rambler, replacing an extra join with an array in which you can search by a cunning index increased productivity by 30 times. It must be understood that then all Rambler content projects spun on typewriters whose power did not exceed the power of a modern smartphone: Pentium 2, 400 MHz, 500 MB of memory. If you're lucky, then the Pentium 3 (it appeared then) up to 800 MHz. Such Pentium 3 could be 2 pieces in the server. And all this served millions of requests.
It is clear that then it was necessary to optimize the code very seriously, otherwise it would not work. Postgres extensibility helped. We sat, thought, and within an acceptable time frame, one could say for a month, did what then formed the basis of everything that is now in Postgres, related to JSON, with full-text search.
Thanks to this, Postgres quickly developed support for poorly structured data. What it is? These are key-values, roughly. In 2004, we made an extension of Hstore in Postgres to store key-value information in the same database field. Then it was not JSON yet, it went into fashion later. And then there was Hstore. Why hstore? We looked at Perl, which has a hash, and now we made a hash with almost the same syntax in Postgres.
At first this thing existed as a separate extension (extension), then it was committed (commit) in the main set of what is included in Postgres. And she was just as popular. That is, JSON has rounded it in popularity recently.
It turns out that in a sense you put an end to this stupid discussion of SQL and noSQL by creating a DBMS that has the properties of both at the same time.
In a way, yes. From noSQL we took good, namely comparative flexibility, without loss of transactionality, without loss of data integrity and everything that usually happens in normal DBMSs.
So, Hstore. But Hstore was sibling. That is, the hash is single-level. This is not JSON, just a hash. And plus arrays in Postgres were before us. We made support for indexes, that is, you could quickly search by what is included in the arrays, and by what lies inside the Hstore, both by keys and by values. This is a useful thing. People began to use it around the world. Then came JSON. He appeared recently, the year 2011-2012 at Postgres. There were three different attempts to implement it. Then all these attempts were thrown, and made in a different way. At first, JSON was just text that lies in a special field.
Was your team doing JSON?
No, our team did an important thing for JSON. When JSON appeared in Postgres, it was just a text field, and in order to extract something from there, some search value had to parse JSON every time. Of course, this worked slowly, but it allowed storing multilevel data.
But there is little sense in such a text box. For example, in my projects, I already stored weakly structured data in text fields, simply without calling it a special type of field. But the question is that with this JSON it was also necessary to work effectively. And what we have already done with our team in 2014 is JSON-B.
It is faster due to the fact that it is already laid out and parsing. Steamed so that you can quickly get the key value. When we made JSON-B, we fastened it to the ability to search by index, then it became really popular.
Okay Returning to specific properties: what else is there that distinguishes Postgres from other DBMSs and is the reason to use it?
All we've been talking about JSON for so long is all about Postgres flexibility. It has many places in which it can be expanded. The other side of flexibility is geodata support. Exactly the same way as special indexes were made, for example, for searching by JSON, by arrays and by texts, approximately through the same place indexes were made for quick search by geo-information, by spatial data. There we also put our rather large Russian hand in this matter.
As a result, PostGIS is such a very widespread way of working with geoinformation data in the world.
Do users develop extensions for Postgres for their projects? Is this a significant amount of its application?
No, of course, these are some kind of “cream” on top. There are people who need it because their task grows to this. This is, first of all, a universal database that very well supports all standards and which is certainly suitable for almost any task.
If you start a startup, for example - take Postgres, you will not be mistaken. Because, firstly, it is functionally extensible. And secondly, if you use its open source version, then do not become a hostage to the license that you need to purchase.
Do you, as an employee of commercial digging, say this, probably, not very happily?
These are the laws of nature, against which there is no arguing. There is open source, and there is open source business. And this is a rather unusual thing, different from ordinary business. But in the future, the role of open source, apparently, will grow. At least, this can be seen in the success of Postgres and in the Gartner schedule, which is boring to everyone, that the open source database is being used more and more often, and there is no getting around it.
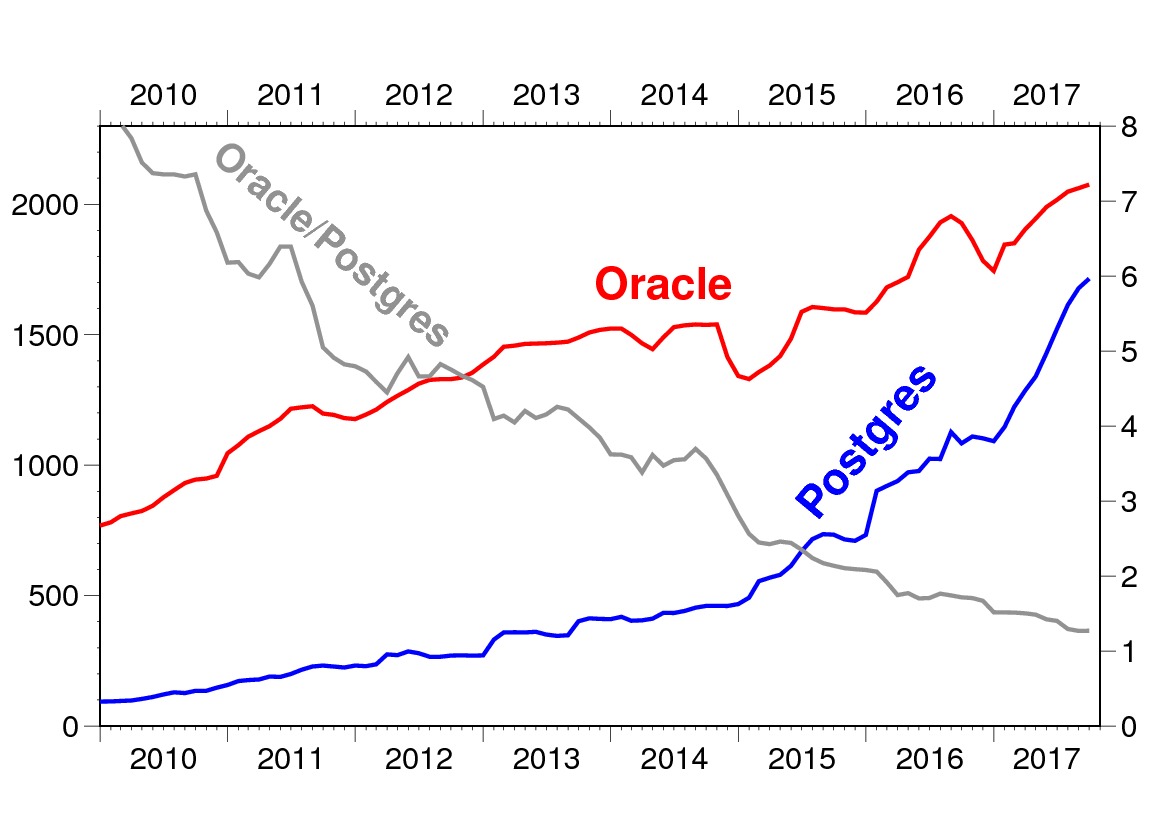
You as a company, why are you needed? Here he is open source: go, download and all is well?
In fact, I went, downloaded, but ran into a problem. Sooner or later, people come across a problem. It is clear that for most users the open source version will do. They will not have problems, they have small bases, they will not grow. But in some cases, you need the help of a professional.
Previously, the model was simple. In this case, I'm talking about Postgres, because different products are at different stages of this evolutionary path. Postgres was originally just a university project. People did not think about money; they were interested in solving the problem. Then he was a volunteer project: people did it for themselves. Moreover, they worked in some companies like ours.
Well, how did you make a decision at Rambler.
Rambler is a good example. We did it because we needed it. We were not at all bothered by business users. Whether someone else needs it or not.
Postgres companies initially began to arise not in Russia, but in other countries. For the first time such a company arose in Japan, however, with Fujitsu money. There have been invested quite a lot. And she started developing Postgres and near-Postgres stuff. Then, in a fairly short time after that, the second quadrant (2nd Quadrant) appeared in England, and in America Enterprise DB. These are all companies that make money on Postgres. All these companies start with the fact that they execute orders. They are engaged ...
Custom development.
Custom development at the DBMS level. We do this too, and we did these things when we weren't a company yet, because Postgres is expanding. “We need the full-text search to search not only like this, but also to correctly ignore our French accents, or our German umlauts. Finish it - we will pay you. " Or: “JSON is a very good thing. I wish I could attach an index to it. And then our portal of free ads will fly a little faster than everyone else. "
These guys really financed the development, paying individual developers or, in some cases, ordering to the young, newly emerged companies some features that they wanted to get. And then gradually the need for commercial versions of Postgres began to arise.
Why, and in general, where did these commercial forks come from? First of all, I must say that Postgres has such a tricky license that legally allows you to make a commercial product out of it. BSD-like license. This is no GPL. You can take at least the same code, even without making any changes to it, leave two lines from the license agreement there, add something else to it, and write that this is my “Vasya Pupkin DB” and I am selling it . To go to the market and sell at least for billions - please, it doesn’t matter. At least someone who buys from Vasya Pupkin “Vasya Pupkin DB” or not is a separate issue. Probably not. And if he brings something of his own there? And they started to do it.
We have a picture where the green and red flags indicate Postgres commercial and non-commercial forks. There are a lot of them. We counted 40-50 pieces. Most of them, naturally, are not successful: they are bent, they are forgotten. Some large organizations, such as Amazon or Salesforce, can fork for themselves, for example. The most famous commercial forks are, of course, Greenplum, EnterpriseDB. Including our Postgres Pro, Japanese Fujitsu Enterprise Postgres.
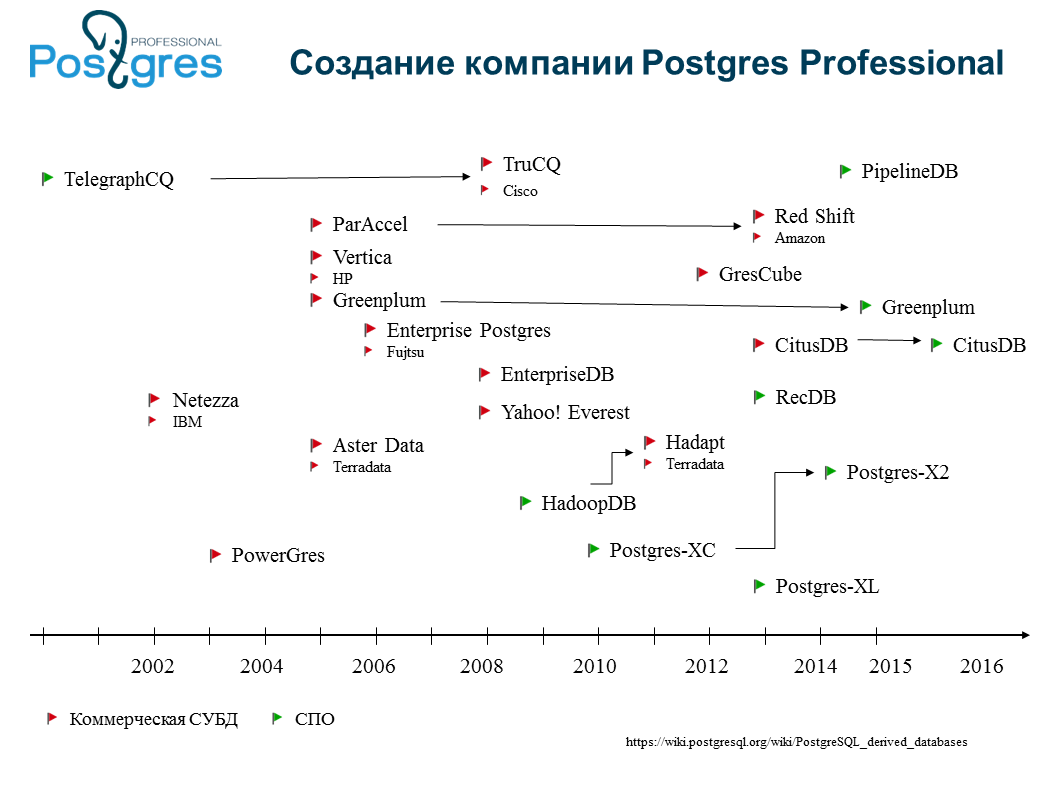
The British, too, have recently made an enterprise version of Postgres. For what? There are specialized forks, for example, Greenplum is a database for massive analytical calculations with great parallelism. They took Postgres about ten years ago, changed the scheduler very much, added work with distributed requests there, though, while losing transactional integrity. But for analytical databases, this does not matter: everything already lies there, and you need to collect and correctly distribute the request across the servers. They made Greenplum.
This thing is used, including, in our Russia. In particular, Tinkoff Bank boasted that they have it. A good thing that has had some commercial success, but has lagged behind open source because it has a high level of incompatibility. They changed the scheduler very much, did a lot of good things, of course, they can be praised for this, but the development of open source has gone the other way. And here the main thing is not to go far. The farther you go, the harder it is to merge later.
The first example is when they made versions of Postgres that have some specific functionality. This is one example of why commercial companies arise. And what else are there?
Greenplum did a really big functional thing that pushes Postgres very sideways. Moreover, this is no longer a universal product, but it well solves an important demanded task.
Another group of forks is our Postgres Pro and Enterprise DB. The latter, oddly enough, despite all their American nature, are engaged in migration from Oracle.
In America, they also switch from Oracle, because it is expensive to pay for each "sneeze". Not everyone wants it, and not everyone has something to pay. Therefore, Enterprise DB offers worldwide migration services from Oracle. And in order to make it easier to crawl, they went along the path of implementing some features that are in Oracle in Enterprise DB.
And what is our Postgres Pro? We decided not to follow this path, although we did some features from Oracle, for example, asynchronous autonomous transactions. But in the long run, we do not see the path for Oracle. Because “follow” means that you will always be behind, and you will never be 100% compatible anyway, and you still have to constantly prove at least partial compatibility. This is a difficult problem.
Despite the fact that you can write a parser for Oracle's PSQL; Thank God, it is documented syntactically, but you will not find very strict documentation on its semantics. Moreover, for full compatibility you will have to reproduce “bug to bug”. So try to do it, and then prove that it really is. We realized that this does not really solve the problem of migration. We decided it was better to move forward. Better to just make the best product.
On the other hand, is it necessary to make compatibility in such a picture at the level of full coverage, not to mention “bug to bug”? The task is to close the conditional 80% of the costs of migration.
It really seems so, but in practice it turns out that when you migrate the system, it looks like this: they give you a finished system. This is a black box wrapped in black paper, tied with a black rope. You do not know what is inside. Is there 80% of these, or does she crawl out a little? It often happens that it was developed by the "tyap-blunder" method of 3 floors, and the builders of the first floor have long sunk somewhere.
And so, in order to migrate to this thing, you have to do reverse engineering - not even in order to rewrite, but in order to understand whether it works or not. That is, if you have the perfect test coverage - then yes, you can say ...
What never happens, of course ..
... You can say: “We replace the engine, run the tests. 100% passed, everything is verified. Go". In reality, this does not happen. This is an ideal case. And so it turns out that you are selling at 80%, and the rest will still be tormented, and you don’t know what in advance. Migration has other, much more significant problems.
Each product, each DBMS has advantages. For Postgres, for example, this is working with JSON and with the arrays that we talked about. Many things that are optimally written on Oracle like this are better written on Postgres in a different way. Therefore, if you migrate "stupidly", then you will get a minimally working subset that is compatible with both. You will not take advantage of either the old database or the new one.
Let’s say a few words about the future. Where is all this going? Will you kill all competitors?
I do not think that we will kill all competitors. In principle, we have such good, “affectionate” goals. We did not come to kill, but to build. Our task is to create a very good database. Better for the best.
And what is it? What is the criterion for this goodness? I doubt that Microsoft has the task of making a very bad database.
Yes, of course, everyone goes to this. Therefore, in the world of databases now there are some trends. And since data volumes are growing faster than everything else, respectively, the main trend of databases now is distribution. Those who will better solve the problem of a distributed database will be well done.
Ivan Panchenko was with us. Thank you Ivan.
Thanks.
Last year, I started filming a series of programs / interviews on the topic of digital business transformation ( they’re here for those who are interested - sign up ). These programs were at the intersection of IT and business, but, nevertheless, more about business.
In the process, it became clear that there are many that have significant depth from a programmer point of view. And this year we started filming a series of interviews under the common label “DZ Online Tech” - now with the emphasis on what's under the hood. Well, since everyone is too lazy to watch the video, of course, these interviews are decrypted, and today I publish the first one - with Ivan Panchenko from Postgres Professional.
Who cares about the original - here it is:
(Well, by the way, I cannot swear that all issues will be decrypted, so if you like it, sign up on YouTube, everything comes there earlier and guaranteed.)
For those who like to read, decryption:
Good afternoon, Ivan. Postgres is widely accepted as an import substitution tool. And the most famous driver for its application is the idea of “let's replace some Western DBMS with Postgres”. Moreover, it is known that he has a lot of his own values. I would like to go through them briefly. If we choose, without looking “import - not import”, but from scratch — why?
Good afternoon. Firstly, most Postgres do not choose because of import substitution. It is clear that there really are government measures and restrictions on the import of foreign software. Postgres Pro is in the registry, so it is suitable for import substitution. In fact, it is a global trend to choose Postgres more and more. We see only its reflection. It is possible that what was expressed in import substitution is, in fact, a consequence of some deeper, more fundamental processes.
Postgres is ripe. This is a good alternative to older commercial databases. All over the world now they understand that Postgres is a product of the same class as whales: Oracle, Microsoft SQL Server and DB2, the last of which they have almost forgotten, but nevertheless, this is a good product.
But, one way or another, DB2 is gradually floating away from the market somewhere, and Oracle, Microsoft SQL is on it. And Postgres is something third that now floats into the market on a global scale. I must say that it floats quite a long time ago - 10 years ago, when good support for Windows appeared in Postgres. When replication appeared in him, they began to perceive him; they started talking about him as a database for business, industry, and something serious.
You still say in the picture "there were two good ones, there is another good one." But there are surely things that put him forward and make him prefer others.
Yes, there are several such things. Firstly, Postgres is an open source product with a specific license. He also has commercial clones. One of them is ours. But the fact that it comes from an open source product is in itself a great advantage.
The second topic is that Postgres is a highly extensible database. This was also a driver of its development.
I must say that the degree of Postgres extensibility is exactly the place where our Russian contribution is most noticeable. The last 15-17 years, our team is mainly engaged in extensibility mechanisms.
For example, at Rambler in 2000, where I first worked with my current company colleagues, we used Postgres extensibility to increase the performance of the Rambler news service by 30 times. How? We are C programmers who can read documentation. These two things allowed us to create a new type of index for quick searching through arrays, which is beyond the scope of the classical relational model, but useful.
In particular, in Rambler, replacing an extra join with an array in which you can search by a cunning index increased productivity by 30 times. It must be understood that then all Rambler content projects spun on typewriters whose power did not exceed the power of a modern smartphone: Pentium 2, 400 MHz, 500 MB of memory. If you're lucky, then the Pentium 3 (it appeared then) up to 800 MHz. Such Pentium 3 could be 2 pieces in the server. And all this served millions of requests.
It is clear that then it was necessary to optimize the code very seriously, otherwise it would not work. Postgres extensibility helped. We sat, thought, and within an acceptable time frame, one could say for a month, did what then formed the basis of everything that is now in Postgres, related to JSON, with full-text search.
Thanks to this, Postgres quickly developed support for poorly structured data. What it is? These are key-values, roughly. In 2004, we made an extension of Hstore in Postgres to store key-value information in the same database field. Then it was not JSON yet, it went into fashion later. And then there was Hstore. Why hstore? We looked at Perl, which has a hash, and now we made a hash with almost the same syntax in Postgres.
At first this thing existed as a separate extension (extension), then it was committed (commit) in the main set of what is included in Postgres. And she was just as popular. That is, JSON has rounded it in popularity recently.
It turns out that in a sense you put an end to this stupid discussion of SQL and noSQL by creating a DBMS that has the properties of both at the same time.
In a way, yes. From noSQL we took good, namely comparative flexibility, without loss of transactionality, without loss of data integrity and everything that usually happens in normal DBMSs.
So, Hstore. But Hstore was sibling. That is, the hash is single-level. This is not JSON, just a hash. And plus arrays in Postgres were before us. We made support for indexes, that is, you could quickly search by what is included in the arrays, and by what lies inside the Hstore, both by keys and by values. This is a useful thing. People began to use it around the world. Then came JSON. He appeared recently, the year 2011-2012 at Postgres. There were three different attempts to implement it. Then all these attempts were thrown, and made in a different way. At first, JSON was just text that lies in a special field.
Was your team doing JSON?
No, our team did an important thing for JSON. When JSON appeared in Postgres, it was just a text field, and in order to extract something from there, some search value had to parse JSON every time. Of course, this worked slowly, but it allowed storing multilevel data.
But there is little sense in such a text box. For example, in my projects, I already stored weakly structured data in text fields, simply without calling it a special type of field. But the question is that with this JSON it was also necessary to work effectively. And what we have already done with our team in 2014 is JSON-B.
It is faster due to the fact that it is already laid out and parsing. Steamed so that you can quickly get the key value. When we made JSON-B, we fastened it to the ability to search by index, then it became really popular.
Okay Returning to specific properties: what else is there that distinguishes Postgres from other DBMSs and is the reason to use it?
All we've been talking about JSON for so long is all about Postgres flexibility. It has many places in which it can be expanded. The other side of flexibility is geodata support. Exactly the same way as special indexes were made, for example, for searching by JSON, by arrays and by texts, approximately through the same place indexes were made for quick search by geo-information, by spatial data. There we also put our rather large Russian hand in this matter.
As a result, PostGIS is such a very widespread way of working with geoinformation data in the world.
Do users develop extensions for Postgres for their projects? Is this a significant amount of its application?
No, of course, these are some kind of “cream” on top. There are people who need it because their task grows to this. This is, first of all, a universal database that very well supports all standards and which is certainly suitable for almost any task.
If you start a startup, for example - take Postgres, you will not be mistaken. Because, firstly, it is functionally extensible. And secondly, if you use its open source version, then do not become a hostage to the license that you need to purchase.
Do you, as an employee of commercial digging, say this, probably, not very happily?
These are the laws of nature, against which there is no arguing. There is open source, and there is open source business. And this is a rather unusual thing, different from ordinary business. But in the future, the role of open source, apparently, will grow. At least, this can be seen in the success of Postgres and in the Gartner schedule, which is boring to everyone, that the open source database is being used more and more often, and there is no getting around it.
You as a company, why are you needed? Here he is open source: go, download and all is well?
In fact, I went, downloaded, but ran into a problem. Sooner or later, people come across a problem. It is clear that for most users the open source version will do. They will not have problems, they have small bases, they will not grow. But in some cases, you need the help of a professional.
Previously, the model was simple. In this case, I'm talking about Postgres, because different products are at different stages of this evolutionary path. Postgres was originally just a university project. People did not think about money; they were interested in solving the problem. Then he was a volunteer project: people did it for themselves. Moreover, they worked in some companies like ours.
Well, how did you make a decision at Rambler.
Rambler is a good example. We did it because we needed it. We were not at all bothered by business users. Whether someone else needs it or not.
Postgres companies initially began to arise not in Russia, but in other countries. For the first time such a company arose in Japan, however, with Fujitsu money. There have been invested quite a lot. And she started developing Postgres and near-Postgres stuff. Then, in a fairly short time after that, the second quadrant (2nd Quadrant) appeared in England, and in America Enterprise DB. These are all companies that make money on Postgres. All these companies start with the fact that they execute orders. They are engaged ...
Custom development.
Custom development at the DBMS level. We do this too, and we did these things when we weren't a company yet, because Postgres is expanding. “We need the full-text search to search not only like this, but also to correctly ignore our French accents, or our German umlauts. Finish it - we will pay you. " Or: “JSON is a very good thing. I wish I could attach an index to it. And then our portal of free ads will fly a little faster than everyone else. "
These guys really financed the development, paying individual developers or, in some cases, ordering to the young, newly emerged companies some features that they wanted to get. And then gradually the need for commercial versions of Postgres began to arise.
Why, and in general, where did these commercial forks come from? First of all, I must say that Postgres has such a tricky license that legally allows you to make a commercial product out of it. BSD-like license. This is no GPL. You can take at least the same code, even without making any changes to it, leave two lines from the license agreement there, add something else to it, and write that this is my “Vasya Pupkin DB” and I am selling it . To go to the market and sell at least for billions - please, it doesn’t matter. At least someone who buys from Vasya Pupkin “Vasya Pupkin DB” or not is a separate issue. Probably not. And if he brings something of his own there? And they started to do it.
We have a picture where the green and red flags indicate Postgres commercial and non-commercial forks. There are a lot of them. We counted 40-50 pieces. Most of them, naturally, are not successful: they are bent, they are forgotten. Some large organizations, such as Amazon or Salesforce, can fork for themselves, for example. The most famous commercial forks are, of course, Greenplum, EnterpriseDB. Including our Postgres Pro, Japanese Fujitsu Enterprise Postgres.
The British, too, have recently made an enterprise version of Postgres. For what? There are specialized forks, for example, Greenplum is a database for massive analytical calculations with great parallelism. They took Postgres about ten years ago, changed the scheduler very much, added work with distributed requests there, though, while losing transactional integrity. But for analytical databases, this does not matter: everything already lies there, and you need to collect and correctly distribute the request across the servers. They made Greenplum.
This thing is used, including, in our Russia. In particular, Tinkoff Bank boasted that they have it. A good thing that has had some commercial success, but has lagged behind open source because it has a high level of incompatibility. They changed the scheduler very much, did a lot of good things, of course, they can be praised for this, but the development of open source has gone the other way. And here the main thing is not to go far. The farther you go, the harder it is to merge later.
The first example is when they made versions of Postgres that have some specific functionality. This is one example of why commercial companies arise. And what else are there?
Greenplum did a really big functional thing that pushes Postgres very sideways. Moreover, this is no longer a universal product, but it well solves an important demanded task.
Another group of forks is our Postgres Pro and Enterprise DB. The latter, oddly enough, despite all their American nature, are engaged in migration from Oracle.
In America, they also switch from Oracle, because it is expensive to pay for each "sneeze". Not everyone wants it, and not everyone has something to pay. Therefore, Enterprise DB offers worldwide migration services from Oracle. And in order to make it easier to crawl, they went along the path of implementing some features that are in Oracle in Enterprise DB.
And what is our Postgres Pro? We decided not to follow this path, although we did some features from Oracle, for example, asynchronous autonomous transactions. But in the long run, we do not see the path for Oracle. Because “follow” means that you will always be behind, and you will never be 100% compatible anyway, and you still have to constantly prove at least partial compatibility. This is a difficult problem.
Despite the fact that you can write a parser for Oracle's PSQL; Thank God, it is documented syntactically, but you will not find very strict documentation on its semantics. Moreover, for full compatibility you will have to reproduce “bug to bug”. So try to do it, and then prove that it really is. We realized that this does not really solve the problem of migration. We decided it was better to move forward. Better to just make the best product.
On the other hand, is it necessary to make compatibility in such a picture at the level of full coverage, not to mention “bug to bug”? The task is to close the conditional 80% of the costs of migration.
It really seems so, but in practice it turns out that when you migrate the system, it looks like this: they give you a finished system. This is a black box wrapped in black paper, tied with a black rope. You do not know what is inside. Is there 80% of these, or does she crawl out a little? It often happens that it was developed by the "tyap-blunder" method of 3 floors, and the builders of the first floor have long sunk somewhere.
And so, in order to migrate to this thing, you have to do reverse engineering - not even in order to rewrite, but in order to understand whether it works or not. That is, if you have the perfect test coverage - then yes, you can say ...
What never happens, of course ..
... You can say: “We replace the engine, run the tests. 100% passed, everything is verified. Go". In reality, this does not happen. This is an ideal case. And so it turns out that you are selling at 80%, and the rest will still be tormented, and you don’t know what in advance. Migration has other, much more significant problems.
Each product, each DBMS has advantages. For Postgres, for example, this is working with JSON and with the arrays that we talked about. Many things that are optimally written on Oracle like this are better written on Postgres in a different way. Therefore, if you migrate "stupidly", then you will get a minimally working subset that is compatible with both. You will not take advantage of either the old database or the new one.
Let’s say a few words about the future. Where is all this going? Will you kill all competitors?
I do not think that we will kill all competitors. In principle, we have such good, “affectionate” goals. We did not come to kill, but to build. Our task is to create a very good database. Better for the best.
And what is it? What is the criterion for this goodness? I doubt that Microsoft has the task of making a very bad database.
Yes, of course, everyone goes to this. Therefore, in the world of databases now there are some trends. And since data volumes are growing faster than everything else, respectively, the main trend of databases now is distribution. Those who will better solve the problem of a distributed database will be well done.
Ivan Panchenko was with us. Thank you Ivan.
Thanks.