What do we know about the loss function landscape in machine learning?
TL; DR
- In deep neural networks, the main obstacle to learning is saddle points, not local minima, as previously thought.
- Most local minima of the objective function are concentrated in a relatively small subspace of weights. The networks corresponding to these minima give approximately the same loss on the test dataset.
- The complexity of the landscape increases towards global lows. In almost the entire volume of the space of weights, the vast majority of saddle points have a large number of directions in which you can escape from them. The closer to the center of the cluster of minima, the less “escape directions” for the saddle points encountered along the path.
- It is still unclear how to find a global extremum (any of them) in the subspace of minima. It appears to be very difficult; and not the fact that a typical global minimum is much better than a typical local minimum, both in terms of loss and in terms of generalizing ability.
- In clumps of minima, there are special curves connecting local minima. The loss function on these curves takes only slightly larger values than in the extrema themselves.
- Some researchers believe that wide lows (with a large radius of the "hole" around) are better than narrow ones. But there are many scientists who believe that the connection between the minimum width and the generalizing ability of the network is very weak.
- Skip connections make the terrain more friendly for gradient descent. There seems to be no reason not to use residual learning at all.
- The wider the layers in the network and the less of them (up to a certain limit), the smoother the landscape of the objective function. Alas, the more redundant the network parameterization, the more the neural network is subject to retraining. If you use super-wide layers, then it is easy to find a global minimum on a training dataset, but such a network will not be generalized.
All, scroll on. I won’t even put KDPV.
The article consists of three parts: a review of theoretical papers, a review of scientific papers with experiments, and cross-comparison. The first part is a little dry, if you get bored, scroll immediately to the third.
But to begin with, clarification on paragraph two. The claimed subspace is small in total volume, but can be arbitrarily large in scope when projected onto any line in hyperspace. It contains both clumps of minima, and just areas where the loss function is small. Imagine two consecutive linear neurons. The output will be the value
 . Suppose we want to, we want to teach them how to reproduce an identity function
. Suppose we want to, we want to teach them how to reproduce an identity function . If we apply to the L2 loss network, then the surface of the error function will look like
. If we apply to the L2 loss network, then the surface of the error function will look like :
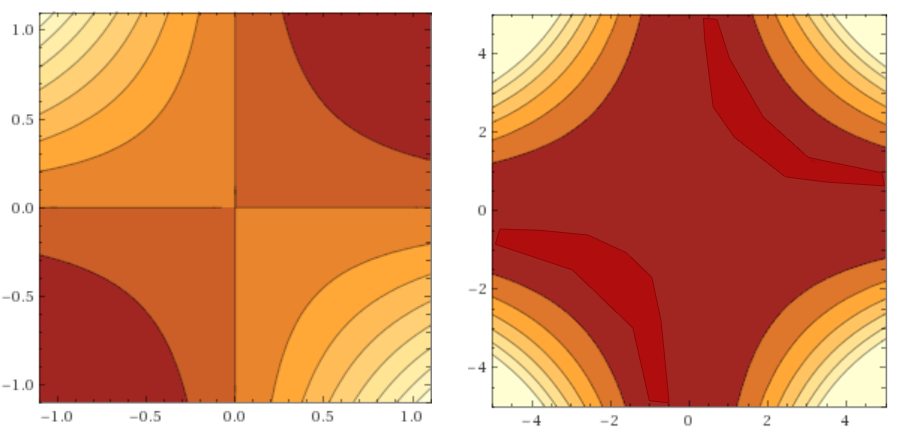
: 
Where on the abscissa is delayed
 and in ordinate -
and in ordinate -  .
. It's obvious that
 perfectly reproduce the identity function, but they do the same thing
perfectly reproduce the identity function, but they do the same thing  and for example
and for example  . All these are global minima (there are an infinite number of them), and the red-burgundy area on the graphs is the subspace of minima (as you can see, it extends infinitely along both axes, but more and more thinner with distance from zero). We observe this behavior due to the symmetry of the weights, and this phenomenon is not unique to linear networks. It is partially treated by regularization, but even so, two global minimums remain. and (plus or minus distortion from regularization).
. All these are global minima (there are an infinite number of them), and the red-burgundy area on the graphs is the subspace of minima (as you can see, it extends infinitely along both axes, but more and more thinner with distance from zero). We observe this behavior due to the symmetry of the weights, and this phenomenon is not unique to linear networks. It is partially treated by regularization, but even so, two global minimums remain. and (plus or minus distortion from regularization). 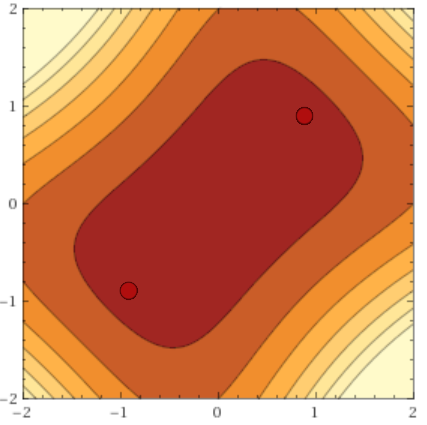
In the future, by “global minimum” I will mean “any of the identical global minimums”, and by “clot of minimums” - “any of the symmetric clusters of local minimums”.
Review of theoretical works
As you know, neural network training is the search for the minimum of the objective loss function
 in the space of weights
in the space of weights  . Alas, finding the global minimum of an arbitrary differentiable function belongs to the class of NP-complex problems [1]. In addition, neural networks can have a very different architecture and accept any data as input, so there is no reason to hope for a deep analysis of one formula with clearly defined restrictions. Functionincredibly multidimensional, therefore, the brute force method is also non-trivial to apply here. However, even some general facts about a typical landscapecan bring considerable benefits: at least set the general direction of practical research.
. Alas, finding the global minimum of an arbitrary differentiable function belongs to the class of NP-complex problems [1]. In addition, neural networks can have a very different architecture and accept any data as input, so there is no reason to hope for a deep analysis of one formula with clearly defined restrictions. Functionincredibly multidimensional, therefore, the brute force method is also non-trivial to apply here. However, even some general facts about a typical landscapecan bring considerable benefits: at least set the general direction of practical research. Until recently, there were few people wishing to tackle such a titanic task, but in early 2014 an article was published by Andrew Saxe and others [2], which discusses the nonlinear dynamics of linear learningneural networks (a formula is given for the optimal learning speed) and the best way to initialize them (orthogonal matrices). The authors get interesting calculations based on the decomposition of the product of the network weights in SVD and theorize how the results can be transferred to nonlinear networks. Although Saxe's work is not directly related to the topic of this article, it encouraged other researchers to take a deeper look at the dynamics of learning neural networks. In particular, a little later in 2014, Yann Dauphin and the team [3] review the existing literature on the dynamics of learning and pay attention not only to the Saxe article, but also to the work of Bray and Dean [4] from 2007 about statistics of critical points in random Gaussian fields. They offer a modification of the Saddle Free Newton (SFN) method, which not only escapes saddle points better, but they also do not require the calculation of the full Gaussian (minimization follows the vectors of the so-called Krylov subspace). The article demonstrates very nice graphs of improving network accuracy, which means SFN is doing something right. The Dauphin article, in turn, gives impetus to new research on the distribution of critical points in the space of weights.
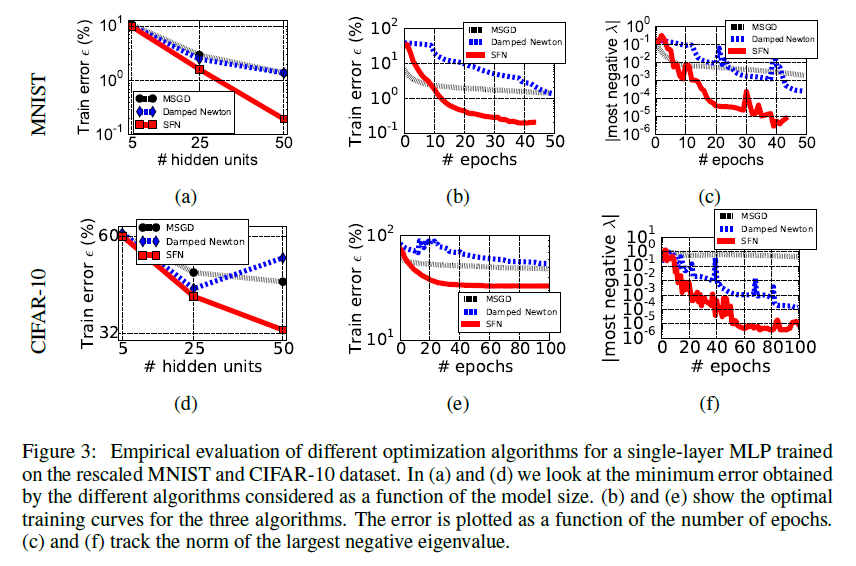
So, there are several areas of analysis of the stated problem.
The first is to steal from someone a little run-up math and apply it to your own model. This approach was incredibly successful by Anna Chromanska and the team [5] [6], using the equations of the theory of spin glasses. They limited themselves to the consideration of neural networks with the following characteristics:
- Direct distribution networks.
- Deep networks. The more weights, the better the asymptotic approximations work.
- ReLU activation features.
- L2 or Hinge loss function.
Then they imposed several more or less realistic restrictions on the model:
- The probability of a neuron being active is described by the Bernoulli distribution.
- The activation paths (which neuron activates which) are evenly distributed.
- The number of weights is excessive to form the distribution function
 . There are no scales whose removal blocks learning or prediction.
. There are no scales whose removal blocks learning or prediction. - Spherical weight limit:
 (Where
(Where  - the number of weights in the network)
- the number of weights in the network) - All input variables have a normal distribution with the same variance.
And a few unrealistic ones:
- The activation paths in the neural network are not specific .
- Input variables are independent of each other.
On the basis of which the following statements were received:
- The minima of the loss function in the neural network form a cluster in a relatively small subspace of weights. Beyond a certain boundary, the values of the loss function their number begins to exponentially decrease.
- For properly trained deep neural networks, the majority of local minima are approximately the same in terms of performance on the test sample.
- The probability of being in a “bad” local minimum is noticeable when working with small networks and decreases exponentially with an increase in the number of parameters in the network.
- Let be
 - the number of negative eigenvalues of the Hessian at the saddle point. The larger it is, the more are the ways in which gradient descent can escape from a critical point. For everybody there is some measure of the value of the objective function
- the number of negative eigenvalues of the Hessian at the saddle point. The larger it is, the more are the ways in which gradient descent can escape from a critical point. For everybody there is some measure of the value of the objective function  starting from which the density of saddle points with such begins to decrease exponentially. These numbers are strictly increasing. In Russian, this means that the loss function has a layered structure, and the closer we are to the global minimum, the more there will be nasty saddle points from which it is difficult to get out.
starting from which the density of saddle points with such begins to decrease exponentially. These numbers are strictly increasing. In Russian, this means that the loss function has a layered structure, and the closer we are to the global minimum, the more there will be nasty saddle points from which it is difficult to get out.
On the one hand, we almost "free" got a lot of proven theorems, showing that under certain conditions neural networks behave in a manner consistent with spin glasses. If anything is able to open the infamous “black box” of neural networks, it’s a matan from quantum physics. But there is an obvious drawback: very strong source premises. Even 1 and 2 of the realistic group seem dubious to me, what can I say about the unrealistic group. The most serious limitation in the model seems to me a uniform distribution of activation paths. What if some small group of activation pathways is responsible for classifying 95% of the elements of the dataset? It turns out that it forms a network in the network, which at times reduces the effective
. There’s an additional catch: Chromanska’s statements are hard to falsify. It is not so difficult to construct an example of weights representing a “bad” local minimum [7], but this does not seem to contradict the message of the article: their statements must be satisfied for large networks. However, even the provided set of weights for a moderately deep feed-forward network, which poorly classifies, say, MNIST is unlikely to be strong evidence, because the authors argue that the probability of encountering a “bad” local minimum tends to zero, and not that they are completely absent. Plus, “for properly trained deep neural networks” is a pretty loose concept ...
The second approach involves building a model of the simplest possible neural network and iteratively bringing it to a state where it can describe modern machine learning monsters. We have long had a basic model - these are linear neural networks (i.e. networks with activation function
 ) with one hidden layer. They lend themselves well to analysis, and have been studying them for a long time, but the results of these theoretical studies were of little interest to anyone, since in general linear networks are not very useful.
) with one hidden layer. They lend themselves well to analysis, and have been studying them for a long time, but the results of these theoretical studies were of little interest to anyone, since in general linear networks are not very useful. At least, few people were interested until recently. Using rather weak restrictions on layer sizes and data properties, Kenji Kawaguchi [8] develops the results of [9] from 1989 and shows that in certain linear neural networks with L2-loss
- Though non-convex and non-concave
- All local minima are global (there can be more than one)
- And all other critical points are saddle
- If - the saddle point of the loss function and the rank of the matrix product of the network weights is equal to the rank of the narrowest layer in the neural network, then the Hessian in has at least one strictly negative eigenvalue.
If the rank of the product is less, then the Hessian matrix can have zero eigenvalues, which means that we cannot so easily understand whether we hit a non-strict local minimum or a saddle point. Compare with features
 at zero and
at zero and  in
in  .
. After that, Kawaguchi takes into account networks with ReLu activation, slightly relaxes the limitations of Choromanska [6], and proves the same statements for neural networks with ReLu nonlinearities and L2-loss. (In the next paper [10], the same author gives a simpler proof). Hardt & Ma [11], inspired by calculations [8] and the success of residual learning, prove even stronger statements for linear networks with skip connections: under certain conditions, they do not even have “bad” critical points without negative eigenvalues of the Hessian (see [ 12] for theoretical justification of why “short circuits” in the network improve the landscape, and [13] for graph examples
before and after adding skip connections). The accumulated knowledge base is summarized by the recently appeared work of Yun, Sra & Jadbabaie [14]. The authors strengthen Kawaguchi's theorems and, like Chromanska, divide the weight space of a linear neural network into a subspace that contains only saddle points, and a subspace that contains only global minima (necessary and sufficient conditions are given). Moreover, scientists finally take a step in the direction we are interested in and prove similar statements for nonlinear neural networks. Let the latter be done with very strong prerequisites, but these are prerequisites different from the conditions of Chromanska.
Visualization Overview
The third approach is the analysis of the values of the Hessian in the learning process. Mathematicians have long been aware of second-order optimization methods. Machine learning specialists occasionally flirt with them (with methods, not with mathematicians ... albeit with mathematicians too), but even truncated second-order descent algorithms have never been particularly popular. The main reason for this lies in the cost of calculating the data necessary for descent, taking into account the second derivative. An honestly calculated Hessian takes a square of the number of memory weights: if there are a million parameters in the network, then in the matrix of the second derivatives there will be
 . But you still want to somehow calculate the eigenvalues of this matrix ...
. But you still want to somehow calculate the eigenvalues of this matrix ... For the same reason, there are few works allowing you to look at the dynamics of the Hessian in the learning process. More precisely, I found exactly one work by Yann LeCun and the company [34] dedicated to this, and even then they work with a relatively primitive network. Plus, in [3] and [12] there are a couple of relevant comments and graphs.
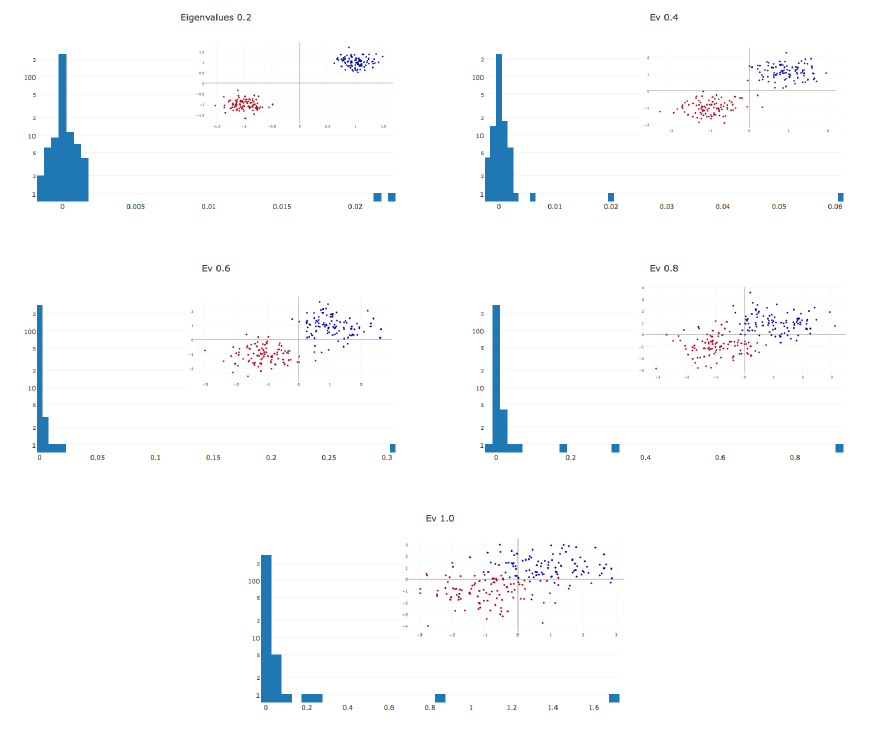
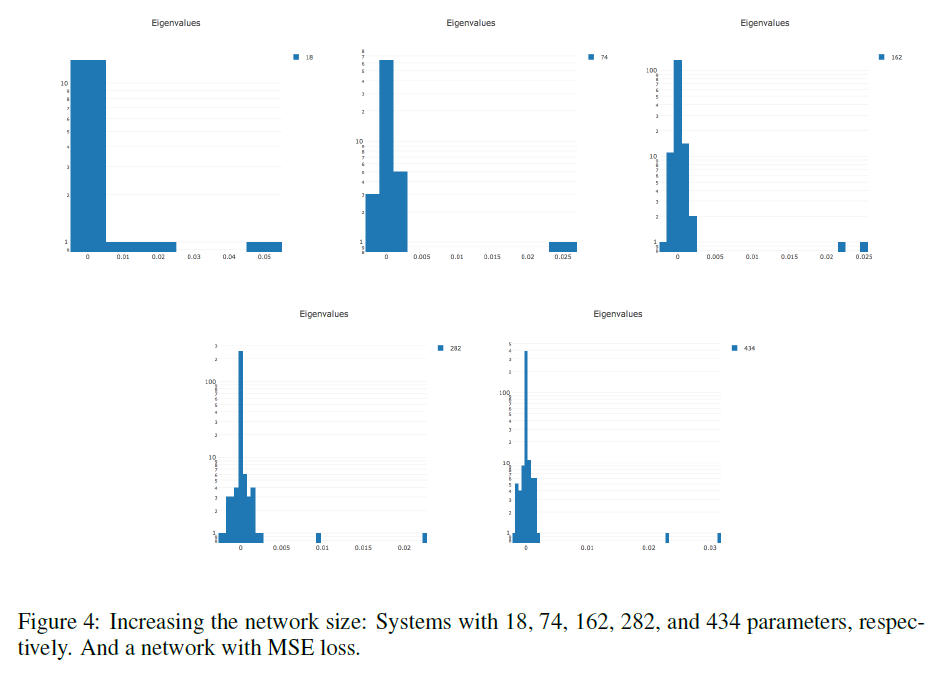
LeCun [34]: Hessian almost entirely consists of zero values throughout the training. During optimization, the Hessian histogram further compresses to zero. Nonzero values are distributed unevenly: a long tail is thrown to the positive side, while negative values are concentrated near zero. Often it only seems to us that the training stopped, while we just ended up in a pool with small gradients. At the breakpoint there are negative eigenvalues of the Hessian.
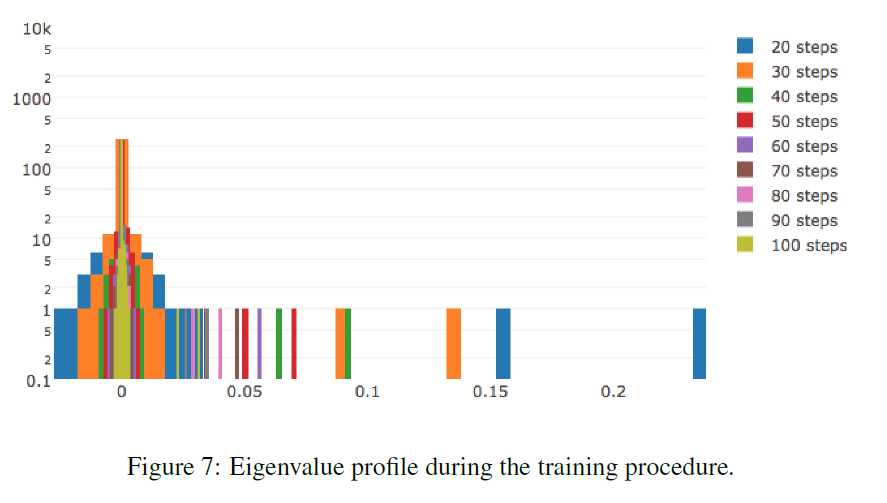
The more complex the data, the more elongated the positive tail of the distribution of eigenvalues.
The more parameters in the network, the more stretched the histogram of eigenvalues in both directions.
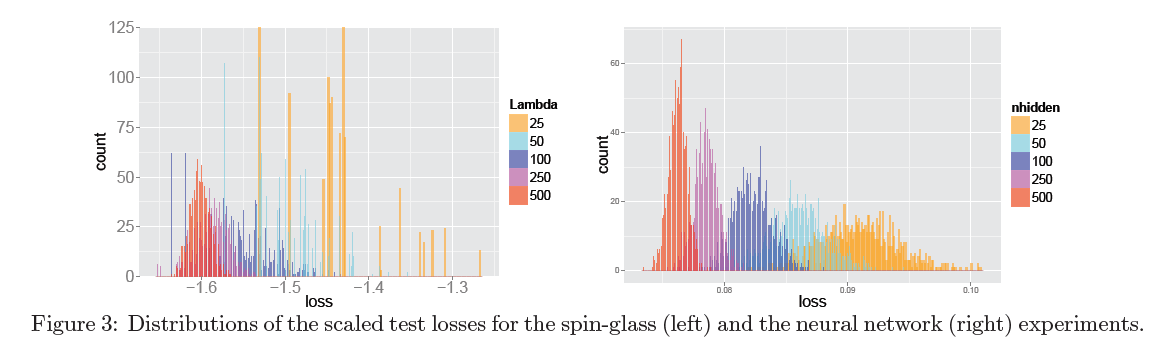
Dauphin et al. [3]: On graphs A and C along the axis
 the relative portion of the negative values at the critical point at which training stopped
the relative portion of the negative values at the critical point at which training stopped  postponed error on the training sample. Graphs B and D show histograms of eigenvalues of the matrix of second derivatives for three points from graphs A and C, respectively. Please note that they are consistent with LeCun histograms.
postponed error on the training sample. Graphs B and D show histograms of eigenvalues of the matrix of second derivatives for three points from graphs A and C, respectively. Please note that they are consistent with LeCun histograms. 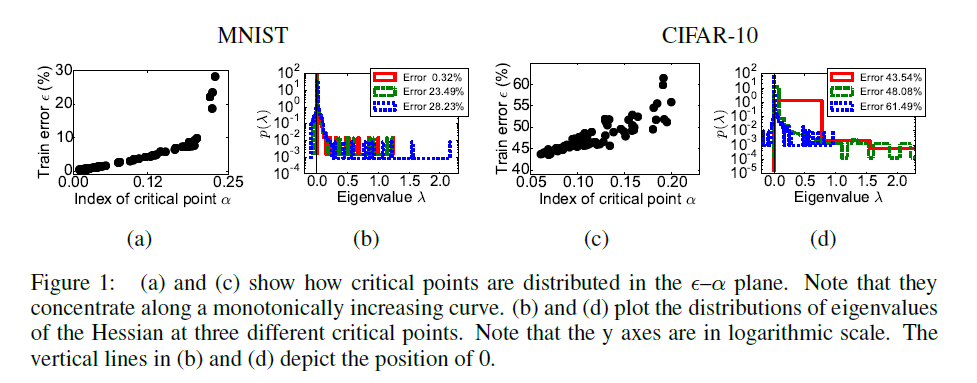
The correlation between the number of escape directions from the saddle point and the quality of the network in it is clearly visible.
Orhan & Pitkow [12]: Relative numbers of degenerate and negative eigenvalues of the Hessian are shown. The article says not quite about the same thing as in [3] and [34], but in general the graphs indirectly confirm the results of two previous works.

Fourth Way - Direct Landscape Analysis
using visualizations of any projections. The idea is trivial, but, as already mentioned, applying it is not at all easy, because inthere may be millions of weights. Usually, two types of visualizations are considered: the values of the loss function with change in the space of weights along a curve and a graph of the loss function in the vicinity of a point for  where
where  and
and  - some vectors defining the section plane of the space of weights. In the case of a one-dimensional projection, the transitions from the initial state of the network to the final state (directly or along the learning curve) or between two final states are usually visualized; in the two-dimensional state, the two most significant vectors in the PCA decomposition of the final part of the learning curve are usually taken. In addition to multidimensionality, the problem of visualizing the objective function is complicated by the fact that essentially the same minimums can have very different weights. For example, if in a linear neural network the weights in one layer are reduced in
- some vectors defining the section plane of the space of weights. In the case of a one-dimensional projection, the transitions from the initial state of the network to the final state (directly or along the learning curve) or between two final states are usually visualized; in the two-dimensional state, the two most significant vectors in the PCA decomposition of the final part of the learning curve are usually taken. In addition to multidimensionality, the problem of visualizing the objective function is complicated by the fact that essentially the same minimums can have very different weights. For example, if in a linear neural network the weights in one layer are reduced in times, and the next after him - in times increase, the resulting sets of weights and the areas of space around them will be very different, while the learned features will be essentially the same. An additional measurement for analysis is the type of minimizer or the parameters of the specific type of minimizer with which it was obtained.
times, and the next after him - in times increase, the resulting sets of weights and the areas of space around them will be very different, while the learned features will be essentially the same. An additional measurement for analysis is the type of minimizer or the parameters of the specific type of minimizer with which it was obtained. One of these works is [16]. In it, researchers look at the gap between the launch endpoints with SGD, Adam, Adadelta, and RMSProp. As in many other works, it is found that various algorithms find characteristically different minima. Also, the authors of the article show that if during the training to change the type of algorithm, then
will change course to another minimum. As a second bonus, researchers look at how the landscape between the batch normalization endpoints will affect the landscape and conclude that, firstly, with batch normalization, the quality of the resulting minimum is much less dependent on the initialization point, and secondly, between the endpoints “walls” appear in the landscape of the objective function - narrow sections with a very large value (it is not clear where this comes from and what to do about it). In any case, the “hills” of loss are visible between the lows in the above graphs, but not at all some kind of complex surface. 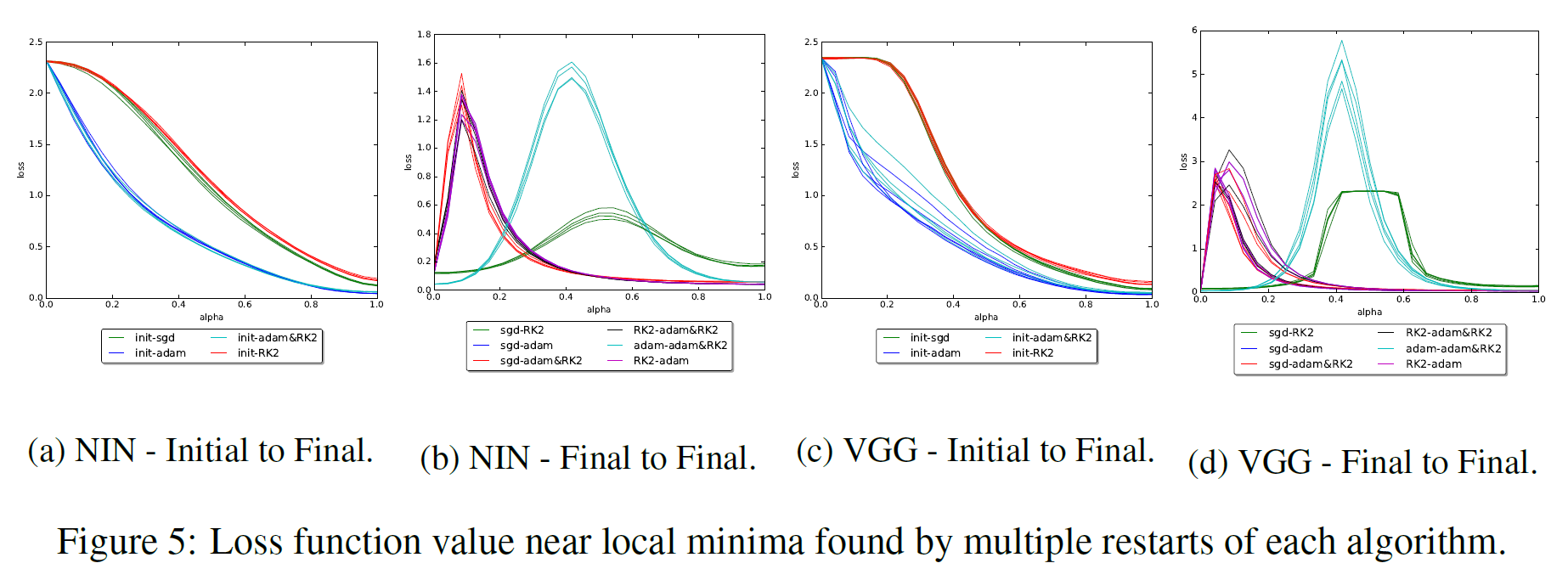
Now we are more interested in a group of studies in which it is proved that between two minima in the space of weights
 and
and  almost always it is possible to draw a curve along the entire length of which the loss function will not exceed
almost always it is possible to draw a curve along the entire length of which the loss function will not exceed  for
for  separated from zero by a certain boundary, but much smaller than the typical values of the loss function [17] [18] [19]. There are several ways to form such a curve at once: as a rule, they have a simple segment between and It is divided into links, after which the nodes connecting them with a gradient descent move in the space of the scales. Using such curves, for example, it is possible to collect better ensembles of networks [18]. Their results show that the cluster of minima has a “porous” structure.
separated from zero by a certain boundary, but much smaller than the typical values of the loss function [17] [18] [19]. There are several ways to form such a curve at once: as a rule, they have a simple segment between and It is divided into links, after which the nodes connecting them with a gradient descent move in the space of the scales. Using such curves, for example, it is possible to collect better ensembles of networks [18]. Their results show that the cluster of minima has a “porous” structure. 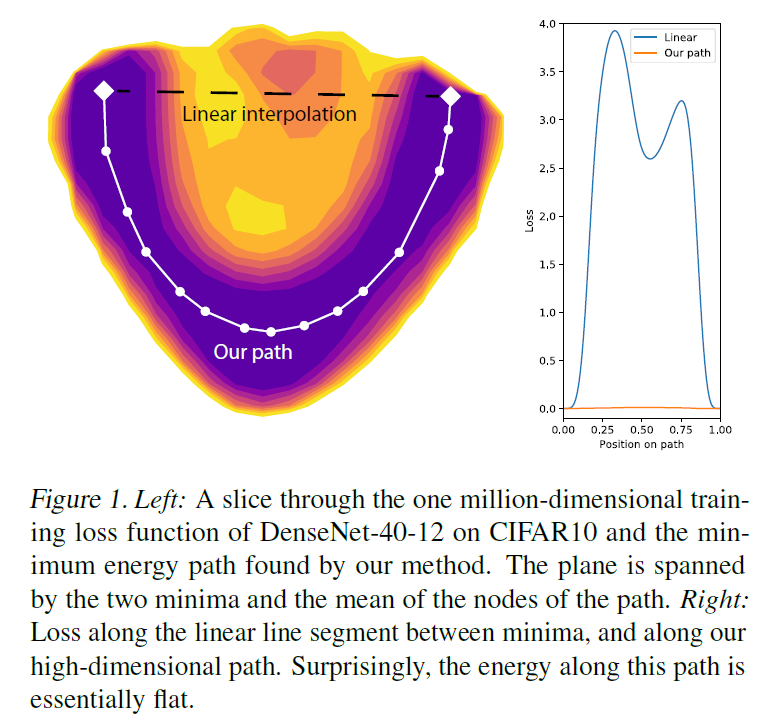
The very recent article from an international team of scientists [23], in which they build loss'a graphs between
 and
and  and the angle between the directions of the gradient at times
and the angle between the directions of the gradient at times  and
and  . It turns out that at the beginning of training, the gradients of the neighboring steps are directed approximately in one direction and the error function decreases monotonously, but from some point in time in between and begins to show characteristic minima, and the angle between the gradients tends to ~ 170 degrees. Indeed, it is very likely that the gradient descent "bounces" from the walls of the "saddle" with a slight slope! The picture is much cleaner when gradient descent is carried out using the entire dataset; the use of minibatch distorts the picture beyond recognition, which is logical. Learning rate does not affect the graph of the angle, but the size of batch'ey - very much. Researchers did not find intersections of local minima.
. It turns out that at the beginning of training, the gradients of the neighboring steps are directed approximately in one direction and the error function decreases monotonously, but from some point in time in between and begins to show characteristic minima, and the angle between the gradients tends to ~ 170 degrees. Indeed, it is very likely that the gradient descent "bounces" from the walls of the "saddle" with a slight slope! The picture is much cleaner when gradient descent is carried out using the entire dataset; the use of minibatch distorts the picture beyond recognition, which is logical. Learning rate does not affect the graph of the angle, but the size of batch'ey - very much. Researchers did not find intersections of local minima.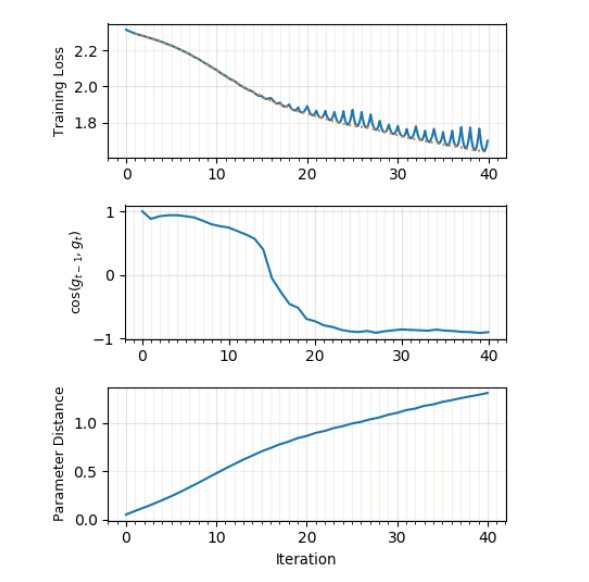
Until now, we believed that the quality of the minimum found depends only on its depth. However, many researchers note that the width of the minimum also matters. Formally, it can be defined in different ways; I will not give various formulations (see [20], if you still want to see them), it suffices to understand the main idea here. Here is an illustration: The
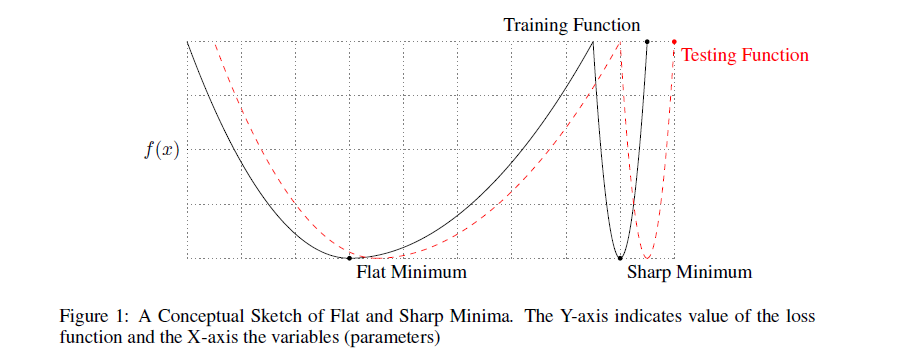
minimum of the black graph on the left is wide, on the right is narrow. Why does it matter? The distribution of training data does not exactly match the distribution of test data. It can be assumed that the minima
 on the test data will look slightly different from the minima of the original function , in particular, the lows are likely to be offset from each other. But if such distortions are not terrible to a wide minimum, then a narrow one can change beyond recognition. Again, turn to the picture above. If you accept that the black graph is the originalSince red is a test one, you can immediately see what problems this can lead to.
on the test data will look slightly different from the minima of the original function , in particular, the lows are likely to be offset from each other. But if such distortions are not terrible to a wide minimum, then a narrow one can change beyond recognition. Again, turn to the picture above. If you accept that the black graph is the originalSince red is a test one, you can immediately see what problems this can lead to. It has been observed in practice that gradient descent with large batch systematically achieves slightly better results in the training set, but loses in the test set. This is often due to the fact that small batch'i make noise in the estimation of the target distribution and do not allow to settle
at a narrow minimum [21]. Approximately the same thing happens as in the picture above: the function is constantly changing (this time intentionally), and ridges are formed in the place of the troughs. Of the narrow hollows with such a "stirring"thrown out, but not wide. The authors of [21] also argue that when training with a small subsample sizeruns away much further from the initialization point than in the opposite case. Such an indicator is described by the term “research ability of the gradient descent algorithm”, and is also considered favorable for achieving good results. Alas, not so simple. We are faced with the problem mentioned above: the width of the minimum depends on the parameterization [20]. In networks with ReLu activations, it’s simple enough to build an example when two sets of weights
and represent essentially the same network, but - a narrow minimum, and - wide. A more specific example can be seen in [13], where the narrow and wide lows on the loss'a interpolation graph change places when regularization is turned on: 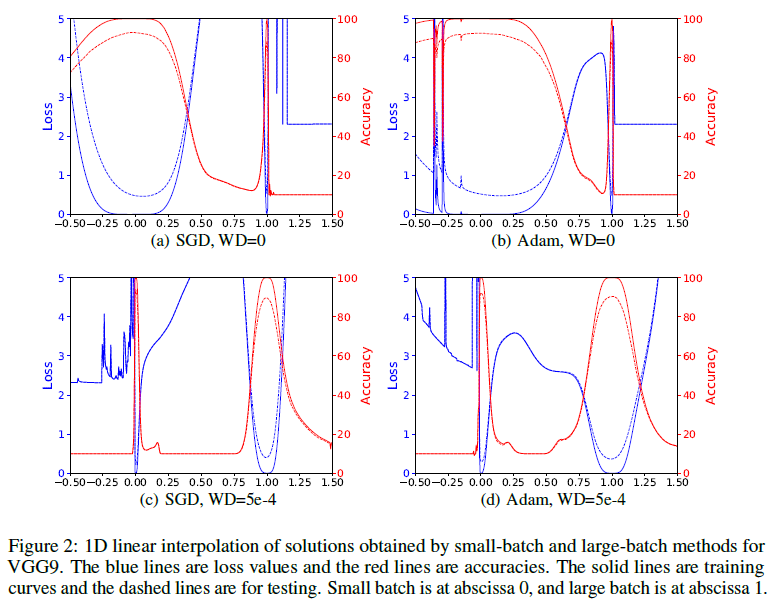
Perhaps this is due to the very modest success of the SGD modification, aimed at directing optimization to wide troughs [ 22]. Very eminent scientists demonstrate plausible histograms of the Hessians, but the increase in quality remains almost invisible.
Cross comparison
So what do we have?

The theoretical works of Chromanska [5], Kawaguchi [8] and Yun [14] are consistent with each other. Linear neural networks are a simple special case, and it is logical that instead of the inner zone of a complex landscape we get one pure global minimum (despite the fact that there is a “saddle zone” both here and there). In [14], much stronger conditions are set for the input function.
The connection between theory and practice:
- Chromanska's claims about the complex landscape in the subspace of minima are consistent with the work on building low-energy curves between minima [17] [18] [19], which, in turn, are consistent with the empirical success of snapshot ensembles [24]. In [19] it was theorized that the abundance of “holes” between the minima is a consequence of excessive network parameterization, and a large number of weights is the main premise in [5].
- Утверждение Chromanska о «слоях» в пространстве весов напрямую подтверждаются гистограммами собственных значений гессианов, в особенности, графиками из [3]: почти прямые линии демонстрируют сильную связь между количеством направлений побега и loss'ом.
- Из теоретических работ напрямую следует поведение полученное в [23], а именно характерное «отскакивание» от стенок ложбины.
- Утверждения о примерной равноценности минимумов согласуются с практическими результатами (сильно ли разнятся loss'ы среди первых десяти мест в типичном каггельном соревновании?), но косвенно антикоррелируют с анализом, какие фичи выучиваются в разные прогоны обучения[25]. Пока неясно, как всё это соотносится с проблемой узких/широких минимумов.
- [12] и [11], которые согласуются с [8] и [14], сами по себе хорошо соотносятся с опытом применения residual learning на практике, а также подтверждаются визуализациями в [13].
- Все вышеперечисленные утверждения совпадают с общими наблюдениями, что даже обычный SGD без накопления импульса стабильно даёт результат не сильно хуже, чем Adam и другие адаптивные алгоритмы градиентного спуска[26][27]. Если бы на пути у SGD встречалось много ловушек, мы бы наблюдали совсем другую картину. Также, если вы запустите обучение сети 100 раз, то скорее всего получите 100 сетей которые выдают примерно одинаковые показатели на валидационной выборке. У вас почти наверняка не будет резких скачков вниз или вверх, что соответствовало бы найденному плохому или, наоборот, слишком хорошему минимуму.
- Во многих работах уточняется, что хоть теоретический анализ полагается на избыточное количество весов, для работы нейросети большая их часть не нужна. «Лишние» веса выполняют другие функции: во-первых, они «берут на себя» полезные сигналы, позволяя перестраиваться нейронам, которые уже несут положительную нагрузку[19], во-вторых, благодаря им в ландшафте целевой функции образуются хорошие пути спуска[32] (сравните с графиками для вариационной оптимизации в [31]), а в-третьих, благодаря им при инициализации сеть с большей вероятностью окажется в области весов, откуда оптимизация вообще начнётся[33]. Утверждение об избыточности параметризации хорошо коррелирует с успехом работ по сжатию сетей (optimal brain damage, и прочее).
In my opinion, the statement remains unproven that you should not look for a global minimum, because it will have the same generalizing ability as the local minima scattered around it. Empirical experience suggests that networks obtained by different starts of the same minimizer make mistakes on different elements (see dissonance graphs, for example, in [16] or in any work devoted to network ensemble). The analysis of learned features says the same thing. In [25], the point is advocated that most of the most useful features are stably learned, but some of the auxiliary ones are not. Should all rare filters be combined, should it be better? Again, recall the ensembles consisting of different versions of the same model [24] and the redundancy of weights in the neural network [28]. It inspires confidence that somehow it’s possible to take the best from every launch of the model and to greatly improve the predictions without changing the model itself. If the terrain in a bunch of minima is really impenetrably impassable for gradient descent, it seems to me that upon reaching it you can try switching from SGD to evolutionary strategies [31] or something similar.
However, these are also just unproven thoughts. Perhaps, indeed, you should not look for a black cat in a black million-dimensional hyperspace if it is not there; it's stupid to fight for the fifth decimal places in the loss. A clear understanding of this would give the scientific community an impetus to concentrate on new network architectures. ResNet is good, why can't you come up with something else? Also, do not forget about the pre- and post-processing of data. If possible, convert
in order to “bare” the underlying fold of the distribution, then do not neglect it. In general, it is worth recalling once again that “find the global minimum of the loss function”
 "Get a well-functioning network at the output." In pursuit of a global minimum, it is very simple to retrain the network to a state of complete disability [35].
"Get a well-functioning network at the output." In pursuit of a global minimum, it is very simple to retrain the network to a state of complete disability [35]. Where, in my opinion, should the scientific community move on?
- We need to try new modified methods of gradient descent, which are well able to cross the terrain with saddle points. Preferably, first-order methods, with a Hessian, any fool can. There are already works on this subject with pretty looking grafts [29] [30], but there are still many low-hanging fruits in this area of research.
- I would like to know more about the subspace of lows. What are its properties? Is it possible, having received a sufficient number of local minima, to estimate where the global, or at least better local, will be located?
- Theoretical studies are concentrated mainly on L2-loss'e. It would be interesting to see how cross-entropy affects the landscape.
- The situation with wide / narrow lows is unclear.
- The question remains about the quality of the global minimum.
If there are students among readers who will soon defend a diploma in machine learning, I would advise them to try the first task. If you know which way to look, it’s much easier to come up with something healthy. It is also interesting to try to replicate the work of LeCun [34], varying the input data.
That's all for now. Follow the events in the scientific world.
Thanks to asobolev from the Open Data Science community for the productive discussion.
List of references
[1] Blum, A. L. and Rivest, R. L.; Training a 3-node neural network is np-complete; 1992.
[2] Saxe, McClelland & Ganguli; Exact solutions to the nonlinear dynamics of learning in deep linear neural networks; 19 Feb 2014. (305 цитат на Google Scholar)
[3] Yann N. Dauphin et al; Identifying and attacking the saddle point problem in high-dimensional non-convex optimization; 10 Jun 2014 (372 циатат на Google Scholar, обратите внимание на эту статью)
[4] Alan J. Bray and David S. Dean; The statistics of critical points of Gaussian fields on large-dimensional spaces; 2007
[5] Anna Choromanska et al; The Loss Surfaces of Multilayer Networks; 21 Jan 2015 (317 цитат на Google Scholar, обратите внимание на эту статью)
[6] Anna Choromanska et al; Open Problem: The landscape of the loss surfaces of multilayer networks; 2015
[7] Grzegorz Swirszcz, Wojciech Marian Czarnecki & Razvan Pascanu; Local Minima in Training of Neural Networks; 17 Feb 2017
[8] Kenji Kawaguchi; Deep Learning without Poor Local Minima; 27 Dec 2016. (70 цитат на Research Gate, обратите внимание на эту статью)
[9] Baldi, Pierre, & Hornik, Kurt; Neural networks and principal component analysis: Learning from examples without local minima; 1989.
[9] Haihao Lu & Kenji Kawaguchi; Depth Creates No Bad Local Minima; 24 May 2017.
[11] Moritz Hardt and Tengyu Ma; Identity matters in deep learning; 11 Dec 2016.
[12] A. Emin Orhan, Xaq Pitkow; Skip Connections Eliminate Singularities; 4 Mar 2018
[13] Hao Li, Zheng Xu, Gavin Taylor, Christoph Studer, Tom Goldstein; Visualizing the Loss Landscape of Neural Nets; 5 Mar 2018 (обратите внимание на эту статью)
[14] Chulhee Yun, Suvrit Sra & Ali Jadbabaie; Global Optimality Conditions for Deep Neural Networks; 1 Feb 2018 (обратите внимание на эту статью)
[15] Kkat; Fallout: Equestria; 25 Jan, 2012
[16] Daniel Jiwoong Im, Michael Tao and Kristin Branson; An Empirical Analysis of Deep Network Loss Surhaces.
[17] C. Daniel Freeman; Topology and Geometry of Half-Rectified Network Optimization; 1 Jun 2017.
[18] Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry Vetrov, Andrew Gordon Wilson; Loss Surfaces, Mode Connectivity, and Fast Ensembling of DNNs; 1 Mar 2018
[19] Felix Draxler, Kambis Veschgini, Manfred Salmhofer, Fred A. Hamprecht; Essentially No Barriers in Neural Network Energy Landscape; 2 Mar 2018 (обратите внимание на эту статью)
[20] Laurent Dinh, Razvan Pascanu, Samy Bengio, Yoshua Bengio; Sharp Minima Can Generalize For Deep Nets; 15 May 2017
[21] Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy and Ping Tak Peter Tang; On Large-batch Training for Deep Learning: Generalization Gap and Sharp Minima; 9 Feb 2017
[22] Pratik Chaudhari, Anna Choromanska, Stefano Soatto, Yann LeCun, Carlo Baldassi, Christian Borgs, Jennifer Chayes, Levent Sagun, Riccardo Zecchina; Entropy-SGD: Biasing Gradient Descent into Wide Valleys; 21 Apr 2017
[23] Chen Xing, Devansh Arpit, Christos Tsirigotis, Yoshua Bengio; A Walk with SGD; 7 Mar 2018
[24] habrahabr.ru/post/332534
[25] Yixuan Li, Jason Yosinski, Jeff Clune, Hod Lipson, & John Hopcroft; Convergent Learning: Do Different Neural Networks Learn the Same Representations? 28 Feb 2016 (обратите внимание на эту статью)
[26] Ashia C. Wilson, Rebecca Roelofs, Mitchell Stern, Nathan Srebro and Benjamin Recht; The Marginal Value of Adaptive Gradient Methods in Machine Learning
[27] shaoanlu.wordpress.com/2017/05/29/sgd-all-which-one-is-the-best-optimizer-dogs-vs-cats-toy-experiment
[28] Misha Denil, Babak Shakibi, Laurent Dinh, Marc'Aurelio Ranzato, Nando de Freitas; Predicting Parameters in Deep Learning; 27 Oct 2014
[29] Armen Aghajanyan; Charged Point Normalization: An Efficient Solution to the Saddle Point Problem; 29 Sep 2016.
[30] Haiping Huang, Taro Toyoizumi; Reinforced stochastic gradient descent for deep neural network learning; 22 Nov 2017.
[31] habrahabr.ru/post/350136
[32] Quynh Nguyen, Matthias Hein; The Loss Surface of Deep and Wide Neural Networks; 12 Jun 2017
[33] Itay Safran, Ohad Shamir; On the Quality of the Initial Basin in Overspecified Neural Networks; 14 Jun 2016
[34] Levent Sagun, Leon Bottou, Yann LeCun; Eigenvalues of the Hessian in Deep Learning: Singularity and Beyond; 5 Oct 2017
[35] www.argmin.net/2016/04/18/bottoming-out
[2] Saxe, McClelland & Ganguli; Exact solutions to the nonlinear dynamics of learning in deep linear neural networks; 19 Feb 2014. (305 цитат на Google Scholar)
[3] Yann N. Dauphin et al; Identifying and attacking the saddle point problem in high-dimensional non-convex optimization; 10 Jun 2014 (372 циатат на Google Scholar, обратите внимание на эту статью)
[4] Alan J. Bray and David S. Dean; The statistics of critical points of Gaussian fields on large-dimensional spaces; 2007
[5] Anna Choromanska et al; The Loss Surfaces of Multilayer Networks; 21 Jan 2015 (317 цитат на Google Scholar, обратите внимание на эту статью)
[6] Anna Choromanska et al; Open Problem: The landscape of the loss surfaces of multilayer networks; 2015
[7] Grzegorz Swirszcz, Wojciech Marian Czarnecki & Razvan Pascanu; Local Minima in Training of Neural Networks; 17 Feb 2017
[8] Kenji Kawaguchi; Deep Learning without Poor Local Minima; 27 Dec 2016. (70 цитат на Research Gate, обратите внимание на эту статью)
[9] Baldi, Pierre, & Hornik, Kurt; Neural networks and principal component analysis: Learning from examples without local minima; 1989.
[9] Haihao Lu & Kenji Kawaguchi; Depth Creates No Bad Local Minima; 24 May 2017.
[11] Moritz Hardt and Tengyu Ma; Identity matters in deep learning; 11 Dec 2016.
[12] A. Emin Orhan, Xaq Pitkow; Skip Connections Eliminate Singularities; 4 Mar 2018
[13] Hao Li, Zheng Xu, Gavin Taylor, Christoph Studer, Tom Goldstein; Visualizing the Loss Landscape of Neural Nets; 5 Mar 2018 (обратите внимание на эту статью)
[14] Chulhee Yun, Suvrit Sra & Ali Jadbabaie; Global Optimality Conditions for Deep Neural Networks; 1 Feb 2018 (обратите внимание на эту статью)
[15] Kkat; Fallout: Equestria; 25 Jan, 2012
[16] Daniel Jiwoong Im, Michael Tao and Kristin Branson; An Empirical Analysis of Deep Network Loss Surhaces.
[17] C. Daniel Freeman; Topology and Geometry of Half-Rectified Network Optimization; 1 Jun 2017.
[18] Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry Vetrov, Andrew Gordon Wilson; Loss Surfaces, Mode Connectivity, and Fast Ensembling of DNNs; 1 Mar 2018
[19] Felix Draxler, Kambis Veschgini, Manfred Salmhofer, Fred A. Hamprecht; Essentially No Barriers in Neural Network Energy Landscape; 2 Mar 2018 (обратите внимание на эту статью)
[20] Laurent Dinh, Razvan Pascanu, Samy Bengio, Yoshua Bengio; Sharp Minima Can Generalize For Deep Nets; 15 May 2017
[21] Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy and Ping Tak Peter Tang; On Large-batch Training for Deep Learning: Generalization Gap and Sharp Minima; 9 Feb 2017
[22] Pratik Chaudhari, Anna Choromanska, Stefano Soatto, Yann LeCun, Carlo Baldassi, Christian Borgs, Jennifer Chayes, Levent Sagun, Riccardo Zecchina; Entropy-SGD: Biasing Gradient Descent into Wide Valleys; 21 Apr 2017
[23] Chen Xing, Devansh Arpit, Christos Tsirigotis, Yoshua Bengio; A Walk with SGD; 7 Mar 2018
[24] habrahabr.ru/post/332534
[25] Yixuan Li, Jason Yosinski, Jeff Clune, Hod Lipson, & John Hopcroft; Convergent Learning: Do Different Neural Networks Learn the Same Representations? 28 Feb 2016 (обратите внимание на эту статью)
[26] Ashia C. Wilson, Rebecca Roelofs, Mitchell Stern, Nathan Srebro and Benjamin Recht; The Marginal Value of Adaptive Gradient Methods in Machine Learning
[27] shaoanlu.wordpress.com/2017/05/29/sgd-all-which-one-is-the-best-optimizer-dogs-vs-cats-toy-experiment
[28] Misha Denil, Babak Shakibi, Laurent Dinh, Marc'Aurelio Ranzato, Nando de Freitas; Predicting Parameters in Deep Learning; 27 Oct 2014
[29] Armen Aghajanyan; Charged Point Normalization: An Efficient Solution to the Saddle Point Problem; 29 Sep 2016.
[30] Haiping Huang, Taro Toyoizumi; Reinforced stochastic gradient descent for deep neural network learning; 22 Nov 2017.
[31] habrahabr.ru/post/350136
[32] Quynh Nguyen, Matthias Hein; The Loss Surface of Deep and Wide Neural Networks; 12 Jun 2017
[33] Itay Safran, Ohad Shamir; On the Quality of the Initial Basin in Overspecified Neural Networks; 14 Jun 2016
[34] Levent Sagun, Leon Bottou, Yann LeCun; Eigenvalues of the Hessian in Deep Learning: Singularity and Beyond; 5 Oct 2017
[35] www.argmin.net/2016/04/18/bottoming-out