JavaScript compiler using ANTLR

Earlier this year, I joined the team working on MongoDB Compass , a GUI for MongoDB. Compass users through Intercom have requested a tool that allows you to write database queries using any programming language convenient for them, supported by the MongoDB driver . That is, we needed the ability to transform (compile) the Mongo Shell language into other languages and vice versa.
This article can be both a practical guide that helps when writing a compiler in JavaScript, and a theoretical resource that includes basic concepts and principles for creating compilers. At the end is not only a complete list of all the materials used in writing, but also links to additional literature aimed at a deeper study of the issue. The information in the article is submitted sequentially, starting with the study of the subject area and then gradually complicating the functionality of the application being developed as an example. If during reading it seems to you that you are not catching the transition from one step to another, you can refer to the full version of this program and perhaps this will help to eliminate the gap.
Content
- Terminology
- Study
- Compiler creation
- Install ANTLR
- Creating a project on Node.js using ANTLR
- Source code analysis and syntax tree building
- Code generation
- Error processing
- Conclusion
Terminology
The Compiler converts a source program in a high-level programming language into an equivalent program in another language, which can be executed without the participation of the compiler.
Lexer (Lexer) - compiler element that performs lexical analysis.
Lexical analysis (Tokenizing) - The process of analytic analysis of the input sequence of characters into recognized groups (tokens, tokens).
Parser (Parser) - compiler element, parses, which results in a parse tree.
Parsing (Parsing) - Process linear sequence matching tokens natural or formal language with its formal grammar.
Token or Token(Lexeme or Token) - A sequence of valid characters in a programming language that makes sense to the compiler.
Visitor (Visitor) - working with wood pattern, wherein the descendants to continue processing them must manually cause traversal methods.
Listener (Listener or Walker) - The pattern of working with wood when the methods to visit all the children are called automatically. The Listener has a method called at the start of a node visit (enterNode) and a method called after a node visit (exitNode).
Parse tree or parse tree (Parse Tree) - structure, which is a result of the syntactic analyzer. It reflects the syntax of the constructions of the input language and clearly contains the complete interconnection of operations.
Abstract Syntax Tree (AST - Abstract Syntax Tree) differs from the parse tree in that it lacks nodes and edges for those syntax rules that do not affect the semantics of the program.
Universal Abstract Syntax Tree (UAST) is a normalized form of AST with language-independent annotations. Depth-first search
tree traversal (DFS) - One of the graph traversal methods. The depth search strategy, as the name implies, is to go “deeper” into the graph as far as possible.
Grammar (Grammar) - A set of instructions for building lexical and syntactic analyzers.
Root node(Root) - The topmost node of the tree from which the traversal begins. This is the only tree node that does not have an ancestor, but is itself an ancestor for all other tree nodes.
Leaf, leaf or terminal node (Leaf) - A node that does not have descendants.
Parent - A node that has a child. Each tree node has zero or more descendant nodes.
A literal (Literal) - Introduction of a fixed value or data type.
The code generator receives an intermediate representation of the source program as input and transforms it into the target language.
Study
There are three ways to solve the problem of transforming one programming language into another (Source-to-source transformation):
- Use existing parsers for specific programming languages.
- Create your own parser.
- Use a tool or library to generate parsers.
The first option is good, but it covers only the most famous and supported languages. For JavaScript, there are such parsers as Esprima , Falafel , UglifyJS , Jison and others. Before you write something yourself, it is worth exploring the existing tools, perhaps they completely cover the functionality you need.
If you are not lucky and you have not found a parser for your language or the parser found does not satisfy all your needs, you can resort to the second option and write it yourself.
A good start for understanding how to write a compiler from scratch could be Super Tiny Compiler. If you remove the comments from the file, then there will be only 200 lines of code that contain all the basic principles of the modern compiler.
The author of the article Implementing a Simple Compiler on 25 Lines of JavaScript shares his experience in creating a JavaScript compiler. And it covers concepts such as lexical analysis, parsing and code generation.
How to write a simple interpreter in JavaScript is another resource that explores the process of creating an interpreter using a simple calculator as an example.
Writing a compiler from scratch is a time-consuming process that requires a thorough preliminary study of the syntactic features of compiled languages. In this case, it is necessary to recognize not only keywords, but also their position relative to each other. The rules for analyzing the source code should be unambiguous and give an identical result at the output, under the same initial conditions.
Tools and libraries for generating parsers can help with this. They take the raw source code, break it into tokens (lexical analysis), then map the linear sequences of tokens to their formal grammar (parsing) and put them in a tree-like organized structure, according to which new code can be built. Some of them are covered in the article Parsing in JavaScript: Tools and Libraries.

At first glance, it might seem that we have a solution to the problem in our pocket, however, in order to teach the parser to recognize the source code, we will have to spend many more man-hours writing instructions (grammars). And in the event that the compiler must support several programming languages, this task is noticeably more complicated.
It is clear that we are not the first developers to face this challenge. The work of any IDE is associated with code analysis, Babel transforms modern JavaScript into a standard supported by all browsers. This means that there must be grammars that we could reuse and thereby not only ease our task, but also avoid a number of potentially serious errors and inaccuracies.
Thus, our choice fell on ANTLR, which best suits our requirements, as it contains grammars for almost all programming languages.
An alternative is Babelfish , which parses any file in any supported language, extracts an AST from it, and converts it to UAST, in which the nodes are not bound to the syntax of the source language. At the input, we can have JavaScript or C #, but at the UAST level we will not see any differences. In compiler terminology, the transformation process is responsible for the process of casting AST to a universal type.

A beginner compiler may also be interested in Astexplorer, an interface that allows you to see what the syntax tree can be for a given code fragment and parser corresponding to the selected language. It can be useful for debugging or for forming a general idea of the structure of AST.
Compiler creation
ANTLR (Another Tool For Language Recognition - another tool for recognizing languages) is a parser generator written in Java. He receives a piece of text as an input, then analyzes it based on grammars and converts it into an organized structure, which in turn can be used to create an abstract syntax tree. ANTLR 3 also took on this task - generated by AST. However, ANTLR 4 excluded this functionality in favor of using StringTemplates and only operates with such a concept as a Parse Tree.
For more information, you can refer to the documentation , or read the excellent article The ANTLR Mega Tutorial, which explains what a parser is, why it is needed, how to configure ANTLR, useful ANTLR functions and much more with a ton of examples.
You can read more about creating grammars here:
To transform one programming language into another, we decided to use ANTLR 4 and one of its grammars, namely ECMAScript.g4. We chose JavaScript because its syntax corresponds to the Mongo Shell language and is also the development language of the Compass application. An interesting fact: we can build a parse tree using Lexer and Parser C #, but bypass it through the nodes of the ECMAScript grammar.
This question requires a more detailed study. With full confidence, we can say that not every code structure will be correctly recognized by default. It will be necessary to expand the bypass functionality with new methods and checks. However, it is already obvious that ANTLR is an excellent tool when it comes to supporting multiple parsers within the same application.
ANTLR creates for us a list of support files for working with trees. The contents of these files are directly dependent on the rules specified in the grammar. Therefore, with any grammar changes, these files must be regenerated. This means that we should not use them directly for writing code, otherwise we will lose our changes at the next iteration. We must create our classes and inherit them from classes produced by ANTLR.
The code generated as a result of ANTLR helps in creating the parse tree, which in turn is the fundamental means of generating new code. The bottom line is to call the child nodes from left to right (provided that this is the order of the source text) to return the formatted text that they represent.
If the node is a literal, we need to return its actual value. This is harder than it sounds if you want the result to be accurate. In this case, you should provide the ability to output floating-point numbers without loss of accuracy, as well as numbers in various number systems. For string literals, it’s worth considering what type of quotation marks you support, and also not to forget about escape sequences of characters that need to be escaped. Do you support code comments? Do you want to keep the user input format (spaces, blank lines), or do you want to bring the text to a more standard, easier to read form. On the one hand, the second option will look more professional, on the other hand, the user of your compiler may not be satisfied as a result, since he probably wants to get output identical to its input format. There is no universal solution for these problems, and they require a more detailed study of the scope of your compiler.
We will consider a more simplified example to concentrate on the basics of writing a compiler using ANTLR.
Install ANTLR
$ brew cask install java
$ cd /usr/local/lib
$ curl -O http://www.antlr.org/download/antlr-4.7.1-complete.jar
$ export CLASSPATH=".:/usr/local/lib/antlr-4.7.1-complete.jar:$CLASSPATH"
$ alias antlr4='java -Xmx500M -cp "/usr/local/lib/antlr-4.7.1-complete.jar:$CLASSPATH" org.antlr.v4.Tool'
$ alias grun='java org.antlr.v4.gui.TestRig'
To make sure that all your installations are successful, type in the terminal:
$ java org.antlr.v4.ToolYou should see information about the ANTLR version, as well as help with the commands.

Creating a project on Node.js using ANTLR
$ mkdir js-runtime
$ cd js-runtime
$ npm init
Install JavaScript runtime , for this we need the npm package antlr4 - JavaScript target for ANTLR 4 .
$ npm i antlr4 --saveDownload the ECMAScript.g4 grammar, which we later feed to our ANTLR.
$ mkdir grammars
$ curl --http1.1 https://github.com/antlr/grammars-v4/blob/master/ecmascript/ECMAScript.g4 --output grammars/ECMAScript.g4
By the way, on the ANTLR website in the Development Tools section you can find links to plugins for such IDEs as Intellij, NetBeans, Eclipse, Visual Studio Code, and jEdit. Color themes, semantic error checking, visualization using diagrams make writing and testing grammars easier.
Finally, run ANTLR.
$ java -Xmx500M -cp '/usr/local/lib/antlr-4.7.1-complete.jar:$CLASSPATH' org.antlr.v4.Tool -Dlanguage=JavaScript -lib grammars -o lib -visitor -Xexact-output-dir grammars/ECMAScript.g4
Add this script to package.json to always have access to it. For any change to the grammar file, we need to restart ANTLR to apply the changes.
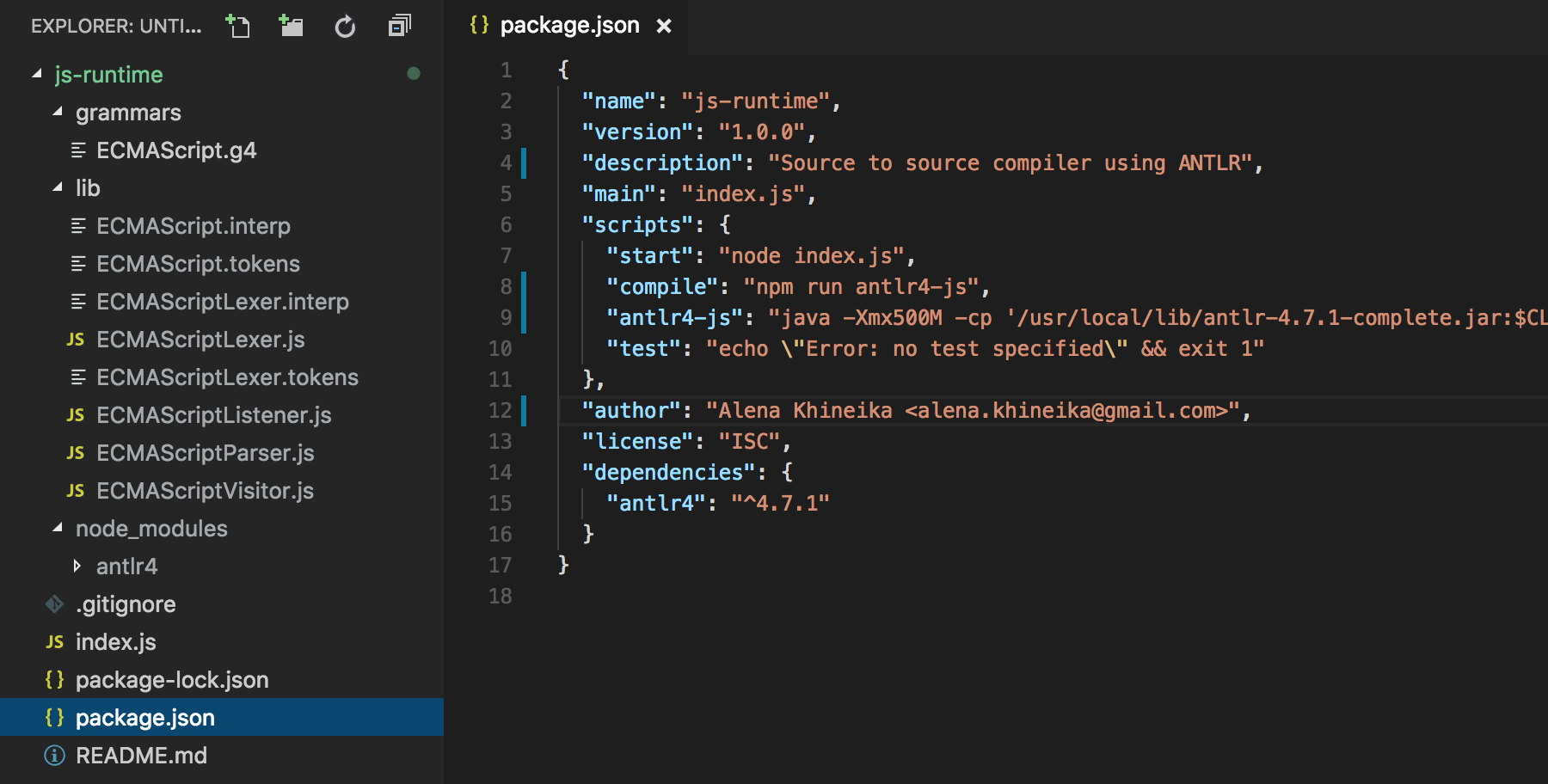
We go to the lib folder and see that ANTLR has created a list of files for us. Let's dwell on three of them in more detail:
- ECMAScriptLexer.js splits the source code character stream into a token stream in accordance with the rules specified in the grammar.
- ECMAScriptParser.js builds an abstract, connected, tree-like structure called a parse tree from the token stream.
- ECMAScriptVisitor.js is responsible for traversing the constructed tree. Theoretically, we could independently process this tree using recursive traversal of descendants in depth. However, with a large number of node types and the complex logic of their processing, it is better to visit each node type with its unique method, as a visitor does.
Note that by default ANTLR does not create * Visitor.js. The standard way to traverse trees in ANTLR is Listener. If you want to generate and then use Visitor instead of Listener, you need to explicitly indicate this using the flag '
-visitor', as we did in our script:$ java -Xmx500M -cp '/usr/local/lib/antlr-4.7.1-complete.jar:$CLASSPATH' org.antlr.v4.Tool -Dlanguage=JavaScript -lib grammars -o lib -visitor -Xexact-output-dir grammars/ECMAScript.g4
The essence of the work of both methods, however, as well as the result, is very similar, however with Visitor your code looks cleaner and you have more control over the transformation process. You can set in what order to visit the nodes of the tree and whether to visit them at all. You can also modify existing sites during a crawl and you do not need to store information about visited sites. The article Antlr4 - Visitor vs Listener Pattern discussed this topic in more detail and with examples.
Source code analysis and syntax tree building
Let's finally get started with programming. You will find an example of similar code literally everywhere if you search by the combination of ANTLR and JavaScript.
const antlr4 = require('antlr4');
const ECMAScriptLexer = require('./lib/ECMAScriptLexer.js');
const ECMAScriptParser = require('./lib/ECMAScriptParser.js');
const input = '{x: 1}';
const chars = new antlr4.InputStream(input);
const lexer = new ECMAScriptLexer.ECMAScriptLexer(chars);
lexer.strictMode = false; // не использовать JavaScript strictMode
const tokens = new antlr4.CommonTokenStream(lexer);
const parser = new ECMAScriptParser.ECMAScriptParser(tokens);
const tree = parser.program();
console.log(tree.toStringTree(parser.ruleNames));
What we have done now: using the lexer and parser that ANTLR generated for us, we brought our source line to the tree view in LISP format (this is the standard tree output format in ANTLR 4). According to the grammar, the root node of the ECMAScript tree is the rule `
program`, so we chose it as the starting point of the traversal in our example. However, this does not mean that this node should always be the first. For the original line, ` {x: 1}` it would be perfectly fair to start a crawl with ' expressionSequence'.const tree = parser.expressionSequence();
If you remove the formatting,,,
.toStringTree()you can see the internal structure of the tree object. Conventionally, the entire process of transforming one programming language into another can be divided into three stages:
- Source code analysis.
- Building a syntax tree.
- Generate new code.
As we can see, thanks to ANTLR, we greatly simplified our work and covered several steps in a few lines of code. Of course, we will return to them, update grammars, transform the tree, but nevertheless a good foundation has already been laid. Grammars that are downloaded from the repository can also be inferior or even with errors. But, perhaps, they already corrected those mistakes that you would have only made if you started writing grammar from scratch yourself. The point is this, you should not blindly trust the code written by other developers, but you can save time writing identical rules to improve existing ones. Perhaps the next generation of young ANTLRs are already downloading your more ideal version of grammar.
Code generation
Create a new directory in the project,
codegenerationand in it a new PythonGenerator.js file.$ mkdir codegeneration
$ cd codegeneration
$ touch PythonGenerator.js
As you may have guessed, as an example, we are transforming something from JavaScript to Python.
The generated ECMAScriptVisitor.js file contains a huge list of methods, each of which is automatically called during a tree walk if the corresponding node is visited. And just at that moment we can change the current node. To do this, create a class that will inherit from ECMAScriptVisitor and override the methods we need.
const ECMAScriptVisitor = require('../lib/ECMAScriptVisitor').ECMAScriptVisitor;
/**
* Visitor проходит по дереву, сгенерированному ANTLR
* с целью трансформировать JavaScript код в Python код
*
* @returns {object}
*/
class Visitor extends ECMAScriptVisitor {
/**
* Начальная точка обхода дерева
*
* @param {object} ctx
* @returns {string}
*/
start(ctx) {
return this.visitExpressionSequence(ctx);
}
}
module.exports = Visitor;
In addition to methods that comply with the syntax rules of grammar, ANTLR also supports four special public methods :
- visit () is responsible for traversing the tree.
- visitChildren () is responsible for traversing nodes.
- visitTerminal () is responsible for bypassing tokens.
- visitErrorNode () is responsible for bypassing invalid tokens.
We implement the methods `
visitChildren()`, ' visitTerminal()' and ` visitPropertyExpressionAssignment()` in our class ./*
* Посещает потомков текущего узла
*
* @param {object} ctx
* @returns {string}
*/
visitChildren(ctx) {
let code = '';
for (let i = 0; i < ctx.getChildCount(); i++) {
code += this.visit(ctx.getChild(i));
}
return code.trim();
}
/**
* Посещает лист дерева (узел без потомков) и возвращает строку
*
* @param {object} ctx
* @returns {string}
*/
visitTerminal(ctx) {
return ctx.getText();
}
/**
* Посещает узел, отвечающий за присваивание значения параметру
*
* @param {object} ctx
* @returns {string}
*/
visitPropertyExpressionAssignment(ctx) {
const key = this.visit(ctx.propertyName());
const value = this.visit(ctx.singleExpression());
return `'${key}': ${value}`;
}
The function `
visitPropertyExpressionAssignment` visits the node responsible for assigning the value to ' 1' parameter ` x`. In Python, the string parameters of an object must be enclosed in quotation marks, unlike JavaScript, where they are optional. In this case, this is the only modification that is required to transform a fragment of JavaScript code into Python code. 
Add a call to our PythonGenerator in index.js.
console.log('JavaScript input:');
console.log(input);
console.log('Python output:');
const output = new PythonGenerator().start(tree);
console.log(output);
As a result of the program execution, we see that our compiler successfully completed its task and converted the JavaScript object into a Python object.

We begin to traverse the tree from parent to descendant, gradually descending to its leaves. And then we go in the reverse order and substitute the formatted values one level higher, thus replacing the entire chain of tree nodes with their textual representation corresponding to the syntax of the new programming language.

Add some debug to our `
visitPropertyExpressionAssignment` function.// Текстовое значение узла
console.log(ctx.getText());
// Кол-во узлов потомков
console.log(ctx.getChildCount());
// console.log(ctx.propertyName().getText()) Параметр x
console.log(ctx.getChild(0).getText());
// :
console.log(ctx.getChild(1).getText());
// console.log(ctx.singleExpression().getText()) Значение 1
console.log(ctx.getChild(2).getText());
Descendants can be accessed both by name and by serial number. Descendants are also nodes, so to get their textual value, not the object representation, we used the `
.getText()` method . We complement ECMAScript.g4 and teach our compiler to recognize the key word `
Number`. 

We regenerate the visitor to pull up the changes made in the grammar.
$ npm run compileNow back to our PythonGenerator.js file and add a list of new methods to it.
/**
* Удаляет ключевое слово `new`
*
* @param {object} ctx
* @returns {string}
*/
visitNewExpression(ctx) {
return this.visit(ctx.singleExpression());
}
/**
* Посещает узел с ключевым словом `Number`
*
* @param {object} ctx
* @returns {string}
*/
visitNumberExpression(ctx) {
const argumentList = ctx.arguments().argumentList();
// JavaScript Number требует один аргумент,
// в противном случае метод возвращает сообщение об ошибке
if (argumentList === null || argumentList.getChildCount() !== 1) {
return 'Error: Number требует один аргумент';
}
const arg = argumentList.singleExpression()[0];
const number = this.removeQuotes(this.visit(arg));
return `int(${number})`;
}
/**
* Удаляет символы кавычек в начале и в конце строки
*
* @param {String} str
* @returns {String}
*/
removeQuotes(str) {
let newStr = str;
if (
(str.charAt(0) === '"' && str.charAt(str.length - 1) === '"') ||
(str.charAt(0) === '\'' && str.charAt(str.length - 1) === '\'')
) {
newStr = str.substr(1, str.length - 2);
}
return newStr;
}
Python does not use the keyword `
new` when calling the constructor, so we delete it, or rather, in the node ' visitNewExpression' we continue to traverse the tree eliminating the first child. Then we replace the keyword ` Number` by ' int', which is its equivalent in Python. Since ` Number` this expression (Expression), we have access to its arguments through the method ' .arguments()'. 
Similarly, we can go through all the methods listed in ECMAScriptVisitor.js and transform all the JavaScript literals, symbols, rules, and the like into their equivalents for Python (or any other programming language).
Error processing
ANTLR by default validates input for compliance with the syntax specified in the grammar. In the event of a discrepancy, the console will be given information about the problem that has arisen, while ANTLR will also return the string as it was able to recognize it. If you remove the colon from the source string `{x: 2}`, ANTLR replaces the unrecognized nodes with `undefined`.

We can influence this behavior and instead of the broken line print detailed error information. First, create a new module in the root of our application, which is responsible for generating custom error types.
$ mkdir error
$ cd error
$ touch helper.js
$ touch config.json
I will not dwell on the features of the implementation of this module, as this is beyond the scope of the topic about compilers. You can copy the finished version below, or write your own version that is more suitable for the infrastructure of your application.
All types of errors that you want to use in your application are indicated in config.json.
{
"syntax": {"generic": {"message": "Something went wrong"}},
"semantic": {
"argumentCountMismatch": {
"message": "Argument count mismatch"
}
}
}
Then error.js cycles through the list from the config and for each record in it creates a separate class inherited from Error.
const config = require('./config.json');
const errors = {};
Object.keys(config).forEach((group) => {
Object.keys(config[group]).forEach((definition) => {
// Имя ошибке присваивается автоматически на основании конфига
const name = [
group[0].toUpperCase(),
group.slice(1),
definition[0].toUpperCase(),
definition.slice(1),
'Error'
].join('');
const code = `E_${group.toUpperCase()}_${definition.toUpperCase()}`;
const message = config[group][definition].message;
errors[name] = class extends Error {
constructor(payload) {
super(payload);
this.code = code;
this.message = message;
if (typeof payload !== 'undefined') {
this.message = payload.message || message;
this.payload = payload;
}
Error.captureStackTrace(this, errors[name]);
}
};
});
});
module.exports = errors;
We will update the `
visitNumberExpression` method and now instead of a text message marked ` Error` we will throw an error ` SemanticArgumentCountMismatchError`, which is easier to catch and thereby begin to distinguish between the successful and problematic result of our application.const path = require('path');
const {
SemanticArgumentCountMismatchError
} = require(path.resolve('error', 'helper'));
/**
* Посещает узел с ключевым словом `Number`
*
* @param {object} ctx
* @returns {string}
*/
visitNumberExpression(ctx) {
const argumentList = ctx.arguments().argumentList();
if (argumentList === null || argumentList.getChildCount() !== 1) {
throw new SemanticArgumentCountMismatchError();
}
const arg = argumentList.singleExpression()[0];
const number = this.removeQuotes(this.visit(arg));
return `int(${number})`;
}
Now let's deal with errors that are directly related to the work of ANTLR, namely those that arise during parsing of code. In the codegeneration directory, create a new file ErrorListener.js and in it a class inherited from `antlr4.error.ErrorListener`.
const antlr4 = require('antlr4');
const path = require('path');
const {SyntaxGenericError} = require(path.resolve('error', 'helper'));
/**
* Пользовательский обработчик ошибок на стадии разбора строки
*
* @returns {object}
*/
class ErrorListener extends antlr4.error.ErrorListener {
/**
* Проверяет на синтаксические ошибки
*
* @param {object} recognizer Структура, используемая для распознавания ошибок
* @param {object} symbol Символ, вызвавший ошибку
* @param {int} line Строка с ошибкой
* @param {int} column Позиция в строке
* @param {string} message Текст ошибки
* @param {string} payload Трассировка стека
*/
syntaxError(recognizer, symbol, line, column, message, payload) {
throw new SyntaxGenericError({line, column, message});
}
}
module.exports = ErrorListener;
To override the standard error output method, we will use two methods available to the ANTLR parser:
- parser.removeErrorListeners () removes the standard ConsoleErrorListener.
- parser.addErrorListener () adds a custom ErrorListener.
This should be done after creating the parser, but before calling it. The full code for the updated index.js will look like this:
const antlr4 = require('antlr4');
const ECMAScriptLexer = require('./lib/ECMAScriptLexer.js');
const ECMAScriptParser = require('./lib/ECMAScriptParser.js');
const PythonGenerator = require('./codegeneration/PythonGenerator.js');
const ErrorListener = require('./codegeneration/ErrorListener.js');
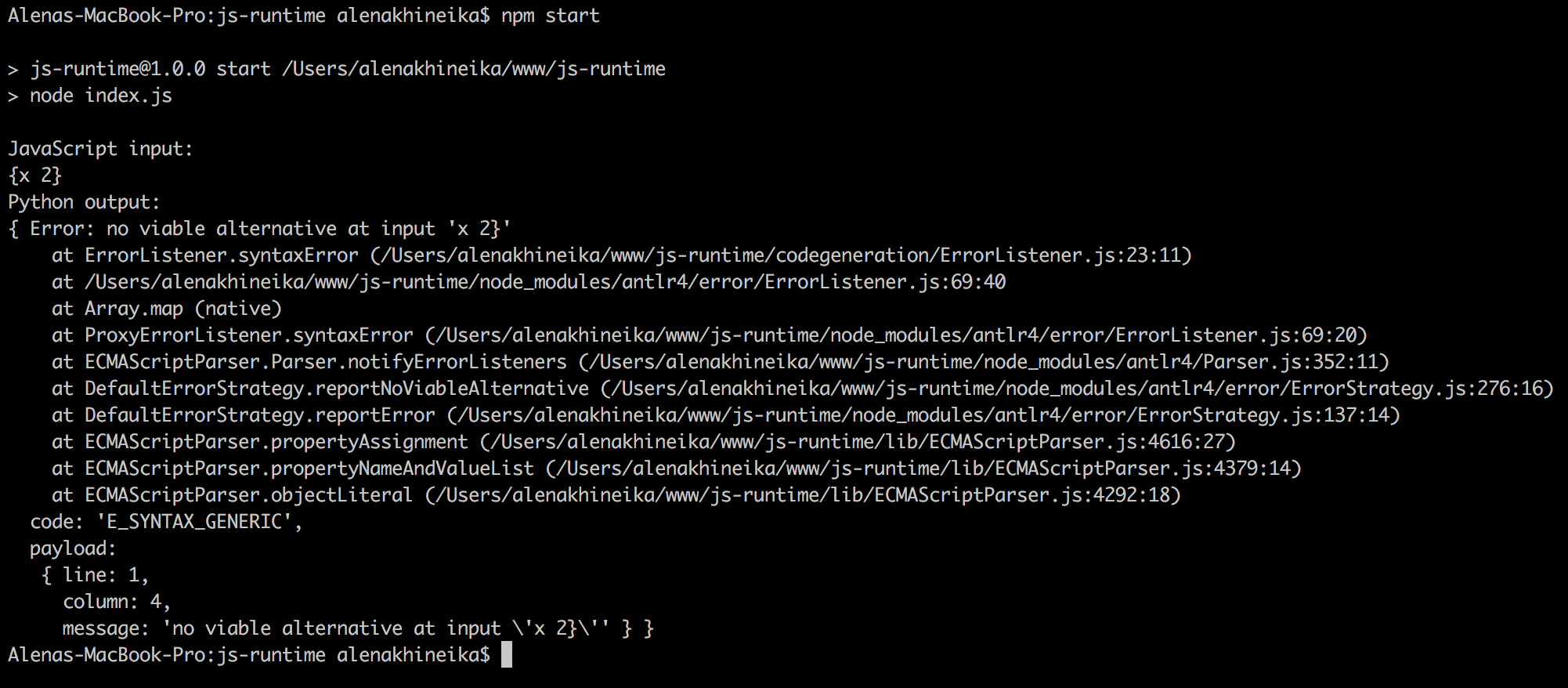
const input = '{x 2}';
const chars = new antlr4.InputStream(input);
const lexer = new ECMAScriptLexer.ECMAScriptLexer(chars);
lexer.strictMode = false; // не использовать JavaScript strictMode
const tokens = new antlr4.CommonTokenStream(lexer);
const parser = new ECMAScriptParser.ECMAScriptParser(tokens);
const listener = new ErrorListener();
parser.removeErrorListeners();
parser.addErrorListener(listener);
console.log('JavaScript input:');
console.log(input);
console.log('Python output:');
try {
const tree = parser.expressionSequence();
const output = new PythonGenerator().start(tree);
console.log(output);
// console.log(tree.toStringTree(parser.ruleNames));
} catch (error) {
console.log(error);
}
Thanks to the information that is now contained in the error object, we can decide how to correctly handle the exception that has occurred, interrupt or continue the program, start an informative log or, last but not least, write tests that support the correct and incorrect source data for the compiler.
Conclusion
If someone asks you to write a compiler, immediately agree! This is very interesting and most likely significantly different from your usual programming tasks. We considered only the simplest nodes in order to outline the idea of writing a compiler in JavaScript using ANTLR. The functionality can be expanded by validating the types of arguments passed to it, adding Extended JSON or BSON support to the grammar, using the identifier table to recognize methods such as toJSON (), toString (), getTimestamp (), and so on. In fact, the possibilities are endless.
At the time of this writing, work on the MongoDB compiler is in its infancy. It is likely that this approach to code transformation will change over time, or more optimal solutions will appear, and then I may write a new article with more relevant information.
Today I am very passionate about writing a compiler and I want to keep the knowledge gained in the process, which may be useful to someone else.
If you want to delve deeper into the topic, I can recommend the following resources for reading:
- The language of languages by Matt Might
- Compiler Construction by Niklaus Wirth
- Compilers Principles, technologies and tools of authors Alfred V. Aho, Monica S. Lam, Ravi Seti, Jeffrey D. Ullman
- Tree structures processing and unified AST by Ivan Kochurkin, Positive Technologies
- Lecture "Fundamentals of Compilers" by A. Aho, R. Seti, J. Ullman
And links to resources used in the article:
- Super Tiny Compiler by James Kyle
- Implementing a Simple Compiler on 25 Lines of JavaScript by Minko Gechev
- How to write a simple interpreter in JavaScript by Peter Olson
- Parsing in JavaScript: Tools and Libraries by Gabriele Tomassetti
- The ANTLR Mega Tutorial by Gabriele Tomassetti
- MySQL Grammar on ANTLR 4 by Ivan Khudyashov
- Processing tree structures and a unified AST by Ivan Kochurkin
- Theory and practice of source parsing using ANTLR and Roslyn by Ivan Kochurkin
- Antlr4 - Visitor vs Listener Pattern by Saumitra Srivastav
Thanks to my Compass team and, in particular, Anna Herlihy for the mentoring and contribution to writing the compiler, to the reviewers Alex Komyagin , Misha Tyulenev for recommendations on the structure of the article, and for lettering to the title illustration to Oksana Nalyvaiko .
English version of the article on Medium: Compiler in JavaScript using ANTLR