ComputerVision and what it is eaten with
 With the development of computer capacities and the advent of many image processing technologies, the question arose more and more often: is it possible to teach a machine to see and recognize images? For example, to distinguish a cat from a dog or even a bloodhound from a basset? There is no need to speak about recognition accuracy: our brain can incomparably faster understand what is in front of us, provided that we have received enough information about the object before. Those. even seeing only a part of the dog, we can say with confidence that it is a dog. And if you are a dog breeder, then you can easily determine the breed of the dog. But how to teach a car to distinguish between them? What algorithms are there? Is it possible to fool a car? (Spoiler: of course you can! Just like our brain.) Let's try to comprehend all these questions and answer them if possible. So let's get started.
With the development of computer capacities and the advent of many image processing technologies, the question arose more and more often: is it possible to teach a machine to see and recognize images? For example, to distinguish a cat from a dog or even a bloodhound from a basset? There is no need to speak about recognition accuracy: our brain can incomparably faster understand what is in front of us, provided that we have received enough information about the object before. Those. even seeing only a part of the dog, we can say with confidence that it is a dog. And if you are a dog breeder, then you can easily determine the breed of the dog. But how to teach a car to distinguish between them? What algorithms are there? Is it possible to fool a car? (Spoiler: of course you can! Just like our brain.) Let's try to comprehend all these questions and answer them if possible. So let's get started.How to teach a car to see?
Machine vision refers to Machine Learning, which includes semantic analyzers, sound recognizers, and more. This is a complex subject area, and it requires deep knowledge of mathematics (including brrrrr, tensor mathematics). There are many algorithms that are used in pattern recognition: VGG16, VGG32, VGG29, ResNet, DenseNet, Inception (V1, V2, V3, V ... there are hundreds of them!). The most popular are VGG16 and Inception V3 and V4. The simplest, most popular and most suitable for a quick start is VGG16, so we select and pick it. Let's start with the name VGG16 and find out what is sacred in it and how it is deciphered. And then K.O. suggests that everything is simple: VGG is a Visual Geometry Group from the Department of Engineering at Oxford University. Well, 16 from? Here it’s a bit more complicated and is already directly connected with the algorithm. 16 - the number of layers of the neural network, which is used for pattern recognition (at last we started an interesting one, otherwise it’s all around). And it's time to get into the very essence of matan. They themselves use from 16 to 19 layers and 3x3 filters at each level of the neural network. Actually, there are several reasons: the greatest performance is with such a number of layers, recognition accuracy (this is quite enough, links to articles,one and two ). It should be noted that the neural network is not used simple, but an improved convolutional neural network (Convolutional Neural Network (CNN) and Convolutional Neural Network with Refinement (CNN-R)).
And now we will understand the principles of operation of this very algorithm, why a convolutional neural network is needed and what parameters it works with. Well, of course, it’s better to do it right away in practice. Assistant in the studio!

This wonderful husky will become our assistant, and we will experiment with her. She already glows with happiness and wants to quickly delve into the details.
So, in simple words: a convolutional neural network works with two “commands” (I greatly exaggerate, but it will be more clear). The first - select the fragment, the second - try to find the whole object. Why the whole thing? Having a set of the smallest patterns with the contours of whole objects, it is easier for the neural networks to obtain characteristic features in the future and compare them with the image that needs to be recognized. And here the image of the algorithm in the final form will help us. Who wants to study in detail, with tons of matan - here's the pruflink . And we move on.
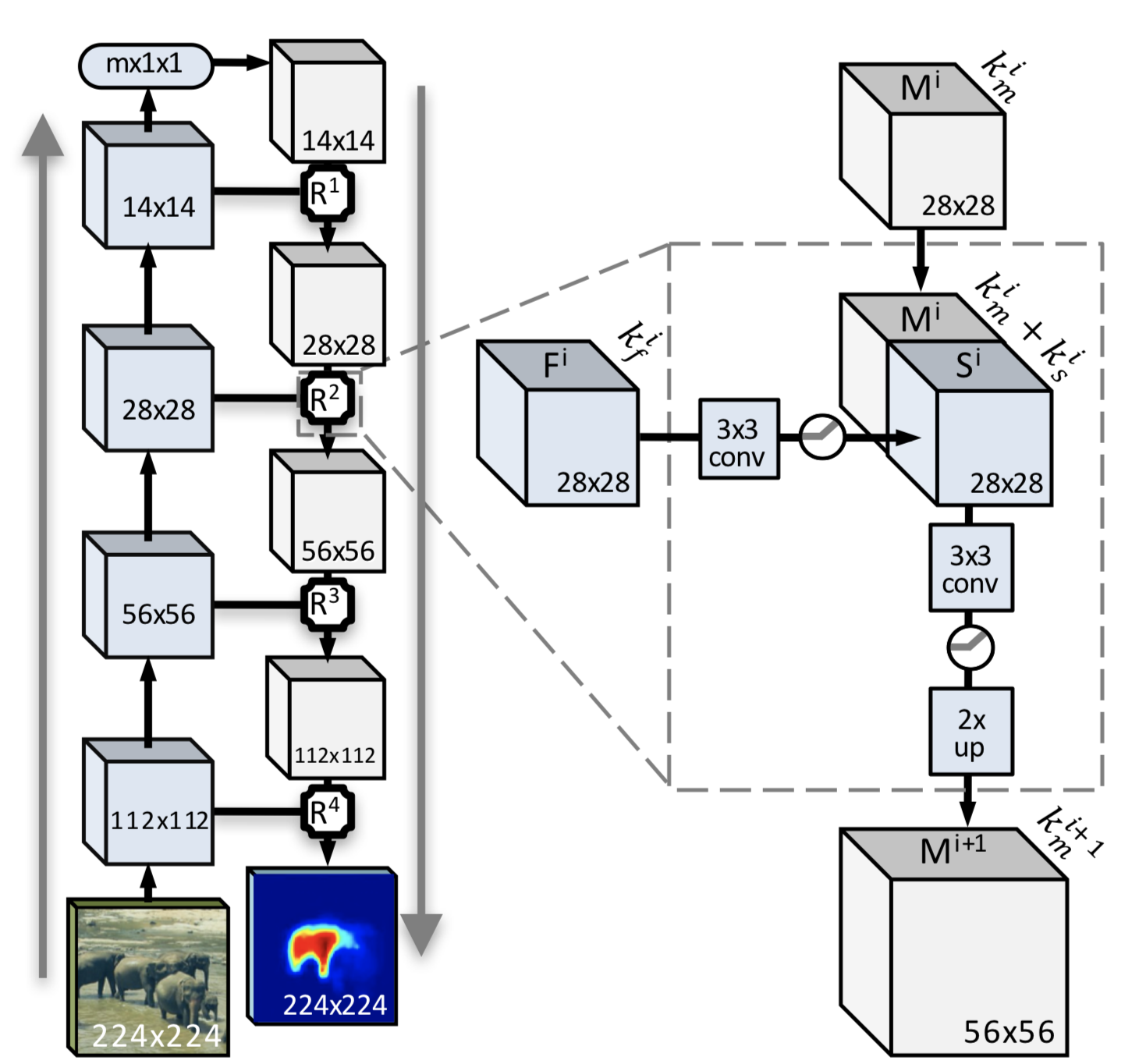
Explaining the following algorithm is not so difficult. This is a complete convolutional neural network algorithm with an improvement module (this is the one that is circled by a dotted line and is present after each convolution step).
The first step: sawing the image in half (with a husky done, but not as spectacular as with the elephants in the picture). Then in half, then more and more, and so we get to the cockroaches, in the sense of block 14x14 or less (the minimum size, as already mentioned, is 3x3). Between the steps is the main magic. Namely, obtaining the mask of the whole object and the probability of finding the whole object on the sawn piece. After all these manipulations, we get a set of pieces and a set of masks for them. What to do with them now? The answer is simple: when reducing the image, we get degradation of neighboring pixels, which will simplify the construction of the mask in a simplified form and will make it possible to increase the likelihood of distinguishing transitions between objects.
Independent source descriptions are built based on the analysis of thumbnails and then the result is averaged for all masks. But it should be noted that this option is not the best when segmenting an object. The averaged mask may not always be applicable for small color differences between objects and background (which is why such a test image was chosen).
The proposed approach is more or less workable, but for objects that are entirely on the image and contrast with the background, at the same time, separation of two identical or similar objects (we will not go far for an example: a herd of sheep, everyone has white wool) will cause significant difficulties .
To obtain an adequate pixel mask and separation of objects, you need to bring the algorithm to mind.
And now the time has come to ask: why do we need this “module-enhancer" at all, if everything seems to be all right?
We add at each step not only the construction of the mask, but also the use of all the information obtained from the low-level functions together with the knowledge about the high-level objects that are recognized in the upper layers of the neural network. Along with obtaining independent results, generation and coarse recognition are performed at each step, the result is a semantically complete functional multichannel map, into which only positive information from early layers is integrated.
What is the difference between the classic convolutional neural network and the improved convolutional neural network?
Each step of reducing the original image allows you to get an encoded mask generated when passing from the general image to the reduced one. Along with this, in the advanced convolutional neural network, there is a movement from a smaller image to a larger one with obtaining characteristic functions (points). The result is a mask obtained as a result of a bi-directional merger of functions and characteristic points.
Sounds pretty confusing. Let's try to apply to our image.

Spectacularly. This is called DeepMask - the rough borders of objects in the image. Let's try to figure out why. Let's start with the simple - with the nose. With image degradation, the contrast is obvious, so the nose is highlighted as an independent object. The same thing with the nostrils: at certain levels of the convolution, they became independent objects due to the fact that they were completely on the fragment. In addition, the face of the second dog is separately circled (how, don’t you see? Yes, here it is, right in front of you!). A piece of hand was recognized as the background. Well, what to do? It does not contrast with the main part of the background in color. But the transition "arm-shirt" is highlighted. And the error in the form of a “hand-net” spot, and a large spot, capturing the background and the husky’s head.
Well, the result is interesting! How can you help the algorithm cope with the task better? Only if you mock our assistant. First, try to make it in grayscale. Hmm ... The photo is worse than in the passport. After that, the laboratory assistant had nothing to lose, I just turned on one filter, and everything turned around ... Sepia, followed by solarization, superimposing and subtracting layers, blurring the background with the addition of images - in general, I saw it and applied it; the main thing is that objects become more visible in the image. As they say, the picture in Photoshop will endure everything. Mocked, it’s time to see how the image will now be recognized.

The neural network said: "There is no one who can be classified at least somehow." Logically, only the nose and eyes are contrasting. Not too characteristic with a small set for training.

Wow, what a horror (sorry, friend)! But here we seriously added contrast to the objects in the image. How? We take and duplicate the image (you can several times). On one we twist the contrast, on the other - brightness, on the third - burn out the colors (make them unnaturally bright) and then add it all up. And finally, let's try to stuff the long-suffering huskies into processing.

I must say that it has become better. Not direct “wow, how cool”, but better. The number of incomplete objects decreased, the contrast between objects appeared. Further experiments with pre-processing will give greater contrast: object - object, object - background. We get 4 segments instead of 8. From the point of view of processing a large stream of images (150 images per minute), it is better not to bother with pre-processing at all. She - so, play on the home computer.
Move on. SharpMask will not practically differ. And SharpMask is building a refined mask of objects. The improvement algorithm is the same.
The main problem of DeepMask is that this model uses a simple direct distribution network that successfully creates “rough” masks, but does not perform pixel segmentation. We skip the example for this step, since Husky is not so easy to live with.
The last step is an attempt to recognize what happened after clarifying the mask.

We launch the quickly assembled demo and get the result - as much as 70% that this is a dog. Not bad.
But how did the machine understand that it was a dog? So we sawed the pieces, got beautiful masks, matrices for them and sets of signs. What's next? And then everything is simple: we have a trained network that has reference sets of features, masks, etc., etc., etc. Well, they are, and then what? Here is our husky with a set of features, here is a reference spherical dog in a vacuum with a set of features. A blunt comparison cannot be done forehead, because a lack of features in the image that we recognize will lead to an error. And what to do? To do this, they came up with such a wonderful parameter as dropout, or a random reset of network parameters. This means the following: both sets are taken and signs are randomly removed from each of them (in other words, there are sets of 10 signs, dropout = 0.1; we drop them according to one sign, then compare them). And as a result? And as a result - PROFIT.
I will immediately answer the question why the second dog is not a dog, and the hand is not a man. The test sample was only 1000 images of cats and dogs. She studied in just two steps of evolution.
Instead of conclusions
So, we got a picture and the result that it was a dog (it’s obvious to us, but for the neural network it wasn’t very good). The training was carried out in just two steps and there was no evolution of the model (which is very important). The image was loaded as is, without processing. In the future, it is planned to check whether the neural network will be able to recognize dogs by the minimum set of signs.
From the pros:
- Conducted training on one machine. If necessary, files can be scattered immediately to other machines, and they (machines) will already be able to do the same.
- High accuracy of determination during training and network evolution (this is sooooo long).
- You can evolve for different recognition algorithms and “retrain” the network.
- A huge database of images COCO and VOC (updated annually).
Of the minuses: dancing with a tambourine with each framework.
PS During the experiments, no husky was harmed. About how they collected, what they collected, how many rakes, to which places and so on - in the next article of our series "Machine vision for housewives."
PPS And quite, quite summarizing: there is no silver bullet, but there is a faust cartridge that can be turned into a file. And for a quick start, the following frameworks were used:
Keras
Caffe
Tensorflow