Hyperpilot opened the source code of its products 100%
- Transfer
We have opened the source code of all our products that we have been working on over the past year, and in this post I want to briefly talk about them.
The last year Hyperpilot worked in stealth mode, so let me explain what we were going to do. Our mission is to provide intelligence to the infrastructure to increase efficiency and productivity. DevOps and system engineers are constantly faced with the need to make many decisions related to container infrastructure and processes that require manual work. These solutions include all the way from virtual machine configuration (instance type, region, etc.), container configuration (resource request, number of container instances, etc.) to application level configuration options (jvm, etc.) . Operators and developers often make static choices, and operating staff have no idea why this decision was made. Worst of all, operators are prone to overdoing, and this leads to inefficient use of infrastructure. We worked on three products that could help operators find tools for better solutions and automate recommendations in the future. Next, I'll talk about high-level products that are in the public domain.
HyperConfig: Smart Configuration Search
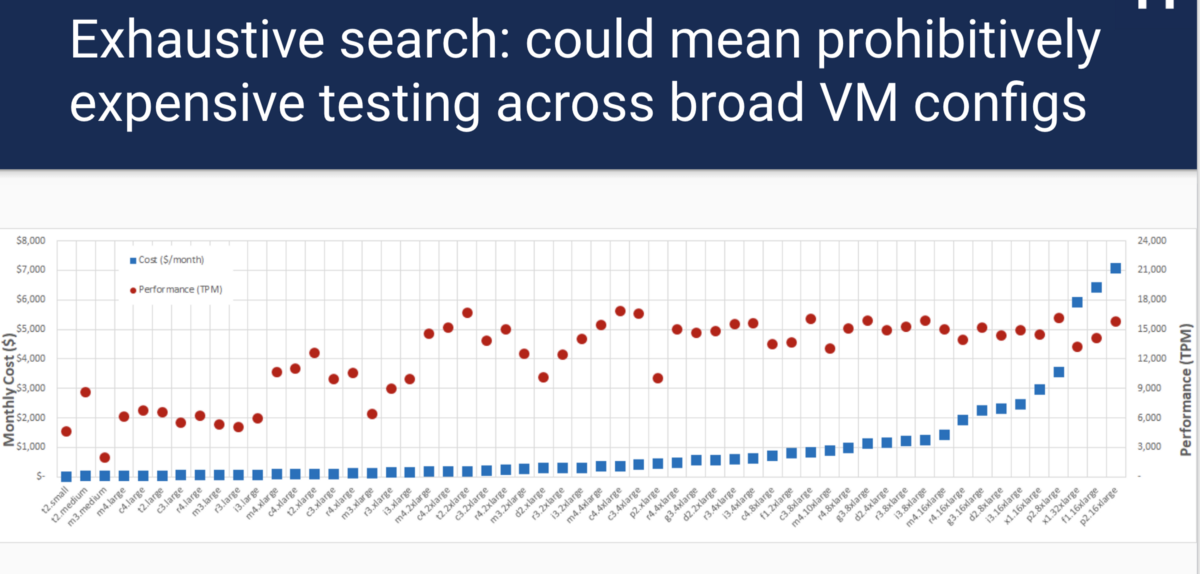
If you used the cloud, deployed docker containers using Kubernetes or Mesos, you know: one of the first problems is figuring out which configuration is best for each component. For example, what type of virtual machine instance should I use? How many nodes to deploy? How much processor time and memory is allocated to the container? All of these issues imply a trade-off between cost and performance. For example, take the size of a virtual machine. Choosing an instance of a large virtual machine will cost a lot more, but may give better performance. Choosing too small a virtual machine leads to performance and SLA problems. It’s hard to determine which solution is better: if you take the MySQL tpcc benchmark and run it on every type of AWS instance,
In addition, an exhaustive search requires a lot of time and money. Fortunately, this is not a new problem, and there are many research solutions, but there is no general open source solution that supports the general conclusion of load testing.
Inspired by the work of CherryPick , we created hyperconfig and proposed a set of AWS instance types for various criteria based on the overall result of load testing.
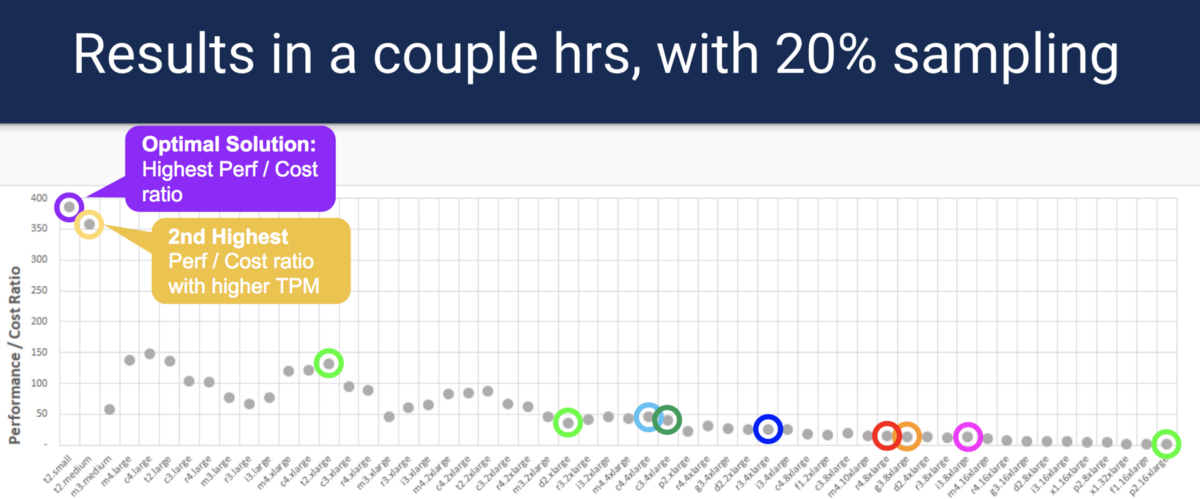
Instead of exhaustive searching for each type of instance, HyperConfig uses a well-known optimization method called Bayesian Optimization to find the best options, while having fewer sample points. Samples can be run in parallel, which reduces time and costs. Please note: HyperConfig does not guarantee the location of the most optimal option, but will select the option that is closest to the optimal one.
For more information on how to run our demo version, as well as details about the code, please refer to the sizing analyzer section .
HyperPath: Resource Problem Analysis
One of the problems that operators face is finding the cause of the performance degradation in the Kubernetes cluster. The problem can come from different sources of infrastructure. However, if you narrow down the search for the problem to the most likely places, you can develop a system that can diagnose and find the source of the performance problem. HyperPath focuses on detecting the problem areas of cpu / memory / network / IO, and also determines if the problem arises due to the limits set for the container (s) or the lack of node resources.
HyperPath assumes that it can access the application’s SLO metric (for example, the delay of the 95th percentile), as well as resource metrics, which include the cpu / mem / net / IO container parameters and similar node level metrics. Using this data, HyperPath will try to correlate which resource metrics have exceeded the threshold and rank the master data with the highest correlation metric.
In the demo, you will see that you can detect bottlenecks in the processor and other resources that have exceeded the SLO threshold during application delay:
For more information and source code, please refer to the diagnosis analyzer section .
Best effort controller
It is well known that all operators intentionally overstate the required amount of resources for their applications. One of the most important reasons for this behavior is to account for surges that can occur suddenly. This leads to low utilization of cluster resources, since peak load occurs only occasionally. We cannot just allocate a minimum of resources and rely on the cloud and autoscaling, since the process of scaling the cluster may take a minute (s) during peak load. How then to use surplus resources? One way is to run the best effort (BE) workloads. You need to make sure that workloads can be monitored, increase or decrease the amount of available resources during bursts.
The work of Christos Kozyrakis and David Lo on Heracles was aimed at solving the problem of improving resource efficiency. For more information on how Heracles works, please refer to the source document . At a very high level, Heracles creates a controller on each node, and each of these controllers has an auxiliary controller for each resource (processor, memory, network, IO, caching, etc.) that monitors resource utilization. He then uses the main application SLO metric as an input to determine when and how to scale resources for each workload. When the application rate increases significantly, we can begin to allocate more resources for BE jobs, and vice versa, to reduce when the load drops.
At Hyperpilot, we developed the Heracles algorithm and made it work on Kubernetes. In the next video, you will see the controller in action when we launched Spark with the BestEffort QoS quality class next to the microservice.
When Spark is launched next to a microservice without a BE controller, you will see an increase in latency due to interference from Spark Job. Please note that even setting BestEffort to work Spark does not exclude interference problems. With the BE controller turned on, we observe a delay that will be controlled within the SLO threshold, and BE jobs can progress without completion.
Additional information on the code base can be found here .
I hope that these projects will show how the use of resource utilization data from kubernetes and applications can affect cost and performance.
Original: Hyperpilot open sourced 100% of its products .