How to Optimize DevOps with Machine Learning
The DevOps software development methodology, which is popular today, is aimed at the active interaction and integration of development specialists and IT specialists. Characteristically, DevOps generates large amounts of data that can be used to simplify workflows, orchestration, monitoring, troubleshooting, or other tasks. The problem is that there is too much of this data. Server logs alone can accumulate several hundred megabytes per week. If monitoring tools are used, then in a short period of time megabytes and gigabytes of data are generated.
The result is predictable: developers do not directly view the data themselves, but set threshold values, that is, they look for exceptions, and do not analyze the data. But even with the help of modern analytical tools, you should know what to look for.

Most of the data created in DevOps processes is related to application deployment. Application monitoring replenishes the server logs, generates error messages, transaction tracking. The only reasonable way to analyze this data and come to some conclusions in real time is to use machine learning (ML).
Most machine learning systems use neural networks, which are a set of multi-level algorithms for data processing. They are trained by entering previous data with a known result. The application compares algorithmically obtained results with known results. Then, the coefficients of the algorithm are adjusted to try to simulate the results.
This may take some time, but if the algorithms and network architecture are built correctly, the machine learning system will begin to produce results that match the actual ones. In fact, the neural network has “studied” or modeled the relationship between data and results. This model can then be used to evaluate future data.
Algorithms of machine analysis and learning allow you to monitor information objects (databases, applications, etc.) and build profiles of the normal (without failures) functioning of the system. In case of any deviations (anomalies), for example, when the response time increases, the application freezes or the transaction slows down, the system fixes this situation and sends a notification about this, which allows building preventive policies that prevent such anomalies.
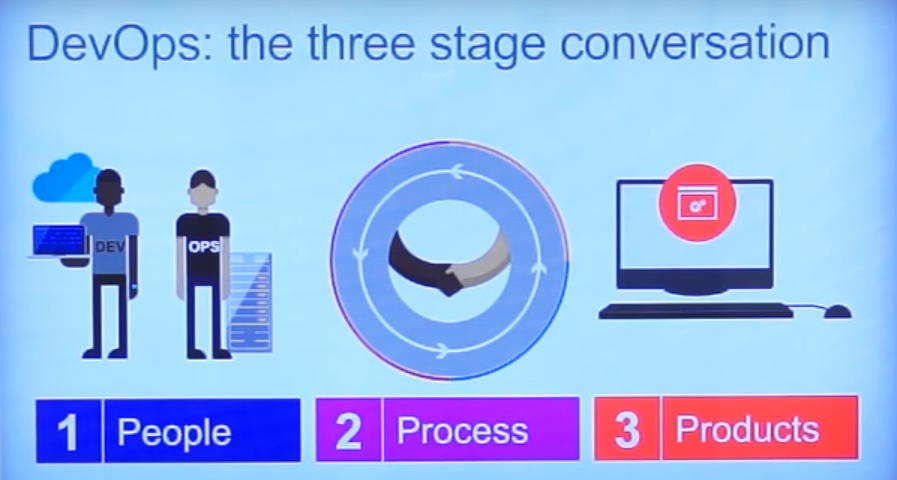
DevOps is a combination of software development and operation processes. Its components are processes, people and products.
How difficult is it to train such a system, how much will it take time, the efforts of experts? Essentially, no training is needed - it learns independently on data sets without the aid of programming and can predict the relationships of data sets. This makes it possible to eliminate the “human factor”, thereby speeding up the system by eliminating manual processes (such as identifying data correlations, dependencies, etc.).
The system itself builds profiles of the normal functioning of the object, and for additional adjustment, parameterization mechanisms are sufficient. However, while machine learning is a very powerful tool, it does need data accumulation. Over time, the number of false positives decreases. Their number can be reduced by almost an order of magnitude with the help of “fine tuning”.
Tuning mechanisms help make algorithms more accurate, adapt them to specific needs. Thus, over time, accuracy increases even more due to accumulated statistics.
The synergy of DevOps and machine learning (ML) opens up new possibilities for predictive analytics, IT Operations Analytics (ITOA), Algorithmic IT Operations (AIOps), etc.
Algorithmic approaches are aimed at identifying anomalies, clustering and correlating data, and forecasting. They help you find answers to many questions. What is the cause of the problem? How to prevent it? Is this behavior normal or abnormal? What can be improved in the application? What should I look for immediately? How to balance the load? There are many areas of application for machine learning in DevOps.
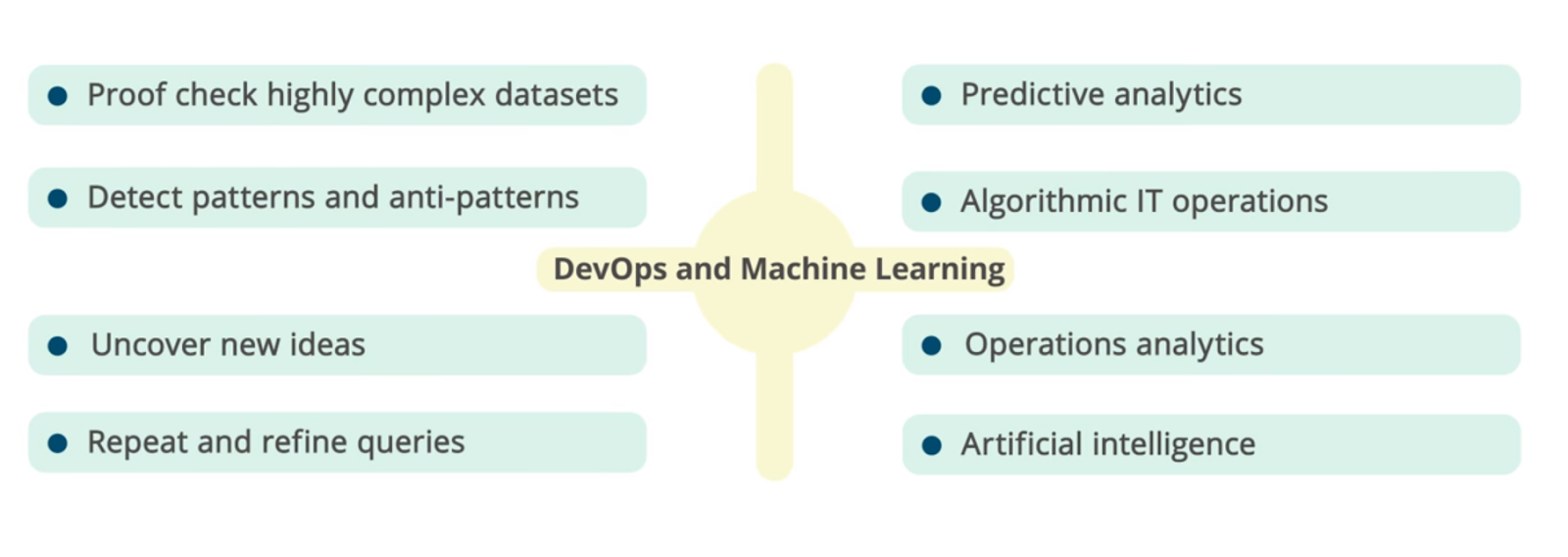
DevOps and ML: analysis of complex data sets, identification of dependencies and patterns, predictive analytics, operational analytics, artificial intelligence, etc.
Machine learning allows you to use large amounts of data and helps to draw informed conclusions. Identification of statistically significant anomalies makes it possible to detect abnormal behavior of infrastructure objects. In addition, machine learning makes it possible to identify not only various anomalies in the processes, but also illegal actions.
Recognizing and grouping records based on common patterns helps to focus on important data and “cut off” secondary information. Analysis of the records that precede the error and follow it increases the efficiency of the search for the root causes of problems; continuous monitoring of applications to identify problems contributes to their quick elimination during operation.
Identification, user data, information security, diagnostic, transactional data, metrics (applications, hosts, virtual machines, containers, servers) - data of the user level, application, middleware layer, virtualization level and infrastructure - all of them are well suited for machine learning and have predictable format.
Regardless of whether you buy a commercial application or create it yourself, there are several ways to use machine learning to improve DevOps.
The ultimate goal is to enhance DevOps methods in a measurable way from concept to deployment and decommissioning.

Machine learning systems can process a variety of data in real time and provide an answer that DevOps developers can use to improve processes and better understand application behavior.
The result will be faster DevOps, a combination of software development and operation processes. Instead of weeks and months, they are reduced to days.
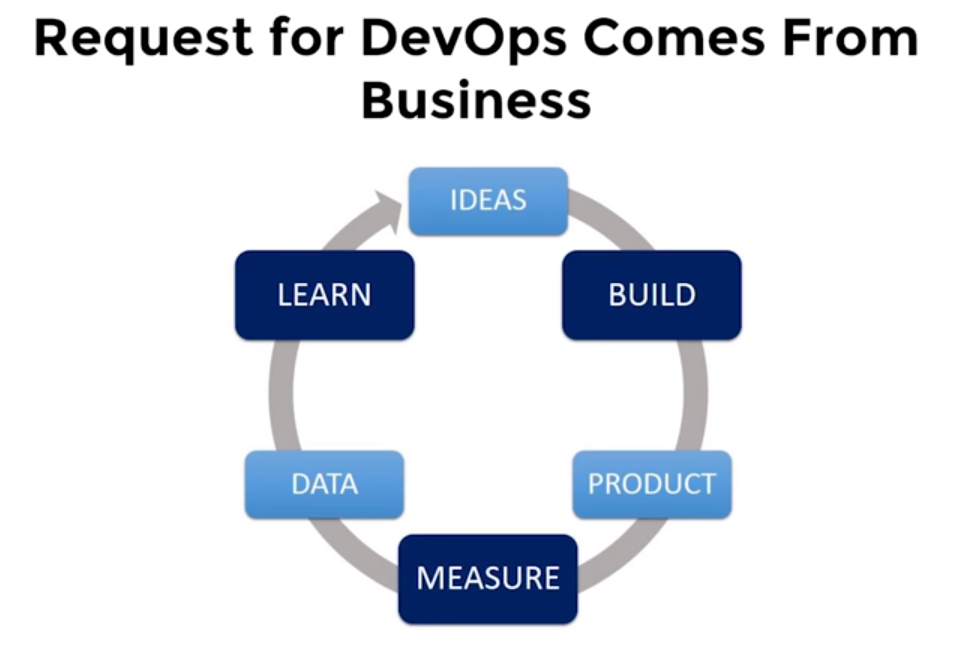
The DevOps cycle (idea, creation, product release, measurement, data collection, exploration) requires acceleration.
The "human factor" significantly affects the operation processes (Ops). The person is entrusted with the task of analyzing data from various sources, their correlation and interpretation. In this case, different tools are used. Such a task is complex, laborious and time consuming. Its automation not only speeds up the process, but also eliminates different interpretations of the data. This is why applying modern machine learning algorithms to DevOps data is so important.

Machine learning provides a single interface for developers and maintenance professionals (Dev and Ops).
Correlation of user data, transaction data, etc. is the most important tool for detecting anomalies in the behavior of various software components. And forecasting is extremely important from the point of view of management, monitoring application performance. It allows you to take proactive measures, understand what you need to pay attention to now, and what will happen tomorrow, or find out how to balance the load.
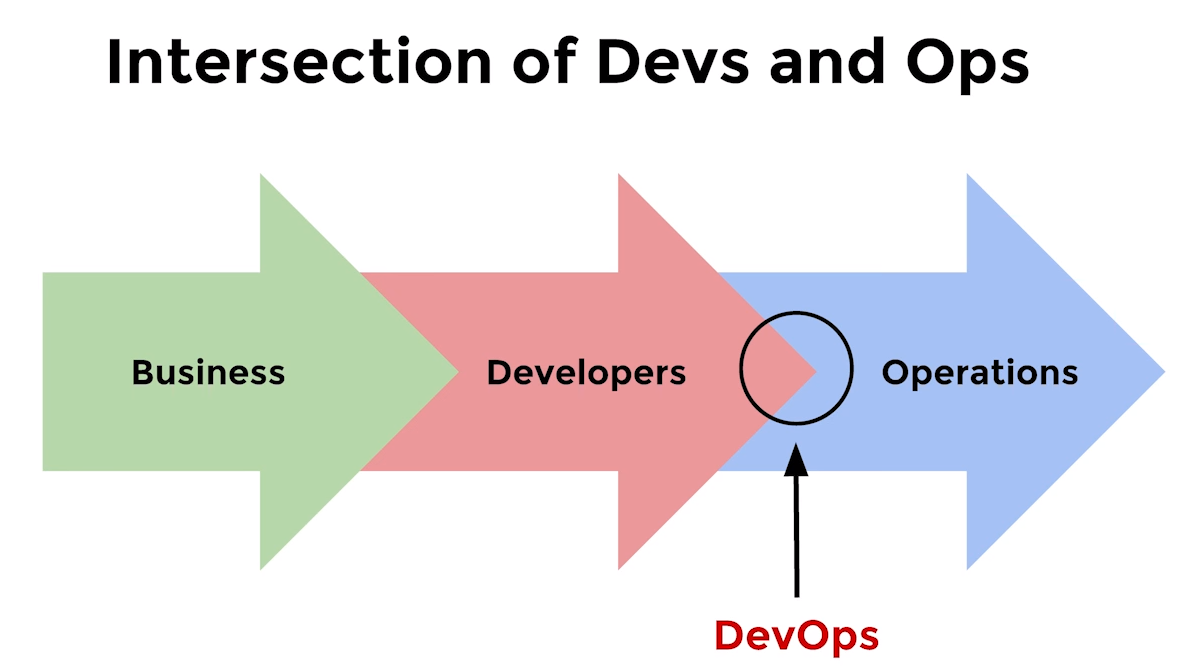
The product delivery cycle should be simple, transparent and fast, however, conflicts often arise at the “intersection point” of Dev and Ops .
In addition, a system with machine learning mechanisms removes barriers between developers and operating services (Dev and Ops). Through application performance diagnostics, developers gain access to valuable diagnostic data.
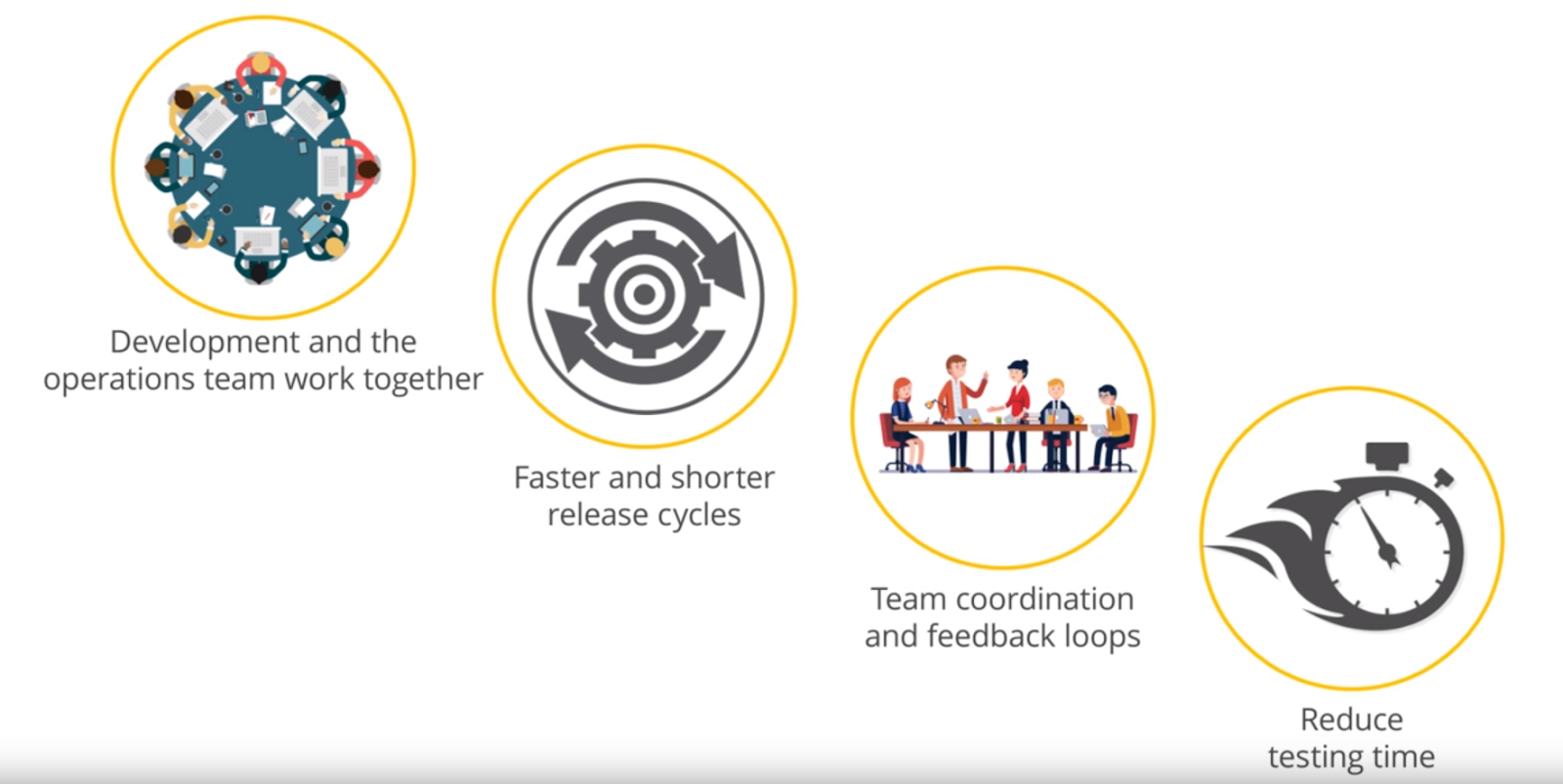
The operations department and development teams work together to complement each other. Release cycles are shortened and accelerated, coordination and feedback are improved, and testing time is reduced.
The implementation of Docker, microservices, cloud technologies and APIs for deploying applications and providing high reliability requires new approaches. Therefore, it is important to use smart tools, and DevOps tool providers integrate smart features in their products to further simplify and speed up software development processes.
Of course, ML is not a substitute for intelligence, experience, creativity and hard work. But today we already see the wide possibilities of its application and even greater potential in the future.
The result is predictable: developers do not directly view the data themselves, but set threshold values, that is, they look for exceptions, and do not analyze the data. But even with the help of modern analytical tools, you should know what to look for.
Most of the data created in DevOps processes is related to application deployment. Application monitoring replenishes the server logs, generates error messages, transaction tracking. The only reasonable way to analyze this data and come to some conclusions in real time is to use machine learning (ML).
Most machine learning systems use neural networks, which are a set of multi-level algorithms for data processing. They are trained by entering previous data with a known result. The application compares algorithmically obtained results with known results. Then, the coefficients of the algorithm are adjusted to try to simulate the results.
This may take some time, but if the algorithms and network architecture are built correctly, the machine learning system will begin to produce results that match the actual ones. In fact, the neural network has “studied” or modeled the relationship between data and results. This model can then be used to evaluate future data.
ML to help DevOps
Algorithms of machine analysis and learning allow you to monitor information objects (databases, applications, etc.) and build profiles of the normal (without failures) functioning of the system. In case of any deviations (anomalies), for example, when the response time increases, the application freezes or the transaction slows down, the system fixes this situation and sends a notification about this, which allows building preventive policies that prevent such anomalies.
DevOps is a combination of software development and operation processes. Its components are processes, people and products.
How difficult is it to train such a system, how much will it take time, the efforts of experts? Essentially, no training is needed - it learns independently on data sets without the aid of programming and can predict the relationships of data sets. This makes it possible to eliminate the “human factor”, thereby speeding up the system by eliminating manual processes (such as identifying data correlations, dependencies, etc.).
The system itself builds profiles of the normal functioning of the object, and for additional adjustment, parameterization mechanisms are sufficient. However, while machine learning is a very powerful tool, it does need data accumulation. Over time, the number of false positives decreases. Their number can be reduced by almost an order of magnitude with the help of “fine tuning”.
Tuning mechanisms help make algorithms more accurate, adapt them to specific needs. Thus, over time, accuracy increases even more due to accumulated statistics.
The synergy of DevOps and machine learning (ML) opens up new possibilities for predictive analytics, IT Operations Analytics (ITOA), Algorithmic IT Operations (AIOps), etc.
Algorithmic approaches are aimed at identifying anomalies, clustering and correlating data, and forecasting. They help you find answers to many questions. What is the cause of the problem? How to prevent it? Is this behavior normal or abnormal? What can be improved in the application? What should I look for immediately? How to balance the load? There are many areas of application for machine learning in DevOps.
| Machine Learning Applications | Explanation |
|---|---|
| Application Delivery Tracking | Activity data for DevOps tools (e.g. Jira, Git, Jenkins, SonarQube, Puppet, Ansible, etc.) ensure transparency of the delivery process. The use of ML can reveal anomalies in this data - large amounts of code, long build times, increased timelines for issuing and verifying code, and identifying many “deviations” in software development processes, including inefficient use of resources, frequent task switching, or process slowdowns. |
| Application Quality Assurance | By analyzing the test results, ML can identify new errors and create a library of test patterns based on such detection. This helps provide comprehensive testing of each release, improving the quality of the delivered applications (QA). |
| Behavior patterns | User behavior patterns can be as unique as fingerprints. Applying ML behavior to Dev and Ops can help identify abnormalities that are malicious activity. For example, abnormal access patterns for important repositories or users who intentionally or accidentally use known “bad” patterns (for example, with a backdoor), deploying unauthorized code or stealing intellectual property. |
| Operation management | Analysis of the application during operation is an area where machine learning can really prove to be, since you have to deal with large amounts of data, the number of users, transactions, etc. DevOps specialists can use ML to analyze user behavior, use resources, bandwidth transaction capabilities etc. to subsequently detect "abnormal" patterns (for example, DDoS attacks, memory leaks, etc.). |
| Notification Management | The simple and practical use of ML is to control the massive flow of warnings (alarms) in operating systems. This may be due to a common transaction identifier, a common set of servers or a common subnet, or the reason is more complex and requires “training” systems over time in order to recognize “known good” and “known bad” warnings. This allows you to filter alerts. |
| Troubleshooting and analytics | This is another area where modern machine learning technologies are showing great performance. ML can automatically detect and sort “known problems” and even some unknowns. For example, ML tools can detect anomalies in “normal” processing, and then further analyze the logs to correlate this problem with a new configuration or deployment. Other automation tools can use ML to prevent operations, open a ticket (or chat window) and assign it to the appropriate resource. Over time, ML will even be able to offer a better solution. |
| Preventing operational failures | ML goes far beyond simple resource planning to prevent disruptions. It can be used to predict, for example, the best configuration to achieve the desired level of performance; the number of customers who will use the new feature; infrastructure requirements, etc. ML identifies “early signs” in systems and applications, allowing developers to initiate a fix or avoid problems in advance. |
| Business Impact Analysis | Understanding the impact of code release on business goals is critical to success at DevOps. By synthesizing and analyzing real usage indicators, ML systems can detect good and bad models for implementing an “early warning system” when applications have problems (for example, by reporting an increase in the frequency of cases when a shopping cart has been abandoned or an increase in a customer’s “route”). |
DevOps and ML: analysis of complex data sets, identification of dependencies and patterns, predictive analytics, operational analytics, artificial intelligence, etc.
Machine learning allows you to use large amounts of data and helps to draw informed conclusions. Identification of statistically significant anomalies makes it possible to detect abnormal behavior of infrastructure objects. In addition, machine learning makes it possible to identify not only various anomalies in the processes, but also illegal actions.
Recognizing and grouping records based on common patterns helps to focus on important data and “cut off” secondary information. Analysis of the records that precede the error and follow it increases the efficiency of the search for the root causes of problems; continuous monitoring of applications to identify problems contributes to their quick elimination during operation.
Identification, user data, information security, diagnostic, transactional data, metrics (applications, hosts, virtual machines, containers, servers) - data of the user level, application, middleware layer, virtualization level and infrastructure - all of them are well suited for machine learning and have predictable format.
DevOps enhancement
Regardless of whether you buy a commercial application or create it yourself, there are several ways to use machine learning to improve DevOps.
| Way | What does he mean |
|---|---|
| From thresholds to data analytics | Because there is so much data, DevOps developers rarely look at and analyze the entire data set. Instead, they set thresholds - a condition for some action. In fact, they drop most of the data collected and focus on deviations. Machine learning applications can do more. They can be trained on all the data, and in the operating mode, these applications can view the entire data stream and draw conclusions. This will help predictive analytics. |
| Search for trends, not mistakes | From the foregoing, it follows that when learning from all the data, a machine learning system can show not only the identified problems. By analyzing data trends, DevOps specialists can identify what will happen over time, that is, make predictions. |
| Analysis and correlation of data sets | A significant part of the data is time series, and it is not difficult to trace one variable. But many trends are the result of the interaction of several factors. For example, the response time may decrease when several transactions simultaneously perform the same action. Such trends are almost impossible to detect with the naked eye or with the help of traditional analytics. But appropriately trained applications will take these correlations and trends into account. |
| New development metrics | In all likelihood, you collect data on delivery speed, search and error correction indicators, plus data obtained from a continuous integration system. The possibilities for finding any combination of data are huge. |
| Historical Data Context | One of the biggest challenges in DevOps is learning from your own mistakes. Even if there is a constant feedback strategy, then most likely it’s something like a wiki that describes the problems we encountered and what we did to investigate them. A common solution to the problem is to reboot the server or restart the application. Machine learning systems can analyze data and clearly show what happened in the last day, week, month or year. You can see seasonal or daily trends. They will give us a picture of our application at any time. |
| Root cause search | This feature is important for improving application quality and allows developers to troubleshoot availability or performance issues. Often failures and other problems are not fully investigated, because they quickly solve the problem of restoring the application. Sometimes rebooting restores, but the root cause of the problem is lost. |
| Correlation between monitoring tools | DevOps often uses several tools to view and process data. Each of them controls the operability and productivity of the application in different ways, but lacks the ability to find the relationship between this data of different tools. Machine learning systems can collect all these disparate data streams, use them as source data, and create a more accurate and reliable picture of the state of the application. |
| Orchestration Effectiveness | With orchestration process metrics, machine learning can be used to determine how effectively this orchestration is performed. Inefficiency can be the result of incorrect methods or poor orchestration, so studying these characteristics can help both in choosing tools and in organizing processes. |
| Predicting a failure at a specific point in time | If you know that monitoring systems give certain indications during a failure, then a machine learning application may look for these patterns as a prerequisite for a specific type of failure. If you understand the cause of this failure, you can take measures to avoid it. |
| Specific metric optimization | Want to increase uptime? Maintain a performance standard? Reduce time between deployments? An adaptive machine learning system can help. Adaptive systems - systems without a specific answer or result. Their goal is to obtain input data and optimize a specific characteristic. For example, airline ticketing systems try to fill planes and optimize revenue by changing ticket prices up to three times a day. You can optimize DevOps processes in the same way. The neural network is trained in such a way as to maximize (or minimize) the value, and not achieve a known result. This allows the system to change its parameters during operation in order to gradually achieve the best result. |
The ultimate goal is to enhance DevOps methods in a measurable way from concept to deployment and decommissioning.
Machine learning systems can process a variety of data in real time and provide an answer that DevOps developers can use to improve processes and better understand application behavior.
Process Acceleration
The result will be faster DevOps, a combination of software development and operation processes. Instead of weeks and months, they are reduced to days.
The DevOps cycle (idea, creation, product release, measurement, data collection, exploration) requires acceleration.
The "human factor" significantly affects the operation processes (Ops). The person is entrusted with the task of analyzing data from various sources, their correlation and interpretation. In this case, different tools are used. Such a task is complex, laborious and time consuming. Its automation not only speeds up the process, but also eliminates different interpretations of the data. This is why applying modern machine learning algorithms to DevOps data is so important.
Machine learning provides a single interface for developers and maintenance professionals (Dev and Ops).
Correlation of user data, transaction data, etc. is the most important tool for detecting anomalies in the behavior of various software components. And forecasting is extremely important from the point of view of management, monitoring application performance. It allows you to take proactive measures, understand what you need to pay attention to now, and what will happen tomorrow, or find out how to balance the load.
The product delivery cycle should be simple, transparent and fast, however, conflicts often arise at the “intersection point” of Dev and Ops .
In addition, a system with machine learning mechanisms removes barriers between developers and operating services (Dev and Ops). Through application performance diagnostics, developers gain access to valuable diagnostic data.
The operations department and development teams work together to complement each other. Release cycles are shortened and accelerated, coordination and feedback are improved, and testing time is reduced.
The implementation of Docker, microservices, cloud technologies and APIs for deploying applications and providing high reliability requires new approaches. Therefore, it is important to use smart tools, and DevOps tool providers integrate smart features in their products to further simplify and speed up software development processes.
Of course, ML is not a substitute for intelligence, experience, creativity and hard work. But today we already see the wide possibilities of its application and even greater potential in the future.