Lessons Learned from LLVM / Clang Codebase
- Transfer
From a translator: in an article that I bring to your attention, the authors examined the LLVM / Clang code base using the CppDepend code analysis tool, which allows you to calculate various code metrics and analyze large projects in order to improve the quality of the code.
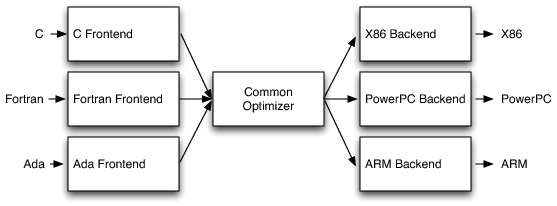
Time has proven that Clang is just as mature a C and C ++ compiler as GCC and Microsoft's compiler, but what makes it special is that it is not just a compiler. This is an infrastructure for creating tools. Due to the fact that its architecture is based on the use of libraries, the reuse and integration of functionality into your project is made more simple and flexible.

Like many other compilers, Clang has three phases:
The frontend, which parses the source code, checks for errors, and builds a language-dependent abstract syntax tree (AST) representing the input code.
Optimizer: Its goal is to optimize the AST generated by the frontend.
Backend: Generates the final code executed by the machine, depending on the target machine.

The biggest difference is that Clang is based on LLVM, and the main idea of LLVM is to use an intermediate representation (IR), which is some kind of bytecode for Java.
LLVM IR is designed to support the intermediate stages of analysis and transformation, which are in the optimizing stage of the compiler. It was developed taking into account many specific requirements, including support for "light" runtime optimizations, interprocedural / interfunctional optimizations, analysis of the program as a whole, aggressive structural transformations, etc. The most important aspect, however, is that the intermediate representation itself is a first-class language with well-defined semantics.
With this structure, we can reuse most of the compiler to create other compilers, for example, you can replace the front-end to support other languages.
It is very interesting to get inside this powerful toy and see how it is designed and implemented. C ++ developers can learn many good practices from this code base.
Let's x-ray the source code using CppDepend and CQLinq to understand some of the developers' decisions.
The main concept in developing clang was the use of libraries. The different parts of the frontend can be explicitly divided into different libraries, which can be shared for various purposes. This approach encourages the use of good interfaces and makes the task easier for new developers (since they will only need to understand a small part of the big picture).
DSM (Dependency Structure Matrix), a dependency structure matrix, is a compact way of representing dependencies between components. A non-empty matrix cell contains a number. This number expresses the bond strength represented by the cell. The strength of the relationship can be expressed as the number of members / methods / fields / types and namespaces involved in the relationship.
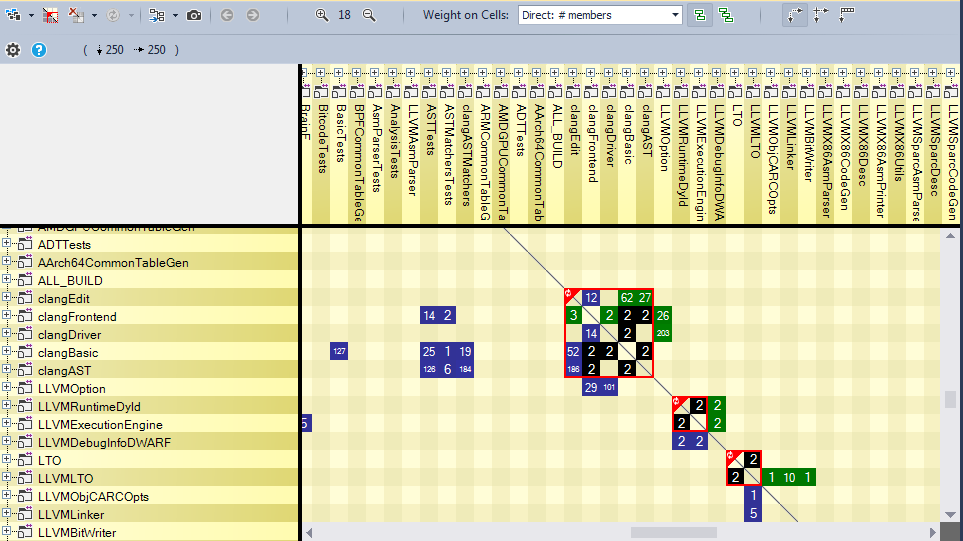
This dependency graph shows us the libraries that clang uses directly.
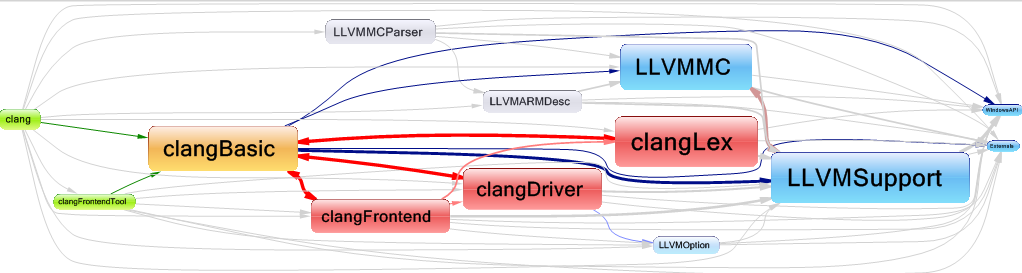
As we can see, there are three cyclic dependencies between the clangBasic / clangFrontEnd, clangBasic / clangDriver and clangBasic / clangLex libraries. It is recommended that you remove any circular dependencies between libraries so that the code is more readable and easier to maintain.
Why is clangFrontend using the clangBasic library?
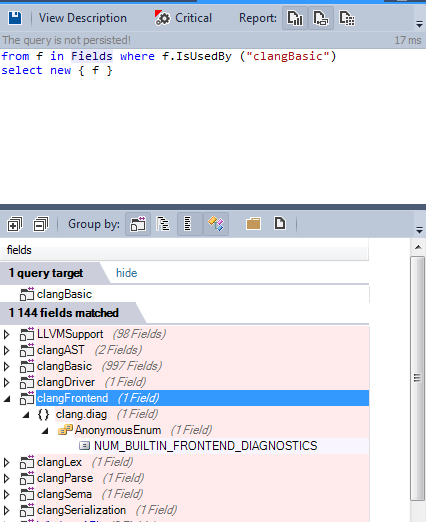
Only one enum field causes a circular dependency, the code can be refactored, and the dependency can be easily fixed.
In C ++, namespaces are used to make code modular, and in LLVM / clang they are used for three main reasons:
Many namespaces contain only enumerations, as shown in the following CQLinq query.
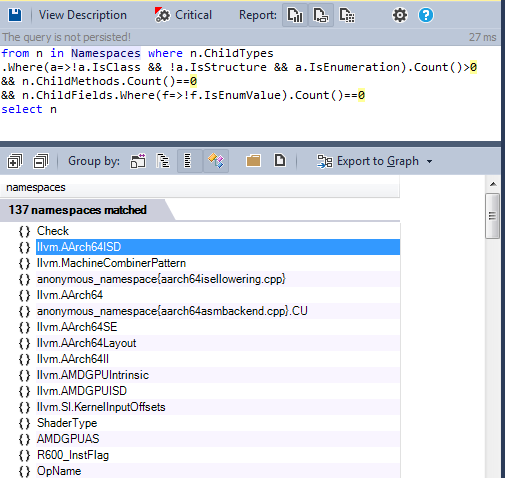
In a large project, it cannot be guaranteed that two different enumerations will not be named the same. The problem was resolved in C ++ 11, using enumeration classes that imply the use of enum values along with the enum name. The code may be refactored in the near future using C ++ 11 enumeration classes.
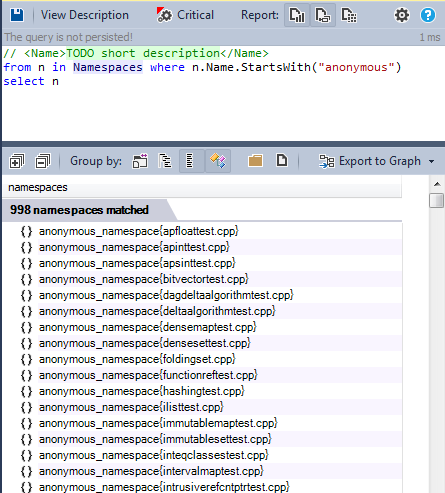
Anonymous namespaces: Namespaces without a name, avoiding the creation of global static variables. The anonymous namespace that you created will only be available in the file in which it is created. Here is a list of all the anonymous namespaces used.
All non-anonymous namespaces:
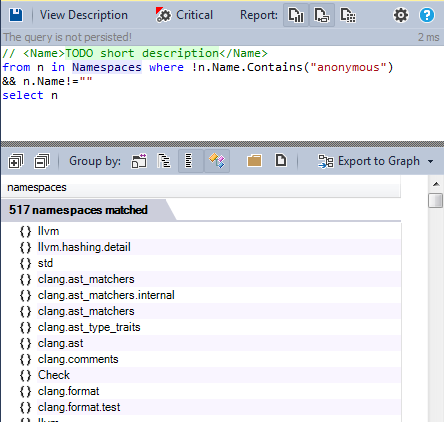
Namespaces are a good solution to make the application modular, LLVM / clang defines more than 500 namespaces to provide modularity to make the code readable and maintainable.
C ++ is not just an object oriented language. Bjarn Straustrup pointed out that C ++ is a multi-paradigm language. It supports many programming styles, or paradigms, and object orientation is just one of them. Others are procedural programming and generalized programming.
2.1.1. Global functions
We find all global functions defined in the LLVM / Clang source:
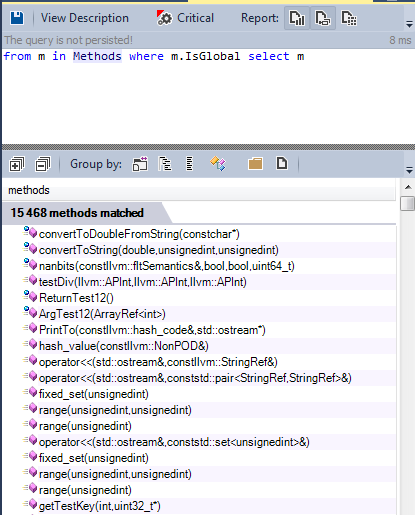
We can divide these functions into three categories:
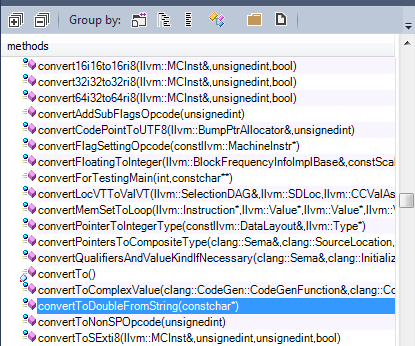
1 - Utilities: For example, conversion functions from one type to another.
2 - Operators: many operators are defined, as the CQLinq result shows:
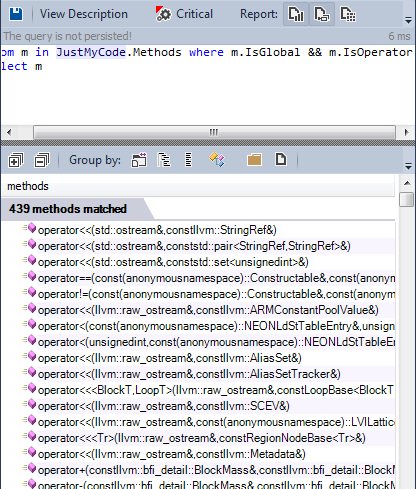
In the llvm / clang source code, almost all overridden operators are found.
3 - Functions related to compiler logic: Many global functions that implement various functions of the compiler.
Perhaps this type of function should be grouped into categories, like static class methods, or grouped by namespace.
2.1.2. Static Global Functions
It is best practice to declare global functions as static, except in those specific cases where you need to call them from another source file.
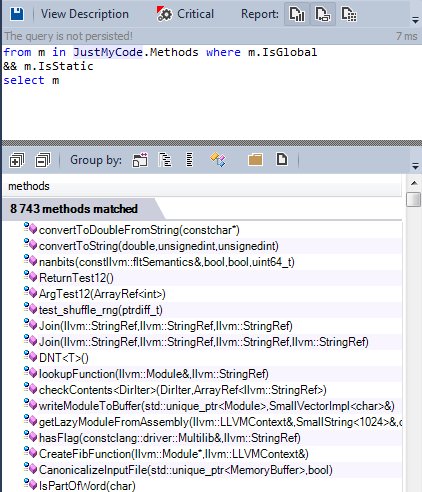
Almost all global functions are declared as static.
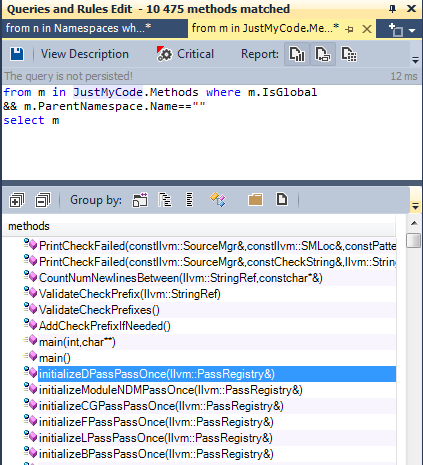
2.1.3. Global functions - candidates for static
Global, non-exported functions that are not declared in the anonymous namespace, are not used by any method outside the file where they were declared - these are good candidates for refactoring to static.
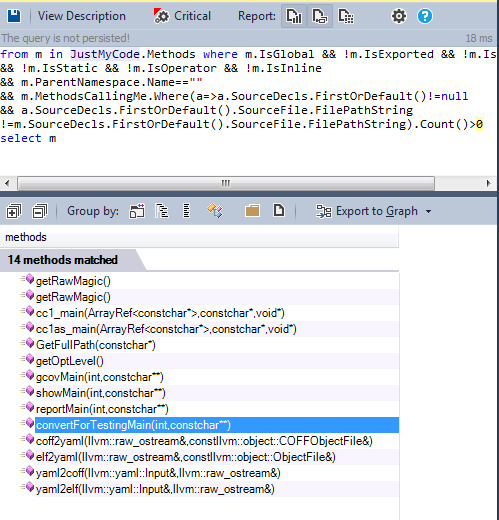
As we can see, only a few functions can be refactored into static ones.
2.2.1. Inheritance
In object-oriented programming (OOP), inheritance is a way to establish an “is” relationship between objects. It is often confused with the way to reuse existing code, which is not good practice because inheritance to reuse the implementation leads to a strong relationship. The reusability of the code is achieved through composition (composition is preferable to inheritance). Let's look for all classes that have at least one base class:
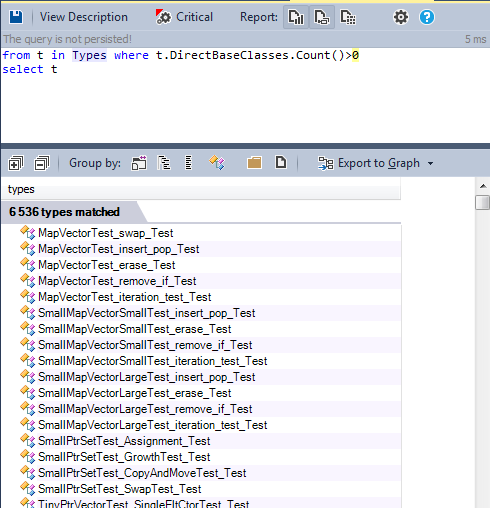
It is best to use Metric View in this query.
In Metric View, the codebase is represented as a Treemap. This is a method of displaying a tree-like data structure using nested rectangles. The tree structure used in CppDepend is the usual code hierarchy:
Projects contain namespaces.
Namespaces contain types.
Types contain methods and fields.
Treemap is a useful way to present CQLinq query results, blue rectangles represent the result, we can see the types associated with the query.
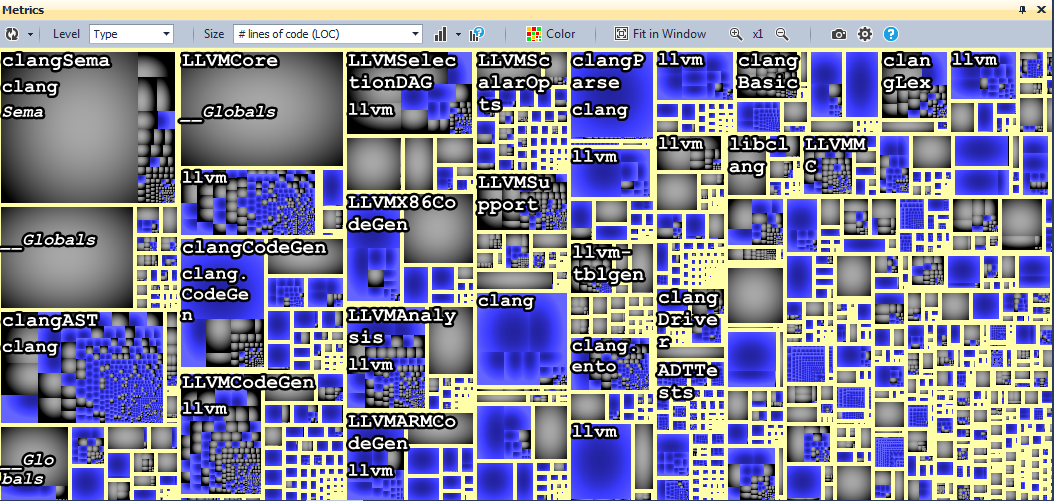
As we can see, inheritance is widely used in llvm / clang source code.
Multiple Inheritance: Let's find classes inherited from more than one class.
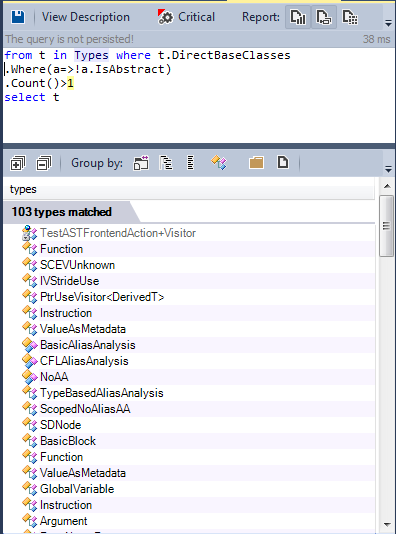
Multiple inheritance is used infrequently; less than 1% of classes are inherited from more than one class.
2.2.2. Virtual Methods
Let's find all the virtual methods defined in the source code:
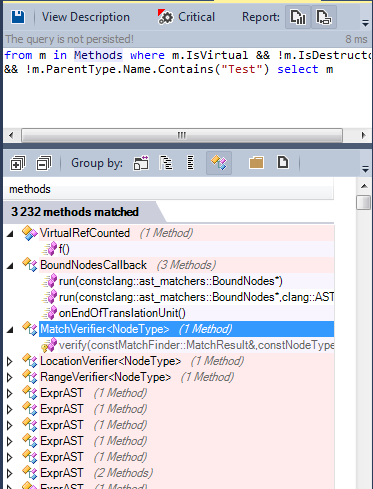
Many methods are virtual, some of them are pure virtual:
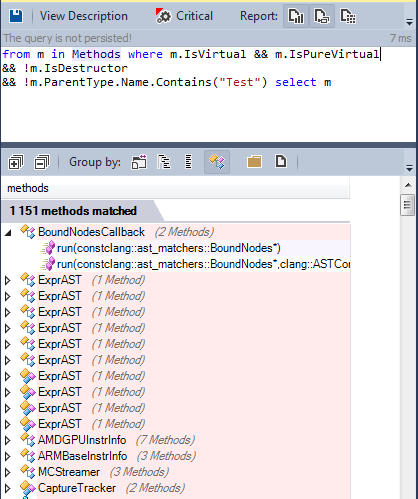
The OOP paradigm is widely used in llvm / clang source code. What about generalized programming?
C ++ provides unique opportunities to express generalized programming ideas through templates. Patterns are a form of parametric polymorphism that allows you to express generalized algorithms and data structures. The mechanism for instantiating C ++ templates ensures that when generalized algorithms and data structures are used, a fully optimized and specialized version will be created specifically for specific parameters, allowing generalized algorithms to be as effective as their non-generalized versions.
2.3.1. Generic Types
Let's find all the generic types defined in the source code:
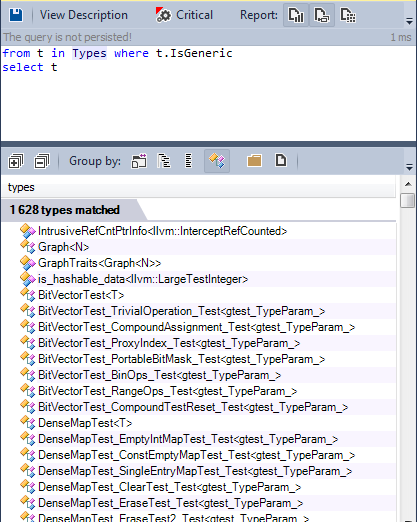
Many types are defined as generic. Let's find generalized methods:
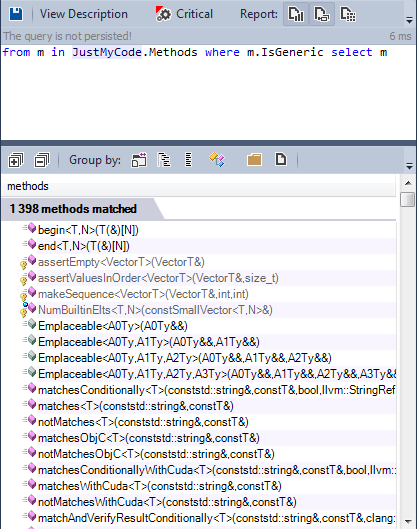
Less than 1% of the methods are generalized.
So, the source code llvm / clang uses three paradigms.
In object-oriented programming, plain old data (POD) is a data structure that represents only a passive collection of values, without the use of object-oriented functions. In computer science, they are also known as passive data structures.
Let's look for POD types in the source code.
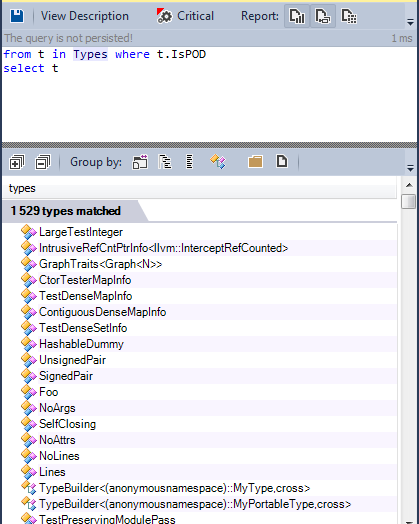
More than 1,500 types are defined as POD types, many of which are used to define the compiler data model.
Design patterns are a software engineering concept that describes solutions to common problems in software design. The Gang of Four patterns are the most popular. Let's find their use in llvm / clang source code.
List of factory methods defined in the source code:
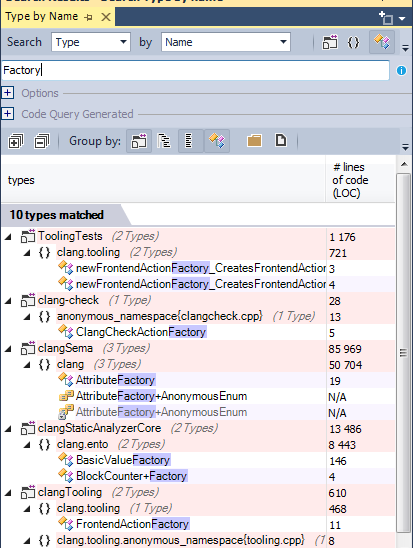
List of abstract factory methods:
An observer pattern is a design pattern in which an object contains a list of observer objects and notifies them automatically of any state changes, usually by calling one of their methods.
There is only one observer in the source text:

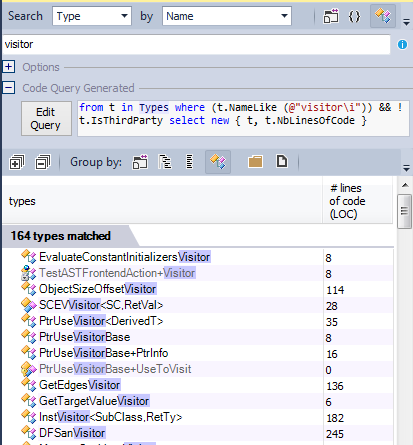
The visitor pattern is recommended when you need to make a walk around the structure and perform specific actions in each node of the structure.
In the llvm / clang source code, the visitor pattern is widely used:
A low degree of adhesion is desirable since changes in one part of the application will require fewer changes in the rest of the application. In the long run, this can save a lot of time, effort and money associated with modifying and adding new features to the application.
A low degree of coupling can be achieved using abstract classes or using generic types and methods.
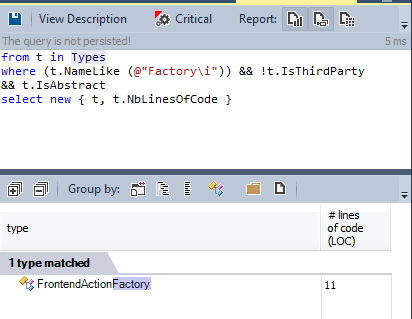
Let's find all the abstract classes defined in the source code:
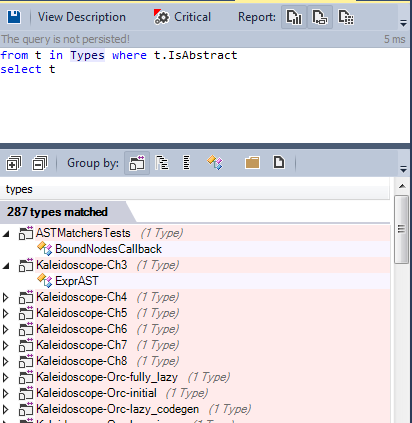
More than 280 types declared as abstract. However, a low degree of adhesion has also been achieved through the use of generic types and generic methods.
Connectivity
The principle of single responsibility states that a class cannot have more than one reason for change. Such classes are called connected. A high LCOM value most often corresponds to poorly connected classes. There are several LCOM metrics. LCOM takes a value in the range [0-1]. LCOM HS (HS stands for Henderson-Sellers) takes a value in the range [0-2]. An LCOM HS value greater than 1 should be alarming. LCOM metrics are considered as:
LCOM = 1 - (sum (MF) / M * F)
LCOM HS = (M - sum (MF) / F) (M-1)
where:
M - the number of class methods (counting static methods, constructors , getters / setters, methods for adding and removing events).
F is the number of non-static fields of the class.
MF - the number of class methods that have access to a specific non-static field.
Sum (MF) - the sum of MF for all non-static fields of the class.
The idea expressed by this formula can be formulated as follows: a connected class if all methods use all non-static fields, i.e. sum (MF) = M * F, and therefore LCOM = 0 and LCOMHS = 0.
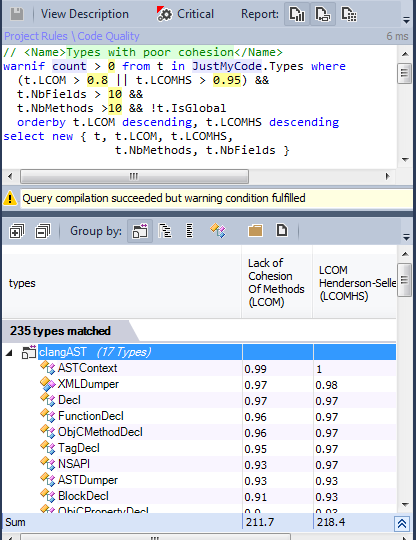
235 classes are considered, perhaps some of them may be refactored to improve connectivity.
An object is called immutable if its state does not change from the moment it was created. Therefore, a class is called immutable if its instances are immutable.
There is one argument in favor of using immutable objects: it greatly simplifies competitive programming. Think about why the write operation in multi-threaded programming is so complicated? Because it is difficult to synchronize the access of threads to a resource (objects or other OS resources). Why is it difficult to synchronize access? Because it is difficult to guarantee that there will be no race between multiple streams. What if there is no write access? In other words, what if the state of the objects to which the threads have access is unchanged? Then there is no need for synchronization.
Another advantage of immutable classes is that they never violate the Lisk substitution principle, here is the definition of the Lisk principle from Wikipedia:
“a subclass should not create new mutators of properties of a base class. If the base class did not provide methods for changing the properties defined in it, a subtype of this class also should not create such methods. In other words, immutable data of the base class should not be mutable in the subclass. "
Here is a list of immutable types in the source code:
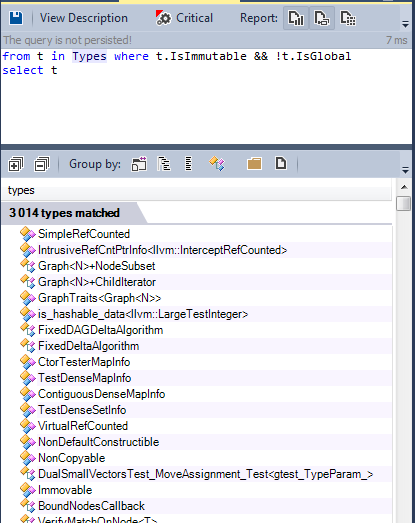
The main advantage of immutable types comes from the fact that they eliminate side effects. I cannot say better than Wes Dyer, and I will quote him:
“We all know that using global variables is not a good idea. This is due to the danger of side effects (global scope). Many programmers who do not use global variables do not understand that the same principle applies to fields, properties, parameters, and variables on a more limited scale: do not change them without good reason (...) "
One way to increase the reliability of the module is to get rid of side effects. This makes compiling and integrating modules easier and more reliable. If they do not have side effects, they always work the same way, regardless of the environment. This is called referential transparency.
Write functions and methods without side effects - these will be pure functions that do not modify the object - this will be better in the sense of the correctness of your program.
Here is a list of all methods with no side effects:
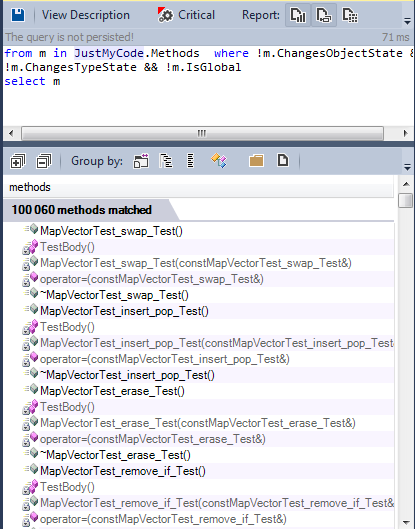
More than 100,000 methods are clean.
Methods with lots of lines of code are hard to maintain and understand. Let's find methods, more than 60 lines.
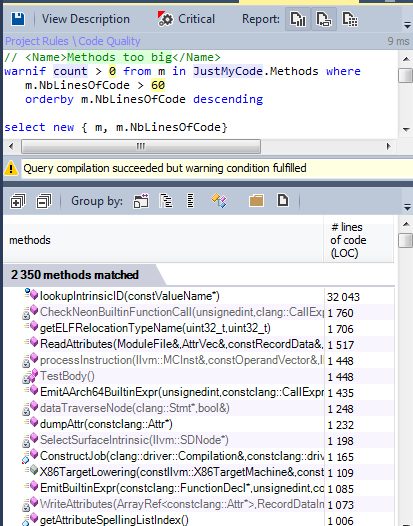
The llvm / clang source code contains more than 100,000 methods, and less than 2% of them can be considered too large.
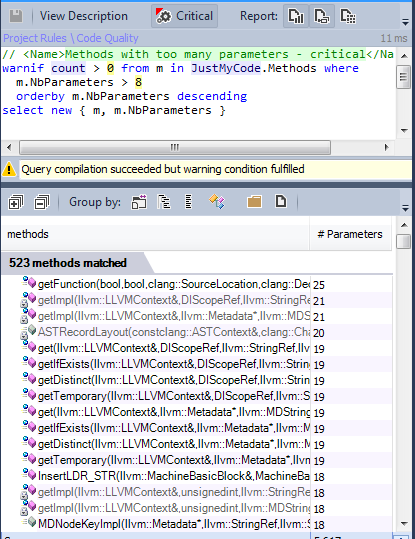
Several methods have more than 8 parameters.
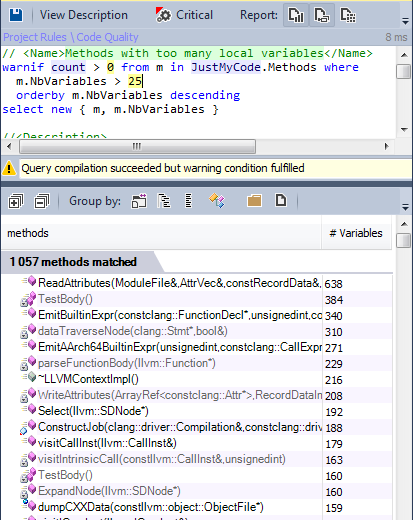
Less than 1% of methods have many local variables.
Many metrics exist to detect complex functions, calculate the number of lines of code, the number of parameters, and the number of local variables.
There are also interesting metrics for detecting complex functions:
Cyclomatic complexity is a popular procedural programming metric equal to the number of decisions that are made in a procedure.
Nested depth is a metric defined for a method that determines the maximum depth of nesting of visibility areas in the method body.
Maximum nesting cycles.
The maximum values allowed for these metrics depend more on the choice of the development team; there are no generally accepted standards.
Let's find methods that can be considered complex.
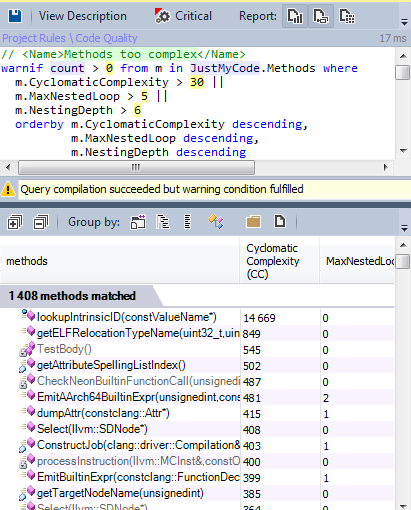
Only 1.5% of the methods are candidates to minimize complexity.
Halstead Complexity is a software metric introduced by Maurice Howard Halstead in 1977. Halstead made the observation that the program metric should reflect the implementation of the algorithm in various languages, but regardless of the platform. These metrics are calculated statically by code.
Halstead introduced many different metrics, consider for example one of them - TimeToImplement, which indicates the time required to program a method in seconds.
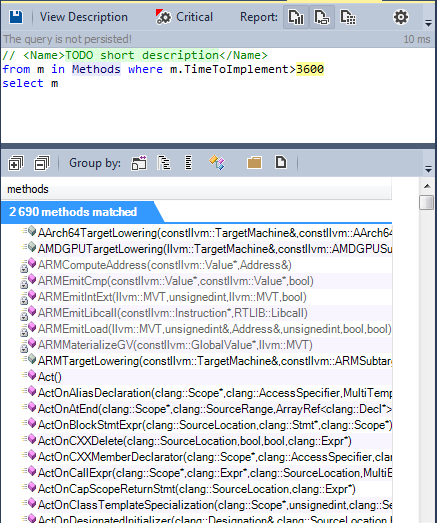
2690 methods require more than an hour to implement.
RTTI is the ability of a system to report a dynamic type of an object and provide type information at runtime (and not at compile time). However, the use of RTTI is controversial in the C ++ community. Many C ++ developers do not use this mechanism.
And what about the llvm / clang development team?
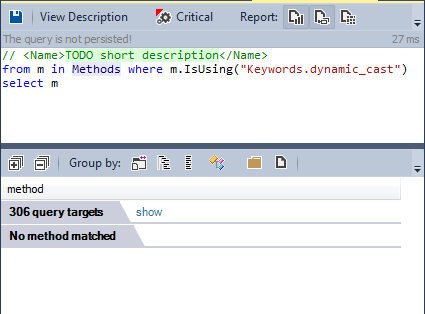
No method uses the dynamic_cast keyword. The llvm / clang development team chose not to use the RTTI engine.
Exception support is another controversial feature of C ++. Many well-known open source C ++ projects do not use it.
Let's see if exceptions are thrown somewhere in the code.
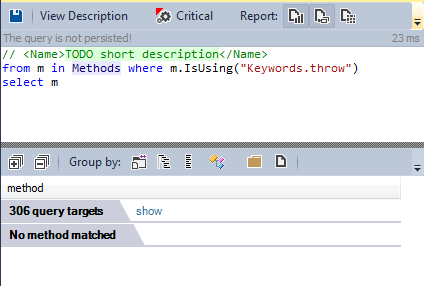
Like RTTI, the exception mechanism is not used.
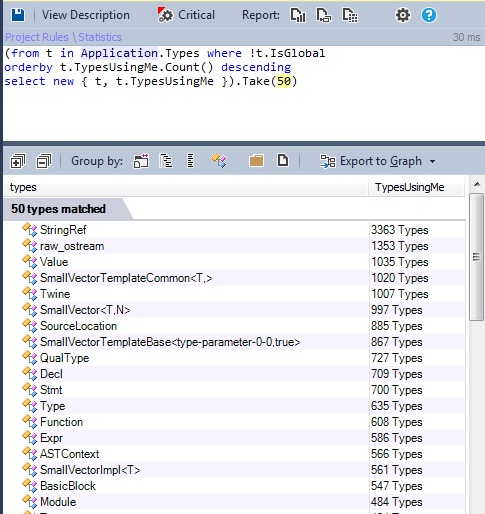
It is interesting to know what are the most used types in the project, since such types should be best designed, implemented, and tested. Any changes in them will affect the project as a whole.
Find them using the TypesUsingMe metric:
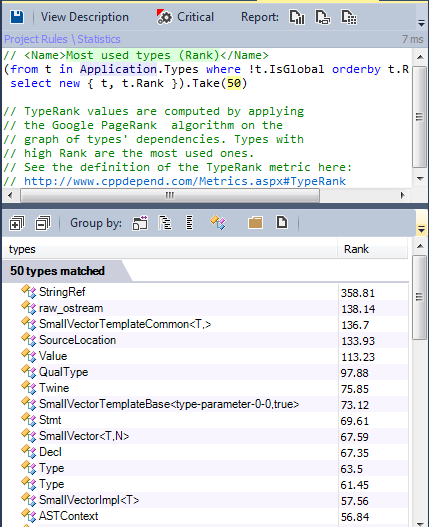
There is another interesting metric for finding popular types: TypeRank.
The TypeRank value is calculated by applying the Google PageRank algorithm on the type dependency graph. The center homothety of 0.15 is applied so that the average TypeRank is equal to one.
Types with a high TypeRank should be tested more carefully, because bugs in them can be more disastrous.
Below are the results of all popular types according to the TypeRank metric:
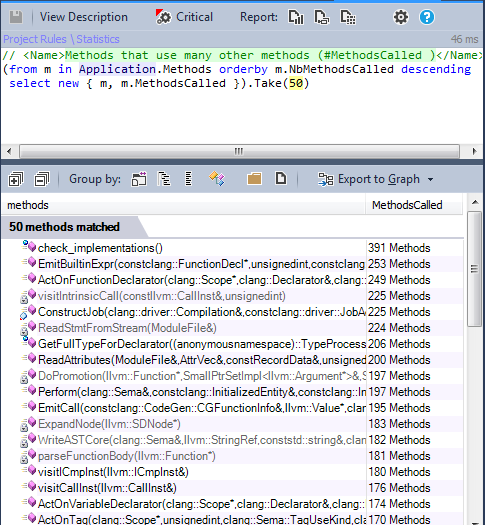
It is interesting to know which methods call many other methods; this can reveal design problems. In some cases, refactoring is required to make them more readable and easier to maintain.
LLVM / Clang is very well designed and implemented, and, like for any other project, it can be improved by some refactoring. In this post, we revealed some of the minimal possible changes that can be made in the source code. Don't be afraid to research the source code and improve your C ++ knowledge.
Time has proven that Clang is just as mature a C and C ++ compiler as GCC and Microsoft's compiler, but what makes it special is that it is not just a compiler. This is an infrastructure for creating tools. Due to the fact that its architecture is based on the use of libraries, the reuse and integration of functionality into your project is made more simple and flexible.
Clang structure
Like many other compilers, Clang has three phases:
The frontend, which parses the source code, checks for errors, and builds a language-dependent abstract syntax tree (AST) representing the input code.
Optimizer: Its goal is to optimize the AST generated by the frontend.
Backend: Generates the final code executed by the machine, depending on the target machine.
What is the difference between Clang and other compilers?
The biggest difference is that Clang is based on LLVM, and the main idea of LLVM is to use an intermediate representation (IR), which is some kind of bytecode for Java.
LLVM IR is designed to support the intermediate stages of analysis and transformation, which are in the optimizing stage of the compiler. It was developed taking into account many specific requirements, including support for "light" runtime optimizations, interprocedural / interfunctional optimizations, analysis of the program as a whole, aggressive structural transformations, etc. The most important aspect, however, is that the intermediate representation itself is a first-class language with well-defined semantics.
With this structure, we can reuse most of the compiler to create other compilers, for example, you can replace the front-end to support other languages.
It is very interesting to get inside this powerful toy and see how it is designed and implemented. C ++ developers can learn many good practices from this code base.
Let's x-ray the source code using CppDepend and CQLinq to understand some of the developers' decisions.
1. Modularity
1.1. Modularity and use of libraries
The main concept in developing clang was the use of libraries. The different parts of the frontend can be explicitly divided into different libraries, which can be shared for various purposes. This approach encourages the use of good interfaces and makes the task easier for new developers (since they will only need to understand a small part of the big picture).
DSM (Dependency Structure Matrix), a dependency structure matrix, is a compact way of representing dependencies between components. A non-empty matrix cell contains a number. This number expresses the bond strength represented by the cell. The strength of the relationship can be expressed as the number of members / methods / fields / types and namespaces involved in the relationship.
This dependency graph shows us the libraries that clang uses directly.
As we can see, there are three cyclic dependencies between the clangBasic / clangFrontEnd, clangBasic / clangDriver and clangBasic / clangLex libraries. It is recommended that you remove any circular dependencies between libraries so that the code is more readable and easier to maintain.
Why is clangFrontend using the clangBasic library?
Only one enum field causes a circular dependency, the code can be refactored, and the dependency can be easily fixed.
1-2 Modularity Using Namespaces
In C ++, namespaces are used to make code modular, and in LLVM / clang they are used for three main reasons:
Many namespaces contain only enumerations, as shown in the following CQLinq query.
In a large project, it cannot be guaranteed that two different enumerations will not be named the same. The problem was resolved in C ++ 11, using enumeration classes that imply the use of enum values along with the enum name. The code may be refactored in the near future using C ++ 11 enumeration classes.
Anonymous namespaces: Namespaces without a name, avoiding the creation of global static variables. The anonymous namespace that you created will only be available in the file in which it is created. Here is a list of all the anonymous namespaces used.
All non-anonymous namespaces:
Namespaces are a good solution to make the application modular, LLVM / clang defines more than 500 namespaces to provide modularity to make the code readable and maintainable.
2. Use of paradigms
C ++ is not just an object oriented language. Bjarn Straustrup pointed out that C ++ is a multi-paradigm language. It supports many programming styles, or paradigms, and object orientation is just one of them. Others are procedural programming and generalized programming.
2.1. Procedural Programming
2.1.1. Global functions
We find all global functions defined in the LLVM / Clang source:
We can divide these functions into three categories:
1 - Utilities: For example, conversion functions from one type to another.
2 - Operators: many operators are defined, as the CQLinq result shows:
In the llvm / clang source code, almost all overridden operators are found.
3 - Functions related to compiler logic: Many global functions that implement various functions of the compiler.
Perhaps this type of function should be grouped into categories, like static class methods, or grouped by namespace.
2.1.2. Static Global Functions
It is best practice to declare global functions as static, except in those specific cases where you need to call them from another source file.
Almost all global functions are declared as static.
2.1.3. Global functions - candidates for static
Global, non-exported functions that are not declared in the anonymous namespace, are not used by any method outside the file where they were declared - these are good candidates for refactoring to static.
As we can see, only a few functions can be refactored into static ones.
2.2. Object Oriented Paradigm
2.2.1. Inheritance
In object-oriented programming (OOP), inheritance is a way to establish an “is” relationship between objects. It is often confused with the way to reuse existing code, which is not good practice because inheritance to reuse the implementation leads to a strong relationship. The reusability of the code is achieved through composition (composition is preferable to inheritance). Let's look for all classes that have at least one base class:
It is best to use Metric View in this query.
In Metric View, the codebase is represented as a Treemap. This is a method of displaying a tree-like data structure using nested rectangles. The tree structure used in CppDepend is the usual code hierarchy:
Projects contain namespaces.
Namespaces contain types.
Types contain methods and fields.
Treemap is a useful way to present CQLinq query results, blue rectangles represent the result, we can see the types associated with the query.
As we can see, inheritance is widely used in llvm / clang source code.
Multiple Inheritance: Let's find classes inherited from more than one class.
Multiple inheritance is used infrequently; less than 1% of classes are inherited from more than one class.
2.2.2. Virtual Methods
Let's find all the virtual methods defined in the source code:
Many methods are virtual, some of them are pure virtual:
The OOP paradigm is widely used in llvm / clang source code. What about generalized programming?
2.3. General programming
C ++ provides unique opportunities to express generalized programming ideas through templates. Patterns are a form of parametric polymorphism that allows you to express generalized algorithms and data structures. The mechanism for instantiating C ++ templates ensures that when generalized algorithms and data structures are used, a fully optimized and specialized version will be created specifically for specific parameters, allowing generalized algorithms to be as effective as their non-generalized versions.
2.3.1. Generic Types
Let's find all the generic types defined in the source code:
Many types are defined as generic. Let's find generalized methods:
Less than 1% of the methods are generalized.
So, the source code llvm / clang uses three paradigms.
3. PODs define a data model
In object-oriented programming, plain old data (POD) is a data structure that represents only a passive collection of values, without the use of object-oriented functions. In computer science, they are also known as passive data structures.
Let's look for POD types in the source code.
More than 1,500 types are defined as POD types, many of which are used to define the compiler data model.
4. Patterns of designing a gang of four
Design patterns are a software engineering concept that describes solutions to common problems in software design. The Gang of Four patterns are the most popular. Let's find their use in llvm / clang source code.
4.1. Factory
List of factory methods defined in the source code:
List of abstract factory methods:
4.2. Observer
An observer pattern is a design pattern in which an object contains a list of observer objects and notifies them automatically of any state changes, usually by calling one of their methods.
There is only one observer in the source text:
4.3. Visitor
The visitor pattern is recommended when you need to make a walk around the structure and perform specific actions in each node of the structure.
In the llvm / clang source code, the visitor pattern is widely used:
5. Coupling and Cohesion
5.1. Clutch
A low degree of adhesion is desirable since changes in one part of the application will require fewer changes in the rest of the application. In the long run, this can save a lot of time, effort and money associated with modifying and adding new features to the application.
A low degree of coupling can be achieved using abstract classes or using generic types and methods.
Let's find all the abstract classes defined in the source code:
More than 280 types declared as abstract. However, a low degree of adhesion has also been achieved through the use of generic types and generic methods.
Connectivity
The principle of single responsibility states that a class cannot have more than one reason for change. Such classes are called connected. A high LCOM value most often corresponds to poorly connected classes. There are several LCOM metrics. LCOM takes a value in the range [0-1]. LCOM HS (HS stands for Henderson-Sellers) takes a value in the range [0-2]. An LCOM HS value greater than 1 should be alarming. LCOM metrics are considered as:
LCOM = 1 - (sum (MF) / M * F)
LCOM HS = (M - sum (MF) / F) (M-1)
where:
M - the number of class methods (counting static methods, constructors , getters / setters, methods for adding and removing events).
F is the number of non-static fields of the class.
MF - the number of class methods that have access to a specific non-static field.
Sum (MF) - the sum of MF for all non-static fields of the class.
The idea expressed by this formula can be formulated as follows: a connected class if all methods use all non-static fields, i.e. sum (MF) = M * F, and therefore LCOM = 0 and LCOMHS = 0.
235 classes are considered, perhaps some of them may be refactored to improve connectivity.
6. Immunity, purity and side effects
6.1. Immutable types
An object is called immutable if its state does not change from the moment it was created. Therefore, a class is called immutable if its instances are immutable.
There is one argument in favor of using immutable objects: it greatly simplifies competitive programming. Think about why the write operation in multi-threaded programming is so complicated? Because it is difficult to synchronize the access of threads to a resource (objects or other OS resources). Why is it difficult to synchronize access? Because it is difficult to guarantee that there will be no race between multiple streams. What if there is no write access? In other words, what if the state of the objects to which the threads have access is unchanged? Then there is no need for synchronization.
Another advantage of immutable classes is that they never violate the Lisk substitution principle, here is the definition of the Lisk principle from Wikipedia:
“a subclass should not create new mutators of properties of a base class. If the base class did not provide methods for changing the properties defined in it, a subtype of this class also should not create such methods. In other words, immutable data of the base class should not be mutable in the subclass. "
Here is a list of immutable types in the source code:
6.2. Purity and side effects
The main advantage of immutable types comes from the fact that they eliminate side effects. I cannot say better than Wes Dyer, and I will quote him:
“We all know that using global variables is not a good idea. This is due to the danger of side effects (global scope). Many programmers who do not use global variables do not understand that the same principle applies to fields, properties, parameters, and variables on a more limited scale: do not change them without good reason (...) "
One way to increase the reliability of the module is to get rid of side effects. This makes compiling and integrating modules easier and more reliable. If they do not have side effects, they always work the same way, regardless of the environment. This is called referential transparency.
Write functions and methods without side effects - these will be pure functions that do not modify the object - this will be better in the sense of the correctness of your program.
Here is a list of all methods with no side effects:
More than 100,000 methods are clean.
7. Quality of implementation
7.1. Too big methods
Methods with lots of lines of code are hard to maintain and understand. Let's find methods, more than 60 lines.
The llvm / clang source code contains more than 100,000 methods, and less than 2% of them can be considered too large.
7.2. Methods with a lot of parameters
Several methods have more than 8 parameters.
7.3. Methods with many local variables
Less than 1% of methods have many local variables.
7.4. Too complicated methods
Many metrics exist to detect complex functions, calculate the number of lines of code, the number of parameters, and the number of local variables.
There are also interesting metrics for detecting complex functions:
Cyclomatic complexity is a popular procedural programming metric equal to the number of decisions that are made in a procedure.
Nested depth is a metric defined for a method that determines the maximum depth of nesting of visibility areas in the method body.
Maximum nesting cycles.
The maximum values allowed for these metrics depend more on the choice of the development team; there are no generally accepted standards.
Let's find methods that can be considered complex.
Only 1.5% of the methods are candidates to minimize complexity.
7.5. Difficulty on Halstead
Halstead Complexity is a software metric introduced by Maurice Howard Halstead in 1977. Halstead made the observation that the program metric should reflect the implementation of the algorithm in various languages, but regardless of the platform. These metrics are calculated statically by code.
Halstead introduced many different metrics, consider for example one of them - TimeToImplement, which indicates the time required to program a method in seconds.
2690 methods require more than an hour to implement.
8. RTTI
RTTI is the ability of a system to report a dynamic type of an object and provide type information at runtime (and not at compile time). However, the use of RTTI is controversial in the C ++ community. Many C ++ developers do not use this mechanism.
And what about the llvm / clang development team?
No method uses the dynamic_cast keyword. The llvm / clang development team chose not to use the RTTI engine.
9. Exceptions
Exception support is another controversial feature of C ++. Many well-known open source C ++ projects do not use it.
Let's see if exceptions are thrown somewhere in the code.
Like RTTI, the exception mechanism is not used.
10. Some statistics
10.1. Most popular types
It is interesting to know what are the most used types in the project, since such types should be best designed, implemented, and tested. Any changes in them will affect the project as a whole.
Find them using the TypesUsingMe metric:
There is another interesting metric for finding popular types: TypeRank.
The TypeRank value is calculated by applying the Google PageRank algorithm on the type dependency graph. The center homothety of 0.15 is applied so that the average TypeRank is equal to one.
Types with a high TypeRank should be tested more carefully, because bugs in them can be more disastrous.
Below are the results of all popular types according to the TypeRank metric:
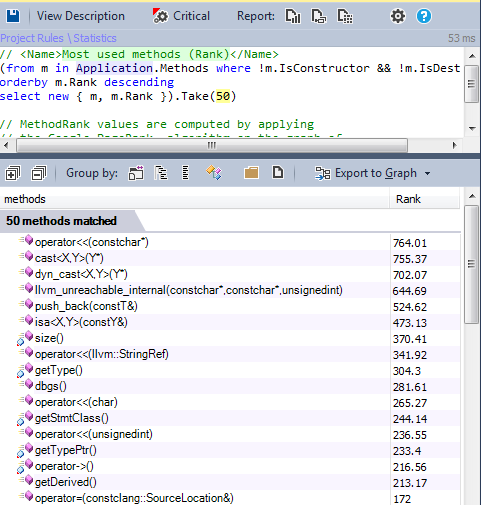
10.2. Most popular methods
10.3. Methods calling many other methods
It is interesting to know which methods call many other methods; this can reveal design problems. In some cases, refactoring is required to make them more readable and easier to maintain.
Summary
LLVM / Clang is very well designed and implemented, and, like for any other project, it can be improved by some refactoring. In this post, we revealed some of the minimal possible changes that can be made in the source code. Don't be afraid to research the source code and improve your C ++ knowledge.