Introduction to Data Vault
Most companies today accumulate various data obtained in the process. Often the data comes from various sources - structured and not very, sometimes in real time, and sometimes they are available in strictly defined periods. All this diversity must be stored in a structured way, so that later it can successfully analyze, draw beautiful reports and notice anomalies in time. For these purposes, a data warehouse (Data Warehouse, DWH) is being designed.
There are several approaches to building such a universal repository that help the architect avoid common problems, and most importantly, ensure the proper level of flexibility and extensibility of DWH. I want to talk about one of these approaches.
Who will be interested in this article?
- Looking for a more functional alternative to the “star” pattern and the Third Normal Form?
- Do you already have a data warehouse, but is it hard to modify?
- Need good support for historicity, and the current architecture is not suitable for this?
- Having trouble collecting data from multiple sources?
If you answered yes to any of these questions, but are not familiar with Data Vault, please look under the cat!
Data Vault is a hybrid approach that combines the advantages of the familiar “star” scheme and 3 normal shapes. This methodology was first announced in 2000 by Dan Linstedt . The approach was invented in the process of developing a data warehouse for the US Department of Defense and has proven itself well. Later, in 2013, Dan announced version 2.0, revised taking into account the rapidly growing popularity of technologies (NoSQL, Hadoop) and the new requirements for DWH. We will talk about Data Vault 2.0.
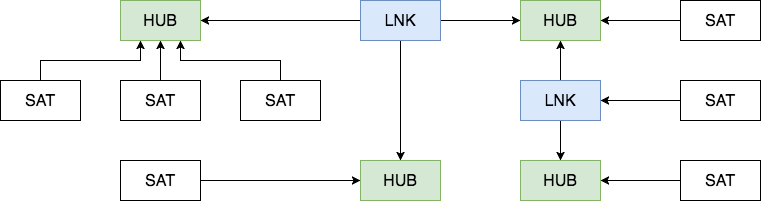
Data Vault consists of three main components - the Hub ,Link and Satellite .
Hub
A hub is a basic representation of an entity (Customer, Product, Order) from a business perspective. The hub table contains one or more fields reflecting the entity in terms of business. Together, these fields are called the “business key.” An ideal candidate for a business key is the organization’s TIN or VIN, and the ID generated by the ID system will be the worst option. A business key must always be unique and unchanging.
The hub also contains the load timestamp and record source meta-fields , which store the time of the initial loading of the entity into the repository and its source (the name of the system, database or file from where the data was downloaded). It is recommended to use the MD5 or SHA-1 hash from the business key as the primary key of the Hub.
Hub Tables
Link
Link tables link multiple hubs with many-to-many relationships. It contains the same metadata as the Hub. The Link may be connected to another Link, but this approach creates problems during loading, so it is better to select one of the Links in a separate Hub.
Link Table
Satellite
All descriptive attributes of the Hub or Links (context) are placed in the Satellite tables. In addition to the context, the Satellite contains a standard set of metadata ( load timestamp and record source ) and one and only one “parent” key. In Satellites, you can easily save the history of the context change, each time adding a new record when updating the context in the source system. To simplify the process of updating a large satellite, a hash diff field can be added to the table : MD5 or SHA-1 hash from all its descriptive attributes. For a Hub or Link, there can be any number of Satellites, usually the context is broken down according to the update frequency. The context from different source systems is usually put in separate satellites.
Satellite Tables
How to work with it?

* The picture is based on an illustration from the book Building a Scalable Data Warehouse with Data Vault 2.0
First, data from operating systems comes in the staging area . The staging area is used as an intermediate in the data loading process. One of the main functions of the Staging zone is to reduce the load on the operational base when executing queries. The tables here completely repeat the original structure, but any restrictions on inserting data, such as not null or checking the integrity of foreign keys, should be turned off in order to leave the ability to insert even damaged or incomplete data (this is especially true for excel tables and other files). Additionally, stage tables contain hashes of business keys and information about load time and data source.
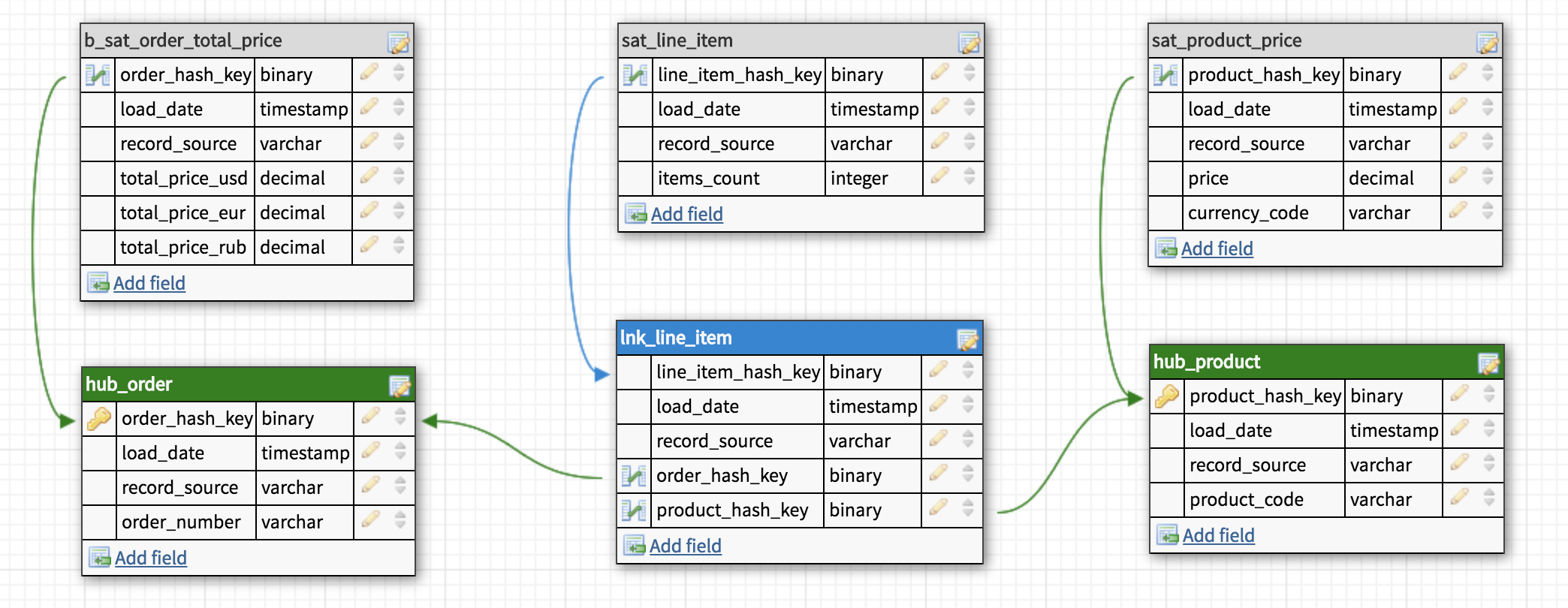
After that, the data is divided into Hubs, Links and Satellites and loaded into the Raw Data Vault . During the download process, they are not aggregated or recalculated in any way.
Business Vault is an optional helper add-on for Raw Data Vault. It is built on the same principles, but contains processed data: aggregated results, converted currencies, etc. The separation is purely logical, physically Business Vault is in the same database as Raw Data Vault and is intended mainly to simplify the formation of storefronts.
Business Satellite
b_sat_order_total_price
When the desired tables have been created and filled, it is the turn of data marts ( the Data Marts ) . Each showcase is a separate database or scheme designed to solve the problems of various users or departments. It may have a specially assembled “star” or a collection of denormalized tables. If possible, it is better to make tables inside the windows virtual, that is, computed on the fly. For this, SQL views are usually used.
Filling Data Vault
Here, everything is quite simple: Hubs are loaded first, then Links and then Satellites. Hubs can be loaded in parallel, as well as Satellites and Links, unless of course link-to-link is used.
There is an option to completely turn off the integrity check and load all the data at the same time. Just such an approach corresponds to one of DV's main tenets - “Load all of the data all the time (Load all of the data, all of the time)” and this is where business keys play a decisive role. The bottom line is that possible problems when loading data should be minimized, and one of the most common problems is a violation of integrity. The approach, of course, is controversial, but I personally use it and find it really convenient: the data is still checked, but after downloading. Often you may encounter the problem of the absence of entries in several Hubs when loading Links and sequentially figure out why a particular Hub is not completely filled, restarting the process and studying a new error. An alternative is to display the missing data after loading and see all the problems at once. As a bonus, we get error tolerance and the ability not to follow the loading order of tables.
Advantages and disadvantages
[+] Flexibility and extensibility.
With Data Vault, both expanding the storage structure and adding and matching data from new sources is no longer a problem. The most complete storage of raw data and a convenient storage structure allow us to create a showcase for any business requirements, and existing solutions in the DBMS market can cope with huge amounts of information and quickly fulfill even very complex queries, which makes it possible to virtualize most storefronts.
[+] Agile approach out of the box.
Modeling storage using the Data Vault methodology is quite simple. The new data simply “connects” to the existing model without breaking or modifying the existing structure. At the same time, we will solve the task as isolated as possible, loading only the necessary minimum, and, probably, our time estimate for such a task will become more accurate. Sprint planning will be easier, and the results are predictable from the first iteration.
[-] The abundance of JOINs
Due to the large number of join operations, queries can be slower than in traditional data warehouses, where tables are denormalized.
[-] Difficulty.
In the methodology described above, there are many important details that are unlikely to figure out in a couple of hours. To this we can add a small amount of information on the Internet and an almost complete lack of materials in Russian (I hope to fix this). As a result, when introducing Data Vault there are problems with the training of the team, many questions arise regarding the nuances of a particular business. Fortunately, there are resources where you can ask these questions. A big lack of complexity is a mandatory requirement for the presence of data marts, since the Data Vault itself is not suitable for direct queries.
[-] Redundancy.
Quite a controversial flaw, but I often see questions about redundancy, so I will comment on this point from my point of view.
Many people don’t like the idea of creating a layer in front of data marts, especially considering that there are about 3 times more tables in this layer than it could be in the third normal form, which means 3 times more ETL processes. This is true, but ETL processes themselves will be much simpler due to their uniformity, and all objects in the repository are quite simple to understand.
The seemingly redundant architecture is built to solve very specific problems, and of course is not a silver bullet. In any case, I would not recommend changing anything until the benefits of Data Vault described above are in demand.
In custody
In this article, I mentioned only the main components of Data Vault - the minimum required for an introductory article. Behind the scenes were Point in time and Bridge tables, features and rules for selecting business key components, and a method for tracking deleted records. I plan to talk about them in the next article, if the topic is of interest to the community.