Learning with reinforcement in Python
- Transfer
Hello colleagues!

In the last publication of the outgoing year, we would like to mention Reinforcement Learning, a topic on which we are already translating a book .
Judge for yourself: there was an elementary article with Medium, which sets out the context of the problem, describes the simplest algorithm with implementation in Python. The article has several gifs. And the motivation, reward and choice of the right strategy on the road to success are things that will be extremely useful in the coming year to each of us.
Enjoy reading!
Reinforcement training is a type of machine learning in which an agent learns to act in the environment, performing actions and thereby gaining intuition, and then observes the results of his actions. In this article, I will tell you how to understand and formulate a reinforcement training task, and then solve it in Python.
Recently, we have become accustomed to the fact that computers play games against humans - either as bots in multiplayer games, or as rivals in one-on-one games: for example, in Dota2, PUB-G, Mario. Deepmind Research Companymade a stir in the news, when in 2016 their program AlphaGo in 2016 overcame the South Korean champion in go. If you are an avid gamer, you could hear about the Dota 2 OpenAI Five top five matches, where cars fought against people and overcame the best Dota2 players in several matches. (If you are interested in the details, the algorithm is analyzed in detail here and it is examined how the machines played).

The latest version of OpenAI Five takes Roshan .
So let's start with the central question. Why do we need reinforcement training? Is it used only in games, or is it applicable in realistic scenarios for solving applied problems? If for the first time you read about learning with reinforcement, then you simply cannot imagine the answer to these questions. After all, reinforcement learning is one of the most widely used and rapidly developing technologies in the field of artificial intelligence.
Here are a number of subject areas in which reinforced learning systems are particularly in demand:
Overview and origin of learning with reinforcement
So, how did the phenomenon of learning with reinforcement form when we have so many methods of machine and deep learning at our disposal? "He was invented by Rich Sutton and Andrew Barto, the supervisor of Rich who helped him prepare the PhD." The paradigm took shape for the first time in the 1980s and was then archaic. Subsequently, Rich believed that she had a great future, and she would eventually receive recognition.
Reinforcement learning supports automation in the environment where it is implemented. Some also operate both machine and deep learning - they are strategically arranged differently, but both paradigms support automation. So why did reinforcement training come about?
It is very similar to the natural learning process, in which the process / model operates and receives feedback on how it manages to cope with the task: good and not.
Machine and deep learning are also learning options, however, they are more focused on identifying patterns in the available data. In reinforcement training, on the other hand, such experience is gained through trial and error; the system gradually finds the right options or a global optimum. A significant added benefit of learning with reinforcement is that in this case it is not necessary to provide an extensive set of training data, as in training with a teacher. Enough will be a few small fragments.
The concept of learning with reinforcement
Imagine teaching your cats new tricks; but, unfortunately, cats do not understand the human language, so you can’t take it and tell them what you are going to play with. Therefore, you will act differently: imitate the situation, and the cat in response will try to react in one way or another. If the cat responded the way you wanted, then you pour milk on it. Do you understand what will happen next? Once again in a similar situation, the cat will once again perform the desired action, and with even greater enthusiasm, hoping that it will feed even better. This is how learning takes place on a positive example; but, if you try to “educate” a cat with negative stimuli, for example, look at it strictly and frown, it usually does not train in such situations.
Similarly, reinforcement training works. We tell the machine some input and actions, and then reward the machine depending on the output. Our ultimate goal is maximizing rewards. Now let's look at how to reformulate the above problem in terms of reinforced learning.
Now, having understood what reinforcement learning is, let's talk in detail about the origins and evolution of reinforcement learning and deep learning with reinforcement, we will discuss how this paradigm allows us to solve problems that are very difficult to train with or without a teacher, and also note the following a curious fact: at present, Google search engine is optimized with the use of reinforcement learning algorithms.
Introduction to reinforcement learning terminology
Agent and Environment play key roles in the reinforcement learning algorithm. The environment is the world in which the Agent has to survive. In addition, the Agent receives back-up signals (reward) from the Environment: this is a number that characterizes how good or bad the current state of the world can be considered. The goal of the Agent is to maximize the total remuneration, the so-called “winnings”. Before writing our first algorithms for reinforcement learning, you need to understand the following terminology.

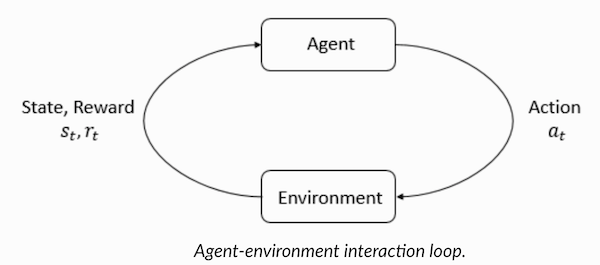
Now, having become familiar with the terminology of learning with reinforcement, let's solve the problem using the appropriate algorithms. Before this, it is necessary to understand how to formulate such a task, and in solving this problem, rely on the terminology of training with reinforcement.
The solution to the problem of a taxi
So, we proceed to the solution of the problem with the use of supporting algorithms.
Suppose we have an area for training an unmanned taxi that we train to deliver passengers to the parking at four different points (
The environment for solving the problem with a taxi can be configured using the Gymfrom the OpenAI company is one of the most popular libraries for solving problems in reinforcement learning. Well, before using the gym, you need to install it on your machine, and for this, the Python package manager called pip is convenient. Below is the installation command.
Next, let's see how our environment will be displayed. All models and interface for this task are already configured in the gym and are named for
“We have 4 locations (indicated by different letters); our task is to catch the passenger at one point and drop him off at another. We get +20 points for a successful disembarkation of a passenger and lose 1 point for each step spent on it. A penalty of 10 points is also provided for each unintended embarkation and disembarkation of a passenger. ”(Source: gym.openai.com/envs/Taxi-v2 )
Here is the conclusion we will see in our console:

Taxi V2 ENV
Excellent,
So, having considered the environment, let's try to understand the task more deeply. Taxi - the only car in this parking. Parking can be divided into a grid
There are 4 points in the environment where passengers are allowed to disembark: this is:
So, in our environment for a taxi there are 5 × 5 × 5 × 4 = 500 possible states. The agent deals with one of 500 states and takes action. In our case, the options are as follows: moving in one direction or another, or the decision to pick up / drop off the passenger. In other words, we have six possible actions at our disposal:
pickup, drop, north, east, south, west (The last four values are directions in which a taxi can move.)
This space
As is clear from the illustration above, taxis cannot perform certain actions in certain situations (walls interfere). In the code describing the environment, we simply assign a penalty of -1 for each hit in the wall, and a taxi, when faced with a wall. Thus, such penalties will accumulate, so the taxi will try not to crash into the walls.
Table of rewards: When creating a “taxi” environment, a primary table of rewards is also created called P. It can be considered a matrix, where the number of states corresponds to the number of rows, and the number of actions to the number of columns. Ie, we are talking about the matrix
Since absolutely all states are recorded in this matrix, you can view the default values of the awards assigned to the state that we chose to illustrate:
The structure of the dictionary is as follows:
To solve this problem without any reinforcement training, you can set a target state, sample the spaces, and then, if you can reach the target state in a certain number of iterations, assume that this moment corresponds to the maximum reward. In other states, the value of remuneration is either nearing the maximum if the program acts correctly (approaches the goal) or accumulates penalties if it makes mistakes. Moreover, the value of the penalty can reach no lower than -10.
Let's write the code to solve this problem without learning with reinforcement.
Since we have a P-table with default remuneration values for each state, we can try to navigate our taxi simply on the basis of this table.
We create an infinite loop that progresses until the passenger gets to the destination (one episode), or, in other words, until the reward rate reaches 20. The method
Conclusion:
credits: OpenAI
The problem is solved, but not optimized, or this algorithm will not work in all cases. We need a suitable interacting agent so that the number of iterations spent by the machine / algorithm on solving the problem remains minimal. Here we will be helped by the Q-learning algorithm, the implementation of which we will consider in the next section.
Introduction to Q-learning
Below is the most popular and one of the most simple algorithms for learning with reinforcement. The medium rewards the agent for gradual learning and for making the most optimal step in a particular state. In the implementation discussed above, we had a table of rewards “P”, according to which our agent will study. Based on the reward table, he chooses the next action depending on how useful it is, and then updates another value, called a Q-value. As a result, a new table is created, called a Q-table, displayed on a combination (Status, Action). If the Q-values are better, then we get more optimized rewards.
For example, if a taxi is in a state where the passenger is at the same point as the taxi, it is extremely likely that the Q-value for the “pick up” action is higher than for other actions, for example, “disembark the passenger” or “go north ".
Q-values are initialized with random values, and as the agent interacts with the environment and receives various rewards by performing certain actions, the Q-values are updated according to the following equation:

This raises the question: how to initialize the Q-values and how count them. As actions are performed, Q values are performed in this equation.
Here Alpha and Gamma are the parameters of the algorithm for Q-learning. Alpha is the pace of learning, and gamma is the discounting factor. Both values can range from 0 to 1 and sometimes equal to one. Gamma can be equal to zero, and alpha - can not, because the value of the loss during the update must be compensated (the pace of learning is positive). The alpha value here is the same as when training with a teacher. Gamma determines how important we want to give the rewards that await us in the future.
This algorithm is summarized below:
Q-learning in Python
Great, now all your values will be stored in a variable
So, your model is trained in environmental conditions, and now knows how to more accurately select passengers. And you got acquainted with the phenomenon of learning with reinforcement, and you can program the algorithm to solve the new problem.
Other reinforcement learning techniques:
The code for this exercise is located at:
vihar / python-reinforcement-learning
In the last publication of the outgoing year, we would like to mention Reinforcement Learning, a topic on which we are already translating a book .
Judge for yourself: there was an elementary article with Medium, which sets out the context of the problem, describes the simplest algorithm with implementation in Python. The article has several gifs. And the motivation, reward and choice of the right strategy on the road to success are things that will be extremely useful in the coming year to each of us.
Enjoy reading!
Reinforcement training is a type of machine learning in which an agent learns to act in the environment, performing actions and thereby gaining intuition, and then observes the results of his actions. In this article, I will tell you how to understand and formulate a reinforcement training task, and then solve it in Python.
Recently, we have become accustomed to the fact that computers play games against humans - either as bots in multiplayer games, or as rivals in one-on-one games: for example, in Dota2, PUB-G, Mario. Deepmind Research Companymade a stir in the news, when in 2016 their program AlphaGo in 2016 overcame the South Korean champion in go. If you are an avid gamer, you could hear about the Dota 2 OpenAI Five top five matches, where cars fought against people and overcame the best Dota2 players in several matches. (If you are interested in the details, the algorithm is analyzed in detail here and it is examined how the machines played).
The latest version of OpenAI Five takes Roshan .
So let's start with the central question. Why do we need reinforcement training? Is it used only in games, or is it applicable in realistic scenarios for solving applied problems? If for the first time you read about learning with reinforcement, then you simply cannot imagine the answer to these questions. After all, reinforcement learning is one of the most widely used and rapidly developing technologies in the field of artificial intelligence.
Here are a number of subject areas in which reinforced learning systems are particularly in demand:
- Unmanned vehicles
- Game industry
- Robotics
- Recommender systems
- Advertising and marketing
Overview and origin of learning with reinforcement
So, how did the phenomenon of learning with reinforcement form when we have so many methods of machine and deep learning at our disposal? "He was invented by Rich Sutton and Andrew Barto, the supervisor of Rich who helped him prepare the PhD." The paradigm took shape for the first time in the 1980s and was then archaic. Subsequently, Rich believed that she had a great future, and she would eventually receive recognition.
Reinforcement learning supports automation in the environment where it is implemented. Some also operate both machine and deep learning - they are strategically arranged differently, but both paradigms support automation. So why did reinforcement training come about?
It is very similar to the natural learning process, in which the process / model operates and receives feedback on how it manages to cope with the task: good and not.
Machine and deep learning are also learning options, however, they are more focused on identifying patterns in the available data. In reinforcement training, on the other hand, such experience is gained through trial and error; the system gradually finds the right options or a global optimum. A significant added benefit of learning with reinforcement is that in this case it is not necessary to provide an extensive set of training data, as in training with a teacher. Enough will be a few small fragments.
The concept of learning with reinforcement
Imagine teaching your cats new tricks; but, unfortunately, cats do not understand the human language, so you can’t take it and tell them what you are going to play with. Therefore, you will act differently: imitate the situation, and the cat in response will try to react in one way or another. If the cat responded the way you wanted, then you pour milk on it. Do you understand what will happen next? Once again in a similar situation, the cat will once again perform the desired action, and with even greater enthusiasm, hoping that it will feed even better. This is how learning takes place on a positive example; but, if you try to “educate” a cat with negative stimuli, for example, look at it strictly and frown, it usually does not train in such situations.
Similarly, reinforcement training works. We tell the machine some input and actions, and then reward the machine depending on the output. Our ultimate goal is maximizing rewards. Now let's look at how to reformulate the above problem in terms of reinforced learning.
- The cat acts as an “agent” exposed to the “environment”.
- The environment is a home or play area, depending on what you are teaching the cat.
- Situations arising from training are called “states”. In the case of a cat, examples of states are when the cat "runs" or "crawls under the bed."
- Agents react by performing actions and moving from one “state” to another.
- After changing the state, the agent receives a “reward” or “fine” depending on the action he has taken.
- “Strategy” is a method of choosing an action to get the best results.
Now, having understood what reinforcement learning is, let's talk in detail about the origins and evolution of reinforcement learning and deep learning with reinforcement, we will discuss how this paradigm allows us to solve problems that are very difficult to train with or without a teacher, and also note the following a curious fact: at present, Google search engine is optimized with the use of reinforcement learning algorithms.
Introduction to reinforcement learning terminology
Agent and Environment play key roles in the reinforcement learning algorithm. The environment is the world in which the Agent has to survive. In addition, the Agent receives back-up signals (reward) from the Environment: this is a number that characterizes how good or bad the current state of the world can be considered. The goal of the Agent is to maximize the total remuneration, the so-called “winnings”. Before writing our first algorithms for reinforcement learning, you need to understand the following terminology.
- States : A state is a complete description of the world in which not a single piece of information characterizing this world has been omitted. This can be a position, fixed or dynamic. As a rule, such states are written in the form of arrays, matrices or tensors of higher order.
- Action : The action usually depends on environmental conditions, and the agent will take different actions in different environments. The set of valid agent actions is recorded in a space called an “action space”. As a rule, the number of actions in space, of course.
- Wednesday : This is the place where the agent exists and interacts with. For different environments, different types of rewards, strategies, etc. are used.
- Reward and win : It is necessary to constantly monitor the reward function R when training with reinforcements. It is critical when setting up an algorithm, optimizing it, and also when you stop learning. It depends on the current state of the world, the action just taken and the next state of the world.
- Strategies : Strategy is the rule according to which the agent chooses the next action. A set of strategies is also referred to as an agent “brain”.
Now, having become familiar with the terminology of learning with reinforcement, let's solve the problem using the appropriate algorithms. Before this, it is necessary to understand how to formulate such a task, and in solving this problem, rely on the terminology of training with reinforcement.
The solution to the problem of a taxi
So, we proceed to the solution of the problem with the use of supporting algorithms.
Suppose we have an area for training an unmanned taxi that we train to deliver passengers to the parking at four different points (
R,G,Y,B). Before this, you need to understand and set the environment in which we start programming in Python. If you are just starting to learn Python, I recommend this article . The environment for solving the problem with a taxi can be configured using the Gymfrom the OpenAI company is one of the most popular libraries for solving problems in reinforcement learning. Well, before using the gym, you need to install it on your machine, and for this, the Python package manager called pip is convenient. Below is the installation command.
pip install gymNext, let's see how our environment will be displayed. All models and interface for this task are already configured in the gym and are named for
Taxi-V2. The following code snippet is used to display this environment.“We have 4 locations (indicated by different letters); our task is to catch the passenger at one point and drop him off at another. We get +20 points for a successful disembarkation of a passenger and lose 1 point for each step spent on it. A penalty of 10 points is also provided for each unintended embarkation and disembarkation of a passenger. ”(Source: gym.openai.com/envs/Taxi-v2 )
Here is the conclusion we will see in our console:
Taxi V2 ENV
Excellent,
envthis is the heart of OpenAi Gym, represents is a unified environment interface. The following are env methods that will be very useful to us env.reset:: dumps the environment and returns a random initial state. env.step(action): Promotes environmental development one step in time.env.step(action): returns the following variables observation: Observation of the environment.reward: Describes whether your action was helpfuldone: Indicates whether we were able to correctly pick up and disembark the passenger, also referred to as “one episode”.info: Additional information, such as performance and latency, for debugging purposes.env.render: Displays a single frame of the medium (useful for rendering)
So, having considered the environment, let's try to understand the task more deeply. Taxi - the only car in this parking. Parking can be divided into a grid
5x5, where we get 25 possible taxi locations. These 25 values are one of the elements of our state space. Please note: at the moment our taxi is located at coordinates (3, 1). There are 4 points in the environment where passengers are allowed to disembark: this is:
R, G, Y, Bor[(0,0), (0,4), (4,0), (4,3)]in coordinates (horizontally; vertically), if it were possible to interpret the above medium in Cartesian coordinates. If we also take into account one more (1) passenger state: inside the taxi, then we can take all combinations of the locations of passengers and their destinations to calculate the total number of states in our environment for taxi training: we have four (4) destinations and five (4+ 1) passenger locations. So, in our environment for a taxi there are 5 × 5 × 5 × 4 = 500 possible states. The agent deals with one of 500 states and takes action. In our case, the options are as follows: moving in one direction or another, or the decision to pick up / drop off the passenger. In other words, we have six possible actions at our disposal:
pickup, drop, north, east, south, west (The last four values are directions in which a taxi can move.)
This space
action space: a collection of all the actions that our agent can take in a given state. As is clear from the illustration above, taxis cannot perform certain actions in certain situations (walls interfere). In the code describing the environment, we simply assign a penalty of -1 for each hit in the wall, and a taxi, when faced with a wall. Thus, such penalties will accumulate, so the taxi will try not to crash into the walls.
Table of rewards: When creating a “taxi” environment, a primary table of rewards is also created called P. It can be considered a matrix, where the number of states corresponds to the number of rows, and the number of actions to the number of columns. Ie, we are talking about the matrix
states × actions. Since absolutely all states are recorded in this matrix, you can view the default values of the awards assigned to the state that we chose to illustrate:
>>> import gym
>>> env = gym.make("Taxi-v2").env
>>> env.P[328]
{0: [(1.0, 433, -1, False)],
1: [(1.0, 233, -1, False)],
2: [(1.0, 353, -1, False)],
3: [(1.0, 333, -1, False)],
4: [(1.0, 333, -10, False)],
5: [(1.0, 333, -10, False)]
}The structure of the dictionary is as follows:
{action: [(probability, nextstate, reward, done)]}.- Values 0–5 correspond to the actions (south, north, east, west, pickup, dropoff) that a taxi can perform in the current state shown in the illustration.
- done allows you to judge when we successfully disembarked the passenger at the desired point.
To solve this problem without any reinforcement training, you can set a target state, sample the spaces, and then, if you can reach the target state in a certain number of iterations, assume that this moment corresponds to the maximum reward. In other states, the value of remuneration is either nearing the maximum if the program acts correctly (approaches the goal) or accumulates penalties if it makes mistakes. Moreover, the value of the penalty can reach no lower than -10.
Let's write the code to solve this problem without learning with reinforcement.
Since we have a P-table with default remuneration values for each state, we can try to navigate our taxi simply on the basis of this table.
We create an infinite loop that progresses until the passenger gets to the destination (one episode), or, in other words, until the reward rate reaches 20. The method
env.action_space.sample()automatically selects a random action from the set of all available actions. Consider what happens:import gym
from time import sleep
# Создаем thr env
env = gym.make("Taxi-v2").env
env.s = 328# Устанавливаем в ноль количество итераций, штрафы и вознаграждение,
epochs = 0
penalties, reward = 0, 0
frames = []
done = Falsewhilenot done:
action = env.action_space.sample()
state, reward, done, info = env.step(action)
if reward == -10:
penalties += 1# Каждый отображенный кадр помещаем в словарь для анимации
frames.append({
'frame': env.render(mode='ansi'),
'state': state,
'action': action,
'reward': reward
}
)
epochs += 1
print("Timesteps taken: {}".format(epochs))
print("Penalties incurred: {}".format(penalties))
# Выводим все возможные действия, состояния, вознагражденияdefframes(frames):for i, frame in enumerate(frames):
clear_output(wait=True)
print(frame['frame'].getvalue())
print(f"Timestep: {i + 1}")
print(f"State: {frame['state']}")
print(f"Action: {frame['action']}")
print(f"Reward: {frame['reward']}")
sleep(.1)
frames(frames)
Conclusion:
credits: OpenAI
The problem is solved, but not optimized, or this algorithm will not work in all cases. We need a suitable interacting agent so that the number of iterations spent by the machine / algorithm on solving the problem remains minimal. Here we will be helped by the Q-learning algorithm, the implementation of which we will consider in the next section.
Introduction to Q-learning
Below is the most popular and one of the most simple algorithms for learning with reinforcement. The medium rewards the agent for gradual learning and for making the most optimal step in a particular state. In the implementation discussed above, we had a table of rewards “P”, according to which our agent will study. Based on the reward table, he chooses the next action depending on how useful it is, and then updates another value, called a Q-value. As a result, a new table is created, called a Q-table, displayed on a combination (Status, Action). If the Q-values are better, then we get more optimized rewards.
For example, if a taxi is in a state where the passenger is at the same point as the taxi, it is extremely likely that the Q-value for the “pick up” action is higher than for other actions, for example, “disembark the passenger” or “go north ".
Q-values are initialized with random values, and as the agent interacts with the environment and receives various rewards by performing certain actions, the Q-values are updated according to the following equation:
This raises the question: how to initialize the Q-values and how count them. As actions are performed, Q values are performed in this equation.
Here Alpha and Gamma are the parameters of the algorithm for Q-learning. Alpha is the pace of learning, and gamma is the discounting factor. Both values can range from 0 to 1 and sometimes equal to one. Gamma can be equal to zero, and alpha - can not, because the value of the loss during the update must be compensated (the pace of learning is positive). The alpha value here is the same as when training with a teacher. Gamma determines how important we want to give the rewards that await us in the future.
This algorithm is summarized below:
- Step 1: we initialize the Q-table, filling it with zeros, and for Q-values we set arbitrary constants.
- Step 2: Now let the agent react to the environment and try different actions. For each state change, select one of all actions possible in a given state (S).
- Step 3: We proceed to the next state (S ') according to the results of the previous action (a).
- Step 4: For all possible actions from state (S '), choose the one with the highest Q-value.
- Step 5: Update the values of the Q-table according to the above equation.
- Step 6: Turn the next state into the current one.
- Step 7: If the target state is reached, end the process and then repeat.
Q-learning in Python
import gym
import numpy as np
import random
from IPython.display import clear_output
# Инициализируем Taxi-V2 Env
env = gym.make("Taxi-v2").env
# Инициализируем произвольные значения
q_table = np.zeros([env.observation_space.n, env.action_space.n])
# Гиперпараметры
alpha = 0.1
gamma = 0.6
epsilon = 0.1
all_epochs = []
all_penalties = []
for i in range(1, 100001):
state = env.reset()
# Инициализируем переменные
epochs, penalties, reward, = 0, 0, 0
done = Falsewhilenot done:
if random.uniform(0, 1) < epsilon:
# Проверяем пространство действий
action = env.action_space.sample()
else:
# Проверяем изученные значения
action = np.argmax(q_table[state])
next_state, reward, done, info = env.step(action)
old_value = q_table[state, action]
next_max = np.max(q_table[next_state])
# Обновляем новое значение
new_value = (1 - alpha) * old_value + alpha * \
(reward + gamma * next_max)
q_table[state, action] = new_value
if reward == -10:
penalties += 1
state = next_state
epochs += 1if i % 100 == 0:
clear_output(wait=True)
print("Episode: {i}")
print("Training finished.")
Great, now all your values will be stored in a variable
q_table. So, your model is trained in environmental conditions, and now knows how to more accurately select passengers. And you got acquainted with the phenomenon of learning with reinforcement, and you can program the algorithm to solve the new problem.
Other reinforcement learning techniques:
- Markov decision processes (MDP) and Bellman equations
- Dynamic programming: model-based RL, iteration over strategies, and iteration over values
- Deep Q-learning
- Gradient Descent Strategies
- SARSA
The code for this exercise is located at:
vihar / python-reinforcement-learning