In-memory databases: application, scaling and important additions
We continue to experiment with the format of the meetings. Recently, in the boxing ring, we encountered a centralized data bus and Service Mesh. This time they decided to try something more peaceful - StandUp, that is, an open microphone. The topic was chosen in-memory database.

When should I switch to in-memory? How and why to scale? And what should I pay attention to? Answers in the speeches of speakers, which we will highlight in this post.
But first, let's introduce the speakers:
Current trends in the financial market impose much more stringent requirements on response time and the operation of process automation in general. In addition, almost all major financial institutions today are striving to build their own ecosystems.
In this regard, we see for ourselves two main applications of in-memory solutions. First, it is caching integration data. According to the classic scenario, in large companies there are several automated systems that provide data upon user request. Or external system - but in this case, the initiator in most cases is the user. Traditionally, these systems stored data structured in a specific way in the database, accessing it on request.
Today, such systems no longer meet the requirements in terms of load. Here you should not forget about remote calls of these systems by consumer systems. Hence the need to revise the approaches to storing and presenting data - users, automated systems, or individual services. Logical output - storing actual data used by services at the in-memory layer level; There are quite a few such successful cases on the market.
This was the first case. The second is effective, from a technical point of view, business process management. Traditional BPM systems automate the execution of certain operations in accordance with a predetermined algorithm. And in many cases there are questions: why are these systems working insufficiently and insufficiently quickly?
As a rule, such systems write their every step (or a small set of steps, designed in the form of a business transaction) to the database. So they are tied to the response time and interaction with these systems. Now the number of instances of business processes running simultaneously in real time, orders of magnitude more than 10 years ago. So modern business process management systems should have significantly better performance and ensure execution of decentralized applications. Moreover, today all companies are moving towards the formation of a large microservice environment. The challenge is that different instances of business processes can share and efficiently use operational data. As part of the orchestration, it makes sense to store them in an in-memory solution.
Suppose that we have a huge number of nodes and services, that a number of business processes are running, the actions of which are implemented in the form of microservices. To improve performance, each of them begins to write its state in a local copy of memory. We get a large number of local copies. How to ensure relevance and consistency for all?
We use in-memory zoning areas. For example, depending on the business domain. When we cut a business domain, we determine that certain microservices / business processes work only within the framework of the zone that is responsible for the corresponding domain. So we can speed up the update of the cache and all the work of in-memory solutions.
At the same time, the cache responsible for the domain works in full replication mode - the limited number of nodes due to domain distribution ensures the speed and accuracy of the solution in this mode. Zoning and maximum fragmentation helps solve synchronization problems, cluster operation, etc. on a large total number of nodes.
There are often natural questions about the reliability of in-memory solutions. Yes, you can not put everything there. In order to ensure reliability, we always have databases next to in-memory. For example, for important issues with reporting that need to be brought together, which can be difficult on a large number of nodes. So our vision for today: a synergy of two approaches .
It is also worth noting that these two approaches are also not entirely correct only to oppose. And at the same time, close on them. Manufacturers and contributors of modern virtualization systems in container mode, such as Kubernetes, already provide us with options for long-term secure storage. Good industrial case studies have already appeared on the implementation of solutions in which storage is carried out in a similar virtualized format.
One of the largest US newspapers provides an opportunity for its readers to get online any number that has been published since the launch of the publication of this newspaper in the 19th century. We can imagine the level of load. Storage is implemented by them through the Apache Kafka platform deployed in Kubernetes. Here is another option for storing information and providing access to it under a large load to a large number of clients. When designing new solutions, this option is also worth paying attention to.
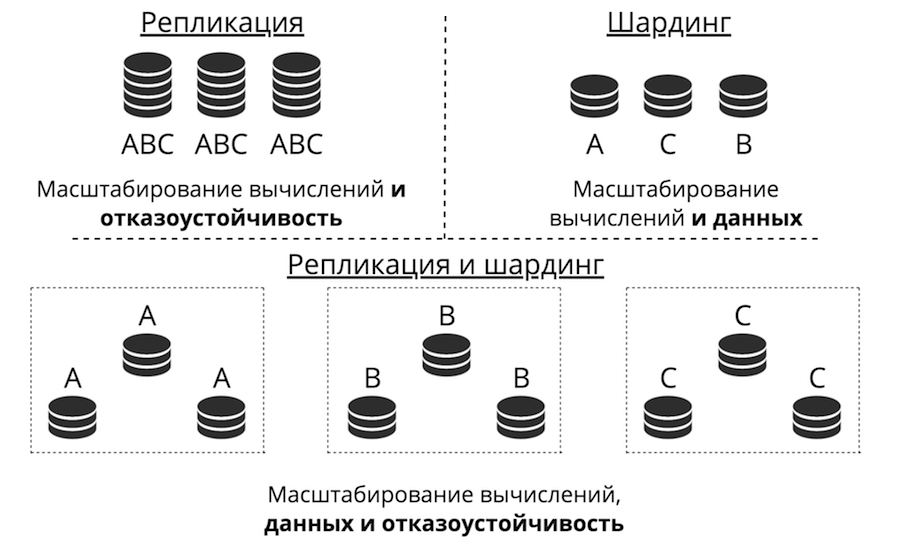
Suppose we have a server. It accepts requests, stores data. Suddenly, requests and data becomes larger, the server ceases to cope with the load. You can upload more hardware to the server and it will accept more requests. But this is a dead-end path for three reasons at once: high cost, limited technical capabilities and problems with resiliency. Instead, there is horizontal scaling: “friends” come to the server to help him complete tasks. The two main types of horizontal scaling are replication and sharding.
Replication - when there are many servers, they all store the same data and client requests are scattered across all of these servers. This is how calculations are scaled, not data. This works when data is placed on one node, but there are so many client requests that one server cannot cope. It also greatly increases resiliency.
Sharding is used to scale data: many servers are made and they store different data. So you scale both calculations and data. But failover in this case is low. If one server fails, then part of the data will be lost.
There is a third approach - to combine them. We divide the cluster into subclusters, call them replica sets. The same data is stored in each of them, and the data does not overlap between replica sets. The result is both data scaling, and computing, and fault tolerance.
Replication is of two types: asynchronous and synchronous. Asynchronous is when client requests are not waiting for data to be scattered across replicas: there are enough entries for one replica. As soon as the data is on the disk, in the log, the transaction is completed successfully and sometime in the background this data is replicated. Synchronous - when a transaction is divided into 2 phases: prepare and commit. Commit will not return success until data is replicated to some replica quorum.
Asynchronous replication is obviously faster, because nothing rests on the network. Data will be sent to the network in the background, and the transaction itself, as recorded in the log, is completed. But there is a problem: replicas can lag from each other, appear out of sync.
Synchronous replication is more reliable, but much slower and more difficult to implement. There are complex protocols. In Tarantool, you can select any of these types of replication, depending on the task.

The backlog of replicas causes not only desynchronization, but also the problem of the master's ignorance: he does not know how to give his changes to the replica. Changes are usually given incrementally - they are applied, and in the same form they fly away to the replica. But what to do with them if the replica is not available? For example, in Tarantool everything can be customized, and the master becomes very flexible.
Another challenge: how to make the topology complex? In Mail.ru, for example, there is a topology with hundreds of Tarantool. It has a tarantool core to which tarantulas replicas for backups are attached in a circle. In Tarantool, you can make completely arbitrary topologies, replication lives well with this.
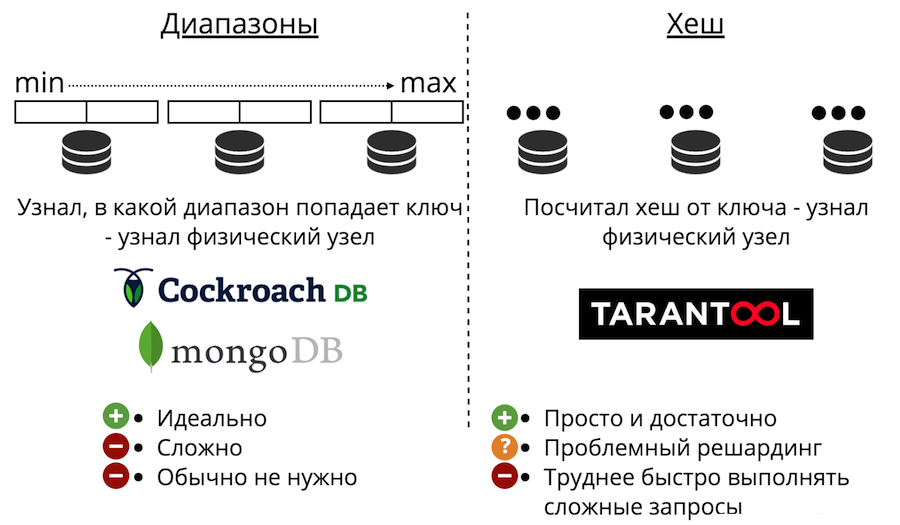
We now turn to data scaling: sharding. It is of two types: ranges and hashes. Sharding by ranges is when all data is sorted by some sharding key, and this large sequence is divided into ranges so that there is approximately the same amount of data in each range. And each range is entirely stored on any one physical node. But usually such a sharding is not needed. Besides, it is always very complicated.
There is also sharding with hashes. It is just represented in Tarantool. It is much easier to implement, use and almost always fits instead of sharding with ranges. It works like this: we consider the hash function to be written to and it returns the number of the physical node to which to save. There are problems: firstly, it is difficult to quickly complete a complex query.
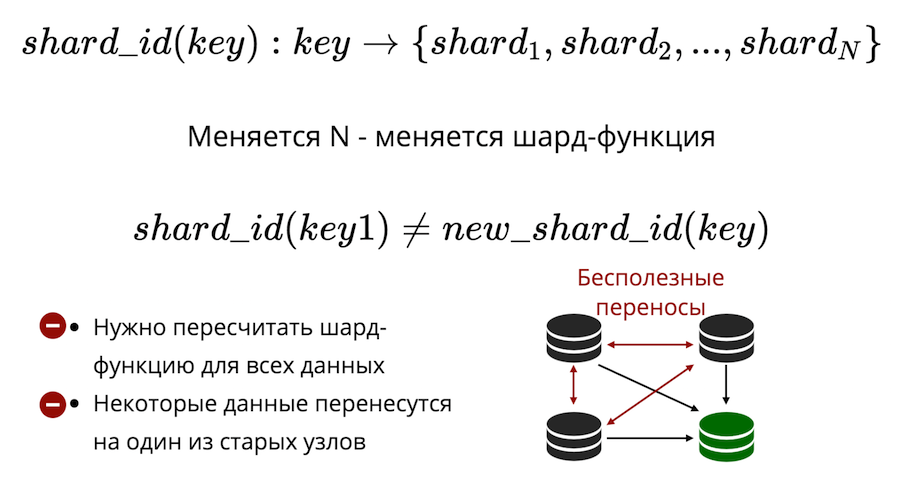
Secondly, there is the problem of resharing. There is some kind of shard function that returns the number of the physical shard to which the key should be stored. And when the number of nodes changes, the shard function also changes. This means that for all the data in the cluster, it will have to be recalculated and verified. Moreover, in classical sharding some data will not be transferred to the new node, but will simply be shuffled between the old nodes. Useless hyphenation can not be reduced to zero in the classic sharding.
In Tarantool, virtual sharding is used: data is distributed not by physical nodes, but by virtual ones. Virtual baketas in a virtual cluster. And virtual storadzhi decomposed on physical. And already there it is guaranteed that each virtual stack lies entirely on any one physical stack.
How does this solve the problem of resharing? The fact is that the number of buckets is fixed and seriously exceeds the number of physical nodes. Thus, no matter how much you physically scale your cluster, there will always be enough buckets to store data and distribute it evenly. And due to the fact that the shard function is unchanged, when changing the composition of the cluster will not have to recalculate it.
As a result, we get three types of sharding: ranges, hashes and virtual buckets. In the case of ranges and bucks, there is a physical search problem.
How to solve it? The first way: just ban rewarding. Then for resarding you have to create a new cluster and transfer everything there. The second way: always go to all nodes. But this makes no sense, because you need to scale, and the calculations do not scale like that. The third option: a proxy module, which serves as a sort of baket router. You start it, send a request there, specifying the number of the batch, and it will send your request as a proxy to the desired physical node.
Business has additional database requirements. He wants it all to be sluggish and disaster proof. He wants high availability: so that nothing is ever lost, so that you can quickly recover. You also need easy and cheap scalability, simple support, platform trust and effective access mechanisms.
All these ideas are not new. Many of these things are more or less implemented in classical DBMS, in particular, replication between data centers.
In-Memory is no longer a technology “start-up”, it is mature products that are used in the largest companies around the world (Barclays, Citi Group, Microsoft, etc.). It is assumed that there all these requirements are met.
So if a catastrophe suddenly happened, there must be an opportunity to recover from the backup. And if we are talking about a financial organization, it is important that this backup be consistent, and not just a copy of all the disks. So that there is no situation when parts of the data were restored at the moment X, and at the other part - at the moment Y. It is very important to have Point-in-time Recovery to minimize the amount of losses even in a situation of data corruption or a particularly severe accident.
It is important to be able to wipe data to disk. So that the cluster does not fall under overload and continues at least more slowly, but work. And to quickly rise from the disk, and then pumped data into memory.
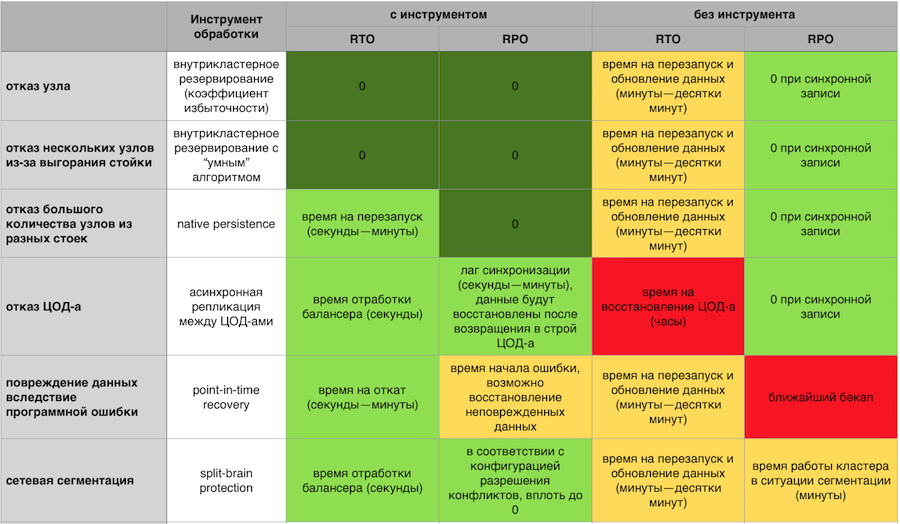
In-Memory Response to Accidents with and without GridGain Failover Components Enabled
The failover cluster should scale easily horizontally and vertically. I do not want to pay for your server and look at how half the resources are idle. I do not want to have a hell of hundreds of processes that need to be managed. I would like a simple in terms of support system, with easy input-output nodes from the cluster and a developed, mature monitoring system.
Consider this view MongoDB. Everyone who worked with MongoDB is aware of a large number of processes. If we have a shardirovannaya MongoDB of 5 shards, then on each shard there will be a replica set of three processes (with a redundancy factor of 3). And these are already 15 processes only on the data itself. Cluster configuration storage is another plus 3 processes, gets 18 in total, and that is without taking into account routers. If you want 20 shards - welcome to the hell of 63+ (for example, another 8, total 71) processes.
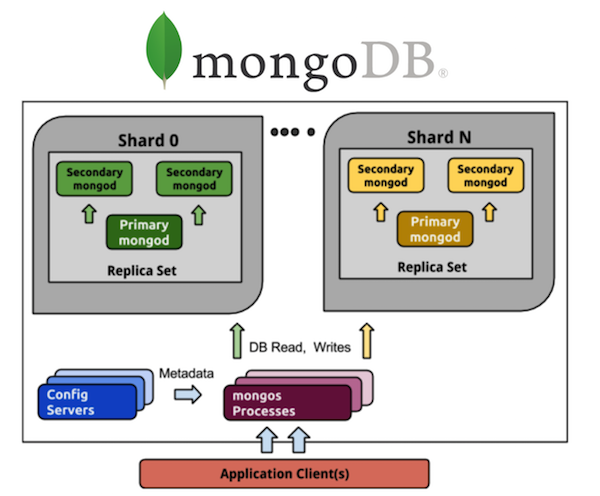
Compare with Cassandra. We take all the same 5 shards - these are 5 processes and 5 nodes with the same redundancy factor of 3, which is much simpler in terms of management. I want 20 shards - these are 20 processes. I can scale my cluster to any number of nodes, not necessarily a multiple of 3 (or another value of the redundancy ratio). Much easier and cheaper to implement and support than replica sets.

In addition, you need to trust the system, to understand what kind of people are behind each individual product. Ideally, the license should be open source or open core. So that in the event of the death of the vendor something could be done. It’s also good if the source code is managed by an independent community - we all remember how MongoDB and Redis changed licenses at the request of the management company. How Aerospike at the beginning of the year imposed restrictions on the "open source" community-editors.
Effective data access is needed. Almost everyone has a structured query language in one form or another. Most often use SQL, it is necessary that adaptation with this language was as easy as possible. This will help the distributed execution of requests when you do not need to send a request separately to each node, but you can communicate with the cluster as a “single window”. Without thinking from an API point of view, this is a set of nodes (remember how hard it is to work with Memcache on large volumes, even at the simplest put / get level, without potentially complex SQL queries), distributed DDL and ACID guarantees.
And finally support. If something suddenly does not work, the company simply loses money. For some areas this is not critical, but it is often important that someone is responsible for the product and its work. So that you can make a claim at any time, and it was quickly resolved.
With this post we are ending the year of Promsvyazbank on Habré. Collected New Year wishes for habrovchan in a small video:
When should I switch to in-memory? How and why to scale? And what should I pay attention to? Answers in the speeches of speakers, which we will highlight in this post.
But first, let's introduce the speakers:
- Andrei Trushkin, Head of Promsvyazbank Innovation and Prospective Technologies Center
- Vladislav Shpileva, developer Tarantool
- Artem Shitov, GridGain Solution Architect
Switch to in-memory
Current trends in the financial market impose much more stringent requirements on response time and the operation of process automation in general. In addition, almost all major financial institutions today are striving to build their own ecosystems.
In this regard, we see for ourselves two main applications of in-memory solutions. First, it is caching integration data. According to the classic scenario, in large companies there are several automated systems that provide data upon user request. Or external system - but in this case, the initiator in most cases is the user. Traditionally, these systems stored data structured in a specific way in the database, accessing it on request.
Today, such systems no longer meet the requirements in terms of load. Here you should not forget about remote calls of these systems by consumer systems. Hence the need to revise the approaches to storing and presenting data - users, automated systems, or individual services. Logical output - storing actual data used by services at the in-memory layer level; There are quite a few such successful cases on the market.
This was the first case. The second is effective, from a technical point of view, business process management. Traditional BPM systems automate the execution of certain operations in accordance with a predetermined algorithm. And in many cases there are questions: why are these systems working insufficiently and insufficiently quickly?
As a rule, such systems write their every step (or a small set of steps, designed in the form of a business transaction) to the database. So they are tied to the response time and interaction with these systems. Now the number of instances of business processes running simultaneously in real time, orders of magnitude more than 10 years ago. So modern business process management systems should have significantly better performance and ensure execution of decentralized applications. Moreover, today all companies are moving towards the formation of a large microservice environment. The challenge is that different instances of business processes can share and efficiently use operational data. As part of the orchestration, it makes sense to store them in an in-memory solution.
Reconciliation problem
Suppose that we have a huge number of nodes and services, that a number of business processes are running, the actions of which are implemented in the form of microservices. To improve performance, each of them begins to write its state in a local copy of memory. We get a large number of local copies. How to ensure relevance and consistency for all?
We use in-memory zoning areas. For example, depending on the business domain. When we cut a business domain, we determine that certain microservices / business processes work only within the framework of the zone that is responsible for the corresponding domain. So we can speed up the update of the cache and all the work of in-memory solutions.
At the same time, the cache responsible for the domain works in full replication mode - the limited number of nodes due to domain distribution ensures the speed and accuracy of the solution in this mode. Zoning and maximum fragmentation helps solve synchronization problems, cluster operation, etc. on a large total number of nodes.
There are often natural questions about the reliability of in-memory solutions. Yes, you can not put everything there. In order to ensure reliability, we always have databases next to in-memory. For example, for important issues with reporting that need to be brought together, which can be difficult on a large number of nodes. So our vision for today: a synergy of two approaches .
It is also worth noting that these two approaches are also not entirely correct only to oppose. And at the same time, close on them. Manufacturers and contributors of modern virtualization systems in container mode, such as Kubernetes, already provide us with options for long-term secure storage. Good industrial case studies have already appeared on the implementation of solutions in which storage is carried out in a similar virtualized format.
One of the largest US newspapers provides an opportunity for its readers to get online any number that has been published since the launch of the publication of this newspaper in the 19th century. We can imagine the level of load. Storage is implemented by them through the Apache Kafka platform deployed in Kubernetes. Here is another option for storing information and providing access to it under a large load to a large number of clients. When designing new solutions, this option is also worth paying attention to.
Scaling in-memory databases with Tarantool
Suppose we have a server. It accepts requests, stores data. Suddenly, requests and data becomes larger, the server ceases to cope with the load. You can upload more hardware to the server and it will accept more requests. But this is a dead-end path for three reasons at once: high cost, limited technical capabilities and problems with resiliency. Instead, there is horizontal scaling: “friends” come to the server to help him complete tasks. The two main types of horizontal scaling are replication and sharding.
Replication - when there are many servers, they all store the same data and client requests are scattered across all of these servers. This is how calculations are scaled, not data. This works when data is placed on one node, but there are so many client requests that one server cannot cope. It also greatly increases resiliency.
Sharding is used to scale data: many servers are made and they store different data. So you scale both calculations and data. But failover in this case is low. If one server fails, then part of the data will be lost.
There is a third approach - to combine them. We divide the cluster into subclusters, call them replica sets. The same data is stored in each of them, and the data does not overlap between replica sets. The result is both data scaling, and computing, and fault tolerance.
Replication
Replication is of two types: asynchronous and synchronous. Asynchronous is when client requests are not waiting for data to be scattered across replicas: there are enough entries for one replica. As soon as the data is on the disk, in the log, the transaction is completed successfully and sometime in the background this data is replicated. Synchronous - when a transaction is divided into 2 phases: prepare and commit. Commit will not return success until data is replicated to some replica quorum.
Asynchronous replication is obviously faster, because nothing rests on the network. Data will be sent to the network in the background, and the transaction itself, as recorded in the log, is completed. But there is a problem: replicas can lag from each other, appear out of sync.
Synchronous replication is more reliable, but much slower and more difficult to implement. There are complex protocols. In Tarantool, you can select any of these types of replication, depending on the task.
The backlog of replicas causes not only desynchronization, but also the problem of the master's ignorance: he does not know how to give his changes to the replica. Changes are usually given incrementally - they are applied, and in the same form they fly away to the replica. But what to do with them if the replica is not available? For example, in Tarantool everything can be customized, and the master becomes very flexible.
Another challenge: how to make the topology complex? In Mail.ru, for example, there is a topology with hundreds of Tarantool. It has a tarantool core to which tarantulas replicas for backups are attached in a circle. In Tarantool, you can make completely arbitrary topologies, replication lives well with this.
Sharding
We now turn to data scaling: sharding. It is of two types: ranges and hashes. Sharding by ranges is when all data is sorted by some sharding key, and this large sequence is divided into ranges so that there is approximately the same amount of data in each range. And each range is entirely stored on any one physical node. But usually such a sharding is not needed. Besides, it is always very complicated.
There is also sharding with hashes. It is just represented in Tarantool. It is much easier to implement, use and almost always fits instead of sharding with ranges. It works like this: we consider the hash function to be written to and it returns the number of the physical node to which to save. There are problems: firstly, it is difficult to quickly complete a complex query.
Secondly, there is the problem of resharing. There is some kind of shard function that returns the number of the physical shard to which the key should be stored. And when the number of nodes changes, the shard function also changes. This means that for all the data in the cluster, it will have to be recalculated and verified. Moreover, in classical sharding some data will not be transferred to the new node, but will simply be shuffled between the old nodes. Useless hyphenation can not be reduced to zero in the classic sharding.
In Tarantool, virtual sharding is used: data is distributed not by physical nodes, but by virtual ones. Virtual baketas in a virtual cluster. And virtual storadzhi decomposed on physical. And already there it is guaranteed that each virtual stack lies entirely on any one physical stack.
How does this solve the problem of resharing? The fact is that the number of buckets is fixed and seriously exceeds the number of physical nodes. Thus, no matter how much you physically scale your cluster, there will always be enough buckets to store data and distribute it evenly. And due to the fact that the shard function is unchanged, when changing the composition of the cluster will not have to recalculate it.
As a result, we get three types of sharding: ranges, hashes and virtual buckets. In the case of ranges and bucks, there is a physical search problem.
How to solve it? The first way: just ban rewarding. Then for resarding you have to create a new cluster and transfer everything there. The second way: always go to all nodes. But this makes no sense, because you need to scale, and the calculations do not scale like that. The third option: a proxy module, which serves as a sort of baket router. You start it, send a request there, specifying the number of the batch, and it will send your request as a proxy to the desired physical node.
Advanced In-Memory on the example of the GridGain platform
Business has additional database requirements. He wants it all to be sluggish and disaster proof. He wants high availability: so that nothing is ever lost, so that you can quickly recover. You also need easy and cheap scalability, simple support, platform trust and effective access mechanisms.
All these ideas are not new. Many of these things are more or less implemented in classical DBMS, in particular, replication between data centers.
In-Memory is no longer a technology “start-up”, it is mature products that are used in the largest companies around the world (Barclays, Citi Group, Microsoft, etc.). It is assumed that there all these requirements are met.
So if a catastrophe suddenly happened, there must be an opportunity to recover from the backup. And if we are talking about a financial organization, it is important that this backup be consistent, and not just a copy of all the disks. So that there is no situation when parts of the data were restored at the moment X, and at the other part - at the moment Y. It is very important to have Point-in-time Recovery to minimize the amount of losses even in a situation of data corruption or a particularly severe accident.
It is important to be able to wipe data to disk. So that the cluster does not fall under overload and continues at least more slowly, but work. And to quickly rise from the disk, and then pumped data into memory.
In-Memory Response to Accidents with and without GridGain Failover Components Enabled
The failover cluster should scale easily horizontally and vertically. I do not want to pay for your server and look at how half the resources are idle. I do not want to have a hell of hundreds of processes that need to be managed. I would like a simple in terms of support system, with easy input-output nodes from the cluster and a developed, mature monitoring system.
Consider this view MongoDB. Everyone who worked with MongoDB is aware of a large number of processes. If we have a shardirovannaya MongoDB of 5 shards, then on each shard there will be a replica set of three processes (with a redundancy factor of 3). And these are already 15 processes only on the data itself. Cluster configuration storage is another plus 3 processes, gets 18 in total, and that is without taking into account routers. If you want 20 shards - welcome to the hell of 63+ (for example, another 8, total 71) processes.
Compare with Cassandra. We take all the same 5 shards - these are 5 processes and 5 nodes with the same redundancy factor of 3, which is much simpler in terms of management. I want 20 shards - these are 20 processes. I can scale my cluster to any number of nodes, not necessarily a multiple of 3 (or another value of the redundancy ratio). Much easier and cheaper to implement and support than replica sets.
In addition, you need to trust the system, to understand what kind of people are behind each individual product. Ideally, the license should be open source or open core. So that in the event of the death of the vendor something could be done. It’s also good if the source code is managed by an independent community - we all remember how MongoDB and Redis changed licenses at the request of the management company. How Aerospike at the beginning of the year imposed restrictions on the "open source" community-editors.
Effective data access is needed. Almost everyone has a structured query language in one form or another. Most often use SQL, it is necessary that adaptation with this language was as easy as possible. This will help the distributed execution of requests when you do not need to send a request separately to each node, but you can communicate with the cluster as a “single window”. Without thinking from an API point of view, this is a set of nodes (remember how hard it is to work with Memcache on large volumes, even at the simplest put / get level, without potentially complex SQL queries), distributed DDL and ACID guarantees.
And finally support. If something suddenly does not work, the company simply loses money. For some areas this is not critical, but it is often important that someone is responsible for the product and its work. So that you can make a claim at any time, and it was quickly resolved.
With this post we are ending the year of Promsvyazbank on Habré. Collected New Year wishes for habrovchan in a small video: