3 unusual cases about the Linux network subsystem

This article presents three small stories that have occurred in our practice: at different times and in different projects. What unites them is that they are connected to the Linux network subsystem (Reverse Path Filter, TIME_WAIT, multicast) and illustrate how deeply it is often necessary to analyze an incident that you encounter for the first time to solve a problem ... and, of course, what joy you can experience as a result received decision.
Story One: About the Reverse Path Filter
A client with a large corporate network decided to pass part of his Internet traffic through a single corporate firewall located behind the router of the central unit. Using iproute2, traffic going to the Internet was directed to the central unit, where several routing tables were already configured. By adding an additional routing table and setting redirection routes to the firewall in it, we turned on traffic redirection from other branches and ... traffic did not go.
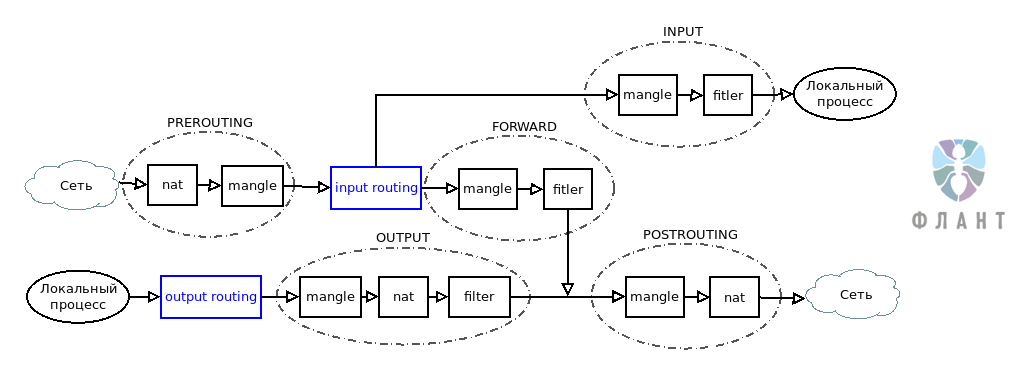
The flow of traffic through tables and Netfilter chains
We began to find out why the configured routing does not work. Traffic was detected on the inbound tunnel interface of the router:
$ sudo tcpdump -ni tap0 -p icmp and host 192.168.7.3
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on tap0, link-type EN10MB (Ethernet), capture size 262144 bytes
22:41:27.088531 IP 192.168.7.3 > 8.8.8.8: ICMP echo request, id 46899, seq 40, length 64
22:41:28.088853 IP 192.168.7.3 > 8.8.8.8: ICMP echo request, id 46899, seq 41, length 64
22:41:29.091044 IP 192.168.7.3 > 8.8.8.8: ICMP echo request, id 46899, seq 42, length 64However, there were no packets on the outbound interface. It became clear that they are filtered on the router, but there were no explicit rules for dropping packets in iptables. Therefore, we started sequentially, as traffic passed, to establish rules that discard our packets and, after installation, watch the counters:
$ sudo iptables -A PREROUTING -t nat -s 192.168.7.3 -d 8.8.8.8 -j DROP
$ sudo sudo iptables -vL -t nat | grep 192.168.7.3
45 2744 DROP all -- any any 192.168.7.3 8.8.8.8 Checked sequentially nat PREROUTING, mangle PREROUTING. In mangle FORWARD, the counter did not increase, which means that packets are lost at the routing stage. After checking again the routes and rules, they began to study what exactly was happening at this stage.
In the Linux kernel, the Reverse Path Filtering (
rp_filter) parameter is enabled by default for each interface . In the case when you use complex, asymmetric routing and the packet with the response will not be returned to the source by the route that the request packet came in, Linux will filter out such traffic. To solve this problem, you must disable Reverse Path Filtering for all of your network devices involved in routing. Below is a simple and quick way to do this for all your network devices:#!/bin/bash
for DEV in /proc/sys/net/ipv4/conf/*/rp_filter
do
echo 0 > $DEV
doneReturning to the case, we solved the problem by disabling the Reverse Path Filter for the tap0 interface and now we consider disconnecting
rp_filterfor all devices participating in asymmetric routing as a good form on routers .The second story: about TIME_WAIT
An unusual problem occurred in the highly loaded web project that we served: from 1 to 3 percent of users could not access the site. When studying the problem, we found out that inaccessibility did not correlate with the loading of any system resources (disk, memory, network, etc.), did not depend on the location of the user or his telecom operator. The only thing that united all users who had problems was that they went online through NAT.
The state
TIME_WAITin the TCP protocol allows the system to verify that the data transfer has really stopped in this TCP connection and that no data has been lost. But the possible number of simultaneously open sockets is a finite value, which means it is a resource that is spent, including on the stateTIME_WAITin which customer service is not performed. 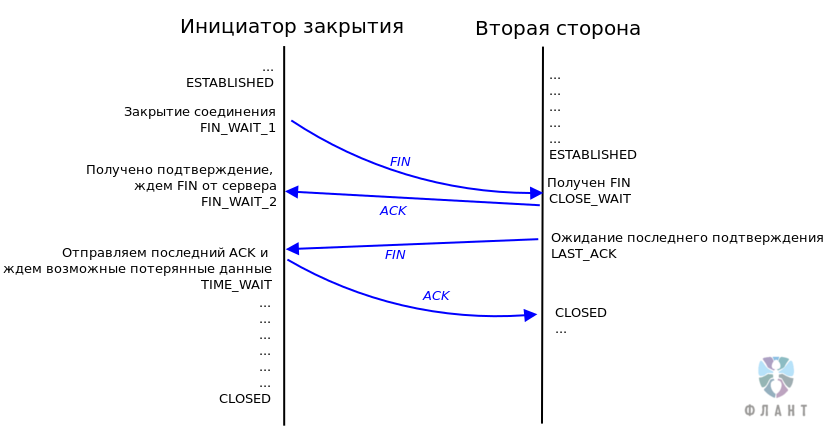
TCP Connection Closing Mechanism The
solution, as expected, was found in the kernel documentation. The natural desire of the administrator of a highload system is to reduce the "idle" resource consumption. A quick googling will show us a lot of tips that call for including Linux kernel options
tcp_tw_reuseand tcp_tw_recycle. But with tcp_tw_recyclenot everything is as simple as it might seem. We will deal with these parameters in more detail:
- The parameter
tcp_tw_reuseis useful to include in the struggle for the resources occupiedTIME_WAIT. A TCP connection is identified by a set of parametersIP1_Port1_IP2_Port2. When the socket goes into stateTIME_WAIT, when disconnected, thetcp_tw_reuseinstallation of a new outgoing connection will occur with the choice of a new local oneIP1_Port1. Old values can only be used when the TCP connection is in a stateCLOSED. If your server creates a lot of outgoing connections, installtcp_tw_reuse = 1and your system will be able to use portsTIME_WAITin case of exhaustion of free ones. To install, write to/etc/sysctl.conf:net.ipv4.tcp_tw_reuse = 1
And run the command:sudo sysctl -p - The parameter is
tcp_tw_recycledesigned to reduce the time spent by the socket in the stateTIME_WAIT. By default, this time is 2 * MSL (Maximum Segment Lifetime), and MSL, according to RFC 793 , is recommended to be set to 2 minutes. Whentcp_tw_recycleyou enable it , you are telling the Linux kernel to use not a constant as MSL, but to calculate it based on the characteristics of your particular network. As a rule (if you do not have dial-up), the inclusion oftcp_tw_recyclesignificantly reduces the time spent by the connection in the stateTIME_WAIT. But there is a pitfall: going into the stateTIME_WAIT, your network stack with it turned ontcp_tw_recyclewill reject all packets from the IP of the second party involved in the connection. This can cause a number of accessibility problems when working due to NAT, which we encountered in the above case. The problem is extremely difficult to diagnose and does not have a simple reproduction / repeatability procedure, so we recommend that extreme care be taken when usingtcp_tw_recycle. If you decide to enable it, enter it on/etc/sysctl.confone line and (do not forget to executesysctl -p):net.ipv4.tcp_tw_recycle = 1
History Three: About OSPF and Multicast Traffic
The serviced corporate network was built on the basis of tinc VPN and the adjacent beams of IPSec and OVPN connections. To route all of this L3 address space, we used OSPF. On one of the nodes where a large number of channels were aggregated, we found that a small part of the networks, despite the correct OSPF configuration, periodically disappears from the route table on this node.

Simplified device of the VPN network used in the described project
First of all, we checked the connection with the routers of problem networks. Communication was stable:
Router 40 $ sudo ping 172.24.0.1 -c 1000 -f
PING 172.24.0.1 (172.24.0.1) 56(84) bytes of data.
--- 172.24.0.1 ping statistics ---
1000 packets transmitted, 1000 received, 0% packet loss, time 3755ms
rtt min/avg/max/mdev = 2.443/3.723/15.396/1.470 ms, pipe 2, ipg/ewma 3.758/3.488 msHaving diagnosed OSPF, we were even more surprised. At the site where the problems were observed, the routers of the problematic networks were not in the list of neighbors. On the other side, the problem router was in the list of neighbors:
Router 40 # vtysh -c 'show ip ospf neighbor' | grep 172.24.0.1Router 1 # vtysh -c 'show ip ospf neighbor' | grep 172.24.0.40
255.0.77.148 10 Init 14.285s 172.24.0.40 tap0:172.24.0.1 0 0 0The next step ruled out possible delivery problems for ospf hello from 172.24.0.1. Requests came from him, but the answers did not go away:
Router 40 $ sudo tcpdump -ni tap0 proto ospf
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on tap0, link-type EN10MB (Ethernet), capture size 262144 bytes
09:34:28.004159 IP 172.24.0.1 > 224.0.0.5: OSPFv2, Hello, length 132
09:34:48.446522 IP 172.24.0.1 > 224.0.0.5: OSPFv2, Hello, length 132No restrictions were set in iptables - we found out that the packet is discarded after passing all the tables in Netfilter. Again we delved into reading the documentation, where a kernel parameter was found
igmp_max_membershipsthat limits the number of multicast connections for one socket. By default, this number is 20. We, for the round number, increased it to 42 - OSPF normalized:Router 40 # echo 'net.ipv4.igmp_max_memberships=42' >> /etc/sysctl.conf
Router 40 # sysctl -p
Router 40 # vtysh -c 'show ip ospf neighbor' | grep 172.24.0.1
255.0.77.1 0 Full/DROther 1.719s 172.24.0.1 tap0:172.24.0.40 0 0 0Conclusion
No matter how complex the problem may be, it is always solvable and often through examination of the documentation. I will be glad to see in the comments a description of your experience in finding solutions to complex and unusual problems.
PS
Read also in our blog: