One for all: how to break the vicious circle of complexity when developing a boxed product
We make software for video surveillance systems with video analysis functions, and this is a boxed product. A boxed product in the same form is immediately available to many users and is used by all of them as they are.
Does it matter whether we make a universal product for many or develop individually for a specific user? When it comes to video analysis, this is simply fundamental.
Take two companies: N and M. Let company N develop an “individual” software product, and M develop a boxed one. Company N develops a product to order, for use in one specific place. And makes it work in the conditions for which the product is being developed. And the company M, which makes the boxed product, must develop in such a way that it provides the target parameters (for accuracy, for example) for a variety of users in a variety of conditions.
Two factors are valid for the boxed video analysis software product:
1. The most diverse conditions of applicability;
2. The inability each time a new user to adjust and adjust the algorithm.
Accordingly, during its development it is necessary to satisfy two conditions:
1. The algorithm should work in automatic mode. That is, without the participation of a person who can “twist” something and set it up in a specific place.
2. The conditions may be very different. And with all parameters, the product must provide target values, for example, in accuracy.
And with regard to shooting conditions and video analysis, the range of possible parameters is very wide: these are sharpness, contrast, color saturation, optical noise level, structure level and spatio-temporal distribution of noise movement, camera installation angle, color rendering parameters, background (scene) complexity, etc. d.
If we take scientific articles, then in them you can see, for example, such illustrations for detecting a moving object:

Look! It's just something sterile: here are two pictures - here is a moving object. And, of course, in such a situation, we will perfectly engineer everything.
But these are unrealistic, ideal conditions.
If all in the same scientific works take illustrations closer to reality, here is what they are:

This is a frame from a real camera. But the conditions are still very good.
But what do we encounter in fact? We are faced with the fact that our algorithms should work in such conditions:

and in such

and even in such.

This is the reality of using video analysis algorithms in a boxed product: the conditions are completely different. In addition, they can change over time. Nevertheless, each algorithm should work well in all such conditions and provide accuracy targets.
And therefore, when developing a boxed product, you need to look for a special non-trivial approach.
There is another very difficult task in our specific development.
When an algorithm is developed, a sample of frames or videos is created for it: videos are prepared, on which work is tracked. The developers are trying to prepare very different videos, with very different shooting conditions and parameters. But in fact it turns out that these videos somehow fall into some rather narrow area of input conditions.
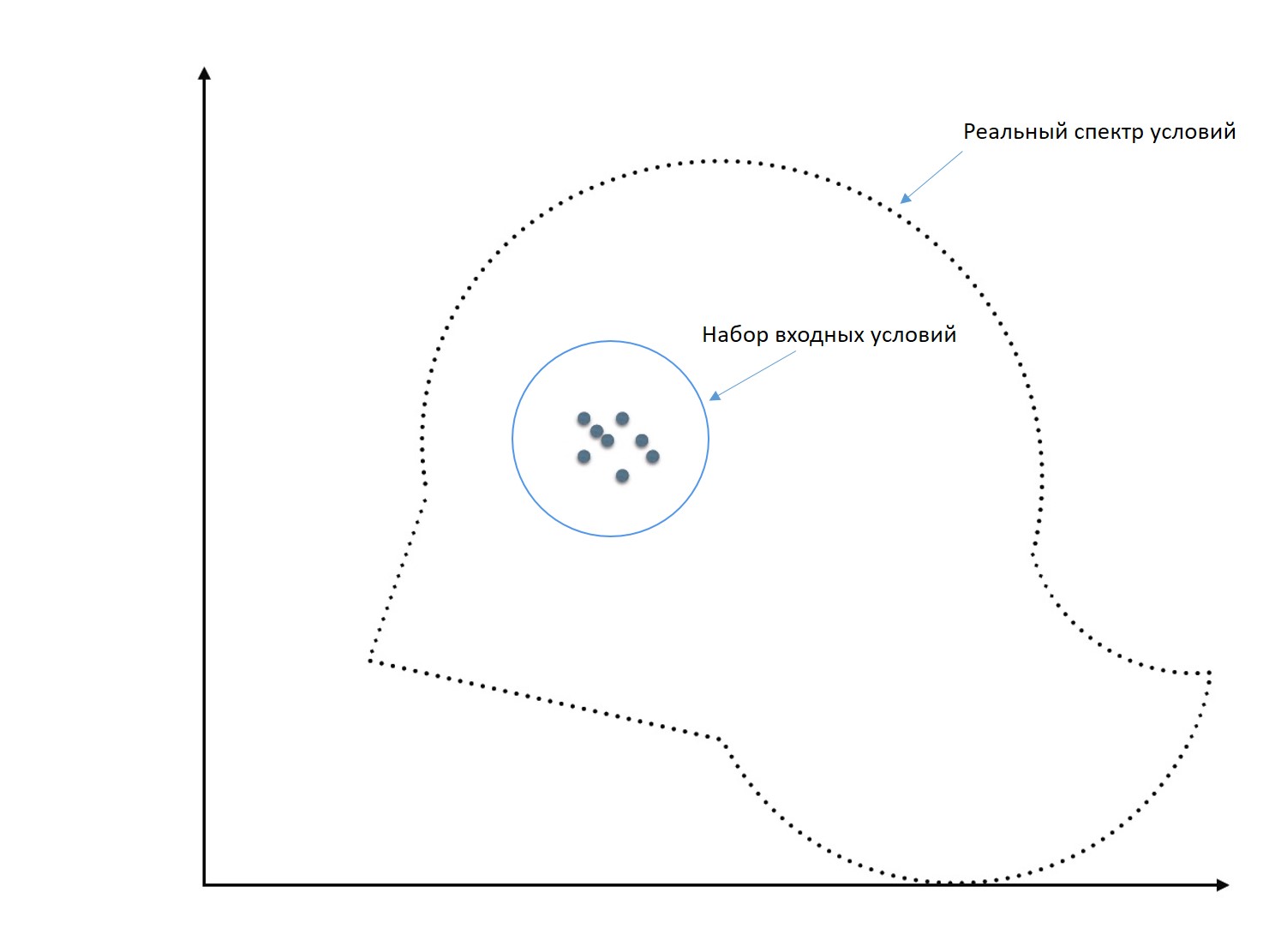
And when an algorithm that works great on a sample will be used in completely different conditions, it may work very poorly or not work at all. Because the whole development was carried out, adjusting to these narrow input conditions.
And this is a global problem.
But an even bigger problem is that in reality this “space of conditions” is not two-dimensional as in the graph above. It is multidimensional. And all parameters can vary within wide limits. And in view of the fact that we are considering a boxed product, its algorithms should work correctly and accurately within all boundaries.
So, we get a huge multidimensional space of conditions and parameters. And our task when developing the algorithm is to place the input points more or less evenly in this space and not to miss any area.
There is no universal method. The only thing that can be recommended here is to go and take a sample of real videos of real cameras from real objects. And try to make sure that they cover the entire space of parameters.
At the same time, the algorithm will one way or another adapt to the specific conditions of these input sample clips.
A way to avoid such a tweak is to test and measure accuracy on a fundamentally different set of videos: develop on some, test on others. Then the chances increase, because if during the testing the algorithms do not work on what they were developed on, then there is no adjustment.
But that’s not all :) It often happens that you develop on some, test on others and find out that it doesn’t work for you or doesn’t work well enough. You begin to understand why it doesn’t work, you understand why, you change something and provide good work on test videos. But in this case there is already a new adjustment ... for them.
1 way - to test all the time on new videos.
It is very effective, but very laborious. Believe me, it’s very difficult to collect videos from real objects for input sampling and tests (including because we are talking about security video systems). And in view of the fact that sometimes testing an algorithm can take place several times a day, you need to stock up with some unrealistic amount of video.
This approach increases the chances of success, reduces the risks of adjustment, but is very resource intensive.
2 way - to make sure that developers do not see why it does not work during tests
Let the developers write the algorithm, and some external person will test it on new videos, who will simply tell them whether accuracy is achieved or not, whether something needs to be improved or not. The developers of these videos should not see in order to exclude the adjustment of corrections.
But in this case, developers must modify the algorithm, not understanding why something doesn’t work for them ...
Neither one nor the other way is realistic. Every time we need to look for some kind of compromise. And the one who leads the development must correctly maintain this balance: how, on the one hand, not to complicate your life so much that you’ll get a new set of test videos for each test, on the other hand, to minimize the risks of adjustment. Or how not to show the developers the videos on which testing is being performed, but at the same time let them know what and why is not working as it should.
And this is the reality in which we are developing.
There is a concept of degradation in development: when a developer improves something in an algorithm, at the same time, something worsens in it. This is a normal, real phenomenon. Therefore, any change in the algorithm must pass a test for introducing degradation into other parameters.
It takes an insane amount of effort. You can do it manually and spend a lot of time and effort, or you can automate the process. But this again raises the problem of fine tuning: when you automate, you fine-tune everything for a finite set of videos. “Automatically” is when everything is marked up: it is said that on this video there are such conditions and parameters, and on this one.
And again, you need to look for balance when testing degradation ...
All this looks like some kind of vicious circle: achieve high accuracy for any conditions, but spend an unrealistic amount of time and effort on it, or sacrifice the versatility of the product, but develop it faster and easier.
It seems that there is one simple way out of this situation (looking ahead, let's say that it’s not a simple one, and no way out :)).
When there is a wide range of parameters, it is possible to clearly formulate to the user the conditions under which this algorithm should work. Any program, module or video analysis algorithm has recommended working conditions under which they give the stated accuracy.
However, with this approach, you need to understand this:
1. You can tell users that they must provide certain parameters, but often in reality it is simply impossible to comply with all parameters. And when it comes to a boxed product, it should work in real conditions ...
2. But the main catch is that even if users are willing to comply with all the recommended conditions, it is often difficult to formalize.
For example, contrast can be described (although the contrast for the whole image can be one, but in the specific area where you are analyzing it is different). But how to formalize, for example, the complexity of the background? How to tell the user what conditions he must comply with in relation to such poorly digitized things?
No matter how complicated and hopeless these situations may seem, this is a reality in which we and other companies work, develop, and do this quite successfully. We must understand and accept that the development of a boxed product for video analysis, which should work in real conditions, is a plus of several orders of magnitude to complexity.
Regardless of how the complex and controversial problems are solved, it is necessary to develop and test in close connection with the user and the real conditions in which he uses the product.
Does it matter whether we make a universal product for many or develop individually for a specific user? When it comes to video analysis, this is simply fundamental.
Let's understand
Take two companies: N and M. Let company N develop an “individual” software product, and M develop a boxed one. Company N develops a product to order, for use in one specific place. And makes it work in the conditions for which the product is being developed. And the company M, which makes the boxed product, must develop in such a way that it provides the target parameters (for accuracy, for example) for a variety of users in a variety of conditions.
Two factors are valid for the boxed video analysis software product:
1. The most diverse conditions of applicability;
2. The inability each time a new user to adjust and adjust the algorithm.
Accordingly, during its development it is necessary to satisfy two conditions:
1. The algorithm should work in automatic mode. That is, without the participation of a person who can “twist” something and set it up in a specific place.
2. The conditions may be very different. And with all parameters, the product must provide target values, for example, in accuracy.
And with regard to shooting conditions and video analysis, the range of possible parameters is very wide: these are sharpness, contrast, color saturation, optical noise level, structure level and spatio-temporal distribution of noise movement, camera installation angle, color rendering parameters, background (scene) complexity, etc. d.
What do smart books write?
If we take scientific articles, then in them you can see, for example, such illustrations for detecting a moving object:
Look! It's just something sterile: here are two pictures - here is a moving object. And, of course, in such a situation, we will perfectly engineer everything.
But these are unrealistic, ideal conditions.
If all in the same scientific works take illustrations closer to reality, here is what they are:
This is a frame from a real camera. But the conditions are still very good.
But how really?
But what do we encounter in fact? We are faced with the fact that our algorithms should work in such conditions:
and in such
and even in such.
This is the reality of using video analysis algorithms in a boxed product: the conditions are completely different. In addition, they can change over time. Nevertheless, each algorithm should work well in all such conditions and provide accuracy targets.
And therefore, when developing a boxed product, you need to look for a special non-trivial approach.
And that's not all
There is another very difficult task in our specific development.
When an algorithm is developed, a sample of frames or videos is created for it: videos are prepared, on which work is tracked. The developers are trying to prepare very different videos, with very different shooting conditions and parameters. But in fact it turns out that these videos somehow fall into some rather narrow area of input conditions.
And when an algorithm that works great on a sample will be used in completely different conditions, it may work very poorly or not work at all. Because the whole development was carried out, adjusting to these narrow input conditions.
And this is a global problem.
But an even bigger problem is that in reality this “space of conditions” is not two-dimensional as in the graph above. It is multidimensional. And all parameters can vary within wide limits. And in view of the fact that we are considering a boxed product, its algorithms should work correctly and accurately within all boundaries.
So, we get a huge multidimensional space of conditions and parameters. And our task when developing the algorithm is to place the input points more or less evenly in this space and not to miss any area.
How to do it?
There is no universal method. The only thing that can be recommended here is to go and take a sample of real videos of real cameras from real objects. And try to make sure that they cover the entire space of parameters.
At the same time, the algorithm will one way or another adapt to the specific conditions of these input sample clips.
A way to avoid such a tweak is to test and measure accuracy on a fundamentally different set of videos: develop on some, test on others. Then the chances increase, because if during the testing the algorithms do not work on what they were developed on, then there is no adjustment.
But that’s not all :) It often happens that you develop on some, test on others and find out that it doesn’t work for you or doesn’t work well enough. You begin to understand why it doesn’t work, you understand why, you change something and provide good work on test videos. But in this case there is already a new adjustment ... for them.
How to break out of this never-ending series of tweaks?
1 way - to test all the time on new videos.
It is very effective, but very laborious. Believe me, it’s very difficult to collect videos from real objects for input sampling and tests (including because we are talking about security video systems). And in view of the fact that sometimes testing an algorithm can take place several times a day, you need to stock up with some unrealistic amount of video.
This approach increases the chances of success, reduces the risks of adjustment, but is very resource intensive.
2 way - to make sure that developers do not see why it does not work during tests
Let the developers write the algorithm, and some external person will test it on new videos, who will simply tell them whether accuracy is achieved or not, whether something needs to be improved or not. The developers of these videos should not see in order to exclude the adjustment of corrections.
But in this case, developers must modify the algorithm, not understanding why something doesn’t work for them ...
Neither one nor the other way is realistic. Every time we need to look for some kind of compromise. And the one who leads the development must correctly maintain this balance: how, on the one hand, not to complicate your life so much that you’ll get a new set of test videos for each test, on the other hand, to minimize the risks of adjustment. Or how not to show the developers the videos on which testing is being performed, but at the same time let them know what and why is not working as it should.
And this is the reality in which we are developing.
But that's not all
There is a concept of degradation in development: when a developer improves something in an algorithm, at the same time, something worsens in it. This is a normal, real phenomenon. Therefore, any change in the algorithm must pass a test for introducing degradation into other parameters.
It takes an insane amount of effort. You can do it manually and spend a lot of time and effort, or you can automate the process. But this again raises the problem of fine tuning: when you automate, you fine-tune everything for a finite set of videos. “Automatically” is when everything is marked up: it is said that on this video there are such conditions and parameters, and on this one.
And again, you need to look for balance when testing degradation ...
To drive into the framework not yourself, but the user?
All this looks like some kind of vicious circle: achieve high accuracy for any conditions, but spend an unrealistic amount of time and effort on it, or sacrifice the versatility of the product, but develop it faster and easier.
It seems that there is one simple way out of this situation (looking ahead, let's say that it’s not a simple one, and no way out :)).
When there is a wide range of parameters, it is possible to clearly formulate to the user the conditions under which this algorithm should work. Any program, module or video analysis algorithm has recommended working conditions under which they give the stated accuracy.
However, with this approach, you need to understand this:
1. You can tell users that they must provide certain parameters, but often in reality it is simply impossible to comply with all parameters. And when it comes to a boxed product, it should work in real conditions ...
2. But the main catch is that even if users are willing to comply with all the recommended conditions, it is often difficult to formalize.
For example, contrast can be described (although the contrast for the whole image can be one, but in the specific area where you are analyzing it is different). But how to formalize, for example, the complexity of the background? How to tell the user what conditions he must comply with in relation to such poorly digitized things?
"The devil is not so terrible ..."
No matter how complicated and hopeless these situations may seem, this is a reality in which we and other companies work, develop, and do this quite successfully. We must understand and accept that the development of a boxed product for video analysis, which should work in real conditions, is a plus of several orders of magnitude to complexity.
Regardless of how the complex and controversial problems are solved, it is necessary to develop and test in close connection with the user and the real conditions in which he uses the product.