Prometheus
- Transfer
Good to all. We are sharing here a very interesting article that we stumbled upon in preparation for our course . The translation goes as it is (with the exception of some comments).
Background
In a nutshell - an introduction about monitoring and appeal of beliefs. As many people know, I accompany Riemann, an event flow processing tool for monitoring distributed systems. In my book on monitoring , I used Riemann as the main tool for exploring new monitoring approaches and patterns, and described the architecture of whitebox monitoring (with selective blackbox monitoring) using a push model.
To understand what I'm talking about, we’ll explain some concepts. Blackbox monitoring is responsible for checking the external characteristics of services or applications: is it possible to connect to the open port of the service, are the correct data or a response code returned. An example of blackbox monitoring is an ICMP request and acknowledgment of a response.
In turn, whitebox monitoring is focused on what is happening inside the service or application. An application that has the appropriate tools returns the state of itself or internal components, the result of transactions or events. This data answers the question “how does the application work” and not the question “does the application work”. Whitebox-monitoring transfers events, logs or metrics to a special monitoring tool or provides information outward for subsequent collection by the monitoring tool.
Most people involved in modern monitoring understand that large investments need to be made in whitebox monitoring. Information obtained from within the application is significantly more valuable for business and operation than that obtained on the surface. This does not mean at all that blackbox monitoring is a waste of resources. External monitoring of services and applications is useful, especially for services that are beyond your control, or when looking from the outside gives a context that is not accessible from the inside, for example, regarding routing or DNS problems.
In the book, I focus on working with the push model, not pull. Also, a lot of attention in the book is paid to the advantages of monitoring based on the push model over the pull model. Many (if not most) monitoring systems are built specifically on the basis of the pull / polling model. In this model, the system polls the service or application that monitors. In turn, in the push model, applications and services themselves send data to the monitoring system.
For many reasons (some of which are not obvious at first glance), I prefer the push model. But the features of both approaches often do not interfere with implementation for a number of reasons (for example, because of scale). And the likelihood of success does not depend on disputes about implementation or tools. I am of the opinion that, first of all, tools should be right for you, and it makes no sense to thoughtlessly follow trends or dogmatism.
It was the desire not to be categorical and the lack of understanding of the differences by the community that inspired me to write an introductory tutorial for one of the leading monitoring tools based on the pull model: Prometheus. It is very popular, especially in the world of containers and Kubernetes.
Introducing Prometheus
Prometheus was developed by Soundcloud engineers who previously worked at Google. It is written in Go, is open source, and is developed with support from the Cloud Native Computing Foundation . The inspiration for the project was Borgmon from Google.
Prometheus is focused on whitebox monitoring. It collects time series data obtained from applications and services. The application provides this data on its own or through plugins called exporters.
The Prometheus platform is based on a server that collects and stores time series data. It has a multidimensional time series model that combines metric names and key / value pairs, called labels for metadata. Time series data is stored on the server; individual servers are autonomous and independent of distributed storage.
The platform also contains client libraries and a number of exporters for specific functions and components. For example, the StatsD exporter, which converts time series StatsD data to the Prometheus format. In addition, there is a push-gateway for receiving small amounts of incoming data and an alert manager that can process notifications generated by triggers or when thresholds for data collected by Prometheus are exceeded.
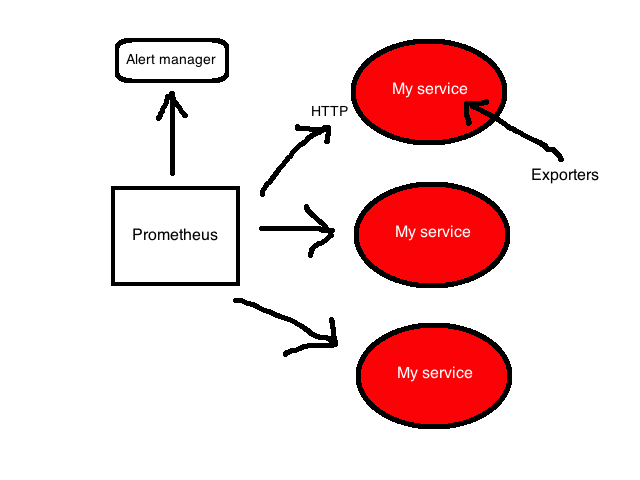
More detailed architecture can be found inPrometheus documentation .
Installation
Prometheus Server - a binary file of the same name prometheus. Take the latest version and unzip it.
The official website also hosts various additional components: alert manager for sending notifications and exporters for a variety of services.
Setup
The prometheus binary file that we just unpacked is configured through the YAML file. Let's see what it is:
Three YAML blocks are defined in this configuration file:
Global
The first global block contains global settings for controlling server behavior.
scrape_interval sets the intervals between polls for an application or service, in our case 15 seconds. This is the resolution of the data scale, that is, the period of time that each data point covers.
evaluation_interval tells Prometheus how often to process data according to the rules. There are two main types of rules: recording rules and alert rules. Recording rules allow you to pre-calculate frequently used and resource-intensive expressions and save the result as new time series data. Alert rules allow you to define alert conditions. Prometheus will (re-) check these conditions every 15 seconds.
External_labels contains a list of key / value pairs for labels that will be added to any metric existing on the server, for example, when an alert is generated.
Rule files The
second block - rule_files, contains a list of files with rules for recording or alert.
Survey Configuration
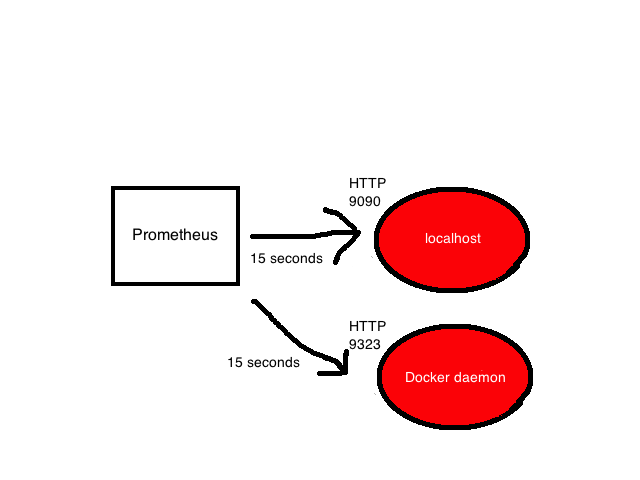
The last block of scrape_configs shows all the goals that Prometheus will poll. Prometheus refers to goals as instances, and groups of instances as jobs. By default, there is only one task - prometheus. Inside it lies static_config with a list of instances (by default there is only one - the Prometheus server). It polls the localhost port 9090 to get the state metrics of the server itself. The metrics are assumed to be in / metrics, so the localhost address is locally polled: 9090 / metrics. The path can be changed using the metric_path option.
A lonely task is pretty boring, so add one more to poll the local Docker daemon. We will use the instructions in the documentationDocker and configure the daemon to return metrics from localhost: 9323 / metrics. And after that, add another task called docker.
The job has a name and instance that refers to the address for receiving Docker daemon metrics. The default path is again / metrics.
The full configuration file can be found at the link .
Starting the server
Let's start the server and see what happens.
Run the binary file and specify the configuration file in the command line flag -config.file. The Prometheus server is now running, polling instances in prometheus and docker jobs, and returning results.
Dashboard
Prometheus has a built-in interface where you can see the results. To do this, open http: // localhost: 9090 / graph in a browser .
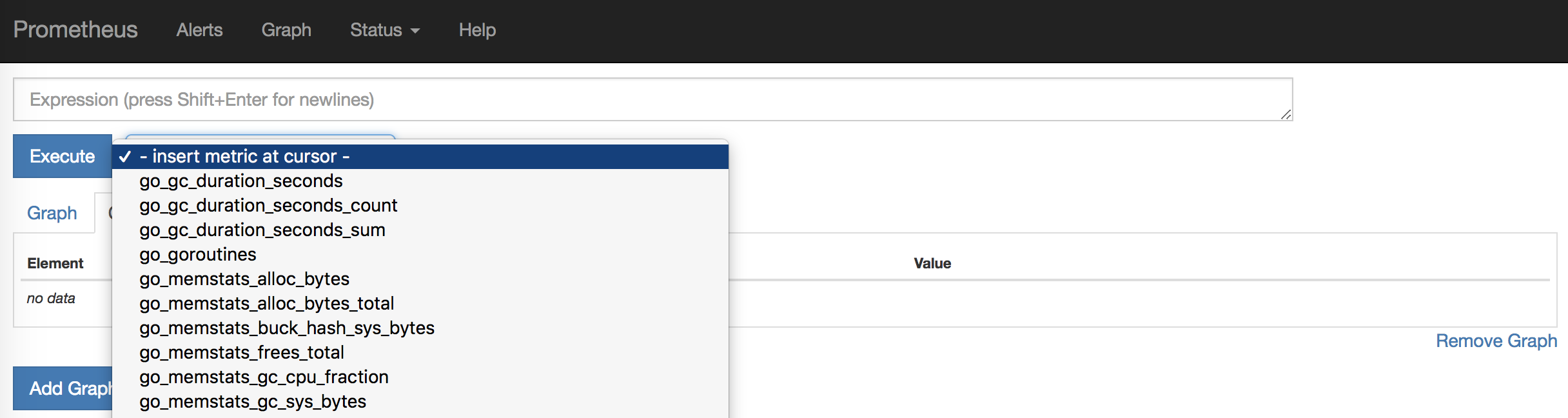
If you click on - insert metric at cursor -, you can select one of the collected metrics. Let's look at the HTTP requests. To do this, select the metric http_requests_total and click Execute.
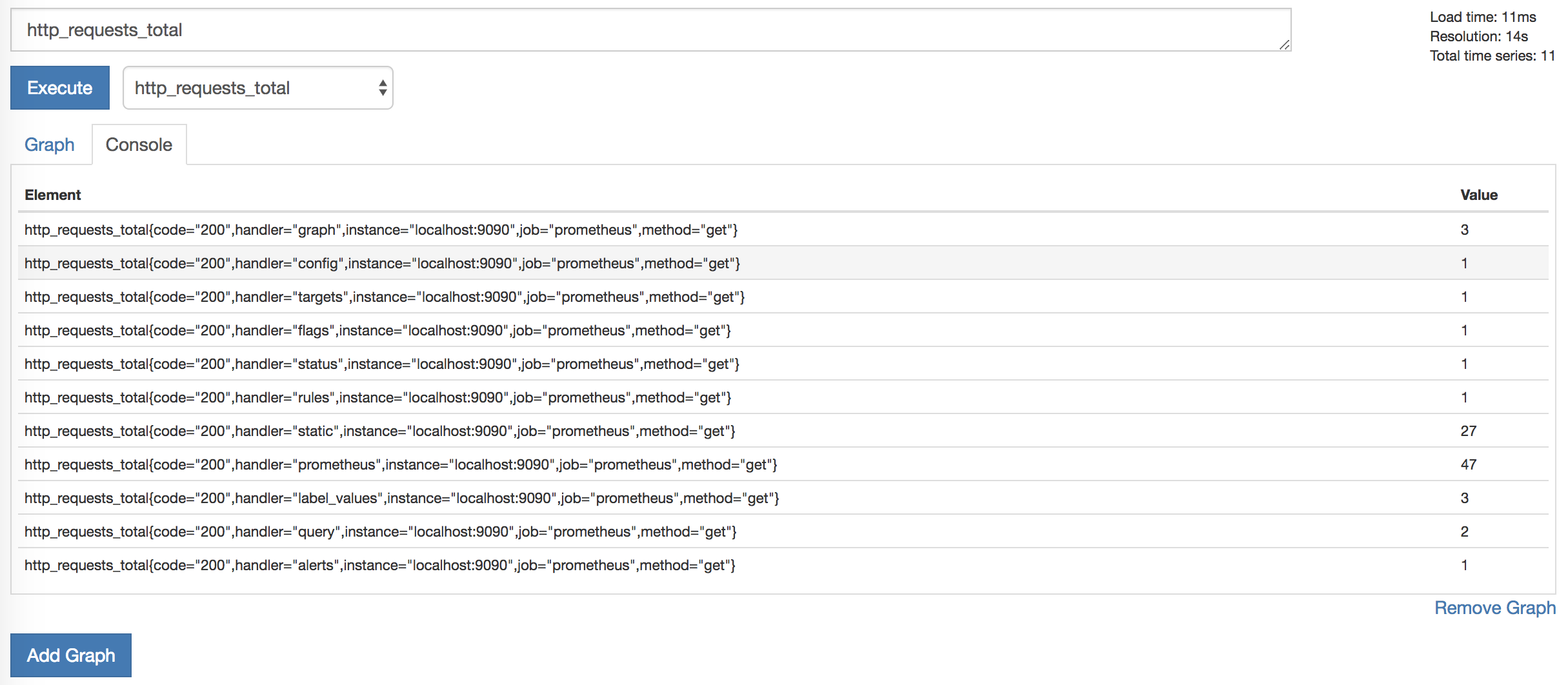
A list of items and values appears, for example:
These elements are metrics that are separated by additional dimensions (they are provided by metric labels). For example, the http_requests_total metric has a handler label that contains information about the process that generates the request. The list of metrics can be reduced by selecting specific metrics containing one of these labels.
The flexibility of the expression language built into the Prometheus server makes it easy to find and aggregate metrics.

We used the handler label to select metrics for the prometheus handler only.
Additionally, we aggregate the metrics of HTTP requests. Let's say you need to see the number of HTTP requests in five minutes, broken down by tasks. To do this, we clarify the request:
Now we’ll execute the request by clicking Execute:

Additionally, you can see the results graph by selecting the Graph tab:

On it we see the total number of HTTP requests for the last five minutes, grouped by tasks.
We can save these queries as recording rules, ensuring their automatic execution and creation of a new metric from this rule.
To do this, add the file to the rule_files block:
And write the following rule in the first.rules file:
This will create a new job: http_requests_total: sum metric for each job.

Now you can make a graph from the metric and add it to the dashboard.
Alerting
Alerts, like aggregation, are rule based. To add a warning rule, you need to register another file in the rule_files block.
In the second.rule file, create a new rule that will notify you when instances have fallen. To do this, we use one of the standard metrics for collecting: up is the state metric, its value is 1 if the poll is successful, and 0 if the poll failed.
Add an alert rule to the rules file. It should look like this:
The alert rule is a bit like a conditional request. We give it the name InstanceDown and a set of rules. The InstanceDown alert is triggered when the up metric is 0 (i.e., the collection of metrics failed) for five minutes. We added a label to the alert: severity = moderate (i.e. severity = moderate) and annotations. Annotations allow you to add more information to the alert, for example, a description of the event. Annotations contain {{}} - brackets for standardization in Go, in which variables are registered. So we can customize the alert using templates . In our case, the variable $ labels contains the metric label, for example, $ labels.instance returns the name of the instance, $ labels.job is the name of the job, etc.
Now, five minutes after stopping the Docker daemon, Prometheus will launch our alert and send a message to the dispatcherAlertmanager (which you must first install and run separately, or use some other tool, for example, the Alerta tool ). Current notifications can be seen on the dashboard in the Alerts tab.
Conclusion
Prometheus is a great platform that is easy to install and configure. The configuration is described in YAML, which simplifies the use of the Infrastructure as Code (IaC) approach. Monitoring simple environments becomes painless thanks to a stand-alone server. Unfortunately, we could not find many examples for more complex environments, so it is worth spending time on experiments and different approaches to find the most optimal way.
The data model is very flexible, especially striking is the ease with which you can label and search metrics. I met most of the client libraries and several exporters - nothing super complicated. Creating tools and generating metrics should not cause much difficulty.
The built-in interface is clean and elegant, and in conjunction with the query language, looks like a suitable tool for debugging or scheduling resources. Recording rules are suitable for aggregating metrics.
I studied a little storage, security, server discovery, and other available integrations - the possibilities look comprehensive. A quick search on GitHub showed an impressive set of tools, integrations and examples, which for sure should be enough for a start.
The main platform has sufficient documentation, but for some related projects it is rather chaotic and incomplete. Although even with limited knowledge of Prometheus, in just an hour I managed to create a working configuration.
Distributing a single binary file without initialization or packaging scripts cannot be called a solution, ready to use out of the box, but, nevertheless, it is a working solution for many projects. There are also various preparatory scripts among configuration management systems that you can use. However, most research tools like Prometheus are likely to handle the installation on their own. Container and Kubernetes support is appealing to people using these tools. And researchers of (micro) services and dynamic or cloud stacks will be interested in server autonomy and portability.
If you have a project where you need to implement monitoring, I recommend Prometheus. It is also worth the time spent if your activities involve containers and tools like Docker and Kubernetes. Due to its flexibility, it is suitable for such tools and architectures much better than other existing platforms.
PS The inspiration for this post was the article Monitoring in the time of Cloud Native, written by Cindy Sridharan. Thanks Cindy!
THE END
We hope you find it helpful.
Background
In a nutshell - an introduction about monitoring and appeal of beliefs. As many people know, I accompany Riemann, an event flow processing tool for monitoring distributed systems. In my book on monitoring , I used Riemann as the main tool for exploring new monitoring approaches and patterns, and described the architecture of whitebox monitoring (with selective blackbox monitoring) using a push model.
To understand what I'm talking about, we’ll explain some concepts. Blackbox monitoring is responsible for checking the external characteristics of services or applications: is it possible to connect to the open port of the service, are the correct data or a response code returned. An example of blackbox monitoring is an ICMP request and acknowledgment of a response.
In turn, whitebox monitoring is focused on what is happening inside the service or application. An application that has the appropriate tools returns the state of itself or internal components, the result of transactions or events. This data answers the question “how does the application work” and not the question “does the application work”. Whitebox-monitoring transfers events, logs or metrics to a special monitoring tool or provides information outward for subsequent collection by the monitoring tool.
Most people involved in modern monitoring understand that large investments need to be made in whitebox monitoring. Information obtained from within the application is significantly more valuable for business and operation than that obtained on the surface. This does not mean at all that blackbox monitoring is a waste of resources. External monitoring of services and applications is useful, especially for services that are beyond your control, or when looking from the outside gives a context that is not accessible from the inside, for example, regarding routing or DNS problems.
In the book, I focus on working with the push model, not pull. Also, a lot of attention in the book is paid to the advantages of monitoring based on the push model over the pull model. Many (if not most) monitoring systems are built specifically on the basis of the pull / polling model. In this model, the system polls the service or application that monitors. In turn, in the push model, applications and services themselves send data to the monitoring system.
For many reasons (some of which are not obvious at first glance), I prefer the push model. But the features of both approaches often do not interfere with implementation for a number of reasons (for example, because of scale). And the likelihood of success does not depend on disputes about implementation or tools. I am of the opinion that, first of all, tools should be right for you, and it makes no sense to thoughtlessly follow trends or dogmatism.
It was the desire not to be categorical and the lack of understanding of the differences by the community that inspired me to write an introductory tutorial for one of the leading monitoring tools based on the pull model: Prometheus. It is very popular, especially in the world of containers and Kubernetes.
Introducing Prometheus
Prometheus was developed by Soundcloud engineers who previously worked at Google. It is written in Go, is open source, and is developed with support from the Cloud Native Computing Foundation . The inspiration for the project was Borgmon from Google.
Prometheus is focused on whitebox monitoring. It collects time series data obtained from applications and services. The application provides this data on its own or through plugins called exporters.
The Prometheus platform is based on a server that collects and stores time series data. It has a multidimensional time series model that combines metric names and key / value pairs, called labels for metadata. Time series data is stored on the server; individual servers are autonomous and independent of distributed storage.
The platform also contains client libraries and a number of exporters for specific functions and components. For example, the StatsD exporter, which converts time series StatsD data to the Prometheus format. In addition, there is a push-gateway for receiving small amounts of incoming data and an alert manager that can process notifications generated by triggers or when thresholds for data collected by Prometheus are exceeded.
More detailed architecture can be found inPrometheus documentation .
Installation
Prometheus Server - a binary file of the same name prometheus. Take the latest version and unzip it.
$ wget https://github.com/prometheus/prometheus/releases/download/v1.8.0/prometheus-1.8.0.darwin-amd64.tar.gz
$ tar -xzf prometheus-*.tar.gz
$ cd prometheus-1.8.0.darwin-amd64/The official website also hosts various additional components: alert manager for sending notifications and exporters for a variety of services.
Setup
The prometheus binary file that we just unpacked is configured through the YAML file. Let's see what it is:
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
monitor: 'codelab-monitor'
rule_files:
# - "first.rules"
# - "second.rules"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
Three YAML blocks are defined in this configuration file:
Global
The first global block contains global settings for controlling server behavior.
scrape_interval sets the intervals between polls for an application or service, in our case 15 seconds. This is the resolution of the data scale, that is, the period of time that each data point covers.
evaluation_interval tells Prometheus how often to process data according to the rules. There are two main types of rules: recording rules and alert rules. Recording rules allow you to pre-calculate frequently used and resource-intensive expressions and save the result as new time series data. Alert rules allow you to define alert conditions. Prometheus will (re-) check these conditions every 15 seconds.
External_labels contains a list of key / value pairs for labels that will be added to any metric existing on the server, for example, when an alert is generated.
Rule files The
second block - rule_files, contains a list of files with rules for recording or alert.
Survey Configuration
The last block of scrape_configs shows all the goals that Prometheus will poll. Prometheus refers to goals as instances, and groups of instances as jobs. By default, there is only one task - prometheus. Inside it lies static_config with a list of instances (by default there is only one - the Prometheus server). It polls the localhost port 9090 to get the state metrics of the server itself. The metrics are assumed to be in / metrics, so the localhost address is locally polled: 9090 / metrics. The path can be changed using the metric_path option.
A lonely task is pretty boring, so add one more to poll the local Docker daemon. We will use the instructions in the documentationDocker and configure the daemon to return metrics from localhost: 9323 / metrics. And after that, add another task called docker.
- job_name: 'docker'
static_configs:
- targets: ['localhost:9323']
The job has a name and instance that refers to the address for receiving Docker daemon metrics. The default path is again / metrics.
The full configuration file can be found at the link .
Starting the server
Let's start the server and see what happens.
$ ./prometheus -config.file "prometheus.yml"Run the binary file and specify the configuration file in the command line flag -config.file. The Prometheus server is now running, polling instances in prometheus and docker jobs, and returning results.
Dashboard
Prometheus has a built-in interface where you can see the results. To do this, open http: // localhost: 9090 / graph in a browser .
If you click on - insert metric at cursor -, you can select one of the collected metrics. Let's look at the HTTP requests. To do this, select the metric http_requests_total and click Execute.
A list of items and values appears, for example:
http_requests_total{code="200",handler="prometheus",instance="localhost:9090",job="prometheus",method="get"}These elements are metrics that are separated by additional dimensions (they are provided by metric labels). For example, the http_requests_total metric has a handler label that contains information about the process that generates the request. The list of metrics can be reduced by selecting specific metrics containing one of these labels.
The flexibility of the expression language built into the Prometheus server makes it easy to find and aggregate metrics.
We used the handler label to select metrics for the prometheus handler only.
Additionally, we aggregate the metrics of HTTP requests. Let's say you need to see the number of HTTP requests in five minutes, broken down by tasks. To do this, we clarify the request:
sum(rate(http_requests_total[5m])) by (job)Now we’ll execute the request by clicking Execute:
Additionally, you can see the results graph by selecting the Graph tab:
On it we see the total number of HTTP requests for the last five minutes, grouped by tasks.
We can save these queries as recording rules, ensuring their automatic execution and creation of a new metric from this rule.
To do this, add the file to the rule_files block:
rule_files:
- "first.rules"
# - "second.rules"And write the following rule in the first.rules file:
job:http_requests_total:sum = sum(rate(http_requests_total[5m])) by (job)This will create a new job: http_requests_total: sum metric for each job.
Now you can make a graph from the metric and add it to the dashboard.
Alerting
Alerts, like aggregation, are rule based. To add a warning rule, you need to register another file in the rule_files block.
rule_files:
- "first.rules"
- "second.rules"In the second.rule file, create a new rule that will notify you when instances have fallen. To do this, we use one of the standard metrics for collecting: up is the state metric, its value is 1 if the poll is successful, and 0 if the poll failed.
Add an alert rule to the rules file. It should look like this:
ALERT InstanceDown
IF up == 0
FOR 5m
LABELS { severity = "moderate" }
ANNOTATIONS {
summary = "Instance {{ $labels.instance }} down",
description = "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.",
}
The alert rule is a bit like a conditional request. We give it the name InstanceDown and a set of rules. The InstanceDown alert is triggered when the up metric is 0 (i.e., the collection of metrics failed) for five minutes. We added a label to the alert: severity = moderate (i.e. severity = moderate) and annotations. Annotations allow you to add more information to the alert, for example, a description of the event. Annotations contain {{}} - brackets for standardization in Go, in which variables are registered. So we can customize the alert using templates . In our case, the variable $ labels contains the metric label, for example, $ labels.instance returns the name of the instance, $ labels.job is the name of the job, etc.
Now, five minutes after stopping the Docker daemon, Prometheus will launch our alert and send a message to the dispatcherAlertmanager (which you must first install and run separately, or use some other tool, for example, the Alerta tool ). Current notifications can be seen on the dashboard in the Alerts tab.
Conclusion
Prometheus is a great platform that is easy to install and configure. The configuration is described in YAML, which simplifies the use of the Infrastructure as Code (IaC) approach. Monitoring simple environments becomes painless thanks to a stand-alone server. Unfortunately, we could not find many examples for more complex environments, so it is worth spending time on experiments and different approaches to find the most optimal way.
The data model is very flexible, especially striking is the ease with which you can label and search metrics. I met most of the client libraries and several exporters - nothing super complicated. Creating tools and generating metrics should not cause much difficulty.
The built-in interface is clean and elegant, and in conjunction with the query language, looks like a suitable tool for debugging or scheduling resources. Recording rules are suitable for aggregating metrics.
I studied a little storage, security, server discovery, and other available integrations - the possibilities look comprehensive. A quick search on GitHub showed an impressive set of tools, integrations and examples, which for sure should be enough for a start.
The main platform has sufficient documentation, but for some related projects it is rather chaotic and incomplete. Although even with limited knowledge of Prometheus, in just an hour I managed to create a working configuration.
Distributing a single binary file without initialization or packaging scripts cannot be called a solution, ready to use out of the box, but, nevertheless, it is a working solution for many projects. There are also various preparatory scripts among configuration management systems that you can use. However, most research tools like Prometheus are likely to handle the installation on their own. Container and Kubernetes support is appealing to people using these tools. And researchers of (micro) services and dynamic or cloud stacks will be interested in server autonomy and portability.
If you have a project where you need to implement monitoring, I recommend Prometheus. It is also worth the time spent if your activities involve containers and tools like Docker and Kubernetes. Due to its flexibility, it is suitable for such tools and architectures much better than other existing platforms.
PS The inspiration for this post was the article Monitoring in the time of Cloud Native, written by Cindy Sridharan. Thanks Cindy!
THE END
We hope you find it helpful.