PostgreSQL Indexes - 7
We have already familiarized ourselves with the PostgreSQL indexing mechanism and the interface of access methods , and examined hash indexes , B-trees , GiST and SP-GiST indexes . And in this part we’ll deal with the GIN index.
Gin
- Jin? .. Jin - it seems that such an American alcoholic drink? ..
- Not a drink I, oh inquiring lad! The old man flushed again, caught himself again, and again pulled himself together. “I’m not a drink, but a powerful and undaunted spirit, and there is no magic in the world that I could not afford.”
Lazar Lagin, "The Old Man Hottabych."
Gin stands for Generalized Inverted Index and should be considered as a genie, not a drink.
Readme
General idea
GIN stands for Generalized Inverted Index - this is the so-called reverse index . It works with data types whose values are not atomic, but consist of elements. At the same time, not the values themselves are indexed, but the individual elements; each element refers to the values in which it occurs.
A good analogy for this method is the index at the end of the book, where for each term there is a list of pages where this term is mentioned. Like the pointer in the book, the index method should provide a quick search for indexed items. To do this, they are stored as an already familiar B-tree(another, simpler implementation is used for it, but in this case it is not essential). Each element has an ordered set of links to table rows containing values with this element. Ordering is not critical for data sampling (the sorting order of TIDs does not make much sense), but it is important from the point of view of the internal structure of the index.
Items are never removed from the GIN index. It is believed that the values containing the elements can disappear, appear, change, but the set of elements of which they consist is quite static. This solution greatly simplifies the algorithms that provide parallel operation with the index of several processes.
If the list of TIDs is small enough, it is placed on the same page as the item (and is called the posting list). But if the list is large, a more efficient data structure is needed, and we already know it - it is again a B-tree. Such a tree is located in separate data pages (and is called a posting tree).
Thus, the GIN index consists of a B-tree of elements, to the leaf records of which B-trees or flat lists of TIDs are attached.
Like the GiST and SP-GiST indexes discussed earlier, GIN provides an application developer with an interface to support various operations on complex data types.
Full Text Search
The main area of application of the gin method is the acceleration of full-text search, so it is logical to consider this index in more detail on this example.
In the part about GiST, there was already a small introduction to full-text search, so we will not repeat ourselves and get right to the point. It is clear that the complex values in this case are documents, and the elements of these documents are tokens.
Let's take the same example that we considered in the part about GiST (we just repeat the refrain twice): The possible structure of such an index is shown in the figure: Unlike all the previous illustrations, references to table rows (TIDs) are shown not by arrows, but by numeric values on a dark background (page number and position in the page):
postgres=# create table ts(doc text, doc_tsv tsvector);
CREATE TABLE
postgres=# insert into ts(doc) values
('Во поле береза стояла'), ('Во поле кудрявая стояла'),
('Люли, люли, стояла'), ('Люли, люли, стояла'),
('Некому березу заломати'), ('Некому кудряву заломати'),
('Люли, люли, заломати'), ('Люли, люли, заломати'),
('Я пойду погуляю'), ('Белую березу заломаю'),
('Люли, люли, заломаю'), ('Люли, люли, заломаю');
INSERT 0 12
postgres=# set default_text_search_config = russian;
SET
postgres=# update ts set doc_tsv = to_tsvector(doc);
UPDATE 12
postgres=# create index on ts using gin(doc_tsv);
CREATE INDEX
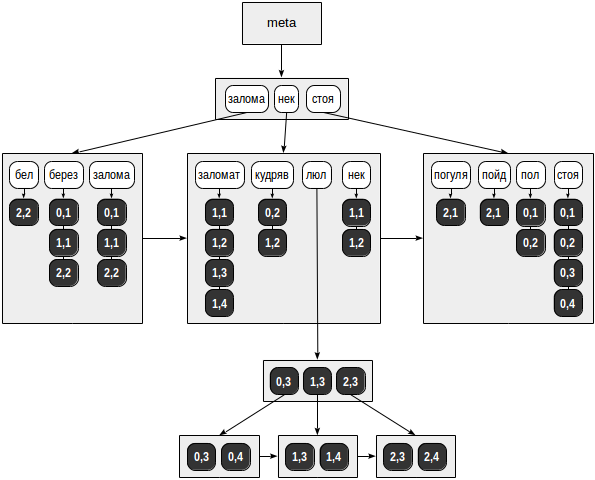
postgres=# select ctid, doc, doc_tsv from ts;
ctid | doc | doc_tsv
--------+-------------------------+--------------------------------
(0,1) | Во поле береза стояла | 'берез':3 'пол':2 'стоя':4
(0,2) | Во поле кудрявая стояла | 'кудряв':3 'пол':2 'стоя':4
(0,3) | Люли, люли, стояла | 'люл':1,2 'стоя':3
(0,4) | Люли, люли, стояла | 'люл':1,2 'стоя':3
(1,1) | Некому березу заломати | 'берез':2 'заломат':3 'нек':1
(1,2) | Некому кудряву заломати | 'заломат':3 'кудряв':2 'нек':1
(1,3) | Люли, люли, заломати | 'заломат':3 'люл':1,2
(1,4) | Люли, люли, заломати | 'заломат':3 'люл':1,2
(2,1) | Я пойду погуляю | 'погуля':3 'пойд':2
(2,2) | Белую березу заломаю | 'бел':1 'берез':2 'залома':3
(2,3) | Люли, люли, заломаю | 'залома':3 'люл':1,2
(2,4) | Люли, люли, заломаю | 'залома':3 'люл':1,2
(12 rows)
In our speculative example, the list of TIDs fit into regular pages for all tokens, except for “lyul”. This token was found in as many as six documents, and for it the list of TIDs was placed in a separate B-tree.
By the way, how to understand how many documents contain a token? For a small table, the “direct” method will also work, as shown below, but what about the large ones, we will see later. We also note that, unlike a regular B-tree, GIN index pages are linked not by a bidirectional, but by a unidirectional list. This is enough, since tree traversal is always performed in only one direction.
postgres=# select (unnest(doc_tsv)).lexeme, count(*) from ts group by 1 order by 2 desc;
lexeme | count
---------+-------
люл | 6
стоя | 4
заломат | 4
берез | 3
залома | 3
пол | 2
нек | 2
кудряв | 2
бел | 1
пойд | 1
погуля | 1
(11 rows)
Request example
How will the following query be executed in our example? First, separate tokens (search keys) are selected from the search query: “standing” and “curly”. This is performed by a special API function that takes into account the data type and strategy defined by the operator class: Next, we find both keys in the B-tree tokens and iterate over the ready lists of TIDs. We get:
postgres=# explain(costs off)
select doc from ts where doc_tsv @@ to_tsquery('стояла & кудрявая');
QUERY PLAN
------------------------------------------------------------------------
Bitmap Heap Scan on ts
Recheck Cond: (doc_tsv @@ to_tsquery('стояла & кудрявая'::text))
-> Bitmap Index Scan on ts_doc_tsv_idx
Index Cond: (doc_tsv @@ to_tsquery('стояла & кудрявая'::text))
(4 rows)
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'tsvector_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gin'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------------+--------------
@@(tsvector,tsquery) | 1 соответствие поисковому запросу
@@@(tsvector,tsquery) | 2 синоним @@ (для обратной совместимости)
(2 rows)
- for “standing” - (0.1), (0.2), (0.3), (0.4);
- for “curls” - (0.2), (1.2).
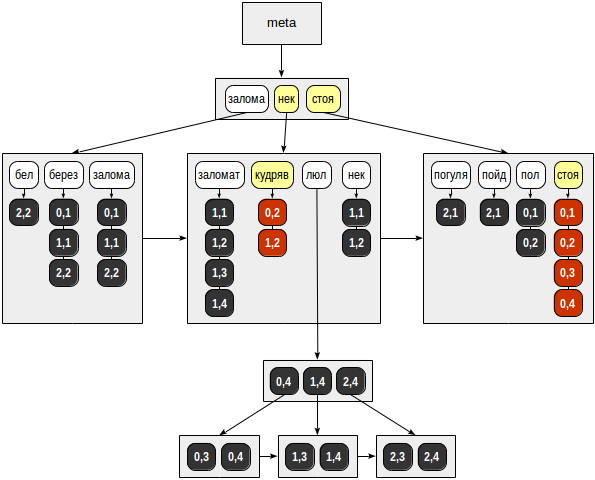
Finally, for each TID found, a matching API function is called, which should determine which of the found lines are suitable for the search query. Since the tokens in our query are combined with a logical “and”, a single line (0.2) is returned: And we get the result: If you compare this approach with the one we considered with respect to GiST, the advantage of GIN for full-text search seems obvious. But not so simple.
| | | функция
| | | согласованности
TID | стоя | кудряв | стоя & кудряв
-------+------+--------+-----------------
(0,1) | T | f | f
(0,2) | T | T | T
(0,3) | T | f | f
(0,4) | T | f | f
(1,2) | f | T | f
postgres=# select doc from ts where doc_tsv @@ to_tsquery('стояла & кудрявая');
doc
-------------------------
Во поле кудрявая стояла
(1 row)
Slow Update Problem
The fact is that inserting or updating data in the GIN index is relatively slow. Each document usually contains many tokens to be indexed. Therefore, when a single document appears or changes, one has to make massive changes to the index tree.
On the other hand, if several documents are changed at once, then some of the tokens may coincide, and the total amount of work will be less than when changing documents one by one.
The GIN index has a fastupdate storage parameter that can be specified when creating the index or changed later:
postgres=# create index on ts using gin(doc_tsv) with (fastupdate = true);
CREATE INDEX
When this option is enabled, the changes will be accumulated in the form of a separate unordered list (in separate linked pages). When this list becomes large enough, or during the cleaning process, all the accumulated changes are immediately made to the index. What is considered a “sufficiently large” list is determined by the gin_pending_list_limit configuration parameter or the index storage parameter of the same name.
But this approach also has negative aspects: firstly, the search is slowed down (due to the fact that in addition to the tree you also have to look at the unordered list), and secondly, the next change can suddenly take a lot of time if the unordered list is full.
Partial match search
В полнотекстовом поиске можно использовать частичное совпадение. Запрос формулируется, например, следующим образом:
gin=# select doc from ts where doc_tsv @@ to_tsquery('залом:*');
doc
-------------------------
Некому березу заломати
Некому кудряву заломати
Люли, люли, заломати
Люли, люли, заломати
Белую березу заломаю
Люли, люли, заломаю
Люли, люли, заломаю
(7 rows)
Такой запрос найдет документы, в которых есть лексемы, начинающиеся на «залом». То есть, в нашем примере, «залома» (которая получилась из слова «заломаю») и «заломат» (из слова «заломати»).
Запрос, разумеется, будет работать в любом случае, даже и без индексов, но GIN позволяет ускорить и такой поиск:
postgres=# explain (costs off)
select doc from ts where doc_tsv @@ to_tsquery('залом:*');
QUERY PLAN
--------------------------------------------------------------
Bitmap Heap Scan on ts
Recheck Cond: (doc_tsv @@ to_tsquery('залом:*'::text))
-> Bitmap Index Scan on ts_doc_tsv_idx
Index Cond: (doc_tsv @@ to_tsquery('залом:*'::text))
(4 rows)
При этом в дереве лексем находятся все лексемы, имеющие указанный в поисковом запросе префикс, и объединяются логическим «или».
Частые и редкие лексемы
To see how indexing works on real data, let's take the pgsql-hackers mailing archive, which we already used in the GiST thread. In this version, the archive contains 356125 letters with the date of departure, the theme, the author and the text. Take the token that is found in a large number of documents. A query using unnest will no longer work on such a volume of data, and the correct way is to use the ts_stat function, which displays information about tokens, the number of documents in which they occurred, and the total number of entries. Choose “wrote”. And let's take some rare word in the developers' mailing list, for example, “tattoo”: Are there any documents in which these tokens appear at the same time? It turns out there are:
fts=# alter table mail_messages add column tsv tsvector;
ALTER TABLE
fts=# set default_text_search_config = default;
SET
fts=# update mail_messages
set tsv = to_tsvector(body_plain);
NOTICE: word is too long to be indexed
DETAIL: Words longer than 2047 characters are ignored.
...
UPDATE 356125
fts=# create index on mail_messages using gin(tsv);
CREATE INDEX
fts=# select word, ndoc
from ts_stat('select tsv from mail_messages')
order by ndoc desc limit 3;
word | ndoc
-------+--------
re | 322141
wrote | 231174
use | 176917
(3 rows)
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') where word = 'tattoo';
word | ndoc
--------+------
tattoo | 2
(1 row)
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count
-------
1
(1 row)
The question is how to fulfill this request. If, as described above, receiving lists of TIDs for both tokens, the search is obviously inefficient: we will have to sort out more than two hundred thousand values, of which only one will be left as a result. Fortunately, using the statistics of the scheduler, the algorithm understands that the “token” token is common, and the “tattoo” is rare. Therefore, the search is performed using a rare token, and the resulting two documents are then checked for the presence of the “token” token. As you can see, the query is executed quickly: Although the search simply “wrote” - much longer: Such optimization works, of course, not only for two tokens, but also in more complex cases.
fts=# \timing on
Timing is on.
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count
-------
1
(1 row)
Time: 0,959 ms
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count
--------
231174
(1 row)
Time: 2875,543 ms (00:02,876)
Sampling limit
The peculiarity of the gin access method is that the result is always returned in the form of a bitmap: this method is not able to issue TIDs one at a time. That is why all query plans that are encountered in this part use bitmap scan.
Therefore, limiting the selection by index using the phrase LIMIT is not quite effective. Pay attention to the projected cost of the operation (“cost” field of the Limit node): The cost is estimated as 1283.61, which is slightly more than the cost of building the entire bitmap 1249.30 (the “cost” field of the Bitmap Index Scan node).
fts=# explain (costs off)
select * from mail_messages where tsv @@ to_tsquery('wrote') limit 1;
QUERY PLAN
-----------------------------------------------------------------------------------------
Limit (cost=1283.61..1285.13 rows=1)
-> Bitmap Heap Scan on mail_messages (cost=1283.61..209975.49 rows=137207)
Recheck Cond: (tsv @@ to_tsquery('wrote'::text))
-> Bitmap Index Scan on mail_messages_tsv_idx (cost=0.00..1249.30 rows=137207)
Index Cond: (tsv @@ to_tsquery('wrote'::text))
(5 rows)
Therefore, the index has a special ability to limit the number of results. The threshold value is set in the configuration parameter gin_fuzzy_search_limit and is equal to zero by default (no restriction occurs). However, it can be set: As you can see, the query produces a different number of rows for different parameter values (if index access is used). The restriction is not exact; more lines than specified can be returned - therefore fuzzy.
fts=# set gin_fuzzy_search_limit = 1000;
SET
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count
-------
5746
(1 row)
fts=# set gin_fuzzy_search_limit = 10000;
SET
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count
-------
14726
(1 row)
Compact performance
Among other things, GIN indexes are good for their compactness. Firstly, if the same token is found in several documents (and this usually happens), it is stored in the index only once. Secondly, TIDs are stored in the index in an orderly manner, and this makes it possible to use simple compression: each next TID in the list is actually stored as a difference with the previous one - usually this is a small number, which requires much less bits than the full 6 byte TID.
To get some idea of the volume, create a B-tree from the text of the letters. Honest comparison, of course, will not work:
- GIN is built on a different data type (tsvector, not text), and it’s smaller,
- but the size of the letters for the B-tree has to be shortened to about two kilobytes.
But nevertheless: At the same time, we will also build a GiST index: Index size after full cleaning (vacuum full): Due to the compactness of the presentation, you can try to use the GIN index when migrating from Oracle as a replacement for bitmap indexes (I will not go into details, but for inquisitive drain leave a link to a Lewis post ). Typically, bitmap indexes are used for fields that have slightly unique values - which is fine for the GIN as well. And PostgreSQL can build a bitmap, as we saw in the first part , on the fly based on any index, including GIN.
fts=# create index mail_messages_btree on mail_messages(substring(body_plain for 2048));
CREATE INDEX
fts=# create index mail_messages_gist on mail_messages using gist(tsv);
CREATE INDEX
fts=# select pg_size_pretty(pg_relation_size('mail_messages_tsv_idx')) as gin,
pg_size_pretty(pg_relation_size('mail_messages_gist')) as gist,
pg_size_pretty(pg_relation_size('mail_messages_btree')) as btree;
gin | gist | btree
--------+--------+--------
179 MB | 125 MB | 546 MB
(1 row)
GiST or GIN?
For many data types, there are operator classes for both GiST and GIN, which raises the question: what to use? Perhaps it is already possible to draw some conclusions.
As a rule, GIN outperforms GiST in accuracy and search speed. If the data does not change often, but you need to search quickly - most likely the choice will fall on the GIN.
On the other hand, if the data changes actively, the overhead of updating the GIN may be too high. In this case, you will have to compare both options and choose the one whose indicators will be better balanced.
Arrays
Another example of using the gin method is indexing arrays. In this case, elements of arrays fall into the index, which allows us to speed up a number of operations on them: In our demo database, there is a representation of routes with flight information. Among other things, it contains the days_of_week column - an array of days of the week on which flights are made. For example, a flight from Vnukovo to Gelendzhik leaves on Tuesdays, Thursdays and Sundays: To build an index, we “materialize” the presentation in a table: Now using the index we can find out all flights departing on Tuesdays, Thursdays and Sundays: It turns out there are 6 of these: How is such a request executed? In exactly the same way as described above:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'array_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gin'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------------+--------------
&&(anyarray,anyarray) | 1 пересечение
@>(anyarray,anyarray) | 2 содержит массив
<@(anyarray,anyarray) | 3 содержится в массиве
=(anyarray,anyarray) | 4 равенство
(4 rows)
demo=# select departure_airport_name, arrival_airport_name, days_of_week
from routes
where flight_no = 'PG0049';
departure_airport_name | arrival_airport_name | days_of_week
------------------------+----------------------+--------------
Внуково | Геленджик | {2,4,7}
(1 row)
demo=# create table routes_t as select * from routes;
SELECT 710
demo=# create index on routes_t using gin(days_of_week);
CREATE INDEX
demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7];
QUERY PLAN
-----------------------------------------------------------
Bitmap Heap Scan on routes_t
Recheck Cond: (days_of_week = '{2,4,7}'::integer[])
-> Bitmap Index Scan on routes_t_days_of_week_idx
Index Cond: (days_of_week = '{2,4,7}'::integer[])
(4 rows)
demo=# select flight_no, departure_airport_name, arrival_airport_name, days_of_week from routes_t where days_of_week = ARRAY[2,4,7];
flight_no | departure_airport_name | arrival_airport_name | days_of_week
-----------+------------------------+----------------------+--------------
PG0005 | Домодедово | Псков | {2,4,7}
PG0049 | Внуково | Геленджик | {2,4,7}
PG0113 | Нарьян-Мар | Домодедово | {2,4,7}
PG0249 | Домодедово | Геленджик | {2,4,7}
PG0449 | Ставрополь | Внуково | {2,4,7}
PG0540 | Барнаул | Внуково | {2,4,7}
(6 rows)
- From the search query, whose role is played by the array {2,4,7}, elements (search keys) are highlighted. Obviously, these will be the values “2”, “4” and “7”.
- The keys tree contains the selected keys and for each of them a list of TIDs is selected.
- From all the TIDs found, the consistency function selects those that fit the operator from the request. For the operator =, only those TIDs that are found in all three lists are suitable (in other words, the source array must contain all the elements). But this is not enough: we also need the array not to contain any other values - and we cannot check this condition by index. Therefore, in this case, the access method asks the indexing mechanism to double-check all issued TIDs according to the table.
Интересно, что бывают стратегии (например, «содержится в массиве»), которые вообще ничего не могут проверить и вынуждены перепроверять по таблице все найденные TID-ы.
А как быть, если нам нужно узнать рейсы, отправляющиеся по вторникам, четвергам и воскресеньям из Москвы? Дополнительное условие не будет поддержано индексом и попадет в графу Filter:
demo=# explain (costs off)
select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Москва';
QUERY PLAN
-----------------------------------------------------------
Bitmap Heap Scan on routes_t
Recheck Cond: (days_of_week = '{2,4,7}'::integer[])
Filter: (departure_city = 'Москва'::text)
-> Bitmap Index Scan on routes_t_days_of_week_idx
Index Cond: (days_of_week = '{2,4,7}'::integer[])
(5 rows)
В данном случае это не страшно (индекс и так отбирает всего 6 строк), но в случаях, когда дополнительное условие увеличивает селективность, хотелось бы иметь такую возможность. Правда, просто так создать индекс не получится:
demo=# create index on routes_t using gin(days_of_week,departure_city);
ERROR: data type text has no default operator class for access method "gin"
HINT: You must specify an operator class for the index or define a default operator class for the data type.
Зато поможет расширение btree_gin, добавляющее классы операторов GIN, имитирующие работу обычного B-дерева.
demo=# create extension btree_gin;
CREATE EXTENSION
demo=# create index on routes_t using gin(days_of_week,departure_city);
CREATE INDEX
demo=# explain (costs off)
select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Москва';
QUERY PLAN
---------------------------------------------------------------------
Bitmap Heap Scan on routes_t
Recheck Cond: ((days_of_week = '{2,4,7}'::integer[]) AND
(departure_city = 'Москва'::text))
-> Bitmap Index Scan on routes_t_days_of_week_departure_city_idx
Index Cond: ((days_of_week = '{2,4,7}'::integer[]) AND
(departure_city = 'Москва'::text))
(4 rows)
JSONB
Another example of a complex data type for which there is built-in GIN support is JSON. To work with JSON values, a number of operators and functions are currently defined, some of which can be accelerated using indexes: As you can see, there are two classes of operators: jsonb_ops and jsonb_path_ops. The first class of operators, jsonb_ops, is used by default. All keys, values, and elements of arrays fall into the index as elements of the original JSON document. A sign is added to each of them whether the given element is a key (this is necessary for the “exists” strategies that distinguish between keys and values). For example, imagine several lines from routes in the form of JSON as follows: An index can look like this:
postgres=# select opc.opcname, amop.amopopr::regoperator, amop.amopstrategy as str
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname in ('jsonb_ops','jsonb_path_ops')
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gin'
and amop.amoplefttype = opc.opcintype;
opcname | amopopr | str
----------------+------------------+-----
jsonb_ops | ?(jsonb,text) | 9 существует ключ верхнего уровня
jsonb_ops | ?|(jsonb,text[]) | 10 существует какой-нибудь ключ верхнего уровня
jsonb_ops | ?&(jsonb,text[]) | 11 существуют все ключи верхнего уровня
jsonb_ops | @>(jsonb,jsonb) | 7 JSON-значение содержится на верхнем уровне
jsonb_path_ops | @>(jsonb,jsonb) | 7
(5 rows)
demo=# create table routes_jsonb as
select to_jsonb(t) route
from (
select departure_airport_name, arrival_airport_name, days_of_week
from routes
order by flight_no limit 4
) t;
SELECT 4
demo=# select ctid, jsonb_pretty(route) from routes_jsonb;
ctid | jsonb_pretty
-------+-----------------------------------------------
(0,1) | { +
| "days_of_week": [ +
| 1 +
| ], +
| "arrival_airport_name": "Сургут", +
| "departure_airport_name": "Усть-Илимск" +
| }
(0,2) | { +
| "days_of_week": [ +
| 2 +
| ], +
| "arrival_airport_name": "Усть-Илимск", +
| "departure_airport_name": "Сургут" +
| }
(0,3) | { +
| "days_of_week": [ +
| 1, +
| 4 +
| ], +
| "arrival_airport_name": "Сочи", +
| "departure_airport_name": "Иваново-Южный"+
| }
(0,4) | { +
| "days_of_week": [ +
| 2, +
| 5 +
| ], +
| "arrival_airport_name": "Иваново-Южный", +
| "departure_airport_name": "Сочи" +
| }
(4 rows)
demo=# create index on routes_jsonb using gin(route);
CREATE INDEX
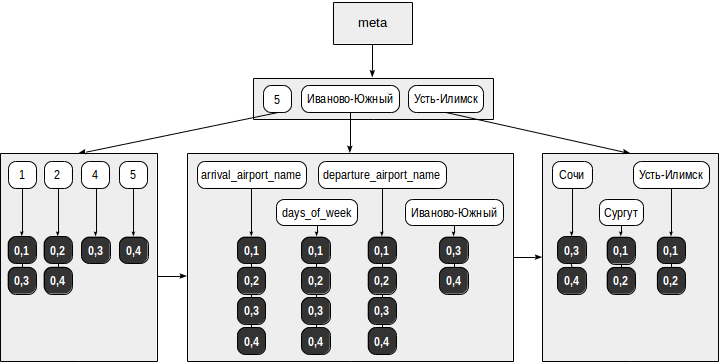
Now, for example, such a request can be performed using the index: The operator checks if the specified path ( ) is present , starting from the root of the JSON document. In our case, the query will return one line: The query is executed as follows:
demo=# explain (costs off)
select jsonb_pretty(route)
from routes_jsonb
where route @> '{"days_of_week": [5]}';
QUERY PLAN
---------------------------------------------------------------
Bitmap Heap Scan on routes_jsonb
Recheck Cond: (route @> '{"days_of_week": [5]}'::jsonb)
-> Bitmap Index Scan on routes_jsonb_route_idx
Index Cond: (route @> '{"days_of_week": [5]}'::jsonb)
(4 rows)
@>"days_of_week": [5]demo=# select jsonb_pretty(route) from routes_jsonb where route @> '{"days_of_week": [5]}';
jsonb_pretty
----------------------------------------------
{ +
"days_of_week": [ +
2, +
5 +
], +
"arrival_airport_name": "Иваново-Южный",+
"departure_airport_name": "Сочи" +
}
(1 row)
"days_of_week": [5]Elements (search keys) are selected from the search query ( ): “days_of_week” and “5”.- The keys tree contains the selected keys and for each of them a list of TIDs is selected: for "5" - (0.4) and for "days_of_week" - (0,1), (0,2), (0,3) , (0.4).
- Из всех найденных TID-ов функция согласованности выбирает те, что подходят под оператор из запроса. Для оператора
@>точно не годятся документы, которые содержат не все элементы из поискового запроса, так что остается только (0,4). Но и оставшийся TID необходимо перепроверить по таблице, потому что по индексу непонятно, в каком порядке в JSON-документе встречаются найденные элементы.
Подробнее про другие операторы можно почитать в документации.
Помимо штатных операций для работы с JSON, уже давольно давно существует расширение jsquery, определяющее язык запросов с более богатыми возможностями (и, разумеется, с поддержкой GIN-индексов). А в 2016 году вышел новый стандарт SQL, который определяет свой набор операций и язык запросов SQL/JSON path. Реализация этого стандарта уже выполнена и мы надеемся на ее появление в PostgreSQL 11.
Внутри
You can look inside the GIN index using the pageinspect extension . Information from the meta page shows general statistics: The page structure provides for a special area called “opaque” for ordinary programs like vacuum, in which access methods can save their information. This data for the GIN is shown by the gin_page_opaque_info function. For example, you can find out the composition of index pages: The gin_leafpage_items function provides information about TIDs stored in the {data, leaf, compressed} pages : Here you can see that the leaf pages of the TID tree actually do not contain separate pointers to table rows, rather small squeezed lists.
fts=# create extension pageinspect;
CREATE EXTENSION
fts=# select * from gin_metapage_info(get_raw_page('mail_messages_tsv_idx',0));
-[ RECORD 1 ]----+-----------
pending_head | 4294967295
pending_tail | 4294967295
tail_free_size | 0
n_pending_pages | 0
n_pending_tuples | 0
n_total_pages | 22968
n_entry_pages | 13751
n_data_pages | 9216
n_entries | 1423598
version | 2
fts=# select flags, count(*)
from generate_series(1,22967) as g(id), -- n_total_pages
gin_page_opaque_info(get_raw_page('mail_messages_tsv_idx',g.id))
group by flags;
flags | count
------------------------+-------
{meta} | 1 метастраница
{} | 133 внутренняя страница B-дерева элементов
{leaf} | 13618 листовая страница B-дерева элементов
{data} | 1497 внутренняя страница B-дерева TID-ов
{data,leaf,compressed} | 7719 листовая страница B-дерева TID-ов
(5 rows)
fts=# select * from gin_leafpage_items(get_raw_page('mail_messages_tsv_idx',2672));
-[ RECORD 1 ]---------------------------------------------------------------------
first_tid | (239,44)
nbytes | 248
tids | {"(239,44)","(239,47)","(239,48)","(239,50)","(239,52)","(240,3)",...
-[ RECORD 2 ]---------------------------------------------------------------------
first_tid | (247,40)
nbytes | 248
tids | {"(247,40)","(247,41)","(247,44)","(247,45)","(247,46)","(248,2)",...
...
The properties
Let's look at the properties of the gin access method (requests were given earlier ): Interestingly, GIN supports the creation of multi-column indexes. At the same time, unlike a regular B-tree, it will not store composite keys, but still separate elements, but only with the indication of the column number. Index Properties: Please note that the output of results one at a time (index scan) is not supported, only the construction of a bitmap scan is possible. Backward scan is not supported: this feature is relevant only for index scanning, but not for scanning on a bitmap. And column level properties:
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
gin | can_order | f
gin | can_unique | f
gin | can_multi_col | t
gin | can_exclude | f
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | f
bitmap_scan | t
backward_scan | f
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | f
search_array | f
search_nulls | f
Nothing is available here: neither sorting (which is understandable), nor using the index as a covering (the document itself is not stored in the index), nor working with undefined values (does not make sense for elements of a complex type).
Other data types
Here are a few more extensions that add GIN support for some data types.
- pg_trgm allows you to determine the "similarity" of words by comparing the number of matching sequences of three letters (trigrams). Two classes of operators are added, gist_trgm_ops and gin_trgm_ops, which support different operators, including comparison using LIKE and regular expressions. This extension can be used in conjunction with full-text search in order to suggest misspelled words.
- hstore implements key-value storage. For this data type, there are operator classes for different access methods, including the GIN. Although, with the advent of the jsonb data type, there are no special reasons to use hstore.
- intarray extends the functionality of integer arrays. Index support includes both GiST and GIN (operator class gin__int_ops).
And two extensions have already been mentioned in the text:
- btree_gin adds GIN support for regular data types to use in a multi-column index along with complex types.
- jsquery defines the JSON query language and the operator class for its index support. This extension is not part of the standard PostgreSQL distribution.
To be continued .