Rabbit operation (RabbitMQ) in the "Survive at any cost" mode
“ Company ” - communication operator of PJSC “Megafon”
“ Noda ” - RabbitMQ server.
“ Cluster ” is an aggregate, in our case of three, RabbitMQ nodes working as a whole.
“ Contour ” is a collection of RabbitMQ clusters, the rules for working with which are determined by the balancer in front of them.
" Balancer ", " Hap " - Haproxy - balancer, performing the function of switching the load on the clusters within the contour. A pair of Haproxy servers running in parallel is used for each loop.
" Subsystem " - the publisher and / or consumer of messages transmitted through the rabbit
" SYSTEM"- a set of Subsystems, which is a single software and hardware solution used in the Company, characterized by distribution throughout the territory of Russia, but with several centers where all the information flows and where the main calculations and calculations take place.
SYSTEM - geographically distributed system - from Khabarovsk and Vladivostok to St. Petersburg and Krasnodar. Architecturally, these are several central contours, divided by the characteristics of the subsystems connected to them.
In a nutshell: for each subscriber action follows the reaction of the Subsystems, which in turn informs the other Subsystems about events and subsequent changes. Messages are generated by any actions with the SYSTEM, not only on the part of subscribers, but also on the part of the Company's employees, and on the part of the Subsystems (a very large number of tasks are performed automatically).
Features of transport in telecom: large, no, not so, BIG stream of various data transmitted through asynchronous transport.
Some Subsystems live on separate Clusters due to the heaviness of message flows — there is simply no resource left for anyone else in the cluster, for example, with a message flow of 5-6 thousand messages / second, the amount of data transferred can reach up to 170-190 Megabytes / second. With this load profile, someone else will land on this cluster will lead to sad consequences: since there are not enough resources to process all data at the same time, the rabbit will start to drive incoming connections during the flow - simple publishers will start, with all the consequences for all Subsystems and SYSTEMS in whole
Basic requirements for transport:
For example, the very fact of the call, through the asynchronous transport flies several different messages. some messages are intended for subsystems living in the same circuit, and some are intended for transmission to central nodes. The same message can be claimed by several subsystems, therefore, at the stage of publishing a message in a rabbit, it is copied and sent to different consumers. And in some cases, copying messages is forcedly implemented on the intermediate circuit - when information must be delivered from the circuit in Khabarovsk, to the circuit in Krasnodar. Transmission is performed through one of the central Contours, where copies of messages are made, for central recipients.
In addition to the events caused by the subscriber's actions, service messages go through the transport that Subsystems exchange. This results in several thousand different message passing routes, some overlap, some exist in isolation. It is enough to name the number of queues involved in the routes on different Loops to understand the approximate scale of the transport map: On central circuits 600, 200, 260, 15 ... and on remote Contours 80-100 ...
With such involvement of transport, the requirement of 100% availability of all transport hubs no longer seem excessive. We turn to the implementation of these requirements.
In addition to RabbitMQ itself , Haproxy is used for load balancing and providing automatic response to emergency situations .
A few words about the software and hardware environment in which our rabbits exist:
It looks conceived (and implemented), all this is approximately like this:

Now for some configs.
The first section of the front describes the entry point - leading to the main cluster, the second section is designed for balancing the reserve level. If you simply describe in the backend section all backup servers of rabbits (backup instruction), then it will work the same way - if the main cluster is completely unavailable, the connections will go to the backup, however, all connections will go to FIRST in the backup server list. To ensure load balancing on all backup nodes, we are introducing another front that we make available only from localhost and assign it as the backup server.
The given example describes the balancing of the remote Circuit - which works within two data centers: the server srv-rmq {01.03.05} - live in the data center №1, srv-rmq {02.04.06} - in the data center №2. Thus, to implement the four-zod solution, we only need to add two more local fronts and two backend sections of the corresponding rabbit servers.
The balancer behavior with this configuration is the following: While at least one primary server is alive, we use it. If the main servers are not available, we work with the reserve. If at least one primary server becomes available, all connections to the backup servers are broken and, when the connection is restored, they already fall on the main cluster.
Operating experience of this configuration shows almost 100% availability of each of the circuits. This solution requires the Subsystems to be completely legitimate and simple: to be able to reconnect with the rabbit after breaking the connection.
So, we have provided load balancing for an arbitrary number of Clusters and automatic switching between them, it's time to go directly to the rabbits.
Each Cluster is created from three nodes, as practice shows - the most optimal number of nodes, which ensures the optimal balance of availability / resiliency / speed. Since the rabbit does not scale horizontally (cluster performance is equal to the performance of the slowest server), we create all nodes with the same, optimal parameters using CPU / Mem / Hdd. We arrange the servers as close as possible to each other - in our case we write down virtual machines within the same farm.
As for the preconditions, following which by the Subsystems will ensure the most stable operation and fulfillment of the requirement to preserve incoming messages:
We get a configured (at the level of the configuration file and settings in the rabbit itself) cluster, which maximally ensures the availability and safety of data. By this we implement the requirement - ensuring the availability and security of data ... in most cases.
There are several points that should be taken into account when operating such highly loaded systems:
What no setting can protect against is a collapsed mnesia base - unfortunately, it is happening with a non-zero probability. Not such global failures (for example, a complete failure of the entire data center - the load will simply switch to another cluster) lead to this deplorable result, but failures more local - within the same network segment.
And it is terrible local network failures, because emergency shutdown of one or two nodes will not lead to fatal consequences - just all requests will go to one node, and as we remember, performance depends on the performance of the node itself. Network failures (we do not take into account small interruptions of communication - they are experienced without serious consequences), lead to a situation where the nodes start the synchronization process between themselves and then the connection breaks again and again for a few seconds.
For example, repeated blinking of the network, and with a periodicity of more than 5 seconds (this is exactly the timeout set in the Hap settings, you can of course play around, but to check the effectiveness you will need to repeat the failure, which nobody wants).
One - two such iterations the cluster can still withstand, but more - the chances are already minimal. In such a situation, stopping a dropped node can save, but it's almost impossible to do it manually. More often, the result is not just a dropout of a node from the cluster with the “Network Partition” message , but also a picture when the data on the part of the queues lived just this node and did not have time to synchronize for the others. Visually, in the queue data is NaN .
And this is already an unambiguous signal - to switch to the backup cluster. Switching will provide hap, you only need to stop the rabbits on the main cluster - a matter of a few minutes. As a result, we get the restoration of transport performance and we can safely proceed to the analysis of the accident and its elimination.
In order to remove a damaged cluster from under load, in order to prevent further degradation, the simplest thing is to make the rabbit work on ports other than 5672. Since we have Hapa who monitor the rabbits in the regular port, its displacement is, for example, 5673 in the settings of the rabbit, it will allow you to start the cluster completely painlessly and try to restore its working capacity and the messages left on it.
We do in a few steps:
At startup, there will be a restructuring of the indexes and in most cases all data is restored in full. Unfortunately, failures occur as a result of which you have to physically delete all messages from the disk, leaving only the configuration — the directories msg_store_persistent , msg_store_transient , queues (for version 3.6) or msg_stores (for version 3.7) are deleted in the database folder .
After such radical therapy, the cluster is launched with preservation of the internal structure, but without messages.
And the most unpleasant option (it was observed once): The damage to the base was such that it was necessary to completely remove the entire base and rebuild the cluster from scratch.
For the convenience of managing and updating rabbits, not a ready-made assembly in rpm is used, but a rabbit disassembled using cpio and reconfigured (changed paths in scripts). The main difference: it does not require root rights for installation / configuration, is not installed on the system (the reassembled rabbit is perfectly packed in tgz) and runs from any user. This approach allows for flexible version upgrades (if this does not require a complete cluster shutdown - in this case, simply switch to the backup cluster and update, not forgetting to specify the offset port for operation). It is even possible to launch several instances of RabbitMQ on one machine — the test is very convenient for tests — you can deploy a reduced architectural copy of a combat zoo.
As a result, shamanism with cpio and paths in scripts received an assembly option: two rabbitmq-base folders (in the original assembly - mnesia folder) and rabbimq-main - put all the necessary scripts for the rabbit and erlang itself.
In rabbimq-main / bin - symlinks to the rabbit and erlang scripts and the rabbit tracking script (description below).
In rabbimq-main / init.d - the rabbitmq-server script through which the logs start / stop / rotate; in lib, the rabbit itself; in lib64, erlang (a truncated version is used, only for rabbit operation, erlang version).
The resulting build is extremely easy to update when new versions are released - add the contents of rabbimq-main / lib and rabbimq-main / lib64 from new versions and replace the symlinks in the bin. If the update also affects control scripts, simply changing the paths to ours in them.
The solid advantage of this approach is the complete continuity of versions - all paths, scripts, control commands remain unchanged, which allows you to use any self-written service scripts without finishing each version.
Since the fall of rabbits, an event, though rare, is happening, it was necessary to embody a mechanism for tracking their well-being - raising in case of a fall (while maintaining the logs of the reasons for the fall). The fall of the node in 99% of cases is accompanied by a log entry, even kill and it leaves traces; this allowed monitoring the trash state with a simple script.
For versions 3.6 and 3.7, the script is slightly different due to the differences in the log entries.
We start in the crontab account under which the rabbit will work (by default rabbitmq) the execution of this script (script name: check_and_run) every minute (for a start we ask the admin to issue the rights to use crontab to the account, but if you have root rights, we do it ourselves):
* / 1 * * * * ~ / rabbitmq-main / bin / check_and_run The
second moment of using the reassembled crawl is the rooting of logs.
Since we are not tied to the logrotate system - we use the functionality provided by the developer: rabbitmq-server script from init.d (for version 3.6)
Making small changes to rotate_logs_rabbitmq ()
Add:
The result of running the rabbitmq-server script with the rotate-logs key: logs are compressed with gzip and stored only for the last 30 days. http_api - the path where the rabbit adds http logs - is configured in the configuration file: {rabbitmq_management, [{rates_mode, detailed}, {http_log_dir, path_to_logs / http_api "}]}
At the same time, I pay attention to {rates_mode, detailed }- the option somewhat increases the load, but it allows you to see on the WEB interface (and, accordingly, get through the API) information about who publishes messages to the Exchanges. Information is extremely necessary, because all connections go through the balancer - we will only see the IP of the balancers themselves. And if you confuse all the subsystems that work with the rabbit so that they fill out the “Client properties” in the properties of their connections to rabbits, then it will be possible at the connection level to get detailed information about who exactly where and with what intensity publishes messages.
With the release of new versions 3.7 there was a complete rejection of the rabbimq-server scriptin init.d. In order to facilitate operation (uniformity of control commands regardless of the rabbit version) and a smoother transition between versions, we continue to use this script in the reassembled rabbit. It’s true again: we ’ll change rotate_logs_rabbitmq () a bit , since in 3.7 the naming mechanism for logs changed after rooting:
Now you only have to make a crontab job for rotirovaniyu logs - for example every day at 23-00:
00 23 * * * ~ / rabbitmq-main
/ init.d / rabbitmq-server rotate-logs We turn to the tasks that need to be addressed within the framework of operation "Rabbit farm":
The operation of our zoo and the solution of the voiced tasks by means of the supplied rabbitmq_management staff plug-in is possible, but extremely inconvenient, which is why the shell was developed and implemented to control the entire diversity of rabbits .
“ Noda ” - RabbitMQ server.
“ Cluster ” is an aggregate, in our case of three, RabbitMQ nodes working as a whole.
“ Contour ” is a collection of RabbitMQ clusters, the rules for working with which are determined by the balancer in front of them.
" Balancer ", " Hap " - Haproxy - balancer, performing the function of switching the load on the clusters within the contour. A pair of Haproxy servers running in parallel is used for each loop.
" Subsystem " - the publisher and / or consumer of messages transmitted through the rabbit
" SYSTEM"- a set of Subsystems, which is a single software and hardware solution used in the Company, characterized by distribution throughout the territory of Russia, but with several centers where all the information flows and where the main calculations and calculations take place.
SYSTEM - geographically distributed system - from Khabarovsk and Vladivostok to St. Petersburg and Krasnodar. Architecturally, these are several central contours, divided by the characteristics of the subsystems connected to them.
What is the task of transport in the realities of telecom?
In a nutshell: for each subscriber action follows the reaction of the Subsystems, which in turn informs the other Subsystems about events and subsequent changes. Messages are generated by any actions with the SYSTEM, not only on the part of subscribers, but also on the part of the Company's employees, and on the part of the Subsystems (a very large number of tasks are performed automatically).
Features of transport in telecom: large, no, not so, BIG stream of various data transmitted through asynchronous transport.
Some Subsystems live on separate Clusters due to the heaviness of message flows — there is simply no resource left for anyone else in the cluster, for example, with a message flow of 5-6 thousand messages / second, the amount of data transferred can reach up to 170-190 Megabytes / second. With this load profile, someone else will land on this cluster will lead to sad consequences: since there are not enough resources to process all data at the same time, the rabbit will start to drive incoming connections during the flow - simple publishers will start, with all the consequences for all Subsystems and SYSTEMS in whole
Basic requirements for transport:
- Availability of transport should be 99.99%. In practice, this translates into a 24/7 job requirement and the ability to automatically respond to any emergencies.
- Data security:% of lost messages on the transport should strive to 0.
For example, the very fact of the call, through the asynchronous transport flies several different messages. some messages are intended for subsystems living in the same circuit, and some are intended for transmission to central nodes. The same message can be claimed by several subsystems, therefore, at the stage of publishing a message in a rabbit, it is copied and sent to different consumers. And in some cases, copying messages is forcedly implemented on the intermediate circuit - when information must be delivered from the circuit in Khabarovsk, to the circuit in Krasnodar. Transmission is performed through one of the central Contours, where copies of messages are made, for central recipients.
In addition to the events caused by the subscriber's actions, service messages go through the transport that Subsystems exchange. This results in several thousand different message passing routes, some overlap, some exist in isolation. It is enough to name the number of queues involved in the routes on different Loops to understand the approximate scale of the transport map: On central circuits 600, 200, 260, 15 ... and on remote Contours 80-100 ...
With such involvement of transport, the requirement of 100% availability of all transport hubs no longer seem excessive. We turn to the implementation of these requirements.
How we solve the tasks
In addition to RabbitMQ itself , Haproxy is used for load balancing and providing automatic response to emergency situations .
A few words about the software and hardware environment in which our rabbits exist:
- All rabbit servers are virtual, with parameters of 8-12 CPU, 16 Gb Mem, 200 Gb HDD. As experience has shown, even the use of creepy non-virtual servers for 90 cores and a bunch of RAM provides a small performance boost at a significantly higher cost. Versions used: 3.6.6 (in practice - the most stable of 3.6) with an erlang of 18.3, 3.7.6 with an erlang of 20.1.
- For Haproxy, the requirements are much lower: 2 CPU, 4 Gb Mem, haproxy version - 1.8 stable. Resource congestion, on all haproxy servers, does not exceed 15% CPU / Mem.
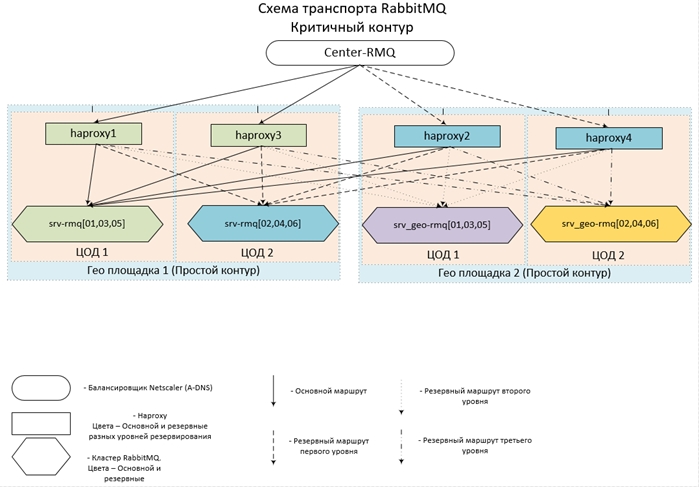
- The entire zoo is located in 14 data centers at 7 sites throughout the country, united in a single network. In each of the data centers there is a cluster of three nods and one hap.
- For remote circuits, 2 data centers are used; for each of the central circuits, 4 each.
- Central Contours interact both with each other and with remote Contours, in turn, remote Contours work only with central ones, they do not have a direct connection between themselves.
- The configurations of Hapov and Clusters within one Contour are completely identical. The entry point for each Contour is a pseudonym for several A-DNS records. Thus, in order not to happen, at least one hap and at least one of the clusters (at least one node in the cluster) will be available in each circuit. Since the case of failure of even 6 servers in two data centers at the same time is extremely unlikely, the availability is close to 100%.
It looks conceived (and implemented), all this is approximately like this:
Now for some configs.
Haproxy configuration
| frontend center-rmq_5672 | ||
| bind | *: 5672 | |
| mode | tcp | |
| maxconn | 10,000 | |
| timeout client | 3h | |
| option | tcpka | |
| option | tcplog | |
| default_backend | center-rmq_5672 | |
| frontend center-rmq_5672_lvl_1 | ||
| bind | localhost: 56721 | |
| mode | tcp | |
| maxconn | 10,000 | |
| timeout client | 3h | |
| option | tcpka | |
| option | tcplog | |
| default_backend | center-rmq_5672_lvl_1 | |
| backend center-rmq_5672 | ||
| balance | leastconn | |
| mode | tcp | |
| fullconn | 10,000 | |
| timeout | server 3h | |
| server | srv-rmq01 10.10.10.10:5672 check inter 5s rise 2 fall 3 on-marked-up shutdown-backup-sessions | |
| server | srv-rmq03 10.10.10.11:5672 check inter 5s rise 2 fall 3 on-marked-up shutdown-backup-sessions | |
| server | srv-rmq05 10.10.10.12:5672 check inter 5s rise 2 fall 3 on-marked-up shutdown-backup-sessions | |
| server | localhost 127.0.0.1:56721 check inter 5s rise 2 fall 3 backup on-marked-down shutdown-sessions | |
| backend center-rmq_5672_lvl_1 | ||
| balance | leastconn | |
| mode | tcp | |
| fullconn | 10000 | |
| timeout | server 3h | |
| server | srv-rmq02 10.10.10.13:5672 check inter 5s rise 2 fall 3 on-marked-up shutdown-backup-sessions | |
| server | srv-rmq04 10.10.10.14:5672 check inter 5s rise 2 fall 3 on-marked-up shutdown-backup-sessions | |
| server | srv-rmq06 10.10.10.5:5672 check inter 5s rise 2 fall 3 on-marked-up shutdown-backup-sessions |
The first section of the front describes the entry point - leading to the main cluster, the second section is designed for balancing the reserve level. If you simply describe in the backend section all backup servers of rabbits (backup instruction), then it will work the same way - if the main cluster is completely unavailable, the connections will go to the backup, however, all connections will go to FIRST in the backup server list. To ensure load balancing on all backup nodes, we are introducing another front that we make available only from localhost and assign it as the backup server.
The given example describes the balancing of the remote Circuit - which works within two data centers: the server srv-rmq {01.03.05} - live in the data center №1, srv-rmq {02.04.06} - in the data center №2. Thus, to implement the four-zod solution, we only need to add two more local fronts and two backend sections of the corresponding rabbit servers.
The balancer behavior with this configuration is the following: While at least one primary server is alive, we use it. If the main servers are not available, we work with the reserve. If at least one primary server becomes available, all connections to the backup servers are broken and, when the connection is restored, they already fall on the main cluster.
Operating experience of this configuration shows almost 100% availability of each of the circuits. This solution requires the Subsystems to be completely legitimate and simple: to be able to reconnect with the rabbit after breaking the connection.
So, we have provided load balancing for an arbitrary number of Clusters and automatic switching between them, it's time to go directly to the rabbits.
Each Cluster is created from three nodes, as practice shows - the most optimal number of nodes, which ensures the optimal balance of availability / resiliency / speed. Since the rabbit does not scale horizontally (cluster performance is equal to the performance of the slowest server), we create all nodes with the same, optimal parameters using CPU / Mem / Hdd. We arrange the servers as close as possible to each other - in our case we write down virtual machines within the same farm.
As for the preconditions, following which by the Subsystems will ensure the most stable operation and fulfillment of the requirement to preserve incoming messages:
- Work with a rabbit is only under the protocol amqp / amqps - through balancing. Authorization under local accounts - within each Cluster (and of the Outline as a whole)
- Subsystems are connected to the rabbit in the passive mode: No manipulations with the entities of the crawls (creating queues / exchanges / binds) are allowed and limited to the level of account rights - we simply do not give permission to configure.
- All necessary entities are created centrally, not by means of the Subsystems, and on all Contour Clusters are done in the same way - to ensure automatic switching to the backup Cluster and back. Otherwise, we can get the picture: we have switched to the reserve, but there is no queue or bind there, and we can get either a connection error or a message loss to choose from.
Now directly settings on rabbits:
- Local KMs do not have access to the Web interface.
- Access to the Web is organized through LDAP - we integrate with AD and we get logging who and where on the webcam went. At the configuration level, we restrict the rights of the AD accounts, not only do we require being in a certain group, so we give only the rights to “look”. Monitoring groups are more than enough. And we assign administrator rights to another group in AD, thus the range of influence on transport is strongly limited.
- To facilitate administration and tracking:
At all VHOST, we immediately hang a level 0 policy with application to all queues (pattern:. *):- ha-mode: all - store all data on all nodes of the cluster, reduces the speed of processing messages, but ensures their safety and availability.
- ha-sync-mode: automatic - we instruct the crawler to automatically synchronize data on all nodes of the cluster: the safety and availability of data also increases.
- queue-mode: lazy - perhaps one of the most useful options that appeared in rabbits from version 3.6 - the immediate recording of messages on the HDD. This option drastically reduces the consumption of RAM and increases the data integrity when the node stops or falls or the cluster as a whole.
- Settings in the configuration file ( rabbitmq-main / conf / rabbitmq.config ):
- Section rabbit : {vm_memory_high_watermark_paging_ratio, 0.5} - the threshold for downloading messages to disk is 50%. When lazy is on, it serves more like insurance when we draw a policy, for example, level 1, in which we forget to include lazy .
- {vm_memory_high_watermark, 0.95} - we limit the crawl to 95% of the total RAM, since only the rabbit lives on the servers, there is no point in imposing more stringent restrictions. 5% "broad gesture" so be it - leave the OS, monitoring and other useful trifles. Since this value is the upper limit - there is enough resources for everyone.
- {cluster_partition_handling, pause_minority} - describes the behavior of the cluster when a Network Partition occurs, for three or more node clusters, it is recommended that this flag - allows the cluster to recover itself.
- {disk_free_limit, "500MB"} - everything is simple when there is 500 MB of free disk space - the publication of messages will be stopped, only reading will be available.
- {auth_backends, [rabbit_auth_backend_internal, rabbit_auth_backend_ldap]} - authorization order in rabbits: First, check for the presence of KM in the local database and if not, go to the LDAP server.
- Section rabbitmq_auth_backend_ldap - configuration of interaction with AD: {servers, ["srv_dc1", "srv_dc2"]} - list of domain controllers on which authentication will take place.
- The parameters that directly describe the user in AD, the LDAP port, etc., are very individual and are described in detail in the documentation.
- The most important thing for us is a description of the rights and restrictions on the administration and access to the Web interface of krolley: tag_queries:
[{administrator, {in_group, "cn = rabbitmq-admins, ou = GRP, ou = GRP_MAIN, dc = My_domain, dc = ru" }},
{monitoring,
{in_group, “cn = rabbitmq-web, ou = GRP, ou = GRP_MAIN, dc = My_domain, dc = ru”}
}] - this design provides administrative privileges to all users of rabbitmq-admins and monitoring rights (minimum sufficient for access to view) for rabbitmq-web group. - resource_access_query :
{for,
[{permission, configure, {in_group, "cn = rabbitmq-admins, ou = GRP, ou = GRP_MAIN, dc = My_domain, dc = en"}},
{permission, write, {in_group, "cn = rabbitmq-admins, ou = GRP, ou = GRP_MAIN, dc = My_domain, dc = en "}},
{permission, read, {constant, true}}
]
} - we ensure the rights to configure and write only to the group of administrators, everything else who successfully authorized the rights are read-only - can read messages via the Web interface.
We get a configured (at the level of the configuration file and settings in the rabbit itself) cluster, which maximally ensures the availability and safety of data. By this we implement the requirement - ensuring the availability and security of data ... in most cases.
There are several points that should be taken into account when operating such highly loaded systems:
- It is better to organize all additional properties of queues (TTL, expire, max-length, etc.) by politicians, and not to hang them with parameters when creating queues. It turns out a flexibly customizable structure that can be customized on the fly to changing realities.
- Using TTL. The longer the queue, the higher the load on the CPU. In order to prevent the “penetration of the ceiling” it is better to limit the queue length in max-length.
- In addition to the rabbit itself, a number of service applications are spinning on the server, which, oddly enough, also requires CPU resources. A greedy rabbit, by default, occupies all the available cores ... It can be an unpleasant situation: the struggle for resources, which will easily lead to brakes on a rabbit. To avoid the occurrence of such a situation, you can, for example, like this: Change the erlang launch parameters — enter a forced limit on the number of used cores. We do this as follows: find the file rabbitmq-env, look for the SERVER_ERL_ARGS = parameter and add to it + sct L0-Xc0-X + SY: Y. Where X is the number of 1 cores (counting starts from 0), Y is the Number of cores -1 (counting from 1). + sct L0-Xc0-X - changes the binding to the cores, + SY: Y - changes the number of shearlers triggered by the Erlang. So for a system of 8 cores, the added parameters will take the form: + sct L0-6c0-6 + S 7: 7. By this we give the rabbit only 7 cores and expect that the OS will launch other processes optimally and hang them on the unloaded core.
The nuances of operating the resulting zoo
What no setting can protect against is a collapsed mnesia base - unfortunately, it is happening with a non-zero probability. Not such global failures (for example, a complete failure of the entire data center - the load will simply switch to another cluster) lead to this deplorable result, but failures more local - within the same network segment.
And it is terrible local network failures, because emergency shutdown of one or two nodes will not lead to fatal consequences - just all requests will go to one node, and as we remember, performance depends on the performance of the node itself. Network failures (we do not take into account small interruptions of communication - they are experienced without serious consequences), lead to a situation where the nodes start the synchronization process between themselves and then the connection breaks again and again for a few seconds.
For example, repeated blinking of the network, and with a periodicity of more than 5 seconds (this is exactly the timeout set in the Hap settings, you can of course play around, but to check the effectiveness you will need to repeat the failure, which nobody wants).
One - two such iterations the cluster can still withstand, but more - the chances are already minimal. In such a situation, stopping a dropped node can save, but it's almost impossible to do it manually. More often, the result is not just a dropout of a node from the cluster with the “Network Partition” message , but also a picture when the data on the part of the queues lived just this node and did not have time to synchronize for the others. Visually, in the queue data is NaN .
And this is already an unambiguous signal - to switch to the backup cluster. Switching will provide hap, you only need to stop the rabbits on the main cluster - a matter of a few minutes. As a result, we get the restoration of transport performance and we can safely proceed to the analysis of the accident and its elimination.
In order to remove a damaged cluster from under load, in order to prevent further degradation, the simplest thing is to make the rabbit work on ports other than 5672. Since we have Hapa who monitor the rabbits in the regular port, its displacement is, for example, 5673 in the settings of the rabbit, it will allow you to start the cluster completely painlessly and try to restore its working capacity and the messages left on it.
We do in a few steps:
- We stop all the nodes of the failed cluster - hap will switch the load to the backup cluster
- Add RABBITMQ_NODE_PORT = 5673 to the rabbitmq-env file — when the rabbit starts up, these settings will be pulled, and the Web interface will still work on 15672.
- We specify the new port on all nodes of the untimely deceased cluster and launch them.
At startup, there will be a restructuring of the indexes and in most cases all data is restored in full. Unfortunately, failures occur as a result of which you have to physically delete all messages from the disk, leaving only the configuration — the directories msg_store_persistent , msg_store_transient , queues (for version 3.6) or msg_stores (for version 3.7) are deleted in the database folder .
After such radical therapy, the cluster is launched with preservation of the internal structure, but without messages.
And the most unpleasant option (it was observed once): The damage to the base was such that it was necessary to completely remove the entire base and rebuild the cluster from scratch.
For the convenience of managing and updating rabbits, not a ready-made assembly in rpm is used, but a rabbit disassembled using cpio and reconfigured (changed paths in scripts). The main difference: it does not require root rights for installation / configuration, is not installed on the system (the reassembled rabbit is perfectly packed in tgz) and runs from any user. This approach allows for flexible version upgrades (if this does not require a complete cluster shutdown - in this case, simply switch to the backup cluster and update, not forgetting to specify the offset port for operation). It is even possible to launch several instances of RabbitMQ on one machine — the test is very convenient for tests — you can deploy a reduced architectural copy of a combat zoo.
As a result, shamanism with cpio and paths in scripts received an assembly option: two rabbitmq-base folders (in the original assembly - mnesia folder) and rabbimq-main - put all the necessary scripts for the rabbit and erlang itself.
In rabbimq-main / bin - symlinks to the rabbit and erlang scripts and the rabbit tracking script (description below).
In rabbimq-main / init.d - the rabbitmq-server script through which the logs start / stop / rotate; in lib, the rabbit itself; in lib64, erlang (a truncated version is used, only for rabbit operation, erlang version).
The resulting build is extremely easy to update when new versions are released - add the contents of rabbimq-main / lib and rabbimq-main / lib64 from new versions and replace the symlinks in the bin. If the update also affects control scripts, simply changing the paths to ours in them.
The solid advantage of this approach is the complete continuity of versions - all paths, scripts, control commands remain unchanged, which allows you to use any self-written service scripts without finishing each version.
Since the fall of rabbits, an event, though rare, is happening, it was necessary to embody a mechanism for tracking their well-being - raising in case of a fall (while maintaining the logs of the reasons for the fall). The fall of the node in 99% of cases is accompanied by a log entry, even kill and it leaves traces; this allowed monitoring the trash state with a simple script.
For versions 3.6 and 3.7, the script is slightly different due to the differences in the log entries.
For version 3.6
#!/usr/bin/pythonimport subprocess
import os
import datetime
import zipfile
defLastRow(fileName,MAX_ROW=200):with open(fileName,'rb') as f:
f.seek(-min(os.path.getsize(fileName),MAX_ROW),2)
return (f.read().splitlines())[-1]
if os.path.isfile('/data/logs/rabbitmq/startup_log'):
ifb'FAILED'in LastRow('/data/logs/rabbitmq/startup_log'):
proc = subprocess.Popen("ps x|grep rabbitmq-server|grep -v 'grep'", shell=True, stdout=subprocess.PIPE)
out = proc.stdout.readlines()
if str(out) == '[]':
cur_dt=datetime.datetime.now()
try:
os.stat('/data/logs/rabbitmq/after_crush')
except:
os.mkdir('/data/logs/rabbitmq/after_crush')
z=zipfile.ZipFile('/data/logs/rabbitmq/after_crush/repair_log'+'-'+str(cur_dt.day).zfill(2)+str(cur_dt.month).zfill(2)+str(cur_dt.year)+'_'+str(cur_dt.hour).zfill(2)+'-'+str(cur_dt.minute).zfill(2)+'-'+str(cur_dt.second).zfill(2)+'.zip','a')
z.write('/data/logs/rabbitmq/startup_err','startup_err')
proc = subprocess.Popen("~/rabbitmq-main/init.d/rabbitmq-server start", shell=True, stdout=subprocess.PIPE)
out = proc.stdout.readlines()
z.writestr('res_restart.log',str(out))
z.close()
my_file = open("/data/logs/rabbitmq/run.time", "a")
my_file.write(str(cur_dt)+"\n")
my_file.close()
For 3.7, only two lines change
if (os.path.isfile('/data/logs/rabbitmq/startup_log')) and (os.path.isfile('/data/logs/rabbitmq/startup_err')):
if ((b' OK 'in LastRow('/data/logs/rabbitmq/startup_log')) or (b'FAILED'in LastRow('/data/logs/rabbitmq/startup_log'))) andnot (b'Gracefully halting Erlang VM'in LastRow('/data/logs/rabbitmq/startup_err')):
We start in the crontab account under which the rabbit will work (by default rabbitmq) the execution of this script (script name: check_and_run) every minute (for a start we ask the admin to issue the rights to use crontab to the account, but if you have root rights, we do it ourselves):
* / 1 * * * * ~ / rabbitmq-main / bin / check_and_run The
second moment of using the reassembled crawl is the rooting of logs.
Since we are not tied to the logrotate system - we use the functionality provided by the developer: rabbitmq-server script from init.d (for version 3.6)
Making small changes to rotate_logs_rabbitmq ()
Add:
find ${RABBITMQ_LOG_BASE}/http_api/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {}
find ${RABBITMQ_LOG_BASE}/*.log.*.back -maxdepth 0 -type f | xargs -i gzip {}
find ${RABBITMQ_LOG_BASE}/*.gz -type f -mtime +30 -delete
find ${RABBITMQ_LOG_BASE}/http_api/*.gz -type f -mtime +30 -delete
The result of running the rabbitmq-server script with the rotate-logs key: logs are compressed with gzip and stored only for the last 30 days. http_api - the path where the rabbit adds http logs - is configured in the configuration file: {rabbitmq_management, [{rates_mode, detailed}, {http_log_dir, path_to_logs / http_api "}]}
At the same time, I pay attention to {rates_mode, detailed }- the option somewhat increases the load, but it allows you to see on the WEB interface (and, accordingly, get through the API) information about who publishes messages to the Exchanges. Information is extremely necessary, because all connections go through the balancer - we will only see the IP of the balancers themselves. And if you confuse all the subsystems that work with the rabbit so that they fill out the “Client properties” in the properties of their connections to rabbits, then it will be possible at the connection level to get detailed information about who exactly where and with what intensity publishes messages.
With the release of new versions 3.7 there was a complete rejection of the rabbimq-server scriptin init.d. In order to facilitate operation (uniformity of control commands regardless of the rabbit version) and a smoother transition between versions, we continue to use this script in the reassembled rabbit. It’s true again: we ’ll change rotate_logs_rabbitmq () a bit , since in 3.7 the naming mechanism for logs changed after rooting:
mv ${RABBITMQ_LOG_BASE}/$NODENAME.log.0 ${RABBITMQ_LOG_BASE}/$NODENAME.log.$(date +%Y%m%d-%H%M%S).back
mv ${RABBITMQ_LOG_BASE}/$(echo$NODENAME)_upgrade.log.0 ${RABBITMQ_LOG_BASE}/$(echo$NODENAME)_upgrade.log.$(date +%Y%m%d-%H%M%S).back
find ${RABBITMQ_LOG_BASE}/http_api/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {}
find ${RABBITMQ_LOG_BASE}/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {}
find ${RABBITMQ_LOG_BASE}/*.gz -type f -mtime +30 -delete
find ${RABBITMQ_LOG_BASE}/http_api/*.gz -type f -mtime +30 -delete
Now you only have to make a crontab job for rotirovaniyu logs - for example every day at 23-00:
00 23 * * * ~ / rabbitmq-main
/ init.d / rabbitmq-server rotate-logs We turn to the tasks that need to be addressed within the framework of operation "Rabbit farm":
- Manipulations with entities of rabbits - creation / removal of entities of a rabbit: ekschendzhey, turns, binds, chauvelov, users, the politician. And to do this is absolutely identical in all Contour Clusters.
- After switching to / from the backup Cluster, it is required to transfer messages that remain on it to the current Cluster.
- Backup Configurations of All Clusters of All Contours
- Full synchronization of Cluster configurations within the contour
- Stop / start rabbits
- Analyze current data streams: do all messages go and, if they do, go where they should or…
- Find and catch passing messages by any criteria.
The operation of our zoo and the solution of the voiced tasks by means of the supplied rabbitmq_management staff plug-in is possible, but extremely inconvenient, which is why the shell was developed and implemented to control the entire diversity of rabbits .