Life hacks for developers: efficient use of SQ (Source Qualifier) in the Informatica Power Center
Hello to all Habroresidents!
We open the blog of RDTEX company with the first post with life hacks for developers. We hope that some of the readers will take advantage of them.
Life hacks were invented during the work on a project to transfer data from one system to another for the subsequent construction of reports in one of the leading banks in the Russian Federation.
Technologies used:
Data source system - Oracle RDBMS (version 11.2.0.4.0)
Data receiver system - Oracle RDBMS (version 11.2.0.4.0)
Integration bus - Informatica (version 10.1.1)
During the implementation of a large integration project, we encountered the following problems:
1. Inefficient use of SQ [Source Qualifier] in the Informatica Power Center.
When using SQ [Source Qualifier] in the Informatica Power Center a limit on the number of characters entered was revealed. The maximum allowable number of characters is 32767. An example of inappropriate use of Source Qualifier is shown in the figure below:
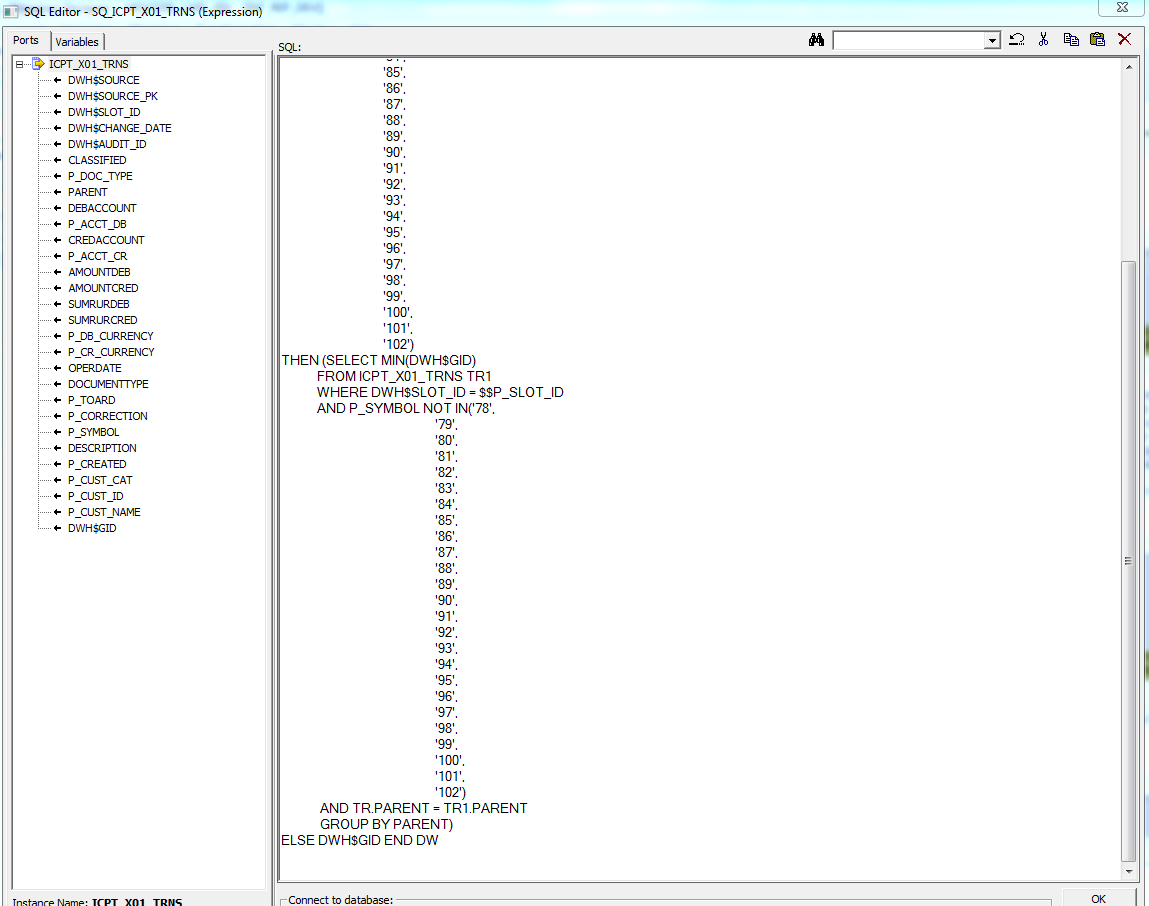
Figure 1 Screenshot from SQ Informatica Power Center
This screenshot shows that the spaces eat up character space, so complex SQL queries do not completely fit ( cropped when pasted into Source Qualifier).
The figure below shows the correct use of Source Qualifier (changes are highlighted with a red marker):
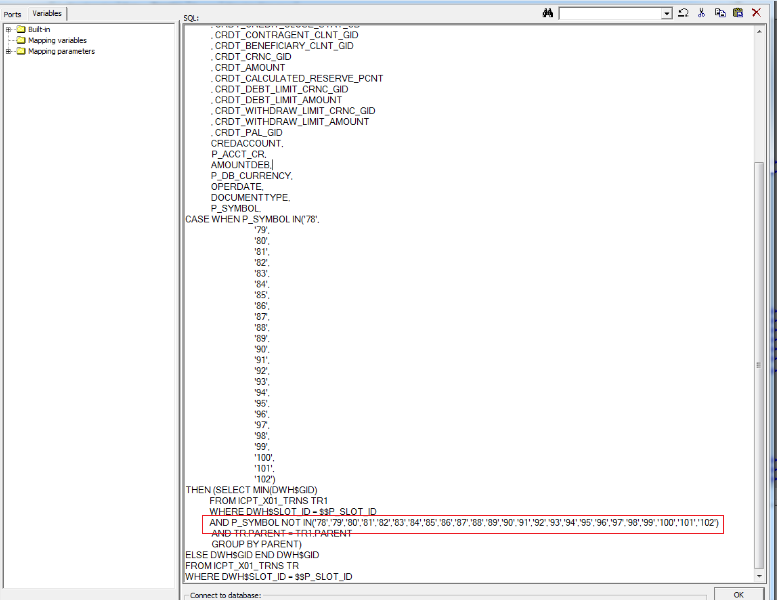
Figure 2 Screenshot from SQ Informatica Power Center with a modified query.
Switching to the next line and alignment was worth the Nth number of characters, removing which we could fit all the SQL code.
2. Incorrect conversion of infinitely large numbers.
Infinitely large numbers were loaded into the Oracle database in the following format:
12676506002282300000000000000
A should have been loaded in the format:
1267650600228229401496703205376
Ie values were rounded, starting with a certain digit of the number.
We propose the following solution:
During the development of mappings in the Informatica Power Center, the field format (for example, string) is immediately entered at a certain stage for values that will definitely come larger, while:
If we summarize the use of the tool, we can distinguish the following advantages :
And a few drawbacks for the objectivity of the picture:
We open the blog of RDTEX company with the first post with life hacks for developers. We hope that some of the readers will take advantage of them.
Life hacks were invented during the work on a project to transfer data from one system to another for the subsequent construction of reports in one of the leading banks in the Russian Federation.
Technologies used:
Data source system - Oracle RDBMS (version 11.2.0.4.0)
Data receiver system - Oracle RDBMS (version 11.2.0.4.0)
Integration bus - Informatica (version 10.1.1)
During the implementation of a large integration project, we encountered the following problems:
1. Inefficient use of SQ [Source Qualifier] in the Informatica Power Center.
When using SQ [Source Qualifier] in the Informatica Power Center a limit on the number of characters entered was revealed. The maximum allowable number of characters is 32767. An example of inappropriate use of Source Qualifier is shown in the figure below:
Figure 1 Screenshot from SQ Informatica Power Center
This screenshot shows that the spaces eat up character space, so complex SQL queries do not completely fit ( cropped when pasted into Source Qualifier).
The figure below shows the correct use of Source Qualifier (changes are highlighted with a red marker):
Figure 2 Screenshot from SQ Informatica Power Center with a modified query.
Switching to the next line and alignment was worth the Nth number of characters, removing which we could fit all the SQL code.
2. Incorrect conversion of infinitely large numbers.
Infinitely large numbers were loaded into the Oracle database in the following format:
12676506002282300000000000000
A should have been loaded in the format:
1267650600228229401496703205376
Ie values were rounded, starting with a certain digit of the number.
We propose the following solution:
During the development of mappings in the Informatica Power Center, the field format (for example, string) is immediately entered at a certain stage for values that will definitely come larger, while:
- If we use the decimal format and if the values we can have up to 28 characters, then you need to enable Properties → “Enable high precision” → “Yes” in the workflow properties in Workflow Manager.
- If we use the double format, while this attribute may receive values greater than 15 characters (for example, 20), then the value will terminate to 15 significant digits and put zero (0) in the rest (i.e. the last 5 characters will be zero ). In this case, it is better to affix the string format and increase the size to the desired one (for example, string20).
If we summarize the use of the tool, we can distinguish the following advantages :
- the tool is convenient for transferring large amounts of data, calculated by terabytes (for example, up to 25-30 tb), especially if you need to transfer them with a minimum number of conversions (almost one-to-one);
- the ability to automatically "pull" attributes (option Propagate Attributes), as well as the "backlight" inside the mapping (from where and where the data is pulled);
- the ability to select the operation mode of both the ETL tool and the ELT tool (depending on the specific IT project).
And a few drawbacks for the objectivity of the picture:
- the lack of "complex" logic data conversion;
- from the point of view of support of the tool itself and understanding of the logic of the operation of individual transformations, it is inferior to some competitors (for example, Oracle Data Integrator).