Three ideas on how to improve development efficiency: Results of the Machine Learning hackathon at SberTech
We regularly hold external hackathons on various topics. But this summer we decided to give employees the opportunity to prove themselves - because for sure they would like to solve the problems on the available data. What happened to colleagues in SberTech - says samorlov , chief development manager in the department for developing a laboratory cluster of super-arrays.

Participants were asked to develop solutions on Machine Learning that would help predict the timing of improvements and critical bugs. These solutions could increase the development efficiency at SberTech, including:
The best ideas of the participants are planned to be implemented in SberTech in the near future.
We perfectly understood that it is impossible to create an industrial solution for a limited time of a hackathon. No one had any illusions and it was clear that the decisions would be largely crude. But why come up with tasks from the air, if we have very specific tasks? As a result, we gave the guys a fan (and, of course, a monetary reward), and in return received some interesting ideas that can be taken into work.
Initial data
The task was solved on the basis of data from Jira internal and external working networks, as well as from the MCC (internal automated project management system). If the data sets from Jira were text fields with history and attachments, then the MCC kept more specific information used to plan changes.
Data sets were posted on a file share with access for participants. Since this is a hackathon, they were supposed to figure out how and what to work with. Like in real life :)
Iron
If we almost did not doubt the knowledge and skills of colleagues, then the power of desktop computers, to put it mildly, is not outrageous. Therefore, a small Hadoop cluster was also provided upon request. The cluster configuration (80 CPU, 200 GB, 1.5 TB) resembles a single-unit server with an emphasis on computing, but no, it's still a cluster deployed in Openstack.
Of course, this is a small stand. It is designed to work out the solutions and integrate our Data Lab and was a greatly reduced copy of the industrial one. But for the hackathon it was enough.
The Data Lab involved the JupyterHUB, which created separate instances of the JupyterNotebook. And in order to be able to work with parallel computing, with the help of Cloudera parcels, we added several kernel options to Jupyter with different sets of python libraries.
As a result, at the entrance we got independent work of N users with the ability to use the necessary versions of the libraries without disturbing anyone. In addition, parallel computing could be started without much headache (we know that there is a Data Science Workbench from Cloudera, and we are already trying to work with it, but at the time of the hackathon this tool was not yet available).
I place - auto-processing bugs
Purpose: Creating a pipeline for automatic processing of bugs in Sberbank-Technology projects.
The authors of the solution: Anna Rozhkova, Pavel Shvets and Mikhail Baranov (Moscow)
As the initial data, the team used the feedback from customers of the Sberbank Online mobile application from Google Play and AppStore, as well as information about bugs from Jira.

First, the participants solved the problem of breaking reviews into positive and negative using a tree-based classifier. Then, using negative reviews, we identified the main topics that caused user dissatisfaction. This is for example:
People who wrote that “everything is bad” fell into a separate category.
Using agglomerative hierarchical clustering, the team divided customer reviews (the advantage of this approach is the ability to add expert opinion, for example, when reviews about goals and contributions can be attributed to one cluster). For example, one of the selected clusters combined problems with logging in to the Asus Zenfone 2 device (the period between the appearance of the first reviews of the problem and the registration of the bug in Jira was 16 days).

The participants suggested minimizing the response time to user problems by doing online feedback processing with auto-creation of bugs for the selected clusters, using the advantage of the bank - a large number of caring customers (1,500 reviews per day). In the course of work, it was possible to achieve accuracy = 86% and precision = 88% when determining negative reviews.
Another team decision is to visualize processes in development. The case was analyzed using the example of Sberbank Online Android (ASBOL).

Participants calculated the number of transitions of bug statuses between team members and drew them in the form of a graph. With this tool it is easier to make management decisions and evenly distribute the load within the team. In addition, you can clearly see who is the key member of the team and where there are bottlenecks in the project. Based on this information, it is proposed to automatically assign bugs to specific team members, given their loading and the criticality of the bug.
In addition, participants tried to solve the problem of automatic prioritization of bugs using logistic regression and a naive Bayesian classifier. For this, the importance of the bug was determined by its description, the presence of investments and other characteristics. However, the model showed a result of accuracy = 54% for cross-validation on 3 folds - at the time of delivery of the work the prototype was not suitable for implementation.
According to the team members, the advantages of their models are simplicity, good interpretation of the result and quick work. This is a step towards real-time processing of user reviews using machine learning, which allows real-time interaction with users, identification and elimination of problems, increasing customer loyalty.
Team presentation
II place - optimization of production processes
Solution author: Anton Baranov (Moscow)
Tasks:
Anton worked with bugs from Jira. The data set included information on more than 67,000 bugs in the status of "completed" from 2011 to 2017. He led the search for solutions to the problems with the help of the Python language libraries and other ML-libraries.
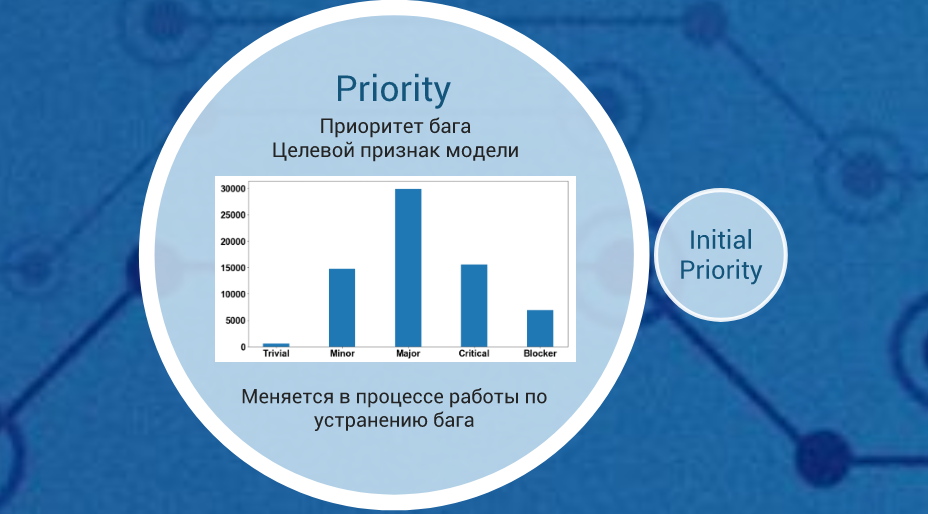
Anton analyzed and selected features that affect the final priority of the bug, and based on them built a model for predicting the final priority. In addition, after analyzing and searching for the features of various time series, he built forecast models for the number of bugs. The proposed solutions will be useful in testing.

In Agile, the result of predicting the number of defects by this model can be taken into account when planning work in future sprints. Anton’s decision will help to more accurately determine the time required to fix problems, which will affect the final performance.
Participant presentation
Solution author: Nikolay Zheltovsky (Innopolis)
Purpose: Creation of a forecasting system based on a neural network to minimize risks in managing IT projects.
From the set of source data proposed by the organizers, the participant chose to upload the list of tasks from Jira. A task is a separate task for developing a software component. Each task in the process of its life cycle undergoes various states: creation, development, various types of testing and coordination, closure. There can be several dozen such states.
Nikolai built and trained a neural network capable of predicting transitions of tasks to certain states and predicting the dates of these events, reporting possible critical events or deviations from planned values — important functions for the control process.

To train the neural network, Nikolai restored the sequence of intermediate states for each task from the event log. One of the intermediate states of the task was applied to the input of the neural network, and the final to the output; thus, the network was trained to predict events. Additionally, derived data was used for training - for example, a table with a temporary difference between all events in the past; the hypothesis was taken into account that tasks on which work is carried out on weekends can be problematic.

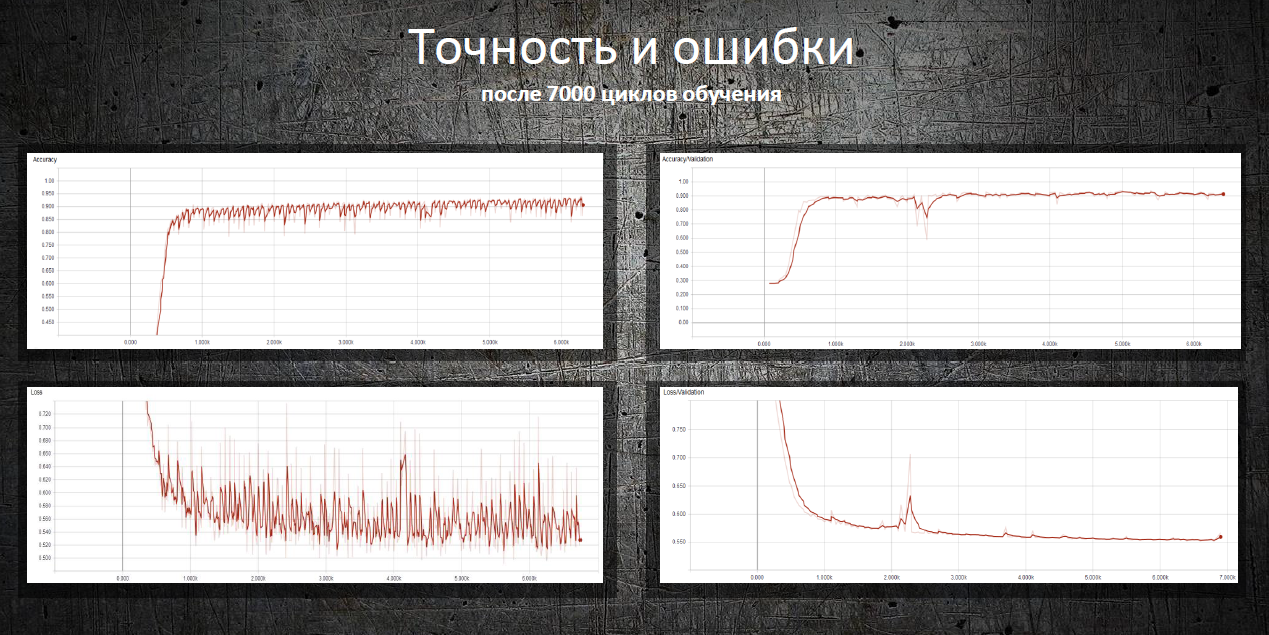
The neural network predicts some critical events with an accuracy of 91-94%. For example, reopening a task. The task closing date is predicted with a deviation from 0 to 37 days immediately after its creation. At later stages, when any work on the task is carried out, the maximum deviation is no more than a week.
Participant presentation
Participants were asked to develop solutions on Machine Learning that would help predict the timing of improvements and critical bugs. These solutions could increase the development efficiency at SberTech, including:
- it is better to plan the loading of commands during corrections at different stages of development;
- to form the release structure in terms of hot fix;
- plan work in sprints - define story points reserved for fixing problems;
- generally reduce the number of bugs in the program code;
- reduce time to market for products;
- increase predictability of decisions and testing effectiveness.
The best ideas of the participants are planned to be implemented in SberTech in the near future.
We perfectly understood that it is impossible to create an industrial solution for a limited time of a hackathon. No one had any illusions and it was clear that the decisions would be largely crude. But why come up with tasks from the air, if we have very specific tasks? As a result, we gave the guys a fan (and, of course, a monetary reward), and in return received some interesting ideas that can be taken into work.
Initial data
The task was solved on the basis of data from Jira internal and external working networks, as well as from the MCC (internal automated project management system). If the data sets from Jira were text fields with history and attachments, then the MCC kept more specific information used to plan changes.
Data sets were posted on a file share with access for participants. Since this is a hackathon, they were supposed to figure out how and what to work with. Like in real life :)
Iron
If we almost did not doubt the knowledge and skills of colleagues, then the power of desktop computers, to put it mildly, is not outrageous. Therefore, a small Hadoop cluster was also provided upon request. The cluster configuration (80 CPU, 200 GB, 1.5 TB) resembles a single-unit server with an emphasis on computing, but no, it's still a cluster deployed in Openstack.
Of course, this is a small stand. It is designed to work out the solutions and integrate our Data Lab and was a greatly reduced copy of the industrial one. But for the hackathon it was enough.
The Data Lab involved the JupyterHUB, which created separate instances of the JupyterNotebook. And in order to be able to work with parallel computing, with the help of Cloudera parcels, we added several kernel options to Jupyter with different sets of python libraries.
As a result, at the entrance we got independent work of N users with the ability to use the necessary versions of the libraries without disturbing anyone. In addition, parallel computing could be started without much headache (we know that there is a Data Science Workbench from Cloudera, and we are already trying to work with it, but at the time of the hackathon this tool was not yet available).
I place - auto-processing bugs
Purpose: Creating a pipeline for automatic processing of bugs in Sberbank-Technology projects.
The authors of the solution: Anna Rozhkova, Pavel Shvets and Mikhail Baranov (Moscow)
As the initial data, the team used the feedback from customers of the Sberbank Online mobile application from Google Play and AppStore, as well as information about bugs from Jira.
First, the participants solved the problem of breaking reviews into positive and negative using a tree-based classifier. Then, using negative reviews, we identified the main topics that caused user dissatisfaction. This is for example:
- updates
- antivirus (root, firmware)
- SMS and payments
People who wrote that “everything is bad” fell into a separate category.
Using agglomerative hierarchical clustering, the team divided customer reviews (the advantage of this approach is the ability to add expert opinion, for example, when reviews about goals and contributions can be attributed to one cluster). For example, one of the selected clusters combined problems with logging in to the Asus Zenfone 2 device (the period between the appearance of the first reviews of the problem and the registration of the bug in Jira was 16 days).
The participants suggested minimizing the response time to user problems by doing online feedback processing with auto-creation of bugs for the selected clusters, using the advantage of the bank - a large number of caring customers (1,500 reviews per day). In the course of work, it was possible to achieve accuracy = 86% and precision = 88% when determining negative reviews.
Another team decision is to visualize processes in development. The case was analyzed using the example of Sberbank Online Android (ASBOL).
Participants calculated the number of transitions of bug statuses between team members and drew them in the form of a graph. With this tool it is easier to make management decisions and evenly distribute the load within the team. In addition, you can clearly see who is the key member of the team and where there are bottlenecks in the project. Based on this information, it is proposed to automatically assign bugs to specific team members, given their loading and the criticality of the bug.
In addition, participants tried to solve the problem of automatic prioritization of bugs using logistic regression and a naive Bayesian classifier. For this, the importance of the bug was determined by its description, the presence of investments and other characteristics. However, the model showed a result of accuracy = 54% for cross-validation on 3 folds - at the time of delivery of the work the prototype was not suitable for implementation.
According to the team members, the advantages of their models are simplicity, good interpretation of the result and quick work. This is a step towards real-time processing of user reviews using machine learning, which allows real-time interaction with users, identification and elimination of problems, increasing customer loyalty.
Team presentation
II place - optimization of production processes
Solution author: Anton Baranov (Moscow)
Tasks:
- Predict the final priority of a bug using information about it. For example: description, discovery phase, project, etc.
- Based on data on the distribution of bugs in time, predict the number of bugs of a certain type, system, stage, etc., in the forecast period.
Anton worked with bugs from Jira. The data set included information on more than 67,000 bugs in the status of "completed" from 2011 to 2017. He led the search for solutions to the problems with the help of the Python language libraries and other ML-libraries.
Anton analyzed and selected features that affect the final priority of the bug, and based on them built a model for predicting the final priority. In addition, after analyzing and searching for the features of various time series, he built forecast models for the number of bugs. The proposed solutions will be useful in testing.
In Agile, the result of predicting the number of defects by this model can be taken into account when planning work in future sprints. Anton’s decision will help to more accurately determine the time required to fix problems, which will affect the final performance.
Participant presentation
III place: risk forecasting
Solution author: Nikolay Zheltovsky (Innopolis)
Purpose: Creation of a forecasting system based on a neural network to minimize risks in managing IT projects.
From the set of source data proposed by the organizers, the participant chose to upload the list of tasks from Jira. A task is a separate task for developing a software component. Each task in the process of its life cycle undergoes various states: creation, development, various types of testing and coordination, closure. There can be several dozen such states.
Nikolai built and trained a neural network capable of predicting transitions of tasks to certain states and predicting the dates of these events, reporting possible critical events or deviations from planned values — important functions for the control process.
To train the neural network, Nikolai restored the sequence of intermediate states for each task from the event log. One of the intermediate states of the task was applied to the input of the neural network, and the final to the output; thus, the network was trained to predict events. Additionally, derived data was used for training - for example, a table with a temporary difference between all events in the past; the hypothesis was taken into account that tasks on which work is carried out on weekends can be problematic.
The neural network predicts some critical events with an accuracy of 91-94%. For example, reopening a task. The task closing date is predicted with a deviation from 0 to 37 days immediately after its creation. At later stages, when any work on the task is carried out, the maximum deviation is no more than a week.
Participant presentation