Description of sorting algorithms and comparison of their performance
Introduction
Many articles have already been written on this subject. However, I have not yet seen an article comparing all the main sorts on a large number of tests of different types and sizes. In addition, implementations and a description of the test suite are far from everywhere. This leads to the fact that there may be doubts about the correctness of the study. However, the purpose of my work is not only to determine which sortings work the fastest (in general, this is already known). First of all, I was interested in exploring algorithms, optimizing them so that they work as quickly as possible. Working on this, I managed to come up with an effective formula for sorting Shell.
In many ways, the article is devoted to how to write all the algorithms and test them. If we talk about programming itself, then sometimes completely unexpected difficulties can arise (largely thanks to the C ++ optimizer). However, it is equally difficult to decide which tests and in what quantities need to be done. The codes of all the algorithms that are laid out in this article are written by me. Available and run results on all tests. The only thing I can’t show is the tests themselves, since they weigh almost 140 GB. At the slightest suspicion, I checked both the code corresponding to the test and the test itself. I hope you enjoy the article.
Description of the main sortings and their implementation
I will try to briefly and clearly describe the sortings and indicate the asymptotics, although the latter is not very important in the framework of this article (it is interesting to know the real time of work). I will not write anything about memory consumption in the future, I only note that sortings using complex data structures (such as sorting by a tree) usually consume it in large quantities, and other sortings in the worst case only create an auxiliary array. There is also the concept of stability (stability) sorting. This means that the relative order of the elements does not change when they are equal. It is also unimportant in the framework of this article (in the end, you can simply attach its index to an element), but it will come in handy in one place.
Bubble sort
We will go through the array from left to right. If the current item is larger than the next, swap them. We do this until the array is sorted. Note that after the first iteration, the largest element will be at the end of the array, in the right place. After two iterations, the two largest elements will be in the right place, and so on. Obviously, after no more than n iterations, the array will be sorted. Thus, the asymptotic behavior in the worst and middle case is O (n 2 ), in the best case - O (n).
Implementation:
void bubblesort(int* l, int* r) {
int sz = r - l;
if (sz <= 1) return;
bool b = true;
while (b) {
b = false;
for (int* i = l; i + 1 < r; i++) {
if (*i > *(i + 1)) {
swap(*i, *(i + 1));
b = true;
}
}
r--;
}
}Shaker sort
(also known as stirring sorting and cocktail sorting). Note that bubble sorting works slowly on tests in which small elements are at the end (they are also called “turtles”). Such an element at each step of the algorithm will shift only one position to the left. Therefore, we will go not only from left to right, but also from right to left. We will support two pointers begin and end, indicating which segment of the array has not yet been sorted. At the next iteration, when reaching end, subtract one from it and move from right to left, similarly, when reaching begin, add one and move from left to right. The asymptotic behavior of the algorithm is the same as that of bubble sorting, but the real time is better.
Implementation:
void shakersort(int* l, int* r) {
int sz = r - l;
if (sz <= 1) return;
bool b = true;
int* beg = l - 1;
int* end = r - 1;
while (b) {
b = false;
beg++;
for (int* i = beg; i < end; i++) {
if (*i > *(i + 1)) {
swap(*i, *(i + 1));
b = true;
}
}
if (!b) break;
end--;
for (int* i = end; i > beg; i--) {
if (*i < *(i - 1)) {
swap(*i, *(i - 1));
b = true;
}
}
}
}Comb sort
Another modification of bubble sort. In order to get rid of the "turtles", we will rearrange the elements standing at a distance. We fix it and we will go from left to right, comparing the elements standing at this distance, rearranging them, if necessary. Obviously, this will allow the “turtles” to quickly get to the beginning of the array. It is optimal to initially take the distance equal to the length of the array, and then divide it by a factor equal to approximately 1.247. When the distance becomes equal to one, the bubble is sorted. In the best case, the asymptotics is O (nlogn), in the worst - O (n 2 ). What asymptotics on average is not very clear to me, in practice it looks like O (nlogn).
Implementation:
void combsort(int* l, int* r) {
int sz = r - l;
if (sz <= 1) return;
double k = 1.2473309;
int step = sz - 1;
while (step > 1) {
for (int* i = l; i + step < r; i++) {
if (*i > *(i + step))
swap(*i, *(i + step));
}
step /= k;
}
bool b = true;
while (b) {
b = false;
for (int* i = l; i + 1 < r; i++) {
if (*i > *(i + 1)) {
swap(*i, *(i + 1));
b = true;
}
}
}
}You can also read about these sorts (bubble, shaker, and comb) here .
Insertion sort
Let's create an array in which, after the completion of the algorithm, the answer will lie. We will insert elements from the original array one by one so that the elements in the response array are always sorted. Asymptotic behavior in the average and worst case is O (n 2 ), at best - O (n). It is more convenient to implement the algorithm in a different way (creating a new array and actually inserting something into it is relatively difficult): just make sure that some prefix of the original array is sorted, instead of inserting, we will change the current element with the previous one while they are in the wrong order.
Implementation:
void insertionsort(int* l, int* r) {
for (int *i = l + 1; i < r; i++) {
int* j = i;
while (j > l && *(j - 1) > *j) {
swap(*(j - 1), *j);
j--;
}
}
}Shell Sort
We use the same idea as sorting with a comb, and apply to sorting by inserts. We fix some distance. Then the elements of the array will be divided into classes - the elements whose distance between them is a multiple of a fixed distance fall into one class. Sort by sorting inserts each class. Unlike sorting with a comb, the optimal set of distances is unknown. There are quite a few sequences with different ratings. Shell sequence - the first element is equal to the length of the array, each succeeding half the previous one. The asymptotic behavior in the worst case is O (n 2 ). Hibbard sequence - 2 n - 1, asymptotics in the worst case - O (n 1,5 ), Sedgwick sequence (the formula is nontrivial, you can see it at the link below) - O (n4/3 ), Pratta (all products of degrees two and three) - O (nlog 2 n). I note that all these sequences need to be calculated only to the size of the array and run from the larger to the smaller (otherwise it will turn out just sorting by inserts). I also conducted additional research and tested different sequences of the form s i = a * s i - 1 + k * s i - 1 (this was partially inspired by the empirical Tsiur sequence - one of the best distance sequences for a small number of elements). The sequences with coefficients a = 3, k = 1/3 turned out to be the best; a = 4, k = 1/4 and a = 4, k = -1/5.
Some useful links:
Shell Sort on the Russian-language Wikipedia
Sorting Shell in English Wikipedia
Habr article
Implementations:
void shellsort(int* l, int* r) {
int sz = r - l;
int step = sz / 2;
while (step >= 1) {
for (int *i = l + step; i < r; i++) {
int *j = i;
int *diff = j - step;
while (diff >= l && *diff > *j) {
swap(*diff, *j);
j = diff;
diff = j - step;
}
}
step /= 2;
}
}
void shellsorthib(int* l, int* r) {
int sz = r - l;
if (sz <= 1) return;
int step = 1;
while (step < sz) step <<= 1;
step >>= 1;
step--;
while (step >= 1) {
for (int *i = l + step; i < r; i++) {
int *j = i;
int *diff = j - step;
while (diff >= l && *diff > *j) {
swap(*diff, *j);
j = diff;
diff = j - step;
}
}
step /= 2;
}
}
int steps[100];
void shellsortsedgwick(int* l, int* r) {
int sz = r - l;
steps[0] = 1;
int q = 1;
while (steps[q - 1] * 3 < sz) {
if (q % 2 == 0)
steps[q] = 9 * (1 << q) - 9 * (1 << (q / 2)) + 1;
else
steps[q] = 8 * (1 << q) - 6 * (1 << ((q + 1) / 2)) + 1;
q++;
}
q--;
for (; q >= 0; q--) {
int step = steps[q];
for (int *i = l + step; i < r; i++) {
int *j = i;
int *diff = j - step;
while (diff >= l && *diff > *j) {
swap(*diff, *j);
j = diff;
diff = j - step;
}
}
}
}
void shellsortpratt(int* l, int* r) {
int sz = r - l;
steps[0] = 1;
int cur = 1, q = 1;
for (int i = 1; i < sz; i++) {
int cur = 1 << i;
if (cur > sz / 2) break;
for (int j = 1; j < sz; j++) {
cur *= 3;
if (cur > sz / 2) break;
steps[q++] = cur;
}
}
insertionsort(steps, steps + q);
q--;
for (; q >= 0; q--) {
int step = steps[q];
for (int *i = l + step; i < r; i++) {
int *j = i;
int *diff = j - step;
while (diff >= l && *diff > *j) {
swap(*diff, *j);
j = diff;
diff = j - step;
}
}
}
}
void myshell1(int* l, int* r) {
int sz = r - l, q = 1;
steps[0] = 1;
while (steps[q - 1] < sz) {
int s = steps[q - 1];
steps[q++] = s * 4 + s / 4;
}
q--;
for (; q >= 0; q--) {
int step = steps[q];
for (int *i = l + step; i < r; i++) {
int *j = i;
int *diff = j - step;
while (diff >= l && *diff > *j) {
swap(*diff, *j);
j = diff;
diff = j - step;
}
}
}
}
void myshell2(int* l, int* r) {
int sz = r - l, q = 1;
steps[0] = 1;
while (steps[q - 1] < sz) {
int s = steps[q - 1];
steps[q++] = s * 3 + s / 3;
}
q--;
for (; q >= 0; q--) {
int step = steps[q];
for (int *i = l + step; i < r; i++) {
int *j = i;
int *diff = j - step;
while (diff >= l && *diff > *j) {
swap(*diff, *j);
j = diff;
diff = j - step;
}
}
}
}
void myshell3(int* l, int* r) {
int sz = r - l, q = 1;
steps[0] = 1;
while (steps[q - 1] < sz) {
int s = steps[q - 1];
steps[q++] = s * 4 - s / 5;
}
q--;
for (; q >= 0; q--) {
int step = steps[q];
for (int *i = l + step; i < r; i++) {
int *j = i;
int *diff = j - step;
while (diff >= l && *diff > *j) {
swap(*diff, *j);
j = diff;
diff = j - step;
}
}
}
}Tree sort
We will insert elements into the binary search tree. After all the elements are inserted, it is enough to go around the tree in depth and get a sorted array. If you use a balanced tree, such as red-black, the asymptotics will be O (nlogn) in the worst, medium and best case. The implementation used a multiset container.
Here you can read about search trees:
Wikipedia
An article on the Habré
And another article on the Habré
Implementation:
void treesort(int* l, int* r) {
multiset m;
for (int *i = l; i < r; i++)
m.insert(*i);
for (int q : m)
*l = q, l++;
} Gnome sort
The algorithm is similar to sorting by inserts. We support the pointer to the current element, if it is larger than the previous one or it is the first - we shift the pointer to the position to the right, otherwise we will change the current and previous elements in places and shift to the left.
Implementation:
void gnomesort(int* l, int* r) {
int *i = l;
while (i < r) {
if (i == l || *(i - 1) <= *i) i++;
else swap(*(i - 1), *i), i--;
}
}Selection sort
At the next iteration, we will find the minimum in the array after the current element and change it with it, if necessary. Thus, after the i-th iteration, the first i elements will stand in their places. Asymptotics: O (n 2 ) in the best, average and worst case. It should be noted that this sorting can be implemented in two ways - by keeping the minimum and its index, or simply rearranging the current element with the one in question, if they are in the wrong order. The first method turned out to be a little faster, which is why it is implemented.
Implementation:
void selectionsort(int* l, int* r) {
for (int *i = l; i < r; i++) {
int minz = *i, *ind = i;
for (int *j = i + 1; j < r; j++) {
if (*j < minz) minz = *j, ind = j;
}
swap(*i, *ind);
}
}Pyramidal Sort / Heapsort
Development of the idea of sorting by choice. We will use the “heap” data structure (or “pyramid”, whence the name of the algorithm). It allows you to get a minimum for O (1), adding elements and extracting a minimum for O (logn). Thus, the asymptotic behavior of O (nlogn) is in the worst, middle and best case. I implemented the heap myself, although in C ++ there is a container priority_queue, since this container is rather slow.
You can read about the bunch here:
Wikipedia, the
article on Habré
Implementation:
template
class heap {
public:
int size() {
return n;
}
int top() {
return h[0];
}
bool empty() {
return n == 0;
}
void push(T a) {
h.push_back(a);
SiftUp(n);
n++;
}
void pop() {
n--;
swap(h[n], h[0]);
h.pop_back();
SiftDown(0);
}
void clear() {
h.clear();
n = 0;
}
T operator [] (int a) {
return h[a];
}
private:
vector h;
int n = 0;
void SiftUp(int a) {
while (a) {
int p = (a - 1) / 2;
if (h[p] > h[a]) swap(h[p], h[a]);
else break;
a--; a /= 2;
}
}
void SiftDown(int a) {
while (2 * a + 1 < n) {
int l = 2 * a + 1, r = 2 * a + 2;
if (r == n) {
if (h[l] < h[a]) swap(h[l], h[a]);
break;
}
else if (h[l] <= h[r]) {
if (h[l] < h[a]) {
swap(h[l], h[a]);
a = l;
}
else break;
}
else if (h[r] < h[a]) {
swap(h[r], h[a]);
a = r;
}
else break;
}
}
};
void heapsort(int* l, int* r) {
heap h;
for (int *i = l; i < r; i++) h.push(*i);
for (int *i = l; i < r; i++) {
*i = h.top();
h.pop();
}
} Quicksort / Quicksort
Choose some support element. After that, throw all the elements smaller than it to the left, and the large ones to the right. We recursively call from each of the parts. As a result, we get a sorted array, since each element less than the reference stood before each larger reference. Asymptotics: O (nlogn) in the average and best case, O (n 2) The worst score is achieved if the support element is not selected correctly. My implementation of this algorithm is completely standard, we go both left and right at the same time, find a pair of elements such that the left element is larger than the reference one and the right one is smaller, and we swap them. In addition to pure quick sorting, sorting was also involved in the comparison, which, with a small number of elements, switches to sorting by inserts. The constant is selected by testing, and sorting by inserts is the best sorting suitable for this task (although you should not think that it is the fastest of the quadratic ones because of this).
Implementation:
void quicksort(int* l, int* r) {
if (r - l <= 1) return;
int z = *(l + (r - l) / 2);
int* ll = l, *rr = r - 1;
while (ll <= rr) {
while (*ll < z) ll++;
while (*rr > z) rr--;
if (ll <= rr) {
swap(*ll, *rr);
ll++;
rr--;
}
}
if (l < rr) quicksort(l, rr + 1);
if (ll < r) quicksort(ll, r);
}
void quickinssort(int* l, int* r) {
if (r - l <= 32) {
insertionsort(l, r);
return;
}
int z = *(l + (r - l) / 2);
int* ll = l, *rr = r - 1;
while (ll <= rr) {
while (*ll < z) ll++;
while (*rr > z) rr--;
if (ll <= rr) {
swap(*ll, *rr);
ll++;
rr--;
}
}
if (l < rr) quickinssort(l, rr + 1);
if (ll < r) quickinssort(ll, r);
}Merge sort
Sort based on the divide and conquer paradigm. We divide the array in half, recursively sort the parts, and then perform the merge procedure: we support two pointers, one to the current element of the first part, the second to the current element of the second part. From these two elements, select the minimum, insert into the answer and move the pointer corresponding to the minimum. Merging works for O (n), the levels of all logn, therefore the asymptotic behavior of O (nlogn). It is efficient to pre-create a temporary array and pass it as an argument to the function. This sorting is recursive, as well as fast, and therefore the transition to quadratic with a small number of elements is possible.
Implementation:
void merge(int* l, int* m, int* r, int* temp) {
int *cl = l, *cr = m, cur = 0;
while (cl < m && cr < r) {
if (*cl < *cr) temp[cur++] = *cl, cl++;
else temp[cur++] = *cr, cr++;
}
while (cl < m) temp[cur++] = *cl, cl++;
while (cr < r) temp[cur++] = *cr, cr++;
cur = 0;
for (int* i = l; i < r; i++)
*i = temp[cur++];
}
void _mergesort(int* l, int* r, int* temp) {
if (r - l <= 1) return;
int *m = l + (r - l) / 2;
_mergesort(l, m, temp);
_mergesort(m, r, temp);
merge(l, m, r, temp);
}
void mergesort(int* l, int* r) {
int* temp = new int[r - l];
_mergesort(l, r, temp);
delete temp;
}
void _mergeinssort(int* l, int* r, int* temp) {
if (r - l <= 32) {
insertionsort(l, r);
return;
}
int *m = l + (r - l) / 2;
_mergeinssort(l, m, temp);
_mergeinssort(m, r, temp);
merge(l, m, r, temp);
}
void mergeinssort(int* l, int* r) {
int* temp = new int[r - l];
_mergeinssort(l, r, temp);
delete temp;
}Counting sort
Create an array of size r - l, where l is the minimum and r is the maximum element of the array. After that, we will go through the array and count the number of occurrences of each element. Now you can go through the array of values and write out each number as many times as needed. Asymptotics - O (n + r - l). You can modify this algorithm to become stable: for this, we determine the place where the next number should stand (these are just prefix sums in the array of values) and we will go through the original array from left to right, putting the element in the right place and increasing the position by 1. This sorting was not tested, since most tests contained sufficiently large numbers that did not allow creating an array of the required size. However, it nevertheless came in handy.
Bucket sort
(also known as basket and pocket sorting). Let l be the minimum and r the maximum element of the array. We divide the elements into blocks, in the first there will be elements from l to l + k, in the second - from l + k to l + 2k, etc., where k = (r - l) / number of blocks. In general, if the number of blocks is two, then this algorithm turns into a kind of quick sort. The asymptotic behavior of this algorithm is unclear; the runtime depends on both the input data and the number of blocks. It is argued that on successful data, the runtime is linear. The implementation of this algorithm turned out to be one of the most difficult tasks. You can do it this way: just create new arrays, sort them and glue them recursively. However, this approach is still quite slow and did not suit me. Effective implementation uses several ideas:
1) We will not create new arrays. To do this, we use the counting sorting technique - we count the number of elements in each block, the prefix amounts, and thus the position of each element in the array.
2) We will not start from empty blocks. We put the indices of non-empty blocks in a separate array and start only from them.
3) Check if the array is sorted. This will not worsen the operating time, since you still need to make a pass in order to find the minimum and maximum, however, it will allow the algorithm to accelerate on partially sorted data, because the elements are inserted into new blocks in the same order as in the original array.
4) Since the algorithm turned out to be rather cumbersome, with a small number of elements it is extremely inefficient. To such an extent that switching to sorting by inserts speeds up work by about 10 times.
It remains only to understand how many blocks need to be selected. On randomized tests, I managed to get the following score: 1500 blocks for 10 7 elements and 3000 for 10 8 . It was not possible to select a formula - the operating time deteriorated several times.
Implementation:
void _newbucketsort(int* l, int* r, int* temp) {
if (r - l <= 64) {
insertionsort(l, r);
return;
}
int minz = *l, maxz = *l;
bool is_sorted = true;
for (int *i = l + 1; i < r; i++) {
minz = min(minz, *i);
maxz = max(maxz, *i);
if (*i < *(i - 1)) is_sorted = false;
}
if (is_sorted) return;
int diff = maxz - minz + 1;
int numbuckets;
if (r - l <= 1e7) numbuckets = 1500;
else numbuckets = 3000;
int range = (diff + numbuckets - 1) / numbuckets;
int* cnt = new int[numbuckets + 1];
for (int i = 0; i <= numbuckets; i++)
cnt[i] = 0;
int cur = 0;
for (int* i = l; i < r; i++) {
temp[cur++] = *i;
int ind = (*i - minz) / range;
cnt[ind + 1]++;
}
int sz = 0;
for (int i = 1; i <= numbuckets; i++)
if (cnt[i]) sz++;
int* run = new int[sz];
cur = 0;
for (int i = 1; i <= numbuckets; i++)
if (cnt[i]) run[cur++] = i - 1;
for (int i = 1; i <= numbuckets; i++)
cnt[i] += cnt[i - 1];
cur = 0;
for (int *i = l; i < r; i++) {
int ind = (temp[cur] - minz) / range;
*(l + cnt[ind]) = temp[cur];
cur++;
cnt[ind]++;
}
for (int i = 0; i < sz; i++) {
int r = run[i];
if (r != 0) _newbucketsort(l + cnt[r - 1], l + cnt[r], temp);
else _newbucketsort(l, l + cnt[r], temp);
}
delete run;
delete cnt;
}
void newbucketsort(int* l, int* r) {
int *temp = new int[r - l];
_newbucketsort(l, r, temp);
delete temp;
}Bitwise Sort / Radix sort
(also known as digital sorting). There are two versions of this sorting, in which, in my opinion, there is little in common, besides the idea of using the representation of a number in some number system (for example, binary).
LSD (least significant digit):
We represent each number in binary form. At each step of the algorithm, we will sort the numbers so that they are sorted by the first k * i bits, where k is some constant. From this definition it follows that at each step it is rather stable to sort the elements by the new k bits. For this, sorting by counting is ideal (2 k of memory and time are needed , which is a little with a successful choice of a constant). Asymptotics: O (n), if we assume that the numbers are of a fixed size (otherwise, it would be impossible to assume that the comparison of two numbers is performed per unit time). The implementation is pretty simple.
Implementation:
int digit(int n, int k, int N, int M) {
return (n >> (N * k) & (M - 1));
}
void _radixsort(int* l, int* r, int N) {
int k = (32 + N - 1) / N;
int M = 1 << N;
int sz = r - l;
int* b = new int[sz];
int* c = new int[M];
for (int i = 0; i < k; i++) {
for (int j = 0; j < M; j++)
c[j] = 0;
for (int* j = l; j < r; j++)
c[digit(*j, i, N, M)]++;
for (int j = 1; j < M; j++)
c[j] += c[j - 1];
for (int* j = r - 1; j >= l; j--)
b[--c[digit(*j, i, N, M)]] = *j;
int cur = 0;
for (int* j = l; j < r; j++)
*j = b[cur++];
}
delete b;
delete c;
}
void radixsort(int* l, int* r) {
_radixsort(l, r, 8);
}MSD (most significant digit):
In fact, some kind of block sorting. Numbers with equal k bits will fall into one block. The asymptotic behavior is the same as that of the LSD version. The implementation is very similar to block sorting, but simpler. It uses the digit function defined in the implementation of the LSD version.
Implementation:
void _radixsortmsd(int* l, int* r, int N, int d, int* temp) {
if (d == -1) return;
if (r - l <= 32) {
insertionsort(l, r);
return;
}
int M = 1 << N;
int* cnt = new int[M + 1];
for (int i = 0; i <= M; i++)
cnt[i] = 0;
int cur = 0;
for (int* i = l; i < r; i++) {
temp[cur++] = *i;
cnt[digit(*i, d, N, M) + 1]++;
}
int sz = 0;
for (int i = 1; i <= M; i++)
if (cnt[i]) sz++;
int* run = new int[sz];
cur = 0;
for (int i = 1; i <= M; i++)
if (cnt[i]) run[cur++] = i - 1;
for (int i = 1; i <= M; i++)
cnt[i] += cnt[i - 1];
cur = 0;
for (int *i = l; i < r; i++) {
int ind = digit(temp[cur], d, N, M);
*(l + cnt[ind]) = temp[cur];
cur++;
cnt[ind]++;
}
for (int i = 0; i < sz; i++) {
int r = run[i];
if (r != 0) _radixsortmsd(l + cnt[r - 1], l + cnt[r], N, d - 1, temp);
else _radixsortmsd(l, l + cnt[r], N, d - 1, temp);
}
delete run;
delete cnt;
}
void radixsortmsd(int* l, int* r) {
int* temp = new int[r - l];
_radixsortmsd(l, r, 8, 3, temp);
delete temp;
}Bitonic sort:
The idea of this algorithm is that the original array is converted into a bit sequence - a sequence that first increases and then decreases. It can be effectively sorted as follows: we divide the array into two parts, create two arrays, in the first we add all the elements equal to the minimum of the corresponding elements of each of the two parts, and in the second - equal to the maximum. It is argued that two biton sequences will be obtained, each of which can be recursively sorted in the same way, after which two arrays can be glued (since any element of the first is less than or equal to any element of the second). In order to convert the original array into a bit sequence, we will do the following: if the array consists of two elements, you can simply end, otherwise divide the array in half, recursively call the algorithm from the halves, after which we sort the first part in order, the second in reverse order and glue it. Obviously, we get a bitone sequence. Asymptotic: O (nlog2 n), because when constructing the bit sequence, we used the sorting working for O (nlogn), and the total level was logn. Also note that the size of the array must be equal to the power of two, so you may have to supplement it with dummy elements (which does not affect the asymptotic behavior).
Implementation:
void bitseqsort(int* l, int* r, bool inv) {
if (r - l <= 1) return;
int *m = l + (r - l) / 2;
for (int *i = l, *j = m; i < m && j < r; i++, j++) {
if (inv ^ (*i > *j)) swap(*i, *j);
}
bitseqsort(l, m, inv);
bitseqsort(m, r, inv);
}
void makebitonic(int* l, int* r) {
if (r - l <= 1) return;
int *m = l + (r - l) / 2;
makebitonic(l, m);
bitseqsort(l, m, 0);
makebitonic(m, r);
bitseqsort(m, r, 1);
}
void bitonicsort(int* l, int* r) {
int n = 1;
int inf = *max_element(l, r) + 1;
while (n < r - l) n *= 2;
int* a = new int[n];
int cur = 0;
for (int *i = l; i < r; i++)
a[cur++] = *i;
while (cur < n) a[cur++] = inf;
makebitonic(a, a + n);
bitseqsort(a, a + n, 0);
cur = 0;
for (int *i = l; i < r; i++)
*i = a[cur++];
delete a;
}Timsort
Hybrid sorting combining insertion sorting and merge sorting. We divide the elements of the array into several subarrays of small size, and we will expand the subarray while the elements in it are sorted. Sort subarrays by sorting inserts, taking advantage of the fact that it works effectively on sorted arrays. Next, we will merge the subarrays as in sorting by merging, taking them of approximately equal size (otherwise, the operating time will approach quadratic). For this, it is convenient to store subarrays on the stack, maintaining the invariant - the farther from the top, the larger the size, and merge subarrays at the top only when the size of the third remoteness from the top of the subarray is larger or equal to the sum of their sizes. Asymptotics: O (n) at best and O (nlogn) at average and worst. The implementation is nontrivial
More timsort described here:
Here
Here
Implementation:
void _timsort(int* l, int* r, int* temp) {
int sz = r - l;
if (sz <= 64) {
insertionsort(l, r);
return;
}
int minrun = sz, f = 0;
while (minrun >= 64) {
f |= minrun & 1;
minrun >>= 1;
}
minrun += f;
int* cur = l;
stack> s;
while (cur < r) {
int* c1 = cur;
while (c1 < r - 1 && *c1 <= *(c1 + 1)) c1++;
int* c2 = cur;
while (c2 < r - 1 && *c2 >= *(c2 + 1)) c2++;
if (c1 >= c2) {
c1 = max(c1, cur + minrun - 1);
c1 = min(c1, r - 1);
insertionsort(cur, c1 + 1);
s.push({ c1 - cur + 1, cur });
cur = c1 + 1;
}
else {
c2 = max(c2, cur + minrun - 1);
c2 = min(c2, r - 1);
reverse(cur, c2 + 1);
insertionsort(cur, c2 + 1);
s.push({ c2 - cur + 1, cur });
cur = c2 + 1;
}
while (s.size() >= 3) {
pair x = s.top();
s.pop();
pair y = s.top();
s.pop();
pair z = s.top();
s.pop();
if (z.first >= x.first + y.first && y.first >= x.first) {
s.push(z);
s.push(y);
s.push(x);
break;
}
else if (z.first >= x.first + y.first) {
merge(y.second, x.second, x.second + x.first, temp);
s.push(z);
s.push({ x.first + y.first, y.second });
}
else {
merge(z.second, y.second, y.second + y.first, temp);
s.push({ z.first + y.first, z.second });
s.push(x);
}
}
}
while (s.size() != 1) {
pair x = s.top();
s.pop();
pair y = s.top();
s.pop();
if (x.second < y.second) swap(x, y);
merge(y.second, x.second, x.second + x.first, temp);
s.push({ y.first + x.first, y.second });
}
}
void timsort(int* l, int* r) {
int* temp = new int[r - l];
_timsort(l, r, temp);
delete temp;
} Testing
Iron and system
Processor: Intel Core i7-3770 CPU 3.40 GHz
RAM: 8 GB
Testing was carried out on an almost clean Windows 10 x64 system installed a few days before launch. Used IDE - Microsoft Visual Studio 2015.
Tests
All tests are divided into four groups. The first group is an array of random numbers for different modules (10, 1000, 10 5 , 10 7 and 10 9 ). The second group is an array that is divided into several sorted subarrays. In fact, we took an array of random numbers modulo 10 9, and then subarrays of size equal to the minimum of the length of the remaining suffix and a random number modulo some constant were sorted. The sequence of constants is 10, 100, 1000, etc. down to the size of the array. The third group is an initially sorted array of random numbers with a certain number of “swaps” - permutations of two random elements. The sequence of swap amounts is the same as in the previous group. Finally, the last group consists of several tests with a fully sorted array (in direct and reverse order), several tests with the original array of natural numbers from 1 to n, in which several numbers are replaced by random, and tests with a large number of repetitions of one element (10 %, 25%, 50%, 75% and 90%). Thus, the tests allow you to see how sorts work on random and partially sorted arrays, which seems most significant. The fourth group is largely opposed to linear-time sortings that like sequences of random numbers. At the end of the article there is a link to a file in which all tests are described in detail.
Input size
It would be rather stupid to compare, for example, sorting with linear run time and quadratic, and run them on tests of the same size. Therefore, each of the test groups is divided into four groups, the sizes of 10 5 , 10 6 , 10 7 and 10 8 elements. Sortings were divided into three groups, in the first - quadratic (sorting by bubble, inserts, choice, shaker and gnomes), in the second - a cross between logarithmic time and square (bitonic, several types of Shell sorting and sorting by tree), in the third all rest. It might surprise someone that tree sorting did not fall into the third group, although its asymptotic behavior is O (nlogn), but, unfortunately, its constant is very large. Sorts of the first group were tested on tests with 105 elements, the second group - on tests with 10 6 and 10 7 , the third - on tests with 10 7 and 10 8 . It is these sizes of data that allow us to somehow see the increase in operating time, with smaller sizes the error is too large, with large sizes the algorithm works for too long (or lack of RAM). With the first group, I did not bother, so as not to disturb the tenfold increase (10 4 elements for quadratic sortings are too few), in the end, they themselves are of little interest.
How was the testing
On each test, 20 launches were carried out, the total operating time was the average of the resulting values. Almost all the results were obtained after one run of the program, however, due to several errors in the code and system glitches (testing nevertheless lasted almost a week of pure time), some sortings and tests had to be subsequently tested.
Subtleties of implementation
It might surprise someone that in the implementation of the testing process itself, I did not use function pointers, which would greatly reduce the code. It turned out that this significantly slows down the algorithm (by about 5-10%). Therefore, I used a separate call to each function (this, of course, would not affect the relative speed, but ... I still want to improve the absolute one). For the same reason, vectors were replaced with ordinary arrays, templates and comparator functions were not used. All this is more relevant for the industrial use of the algorithm than its testing.
results
All results are available in several forms - three diagrams (a histogram that shows the change in speed when moving to the next restriction on one type of test, a graph that shows the same, but sometimes more clearly, and a histogram that shows which sorting is best works on some type of test) and the tables on which they are based. The third group was divided into three parts, and then little would be clear. However, even so far not all diagrams are successful (I seriously doubt the usefulness of the third type of diagrams), but I hope everyone can find the most suitable one for understanding.
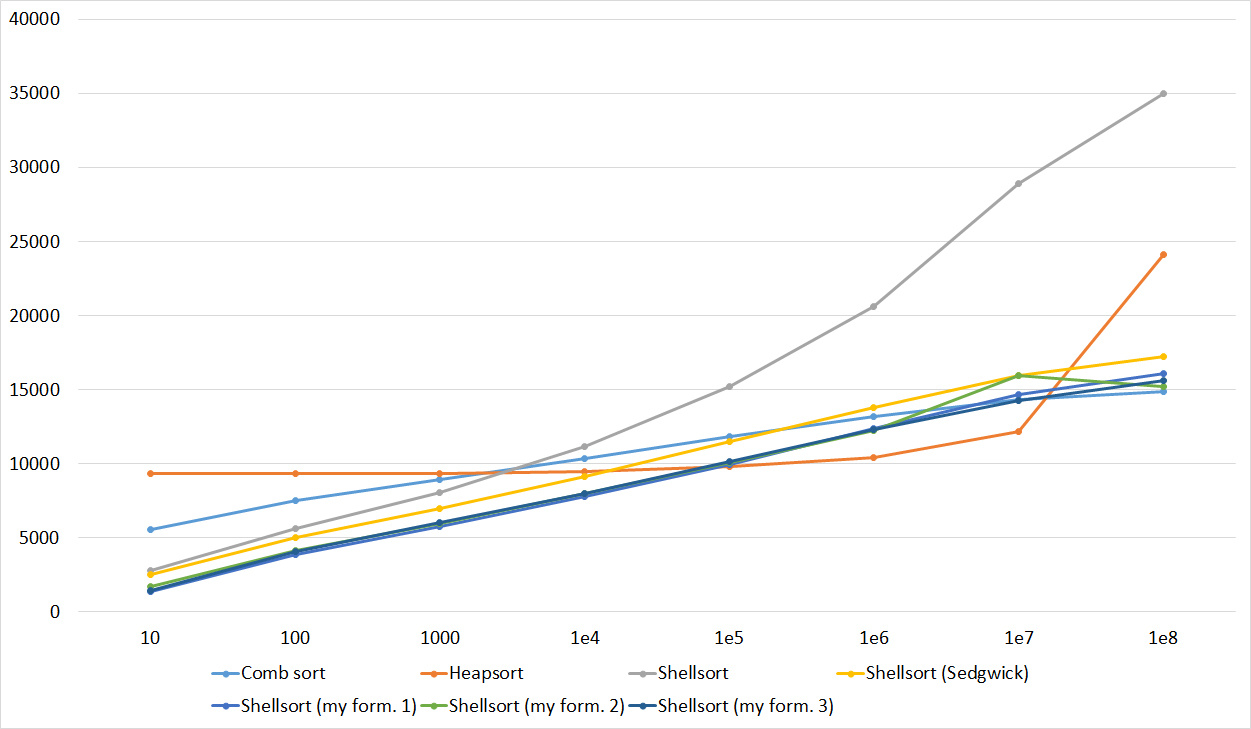
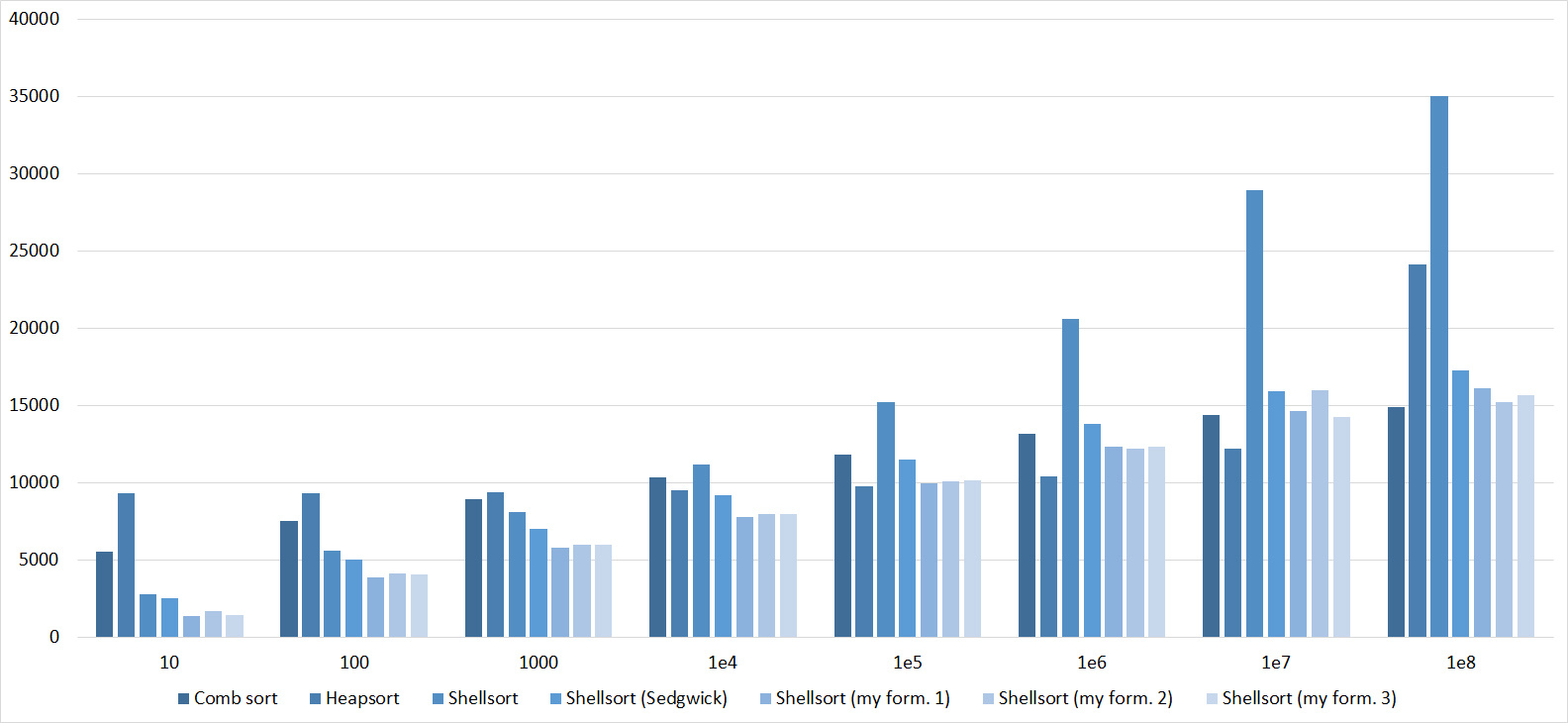
Since there are so many pictures, they are hidden by spoilers. A few comments about the notation. Sortings are named as above, if it is a Shell sort, then the author of the sequence is indicated in parentheses, Ins (for compactness) is assigned to the names of sorts that switch to sorting by inserts. In the diagrams, the second group of tests indicates the possible length of sorted subarrays, the third group indicates the number of swaps, and the fourth indicates the number of replacements. The overall result was calculated as an average of four groups.
First sort group
Array of random numbers
Tables
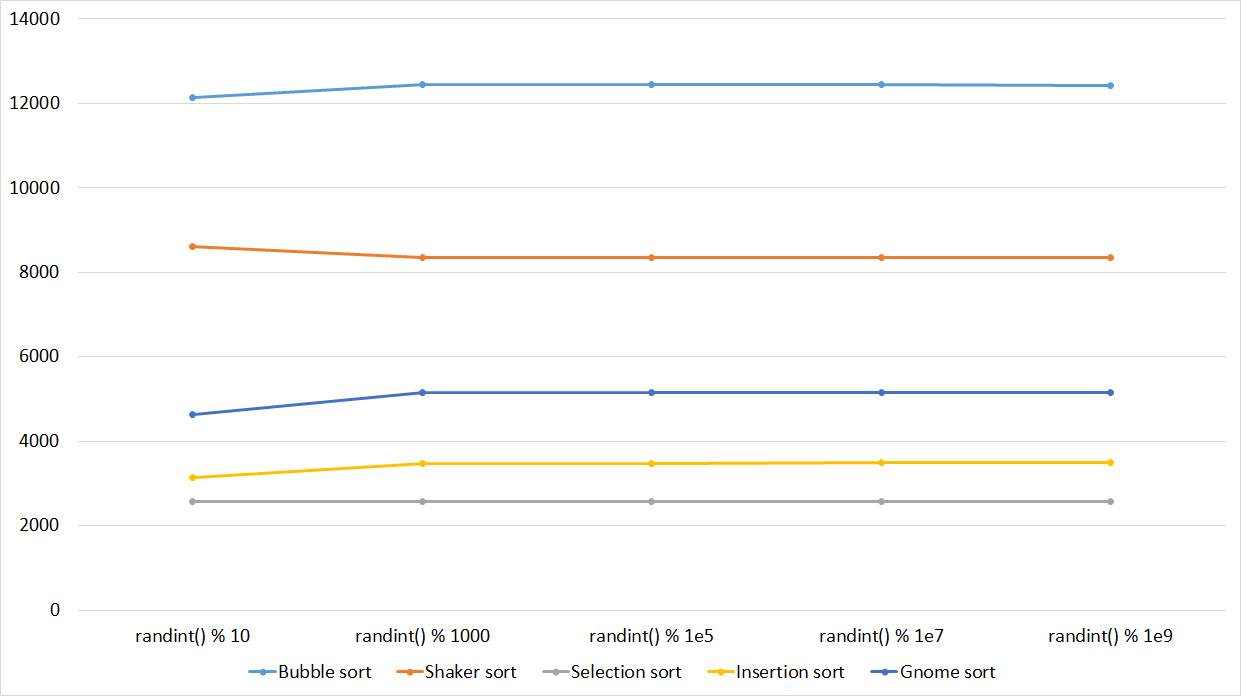


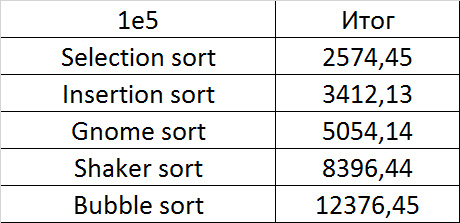
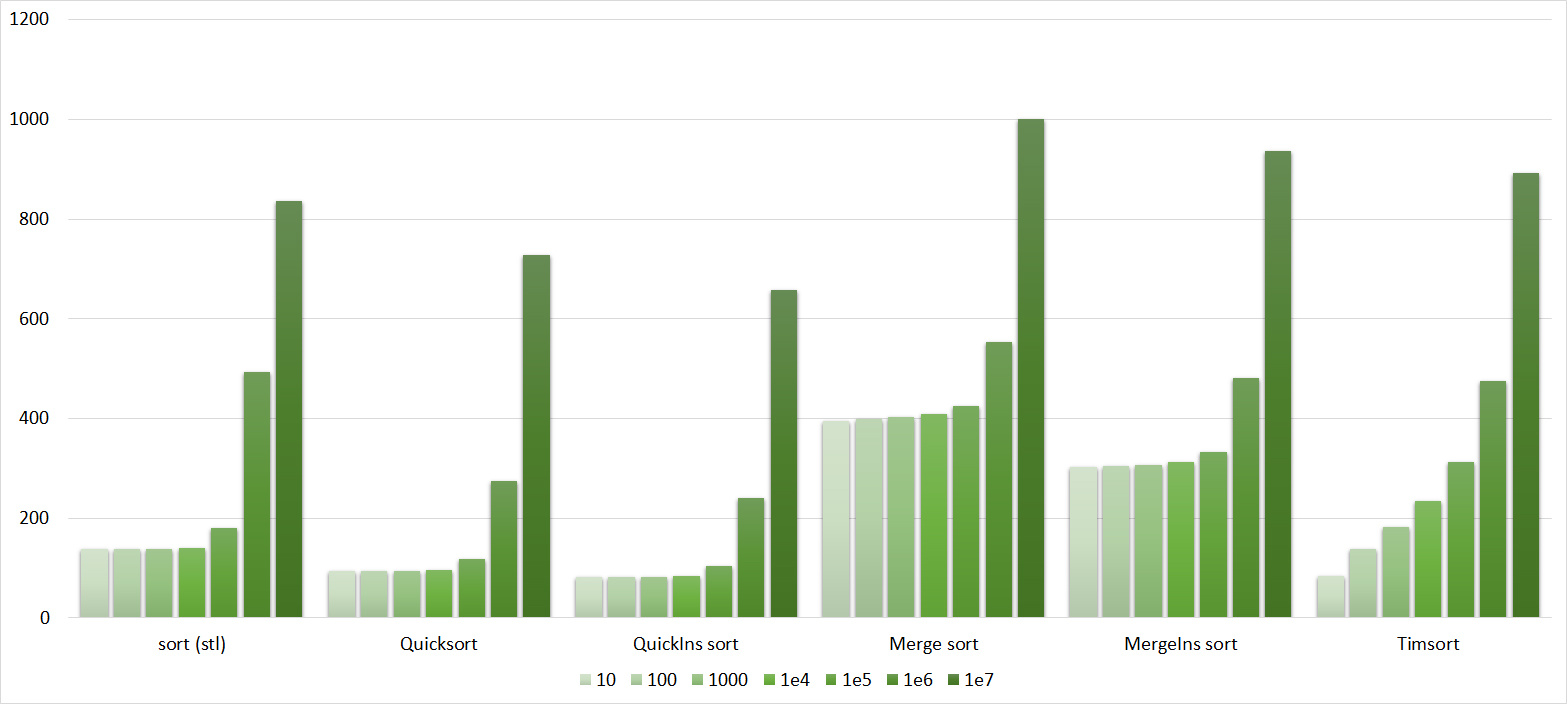
Quite boring results, even partial sorting with a small module is almost invisible.
Partially Sorted Array
Tables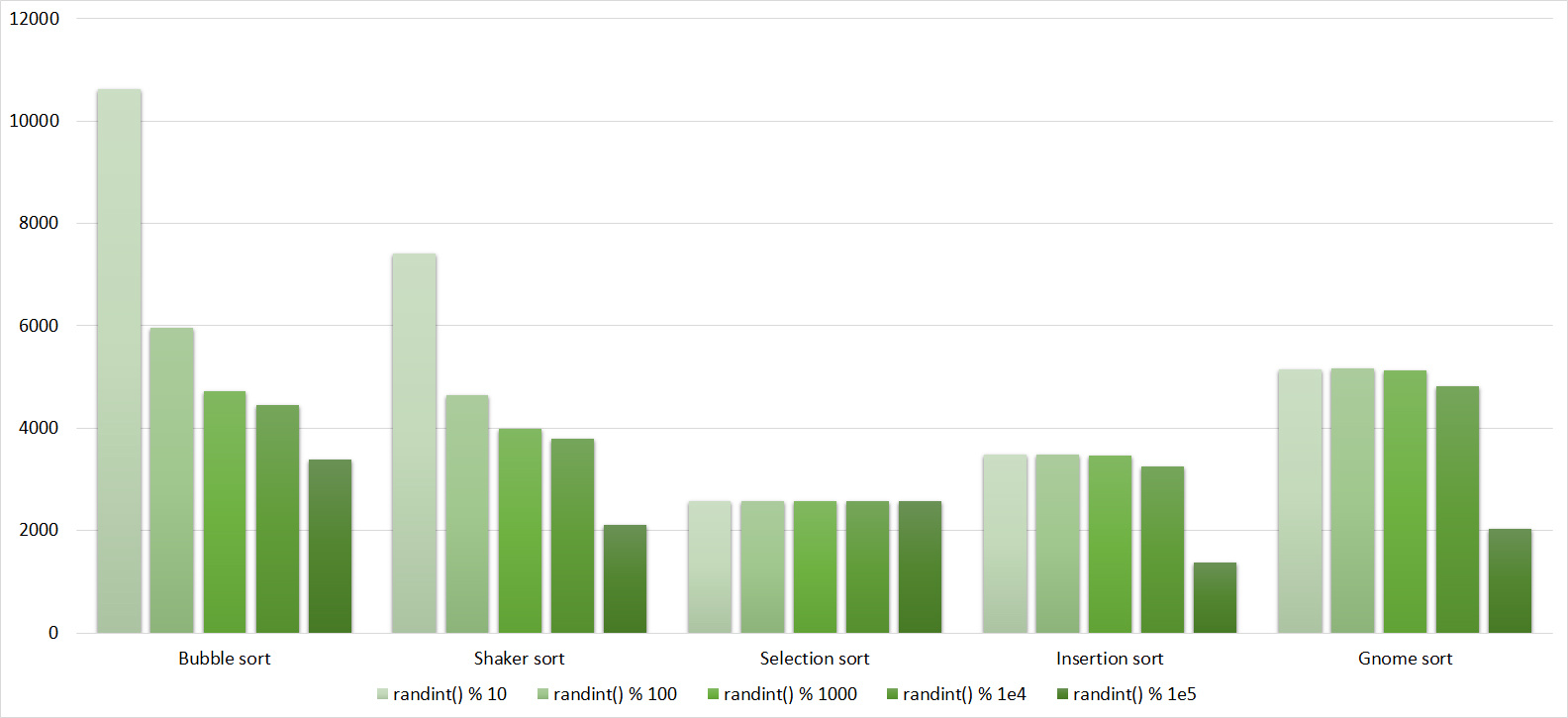
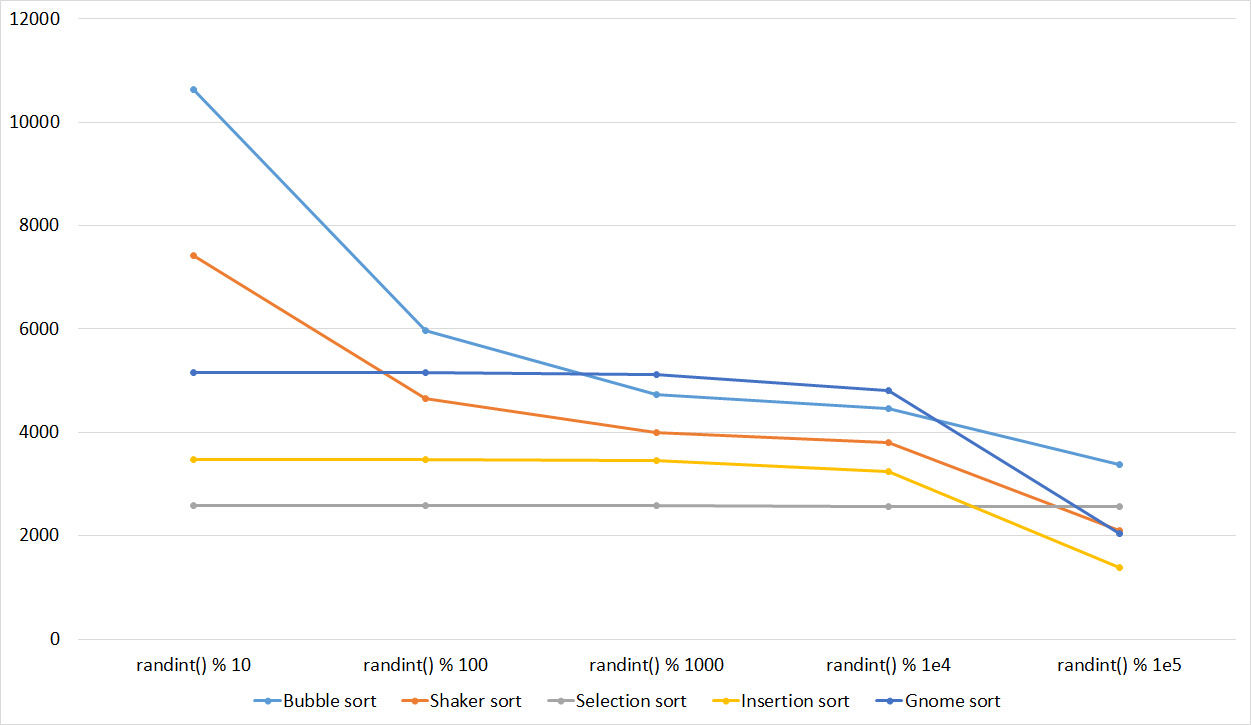
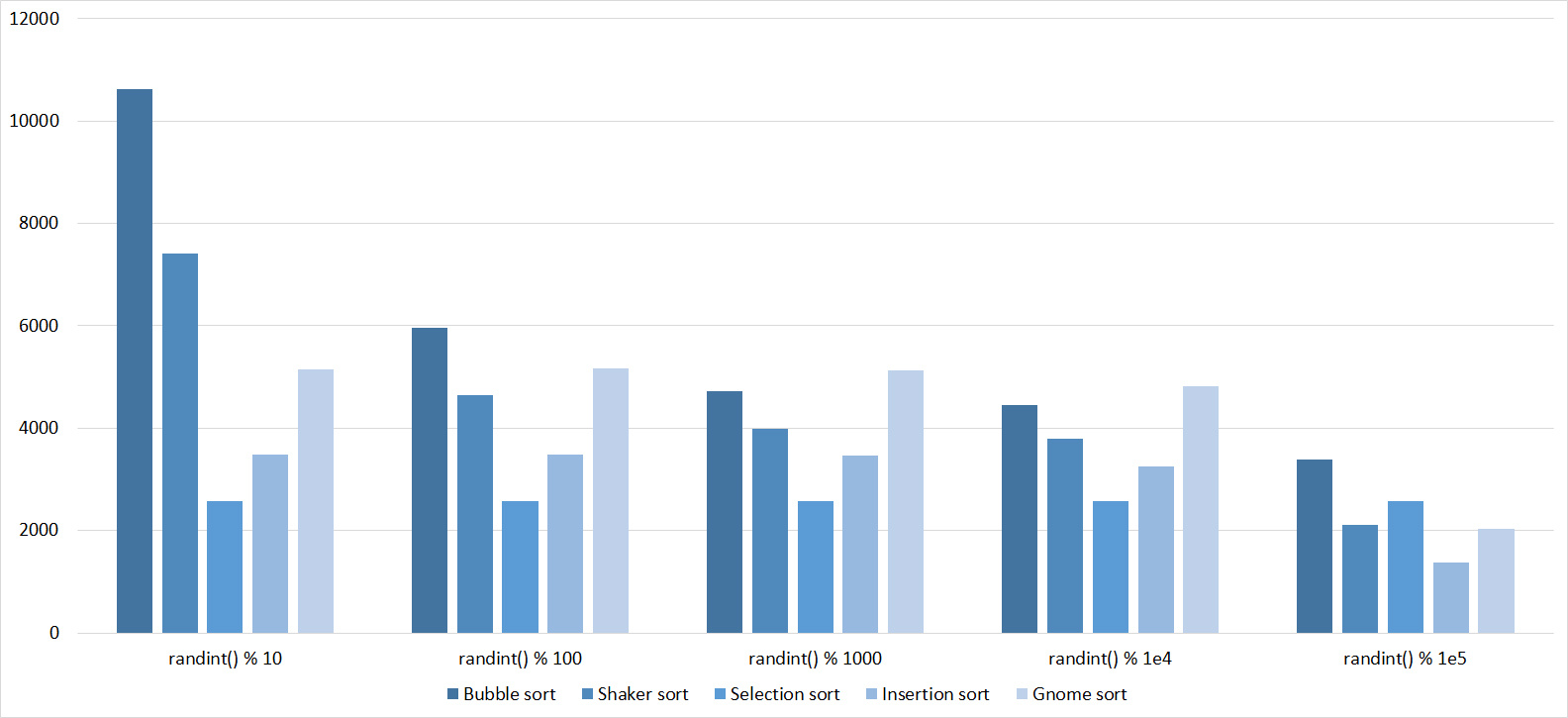

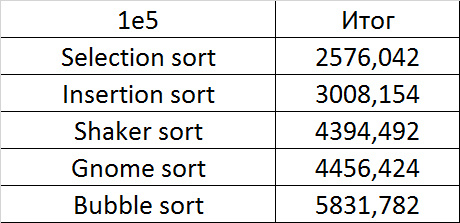
Already much more interesting. Exchange sortings reacted most violently, shaker even overtook the gnome. Sorting inserts accelerated only at the very end. Sorting by choice, of course, works just as well.
Swaps
Tables
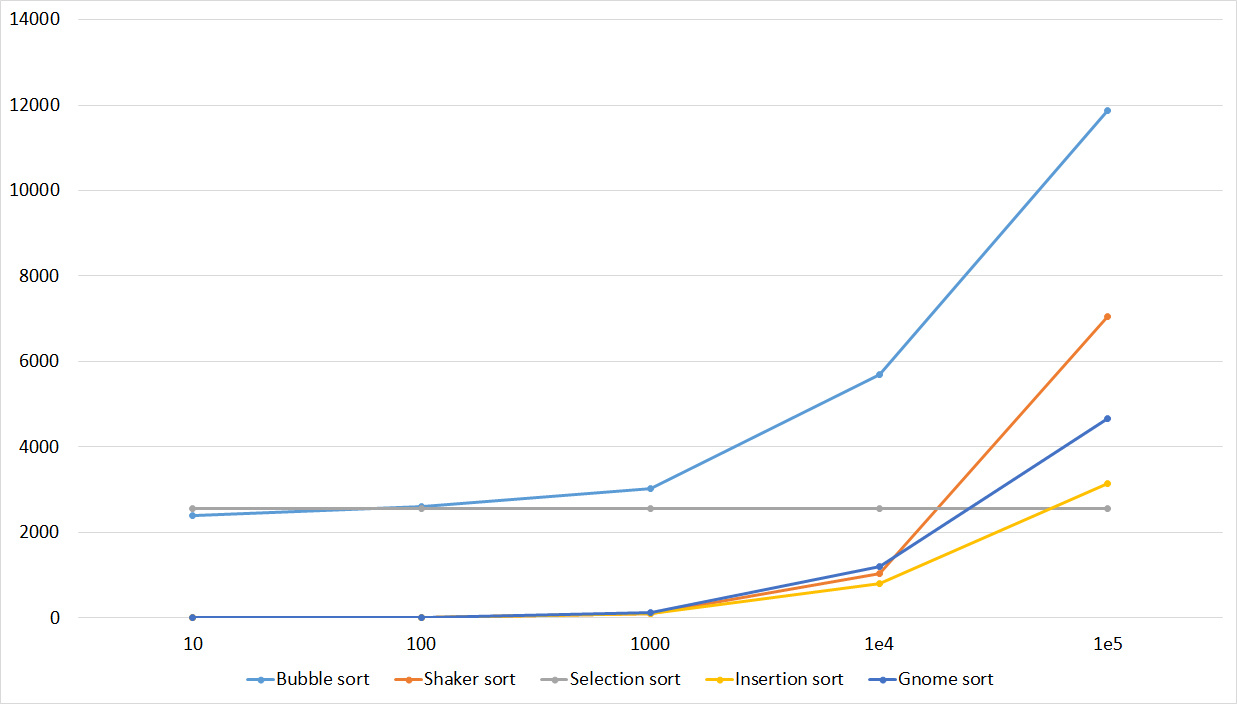



Here, finally, sorting by inserts has shown itself, although the growth in speed with the shaker is about the same. Here the weakness of sorting by the bubble was manifested - just one swap moving a small element to the end is enough, and it already works slowly. Sorting selection was almost at the end.
Permutation changes
Tables
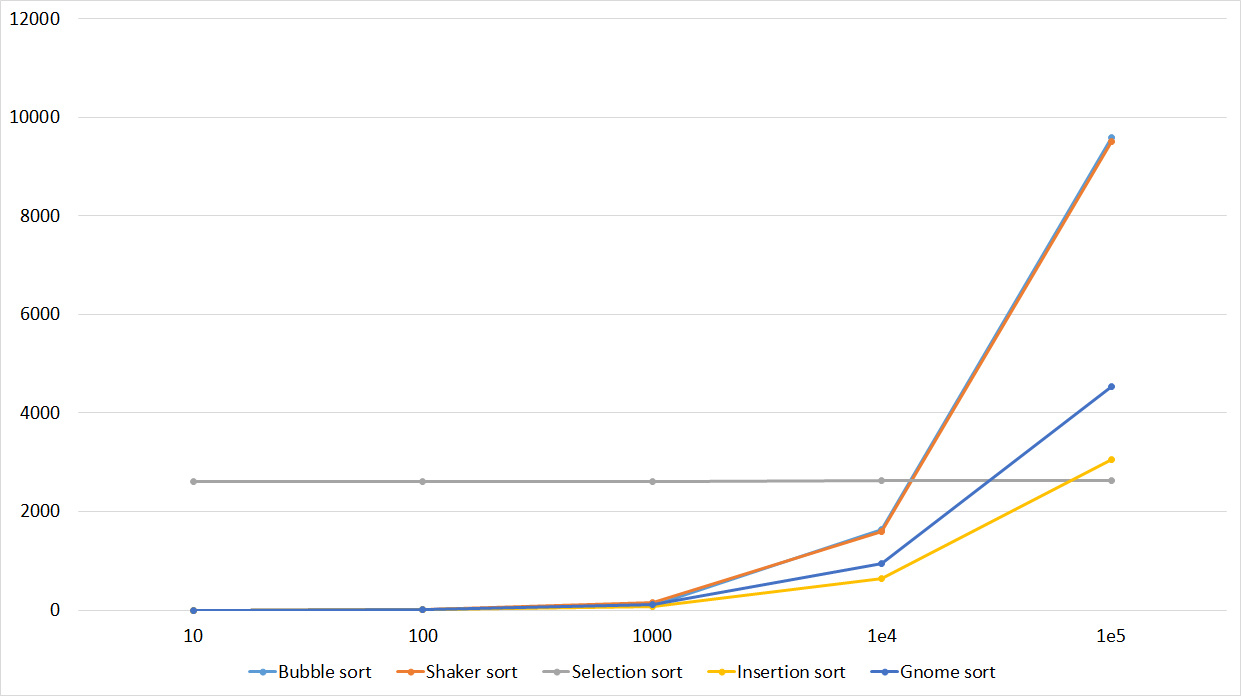
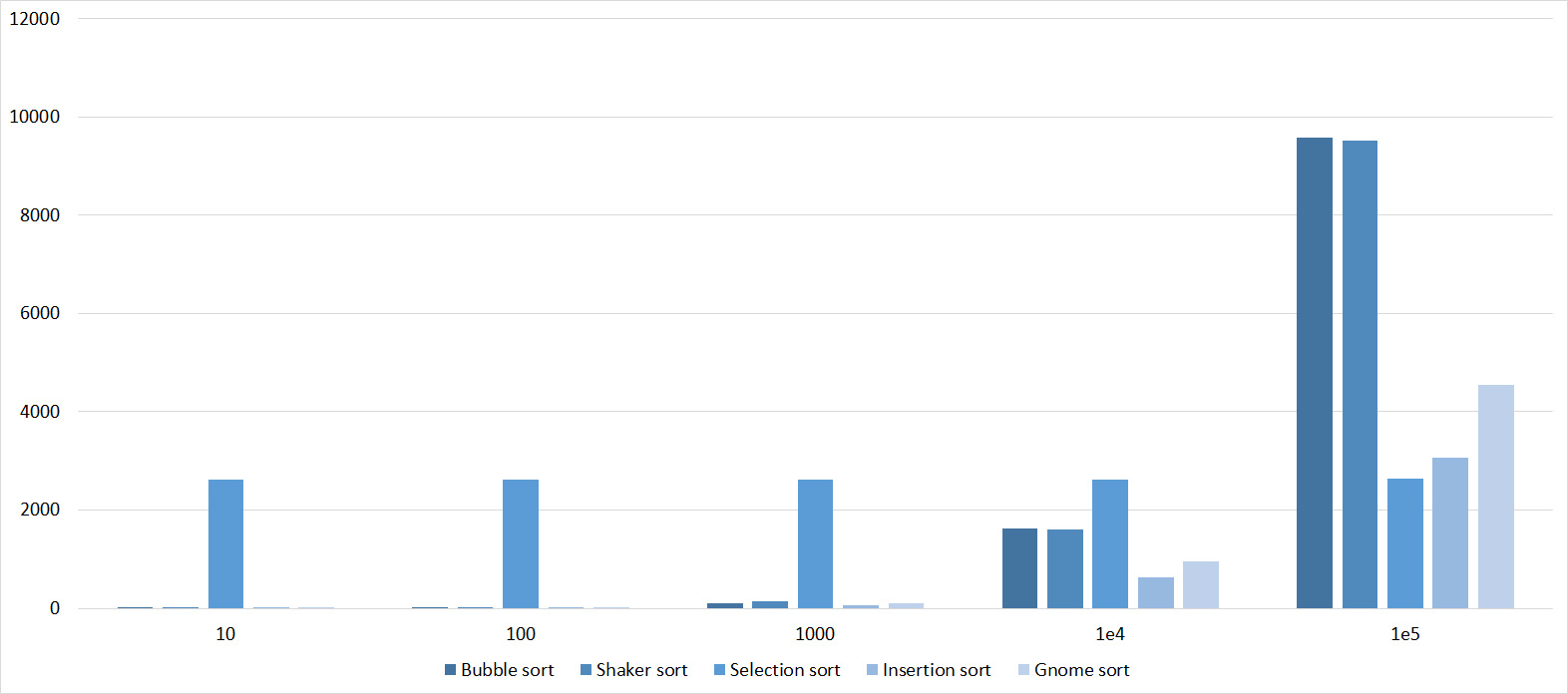

The group is almost no different from the previous one, so the results are similar. However, the sorting by the bubble breaks ahead, since a random element inserted into the array is likely to be larger than all the others, that is, it moves to the end in one iteration. Sorting by choice has become an outsider.
Repetitions
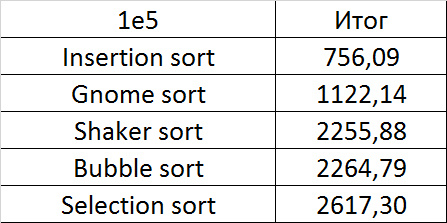
Tables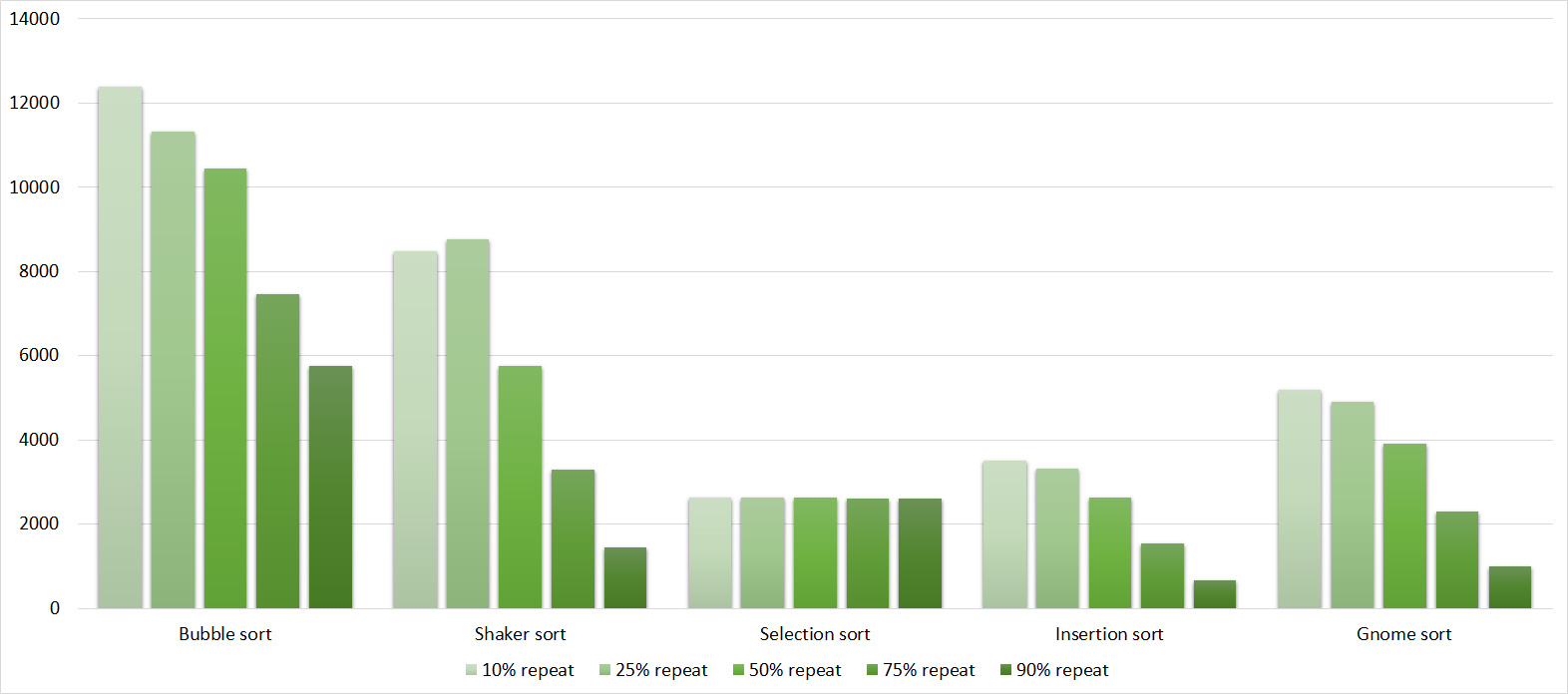
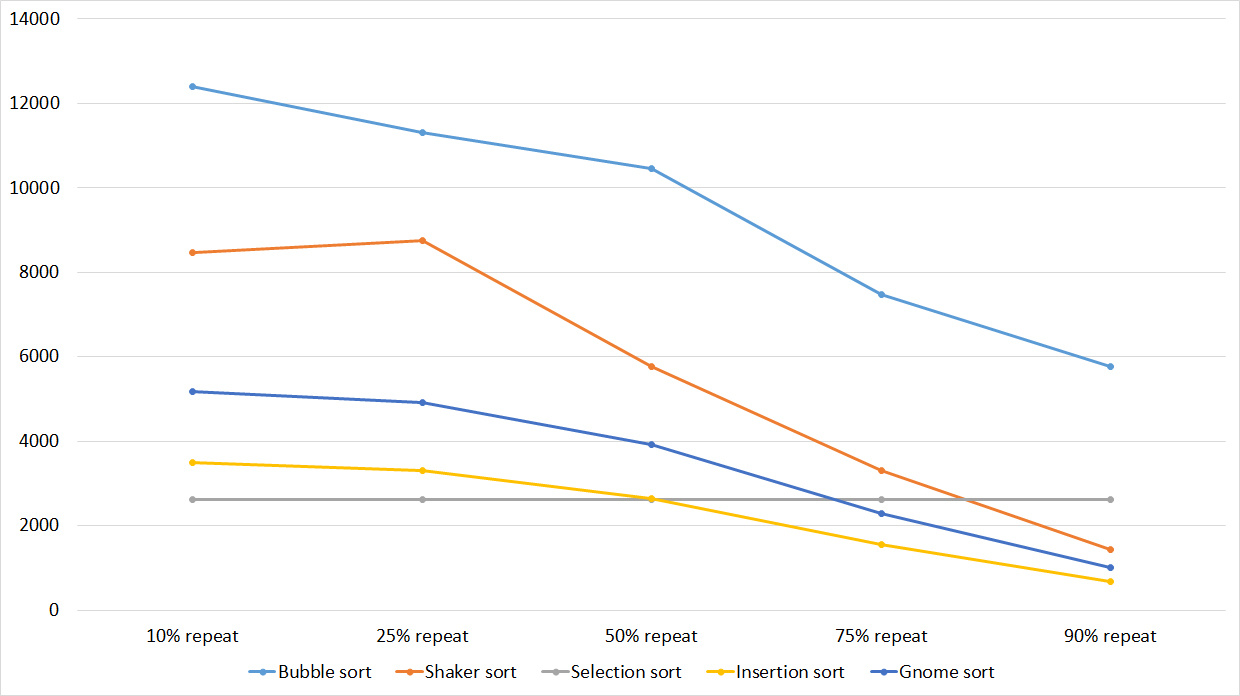
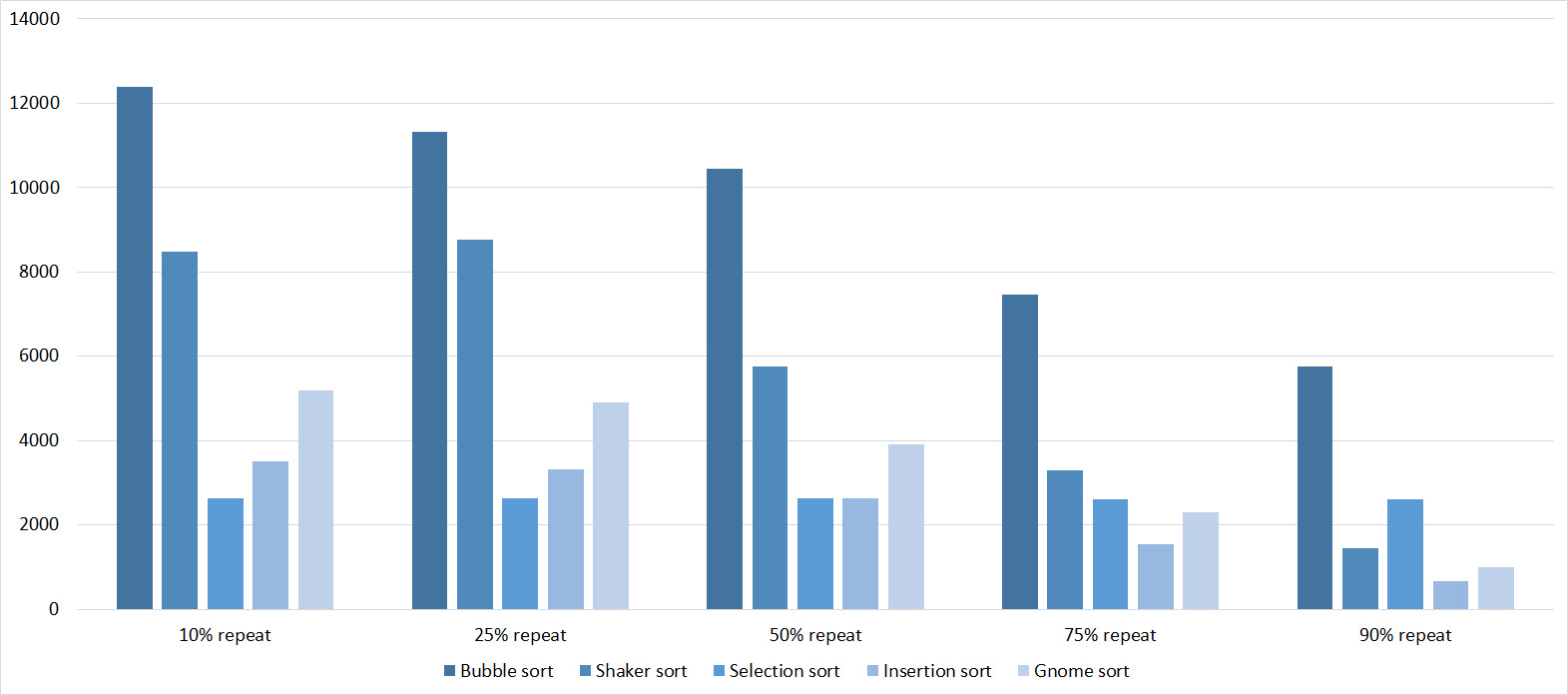

Here, all sortings (except, of course, sortings by choice) worked almost identically, accelerating as the number of repetitions increased.
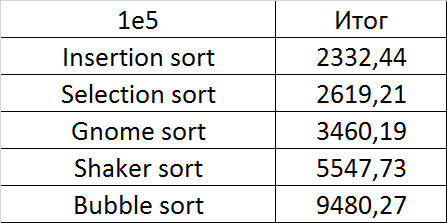
Final results

Due to its absolute indifference to the array, sorting by choice, which worked faster than anyone on random data, still lost to sorting by inserts. Dwarf sorting was noticeably worse than the latter, which is why its practical use is doubtful. Shaker and bubble sortings were the slowest.
The second group of sorts
Array of random numbers
Tables, 1-6 elements
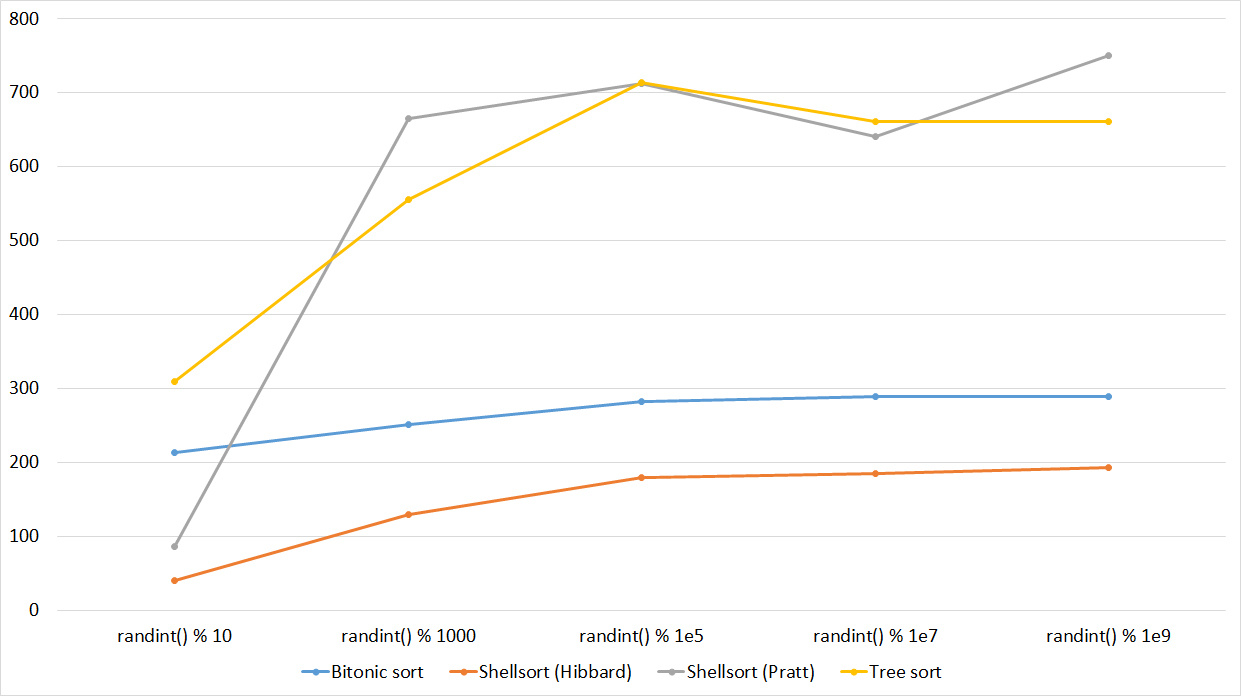
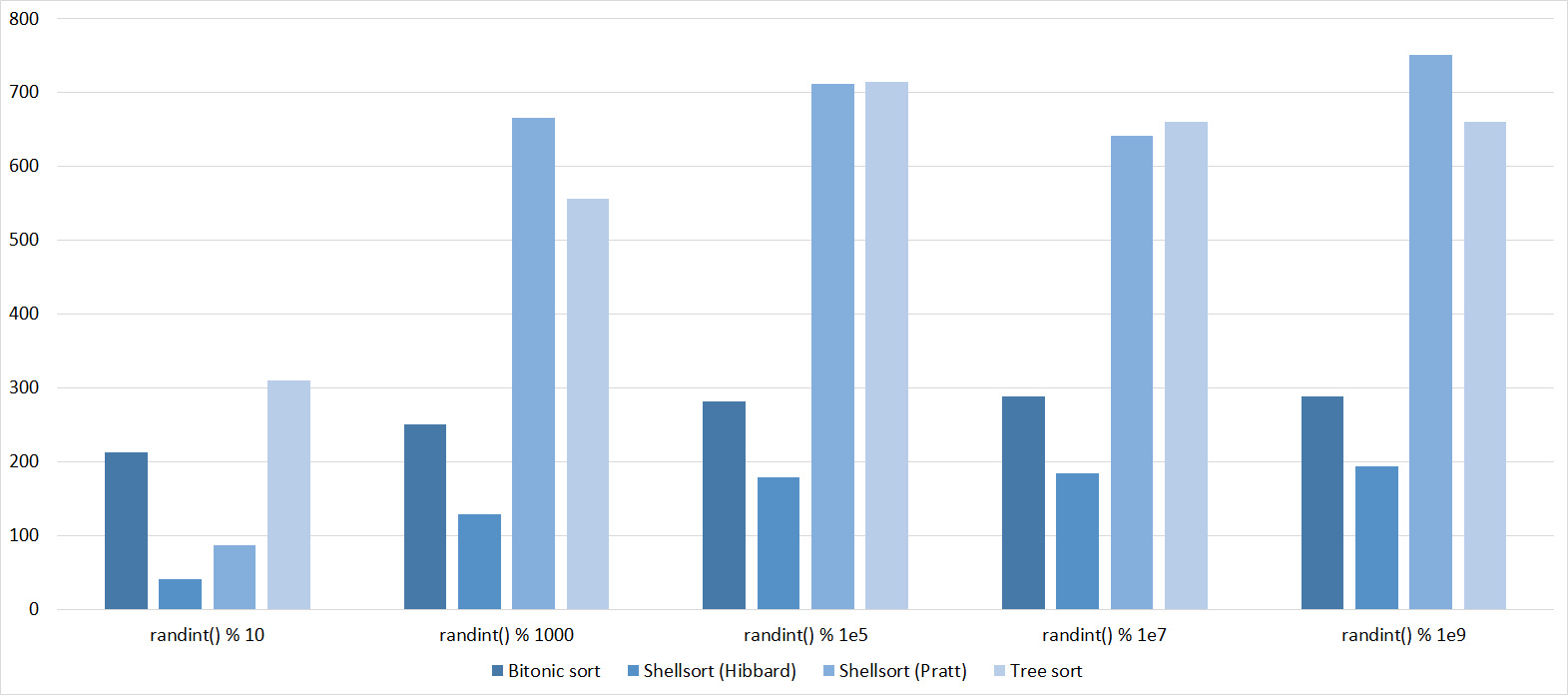


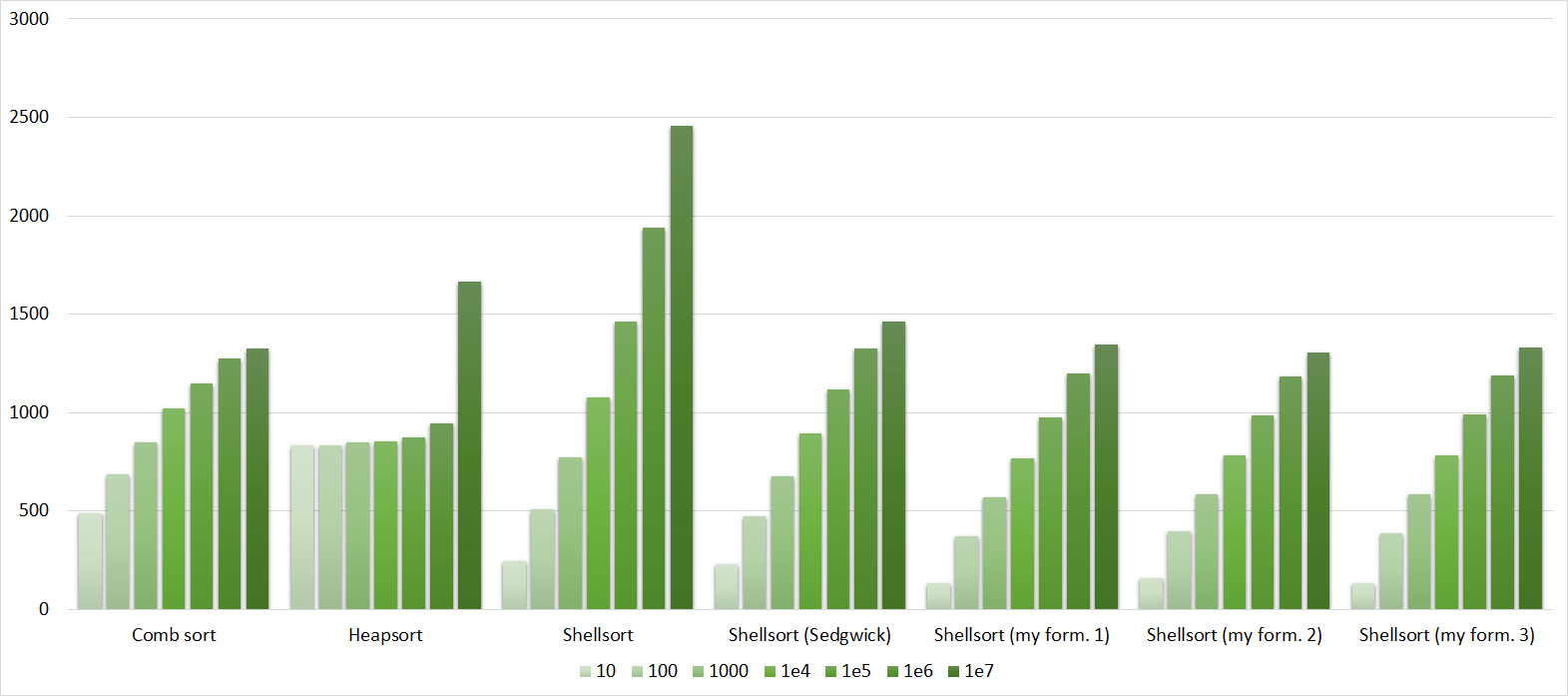
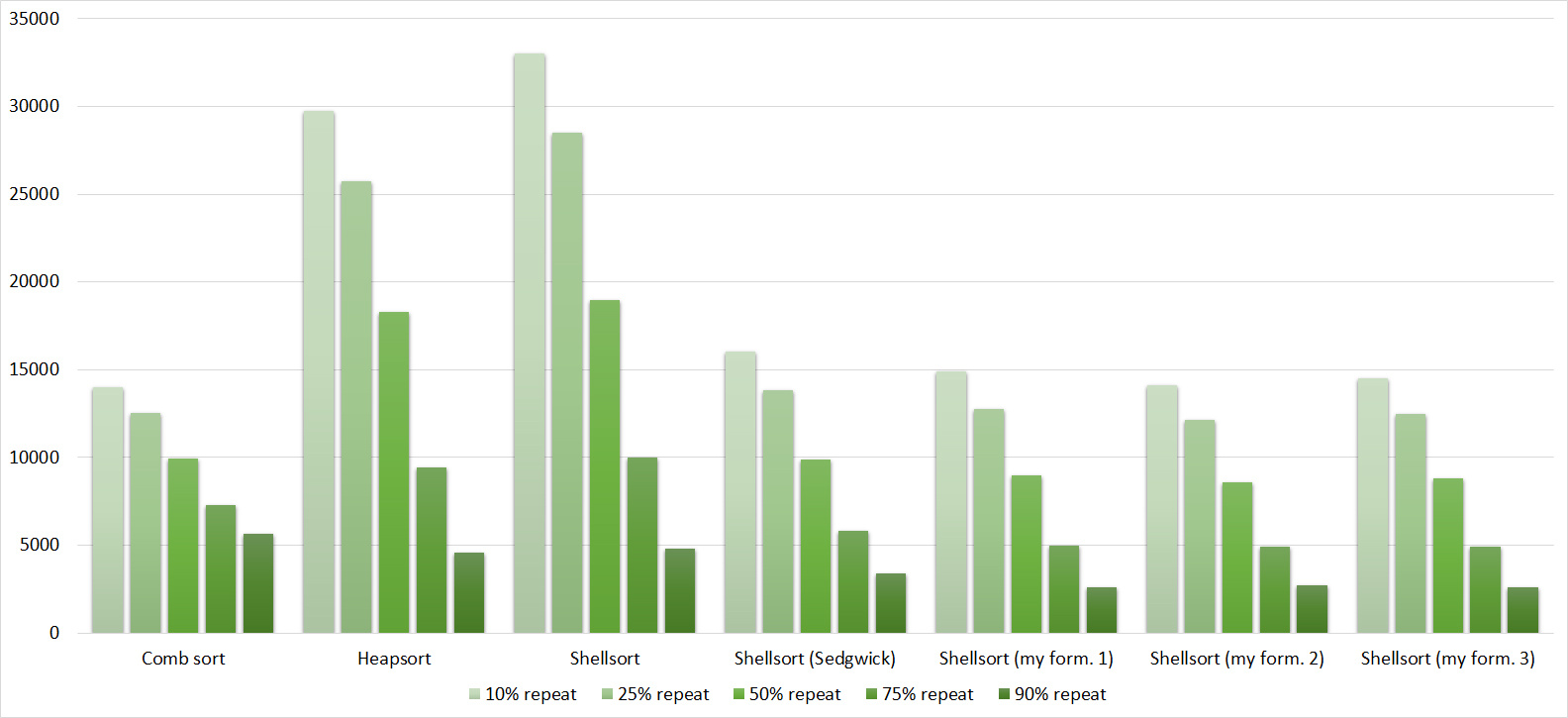
Shell sorting with the Pratt sequence behaves very strangely, the rest are more or less clear. Sorting by a tree likes partially sorted arrays, but does not like repetitions, which is probably why the worst time is in the middle.
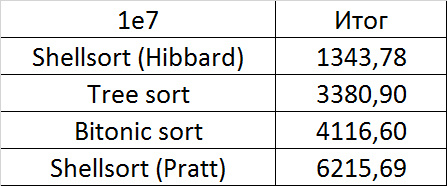
Tables, 1e7 elements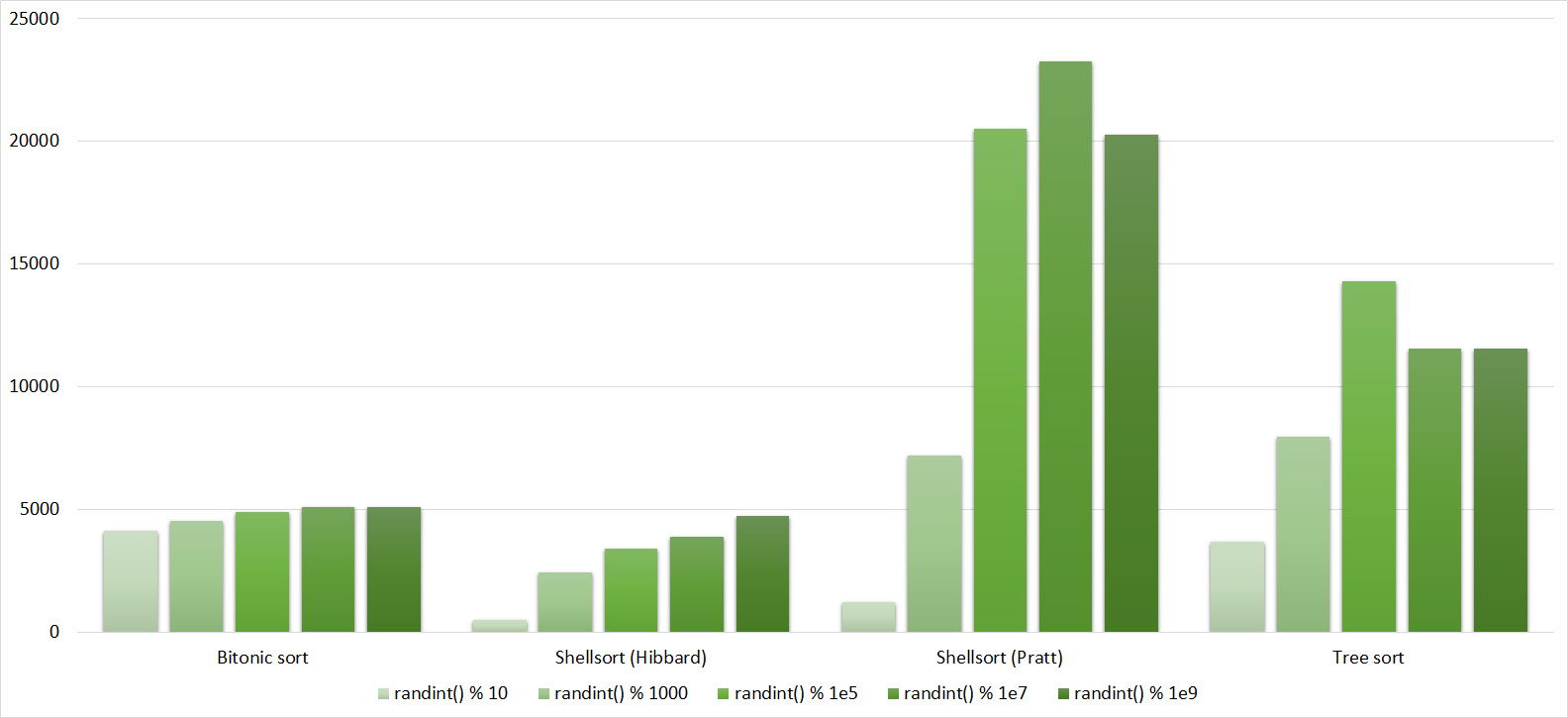
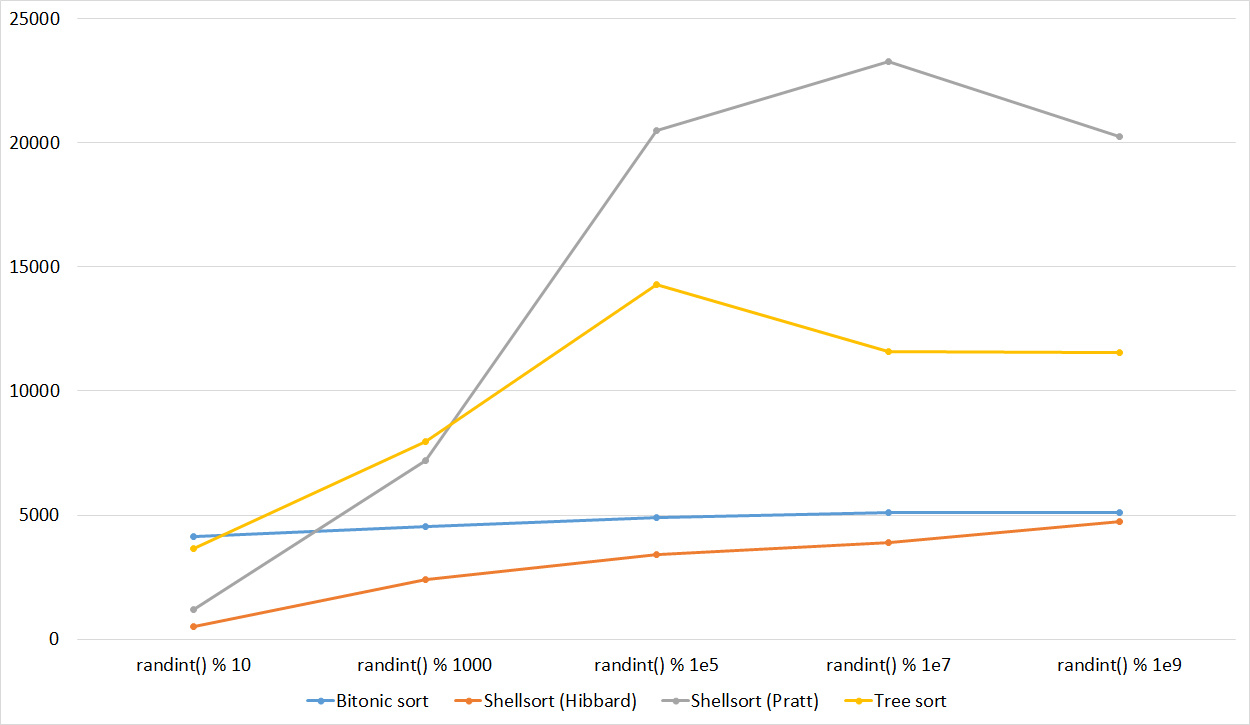
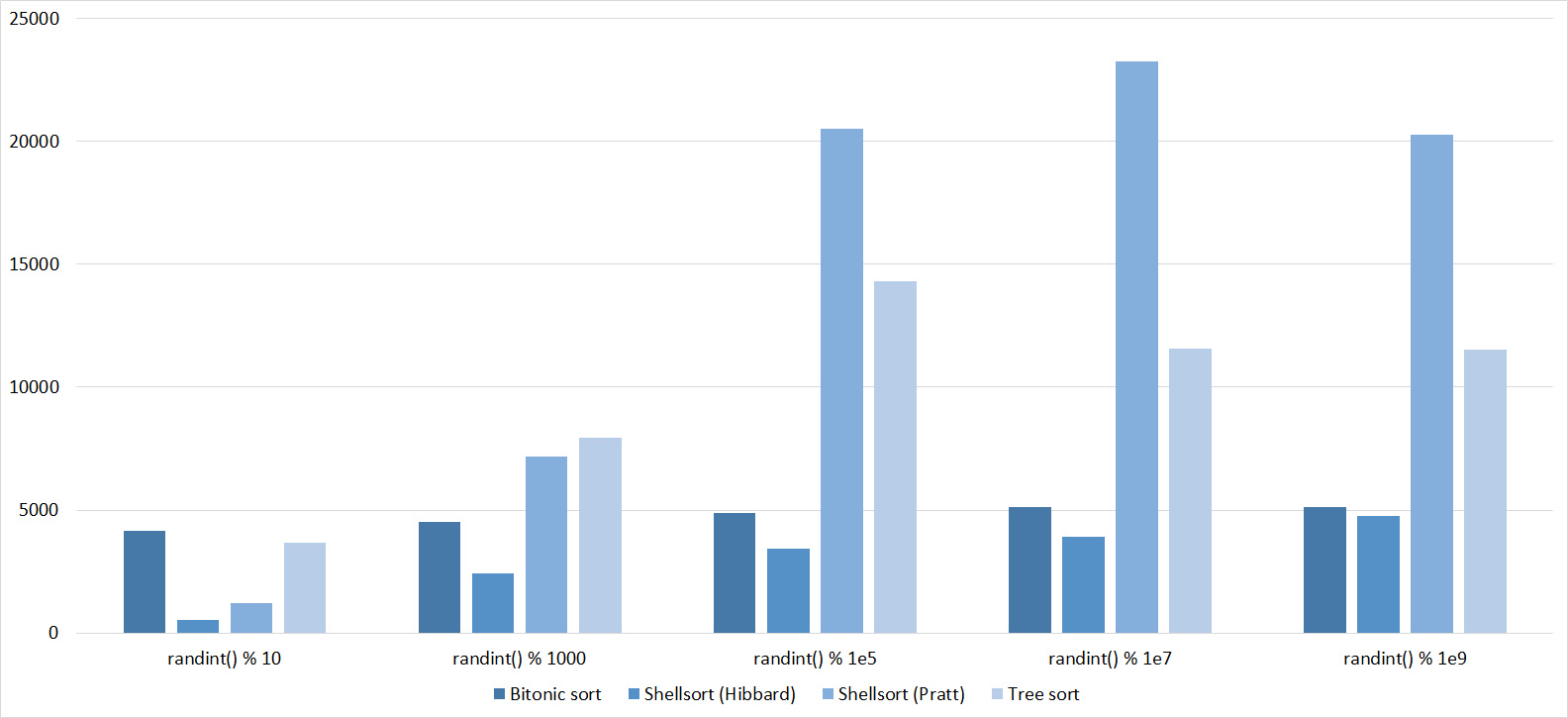

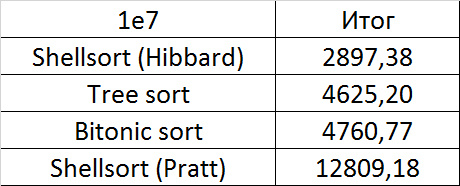
Everything is as before, only Shell and Pratt strengthened in the second group due to sorting. The influence of asymptotics also becomes noticeable - tree sorting is in second place, unlike a group with a smaller number of elements.
Partially Sorted Array
Tables, 1-6 elements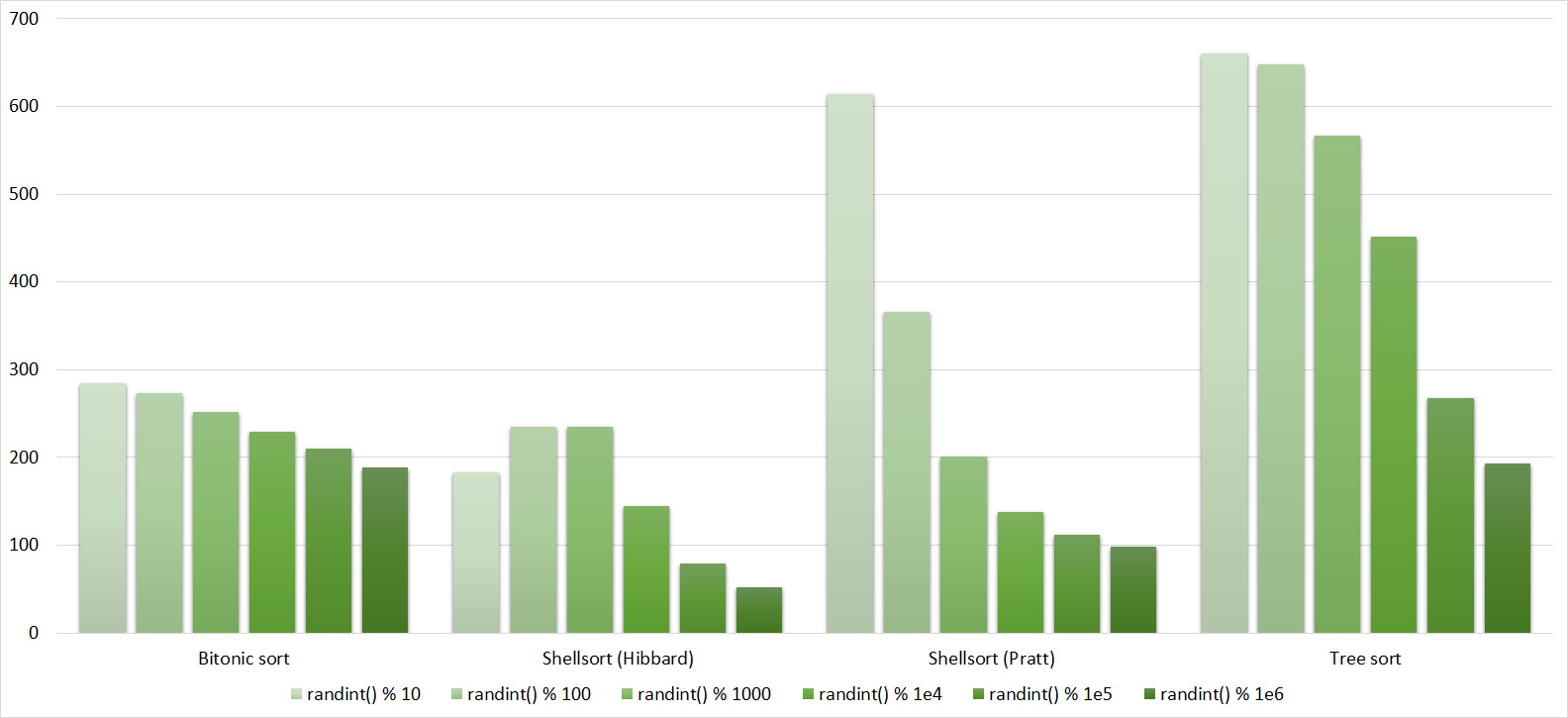
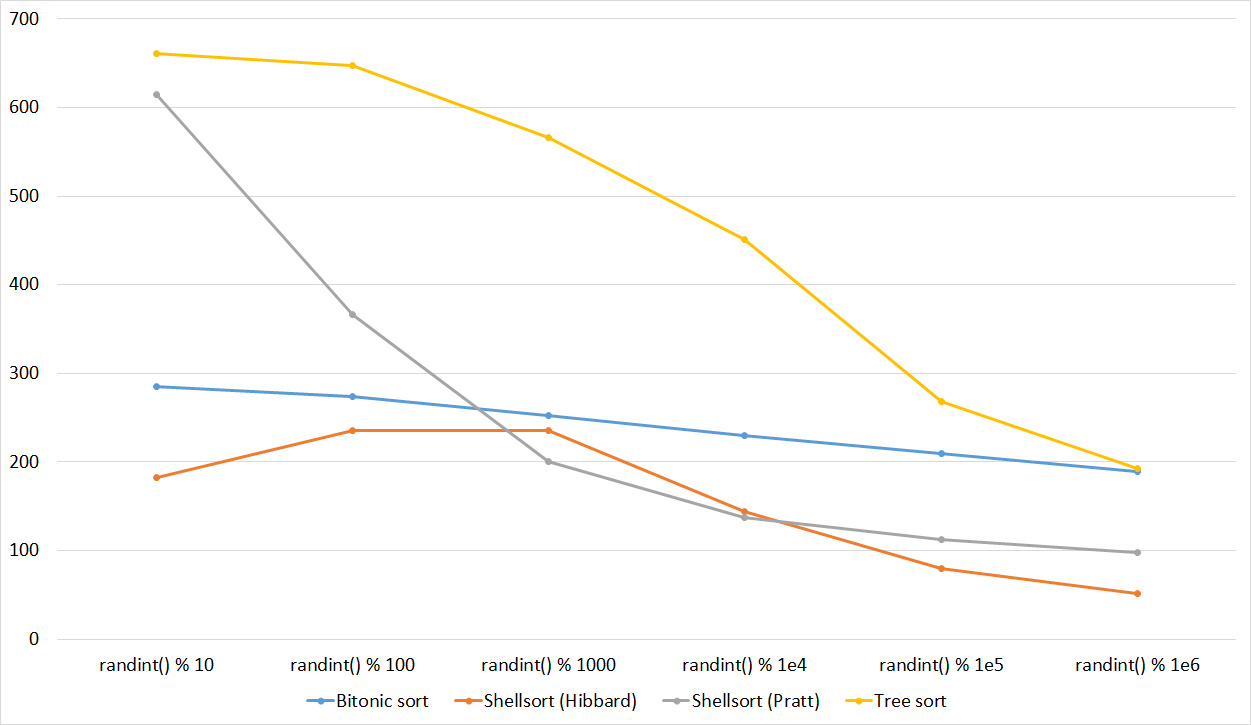



Here, all sortings behave understandably, except for Shell and Hibbard, which for some reason does not immediately begin to accelerate.
Tables, 1e7 elements
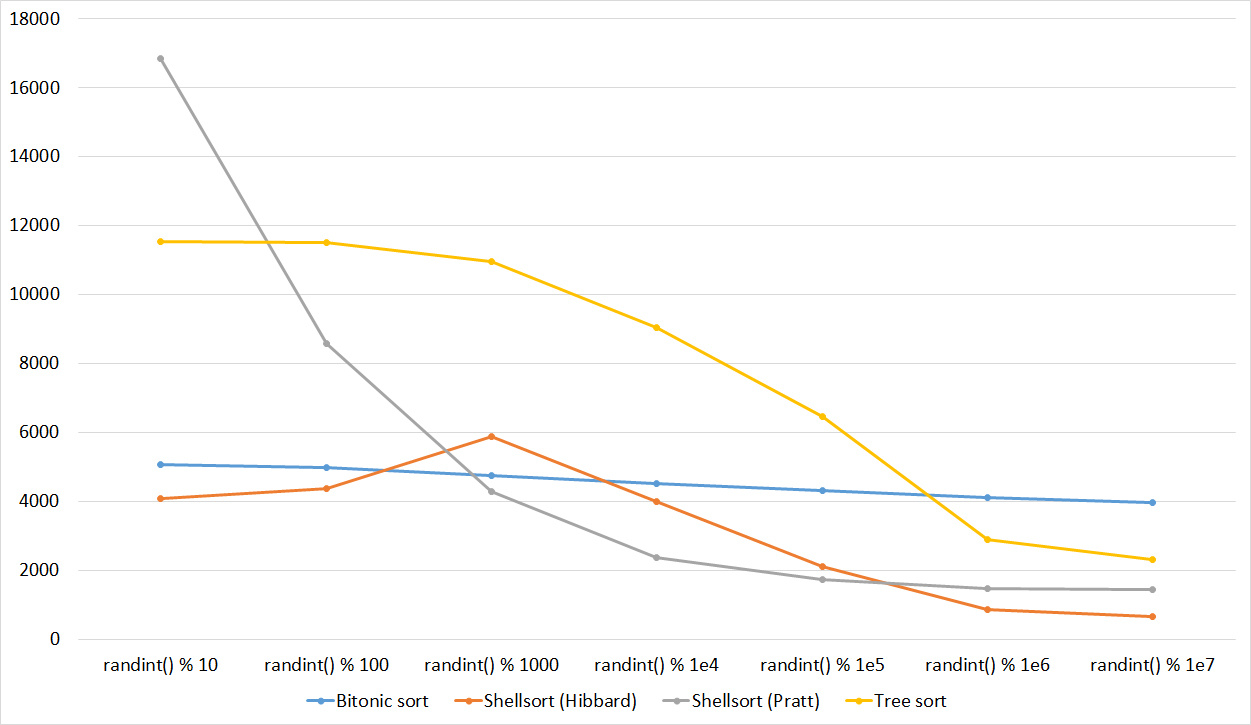


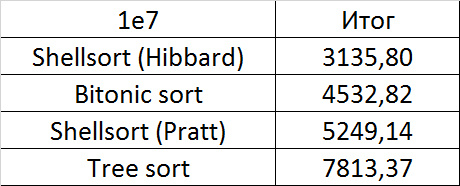
Here, in general, as before. Even the asymptotics of sorting by a tree did not help her escape from last place.
Swaps
Tables, 1-6 elements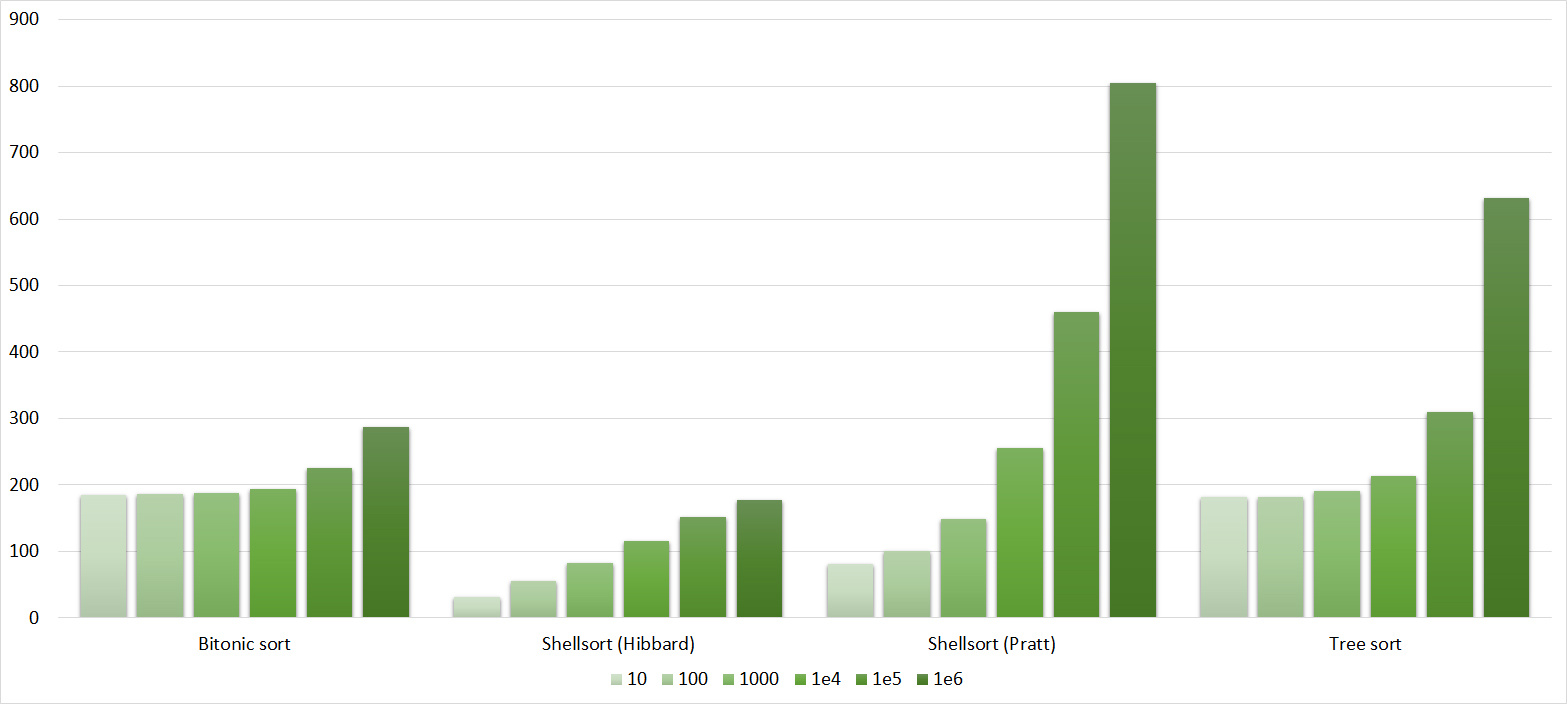
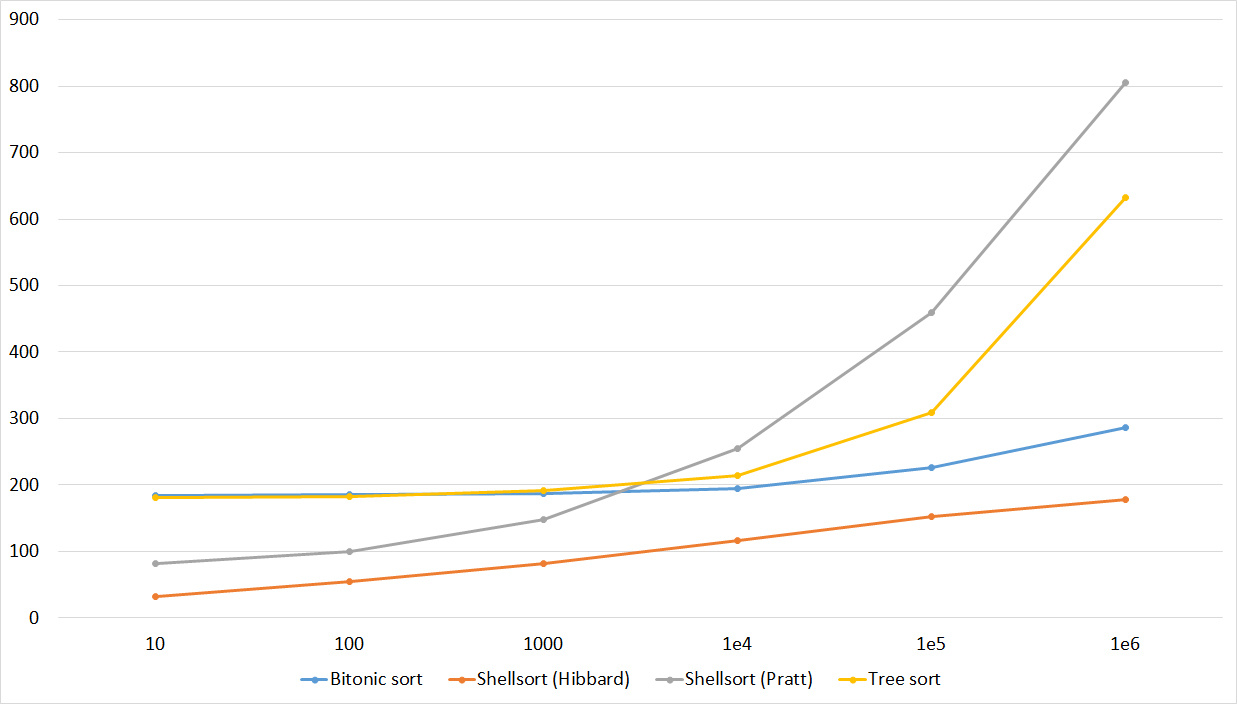
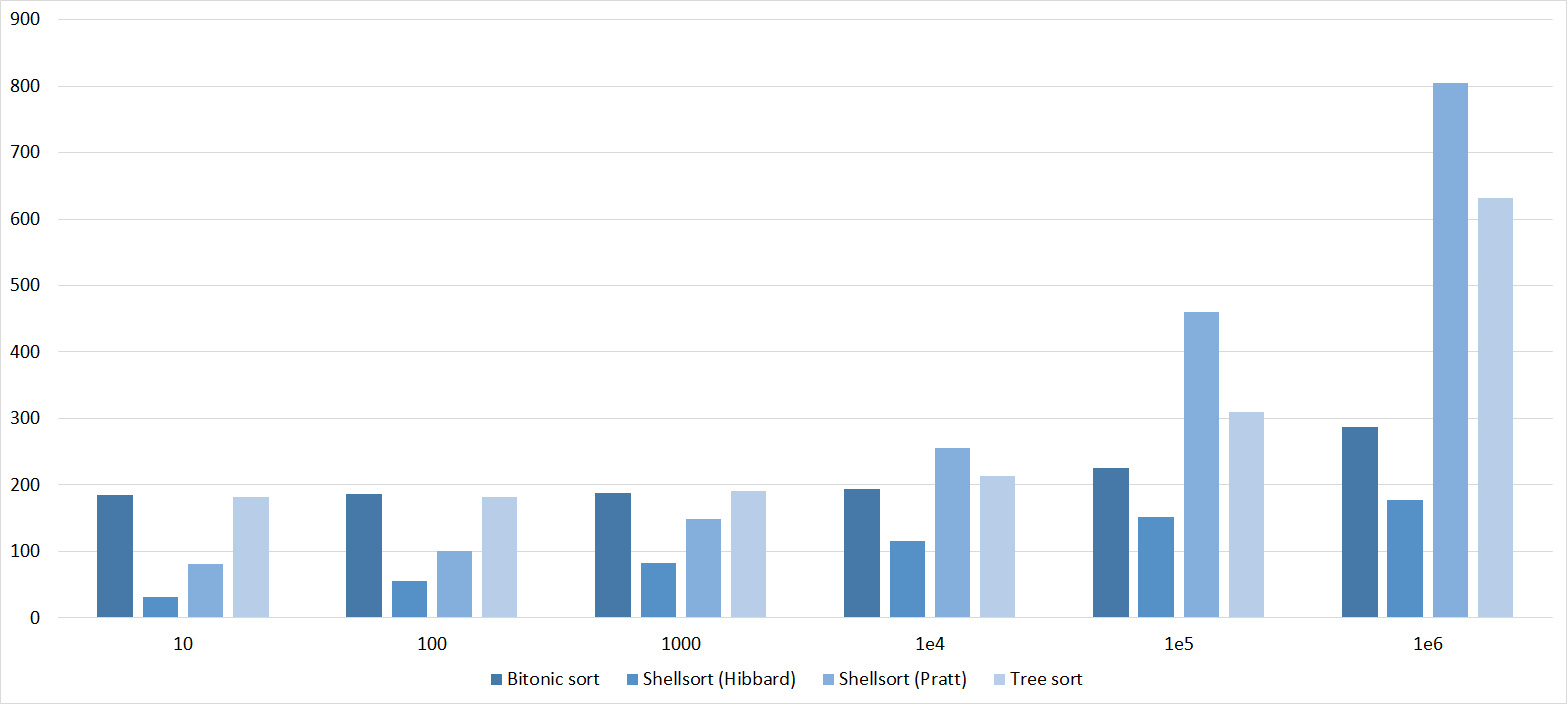

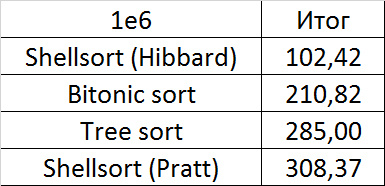
Tables, 1e7 elements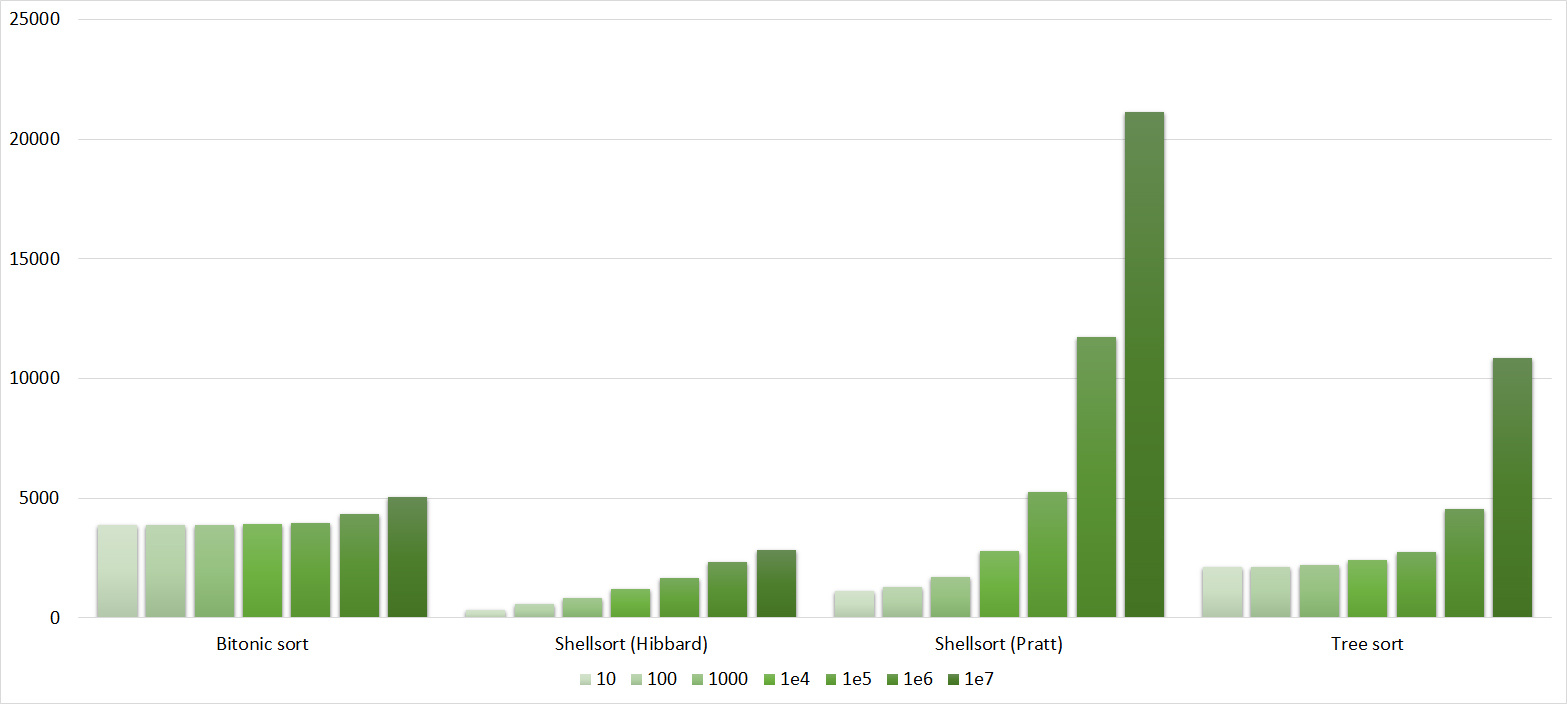
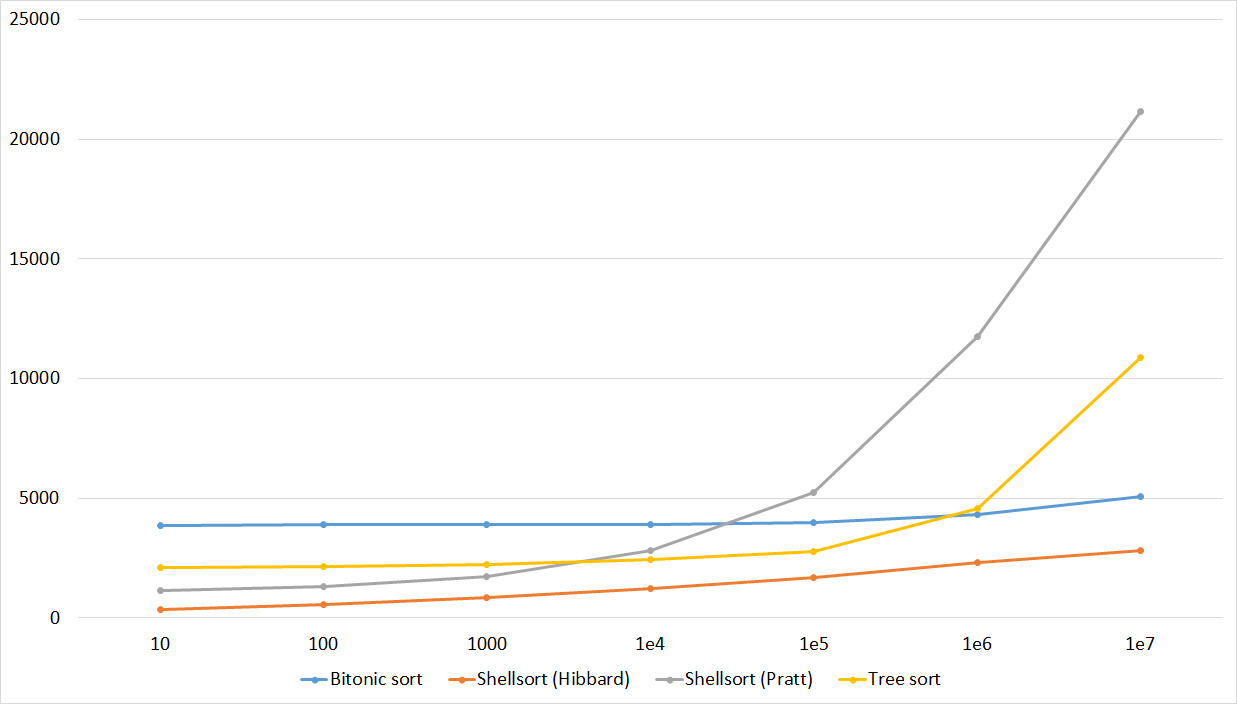
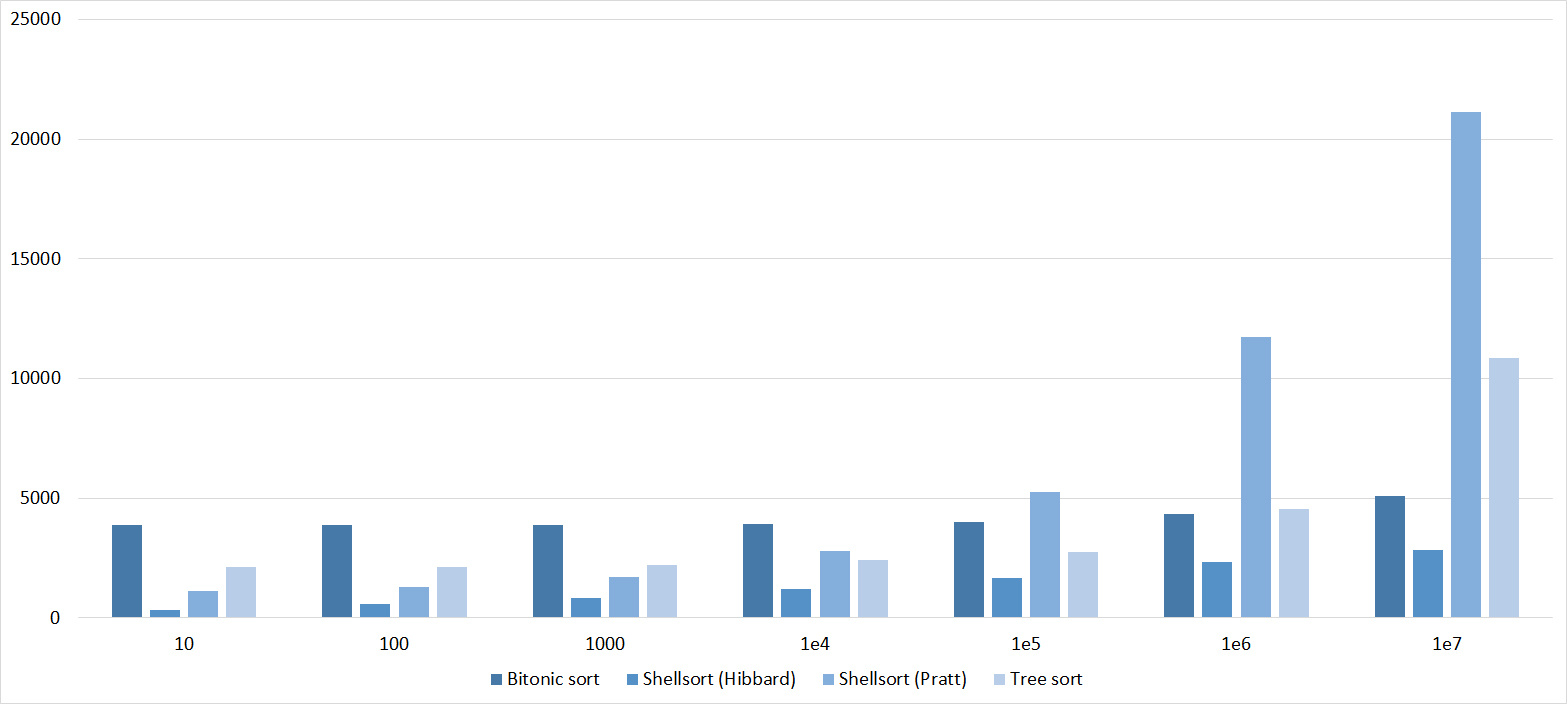

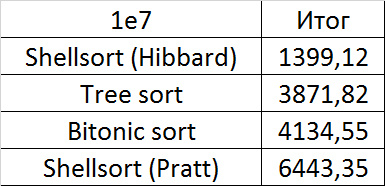
It is noticeable here that Shell sortings have a great dependence on partial sorting, since they behave almost linearly, and the other two only fall strongly in the last groups.
Permutation changes
Tables, 1-6 elements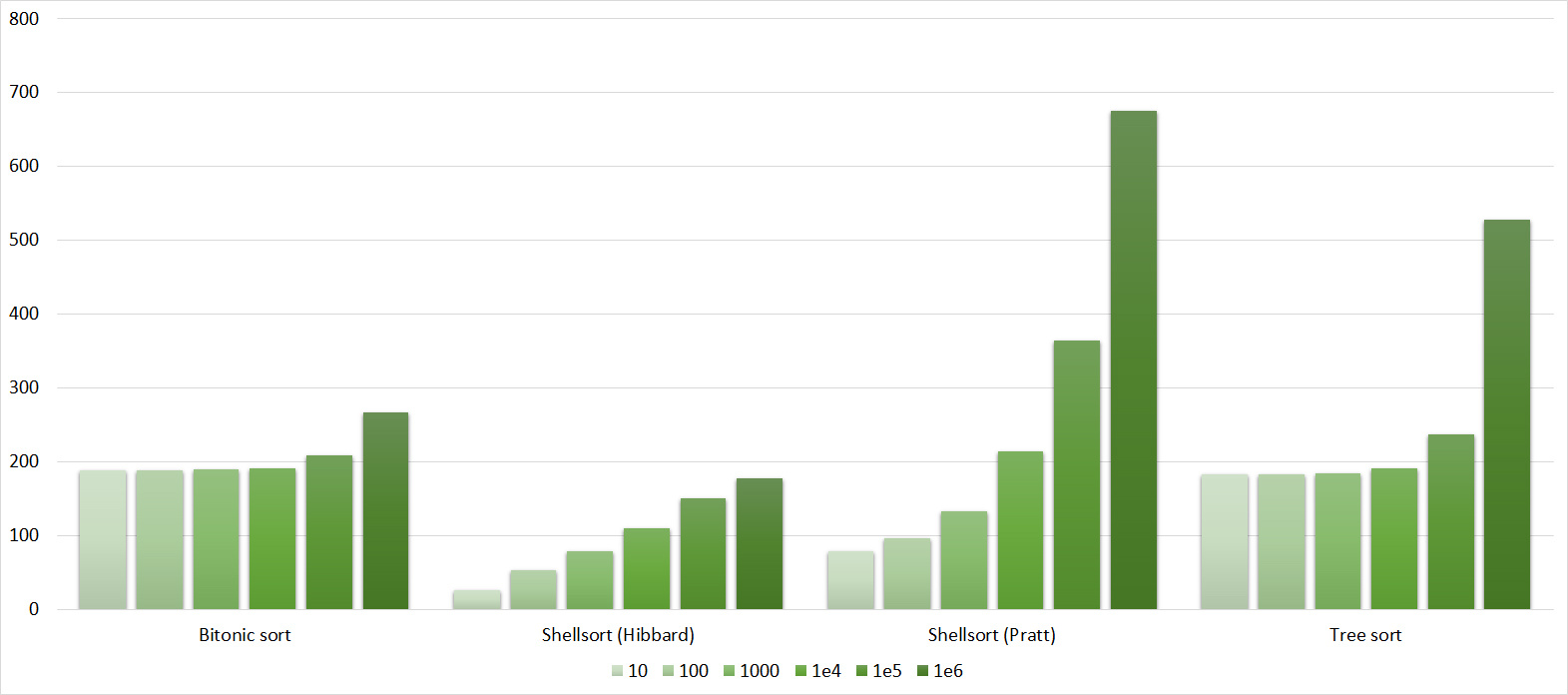
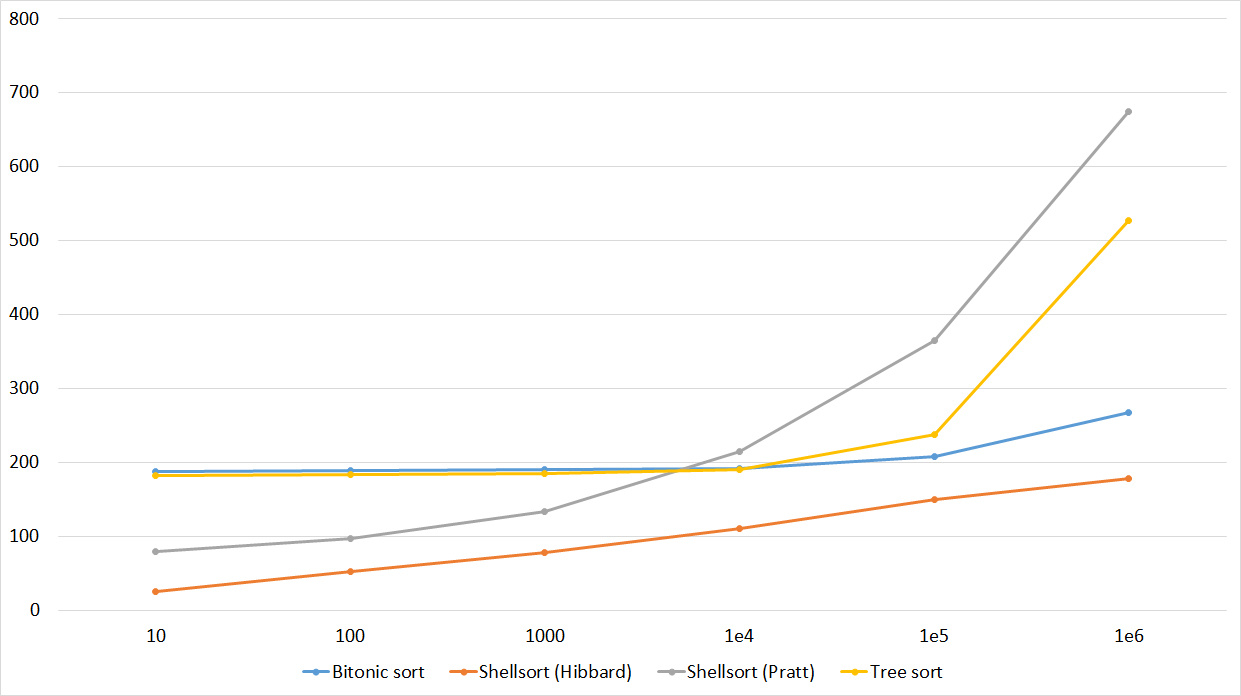
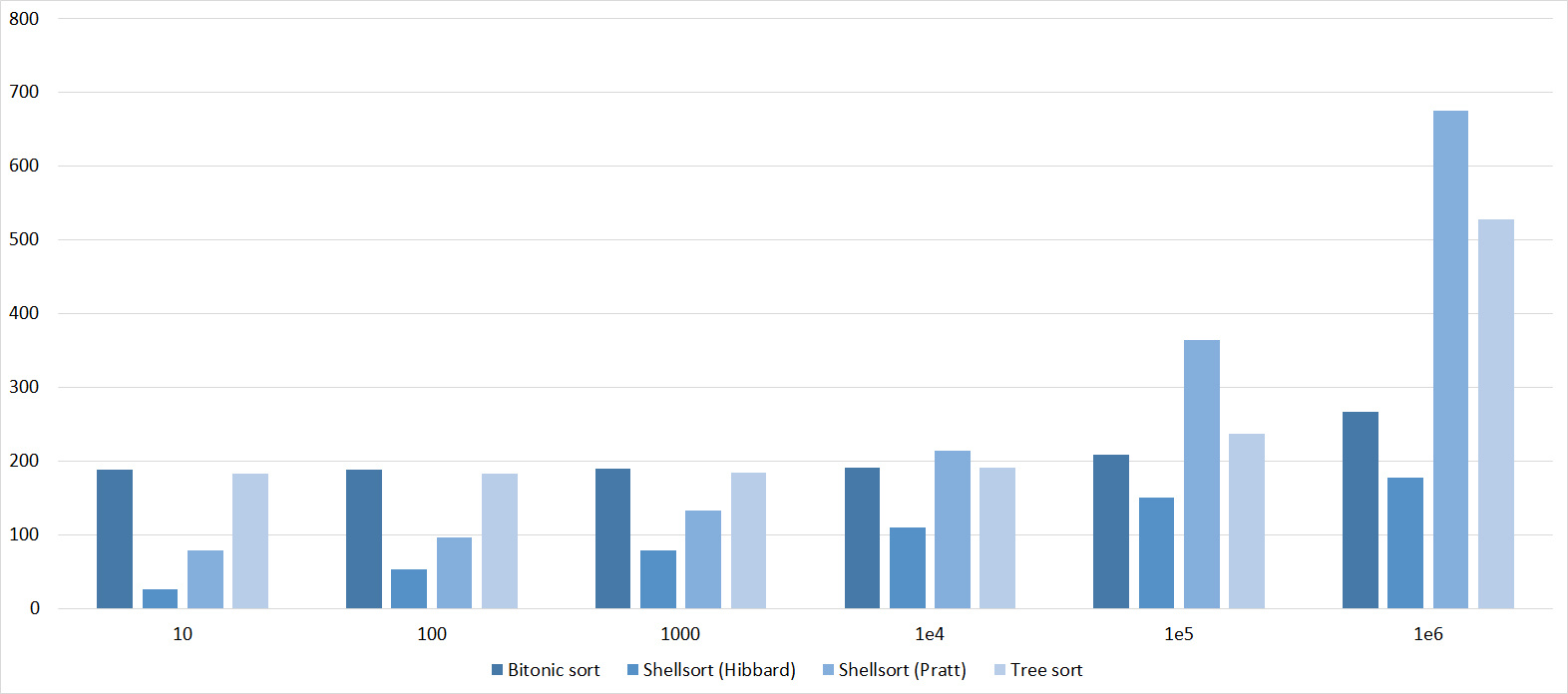

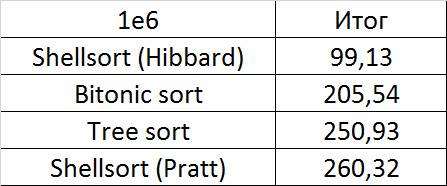
Tables, 1e7 elements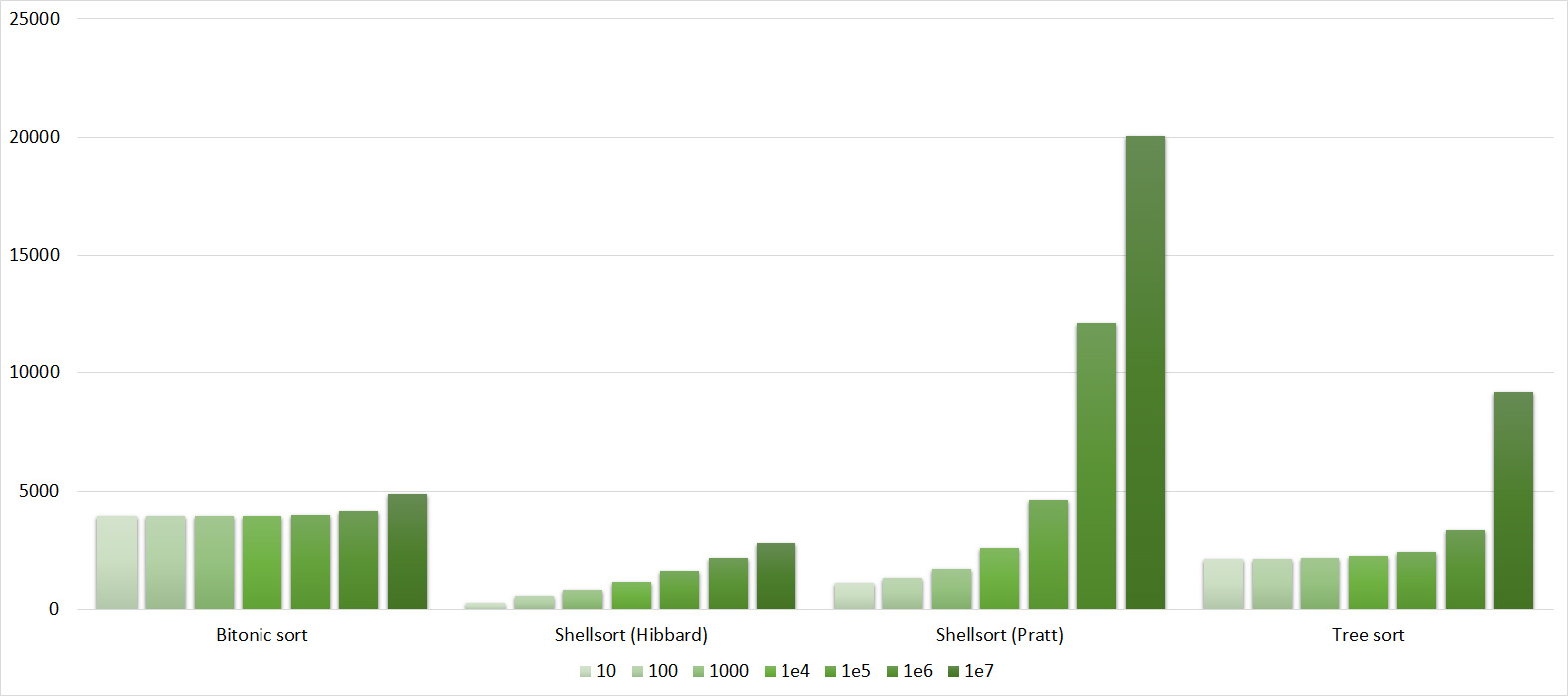

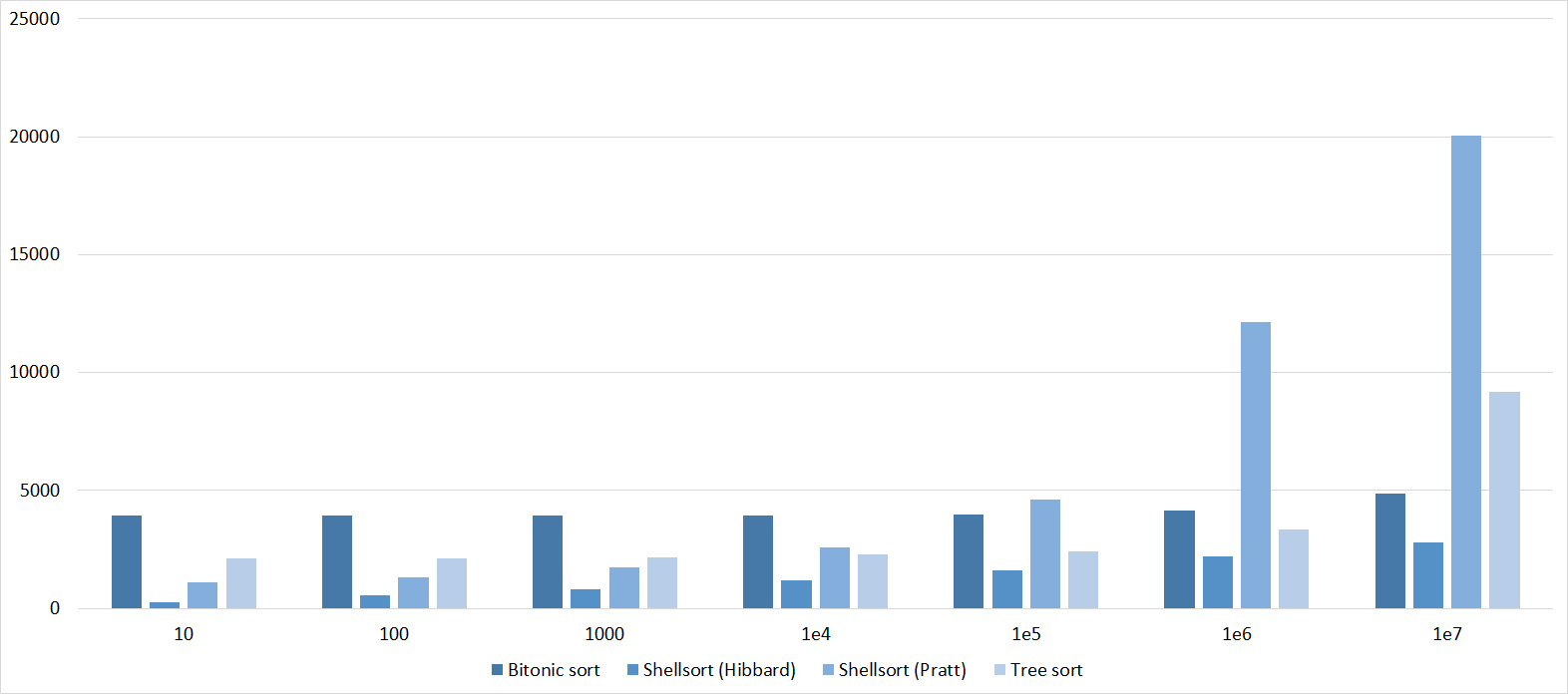

Everything here is similar to the previous group.
Repetitions
Tables, 1-6 elements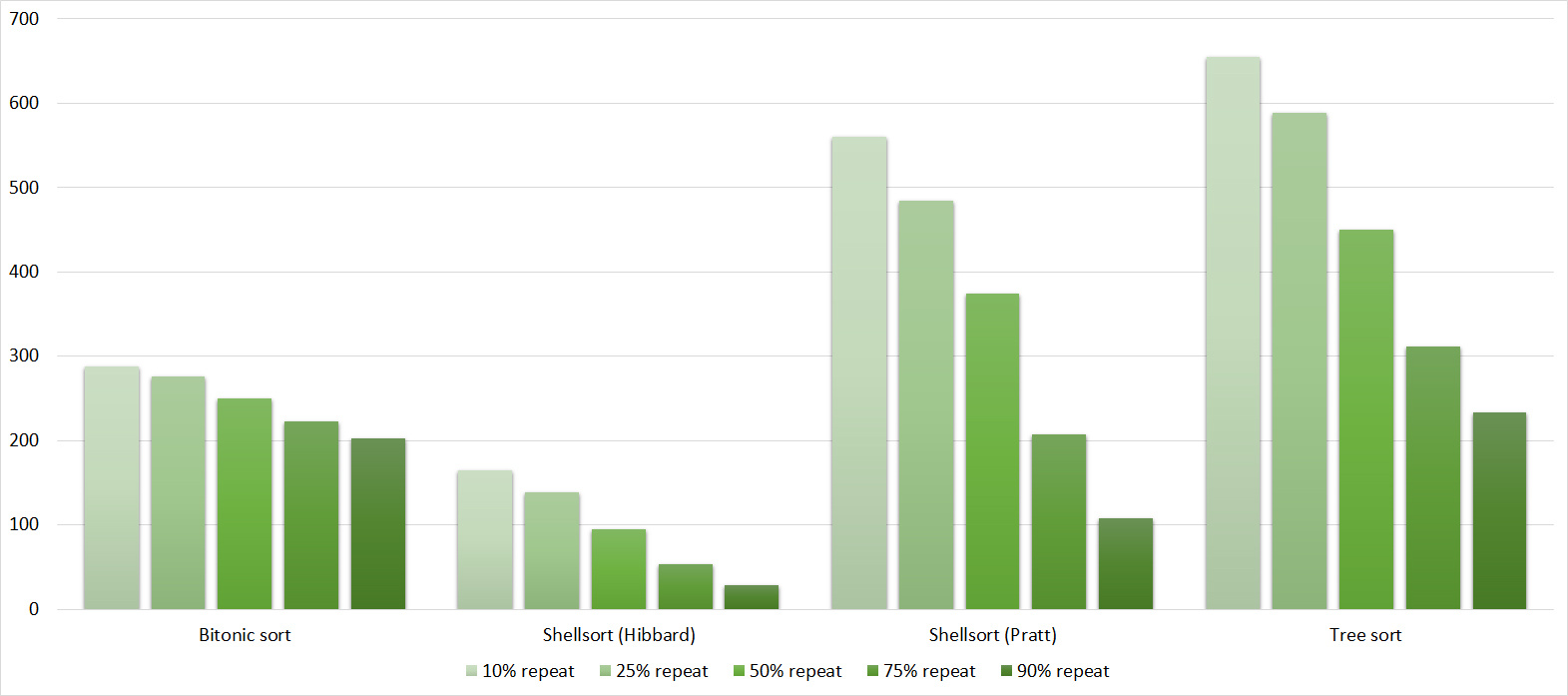
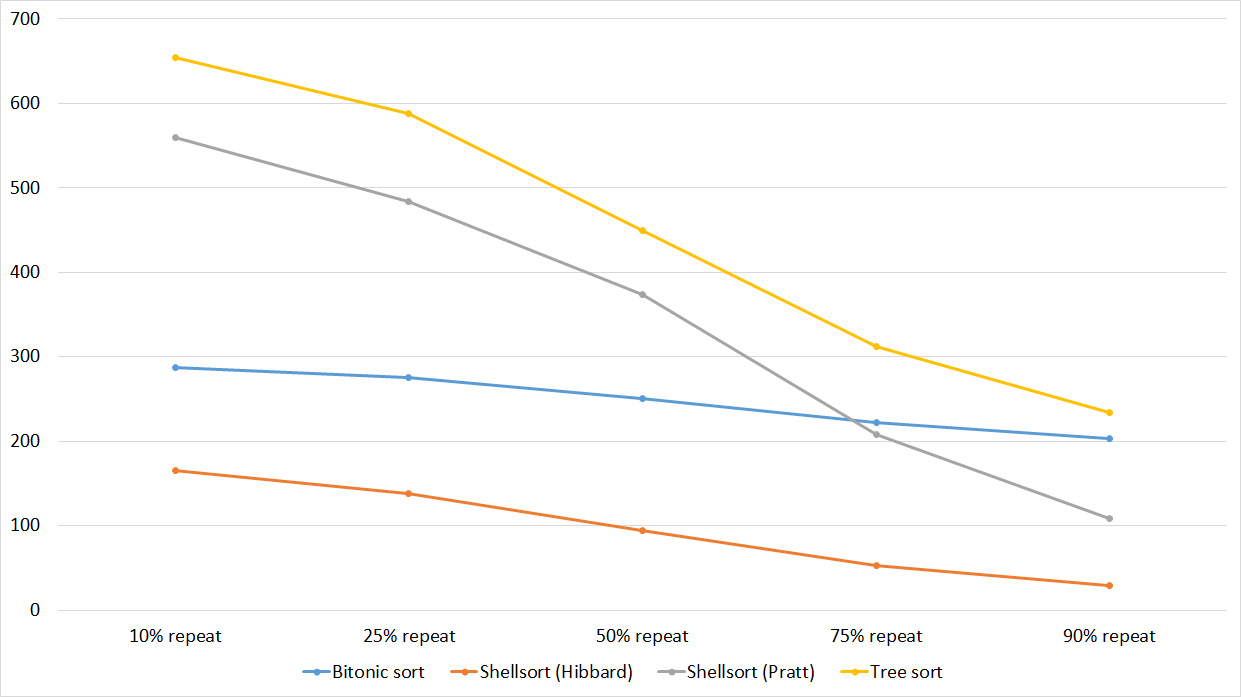


Again, all sortings showed amazing balance, even bitonic, which, it would seem, is almost independent of the array.
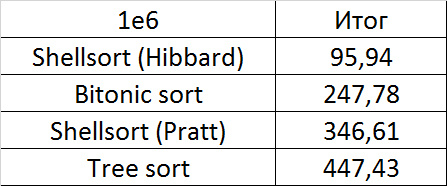
Tables, 1e7 elements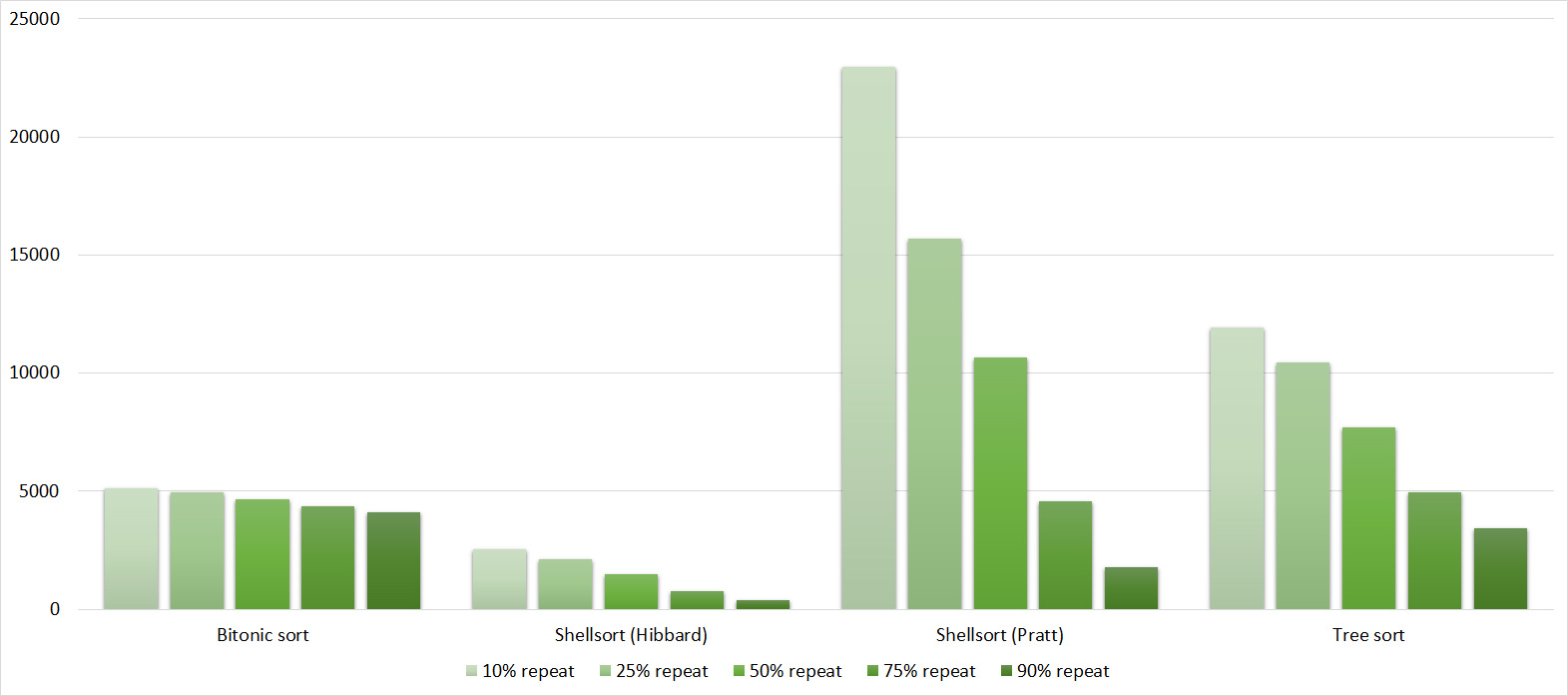
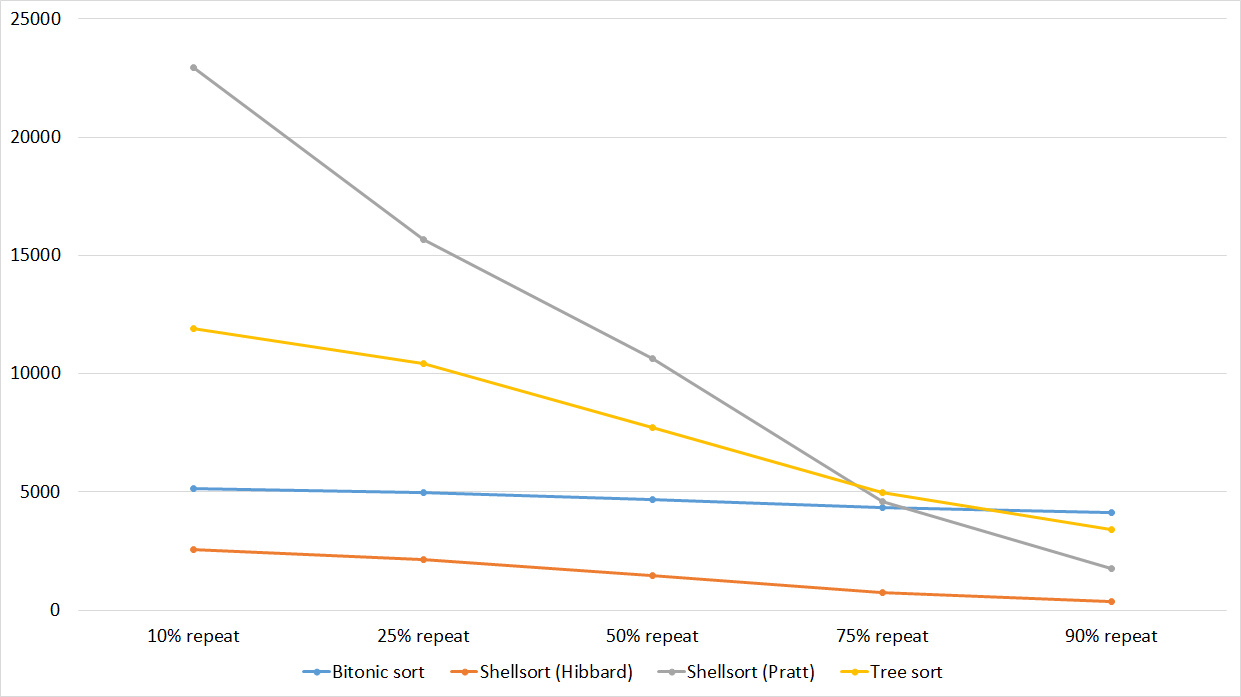
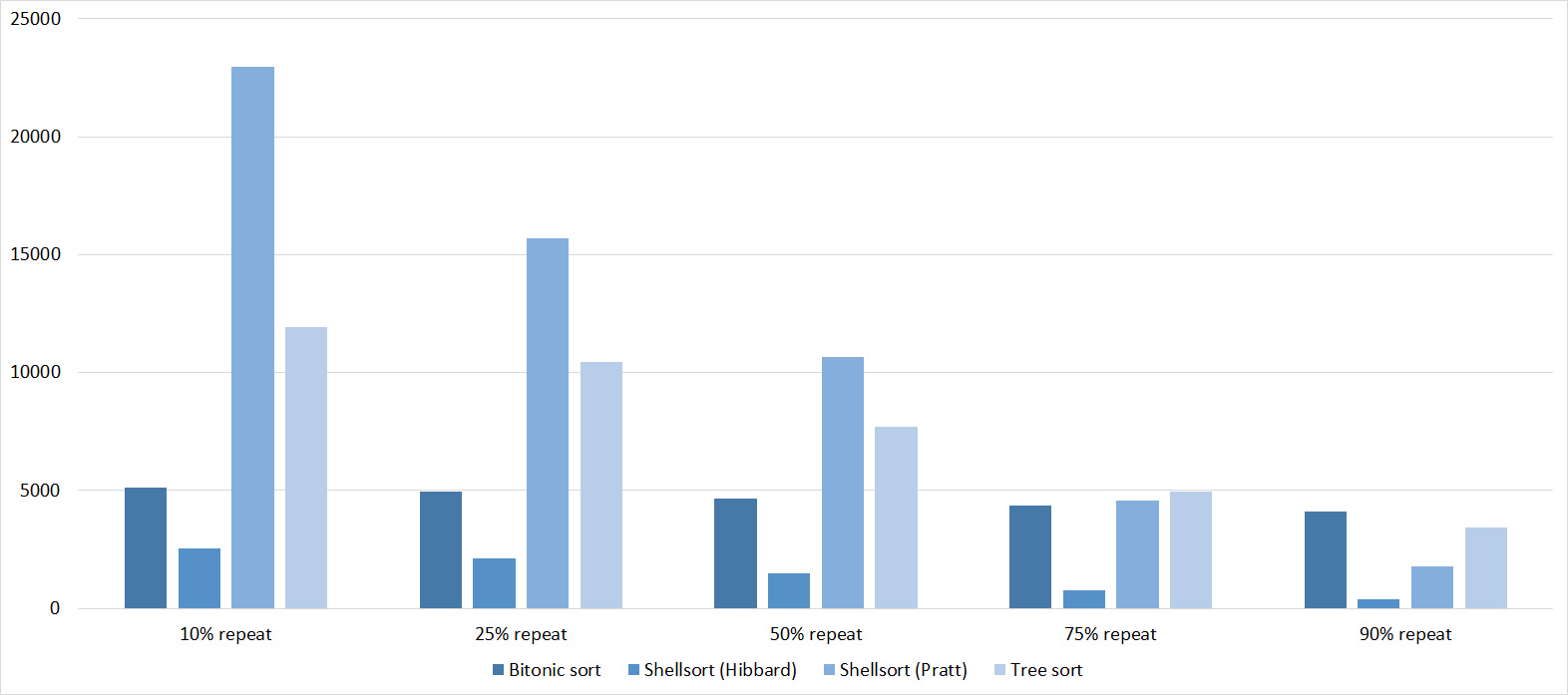

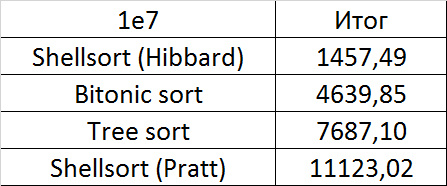
Nothing interesting.
Final results
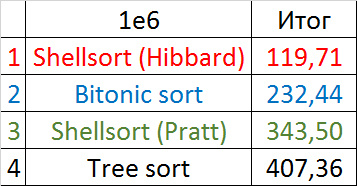
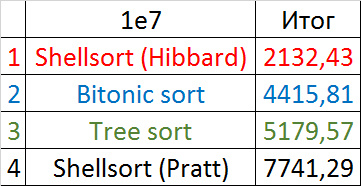
A convincing first place went to Shell's sorting by Hibbard, not yielding in any intermediate group. Perhaps it was worth sending her to the first group of sortings, but ... she is too weak for this, and then almost no one would be in the group. Biton sorting pretty confidently took second place. The third place with a million elements was taken by another sorting by Shell, and with ten million sortings by a tree (asymptotic behavior affected). It is worth noting that with a tenfold increase in the size of the input data, all algorithms, except for tree sorting, slowed down by almost 20 times, and the last only 13.
Third Sort Group
Array of random numbers
Tables, 1e7 elements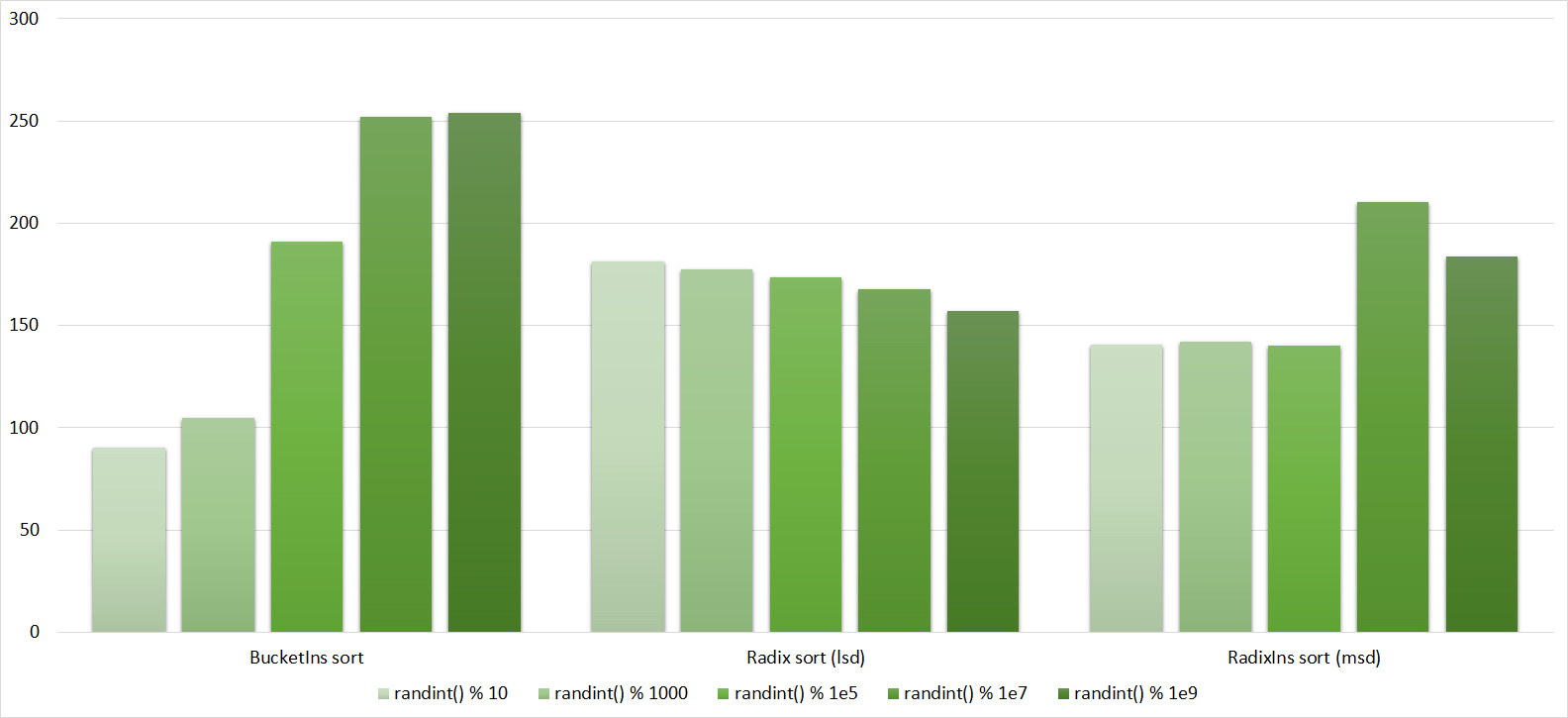

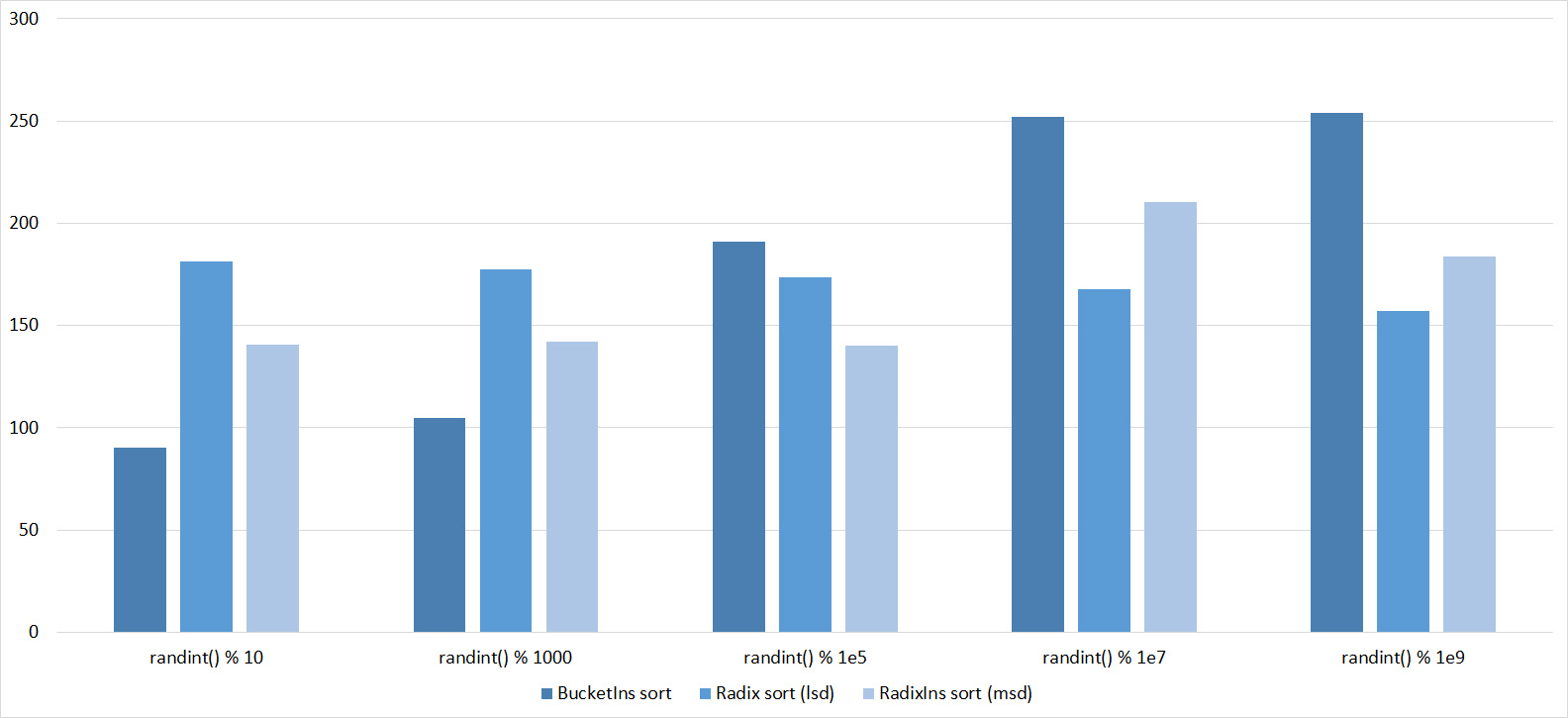
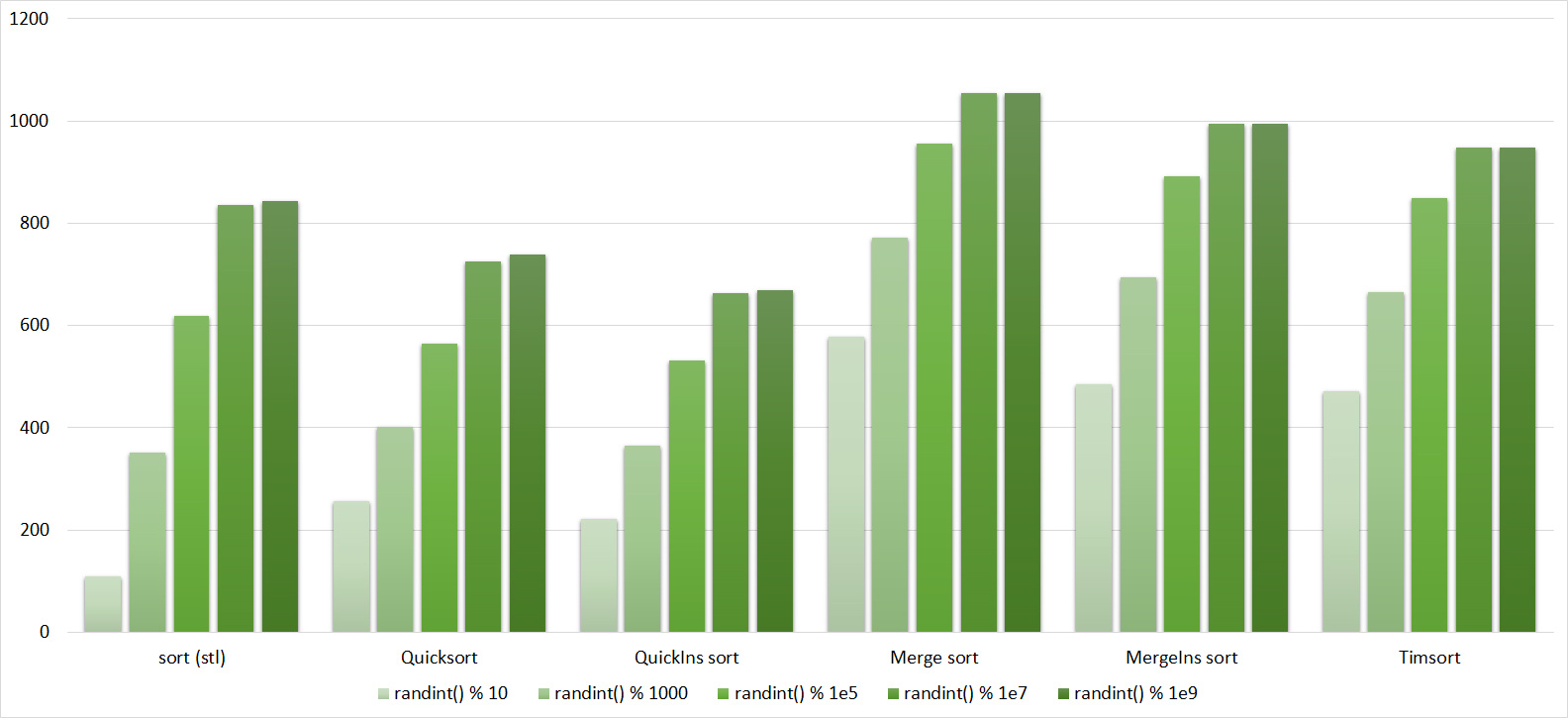
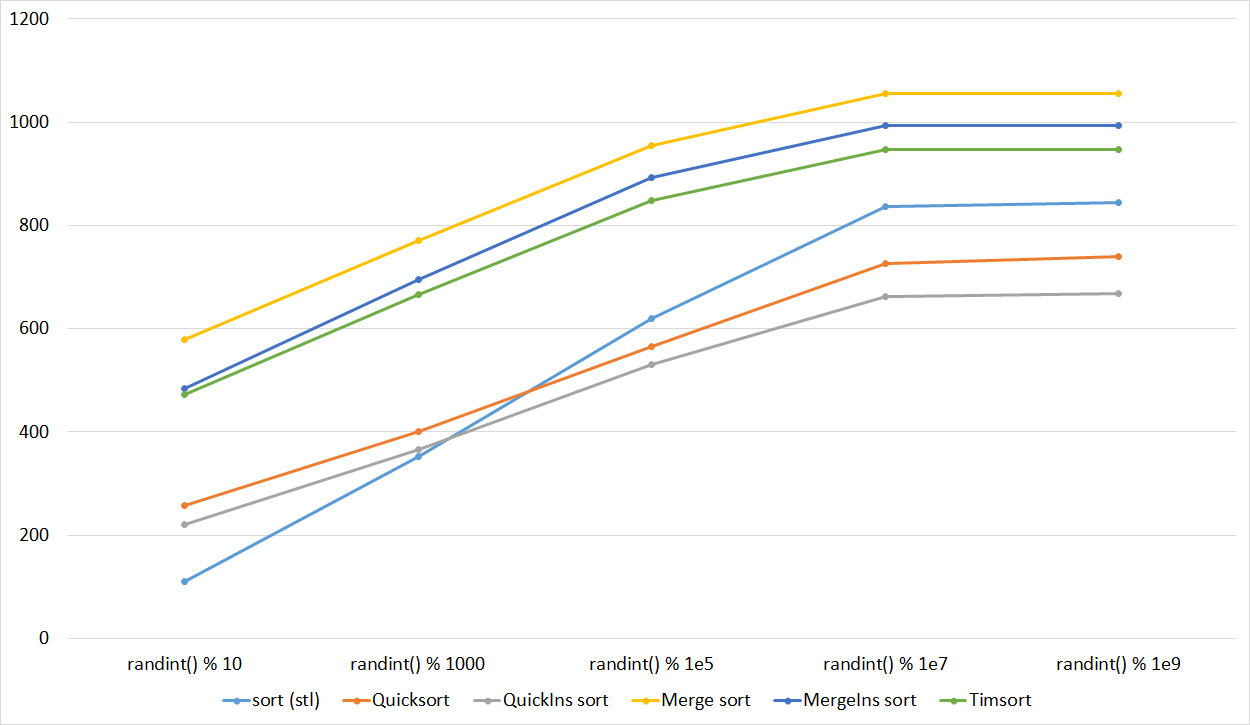
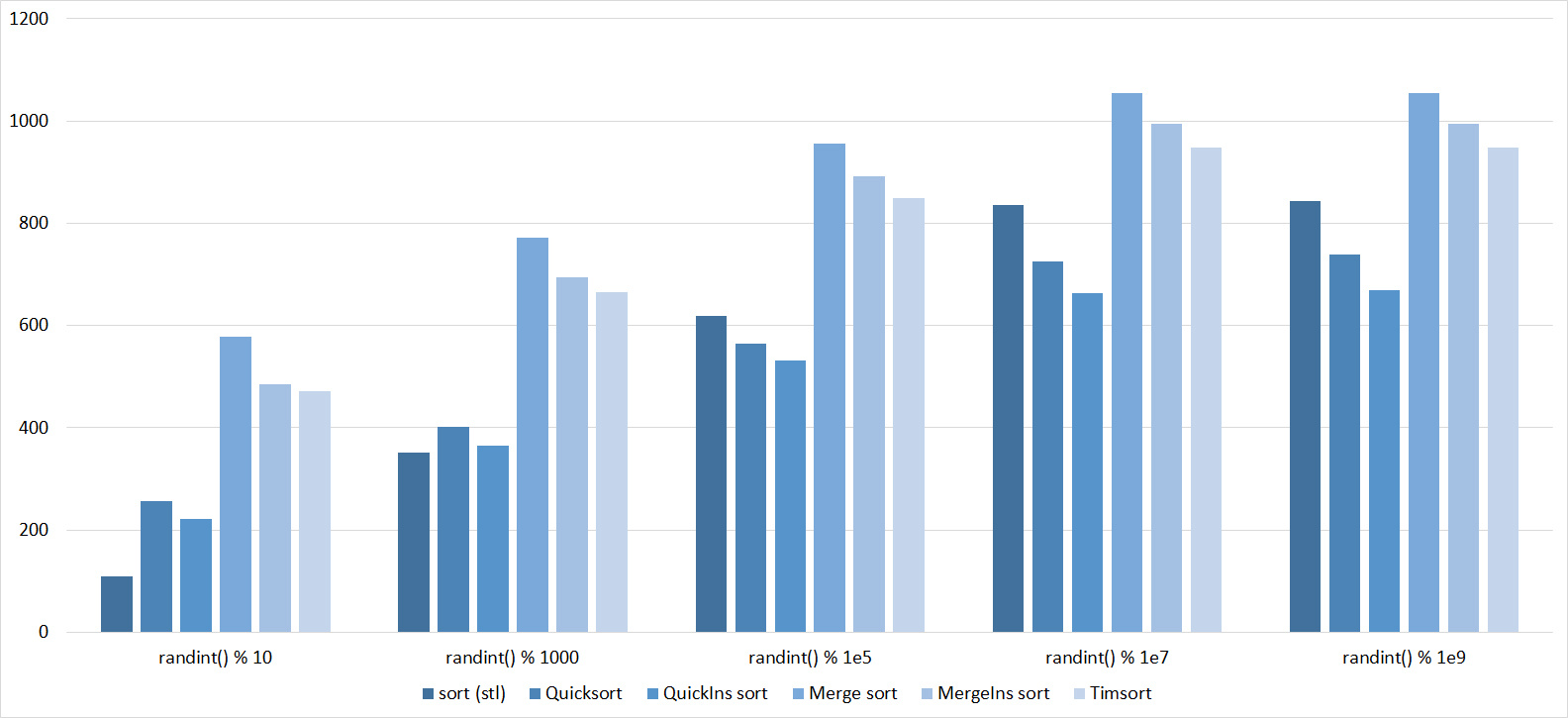
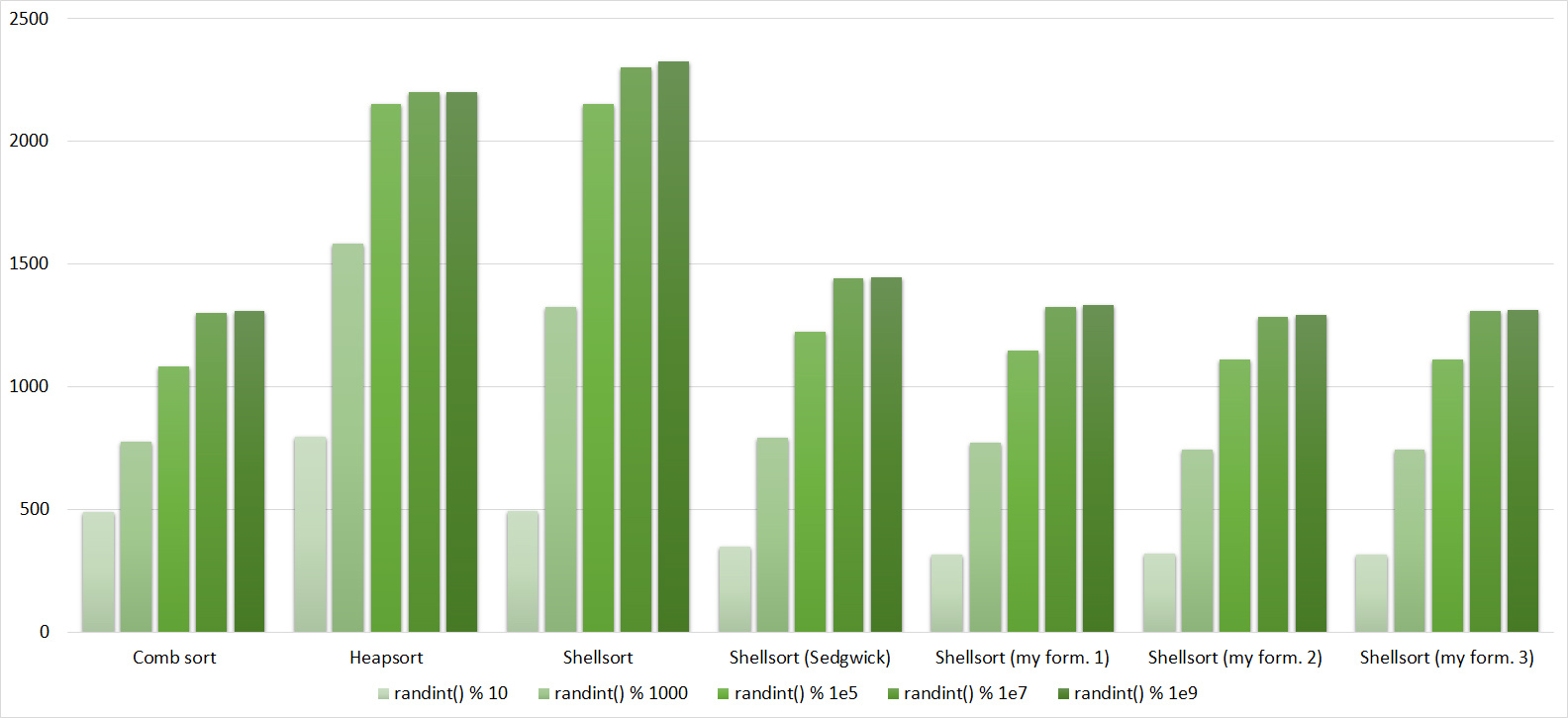
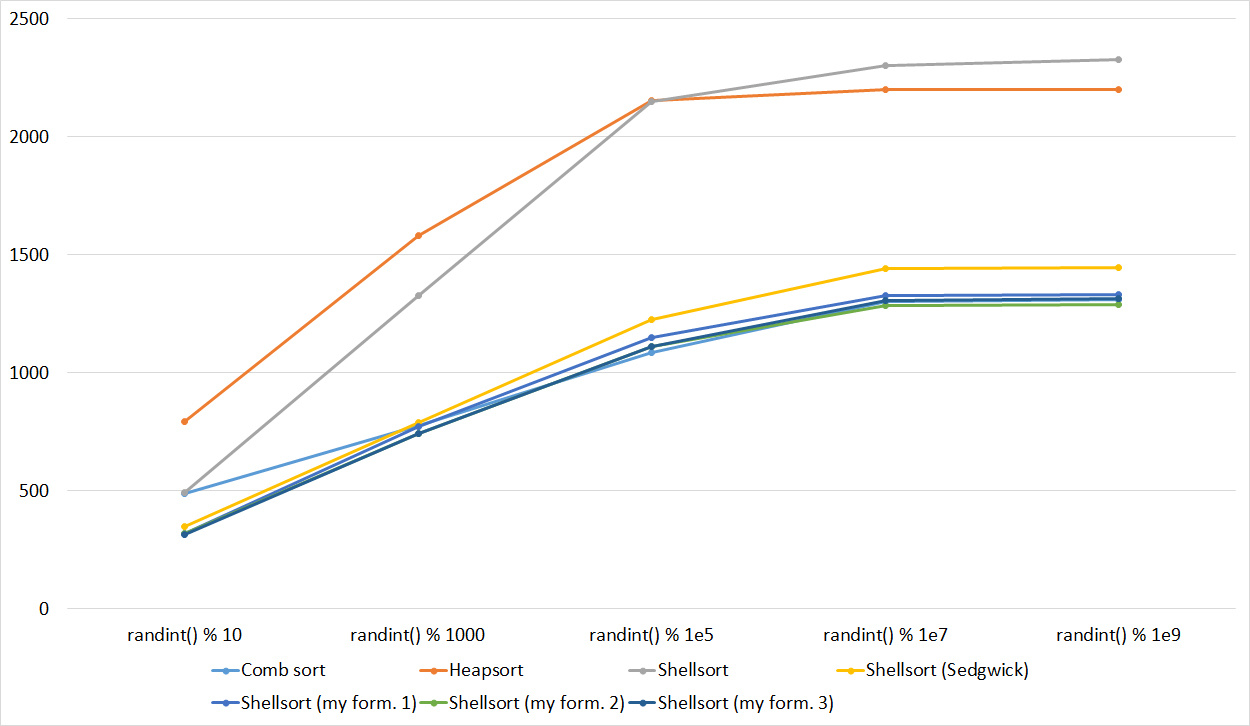
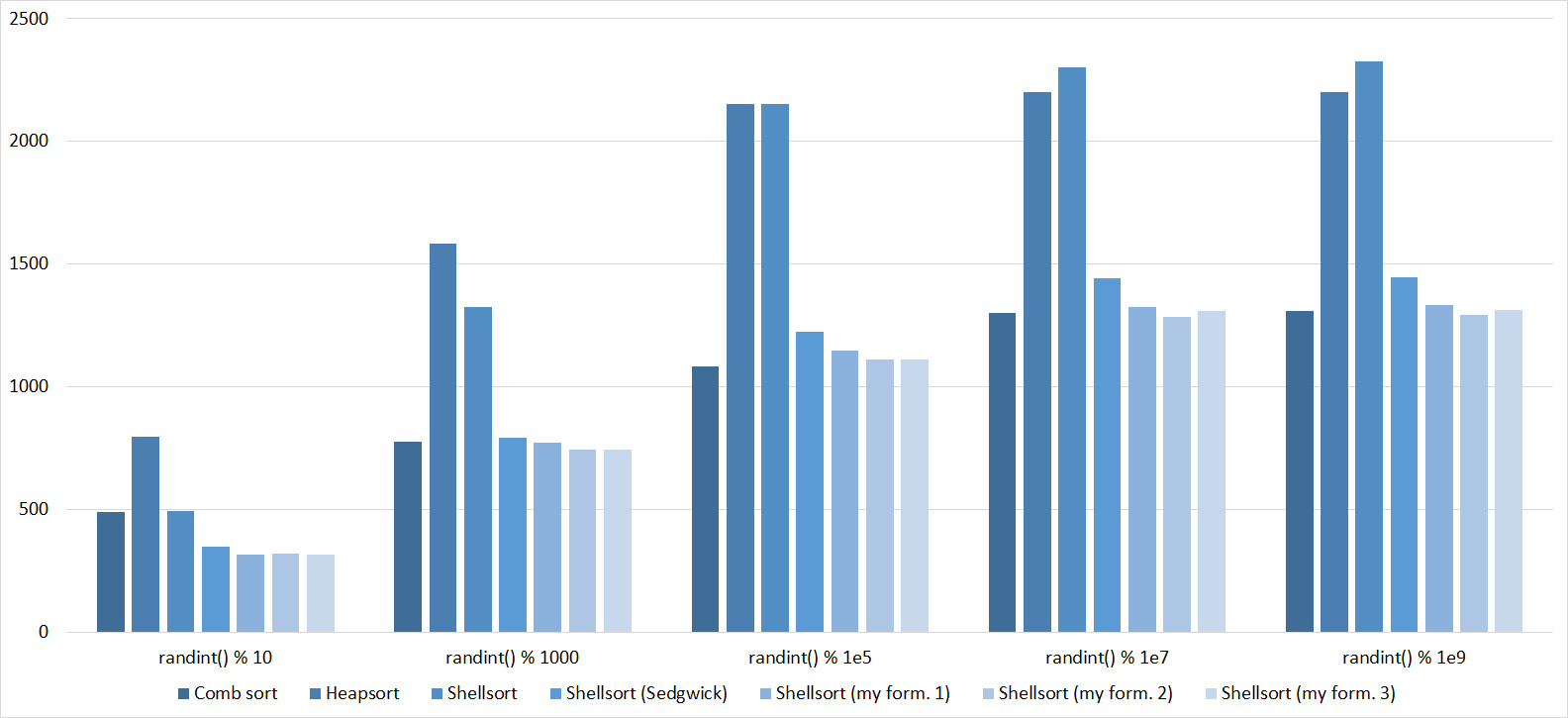
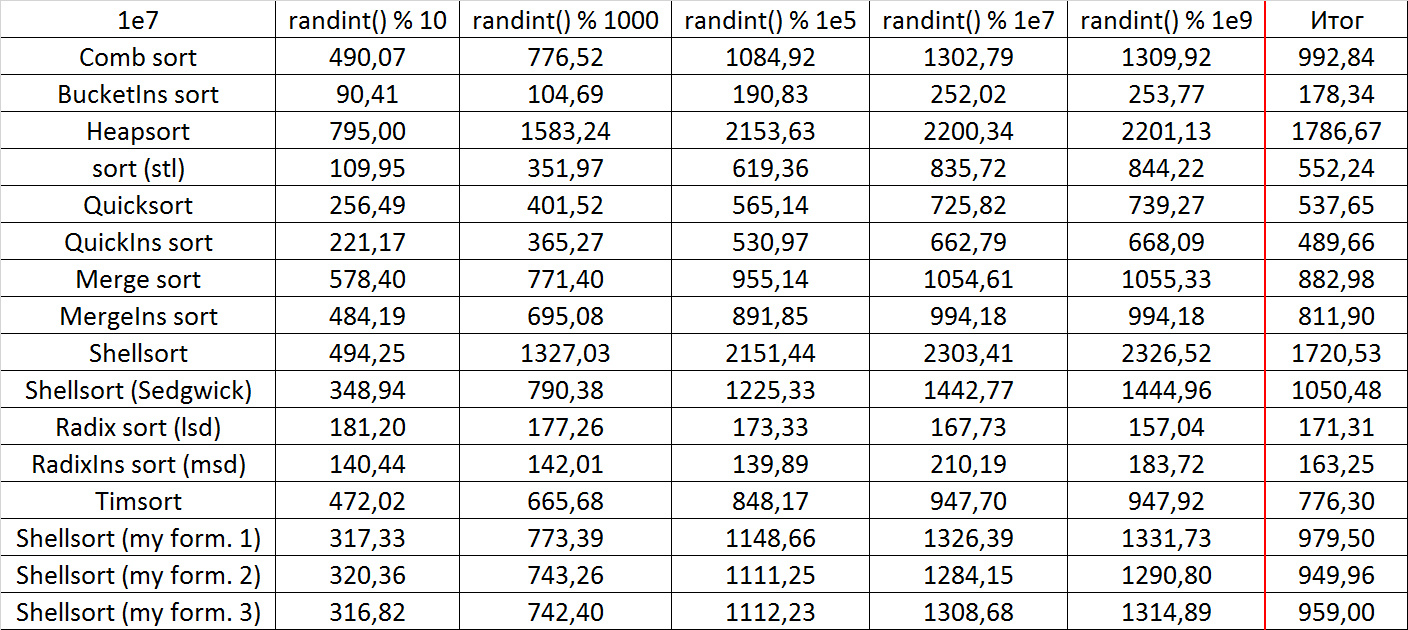
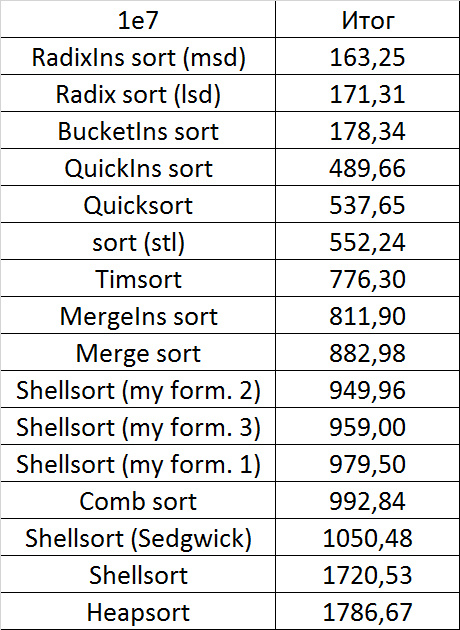
Tables, 1e8 elements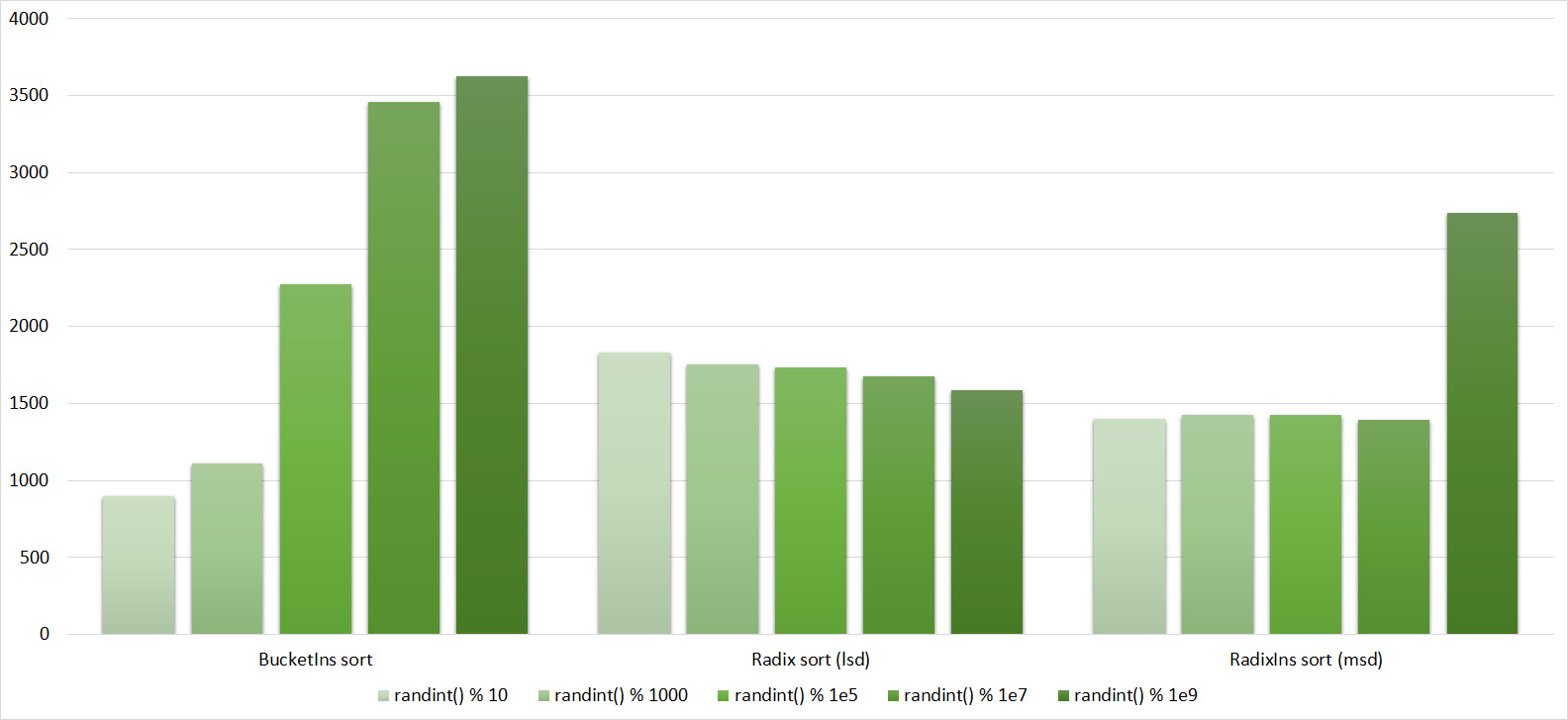

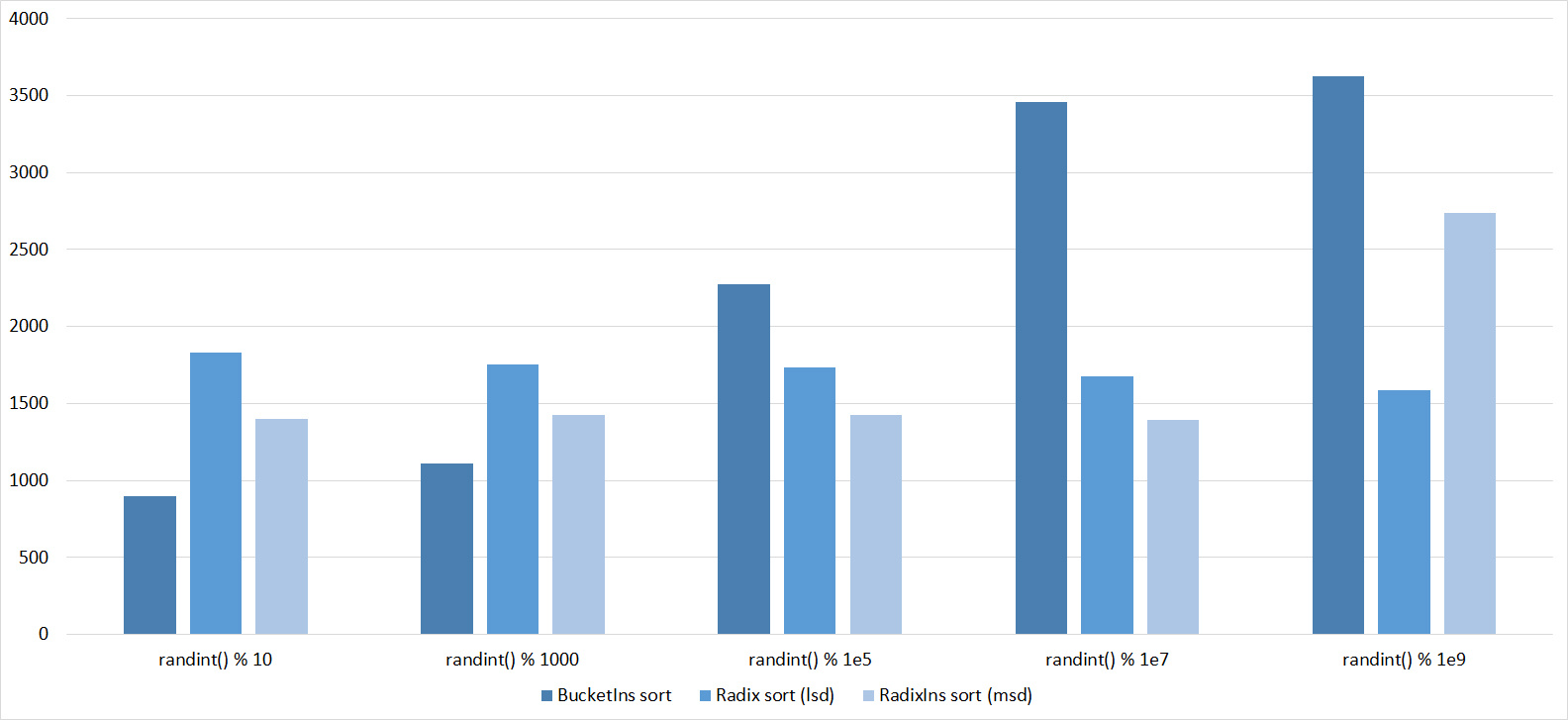

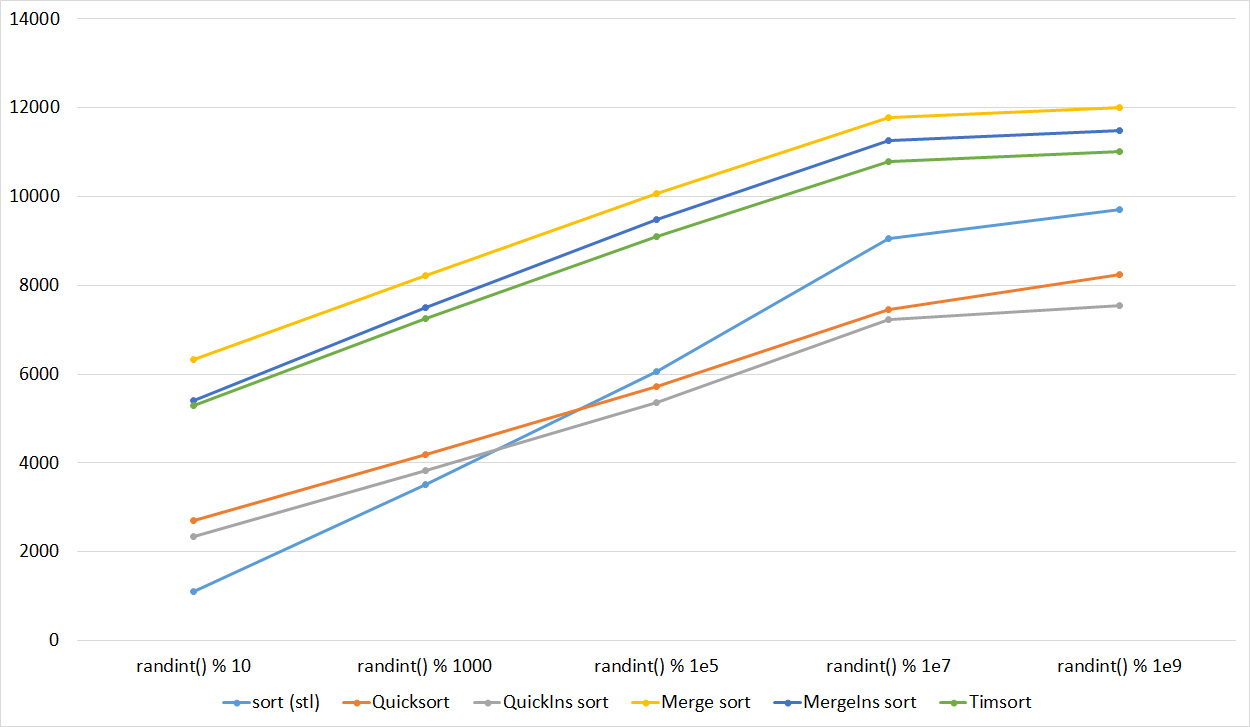
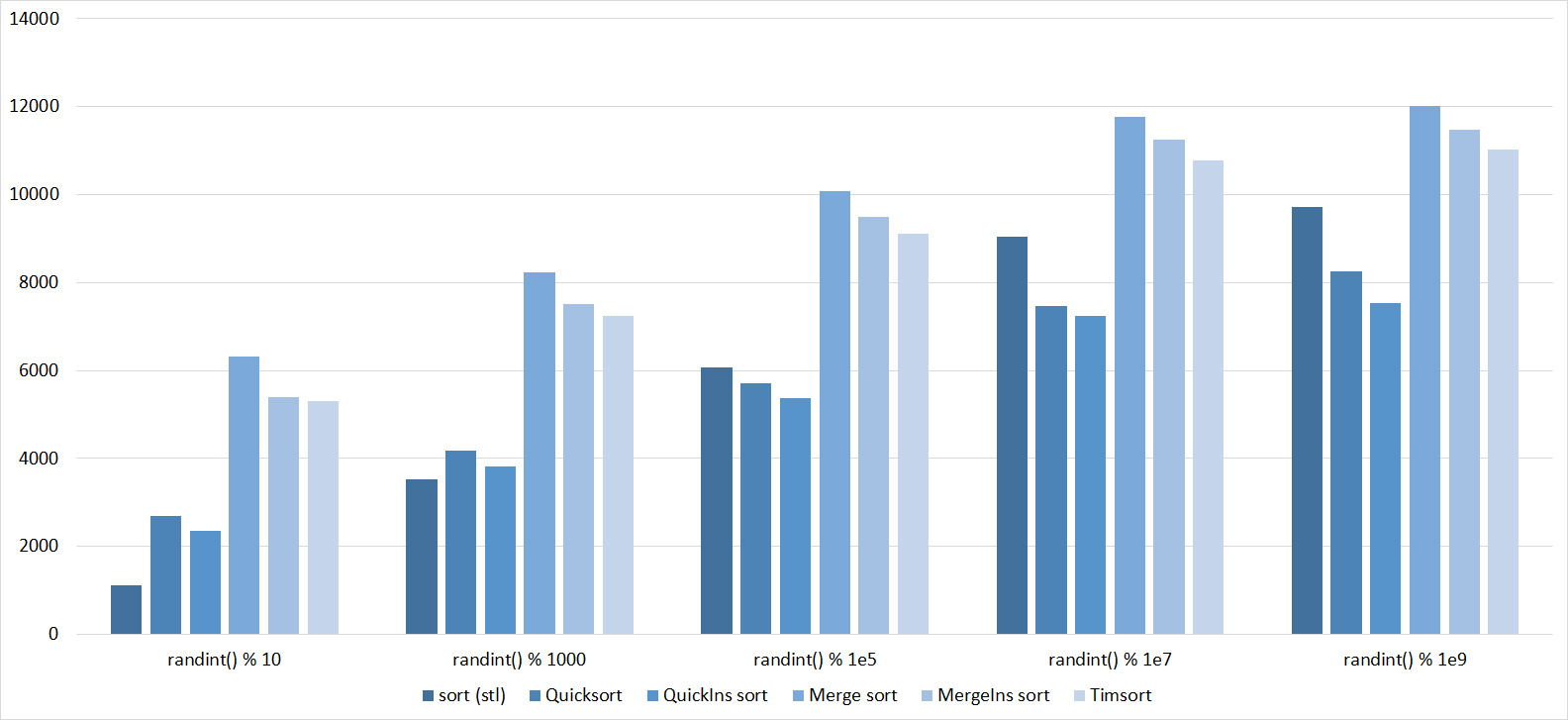
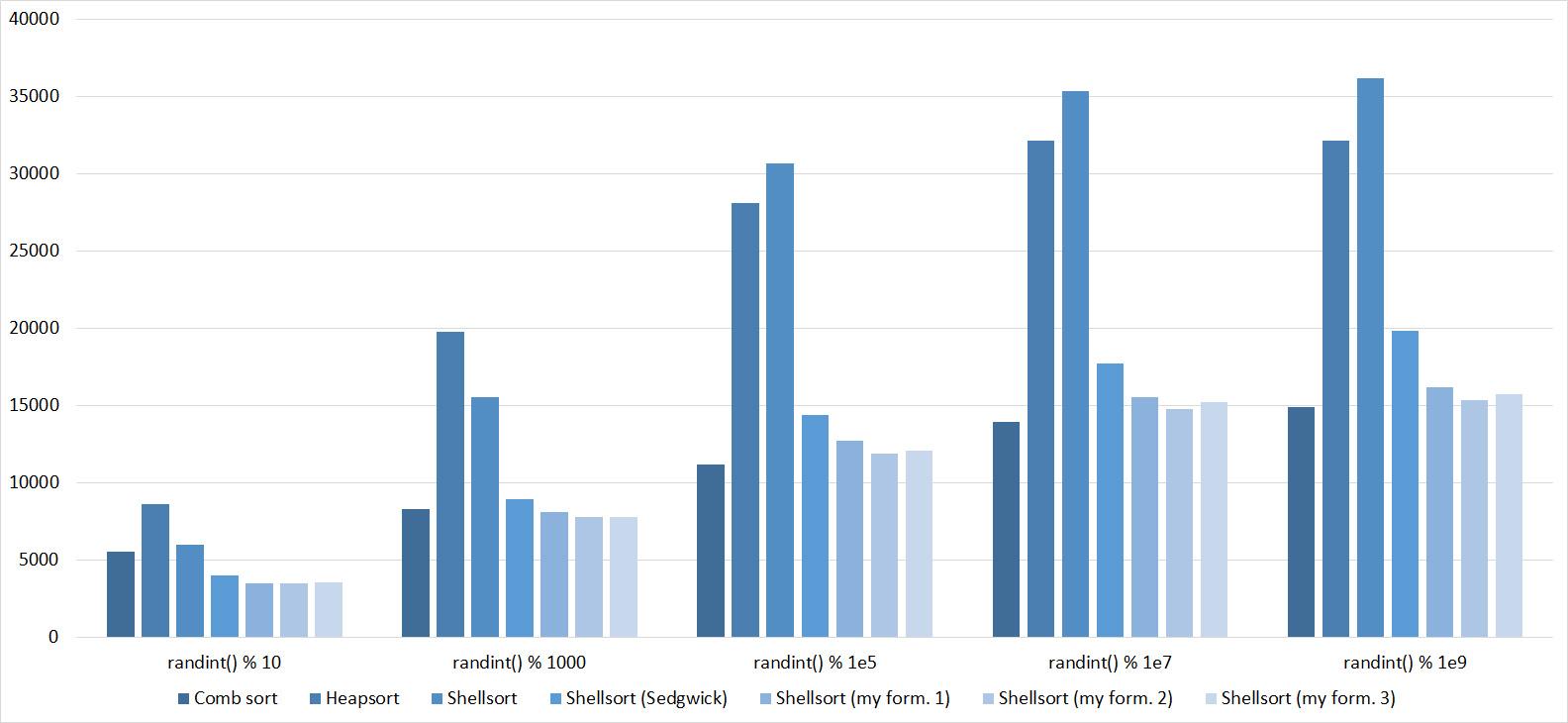
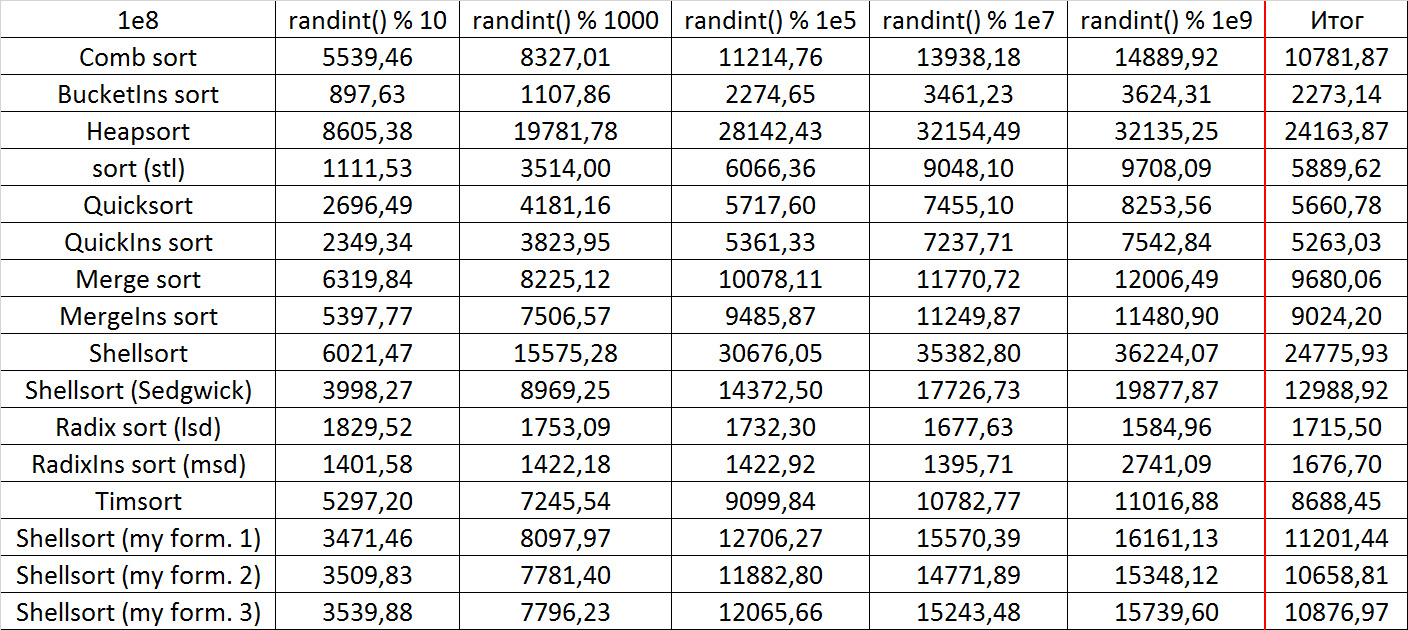
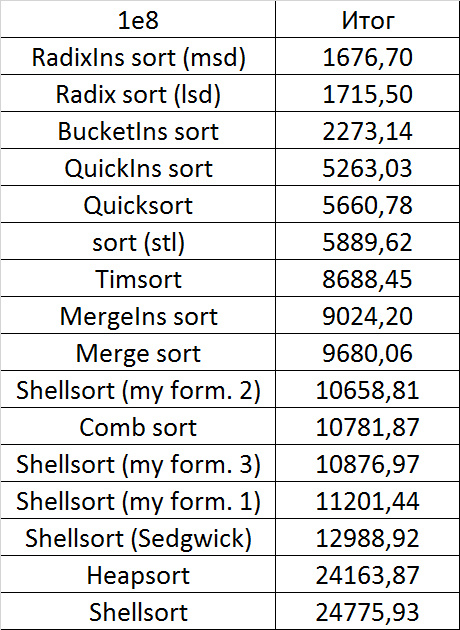
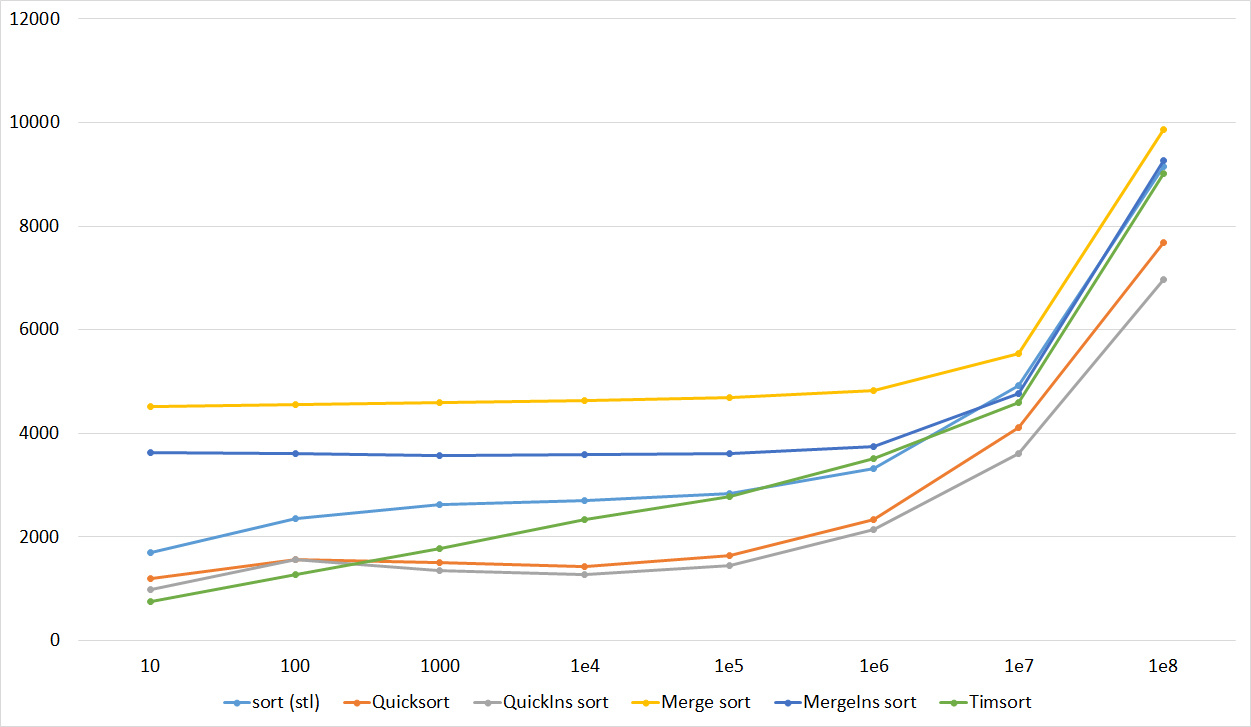
Almost all sortings of this group have almost the same dynamics. Why are almost all sorts accelerated when the array is partially sorted? Exchange sortings work faster because fewer exchanges are needed, Shell sorting uses insertion sorting, which is greatly accelerated on such arrays, in pyramidal sorting, when elements are inserted, sifting ends immediately, in a merge sorting, at best, half as many comparisons are performed. Block sorting works the better, the smaller the difference between the minimum and maximum element. Only bitwise sorting is fundamentally different, which doesn’t matter. The LSD version works better the larger the module. Dynamics MSD version is not clear to me, the fact that it worked faster than LSD surprised.
Partially Sorted Array
Tables, 1e7 elements


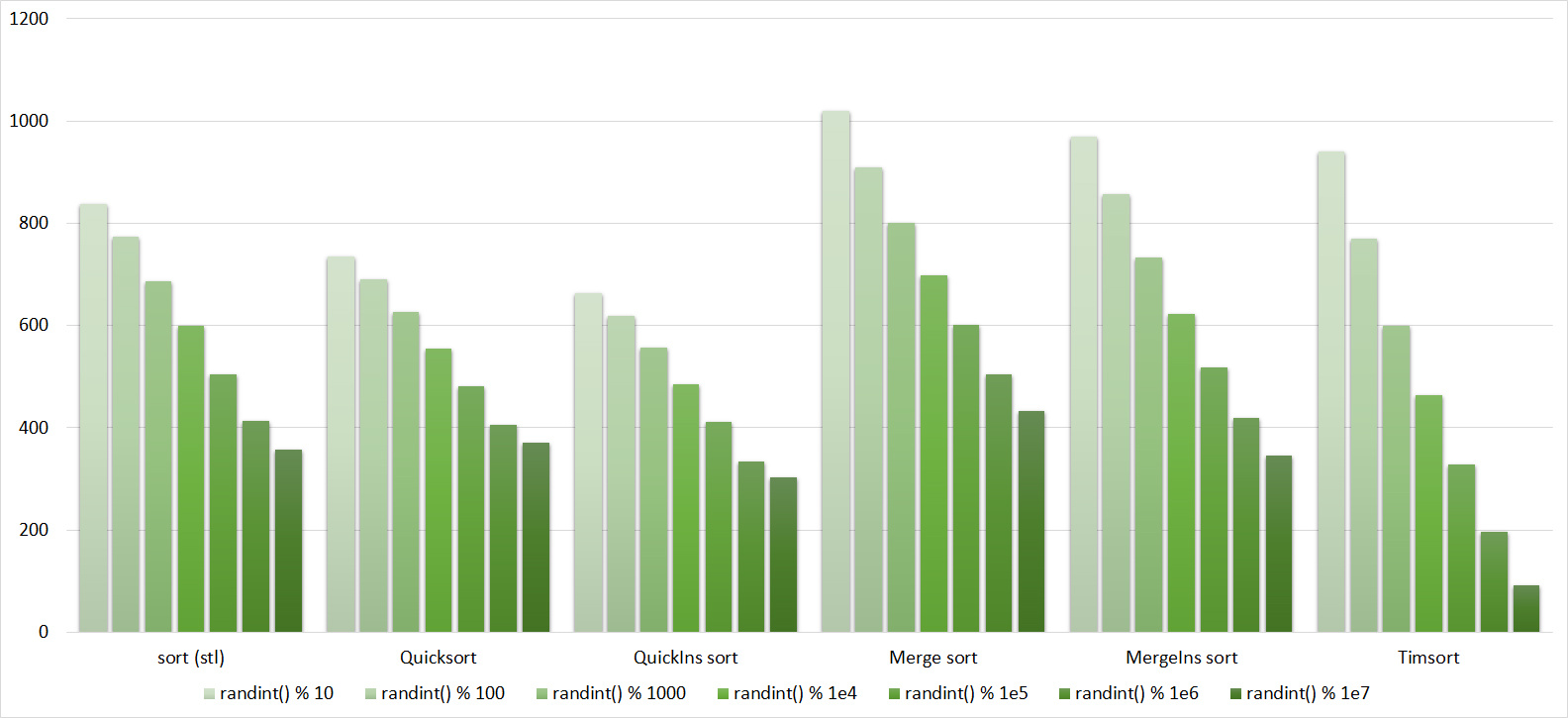
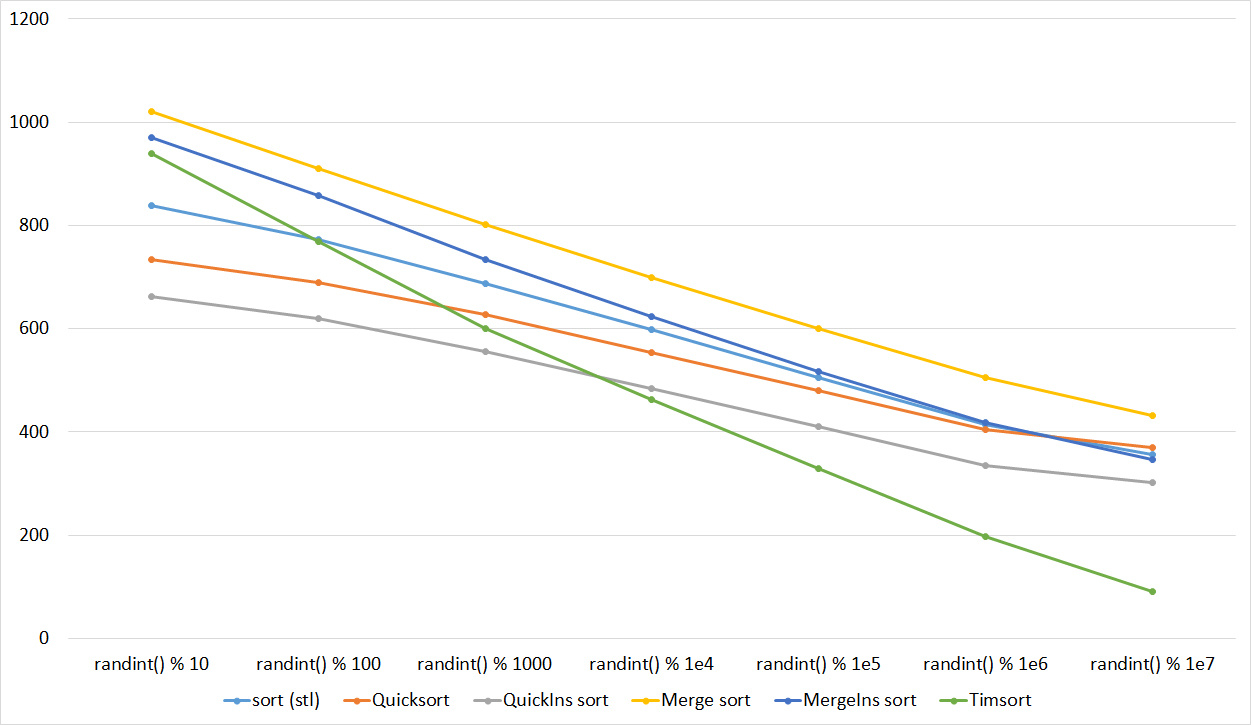
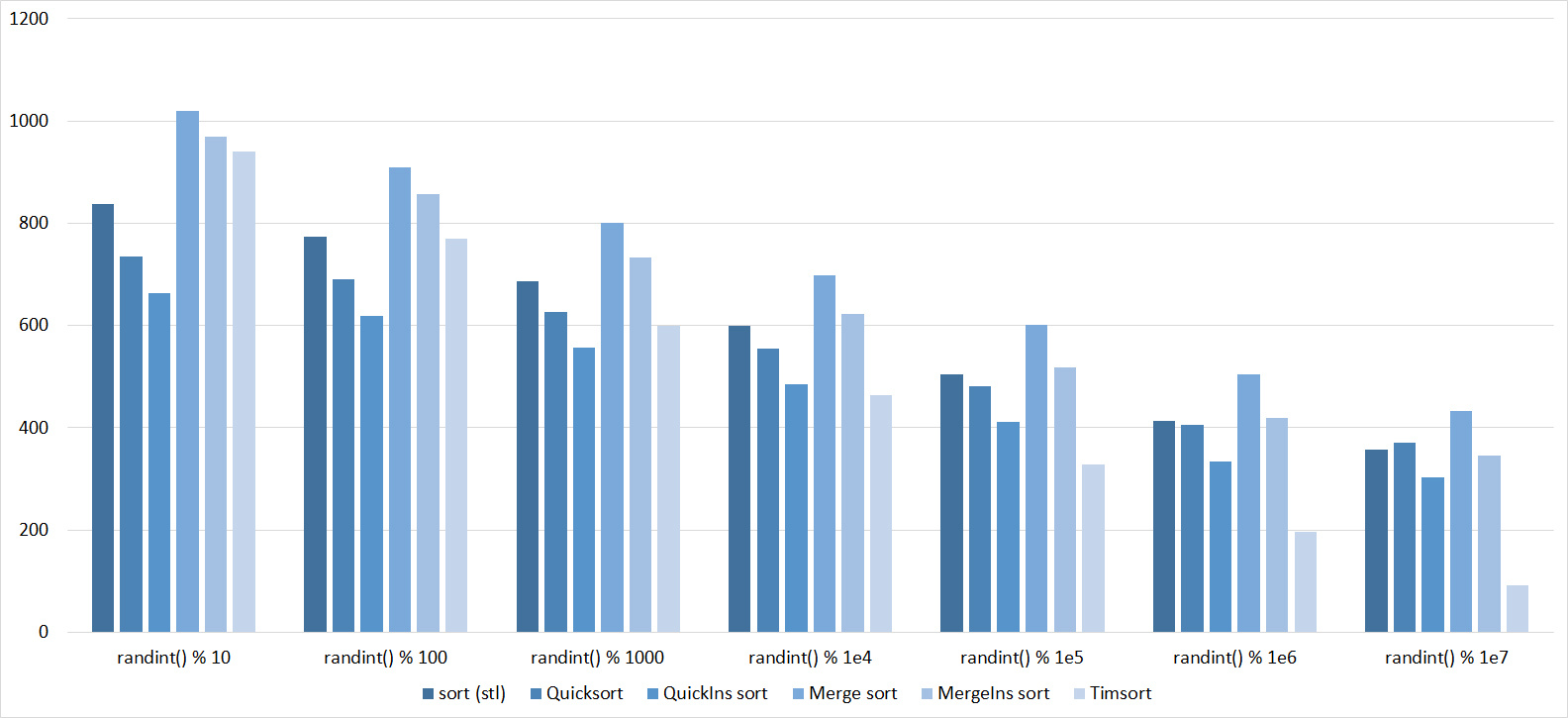
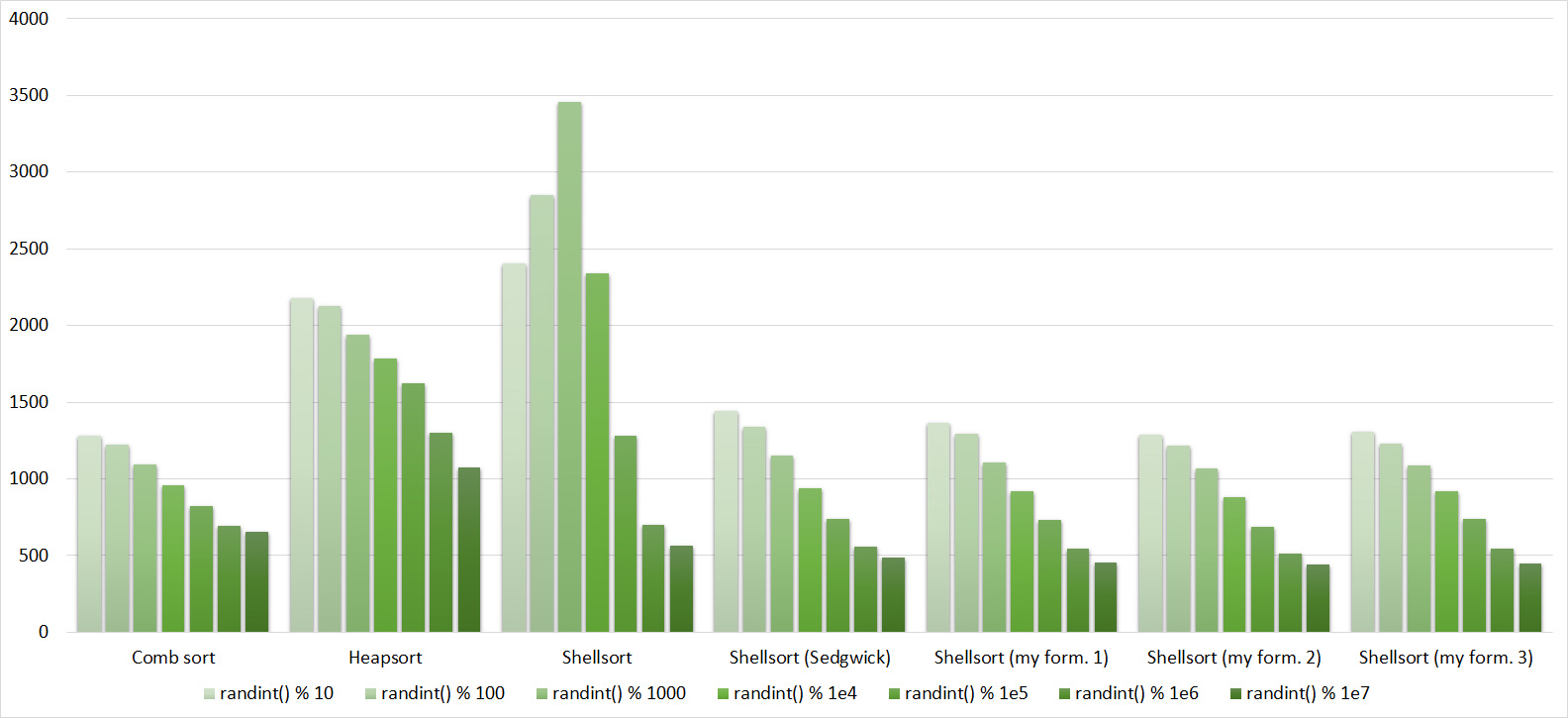




Tables, 1e8 elements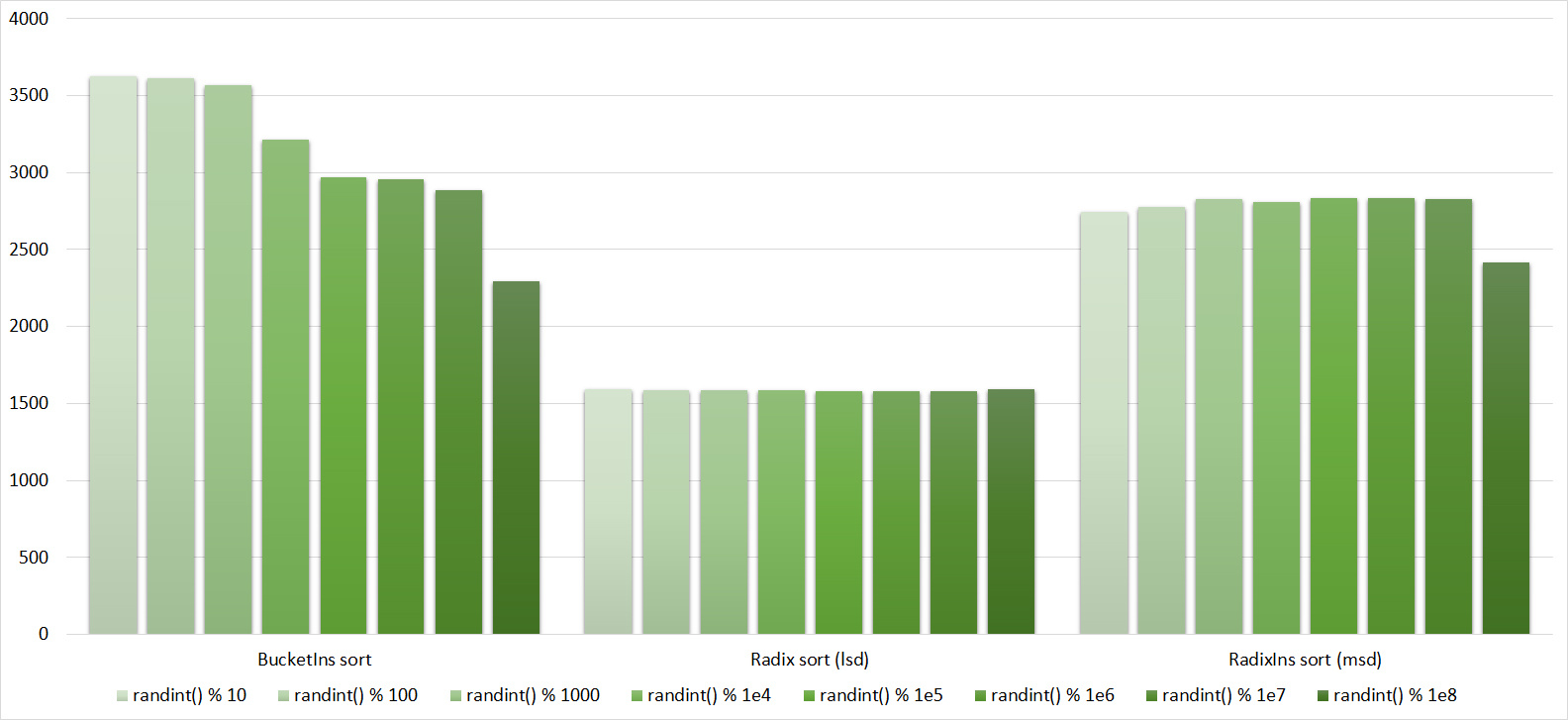
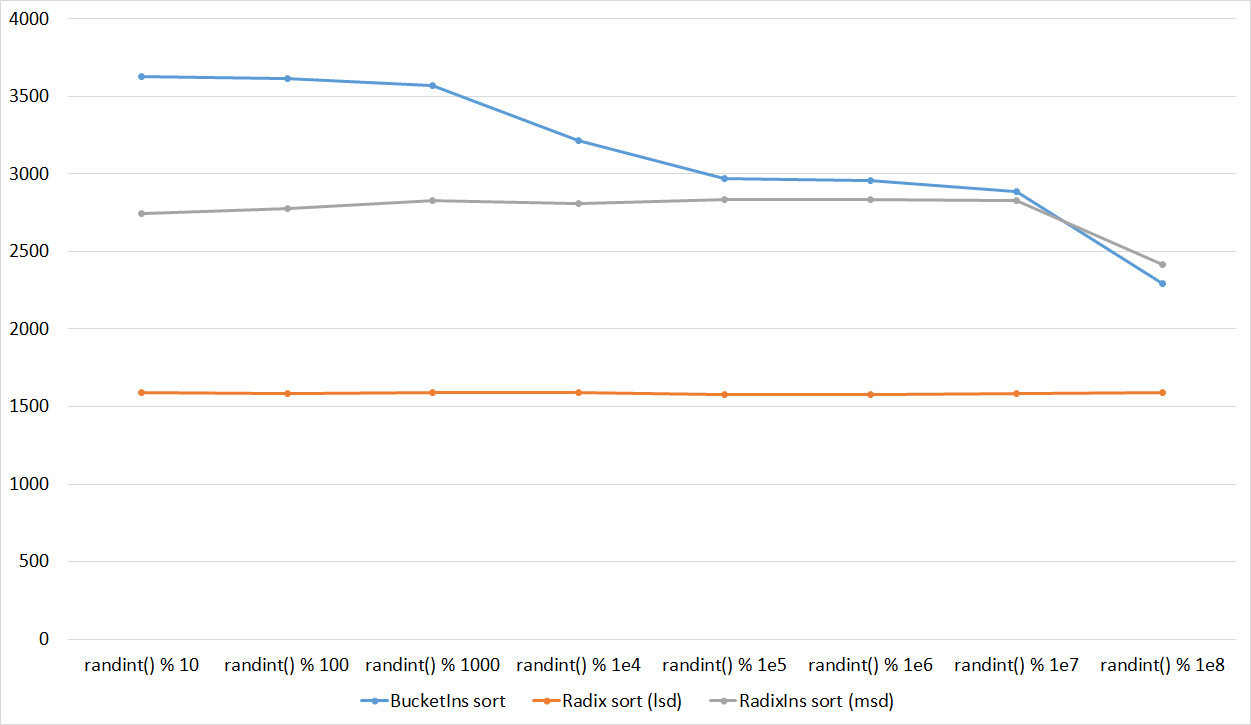
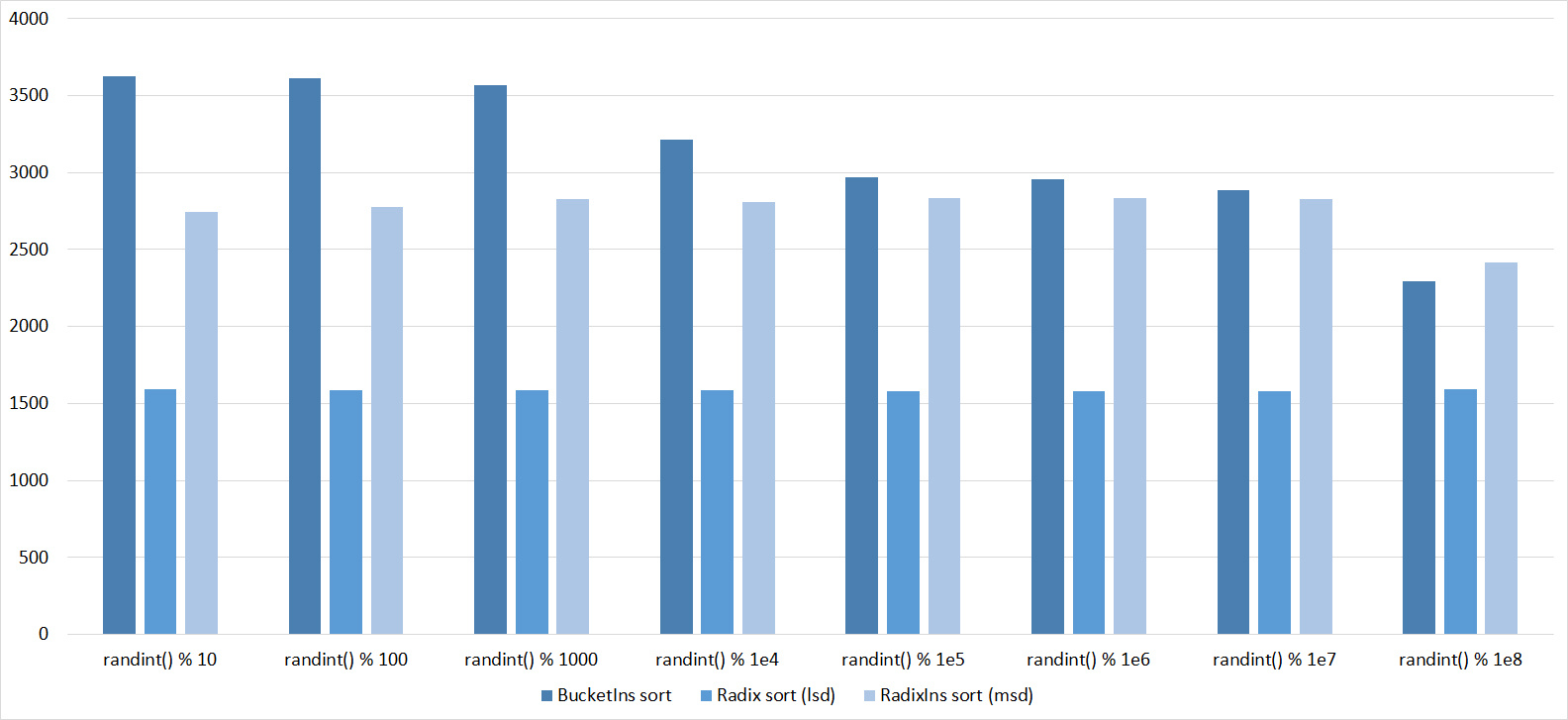
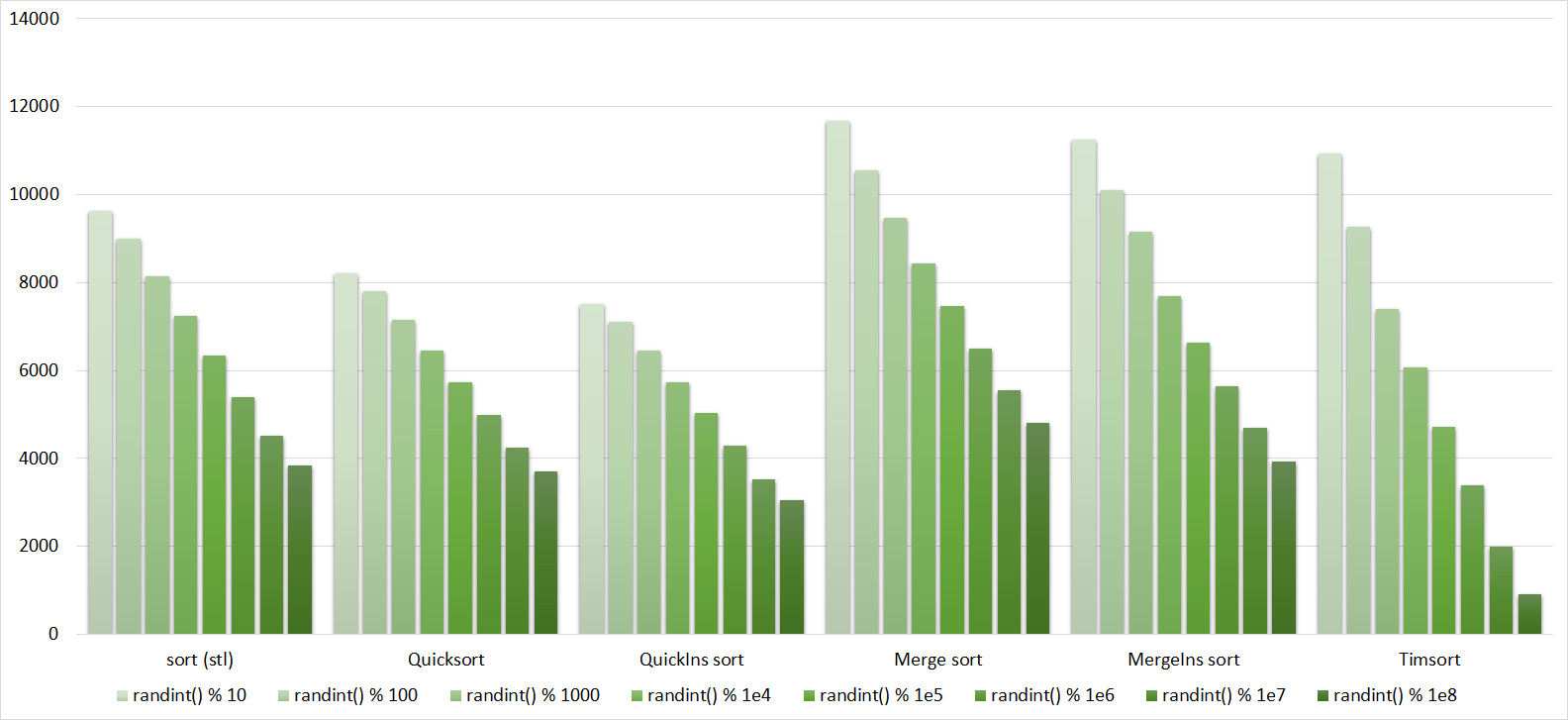
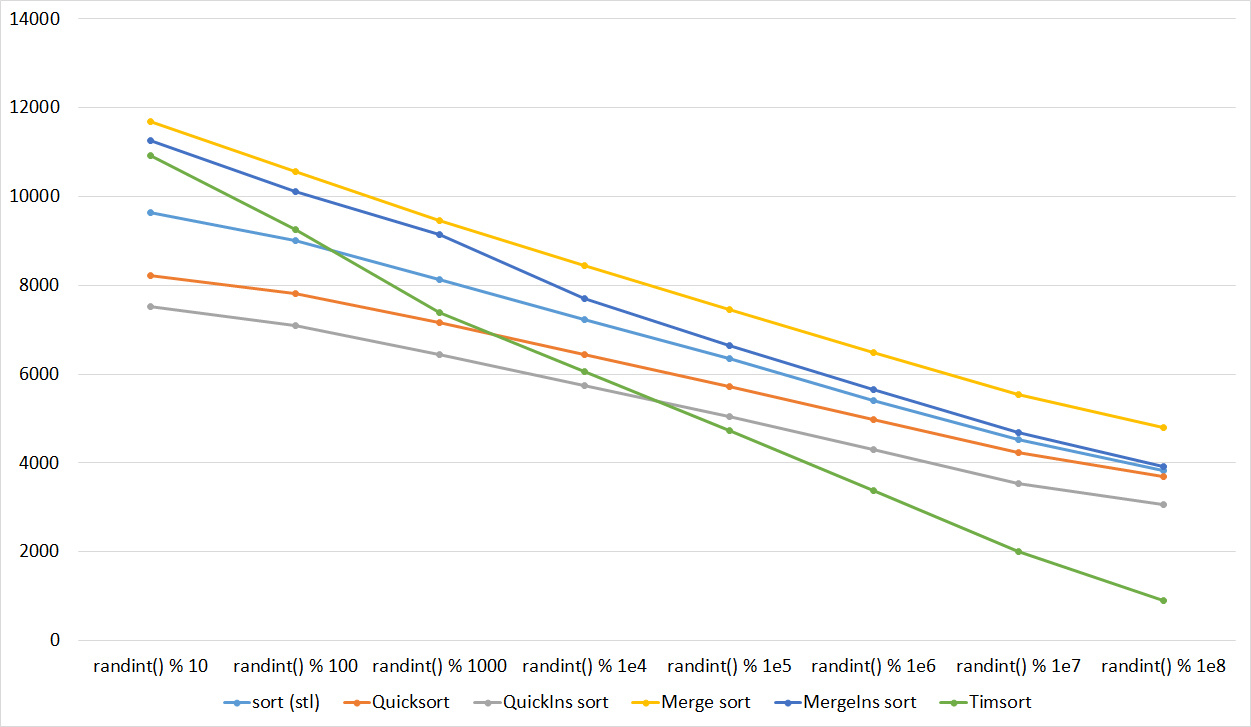
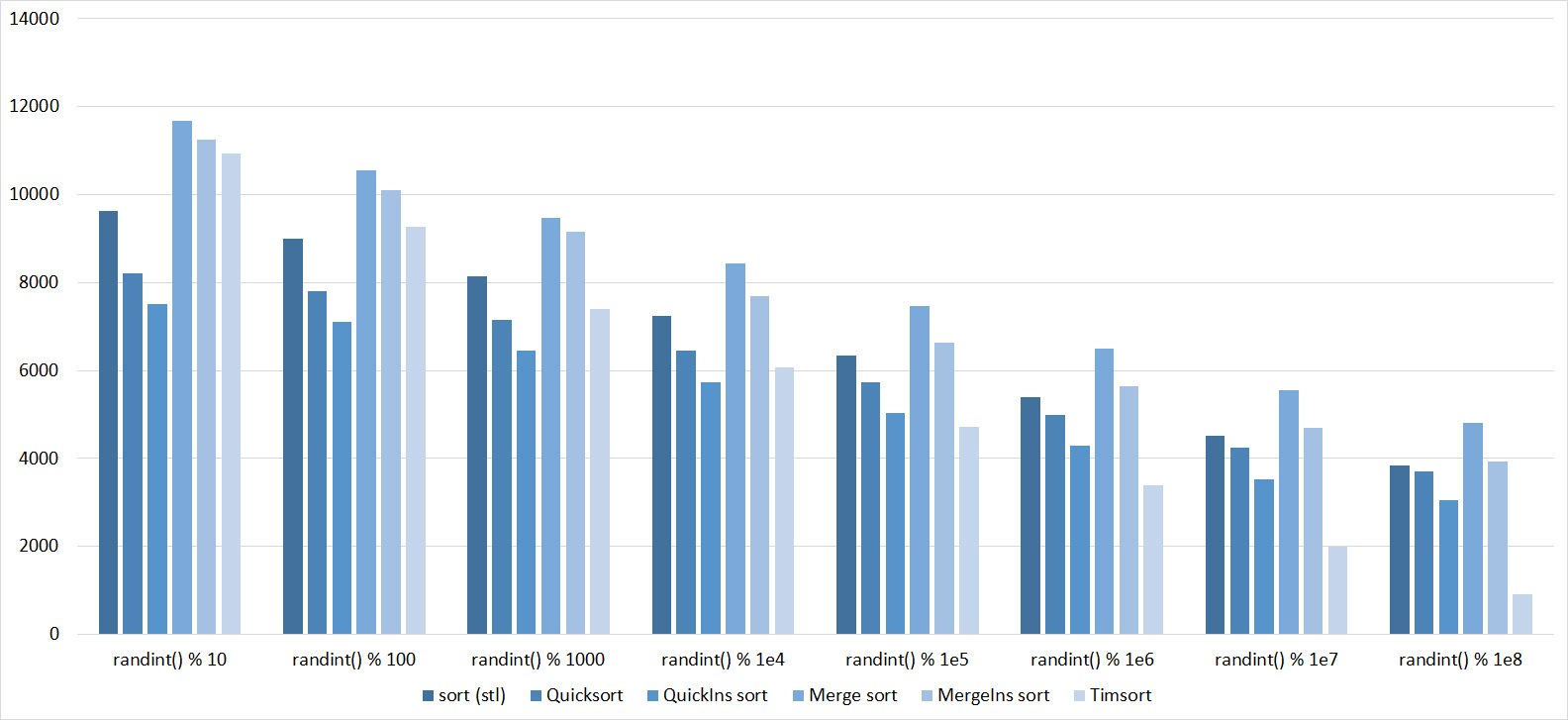
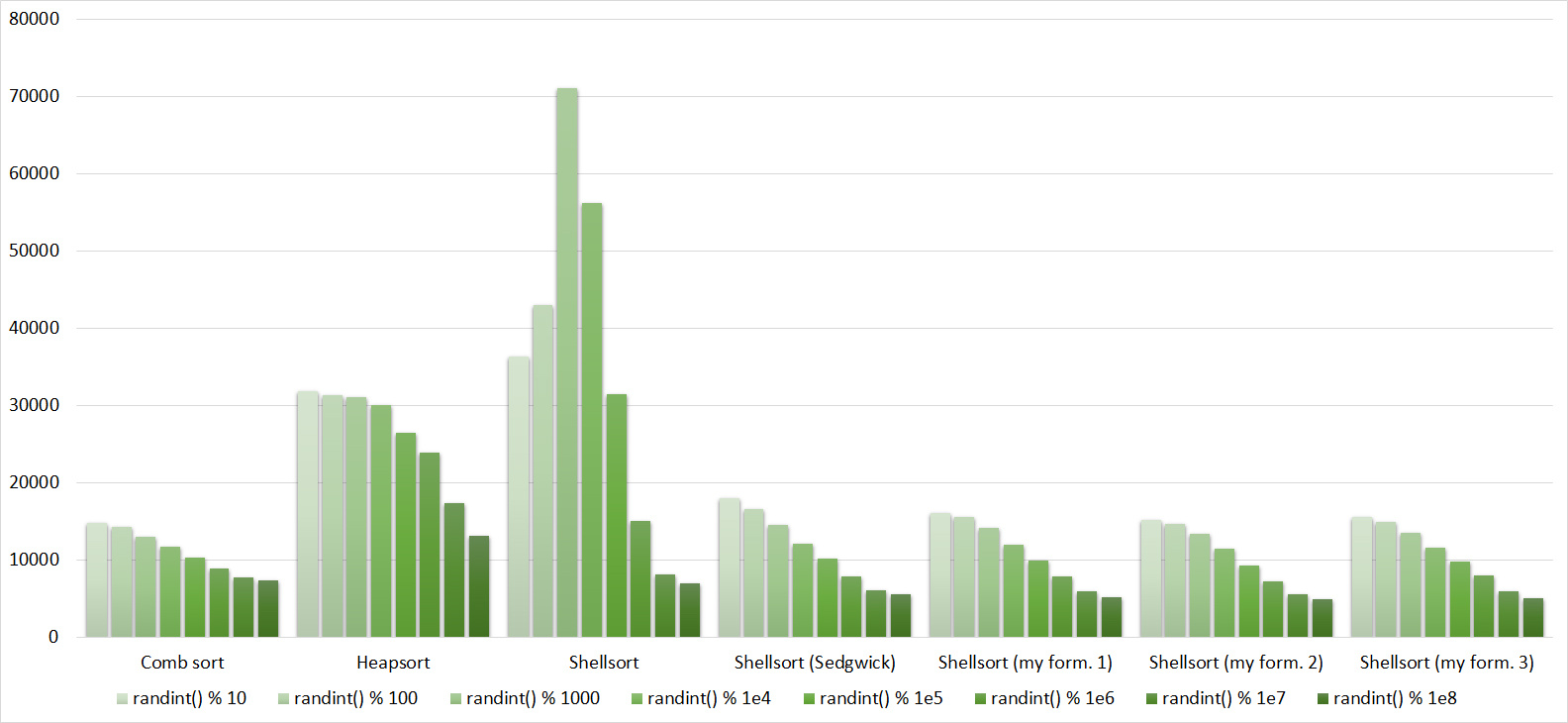
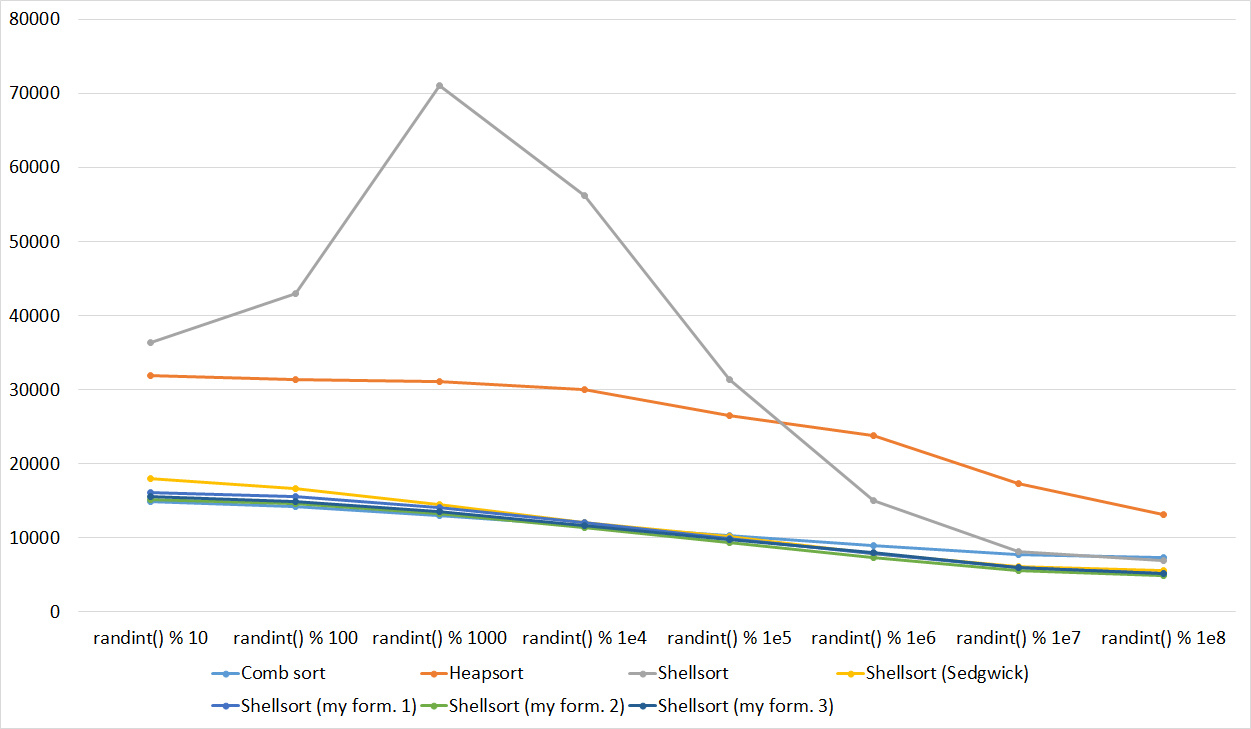
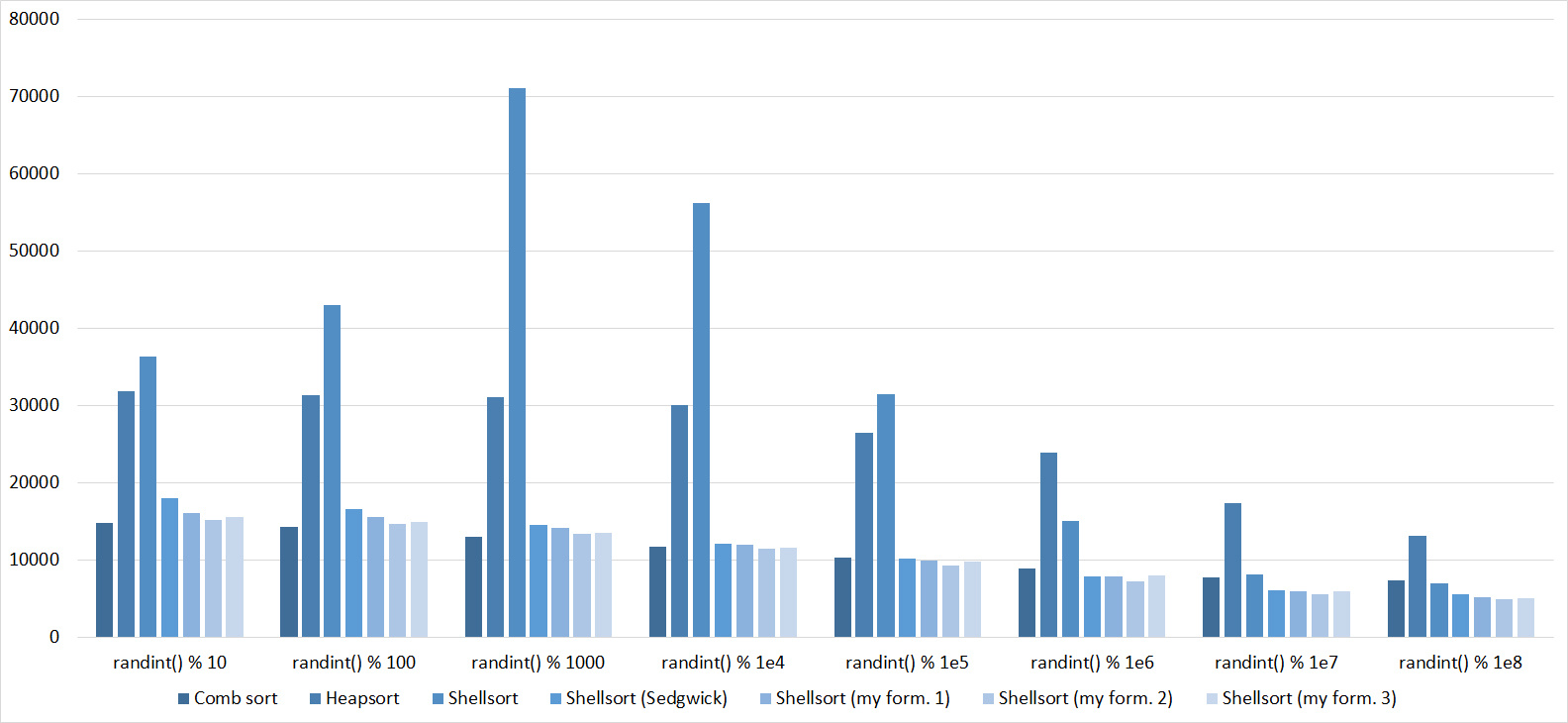

Everything here is also pretty clear. The Timsort algorithm has become noticeable, sorting is stronger on it than on the others. This allowed this algorithm to almost equal the optimized version of quick sort. Block sorting, despite the improvement in the operating time with partial sorting, could not overtake bitwise sorting.
Swaps
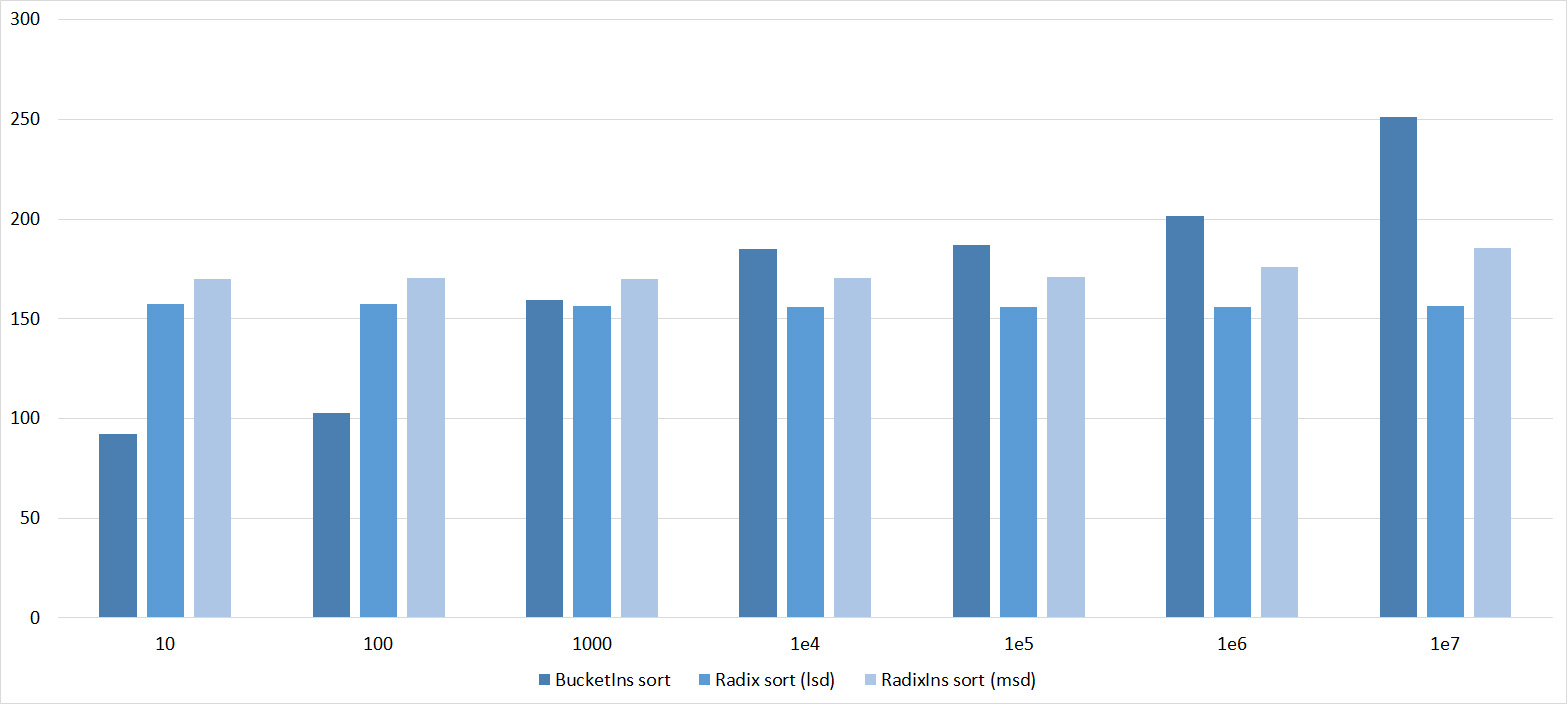
Tables, 1e7 elements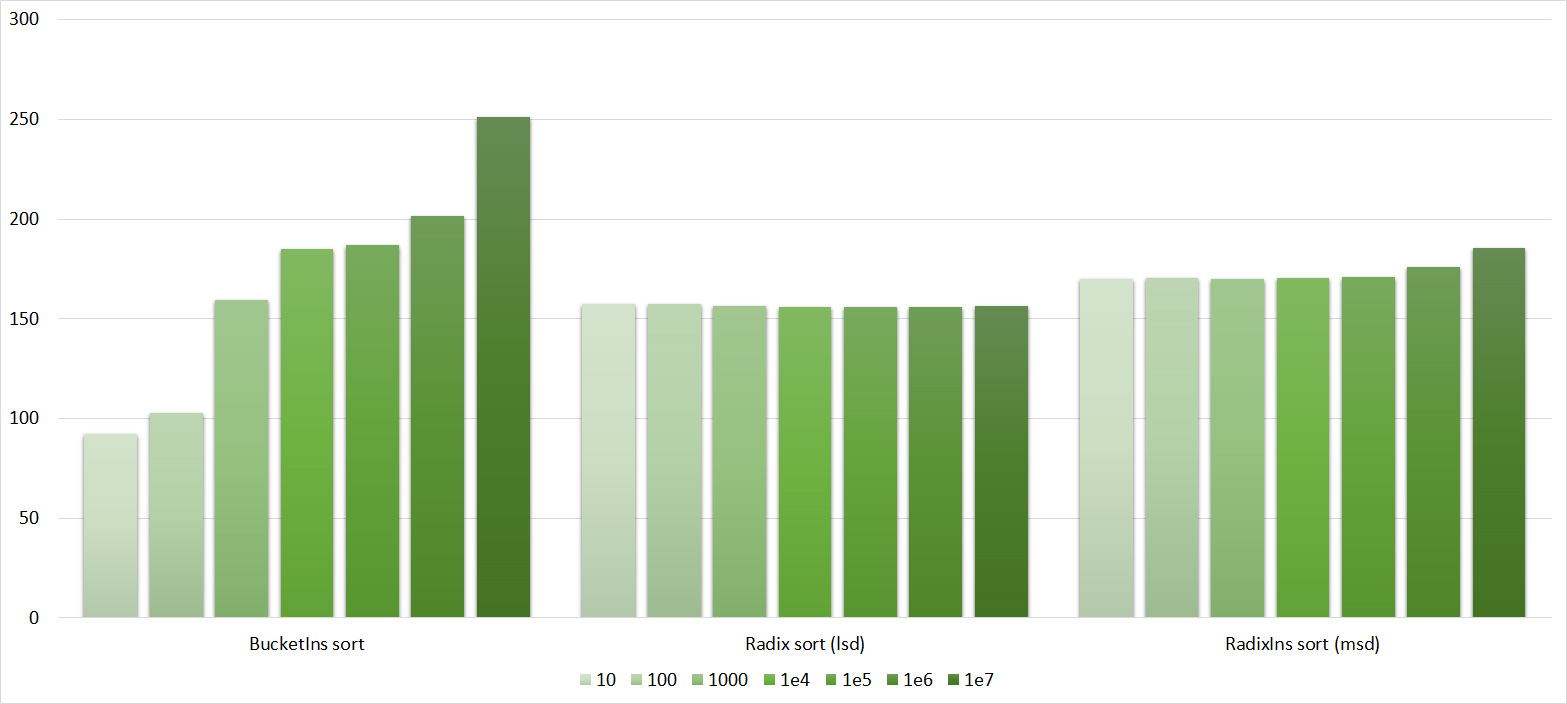

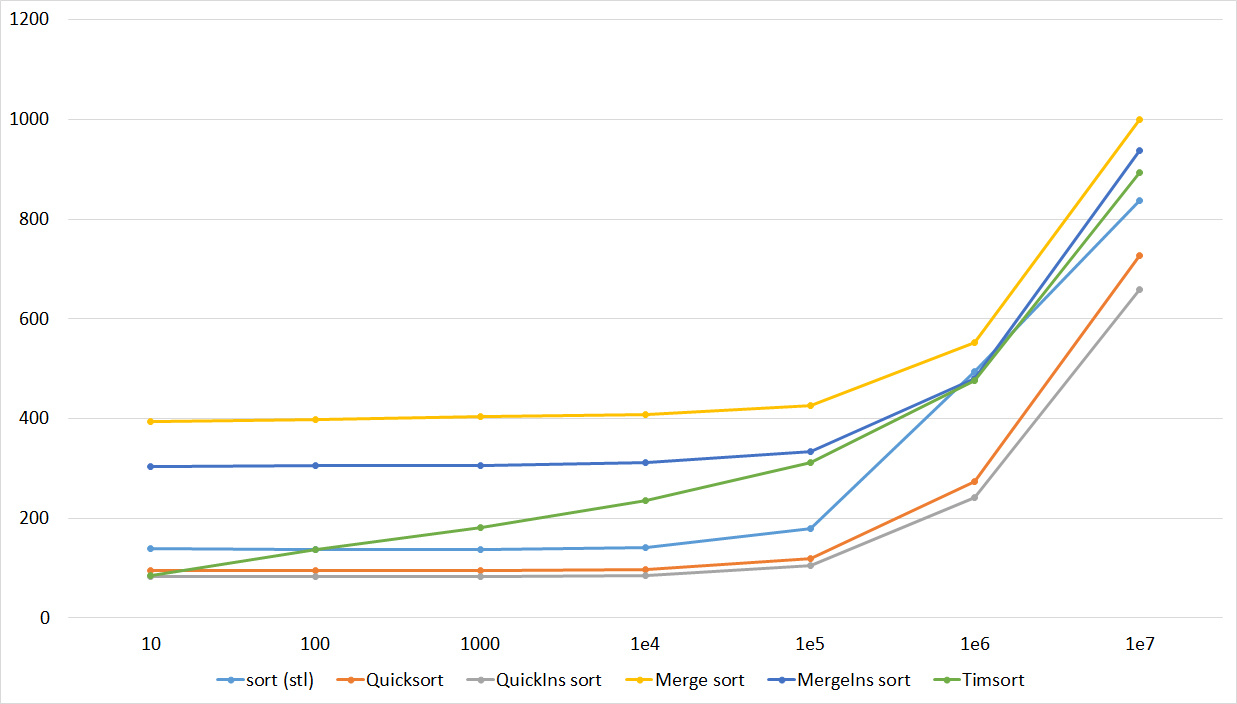
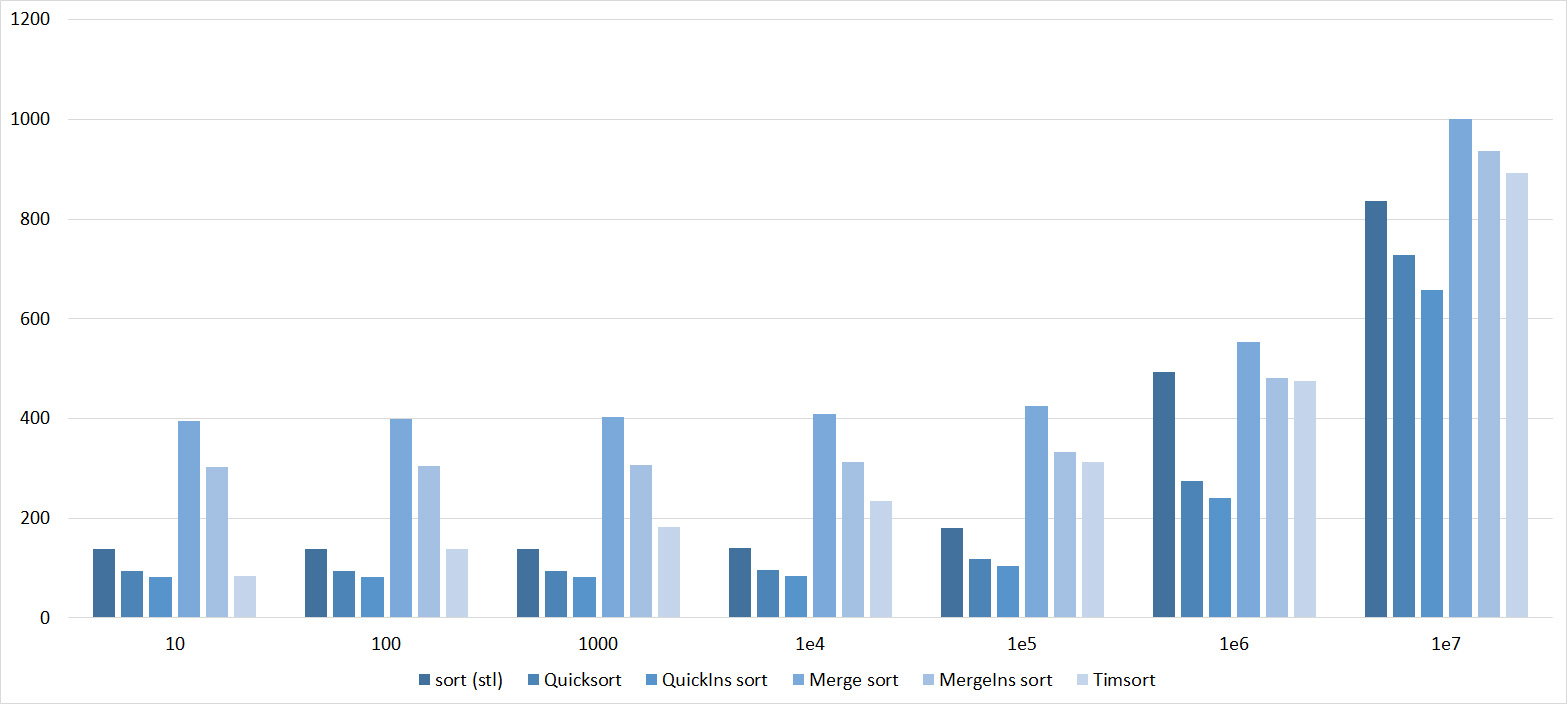

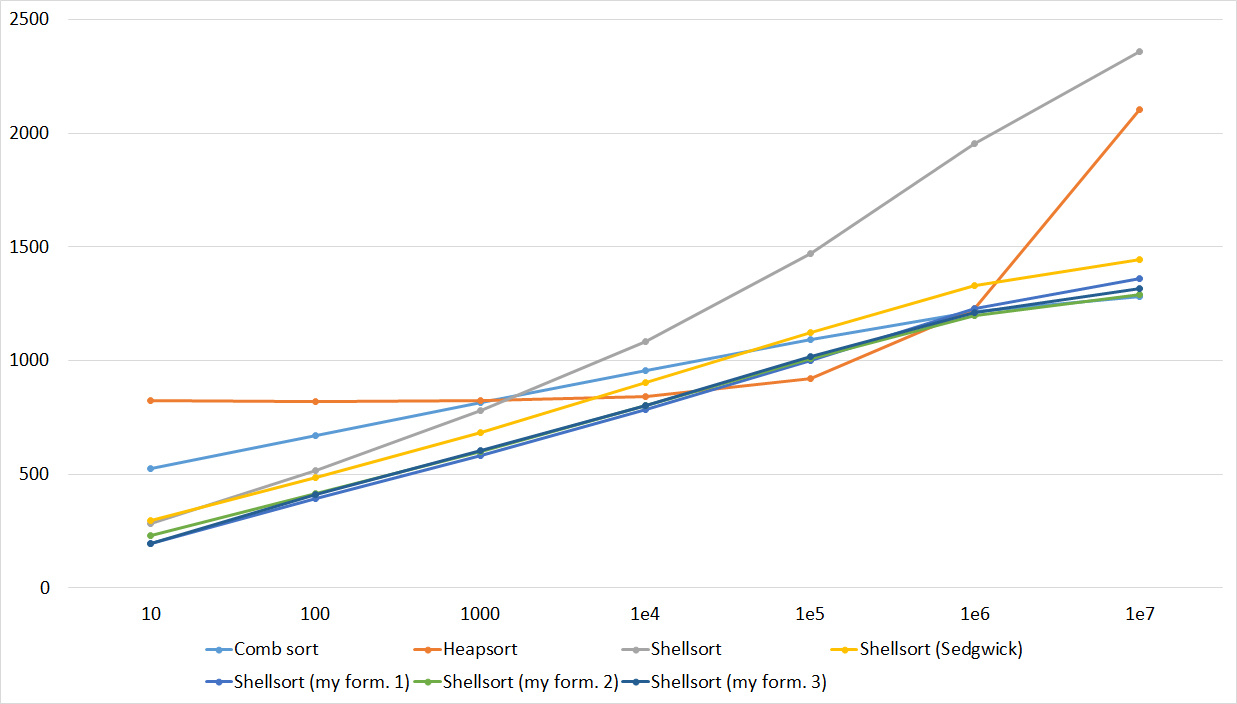

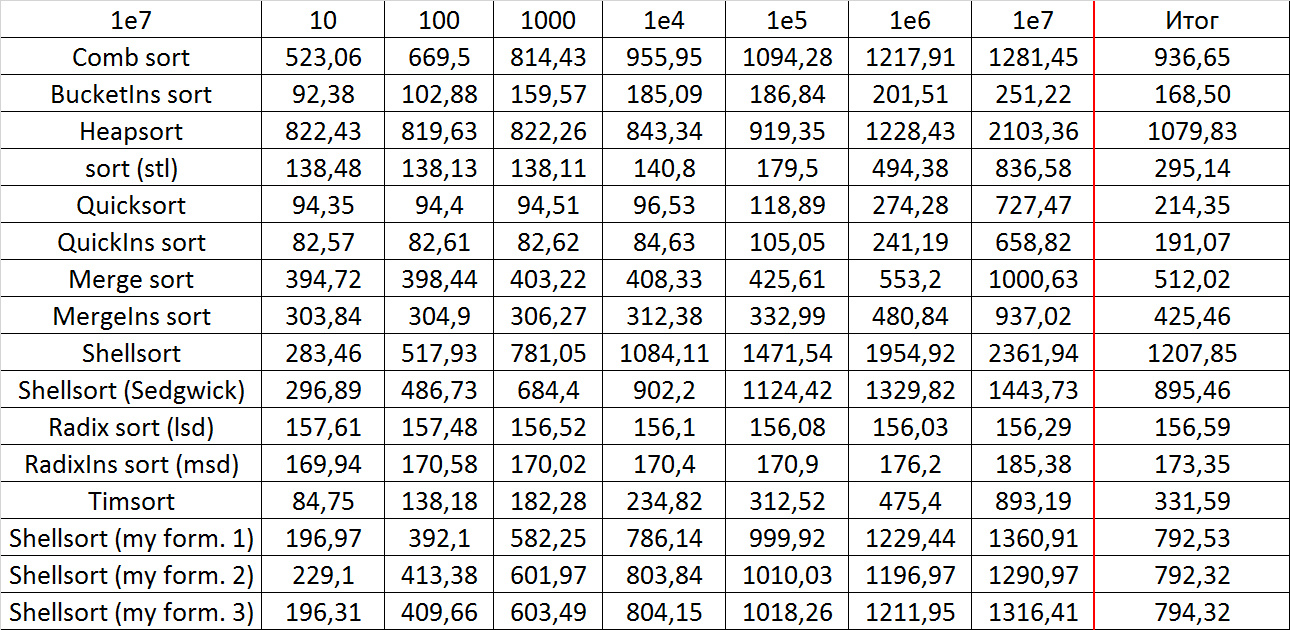

Tables, 1e8 elements
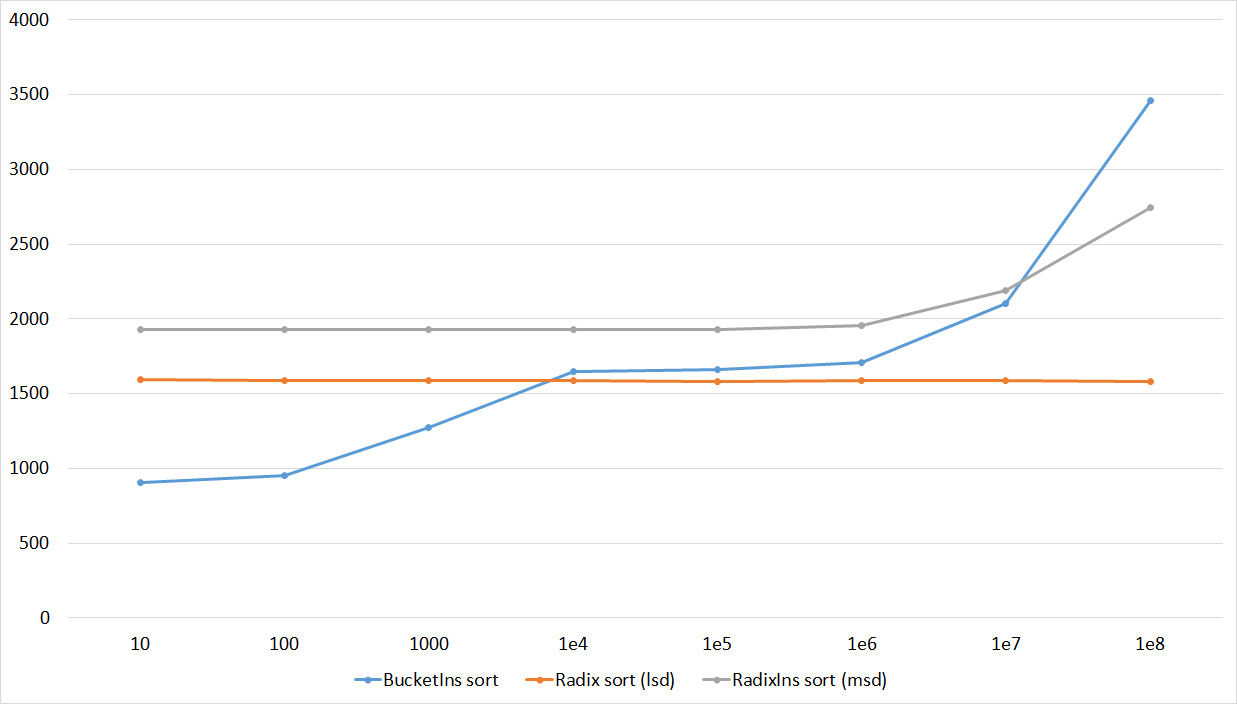
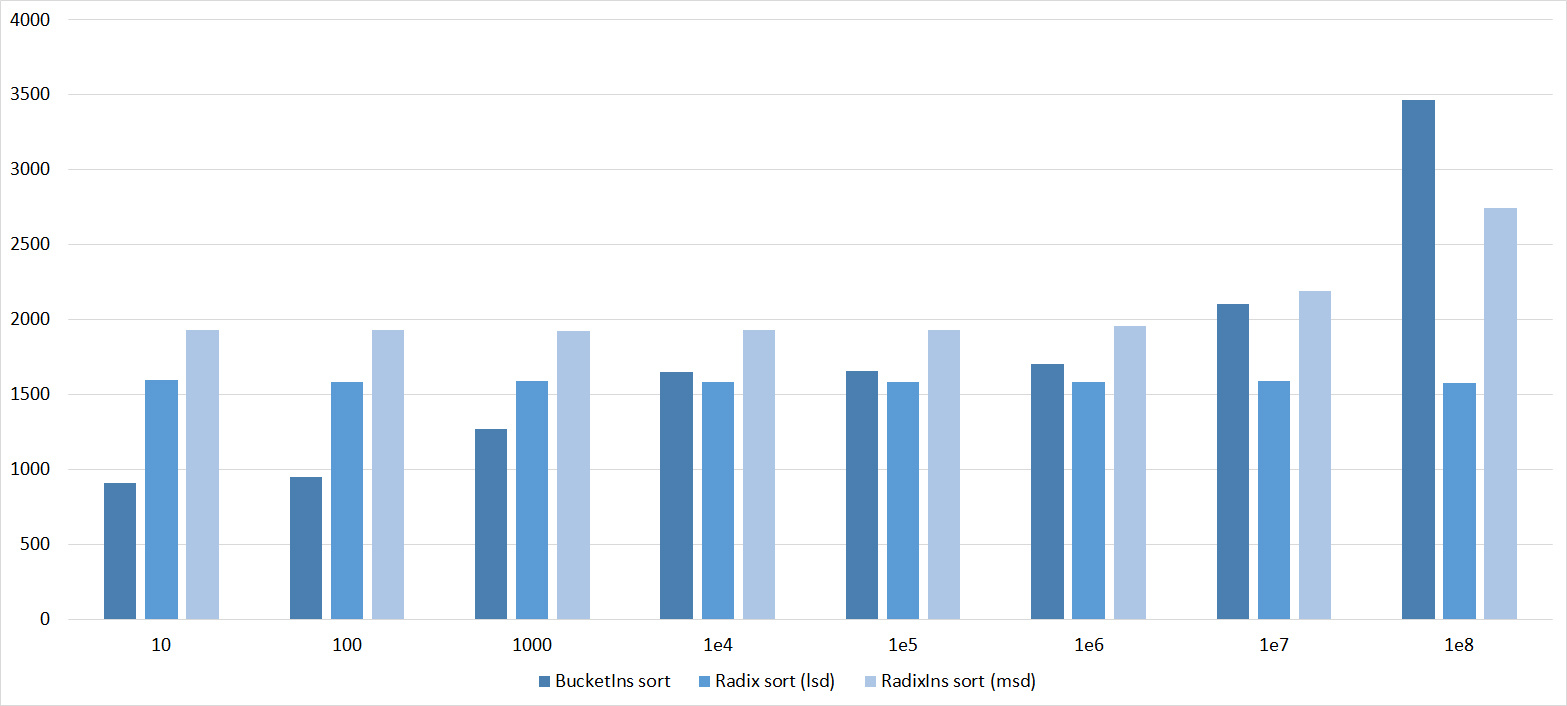
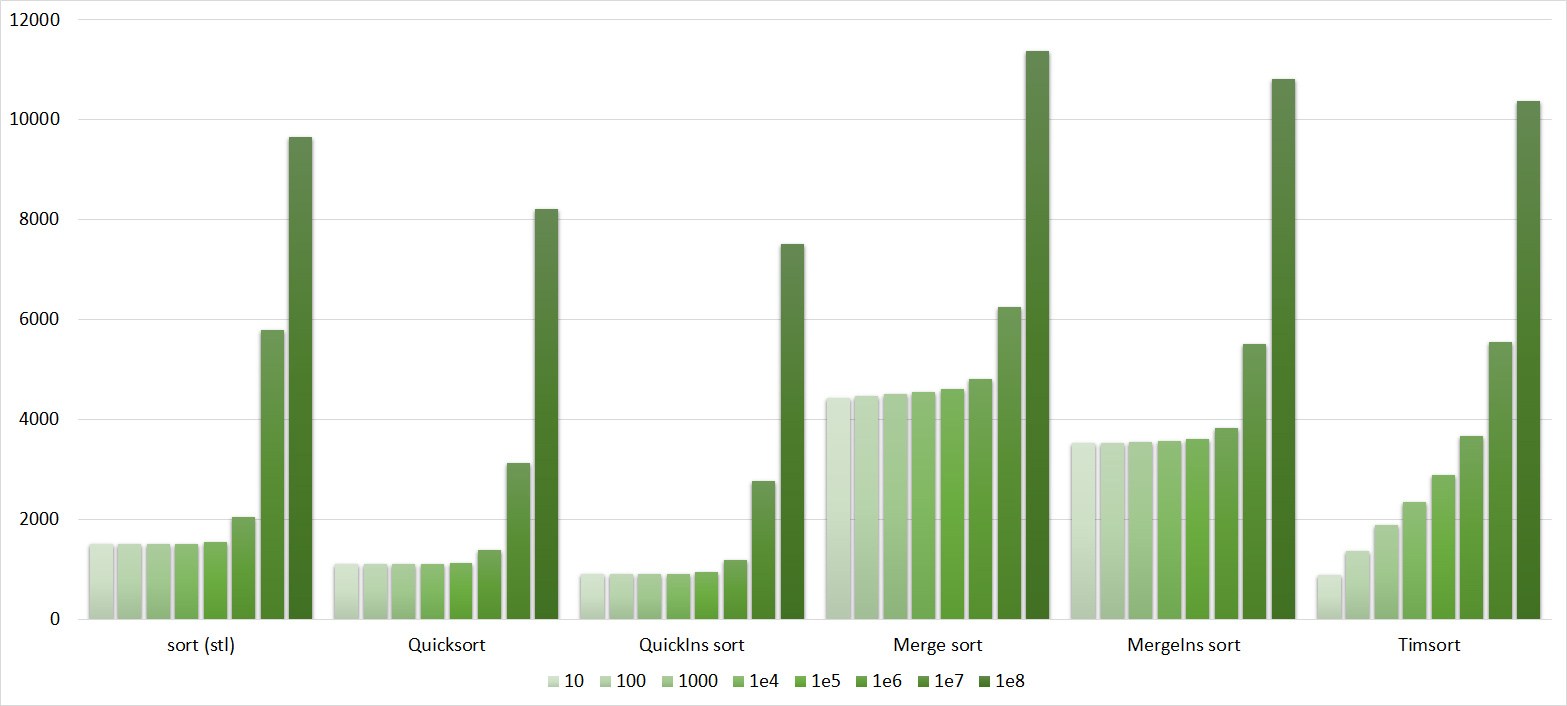
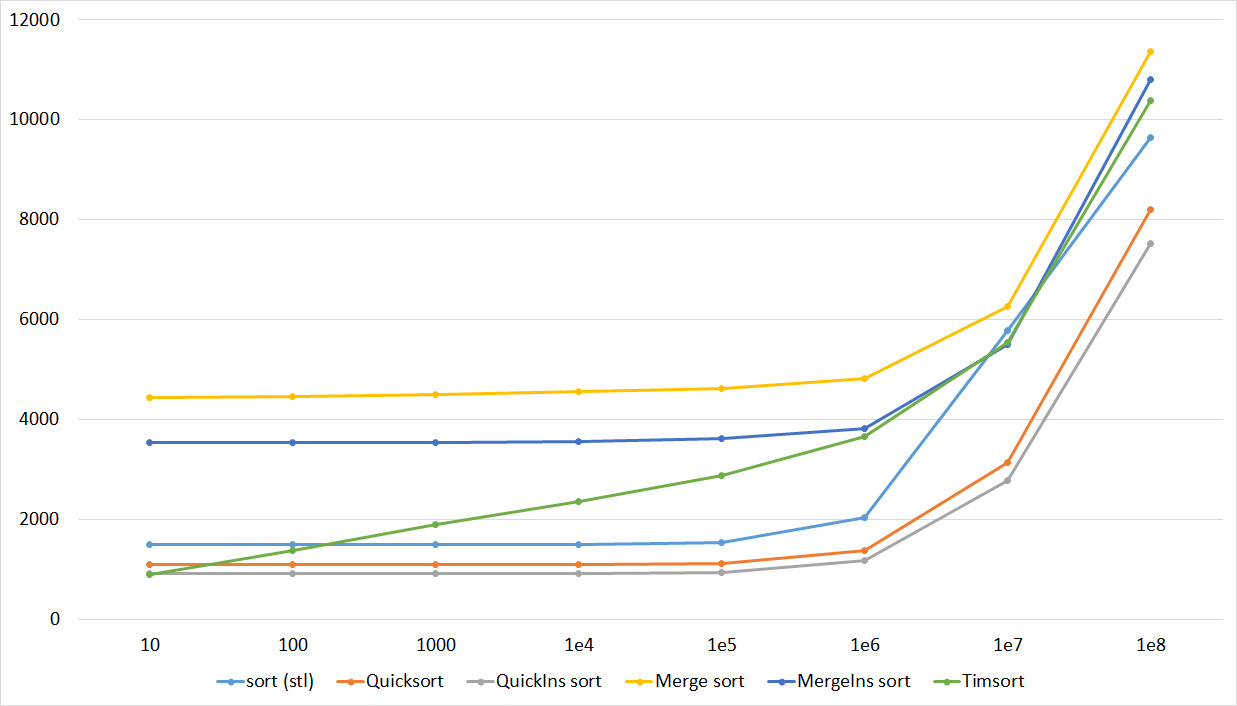
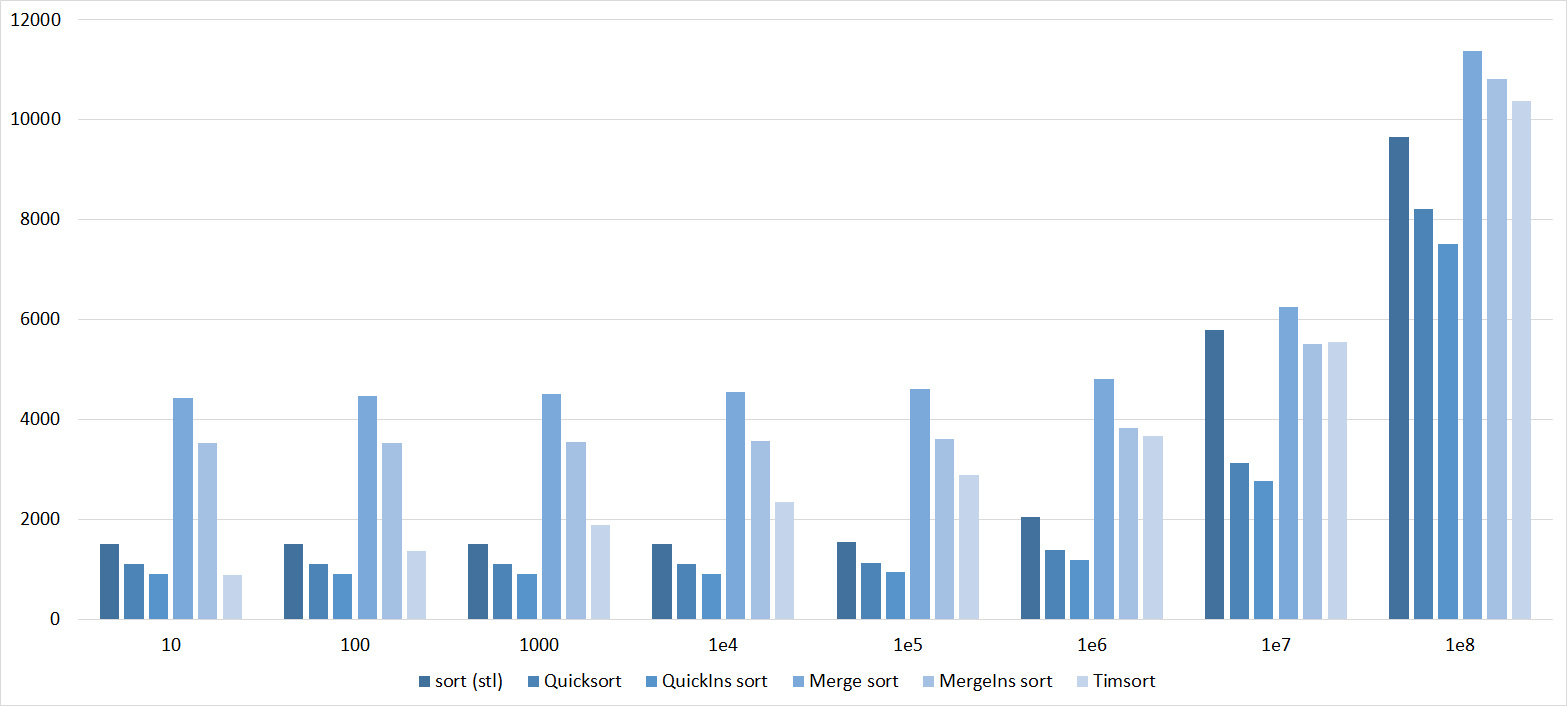
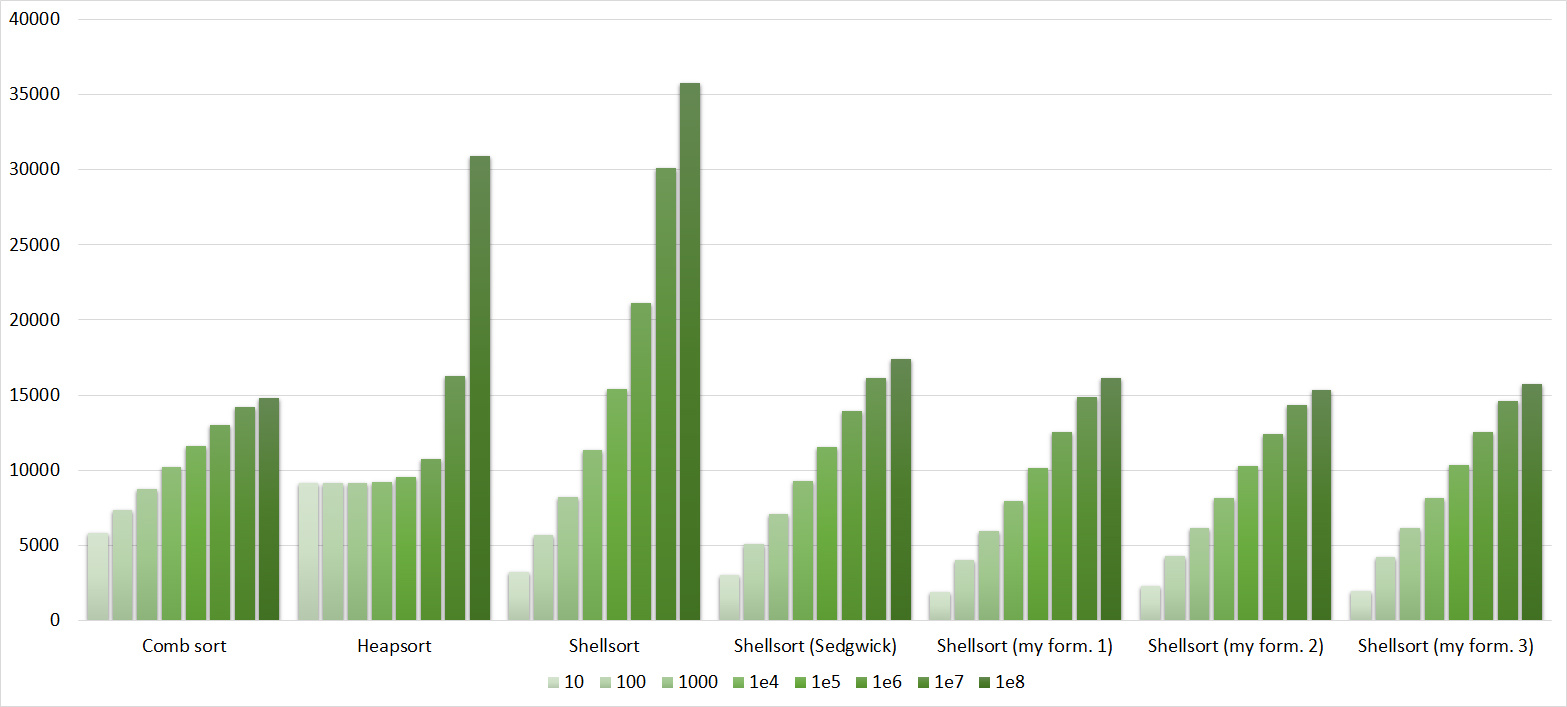
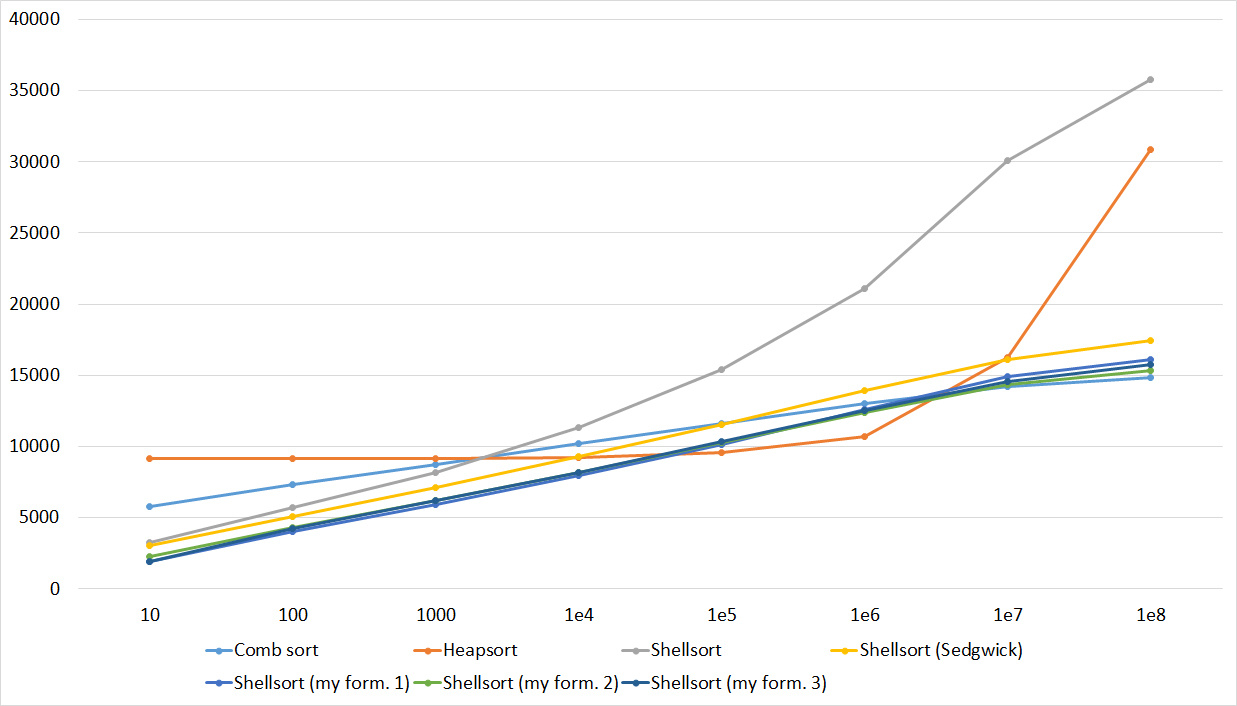

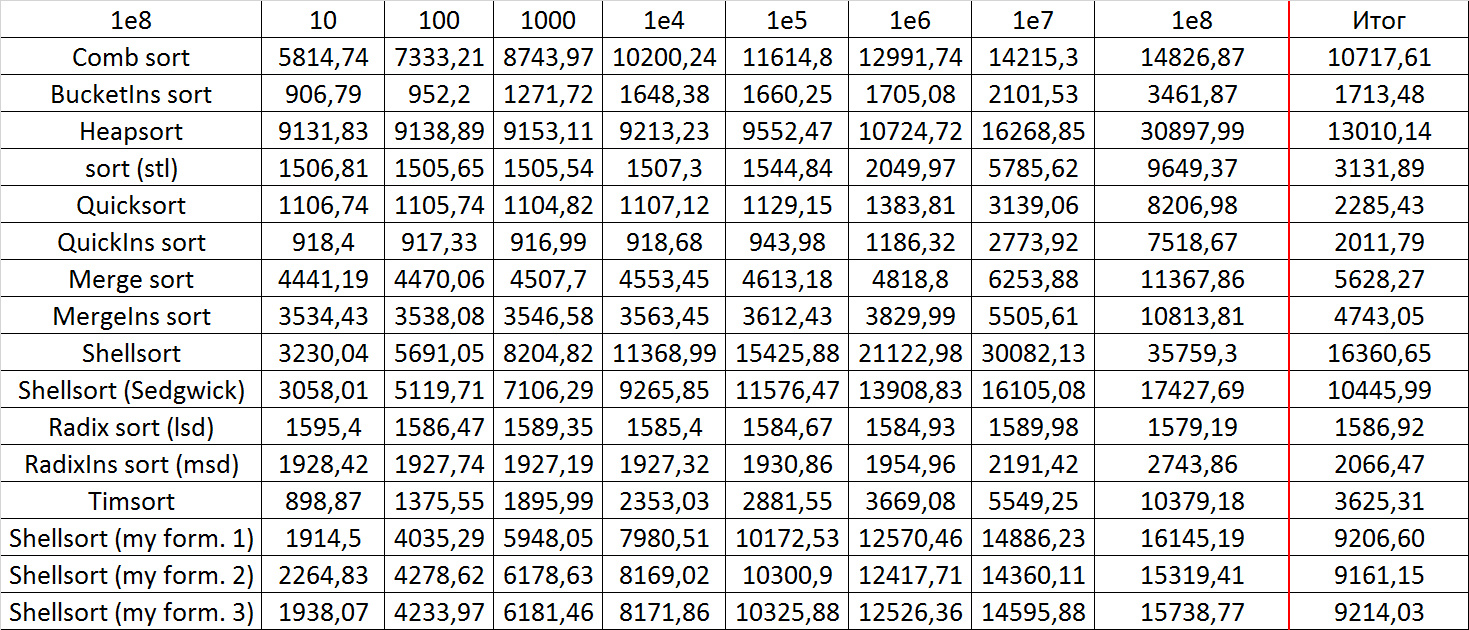
Quick sorts worked really well here. This is most likely due to the successful selection of the support element. Everything else is almost the same as in the previous group.
Permutation changes
Tables, 1e7 elements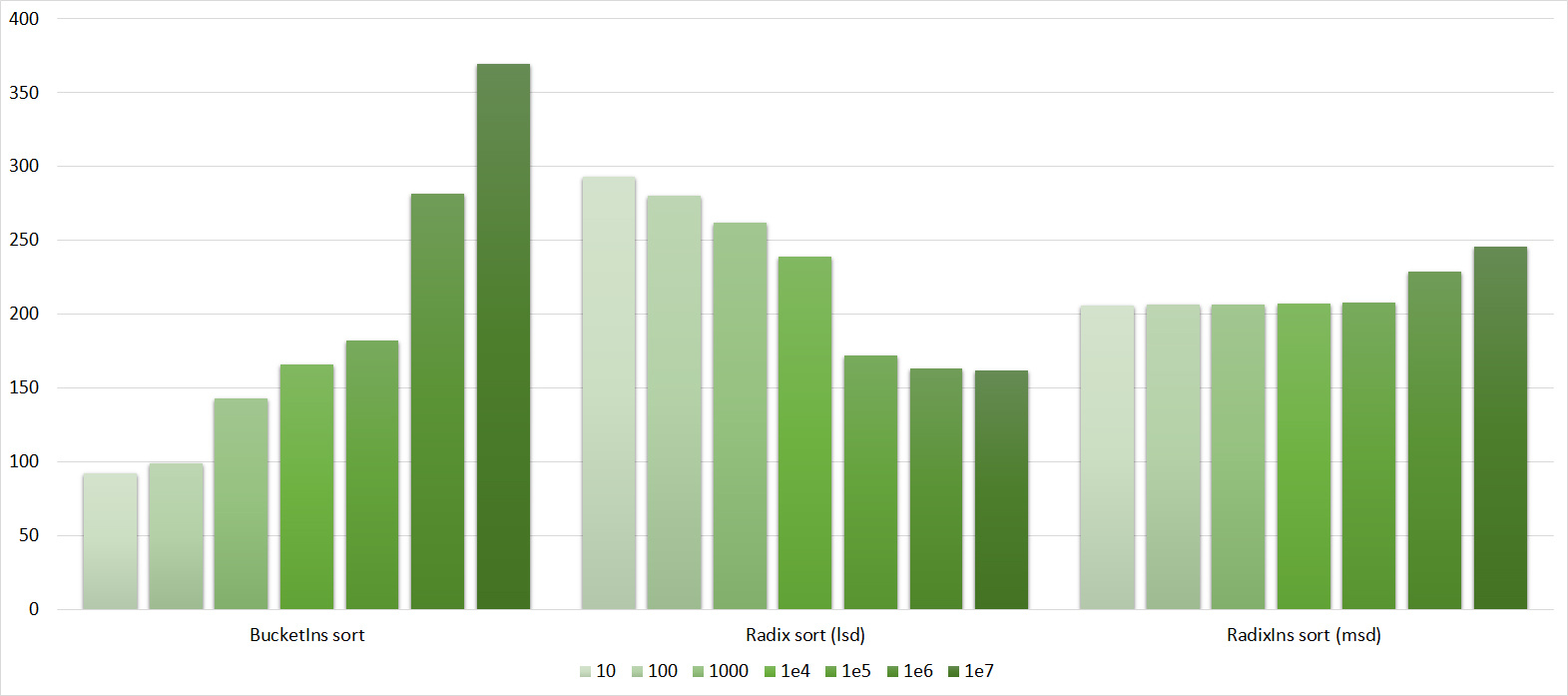
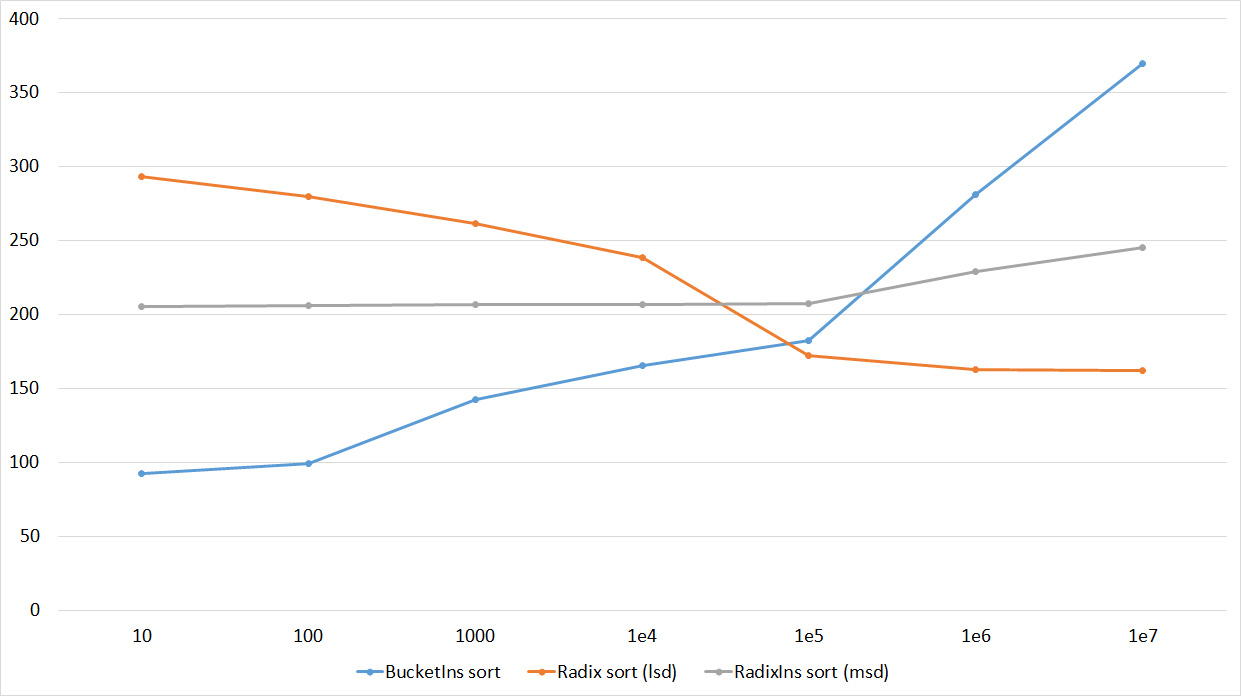
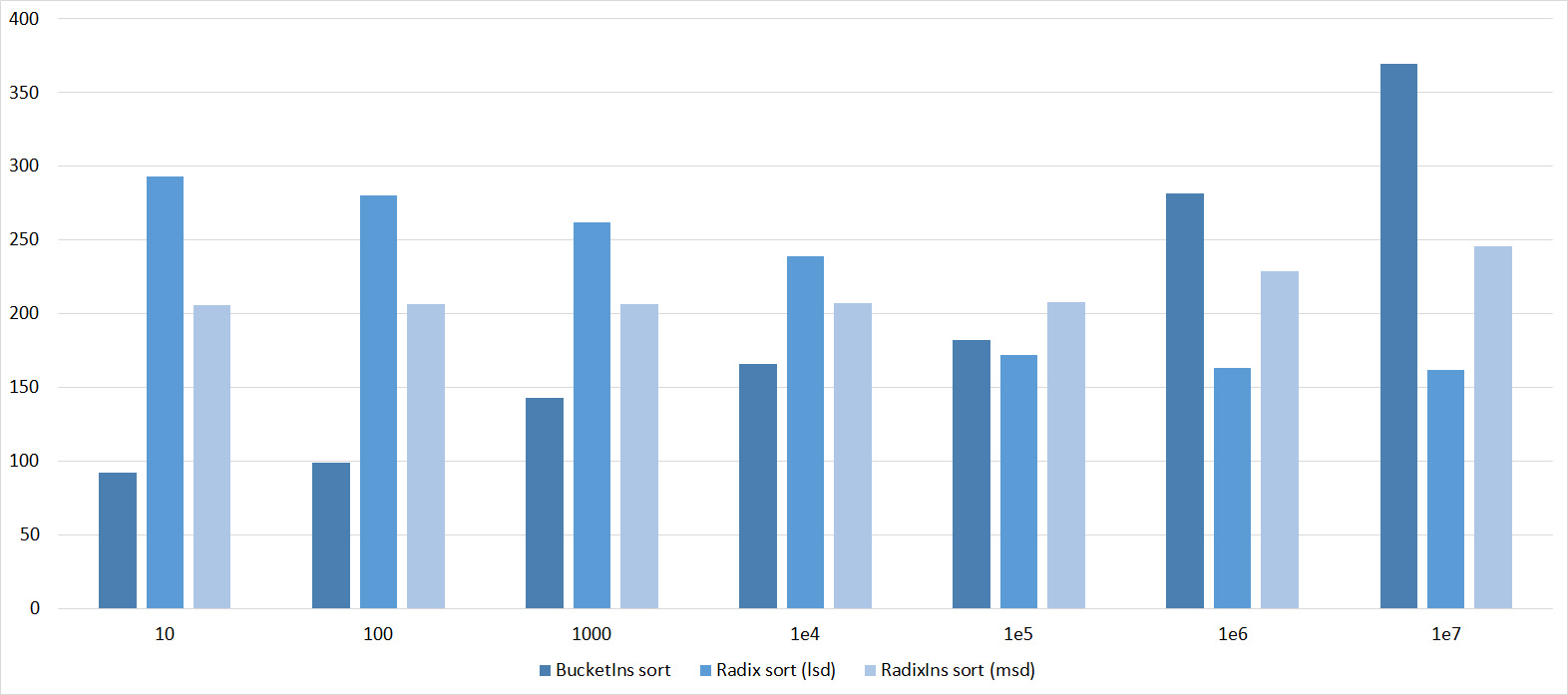
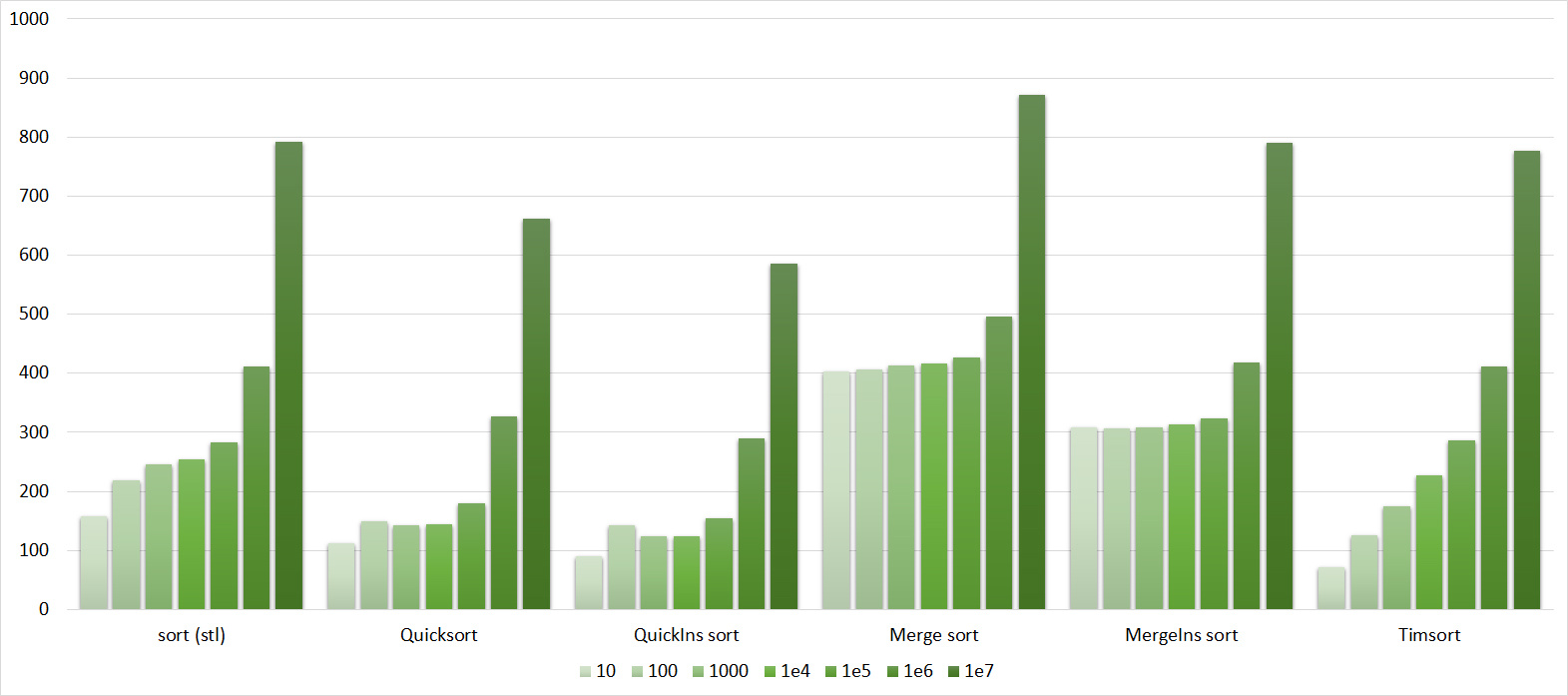
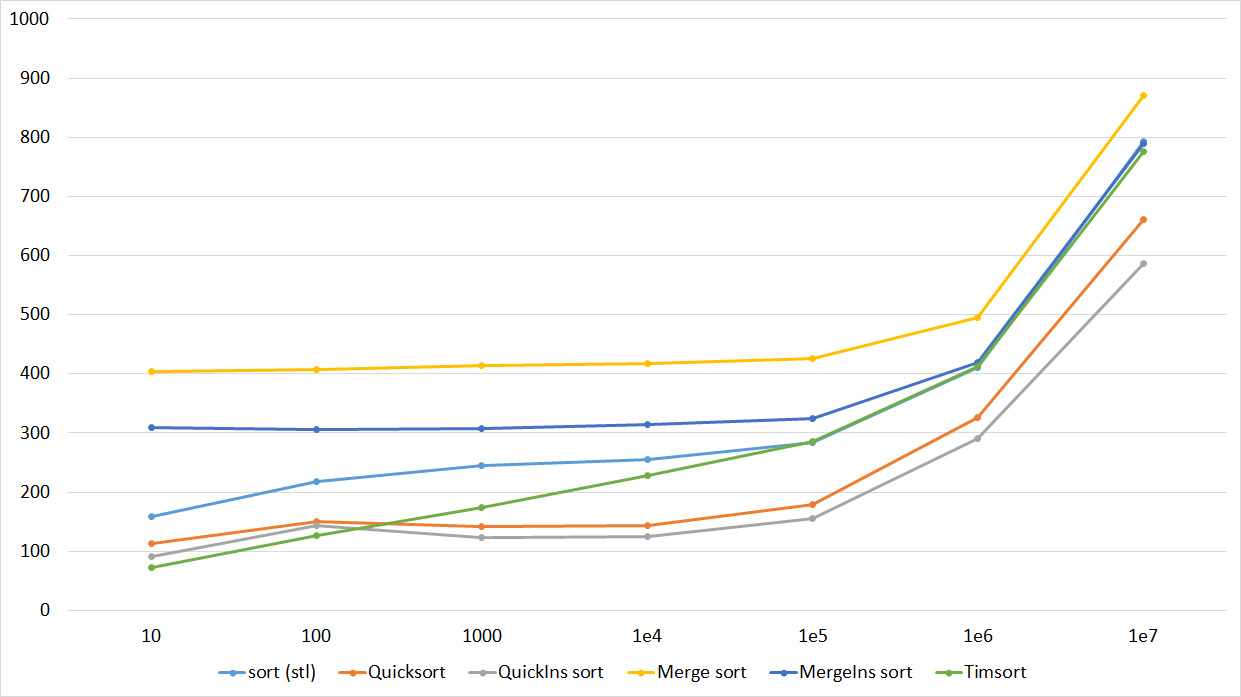
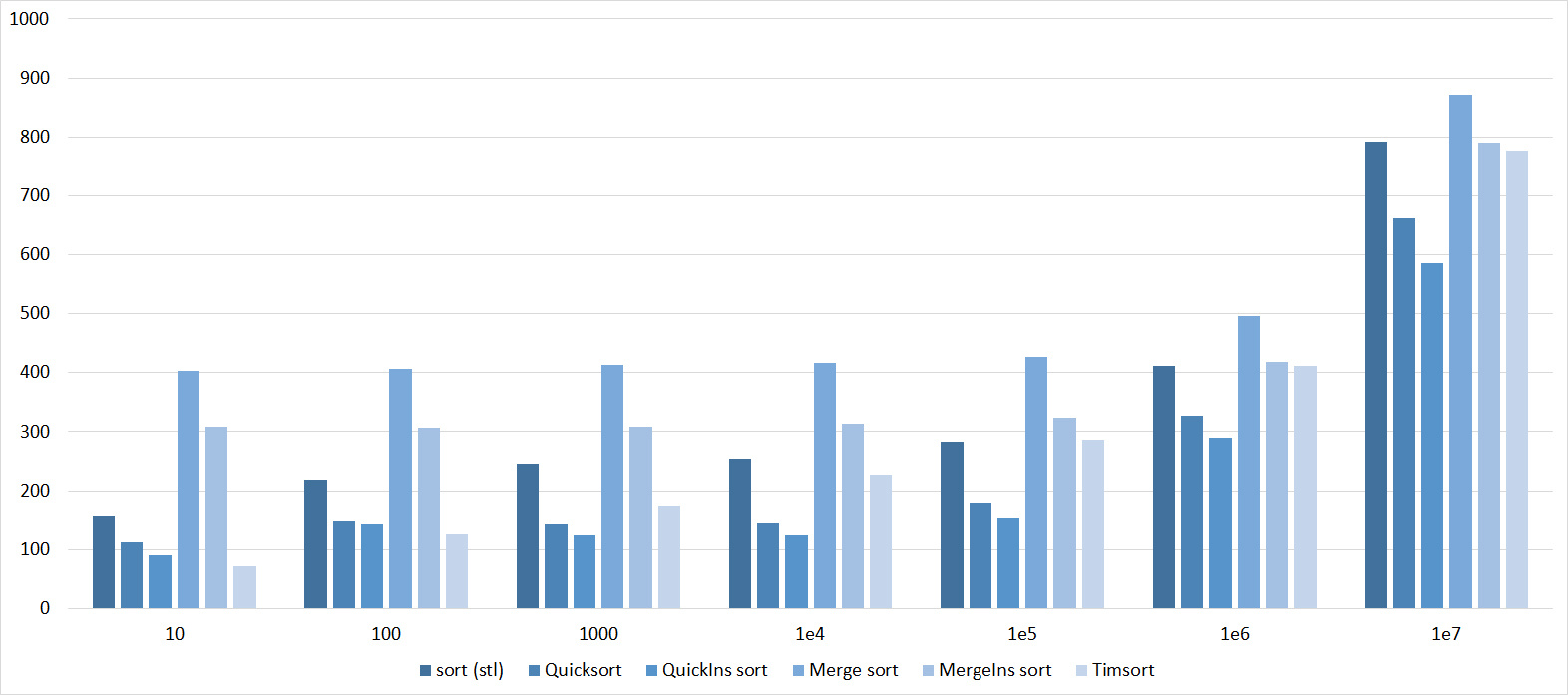


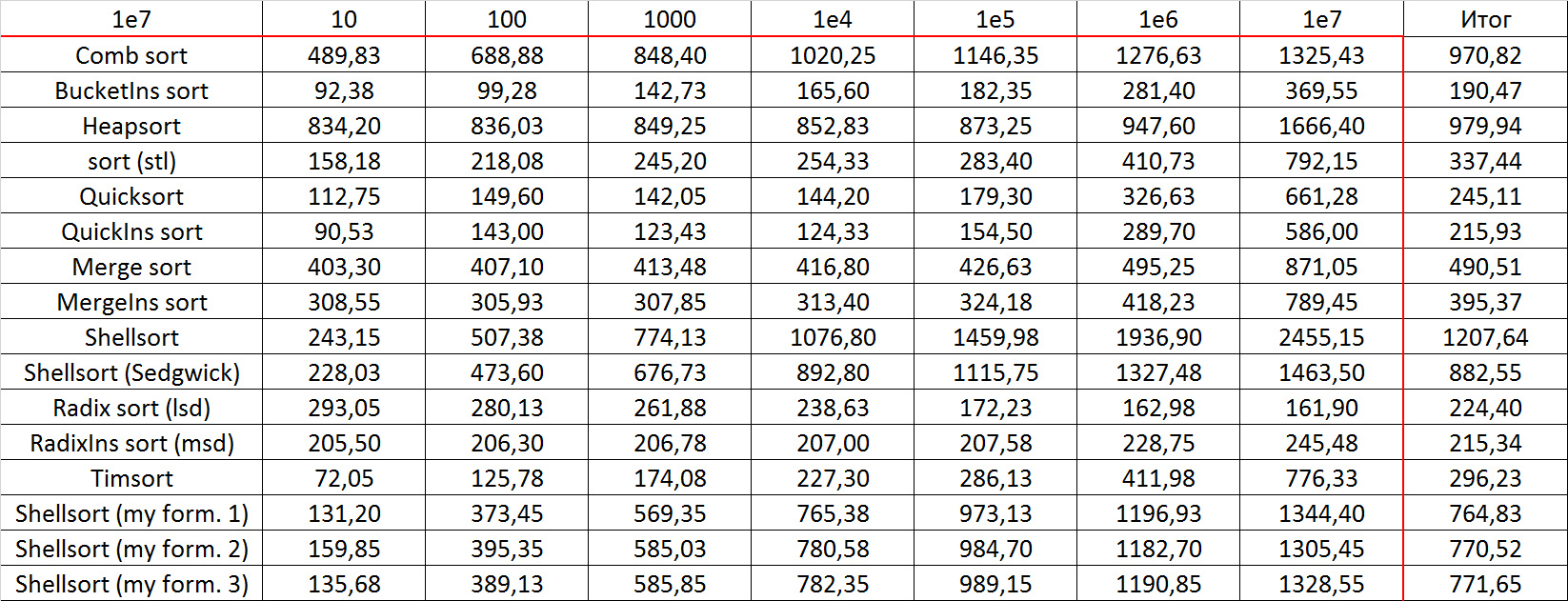
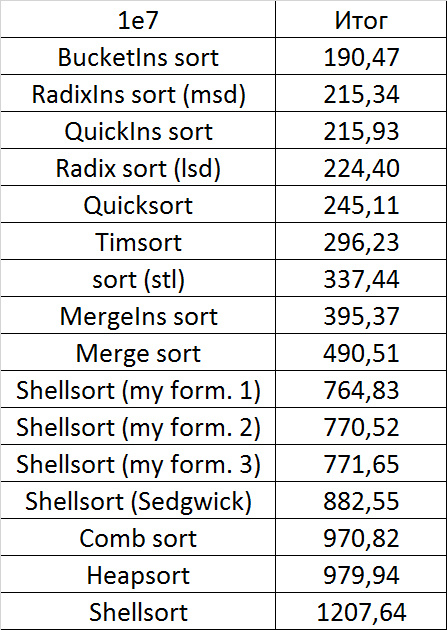
Tables, 1e8 elements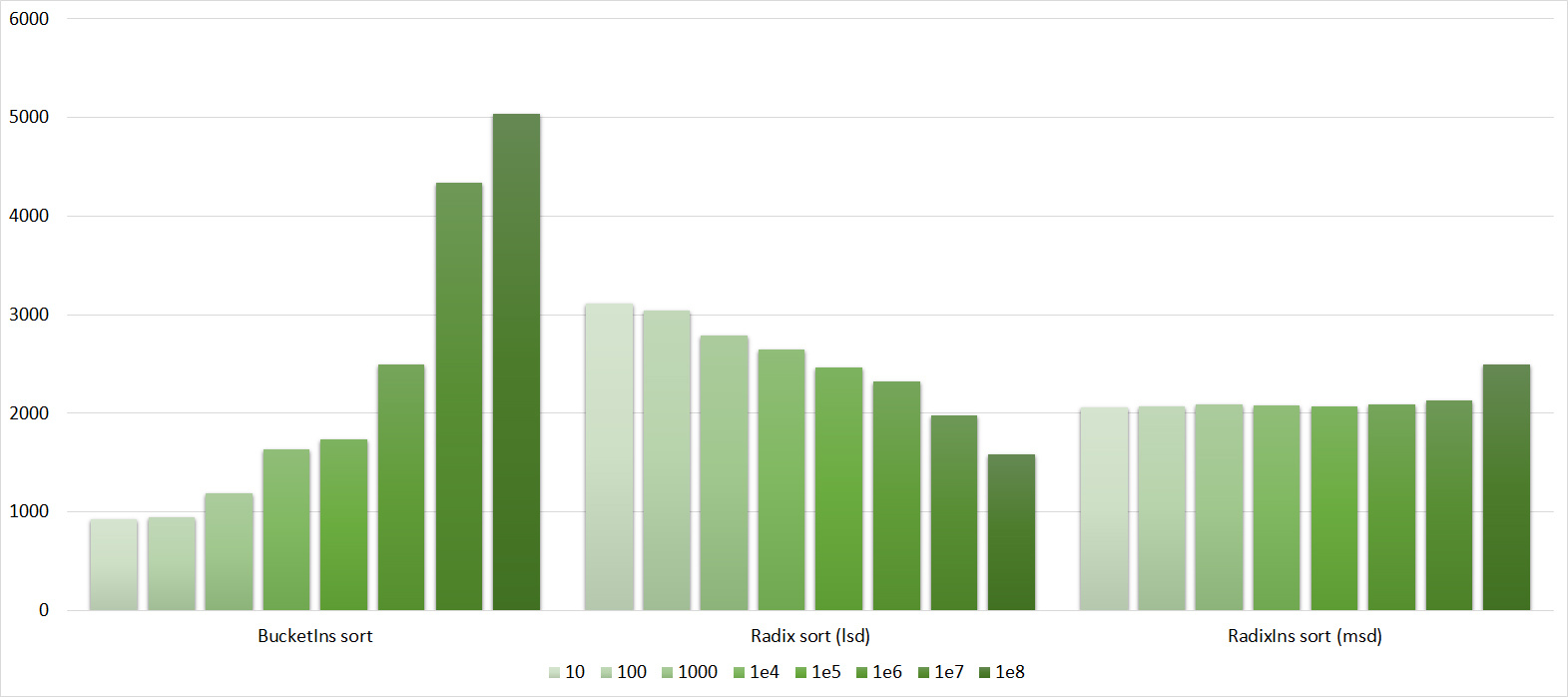






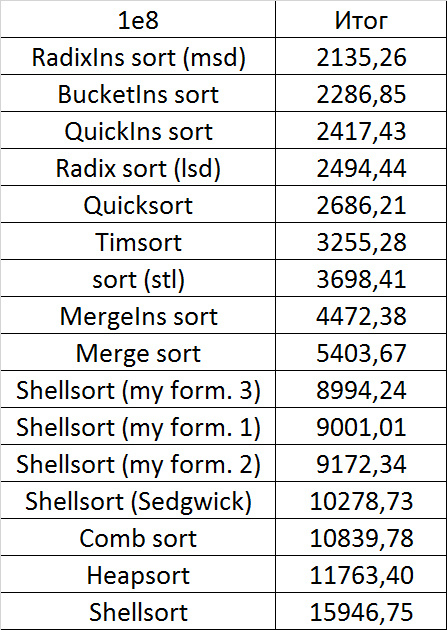
I managed to achieve the desired goal - bitwise sorting fell even below the adapted fast. Block sorting was better than the rest. For some reason, timsort overtook the built-in C ++ sort, although in the previous group it was lower.
Repetitions
Tables, 1e7 elements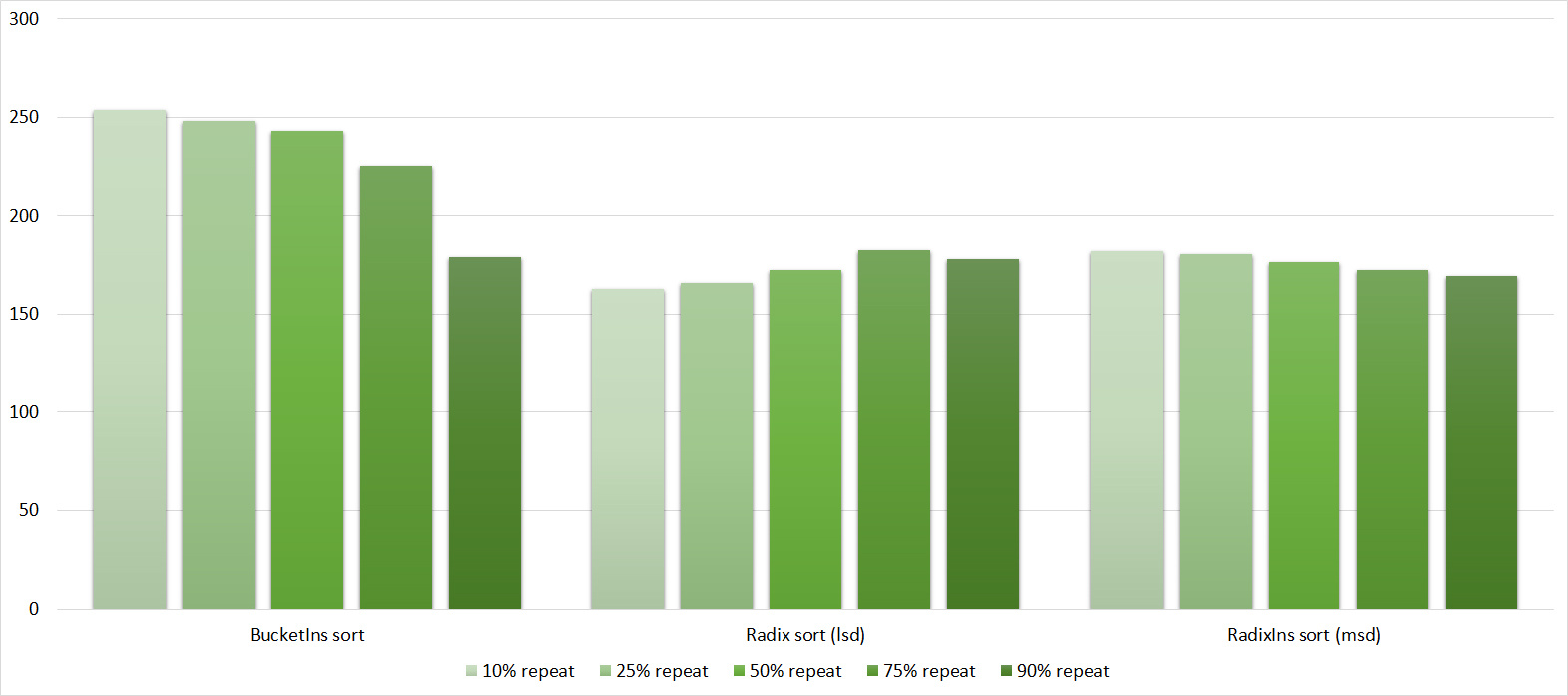
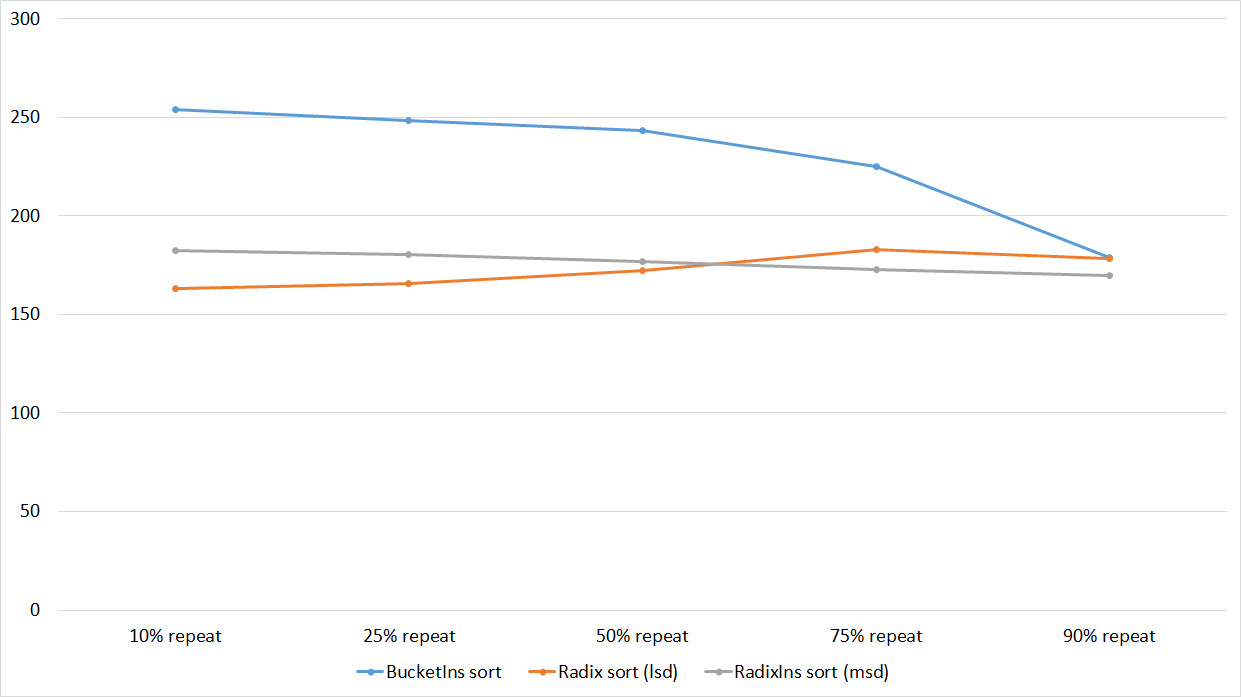

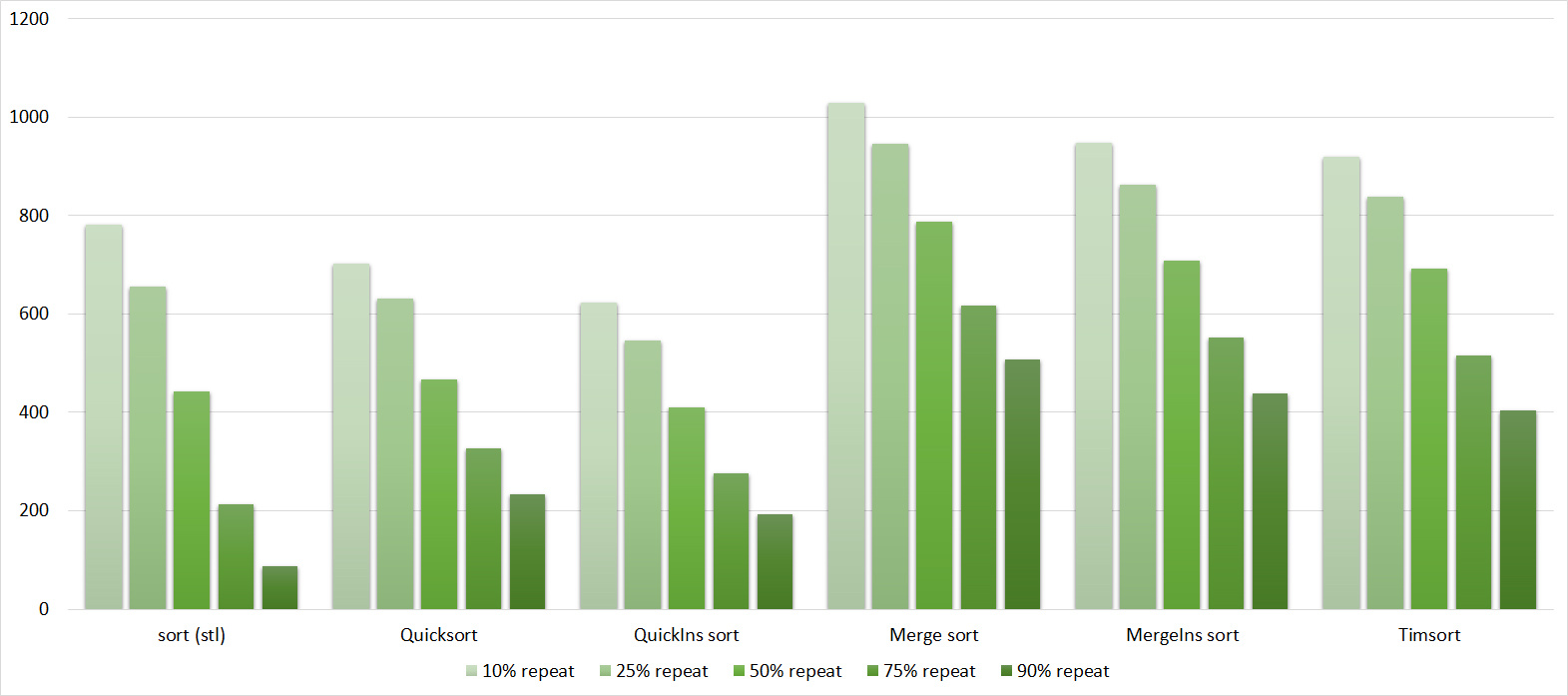


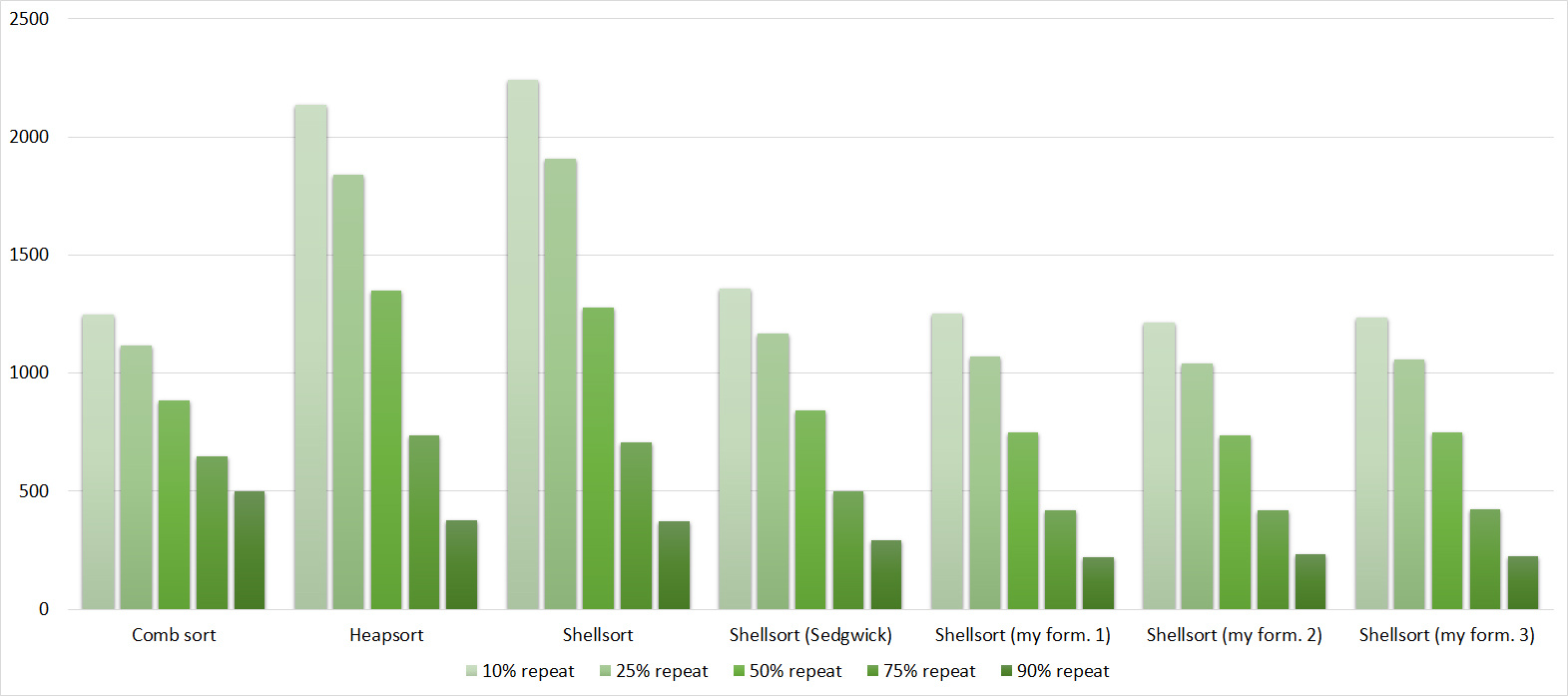
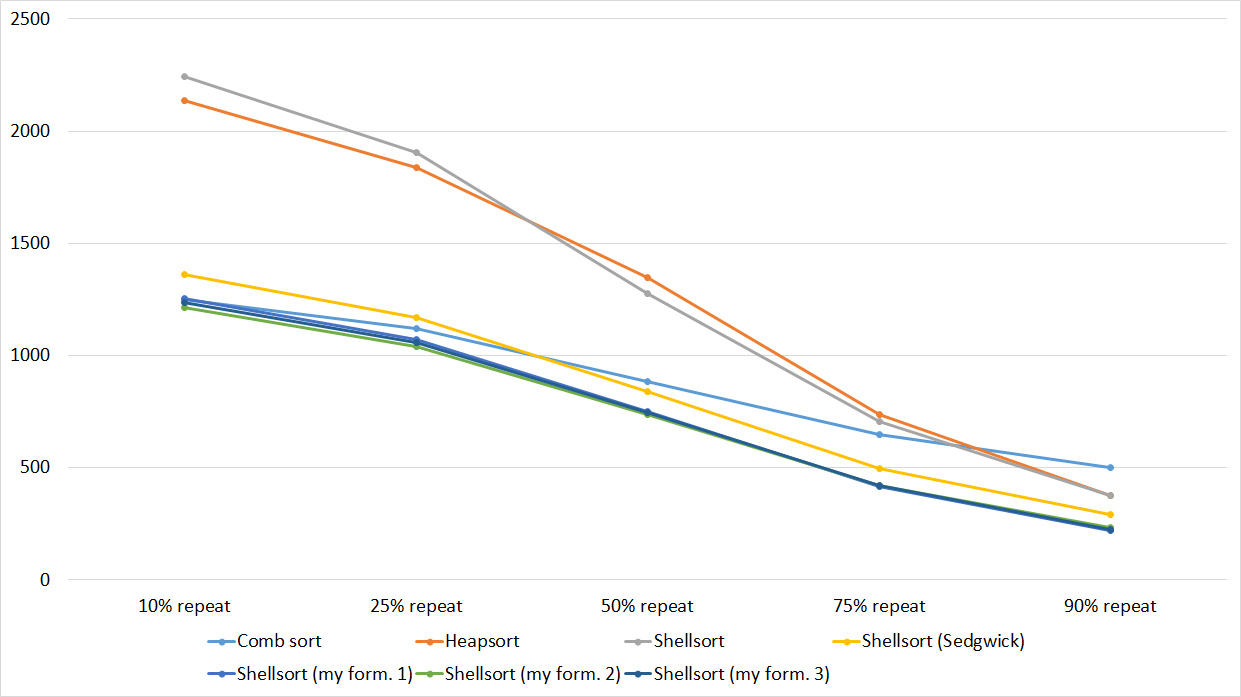
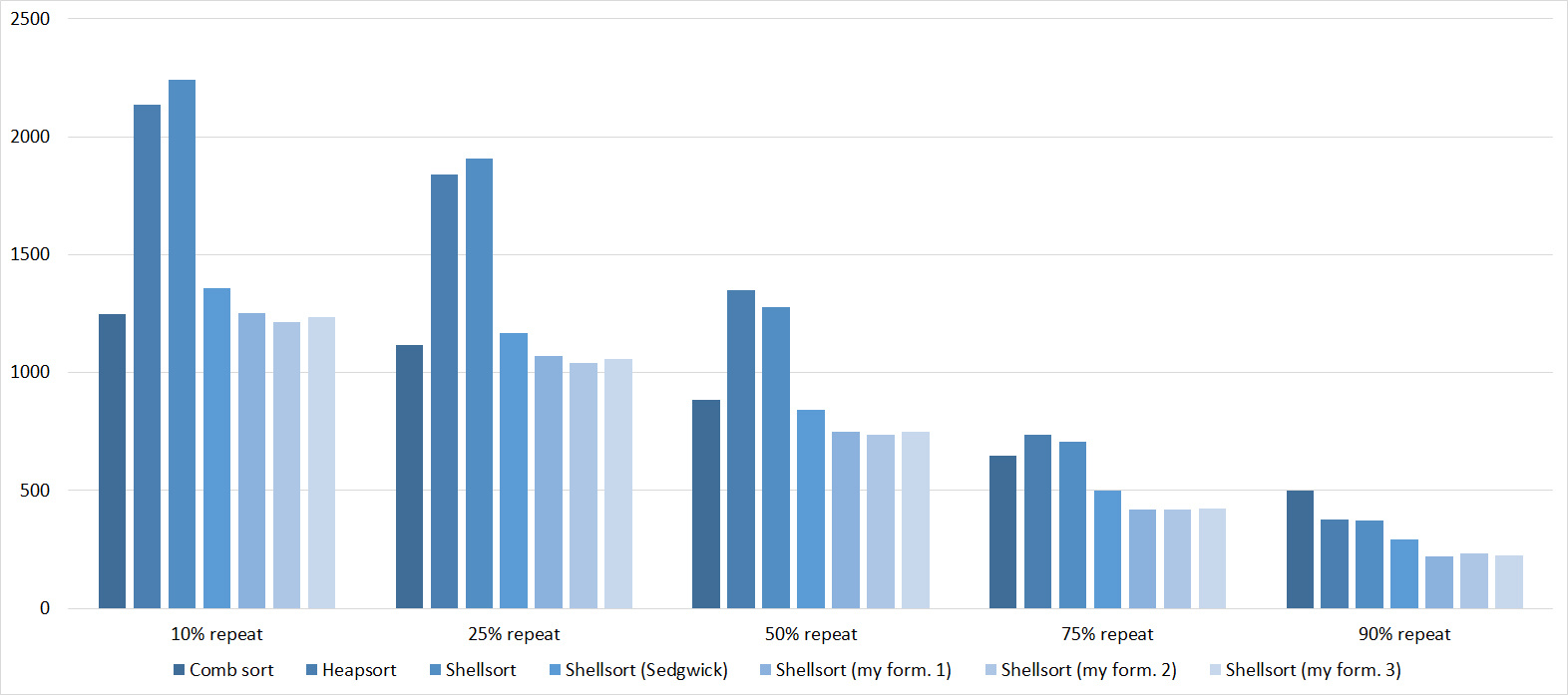
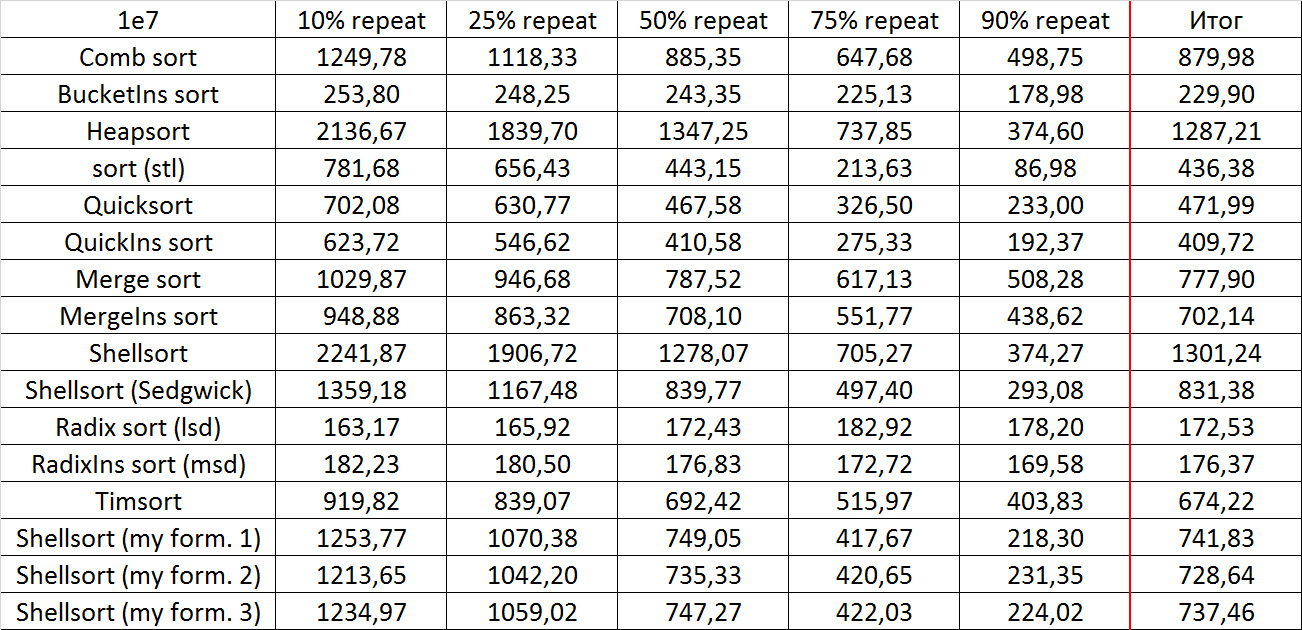
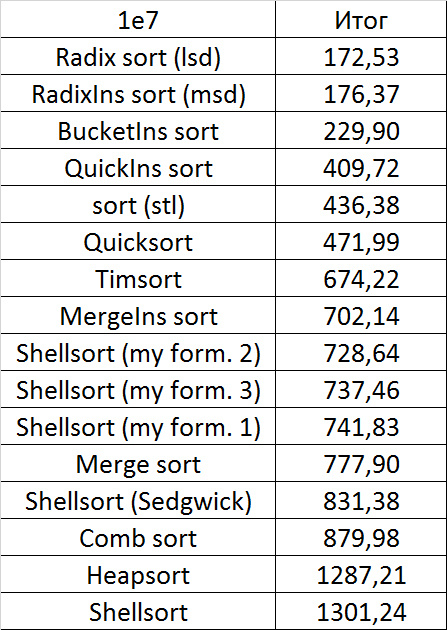
Tables, 1e8 elements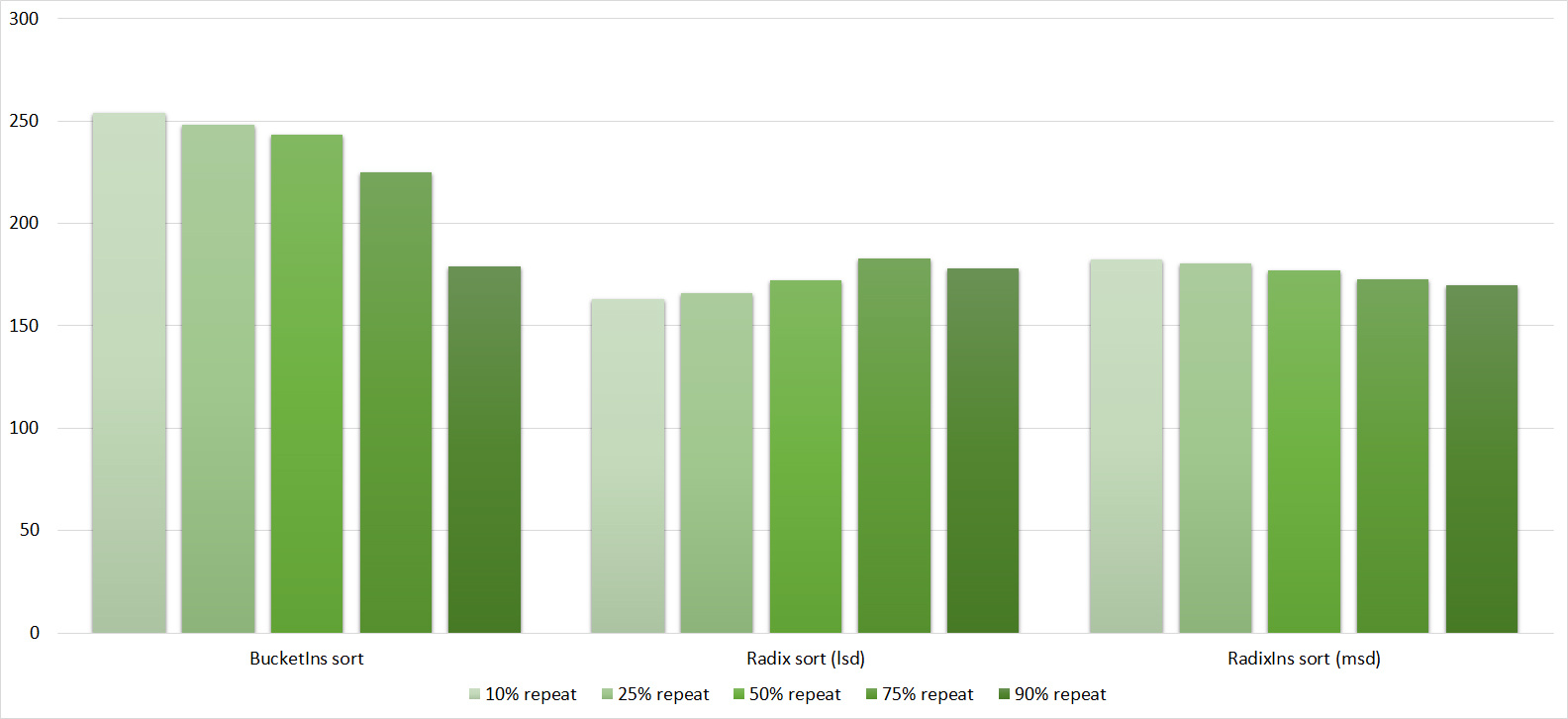

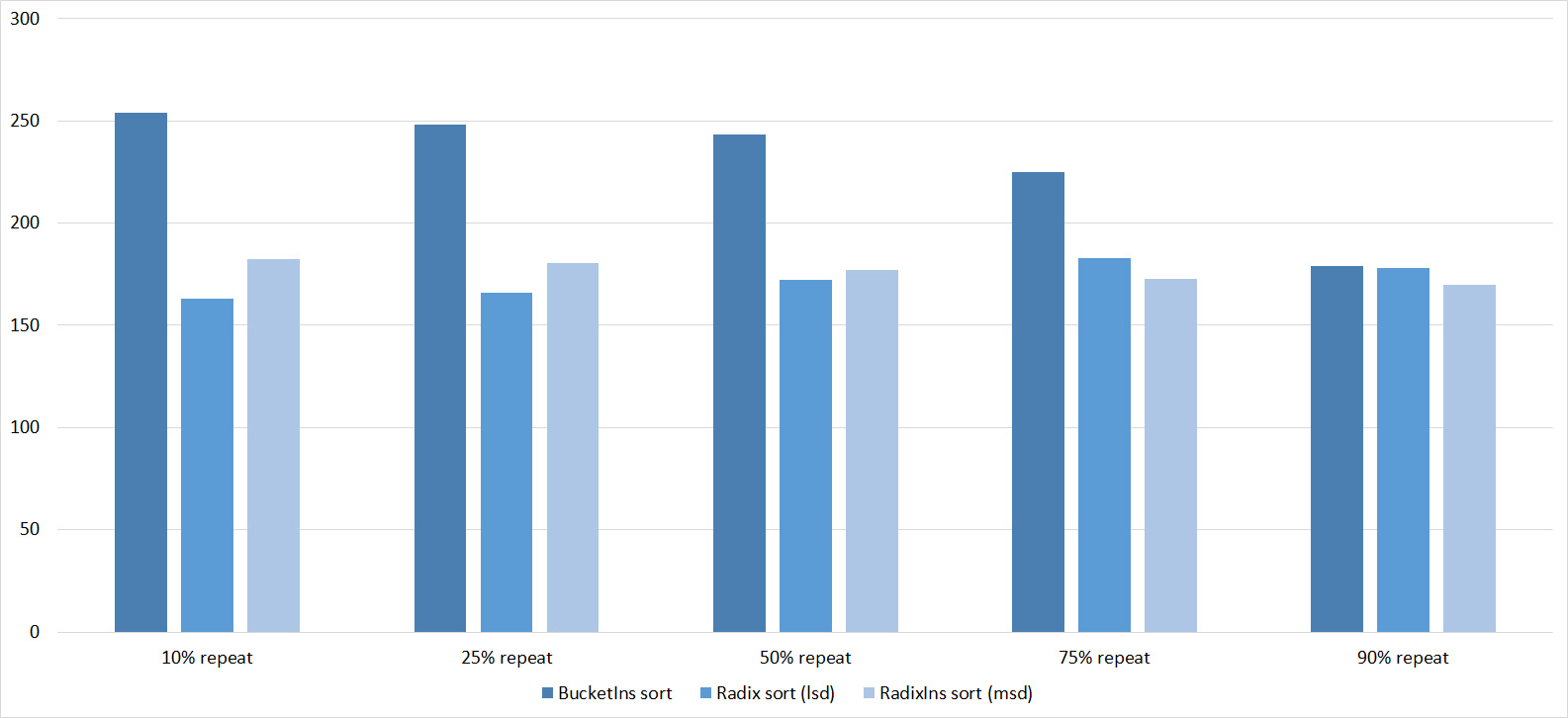

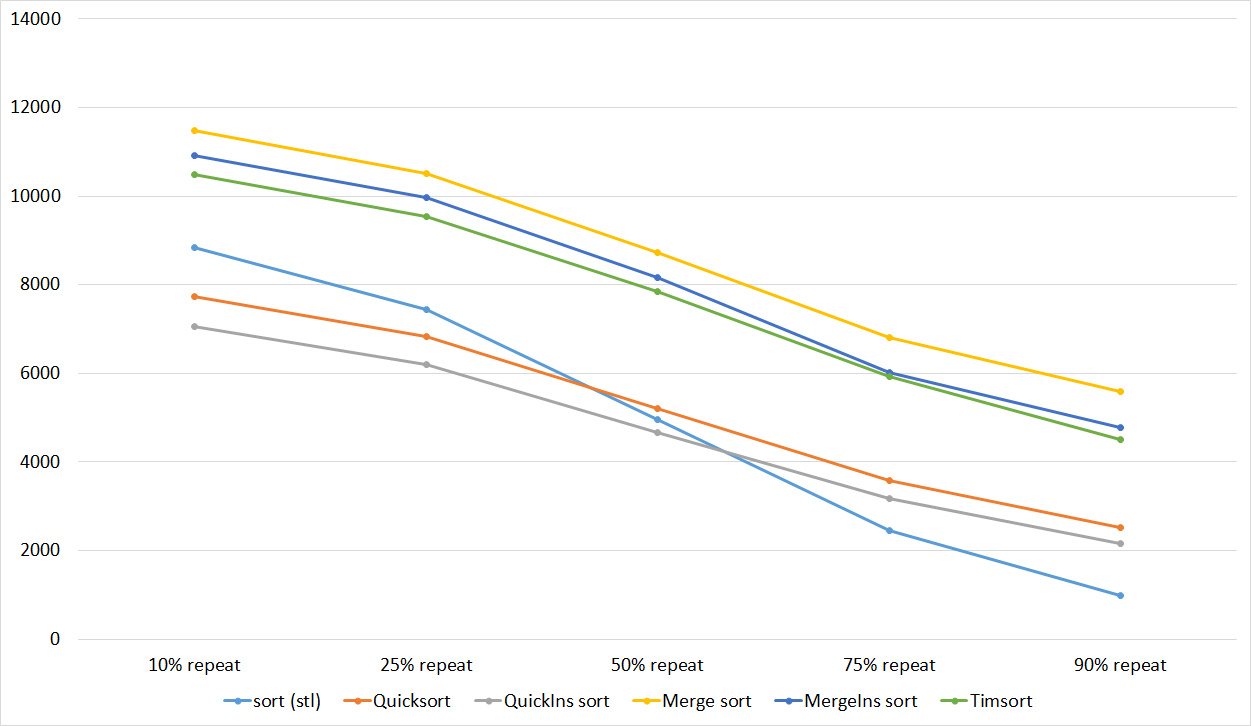
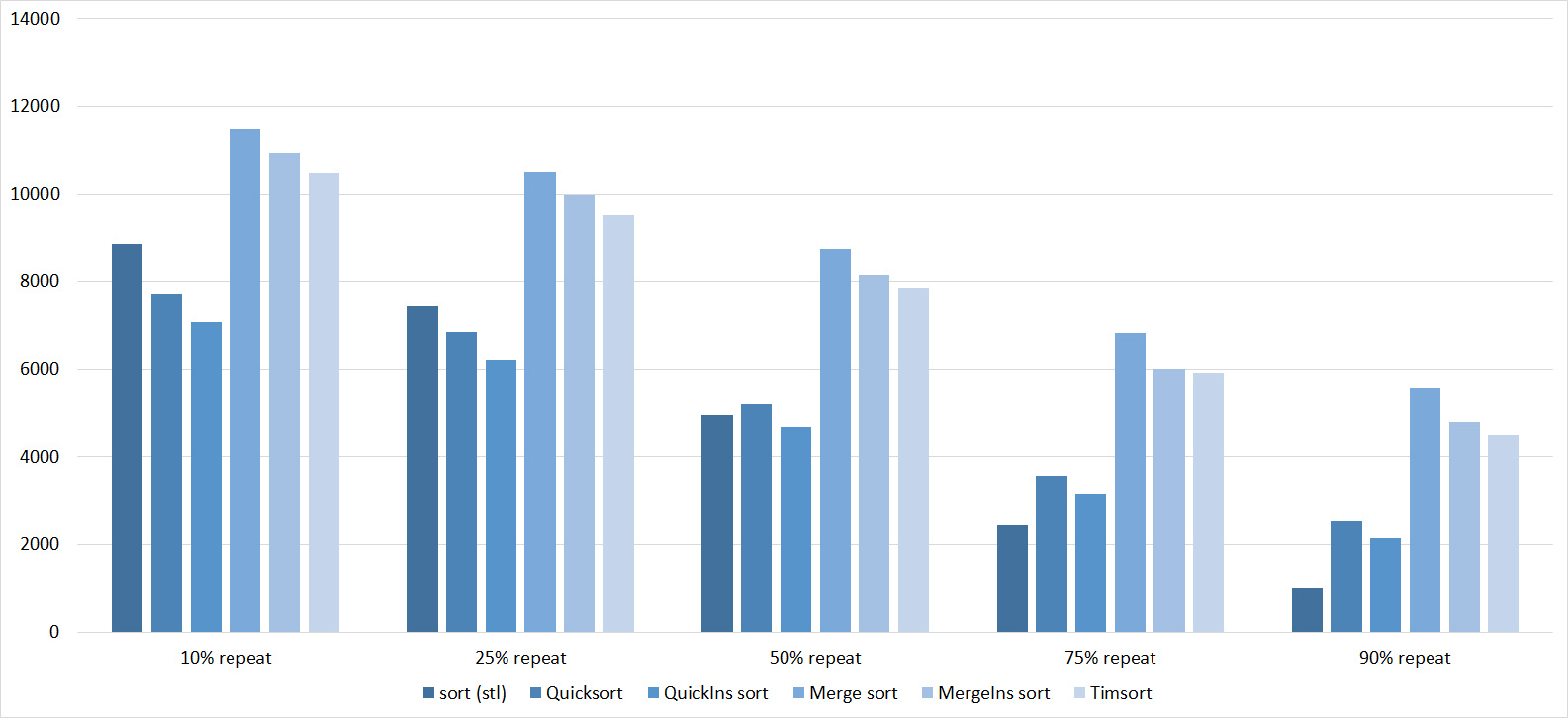
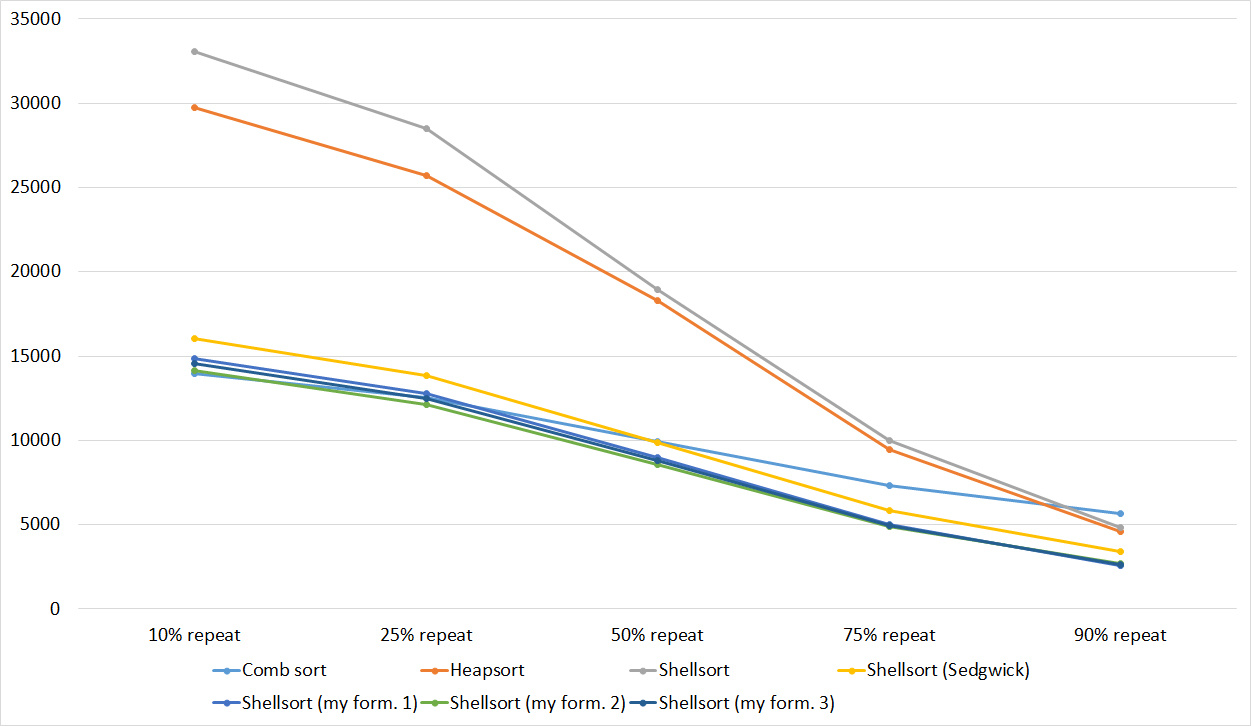
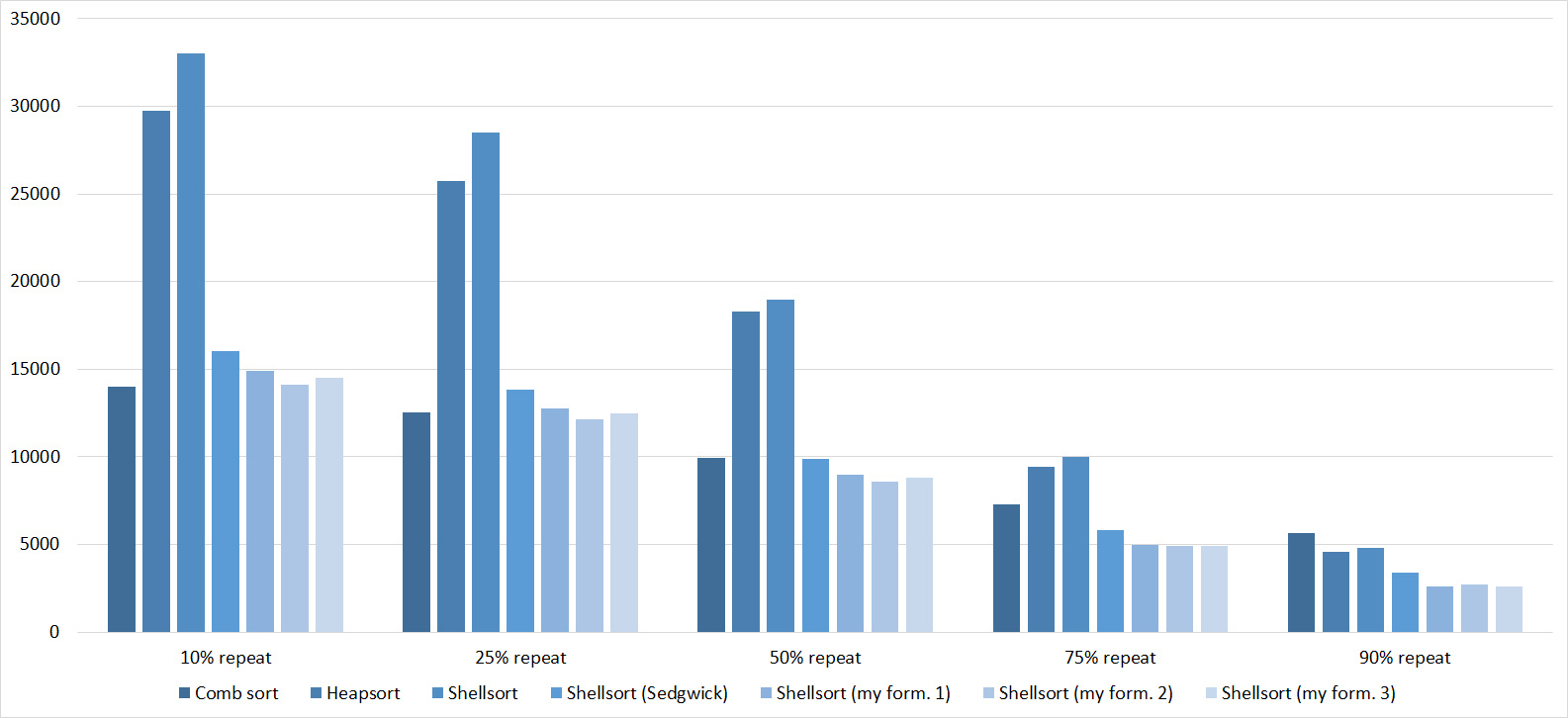
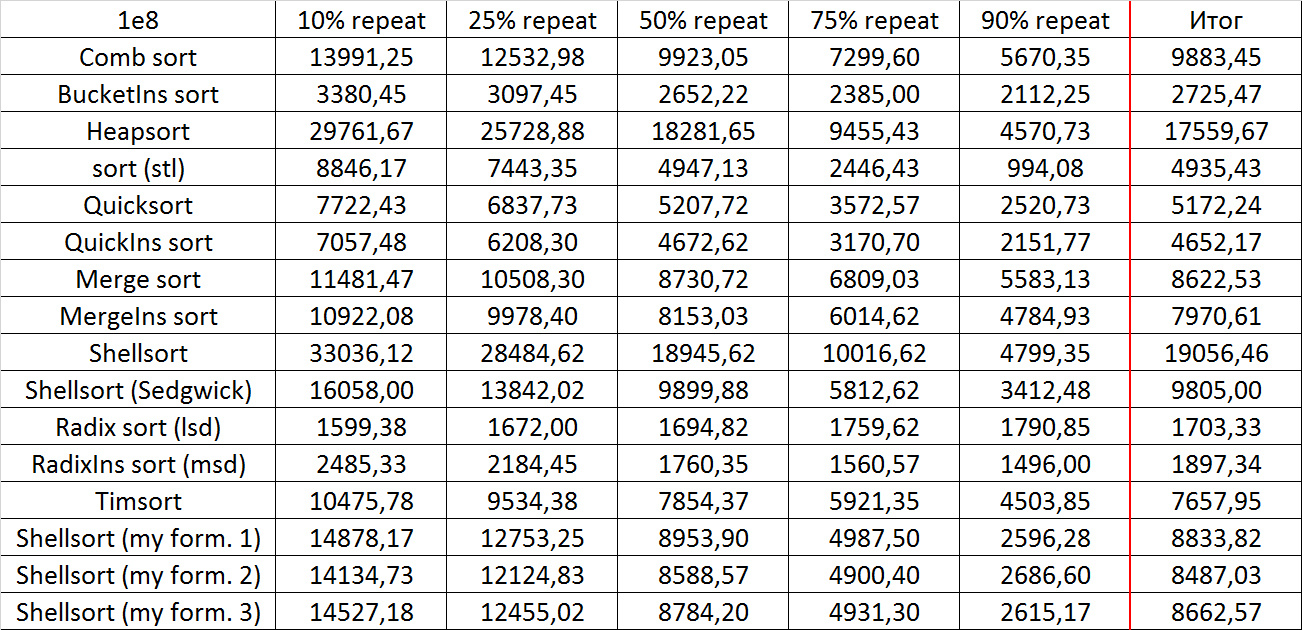
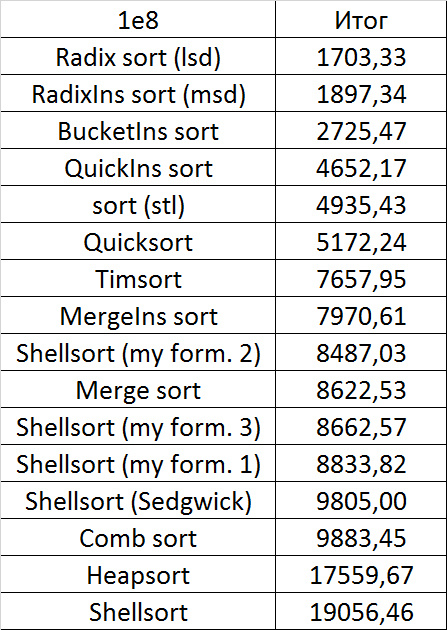
Everything is pretty dreary here, all sortings work with the same dynamics (except for linear ones). From the unusual, you can see that the merge sort fell below the Shell sort.
Final results
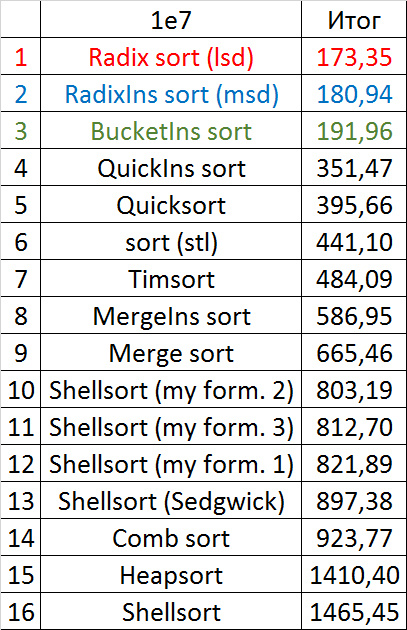

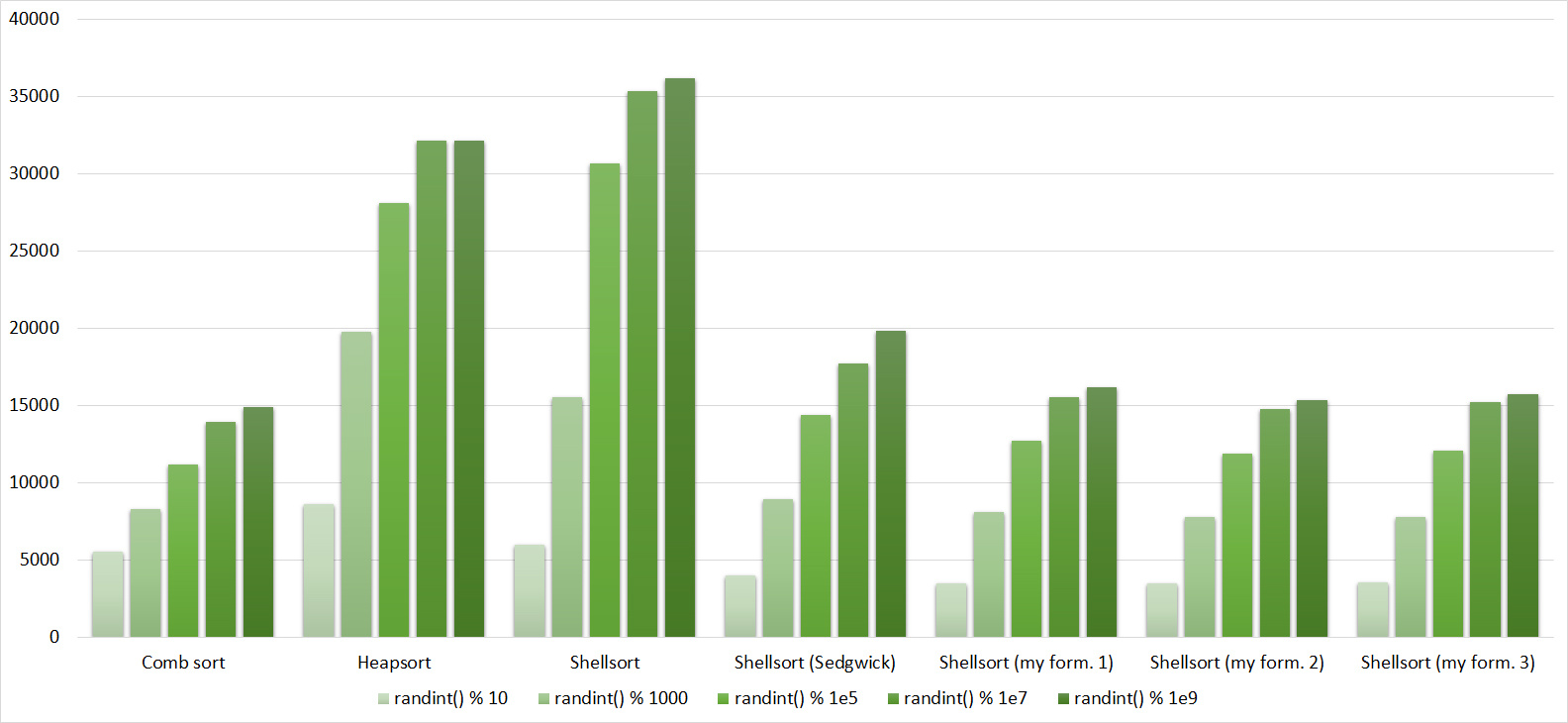
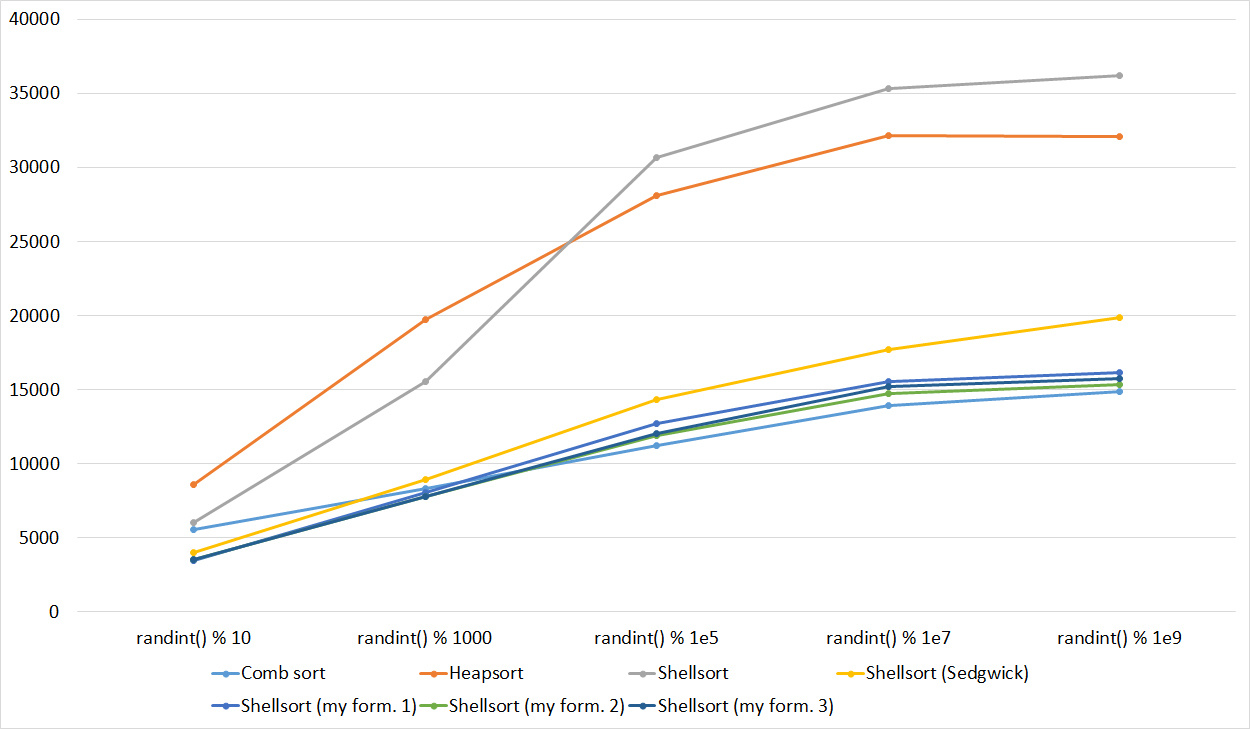
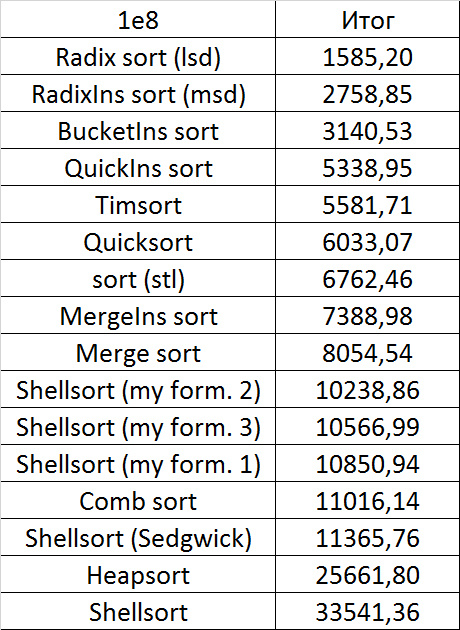
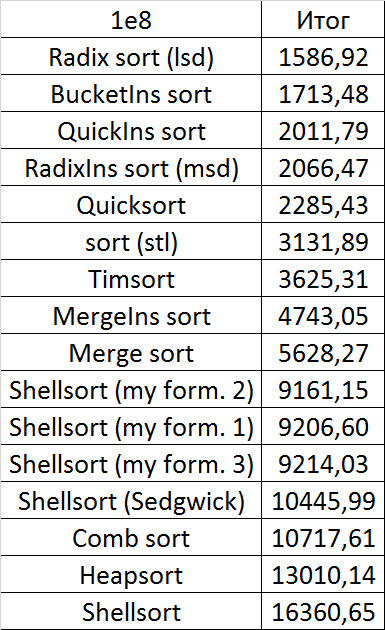
Despite my efforts, the LSD version of bitwise sorting nevertheless took first place at 10 7 and 10 8 elements. She also showed an almost linear increase in time. Her only weakness that I noticed was poor work with permutations. The MSD version worked a little worse, primarily due to the large number of tests consisting of random numbers modulo 10 9. I was satisfied with the implementation of block sorting, despite being cumbersome, it showed a good result. By the way, I noticed this too late, it is not fully optimized, you can still separately create the run and cnt arrays so as not to waste time deleting them. Next, various versions of quick sorting confidently took their places. Timsort failed, in my opinion, to show them serious competition, although he was not far behind. Further in speed are merge sortings, after them are my Shell sort versions. The sequence s * 3 + s / 3 turned out to be the best, where s is the previous element of the sequence. Next is the only discrepancy in the two tables - comb sorting turned out to be better with more elements than Shell sorting with Sedgwick sequence.
The last one won. By the way, Shell sorting, as I later checked, works very poorly on tests of size 2 n , so she was just lucky to be in the first group.
If we talk about practical application, bitwise sorting is good (especially the lsd version), it is stable, easy to implement and very fast, but not based on comparisons. Of the comparisons based on comparisons, quicksort looks best. Its disadvantages are instability and quadratic run time on unsuccessful input data (even if they can only occur with the intentional creation of a test). But you can fight this, for example, by choosing a support element by some other principle, or by switching to another sorting if it fails (for example, introsort, which, if I remember correctly, is implemented in C ++). Timsort lacks these shortcomings, works better on highly sorted data, but is still slower in general and much more difficult to write. The rest of the sorting at the moment, perhaps, is not very practical. Except of course
Conclusion
I must note that not all known sortings took part in testing, for example, smooth sorting was missed (I just could not adequately implement it). However, I don’t think that this is a big loss, this sorting is very bulky and slow, as you can see, for example, from this article: habrahabr.ru/post/133996 You can also investigate sorting for parallelization, but, firstly, I don’t have experience, and secondly, the results that are obtained are extremely unstable, the influence of the system is very great.
Here you can see the results of all launches, as well as some auxiliary tests: a link to the document .
Here you can see the code of the whole project
Implementations of algorithms with vectors remained, but I do not guarantee their correctness and good work. It’s easier to take function codes from the article and redo it. Test generators may also not correspond to reality, in fact they took on this form after creating the tests, when it was necessary to make the program more compact.
In general, I am pleased with the work done, I hope that you were interested.