Holivarny story about the linter
We all write code. Lots of code. Of course, there are errors. Sometimes it's just a curve code, and sometimes the cost of a mistake is a blown up spacecraft . Of course, no one makes intentional jambs, everyone tries to monitor quality to the best of their ability, but without static analysis tools one can hardly be sure that everything is perfect.
Linters help lead the code to a single style and avoid mistakes. However, only if you are ready for suffering, and do not eventually dismiss "pylint: disable", only so that it lags behind. What a linter should be, and why Pylint should not do, Nikita Sobolev ( sobolevn ), who understands and loves linter so much that he even called his company so as not to upset them - wemake.services, knows.
Below is the text version of the report on Moscow Python Conf ++ about linters, how to do them correctly and how not to. There was a lot of interactive, online and communication with the audience. The speaker, along the way, conducted polls and tried to convince listeners: he looked at the trend and, like in debates, tried to equalize the ratio and change public opinion. Some part of the polls fell into deciphering, but not all, so a video is attached to complete the picture.
Why do we need linter?
The most important task of the linter is to bring the code to uniformity . There are many options to write the same thing in Python: put a comma here or there, forget to close the brackets, or remember. When people write code for a long time, it becomes similar to a patchwork of loose pieces sewn at different times. Working with such a blanket is unpleasant, it discourages the desire to read the code, and this is very bad.
Linter make life easier on review . I come to the code review and think: “I don’t want to do this! Now there will be extra spaces and other nonsense! ”I want someone else to prepare a good code, and after that I will appreciate the big conceptual things.
Sometimes I look at the code and think that everything seems fine, and then I see in a function too many variables or an error that I didn’t pay attention to. Automatics would find this error, and I looked through it. In order not to fall into such situations - I use a linter - he finds everything that is hidden and difficult to find.
The simplest ones check only the style , for example, Flake8 . To some extent, it’s also Black, but rather it’s an auto-formatter linter. Linters are harder to check the semantics , and not just the style: what are you doing, why, and beat you in the hands if you write with errors. A good example is Pylint , which we all know, use and love. I call such linters Best practices . The third type is Type checking , these linters are a bit apart. Type checking in Python is a novelty; two competing platforms are doing it now: Mypy and Pyre .
I do not claim that the linters are a panacea and a replacement for everything. This is not true. Linters - the first step of the pyramid, on which the code gets into production.
There are three steps in the pyramid:
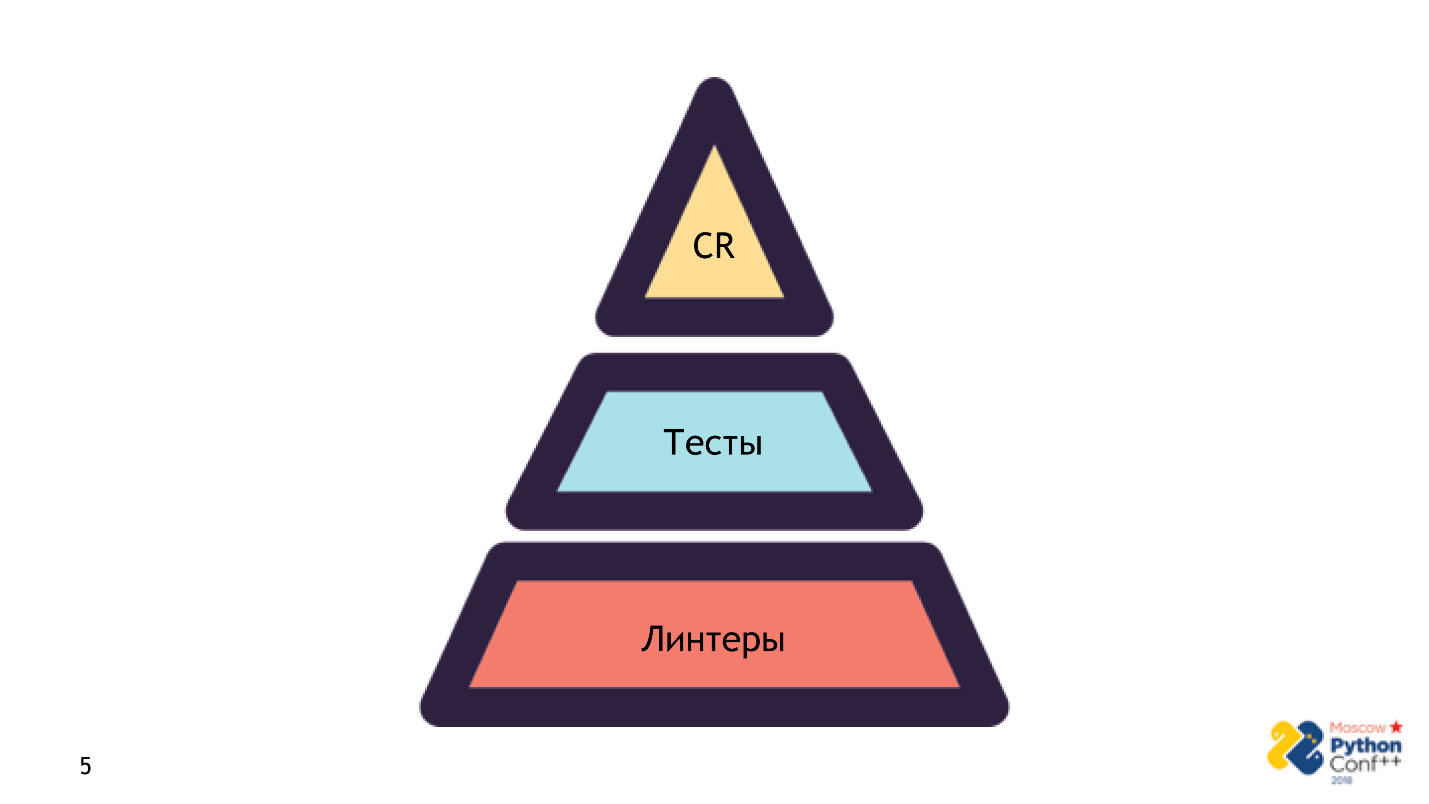
These are necessary steps to get the code into production. If you did not pass one step, you forgot something or the reviewer said that it will not work like this, you will see the inscription: failed - the bad code does not get into production.
If you ask developers from a harsh enterprise, in which they work 7 days a week, whether they use a linter, it turns out that at least a third of them use linters very strictly: CI drops, checks are harsh . The rest are about equally used linters only to check the style , never and as a reporting system : launch the linter, generate a report and see how bad everything is. Linters are used, and this is good. In our company, everything is built very harshly: hard lintting, a lot of checks, a double code review.
Code Review
Problems arise just at this stage. This is the top and most difficult stage of the pyramid: it will not be possible to automate the code review, and if possible, it will lead to the automation of writing code. Then programmers will not be needed.
The standard process looks like this: the code comes to the review, I find errors, and I don’t want to allow them anymore. For example, I saw that a developer caught a BaseException: “Don't be so. Please don't catch it! ” 10 days later the same. Once again I remind:
- BaseException we do not catch.
- Ok, I get it.
A year goes by - the same mistake. A new person comes - the same mistake. I think - how to automate everything so that the situation does not repeat, and only comes to mind: “ Let's flush our linter?»Let's create an open package, put there all the rules that we use in our work and automate the checking of the rules, so that every time we don’t write hands on the code review. We automate everything well and immediately!
Naturally, you can say: “ Ready linters already exist, they work, everyone uses them - why make their own?”, And you will be absolutely right, because there are really linters. Let's see which ones and what they do.
Pylint
On the air heading " Why not Pylint? “I’ve heard this question many times. I will answer it softer. Pylint is a great tool, a rock star for Python code, but it does have features that I don’t want to see in my linter.
It mixes everything together: stylistic checks, Best practices and Type checking . In Pylint Type checking is underdeveloped, because there is no information about the types: it tries to deduce it somehow, but it turns out not very. Therefore, often when I write on Django
Another feature hidden from the user is the Pylint own implementation of Abstract syntax tree in Python . This is what the code looks like when you parse it and get information about the tree of nodes that make up the code. I do not really trust my own implementations, because they are always wrong.
In addition to Pylint, there are other linters who also do their job.
SonarQube
Beautiful, but a separate tool that lives somewhere near your project.
The company, which is engaged in the development of SonarQube, specifically looks at the concept of product development. This can be a problem.
The advantage of SonarQube is that it has very cool checks that show the complexity, possible hidden errors and bugs. I like checks, I would leave them, and I would change the platform.
Flake8
A wonderful linter is very simple, but with one problem: there are few rules with which he checks how well the code is written. At the same time, Flake8 has a lot of very simple plugins: the minimum plug-in is 2 methods that need to be implemented. I thought - let's take Flake8 as a basis and write plugins, but with my own understanding of the benefits to the company. And we did.
The most stringent linter in the world
We made a tool in which we collected everything that we consider correct for Python and called wemake-python-styleguide . The plugin was posted publicly, as I believe that Open Source by Default is a good practice . I am deeply convinced that many tools will benefit if they are laid out in Open Source. For our tool we came up with the slogan: “The most stringent linter in the world!”
If you use a linter, and it doesn’t make you suffer so much that you grab your head: “What else you don’t like, damn you,” then this is a bad linter. It skips errors, does not follow the quality of the code enough, and we do not need it. We need the most stringent in the world, which checks a lot. Now we have about 250 different checks in both categories : stylistic and Best practices, but without Type checking. Mypy does it, we don’t treat it in any way.
Our linter has no compromise. We have no rules of the category "I would not want to do it, but if you really want, then you can." No, we always say harshly — we don’t do it, because it’s bad. Then people come and say: “There is 2.5 use case, where it is possible in principle!”. If such cases, clearly write that here this line is permissible, so that the linter would ignore it, but explain why. This should be a comment, why did you allow some strange practice and why do you do it. This approach is also useful for documenting code.
The most stringent linter does not require configuration (WIP) . We still have the settings, but we want to get rid of them: having freedom, the user will surely adjust so that the linter will not work properly.
With this approach, the code will be consistent and will work the same for everyone, at least in theory. We are still working on this, and while there are settings, you can use our tool and customize it for yourself.
From a large number of tools.
There are 4 groups of rules that we use and enforce.
Difficulty is the biggest problem. We do not know what complexity is and do not see it in the code. We look at the code with which we work every day and it seems that it is not complicated - take, read, everything works. This is not true. Simple code is a familiar code. Difficulty has clear criteria that we check. About the criteria themselves - later. If the code violates the criteria, then we say: “The code is complex, rewrite!”
Names for variables are an unsolved programming problem. Who will read, when and in what context is not clear. We try to make the names as consistent and understandable as possible, but although we are trying, the problem has not yet been fully resolved.
For consistencywe have a simple rule - write the same everywhere. If there is any approved approach, use it everywhere. It doesn't matter if you like it or not, consistency is more important.
We try to use only the best practices. If we know that some practice is not very good, then we prohibit its use. If a developer wants to use a prohibited practice, we expect an argument from him: why and why to apply. Perhaps, during the description process, an understanding will come about why it is bad.
What is complexity?
Complexity has specific metrics that you can look at and say - difficult or not. A lot of them.
Cyclomatic Complexity - everyone's favorite cyclomatic complexity. It finds a large number of nested
Arguments, Statements and Returns. These are quantitative metrics: how many arguments are in a function or method, how many inside the body of this function or the statements and returns method.
Cohesion and Coupling are popular metrics from the OOP world. CohesionShows the connectedness of the class inside. For example, there is a class, and inside you use all the methods and properties - everything that you declared. This is a good class with high cohesion inside. Coupling is how much different parts of the system are connected: modules and classes. We want to achieve maximum cohesion within the class and minimal coherence outside. Then the system is easily maintained and works well.
Jones Complexity - I borrowed this metric, but only because it is a bomb! Jones Complexity determines the complexity of the line - the harder the line, the harder it is to understand, because short-term human memory can not process more than 5-9 objects at once. This is the so-called "Miller's wallet" .
We look at these important metrics and some others, which are much more, and determine whether the code is suitable or not. In our understanding, complexity is a waterfall .
Waterfall difficulty
The difficulty begins with the fact that we have written a line, and it is still good. But then comes the business and says that prices have doubled, and we multiply by 2. At this point Jones Complexity goes crazy and says that now the line is too complicated - there is too much logic.
Well, we start a new variable, and the function complexity analyzer says:
- No, this is impossible - now there are too many variables inside the function.
I will make a new method , and pass arguments to it. Now checking the number of arguments of a function, or the number of methods inside a class says that this is also not possible - the class is too complex and should be split into two parts. Smashed, highlighting another class. Now there are more classes and everything is fine, but the complexity testThe module reports that the module is now too complex and needs to be refactored. Why?!
This is called suffering. That is why I say that the linter must make suffer. We started by multiplying by 2 in one line, and finished refactoring the entire system . Adding a small piece of code leads to refactoring of whole modules, because complexity is spreading out like a waterfall and covers everything that is possible.
“Need to refactor” - this thing makes you refactor code. You can not just sit out: "This code does not touch, like it works." No, once you change the code in another place, and the waterfall of complexity will flood the module that did not touch and you will have to refactor it. I believe that refactoring is good, and the more it is, the more stable and better your system works. And everything else is subjective!
Now let's talk about tastes. This is a holivar and interactive part!
Holivar
Let's talk, comments are open. First, let me remind you that names are a complex and unsolved problem. You can fight because of how to name a variable, but we have some approaches that help at least not to make obvious mistakes.
Names
How do you like these: var, value, item, obj, data, result ? What is data ? Any data. What is result ? Some kind of result. I often see the result variable and a call to some kind of hellish method of an incomprehensible class - and I think: “What is this result? Why is it here? ”
There are many developers who disagree with me, and they say that value is a normal variable name:
- I always use key and value!
- Why not use key and value, but say that the key is the name and value is the last name? Why it is impossible to name first_name and last_name - now there is a context.
Usually people agree, but they still argue. This is a very holivar piece: at least 3 people spent an hour of their lives on me to argue with me about it.
To name variables in one letter is normal?
For example, q ? We all know the classic case:
I believe that it is impossible to give names in one letter. I want more context and it’s good that the second half of the developers agree with me. If in C this is somehow permissible due to historical heritage, then in Python this is a very big problem and you don’t need to do that.
Consistency
Let's just choose one of many ways, and say, "Let's do this." Good or bad - no longer important - just consistently.
We are talking only about Python 3, we don’t consider Legacy at all.
I have an argument: when we are inherited from something, we should know from what it would be nice to see the name of the parent. The funny thing is that we usually see the name of the parent, except when it is an object . Therefore, I formulated a rule for myself: when I write a class, I inherit from something - I always write the name of the parent. It doesn't matter what it will be - Model, object or something else.
If there is a choice to write
Two thirds of developers are more accustomed to the second option, and I even know why. My hypothesis: all because we long migrated from the second version of Python to the third, and now we show that we write on the third Python. I do not know how correct the hypothesis is, but it seems to me that this is so.
F-lines are terrible?
Variants of answers:
There is a hypothesis that f-lines are terrible. They shove anything! F-lines are not the same as the
There are two problems with f-lines. We declared the template for the f-string and everything works. And then we decide to move the template 2 lines up or move it to another function - and everything breaks. Now there is no context that allowed the formatting of strings , and we cannot process them correctly. The second big problem with f-strings: they allow you to do scary -thrust logic into the template . Suppose there is a line in which we simply insert the username and the word “Hello” - this is normal. There is nothing particularly scary, but then we see that the username comes in capital letters, we decide to translate it into the Title case and write directly in the template
All these problems make me say that f-lines are a bad topic , we don’t use them. The funny thing is that we do not have a case in which only f-lines are suitable for us. Usually any formatting is suitable, but we have chosen
Numbers
Whether you like these numbers:
- Please multiply by 147.
- Why by 147?
- We have such a tariff.
I multiplied and forgot, or for a long time picked up some value of the coefficient to make it work - and then I forget how I picked it up and why. It turns out that an important research work remained hidden behind a number without a name. I don’t even know what the number is, but I can only find, recall and restore from the commit only.
Why not do it differently - all complex numbers should be put into their own variable with the name and documentation? For example, for the number 69, write that this is an average in the market, and now the constant has a name and context. I will write a comment that I took a constant on the site of such a study. If the research changes in the future, then I’ll come in and update the data.
Thus, we guarantee that no magic numbers will get through our code and will not complicate it from the inside. They make their way through checking the complexity of each line and say: “Here's the number 4766. What I mean is, I don’t know, figure it out for yourself!” For me it was a great discovery.
But there are exceptions - these are numbers from −10 to 10, numbers 100, 1000 and the like, simply because they are often found without them is difficult. We are tough, but not sadists and think a little.
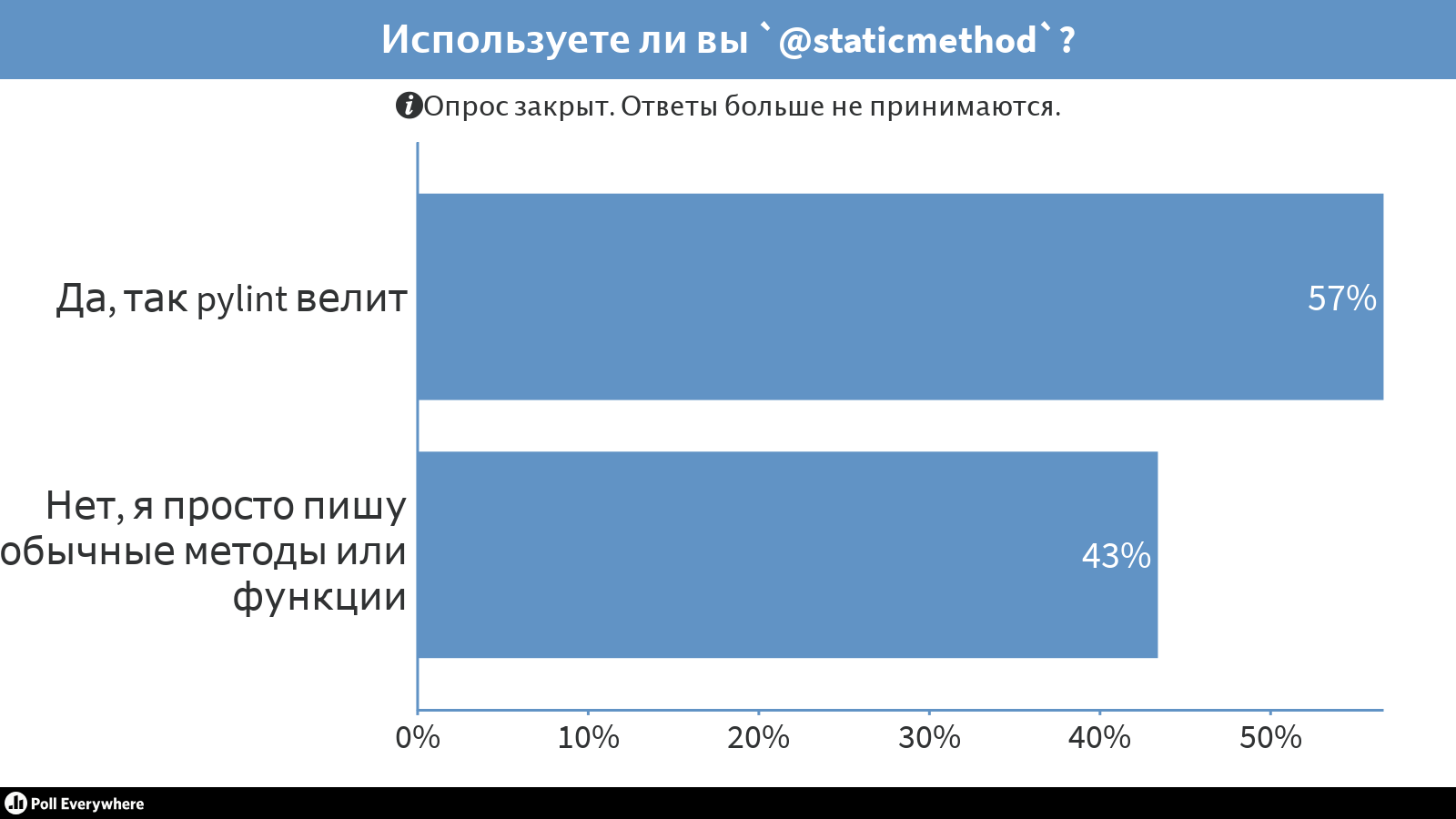
Do you use '@staticmethod'?
Let's think about what staticmethod is . Have you ever wondered why it is in Python? Me not. I had a great pylint, who said:
- Look, you do not use
- Well, Pylint, I will do staticmethod.
Then I taught Python to beginners, and they asked what staticmethod is and why it is needed. I did not know the answer and thought about whether it is possible to write the same function, or not to use it in a regular function
I googled the question, and it turned out to be as deep as a rabbit hole. There are many other programming languages in which staticmethod also do not like. And it is argued that staticmethod breaks the object model. As a result, I realized that staticmethod is not the place , and we sawed it out. Now, if we use the staticmethod decorator, the linter will say: “No, I'm sorry, refactor!”
Most developers disagree with me, but about half still think that it is better to write instead of staticmethod either the usual methods or the usual functions.
Logic in __init __. Ru - good or bad?
This is my favorite topic. Surely, when you create a new package and somehow call it - it creates __init __. Py and you think what to put in it? What to put in __init __. Ru, and what - in files next to each other? For me it was a non-trivial question, and I was always lost: probably something most important? Then I thought, no, on the contrary, I would put the most important in the most understandable context. If you put something in __init __. Ru, and then import it all, you get cyclical imports - also bad.
I looked at various popular libraries, climbed their __init __. Py, and noticed that mostly there is either garbage or backward compatibility. For me, this question has become acute, when I started creating large packages with a lot of subpackages - you get lost. As a result, we decided to bring all possible logic into separate modules, and it works. Nobody breaks Python, everything is fine, just as before, there is simply no logic in __init __. Py, and 90% of the surveyed colleagues agree with us.
You say - well, you changed the API, but you want users to still import what they want, and where they want from? Yes, you can, because the issue of compatibility is separate. We do not want to break the user API by refactoring internal code. Therefore, there are cases in which there may be some logic in __init __. Ru: imports, redefinitions of what you have deleted.
But there is a setting that is called
The hasattr function often need you?
How often does the hasattr function need ? It seems to me that often enough, because in Python dynamic typing is ducky. We sometimes need a hasattr to check for the presence of an argument or attribute on a class (provocation).
In fact, I believe that there is no need for hasattr, this function does not work the way you think. When I talked to developers and asked how hasattr works, they often answered that the function looks for the presence of an attribute. Due to the fact that Python is dynamically and type-typed, hasattr can do anything at all. Sometimes it may even go to the database, and you will not even know about it. Therefore, it is better to use getattrand the “Better apologize than permission” approach. With a combination of these two approaches, you abandon the hasattr function — either getattr or exception .
At the conference, the hall divided 50 to 50 - perhaps it was the most persistent struggle of all the polls, but still my candidate lost the election.
What we want to add to our linter
This is not in our linter, but we really want a layer-linter . What is he doing? You specify in a text format contracts: what can be imported and what is not, in which places you can import and in which not. You create a contract for how business code will be divided into layers within your code. Because of this, you get a great increase in quality without any gestures. Highly recommend.
I have already spoken about cohesion . We do not have this plugin at the base, but we use it. Cohesion looks at how your class is connected inside. He has a lot of False Positive errors and cannot use it in production, but we use it for analytics - we see which classes are good and which are bad. Vulture
pluginuses the search for unused code in Python and allows you to delete it. Due to the fact that Python is a very dynamic language, the plugin gives a lot of errors. Therefore, we use it as a cohesion.
Radon allows you to watch different metrics of your code, there are a lot of them: Halstead , Maintainability Index , cyclomatic complexity. Try it, run the code and see its odds - that's cool.
Final type
I love final classes in python. They were recently added to Typing Extensions, and before that I had my own package, which I wrote myself. I believe that if you made a class, and it can no longer be inherited, this is good, because you just fixed the implementation. If a person says that he still wants to change something, then why? Do not. Use the composition. If you change something - write the documentation, and then, perhaps, it is possible.
Gratis
Our linter appeared thanks to the work of many people, and I am very grateful to them.

All linter contributors are on this slide to say a public thanks to them.
If you want to contribute our linter, you can do it too. Send pool requests, we will review them. Together we will do a cool thing that will help our Python code to become much cleaner, better and more pleasant.
And now let's light up some holivar through interactive. Voting results during a speech under the spoiler. Vote and check if the majority of developers do this, or check out the cheaters, and then drown for your option.
Linters help lead the code to a single style and avoid mistakes. However, only if you are ready for suffering, and do not eventually dismiss "pylint: disable", only so that it lags behind. What a linter should be, and why Pylint should not do, Nikita Sobolev ( sobolevn ), who understands and loves linter so much that he even called his company so as not to upset them - wemake.services, knows.
Below is the text version of the report on Moscow Python Conf ++ about linters, how to do them correctly and how not to. There was a lot of interactive, online and communication with the audience. The speaker, along the way, conducted polls and tried to convince listeners: he looked at the trend and, like in debates, tried to equalize the ratio and change public opinion. Some part of the polls fell into deciphering, but not all, so a video is attached to complete the picture.
Why do we need linter?
The most important task of the linter is to bring the code to uniformity . There are many options to write the same thing in Python: put a comma here or there, forget to close the brackets, or remember. When people write code for a long time, it becomes similar to a patchwork of loose pieces sewn at different times. Working with such a blanket is unpleasant, it discourages the desire to read the code, and this is very bad.
Linter make life easier on review . I come to the code review and think: “I don’t want to do this! Now there will be extra spaces and other nonsense! ”I want someone else to prepare a good code, and after that I will appreciate the big conceptual things.
Sometimes I look at the code and think that everything seems fine, and then I see in a function too many variables or an error that I didn’t pay attention to. Automatics would find this error, and I looked through it. In order not to fall into such situations - I use a linter - he finds everything that is hidden and difficult to find.
What are the linters?
The simplest ones check only the style , for example, Flake8 . To some extent, it’s also Black, but rather it’s an auto-formatter linter. Linters are harder to check the semantics , and not just the style: what are you doing, why, and beat you in the hands if you write with errors. A good example is Pylint , which we all know, use and love. I call such linters Best practices . The third type is Type checking , these linters are a bit apart. Type checking in Python is a novelty; two competing platforms are doing it now: Mypy and Pyre .
How to use linters?
I do not claim that the linters are a panacea and a replacement for everything. This is not true. Linters - the first step of the pyramid, on which the code gets into production.
There are three steps in the pyramid:
- Run the linters . It is very fast and does not need anything except the source code - no infrastructure, no settings. Check: the first sanity check has passed - everything is fine, we are working further.
- Stage tests . This process is more complicated and longer due to errors not related to the code. We already need the correct and complete setup of the entire application.
- Stage Review .
These are necessary steps to get the code into production. If you did not pass one step, you forgot something or the reviewer said that it will not work like this, you will see the inscription: failed - the bad code does not get into production.
Do you use a linter at work?
If you ask developers from a harsh enterprise, in which they work 7 days a week, whether they use a linter, it turns out that at least a third of them use linters very strictly: CI drops, checks are harsh . The rest are about equally used linters only to check the style , never and as a reporting system : launch the linter, generate a report and see how bad everything is. Linters are used, and this is good. In our company, everything is built very harshly: hard lintting, a lot of checks, a double code review.
Code Review
Problems arise just at this stage. This is the top and most difficult stage of the pyramid: it will not be possible to automate the code review, and if possible, it will lead to the automation of writing code. Then programmers will not be needed.
The standard process looks like this: the code comes to the review, I find errors, and I don’t want to allow them anymore. For example, I saw that a developer caught a BaseException: “Don't be so. Please don't catch it! ” 10 days later the same. Once again I remind:
- BaseException we do not catch.
- Ok, I get it.
A year goes by - the same mistake. A new person comes - the same mistake. I think - how to automate everything so that the situation does not repeat, and only comes to mind: “ Let's flush our linter?»Let's create an open package, put there all the rules that we use in our work and automate the checking of the rules, so that every time we don’t write hands on the code review. We automate everything well and immediately!
Naturally, you can say: “ Ready linters already exist, they work, everyone uses them - why make their own?”, And you will be absolutely right, because there are really linters. Let's see which ones and what they do.
Pylint
On the air heading " Why not Pylint? “I’ve heard this question many times. I will answer it softer. Pylint is a great tool, a rock star for Python code, but it does have features that I don’t want to see in my linter.
It mixes everything together: stylistic checks, Best practices and Type checking . In Pylint Type checking is underdeveloped, because there is no information about the types: it tries to deduce it somehow, but it turns out not very. Therefore, often when I write on Django
model_name.some_property, I can see the error: “Sorry, there is no such property - you cannot use it!” I remember that there is a plug-in, I put it, then I use Celery, some trouble also begins with it, I put the plug-in for Celery, I use some more sometime a magical library, and in the end I just write everywhere: “pylint: disable” ... This is not what I want to get from the linter. Another feature hidden from the user is the Pylint own implementation of Abstract syntax tree in Python . This is what the code looks like when you parse it and get information about the tree of nodes that make up the code. I do not really trust my own implementations, because they are always wrong.
In addition to Pylint, there are other linters who also do their job.
SonarQube
Beautiful, but a separate tool that lives somewhere near your project.
- SonarQube will not be able to run frequently : it needs to be placed somewhere, watched, monitored, tuned.
- It is written in Java . If you want to fix your linter for Python, then you will write code in Java. I believe that conceptually this is wrong - a developer who can write in Python should be able to write code to test Python.
The company, which is engaged in the development of SonarQube, specifically looks at the concept of product development. This can be a problem.
The advantage of SonarQube is that it has very cool checks that show the complexity, possible hidden errors and bugs. I like checks, I would leave them, and I would change the platform.
Flake8
A wonderful linter is very simple, but with one problem: there are few rules with which he checks how well the code is written. At the same time, Flake8 has a lot of very simple plugins: the minimum plug-in is 2 methods that need to be implemented. I thought - let's take Flake8 as a basis and write plugins, but with my own understanding of the benefits to the company. And we did.
The most stringent linter in the world
We made a tool in which we collected everything that we consider correct for Python and called wemake-python-styleguide . The plugin was posted publicly, as I believe that Open Source by Default is a good practice . I am deeply convinced that many tools will benefit if they are laid out in Open Source. For our tool we came up with the slogan: “The most stringent linter in the world!”
The key word in our linter is strict, which means pain and suffering.
If you use a linter, and it doesn’t make you suffer so much that you grab your head: “What else you don’t like, damn you,” then this is a bad linter. It skips errors, does not follow the quality of the code enough, and we do not need it. We need the most stringent in the world, which checks a lot. Now we have about 250 different checks in both categories : stylistic and Best practices, but without Type checking. Mypy does it, we don’t treat it in any way.
Our linter has no compromise. We have no rules of the category "I would not want to do it, but if you really want, then you can." No, we always say harshly — we don’t do it, because it’s bad. Then people come and say: “There is 2.5 use case, where it is possible in principle!”. If such cases, clearly write that here this line is permissible, so that the linter would ignore it, but explain why. This should be a comment, why did you allow some strange practice and why do you do it. This approach is also useful for documenting code.
The most stringent linter does not require configuration (WIP) . We still have the settings, but we want to get rid of them: having freedom, the user will surely adjust so that the linter will not work properly.
A good tool in the settings does not need - it has good default values.
With this approach, the code will be consistent and will work the same for everyone, at least in theory. We are still working on this, and while there are settings, you can use our tool and customize it for yourself.
Who do you depend on?
From a large number of tools.
- Flake8 .
- Eradicate is a cool plugin that finds commented out snippets in the code and forces you to delete them, because storing dead code in a project is bad. We do not allow to do so.
- Isort is a tool that makes sorting imports correctly: in order, indenting, beautiful quotes.
- Bandit is a great utility for checking code security statically. He finds stitched passwords, clumsy uses
assertin the code, callsPopen,sys.exitand says that all this cannot be used, and if he wants to, he asks to write a reason. - And even more than 20 plugins that check brackets, quotes and commas.
What are we checking?
There are 4 groups of rules that we use and enforce.
Difficulty is the biggest problem. We do not know what complexity is and do not see it in the code. We look at the code with which we work every day and it seems that it is not complicated - take, read, everything works. This is not true. Simple code is a familiar code. Difficulty has clear criteria that we check. About the criteria themselves - later. If the code violates the criteria, then we say: “The code is complex, rewrite!”
Names for variables are an unsolved programming problem. Who will read, when and in what context is not clear. We try to make the names as consistent and understandable as possible, but although we are trying, the problem has not yet been fully resolved.
For consistencywe have a simple rule - write the same everywhere. If there is any approved approach, use it everywhere. It doesn't matter if you like it or not, consistency is more important.
We try to use only the best practices. If we know that some practice is not very good, then we prohibit its use. If a developer wants to use a prohibited practice, we expect an argument from him: why and why to apply. Perhaps, during the description process, an understanding will come about why it is bad.
What is complexity?
Complexity has specific metrics that you can look at and say - difficult or not. A lot of them.
Cyclomatic Complexity - everyone's favorite cyclomatic complexity. It finds a large number of nested
if, forother structures in the code , and indicates that the code is too extensive and difficult to read. With the nested code, everything is bad: you read, you read, you read - you go back, you read, you read, you read - you jumped up, then in another cycle. It is impossible to safely pass such a code from top to bottom. Arguments, Statements and Returns. These are quantitative metrics: how many arguments are in a function or method, how many inside the body of this function or the statements and returns method.
Cohesion and Coupling are popular metrics from the OOP world. CohesionShows the connectedness of the class inside. For example, there is a class, and inside you use all the methods and properties - everything that you declared. This is a good class with high cohesion inside. Coupling is how much different parts of the system are connected: modules and classes. We want to achieve maximum cohesion within the class and minimal coherence outside. Then the system is easily maintained and works well.
Jones Complexity - I borrowed this metric, but only because it is a bomb! Jones Complexity determines the complexity of the line - the harder the line, the harder it is to understand, because short-term human memory can not process more than 5-9 objects at once. This is the so-called "Miller's wallet" .
We look at these important metrics and some others, which are much more, and determine whether the code is suitable or not. In our understanding, complexity is a waterfall .
Waterfall difficulty
The difficulty begins with the fact that we have written a line, and it is still good. But then comes the business and says that prices have doubled, and we multiply by 2. At this point Jones Complexity goes crazy and says that now the line is too complicated - there is too much logic.
Well, we start a new variable, and the function complexity analyzer says:
- No, this is impossible - now there are too many variables inside the function.
I will make a new method , and pass arguments to it. Now checking the number of arguments of a function, or the number of methods inside a class says that this is also not possible - the class is too complex and should be split into two parts. Smashed, highlighting another class. Now there are more classes and everything is fine, but the complexity testThe module reports that the module is now too complex and needs to be refactored. Why?!
This is called suffering. That is why I say that the linter must make suffer. We started by multiplying by 2 in one line, and finished refactoring the entire system . Adding a small piece of code leads to refactoring of whole modules, because complexity is spreading out like a waterfall and covers everything that is possible.
“Need to refactor” - this thing makes you refactor code. You can not just sit out: "This code does not touch, like it works." No, once you change the code in another place, and the waterfall of complexity will flood the module that did not touch and you will have to refactor it. I believe that refactoring is good, and the more it is, the more stable and better your system works. And everything else is subjective!
Now let's talk about tastes. This is a holivar and interactive part!
Holivar
Let's talk, comments are open. First, let me remind you that names are a complex and unsolved problem. You can fight because of how to name a variable, but we have some approaches that help at least not to make obvious mistakes.
Names
How do you like these: var, value, item, obj, data, result ? What is data ? Any data. What is result ? Some kind of result. I often see the result variable and a call to some kind of hellish method of an incomprehensible class - and I think: “What is this result? Why is it here? ”
There are many developers who disagree with me, and they say that value is a normal variable name:
- I always use key and value!
- Why not use key and value, but say that the key is the name and value is the last name? Why it is impossible to name first_name and last_name - now there is a context.
Usually people agree, but they still argue. This is a very holivar piece: at least 3 people spent an hour of their lives on me to argue with me about it.
To name variables in one letter is normal?
For example, q ? We all know the classic case:
for i in some_iterable:. What is i ? In C, this is standard practice, and from it everything goes. But in Python, collections and iterators. In the collections are elements that have names - let's call them somehow differently.Half of the developers think that calling variables i, x, y, z is normal.
I believe that it is impossible to give names in one letter. I want more context and it’s good that the second half of the developers agree with me. If in C this is somehow permissible due to historical heritage, then in Python this is a very big problem and you don’t need to do that.
Consistency
Let's just choose one of many ways, and say, "Let's do this." Good or bad - no longer important - just consistently.
We are talking only about Python 3, we don’t consider Legacy at all.
I have an argument: when we are inherited from something, we should know from what it would be nice to see the name of the parent. The funny thing is that we usually see the name of the parent, except when it is an object . Therefore, I formulated a rule for myself: when I write a class, I inherit from something - I always write the name of the parent. It doesn't matter what it will be - Model, object or something else.
If there is a choice to write
Class Some(object)or class Some, then I will choose the first one. On the one hand, it shows that we obviously always write what we inherit from. On the other hand, it does not have much verbosity: we do not lose anything from a few extra keystrokes. Two thirds of developers are more accustomed to the second option, and I even know why. My hypothesis: all because we long migrated from the second version of Python to the third, and now we show that we write on the third Python. I do not know how correct the hypothesis is, but it seems to me that this is so.
F-lines are terrible?
Variants of answers:
- Yes: they lose context, thrust logic into a pattern and are not lazy - (38%).
- Not! They are a miracle! - (62%).
There is a hypothesis that f-lines are terrible. They shove anything! F-lines are not the same as the
.formatdifferences are cardinal. When we declare a template and then format it, we perform two actions separately: first, we define the template, and then we format it. When we declare an f-string, we perform two actions at the same time: we immediately declare the template and format it at the same time. There are two problems with f-lines. We declared the template for the f-string and everything works. And then we decide to move the template 2 lines up or move it to another function - and everything breaks. Now there is no context that allowed the formatting of strings , and we cannot process them correctly. The second big problem with f-strings: they allow you to do scary -thrust logic into the template . Suppose there is a line in which we simply insert the username and the word “Hello” - this is normal. There is nothing particularly scary, but then we see that the username comes in capital letters, we decide to translate it into the Title case and write directly in the template
username.title(). Then conditions, cycles, imports appear in the template. And all the other parts of php. All these problems make me say that f-lines are a bad topic , we don’t use them. The funny thing is that we do not have a case in which only f-lines are suitable for us. Usually any formatting is suitable, but we have chosen
.format - everything else is impossible — neither %, nor f-lines. Work.format we also merge because you can put curly quotes inside it and write either the name of the variable or its order.During the report, the number of opponents of f-lines increased from 33 to 38% - this is a small, but a victory.
Numbers
Whether you like these numbers:
final_score = 69 * previous result / 3.14. It seems that this is a standard line of code, but what is 69? Such questions often arise when I look at the code that I wrote some time ago, and the manager at the time says: - Please multiply by 147.
- Why by 147?
- We have such a tariff.
I multiplied and forgot, or for a long time picked up some value of the coefficient to make it work - and then I forget how I picked it up and why. It turns out that an important research work remained hidden behind a number without a name. I don’t even know what the number is, but I can only find, recall and restore from the commit only.
Why not do it differently - all complex numbers should be put into their own variable with the name and documentation? For example, for the number 69, write that this is an average in the market, and now the constant has a name and context. I will write a comment that I took a constant on the site of such a study. If the research changes in the future, then I’ll come in and update the data.
Thus, we guarantee that no magic numbers will get through our code and will not complicate it from the inside. They make their way through checking the complexity of each line and say: “Here's the number 4766. What I mean is, I don’t know, figure it out for yourself!” For me it was a great discovery.
As a result, we realized that this should be monitored, and we don’t miss any magic numbers in the code. It's good that almost 100% of our colleagues agree with us, and they also do not use such numbers.
But there are exceptions - these are numbers from −10 to 10, numbers 100, 1000 and the like, simply because they are often found without them is difficult. We are tough, but not sadists and think a little.
Do you use '@staticmethod'?
Let's think about what staticmethod is . Have you ever wondered why it is in Python? Me not. I had a great pylint, who said:
- Look, you do not use
self , cls - do staticmethod! - Well, Pylint, I will do staticmethod.
Then I taught Python to beginners, and they asked what staticmethod is and why it is needed. I did not know the answer and thought about whether it is possible to write the same function, or not to use it in a regular function
self, simply because it is such a class and something happens. Why do we need staticmethod construction?I googled the question, and it turned out to be as deep as a rabbit hole. There are many other programming languages in which staticmethod also do not like. And it is argued that staticmethod breaks the object model. As a result, I realized that staticmethod is not the place , and we sawed it out. Now, if we use the staticmethod decorator, the linter will say: “No, I'm sorry, refactor!”
Most developers disagree with me, but about half still think that it is better to write instead of staticmethod either the usual methods or the usual functions.
Logic in __init __. Ru - good or bad?
This is my favorite topic. Surely, when you create a new package and somehow call it - it creates __init __. Py and you think what to put in it? What to put in __init __. Ru, and what - in files next to each other? For me it was a non-trivial question, and I was always lost: probably something most important? Then I thought, no, on the contrary, I would put the most important in the most understandable context. If you put something in __init __. Ru, and then import it all, you get cyclical imports - also bad.
I looked at various popular libraries, climbed their __init __. Py, and noticed that mostly there is either garbage or backward compatibility. For me, this question has become acute, when I started creating large packages with a lot of subpackages - you get lost. As a result, we decided to bring all possible logic into separate modules, and it works. Nobody breaks Python, everything is fine, just as before, there is simply no logic in __init __. Py, and 90% of the surveyed colleagues agree with us.
You say - well, you changed the API, but you want users to still import what they want, and where they want from? Yes, you can, because the issue of compatibility is separate. We do not want to break the user API by refactoring internal code. Therefore, there are cases in which there may be some logic in __init __. Ru: imports, redefinitions of what you have deleted.
But there is a setting that is called
I_CONTROL_CODE - I control the code. This is the case when it is justified. When I control the code I use, there is no logic in __init __. Py - only documentation. But if I don’t control the code, it is used by other people who download my library, do something, then you can put redefinitions and imports there.The hasattr function often need you?
How often does the hasattr function need ? It seems to me that often enough, because in Python dynamic typing is ducky. We sometimes need a hasattr to check for the presence of an argument or attribute on a class (provocation).
In fact, I believe that there is no need for hasattr, this function does not work the way you think. When I talked to developers and asked how hasattr works, they often answered that the function looks for the presence of an attribute. Due to the fact that Python is dynamically and type-typed, hasattr can do anything at all. Sometimes it may even go to the database, and you will not even know about it. Therefore, it is better to use getattrand the “Better apologize than permission” approach. With a combination of these two approaches, you abandon the hasattr function — either getattr or exception .
At the conference, the hall divided 50 to 50 - perhaps it was the most persistent struggle of all the polls, but still my candidate lost the election.
What we want to add to our linter
This is not in our linter, but we really want a layer-linter . What is he doing? You specify in a text format contracts: what can be imported and what is not, in which places you can import and in which not. You create a contract for how business code will be divided into layers within your code. Because of this, you get a great increase in quality without any gestures. Highly recommend.
I have already spoken about cohesion . We do not have this plugin at the base, but we use it. Cohesion looks at how your class is connected inside. He has a lot of False Positive errors and cannot use it in production, but we use it for analytics - we see which classes are good and which are bad. Vulture
pluginuses the search for unused code in Python and allows you to delete it. Due to the fact that Python is a very dynamic language, the plugin gives a lot of errors. Therefore, we use it as a cohesion.
Radon allows you to watch different metrics of your code, there are a lot of them: Halstead , Maintainability Index , cyclomatic complexity. Try it, run the code and see its odds - that's cool.
Final type
I love final classes in python. They were recently added to Typing Extensions, and before that I had my own package, which I wrote myself. I believe that if you made a class, and it can no longer be inherited, this is good, because you just fixed the implementation. If a person says that he still wants to change something, then why? Do not. Use the composition. If you change something - write the documentation, and then, perhaps, it is possible.
Gratis
Our linter appeared thanks to the work of many people, and I am very grateful to them.
All linter contributors are on this slide to say a public thanks to them.
If you want to contribute our linter, you can do it too. Send pool requests, we will review them. Together we will do a cool thing that will help our Python code to become much cleaner, better and more pleasant.
By the way, Nikita Sobolev joined the Moscow Python Conf ++ program committee , and helps in preparing the classroom program. The conference in two months, and we have already selected two thirds of the reports, you can study them here and decide to participate in our productive event for Python programmers.
And now let's light up some holivar through interactive. Voting results during a speech under the spoiler. Vote and check if the majority of developers do this, or check out the cheaters, and then drown for your option.
View someone else's opinion


Only registered users can participate in the survey. Sign in , please.