Virtuozzo: What are the real benefits of distributed storage?

There are many technologies that allow you to save important information in case of failure of the media, as well as speed up access to important data. But our Virtuozzo Storage hyper-converged storage outperforms open source software-defined solutions, as well as off-the-shelf SAN or NAS systems. And today we are talking about the architecture of the system and its advantages.
To begin with, it’s worth mentioning what Virtuozzo Storage is (VZ Storage in the development environment). The solution is a distributed storage that uses the same infrastructure that your virtual machines and containers are running on (the so-called hyper-converged infrastructure). Initially, the product developed along with Virtuozzo virtualization. However, if you do not need a full-fledged virtualization system, the project is now available as a separate distributed storage that can work with any clients.
Generally speaking, VZ Storage uses drives in the same servers that serve the virtualization system. Thus, you no longer need to purchase separate equipment, for example, an expensive SAN / NAS controller, to create a network storage environment. One of the distinguishing features of VZ Storage is the choice of data storage method (redundancy scheme) for different categories of data. Temporary logs, for example, may not be backed up at all, and for important data various protection technologies are provided - replication (full duplication) or self-healing codes (Erasure Coding).
Iron
Since VZ Storage is a hyper converged storage system, it can be deployed using any x86 standard architecture server. However, in order for the system to work efficiently, at least three hard disks with at least 100 GB each, a dual-core processor (we give the core to the storage), and 2 GB of RAM must be installed in each server. In more powerful configurations, we recommend installing one processor core and 4GB of memory for every 8 hard drives. That is, using, for example, 15 disks on the node to create storage, to support the operation of the storage cluster, you need only 2 cores and 8GB of RAM.
Since we are talking about distributed storage, servers must be networked. Theoretically, you can use the same data network on which the virtualization cluster works, but it is much more efficient to have a second network adapter with a bandwidth of at least 1 Gb / s, because the speed of reading and writing data will directly depend on the characteristics of the network. In addition, a separate network will be useful from a security point of view.
Architecture
The distributed architecture of VZ Storage implies that we install various system components on physical or virtual servers: a control panel with a graphical interface, a data storage server (Chunk Server - CS), a metadata server (MetaData Server - MDS), and mounting a storage for reading / writing data (Client). One node can run multiple components in any combination. That is, one server, for example, can simultaneously store both data and metadata, and run virtual machines, and provide a cluster control panel.

All data in the cluster is divided into blocks of a fixed size (“chunks” - chunks). For each “chunk” several replicas (its copies) are created, and they are placed on different machines (to ensure fault tolerance in case of failure of the whole machine). When installing the cluster, you specify the normal and minimum number of replicas. If some machine crashes or the drive stops working, the cluster forces will play all the lost replicas on the remaining ones - up to the normal number parameter (usually 3). At this time, the system still allows you to write part of the data without delay. But, if, due to a failure, the number of copies fell below the minimum value (usually 2), that is, two components simultaneously failed, the cluster only allows you to read data, and for recording, clients will have to wait until at least the minimum number of copies has been restored. The system restores the chunks with which it is working, with the highest priority.
The number of CS and MDS on each server is determined by the number of physical disks. VZ Storage binds one component to one drive, thereby creating a clear separation of resources and replicas between different physical equipment.
What are the advantages?
We got a little acquainted with the structure and requirements of VZ Storage, and now the question arises, why is all this necessary? What are the advantages of the system? The most important advantage of VZ Storage is its reliability. Using the same equipment (possibly adding network controllers and disks to it), you get a highly efficient, easily scalable system with a streamlined mechanism for working with data and metadata. VZ Storage provides continuous and reliable data storage, including VM disks and container application data for Docker, Kubernetes or Rancher.
The second plus is low cost of ownership (TCO). In addition to the fact that the solution does not need to purchase a separate expensive hardware and you can choose backup options for various data, VZ Storage has the ability to use erasure coding (redundancy codes such as Reed-Solomon). This reduces overall capacity requirements while maintaining the ability to recover data in the event of a failure. The method is suitable for storing large amounts of data when the highest access speed is far from the most important thing.
What are the benefits of erasure coding (EC)? Erasure codding can significantly reduce disk usage. This is achieved through special data processing.
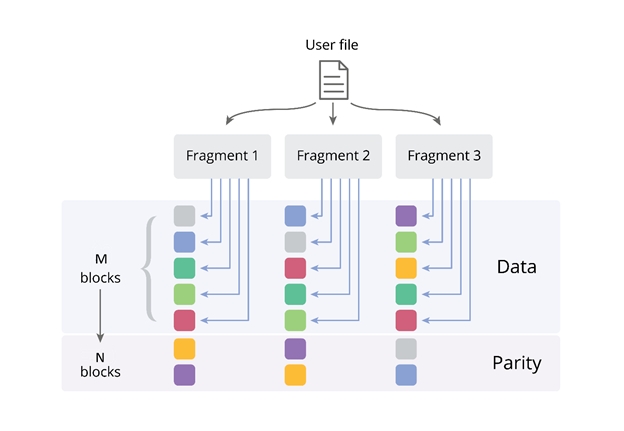
With the redundancy formula M + N [/ X], EC allows you to use much less disk space. If M is the number of data blocks, N is the number of blocks of special checksums (“Parity”), and X is the write permissibility parameter (it is characterized by how many nodes of the storage system may be unavailable when the client can still write data to its files). For the system to work, the minimum number of nodes in VZ Storage must be 5 (in this case, M = 3, N = 2, or “3 + 2”). The picture shows an example where M = 5, N = 2 or “5 + 2”.
On the example of installing a system with a 5 + 2 configuration and EC enabled, we can guarantee an additional capacity load of only 40%, creating only 2GB of backup data for every 5GB of application data).
In this case, for secure storage of 100 TB of data, you need only 140 TB of capacity. This approach helps optimize the budget or ensure the storage of large amounts of data in cases where it is already physically impossible to install more disks in a cluster, more servers in a rack, and more racks in a server. At the same time, we maintain high data availability - even if two elements of the storage system fail, the remaining nodes of the system will allow us to restore all the data up to a bit, without stopping the application. The table shows the values of the reserve capacity, and, as you can see, the results of using erasure coding are really impressive when a lot of machines are used in the cluster. For example, in a 17 + 3 configuration with erasure coding, the backup capacity is only 18%

Another thing is performance. Of course, erasure coding increases the load on the CPU, but very slightly. Due to SSE instructions on modern processors, one core can process up to ~ 2GB / s of data.
The plus of the distributed storage system is that you can specify different types of redundancy for different loads. And in the case of direct replicas, a cluster with a large number of nodes, in contrast, provides much greater performance. However, we’ll talk about the performance of VZ Storage in more detail in the next post, since measurements of the effectiveness of a hyperconverged storage system depend on a huge number of factors, including hardware characteristics, type of network architecture, load characteristics, and so on.
Only registered users can participate in the survey. Please come in.
What do you consider the most important characteristic of a modern storage system?
- 6.8% High performance 3
- 52.2% Reliable data storage 23
- 9% Use of standard hardware 4
- 2.2% Hyperconvergence 1
- 6.8% Easy to control 3
- 22.7% Open Source 10
- 0% Integration with various APIs and platforms (aka Kubernetes) 0