JSON API - we work according to the specification
Recently, web development has split. Now we are not all full-stack programmers - we are front-end and back-end vendors. And the most difficult in this, as elsewhere, is the problem of interaction and integration.
Frontend with backend interact through API. And on what kind of API it is, how good or bad the backend and the frontend have agreed among themselves, the whole result of the development depends. If we all begin to discuss how to make a padzhinatsiyu, and spend on reworking it all day, then we can not get to the business objectives.
In order not to slip and not build holivars about the names of variables, we need a good specification. Let's talk about what it should be, so that all life is easier. At the same time we will become experts in cycling sheds.

Let's start from afar - with a problem that we solve.
Long ago, in 1959, Cyril Parkinson (not to be confused with the disease, this is a writer and an economic figure) came up with several interesting laws. For example, that costs grow with income, etc. One of them is called the Law of Triviality:
Parkinson was an economist, so he explained his laws in economic terms, something like this. If you come to the board of directors and say that you need $ 10 million to build a nuclear power plant, this issue will most likely be discussed much less than allocating 100 pounds for a bicycle shed for employees. Because everyone knows how to build a bike shed, everyone has their own opinion, everyone feels important and wants to participate, and the nuclear power plant is something abstract and distant, 10 million have never been seen either - there are fewer questions.
In 1999, the Parkinson's law of triviality appeared in programming, which was then actively developed. In programming, this law was found mainly in English-language literature and sounded like a metaphor. Called it The Bikeshed effect (the effect of a bicycle shed), but the essence is the same - we are ready and want to discuss a bicycle shed much longer than building a power station.
This term was introduced into programming by the Danish developer Poul-Henning Kamp, who participated in the creation of FreeBSD. During the design process, the team discussed how the sleep function should work for a very long time. This is a quote from the letter Poul-Henning Kamp (the development was then conducted in e-mail correspondence):
In this letter, he says that there are a bunch of much more important unsolved problems: “Let's not do the bicycle shed, we'll do something about it and go ahead!”
So Poul-Henning Kamp in 1999 introduced the term bikeshed into English-language literature which can be rephrased as:
The simpler we add or change, the more opinions we have to listen to. I think many have met with this. If we solve a simple question, for example, how to name variables, - for a machine, it makes no difference - this question will cause a huge number of holivars. And serious, really important for business problems are not discussed and go as a background.
What do you think is more important: how do we communicate between the backend and the front-end, or the business tasks that we do? Everyone thinks differently, but any customer, a person who is waiting for you to bring him money, will say: “Do me our business tasks already!” He absolutely doesn’t care how you transfer data between the backend and the frontend. Perhaps he does not even know what backend and frontend are.
I would like to summarize the introduction with the statement:The API is a bike shed.
Link to the presentation of the report
On the speaker: Alexey Avdeev ( Avdeev ) works for Neuron.Digital, a company that deals with neurons and makes a cool frontend for them. Alexey also pays attention to OpenSource, and advises everyone. Engaged in development for a long time - since 2002, he found the ancient Internet, when computers were large, the Internet was small, and the absence of JS did not bother anyone and everyone put on the sites on the tables.
How to deal with bike sheds?
After the distinguished Cyril Parkinson derived the law of triviality, he was much discussed. It turns out that the effect of a bike shed here can easily be avoided:
Anti-bikeshedding tool
I want to tell you about the objective tools to solve the problem of a bicycle shed. To demonstrate what an anti-bikeshedding tool is, I’ll tell you a little story.
Imagine that we have a novice backend developer. He recently came to the company, and he was assigned to design a small service, for example, a blog, for which he needed to write a REST protocol.
 Roy Fielding, REST author.
Roy Fielding, REST author.
In the photo, Roy Fielding, who defended his thesis “Architectural Styles and Design of Network Software Architectures” in 2000 and thereby introduced the term REST. Moreover, he invented HTTP and, in fact, is one of the founders of the Internet.
REST is a set of architectural principles that say how to design REST protocols, REST API, RESTful services. These are rather abstract and complex architectural principles. I am sure that none of you have ever seen an API made entirely according to all RESTful principles.
REST architecture requirements
I will cite several requirements for REST protocols, to which I will later refer and rely. There are quite a few of them, in Wikipedia you can read about it in more detail.
1. Model client-server.
The most important principle of REST, that is, our interaction with the backend. By REST, the backend is a server, the front-end is a client, and we communicate in a client-server format. Mobile devices are also a client. Developers for hours, refrigerators, and other services are also developing the client side. The RESTful API is the server that the client is accessing.
2. Lack of condition.
The server must be missing a state, that is, everything that is needed for the response comes in the request. When a session is stored on the server, and different answers come up depending on this session, this is a violation of the REST principle.
3. Uniform interface.
This is one of the key basic principles on which the REST API should be built. It includes the following:
There are 3 more principles that I do not cite, because they are not important for my story.
RESTful blog
Let's return to the novice backend developer who was asked to make a service for a RESTful blog. Below is an example of a prototype.
This is a site that has articles, you can comment on them, the article and comments have an author - a standard story. Our novice backend developer will do the RESTful API for this blog.
With all the blog data we work on the principle of СRUD .
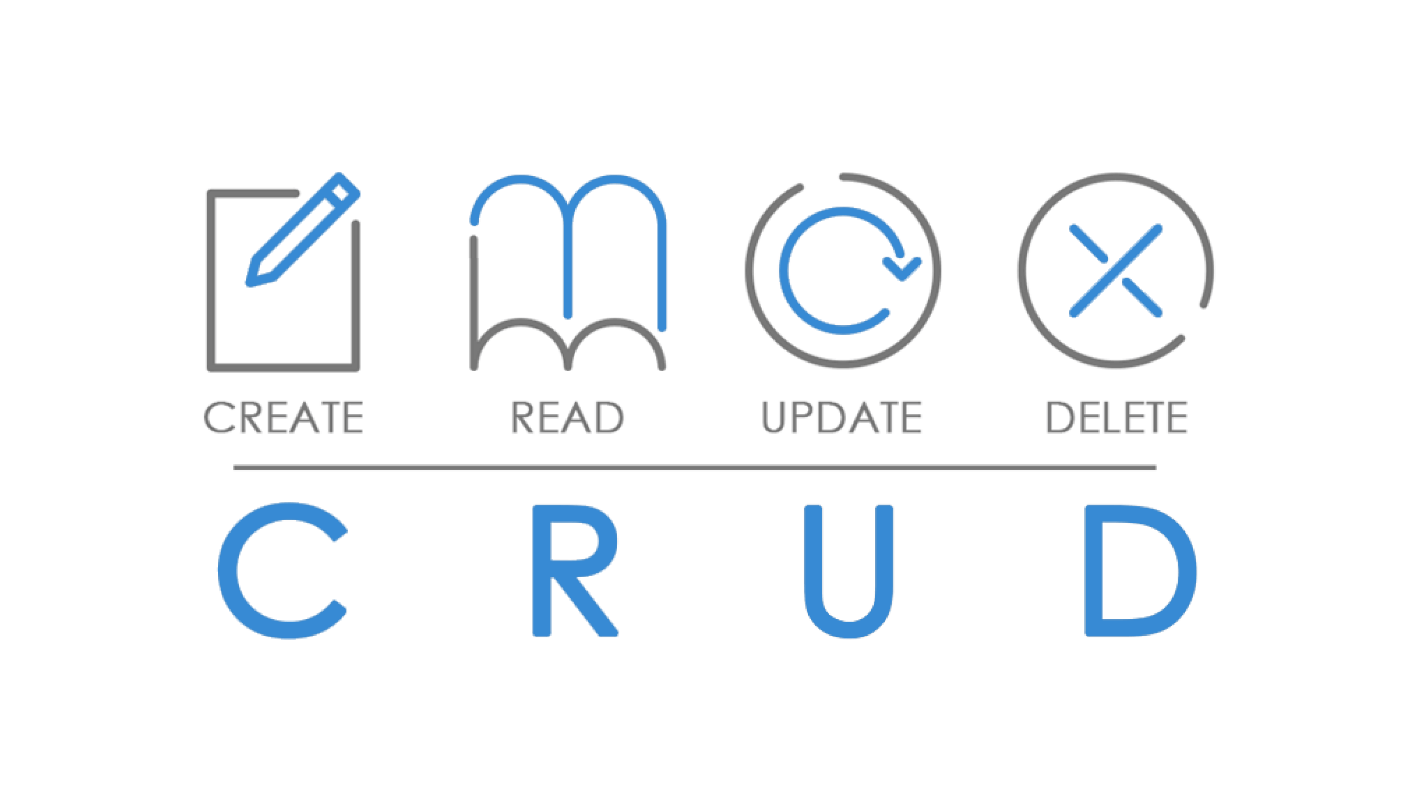
It should be possible to create any resource, read, update and delete. Let's try to ask our backend developer to build a RESTful AP I based on the CRUD principle. That is, write methods to create articles, get a list of articles or a separate article, update and delete.
Let's see how he could do it.

Here everything is wrong regarding all REST principles.. The most interesting thing is that it works. I actually got an API that looked something like this. For the customer, this is a bicycle shed, for developers, an excuse to talk and argue, and for a novice developer, this is just a huge, brave new world where he stumbles, falls, breaks his head. He has to redo time after time.

This is a REST option. According to the principles of resource identification, we work with resources — with articles (articles) and use the HTTP methods suggested by Roy Fielding. He could not use his previous work in his next work.
Many people use the PUT method to update articles; it has a slightly different semantics. The PATCH method updates the fields that were transferred, and PUT simply replaces one article with another. In semantics, PATCH is merge, and PUT is replace.
Our novice backend developer dropped, he was picked up and said: “Everything is all right, do this,” and he honestly remade it. But further it is waiting for a huge big way through thorns.
Why is it so right?
However, this “bicycle shed” will work the previous way. Computers communicated before REST, and everything worked. But now the industry has a standard.
Remove the article
Consider an example with the removal of the article. Suppose there is a normal, resource method DELETE / articles, which deletes an article by id. HTTP contains headers. The Accept header accepts the type of data that the client wants to receive in response. Our junior wrote a server that returns 200 OK, Content-Type: application / json, and sends an empty body: A very common error is made here - an empty body . It seems to be all logical - the article is deleted, 200 OK, the application / json header is present, but the client is likely to fall. He throws an error, because the empty body is not valid. If you have ever tried to parse an empty string, you have come across the fact that any json parser stumbles and falls on this.
How can I fix this situation? Most probably the best option is to pass on json. If we said: “Accept, give us json”, the server says: “Content-Type, I give you json”, give json. An empty object, an empty array - put something there - it will be a solution, and it will work.
There is still a solution. In addition to 200 OK, there is a response code 204 - no content. With it you can not transfer the body. Not everyone knows about this.
So I brought to the media types.
MIME types
Media types are like file extensions, only on the web. When we transfer data, we must inform or request which type we want to receive in response.
You can simply specify a specific type:
Content-Type and Accept headers are and are important.
If your API is built on JSON, always pass Accept: application / json and Content-Type application / json.
An example of file types.

Media types are similar to these file types, only on the Internet.
Response codes
The next example of the adventures of our junior developer is the response codes.

The funniest tot d reply - 200 OK. Everybody loves him - it means that everything went right. I even had a case - I received errors 200 OK . In fact, something fell on the server, in response, an HTML page comes up in response, with an error in the HTML. I requested application json with code 200 OK, and thought how to work with it? You go by the response, look for the word "error", you think that this is a mistake.
This works, however in HTTP there are many other codes that can be used, and according to REST, Roy Fielding recommends using them. For example, the creation of an entity (article) can be answered:
Entity creation
Next example: we create an entity, speak Content-Type: application / json, and pass this application / json. This is done by the client - our front end. Suppose we create this article: In response, the code may come:
But it is absolutely incomprehensible what exactly happened: which entity is unworkable, why can't I go there, and what finally happened to the server?
Return errors
Be sure to (and this junior do not know) in return, return errors. This is semantic and correct. By the way, Fielding did not write about this, that is, it was invented later and built on top of REST.
The backend may return an array with errors in response, there may be several of them. Each error can have its own status and title. This is great, but it is already at the agreement level over REST. This can be our anti-bikeshedding tool to stop arguing and make a good right API right away.
Add padzhinatsiyu
The next example: designers come to our beginning backend developer and say: “We have a lot of articles, we need a padjina. We drew this one. ”

Consider it in more detail. First of all, 336 pages catch your eye. When I saw this, I thought how to get this figure at all. Where to get 336, because the list of articles comes to me at the request of the list of articles. For example, there are 10 thousand of them, that is, I need to download all the articles, divide by the number of pages and find out this number. I will load these articles for a very long time, I need a way to get the number of records quickly. But if our API gives the list, then where is the number of records generally shoved, because in response comes an array of articles. It turns out that since the number of entries is not put anywhere, it should be added to each article so that each article says: “And there are so many of us all!”.
However, there is an agreement on top of the REST API that solves this problem.
List request
In order for the API to be extensible, you can immediately use GET-parameters for padzhinatsii: the size of the current page and its number, so that exactly the piece of the page that we requested returned. It's comfortable. In response, you can not immediately give an array, but add additional nesting. For example, the data key will contain an array, the data we requested, and the meta key, which was not there before, will contain a total number. Thus, the API can return additional information. In addition to count there may be some other information - it is expandable. Now, if the junior didn’t do it right away, but only after he was asked to make a padjinija, then he made an incompatible change back , broke the API, and all clients have to be redone - this is usually very painful.
Padzhinatsiya is different. I offer several lifehacks that you can use.
[offset] ... [limit]
For those working with databases, perhaps already on the subcortex [offset] ... [limit]. Using it instead of page [size] ... page [number] will be easier. This is a slightly different approach.
Cursor Padjination
Cursor padjination uses a pointer to the entity with which you want to start loading records. For example, it is very convenient when you use padzhinatsiya or podgruzku in lists that often change. Let's say in our blog constantly write new articles. The third page now is not the same third page, which will be in a minute, but going to the fourth page, we will get part of the records from the third page on it, because the entire list will move.
This problem is solved by the cursor padzhinatsiya. We say: “Load the articles that go after the article published at this time” - there can be no shift technologically, and this is cool.
Problem n +1
The next problem that our junior developer will definitely encounter is the N + 1 problem (the backendors will understand). Suppose you need to display a list of 10 articles. We upload a list of articles, each article has an author, and for each article you need to download the author. We send:
Total: 11 requests to display a small list.
Add links
On the backend, this problem is solved in all ORMs — you just have to remember to add this connection. These connections can be used on the frontend. This is done as follows: You can use a special GET parameter, call it include (as on the backend), saying which links we need to load along with the articles. Suppose we download articles, and we want to immediately get more of their author along with the articles. The answer looks like this: The data has transferred its own attributes of the articles and added the key relationships. In this key, we put all the links. Thus, in one request, we received all the data that we received before with 11 requests. This is a cool life hack that solves a problem with N + 1 well on the frontend.
Data duplication problem
Suppose you need to display 10 articles with the author, all articles have one author, but the object with the author is very large (for example, a very long last name that occupies a megabyte). One author is included in the answer 10 times, and 10 inclusions of the same author in response will take 10 MB.
Since all objects are the same, the problem that one author is included 10 times (10 MB) is solved with the help of normalization, which is used in databases. Normalization can also be used at the front end in working with the API - this is very cool.
We mark all entities with some type (this is the type of representation, the type of resource). Roy Fielding introduced the concept of a resource, that is, they requested articles - they received an “article”. In relationships, we place a link to the type of people, that is, we still have the resource people somewhere. And the resource itself, we take in a separate key included, which lies on the same level with data. Thus, all related entities in a single copy fall into the special key included. We store only links, and the entities themselves are stored in included. Request size has decreased. This is a life hack that the beginner backend doesn't know about. He will know this later when he needs to break the API.
Not all resource fields needed
The following life hack can be applied when not all resource fields are needed. This is done with the help of a special GET parameter, in which the attributes that need to be returned are listed separated by commas. For example, the article is large, and the content field may have megabytes, but we only need to display a list of titles - we do not need content in the answer. If you need, for example, the date of publication, you can write “published date” separated by commas. In response, two fields will come to attributes. This is an agreement that can be used as an anti-bikeshedding tool.
Search by articles
Often we need searches and filters. There are agreements for this - special GET-parameters filters:
● - search; ● - download articles from a specific date; ● - download articles that are only published; ● - upload articles with the first author.
Sort articles
● - by title; ● - by date of publication; ● - by date of publication in the opposite direction; ● - first by author, then by date of publication in the opposite direction, if articles are from one author.
Need to change URLs
Solution: hypermedia, which I have already mentioned, can be done as follows. If we want the object (resource) to be self-describing, the client could understand via hypermedia what can be done with it, and the server could develop independently of the client, then you can add links to the list of articles, to the article itself using special keys links : Or related, if we want to tell the client how to upload a comment to this article: The client sees that there is a link, follows it, loads a comment. If there is no link, then there are no comments. This is convenient, but so few do. Fielding came up with the principles of REST, but not all of them entered our industry. We mainly use two or three.
In 2013, all life hacking, which I told you about, Steve Klabnik combined into the JSON API specification and registered as a new media type over JSON . So our junior backend developer, gradually evolving, came to the JSON API.
JSON API
On the site http://jsonapi.org/implementations/ everything is described in detail: there is even a list of 170 different implementations of specifications for 32 programming languages - and these are just added to the catalog. Libraries, parsers, serializers, etc. have already been written.
Since this specification is open source, everything is invested in it. I, among other things, wrote something myself. I am sure there are many such people. You can join this project yourself.
Pros JSON API
JSON API specification solves a number of problems - a common convention for everyone . Once there is a general agreement, we do not argue within the team - the bicycle shed is documented. We have an agreement on what materials to make a bike shed and how to paint it.
Now, when a developer does something wrong and I see it, I do not start the discussion, but I say: “Not according to the JSON API!” And show it in place in the specification. They hate me in the company, but they gradually get used to it, and everyone started to like the JSON API. New services by default we do for this specification. We have a date key, we are ready to add meta, include keys. For filters there is a reserved GET-filters parameter. We do not argue how to name the filter - we use this specification. It describes how to make a URL.
Since we do not argue, but do business tasks, the development productivity is higher . We have described the specifications, the developer read the backend, made the API, we screwed it up - the customer is happy.
Popular problems have already been solved , for example, with padzhinatsii. There are many tips in the specification.
Since this is JSON (thanks to Douglas Crockford for this format), it is laconic XML, it is quite easy to read and understand .
The fact that this Open Source can be a plus and a minus, but I love Open Source.
Cons JSON API
The object has grown (date, attributes, included, etc.) - the frontend needs to parse answers: be able to iterate over arrays, walk around the object and know how reduce works. Not all novice developers know these complex things. There are serializers / deserializers libraries, you can use them. In general, this is just working with data, but the objects are large.
And the back pain begins:
JSON API Pitfalls
A little hardcore.
The number of relationships in the issue is not limited. If we do include, we request articles, adding comments to them, then in response we will receive all the comments of this article. There are 10,000 comments - get all 10,000 comments: Thus, 5 MB was actually received in response to our request: “In the specification it is written that way - we need to correctly reformulate the request: We request comments with a filter on the article, say:“ 30 stuff, please "And we get 30 comments. This is the ambiguity. The same things can be ambiguously formulated : ● - we request an article with comments; ● - we request comments on the article; ●
This is the same thing - the same data, which is obtained in different ways, there is some ambiguity. This reef is not immediately visible.
One-to-many polymorphic links very quickly emerge into REST. On the back end there is a commentable polymorphic link - it comes out in REST. So it should happen, but it can be disguised. In JSON API you will not disguise - it will come out. Complicated "many to many" links with additional parameters . Also all the link tables come out:
Swagger
Swagger is an online documentation tool.
Suppose our backend developer was asked to write documentation for his API, and he wrote it. This is easy if the API is simple. If this is a JSON API, Swagger is not so easy to write.
Example: Swagger Animal Store. Each method can be opened, see the response and examples.
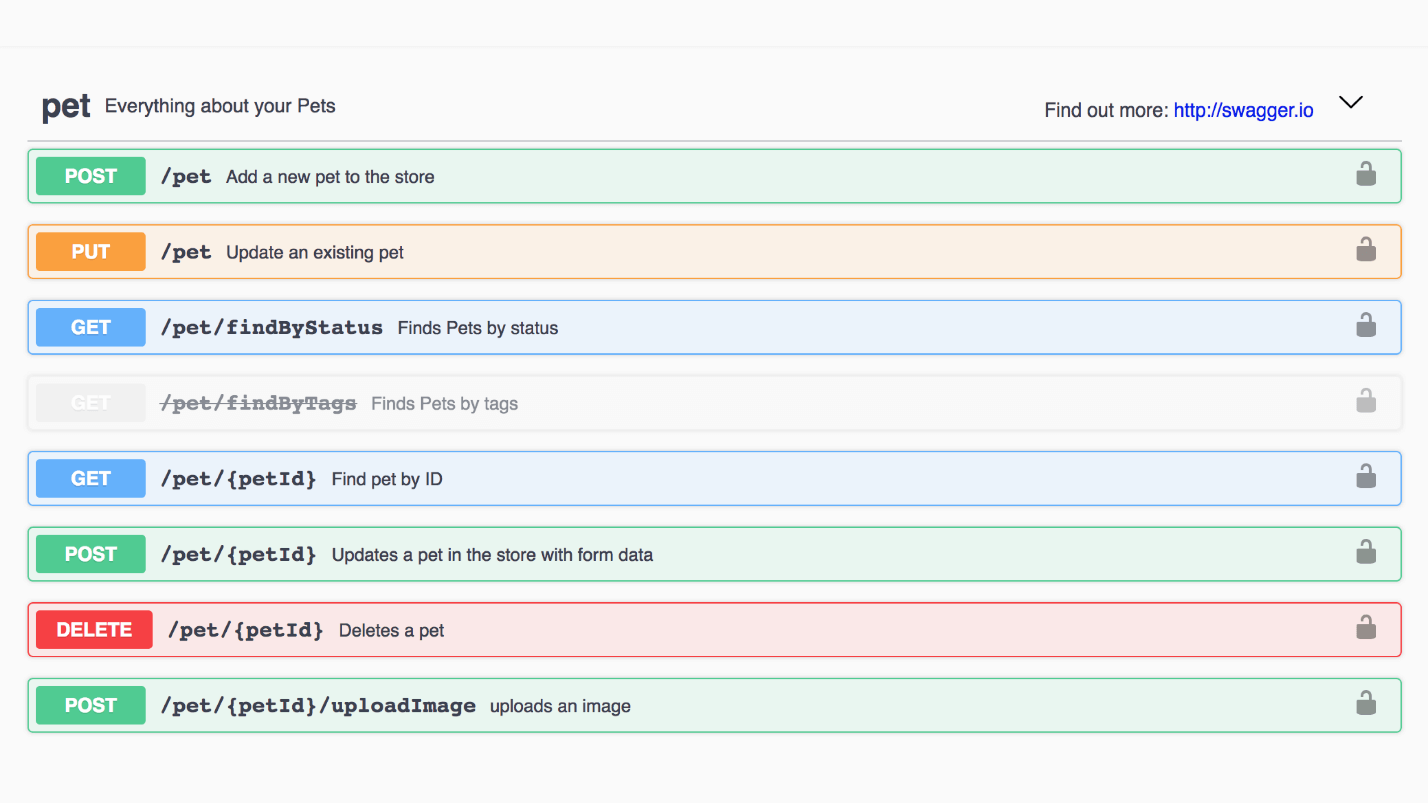
This is an example of a Pet model. Here is a cool interface, everything is easy to read.
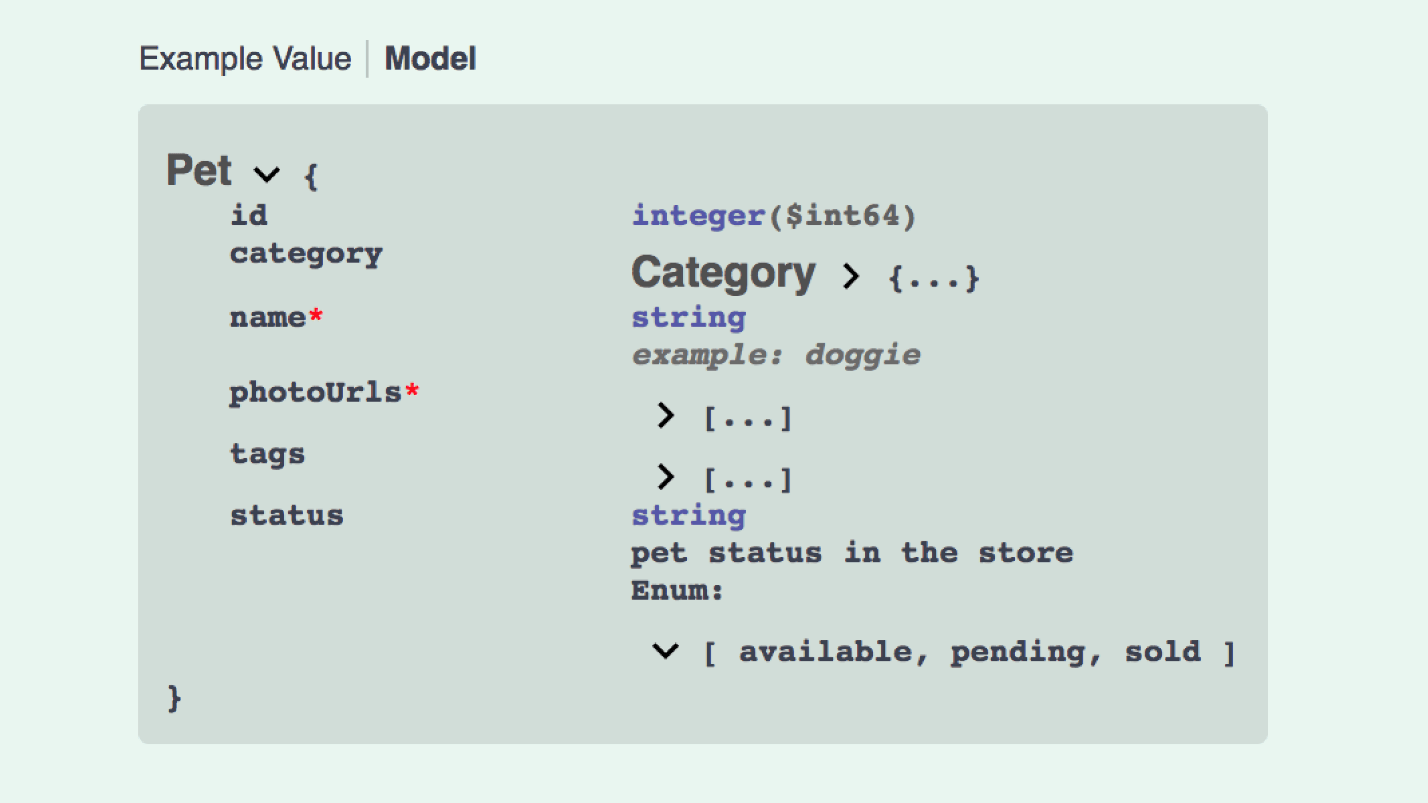
And this is how the creation of the JSON API model looks like:

This is not so great anymore. We need data, in data something with relationships, included contains 5 types of model, etc. Swagger can be written, Open API is a powerful thing, but difficult.
Alternative
There is the OData specification, which appeared a bit later - in 2015. This is “The best way to REST”, as the official website assures. Looks like this:
Answer version looks like this: Here is the extended application / json and the object. We did not use OData, first, because it is the same as the JSON API, but it is not concise. There are huge objects there and it seems to me that everything is much worse read. OData is also released in Open Source, but it’s more complicated.
What is with GraphQL?
Naturally, when we were looking for a new API format, we ran into this hyip.
● High entry threshold.
From the point of view of the frontend, everything looks cool, but a new developer will not be able to write GraphQL, because you first need to study it. It's like SQL - you can't immediately write SQL, you need to at least read what it is, go through the tutorials, that is, the input threshold increases.
● Big bang effect.
If there was no API in the project, and we began to use GraphQL, after a month we realized that it does not suit us, it will be too late. Have to write crutches. With JSON API or with OData, you can evolve - the simplest RESTful, progressively improving, turns into a JSON API.
● Hell on the back end.
GraphQL causes a hell on the backend - straightforwardly one-on-one, like a fully implemented JSON API, because GraphQL has full control over the queries, and this is the library, and you will need to solve a bunch of questions:
Instead of conclusions
I recommend to stop arguing about the bike shed, and take the anti-bikeshedding tool as a specification and just make the API according to a good specification.
To find your standard for solving the problem of a bicycle shed, look at these links:
● http://jsonapi.org
● http://www.odata.org
● https://graphgl.org
● http: //xmlrpc.scripting. com
● https://www.jsonrpc.org
Contact Speaker Alexey Avdeev: alexey-avdeev.com and profile on github .
Frontend with backend interact through API. And on what kind of API it is, how good or bad the backend and the frontend have agreed among themselves, the whole result of the development depends. If we all begin to discuss how to make a padzhinatsiyu, and spend on reworking it all day, then we can not get to the business objectives.
In order not to slip and not build holivars about the names of variables, we need a good specification. Let's talk about what it should be, so that all life is easier. At the same time we will become experts in cycling sheds.
Let's start from afar - with a problem that we solve.
Long ago, in 1959, Cyril Parkinson (not to be confused with the disease, this is a writer and an economic figure) came up with several interesting laws. For example, that costs grow with income, etc. One of them is called the Law of Triviality:
The time spent discussing the item is inversely proportional to the amount in question.
Parkinson was an economist, so he explained his laws in economic terms, something like this. If you come to the board of directors and say that you need $ 10 million to build a nuclear power plant, this issue will most likely be discussed much less than allocating 100 pounds for a bicycle shed for employees. Because everyone knows how to build a bike shed, everyone has their own opinion, everyone feels important and wants to participate, and the nuclear power plant is something abstract and distant, 10 million have never been seen either - there are fewer questions.
In 1999, the Parkinson's law of triviality appeared in programming, which was then actively developed. In programming, this law was found mainly in English-language literature and sounded like a metaphor. Called it The Bikeshed effect (the effect of a bicycle shed), but the essence is the same - we are ready and want to discuss a bicycle shed much longer than building a power station.
This term was introduced into programming by the Danish developer Poul-Henning Kamp, who participated in the creation of FreeBSD. During the design process, the team discussed how the sleep function should work for a very long time. This is a quote from the letter Poul-Henning Kamp (the development was then conducted in e-mail correspondence):
It would be a good idea to get to sleep (1). * We have around here.
In this letter, he says that there are a bunch of much more important unsolved problems: “Let's not do the bicycle shed, we'll do something about it and go ahead!”
So Poul-Henning Kamp in 1999 introduced the term bikeshed into English-language literature which can be rephrased as:
The amount of noise generated by a change in a code is inversely proportional to the complexity of the change.
The simpler we add or change, the more opinions we have to listen to. I think many have met with this. If we solve a simple question, for example, how to name variables, - for a machine, it makes no difference - this question will cause a huge number of holivars. And serious, really important for business problems are not discussed and go as a background.
What do you think is more important: how do we communicate between the backend and the front-end, or the business tasks that we do? Everyone thinks differently, but any customer, a person who is waiting for you to bring him money, will say: “Do me our business tasks already!” He absolutely doesn’t care how you transfer data between the backend and the frontend. Perhaps he does not even know what backend and frontend are.
I would like to summarize the introduction with the statement:The API is a bike shed.
Link to the presentation of the report
On the speaker: Alexey Avdeev ( Avdeev ) works for Neuron.Digital, a company that deals with neurons and makes a cool frontend for them. Alexey also pays attention to OpenSource, and advises everyone. Engaged in development for a long time - since 2002, he found the ancient Internet, when computers were large, the Internet was small, and the absence of JS did not bother anyone and everyone put on the sites on the tables.
How to deal with bike sheds?
After the distinguished Cyril Parkinson derived the law of triviality, he was much discussed. It turns out that the effect of a bike shed here can easily be avoided:
- Do not listen to advice. I think, so an idea for yourself - if you don’t listen to advice, you can do it all, especially in programming, and especially if you are a novice developer.
- Do as you wish. “I am an artist, I see it so!” - no bikeshed effect, everything is done, but very strange things appear at the exit. This is often found in freelancing. Surely you are faced with tasks that had to finish for another developer and the implementation of which caused you to be perplexed.
- Ask yourself is it important? If not, you can simply not discuss, but this is a matter of personal consciousness.
- Use objective criteria. About this point I just will speak in the report. To avoid the effect of a bicycle shed, you can use criteria that objectively say which is better. They exist.
- Do not talk about what you do not want to listen to advice. In our company, novice backend developers are introverts, so it happens that they do something that they don’t tell others. As a result, we meet surprises. This method works, but in programming it is not the best option.
- If you do not care about the problem, you can simply let go of it or choose any of the proposed options that have arisen during the holivar process.
Anti-bikeshedding tool
I want to tell you about the objective tools to solve the problem of a bicycle shed. To demonstrate what an anti-bikeshedding tool is, I’ll tell you a little story.
Imagine that we have a novice backend developer. He recently came to the company, and he was assigned to design a small service, for example, a blog, for which he needed to write a REST protocol.
Roy Fielding, REST author.In the photo, Roy Fielding, who defended his thesis “Architectural Styles and Design of Network Software Architectures” in 2000 and thereby introduced the term REST. Moreover, he invented HTTP and, in fact, is one of the founders of the Internet.
REST is a set of architectural principles that say how to design REST protocols, REST API, RESTful services. These are rather abstract and complex architectural principles. I am sure that none of you have ever seen an API made entirely according to all RESTful principles.
REST architecture requirements
I will cite several requirements for REST protocols, to which I will later refer and rely. There are quite a few of them, in Wikipedia you can read about it in more detail.
1. Model client-server.
The most important principle of REST, that is, our interaction with the backend. By REST, the backend is a server, the front-end is a client, and we communicate in a client-server format. Mobile devices are also a client. Developers for hours, refrigerators, and other services are also developing the client side. The RESTful API is the server that the client is accessing.
2. Lack of condition.
The server must be missing a state, that is, everything that is needed for the response comes in the request. When a session is stored on the server, and different answers come up depending on this session, this is a violation of the REST principle.
3. Uniform interface.
This is one of the key basic principles on which the REST API should be built. It includes the following:
- Resource identification is how we should build URLs. By REST, we are accessing a server for some resource.
- Manipulate resources through presentation. The server returns us a view that is different from what is in the database. It doesn't matter if you store information in MySQL or PostgreSQL - we have a presentation.
- “Self-describing” messages — that is, the message contains an id, links where you can get this message again — everything you need to work with this resource again.
- Hypermedia is a link to the following actions with a resource. It seems to me that no REST API does it, but it is described by Roy Fielding.
There are 3 more principles that I do not cite, because they are not important for my story.
RESTful blog
Let's return to the novice backend developer who was asked to make a service for a RESTful blog. Below is an example of a prototype.
This is a site that has articles, you can comment on them, the article and comments have an author - a standard story. Our novice backend developer will do the RESTful API for this blog.
With all the blog data we work on the principle of СRUD .
It should be possible to create any resource, read, update and delete. Let's try to ask our backend developer to build a RESTful AP I based on the CRUD principle. That is, write methods to create articles, get a list of articles or a separate article, update and delete.
Let's see how he could do it.
Here everything is wrong regarding all REST principles.. The most interesting thing is that it works. I actually got an API that looked something like this. For the customer, this is a bicycle shed, for developers, an excuse to talk and argue, and for a novice developer, this is just a huge, brave new world where he stumbles, falls, breaks his head. He has to redo time after time.
This is a REST option. According to the principles of resource identification, we work with resources — with articles (articles) and use the HTTP methods suggested by Roy Fielding. He could not use his previous work in his next work.
Many people use the PUT method to update articles; it has a slightly different semantics. The PATCH method updates the fields that were transferred, and PUT simply replaces one article with another. In semantics, PATCH is merge, and PUT is replace.
Our novice backend developer dropped, he was picked up and said: “Everything is all right, do this,” and he honestly remade it. But further it is waiting for a huge big way through thorns.
Why is it so right?
- because Roy Fielding said so;
- because it is REST;
- because these are the architectural principles on which our profession is built now.
However, this “bicycle shed” will work the previous way. Computers communicated before REST, and everything worked. But now the industry has a standard.
Remove the article
Consider an example with the removal of the article. Suppose there is a normal, resource method DELETE / articles, which deletes an article by id. HTTP contains headers. The Accept header accepts the type of data that the client wants to receive in response. Our junior wrote a server that returns 200 OK, Content-Type: application / json, and sends an empty body: A very common error is made here - an empty body . It seems to be all logical - the article is deleted, 200 OK, the application / json header is present, but the client is likely to fall. He throws an error, because the empty body is not valid. If you have ever tried to parse an empty string, you have come across the fact that any json parser stumbles and falls on this.
01. DELETE /articles/1 НТТР/1.1
02. Accept: application/json01. HTTP/1.1 200 OK
02. Content-Type: application/json
03. null
How can I fix this situation? Most probably the best option is to pass on json. If we said: “Accept, give us json”, the server says: “Content-Type, I give you json”, give json. An empty object, an empty array - put something there - it will be a solution, and it will work.
There is still a solution. In addition to 200 OK, there is a response code 204 - no content. With it you can not transfer the body. Not everyone knows about this.
So I brought to the media types.
MIME types
Media types are like file extensions, only on the web. When we transfer data, we must inform or request which type we want to receive in response.
- The default is text / plain - just text.
- If nothing is specified, then the browser is likely to keep in mind application / octet-stream - just a bit stream.
You can simply specify a specific type:
- application / pdf;
- image / png;
- application / json;
- application / xml;
- application / vnd.ms-excel.
Content-Type and Accept headers are and are important.
The API and client must pass the Content-Type and Accept headers.
If your API is built on JSON, always pass Accept: application / json and Content-Type application / json.
An example of file types.
Media types are similar to these file types, only on the Internet.
Response codes
The next example of the adventures of our junior developer is the response codes.
The funniest to
This works, however in HTTP there are many other codes that can be used, and according to REST, Roy Fielding recommends using them. For example, the creation of an entity (article) can be answered:
- 201 Created - successful code. The article is created, in response, you must return the created article.
- 202 Accepted means that the request has been accepted, but its result will be later. These are long-running operations. On Accepted, you can not return any body. That is, if you do not give the Content-Type in the answer, then the body also may not be. Or Content-Type text / plane - everything, no questions. An empty string is valid text / plane.
- 204 No Content - the body may be completely absent.
- 403 Forbidden - you can not create this article.
- 404 Not Found - you climbed somewhere wrong, there is no such way, for example.
- 409 Conflict - an extreme case that few people use. It can be needed if you are on the client, and not on the backend, generating an id, and at that time someone has already managed to create this article. Conflict is the right answer in this case.
Entity creation
Next example: we create an entity, speak Content-Type: application / json, and pass this application / json. This is done by the client - our front end. Suppose we create this article: In response, the code may come:
01. POST /articles НТТР/1.1
02. Content-Type: application/json
03. { "id": 1, "title": "Про JSON API"}- 422 Unprocessable Entity - unhandled entity. Everything seems to be great - semantics, there is code;
- 403 Forbidden;
- 500 Internal Server Error.
But it is absolutely incomprehensible what exactly happened: which entity is unworkable, why can't I go there, and what finally happened to the server?
Return errors
Be sure to (and this junior do not know) in return, return errors. This is semantic and correct. By the way, Fielding did not write about this, that is, it was invented later and built on top of REST.
The backend may return an array with errors in response, there may be several of them. Each error can have its own status and title. This is great, but it is already at the agreement level over REST. This can be our anti-bikeshedding tool to stop arguing and make a good right API right away.
01. HTTP/1.1 422 Unprocessable Entity
02. Content-Type: application/json
03.
04. { "errors": [{
05. "status": "422",
06. "title": "Title already exist",
07. }]}Add padzhinatsiyu
The next example: designers come to our beginning backend developer and say: “We have a lot of articles, we need a padjina. We drew this one. ”
Consider it in more detail. First of all, 336 pages catch your eye. When I saw this, I thought how to get this figure at all. Where to get 336, because the list of articles comes to me at the request of the list of articles. For example, there are 10 thousand of them, that is, I need to download all the articles, divide by the number of pages and find out this number. I will load these articles for a very long time, I need a way to get the number of records quickly. But if our API gives the list, then where is the number of records generally shoved, because in response comes an array of articles. It turns out that since the number of entries is not put anywhere, it should be added to each article so that each article says: “And there are so many of us all!”.
However, there is an agreement on top of the REST API that solves this problem.
List request
In order for the API to be extensible, you can immediately use GET-parameters for padzhinatsii: the size of the current page and its number, so that exactly the piece of the page that we requested returned. It's comfortable. In response, you can not immediately give an array, but add additional nesting. For example, the data key will contain an array, the data we requested, and the meta key, which was not there before, will contain a total number. Thus, the API can return additional information. In addition to count there may be some other information - it is expandable. Now, if the junior didn’t do it right away, but only after he was asked to make a padjinija, then he made an incompatible change back , broke the API, and all clients have to be redone - this is usually very painful.
01. GET /articles?page[size]=30&page[number]=2
02. Content-Type: application/json
01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }
Padzhinatsiya is different. I offer several lifehacks that you can use.
[offset] ... [limit]
01. GET /articles?page[offset]=30&page[limit]=30
02. Content-Type: application/json
01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }
For those working with databases, perhaps already on the subcortex [offset] ... [limit]. Using it instead of page [size] ... page [number] will be easier. This is a slightly different approach.
Cursor Padjination
01. GET /articles?page[published_at]=1538332156
02. Content-Type: application/json01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }Cursor padjination uses a pointer to the entity with which you want to start loading records. For example, it is very convenient when you use padzhinatsiya or podgruzku in lists that often change. Let's say in our blog constantly write new articles. The third page now is not the same third page, which will be in a minute, but going to the fourth page, we will get part of the records from the third page on it, because the entire list will move.
This problem is solved by the cursor padzhinatsiya. We say: “Load the articles that go after the article published at this time” - there can be no shift technologically, and this is cool.
Problem n +1
The next problem that our junior developer will definitely encounter is the N + 1 problem (the backendors will understand). Suppose you need to display a list of 10 articles. We upload a list of articles, each article has an author, and for each article you need to download the author. We send:
- 1 request for a list of articles;
- 10 requests to get the authors of each article.
Total: 11 requests to display a small list.
Add links
On the backend, this problem is solved in all ORMs — you just have to remember to add this connection. These connections can be used on the frontend. This is done as follows: You can use a special GET parameter, call it include (as on the backend), saying which links we need to load along with the articles. Suppose we download articles, and we want to immediately get more of their author along with the articles. The answer looks like this: The data has transferred its own attributes of the articles and added the key relationships. In this key, we put all the links. Thus, in one request, we received all the data that we received before with 11 requests. This is a cool life hack that solves a problem with N + 1 well on the frontend.
01. GET /articles?include =author
02. Content-Type: application/json
01. НТТР/1.1 200 ОК
02. { "data": [{
03. { attributes: { "id": 1, "title": "JSON API" },
04. { relationships: {
05. "author": { "id": 1, "name": "Avdeev" } }
06. }, ...
07. }]}Data duplication problem
Suppose you need to display 10 articles with the author, all articles have one author, but the object with the author is very large (for example, a very long last name that occupies a megabyte). One author is included in the answer 10 times, and 10 inclusions of the same author in response will take 10 MB.
Since all objects are the same, the problem that one author is included 10 times (10 MB) is solved with the help of normalization, which is used in databases. Normalization can also be used at the front end in working with the API - this is very cool.
01. НТТР/1.1 200 ОК
02. { "data": [{
03. "id": "1″, "type": "article",
04. "attributes": { "title": "JSON API" },
05. "relationships": { ... }
06. "author": { "id": 1, "type": "people" } }
07. }, ... ]
08. }We mark all entities with some type (this is the type of representation, the type of resource). Roy Fielding introduced the concept of a resource, that is, they requested articles - they received an “article”. In relationships, we place a link to the type of people, that is, we still have the resource people somewhere. And the resource itself, we take in a separate key included, which lies on the same level with data. Thus, all related entities in a single copy fall into the special key included. We store only links, and the entities themselves are stored in included. Request size has decreased. This is a life hack that the beginner backend doesn't know about. He will know this later when he needs to break the API.
01. НТТР/1.1 200 ОК
02. {
03. "data": [ ... ],
04. "included": [{
05. "id": 1, "type": "people",
06. "attributes": { "name": "Avdeev" }
07. }]
08. }Not all resource fields needed
The following life hack can be applied when not all resource fields are needed. This is done with the help of a special GET parameter, in which the attributes that need to be returned are listed separated by commas. For example, the article is large, and the content field may have megabytes, but we only need to display a list of titles - we do not need content in the answer. If you need, for example, the date of publication, you can write “published date” separated by commas. In response, two fields will come to attributes. This is an agreement that can be used as an anti-bikeshedding tool.
GET /articles?fields[article]=title НТТР/1.101. НТТР/1.1 200 OK
02. { "data": [{
03. "id": "1″, "type": "article",
04. "attributes": { "title": "Про JSON API" },
05. }, ... ]
06. }Search by articles
Often we need searches and filters. There are agreements for this - special GET-parameters filters:
● - search; ● - download articles from a specific date; ● - download articles that are only published; ● - upload articles with the first author.
GET /articles?filters[search]=api HTTP/1.1GET /articles?fiIters[from_date]=1538332156 HTTP/1.1GET /articles?filters[is_published]=true HTTP/1.1GET /articles?fiIters[author]=1 HTTP/1.1Sort articles
● - by title; ● - by date of publication; ● - by date of publication in the opposite direction; ● - first by author, then by date of publication in the opposite direction, if articles are from one author.
GET /articles?sort=title НТТР/1.1GET /articles?sort=published_at HTTP/1.1GET /articles?sort=-published_at HTTP/1.1GET /articles?sort=author,-publisbed_at HTTP/1.1Need to change URLs
Solution: hypermedia, which I have already mentioned, can be done as follows. If we want the object (resource) to be self-describing, the client could understand via hypermedia what can be done with it, and the server could develop independently of the client, then you can add links to the list of articles, to the article itself using special keys links : Or related, if we want to tell the client how to upload a comment to this article: The client sees that there is a link, follows it, loads a comment. If there is no link, then there are no comments. This is convenient, but so few do. Fielding came up with the principles of REST, but not all of them entered our industry. We mainly use two or three.
01. GET /articles НТТР/1.1
02. {
03. "data": [{
04. ...
05. "links": { "self": "http://localhost/articles/1" },
06. "relationships": { ... }
07. }],
08. "links": { "self": "http://localhost/articles" }
09. }
01. ...
02. "relationships": {
03. "comments": {
04. "links": {
05. "self": "http://localhost/articles/l/relationships/comments",
06. "related": "http://localhost/articles/l/comments"
07. }
08. }
09. }In 2013, all life hacking, which I told you about, Steve Klabnik combined into the JSON API specification and registered as a new media type over JSON . So our junior backend developer, gradually evolving, came to the JSON API.
JSON API
On the site http://jsonapi.org/implementations/ everything is described in detail: there is even a list of 170 different implementations of specifications for 32 programming languages - and these are just added to the catalog. Libraries, parsers, serializers, etc. have already been written.
Since this specification is open source, everything is invested in it. I, among other things, wrote something myself. I am sure there are many such people. You can join this project yourself.
Pros JSON API
JSON API specification solves a number of problems - a common convention for everyone . Once there is a general agreement, we do not argue within the team - the bicycle shed is documented. We have an agreement on what materials to make a bike shed and how to paint it.
Now, when a developer does something wrong and I see it, I do not start the discussion, but I say: “Not according to the JSON API!” And show it in place in the specification. They hate me in the company, but they gradually get used to it, and everyone started to like the JSON API. New services by default we do for this specification. We have a date key, we are ready to add meta, include keys. For filters there is a reserved GET-filters parameter. We do not argue how to name the filter - we use this specification. It describes how to make a URL.
Since we do not argue, but do business tasks, the development productivity is higher . We have described the specifications, the developer read the backend, made the API, we screwed it up - the customer is happy.
Popular problems have already been solved , for example, with padzhinatsii. There are many tips in the specification.
Since this is JSON (thanks to Douglas Crockford for this format), it is laconic XML, it is quite easy to read and understand .
The fact that this Open Source can be a plus and a minus, but I love Open Source.
Cons JSON API
The object has grown (date, attributes, included, etc.) - the frontend needs to parse answers: be able to iterate over arrays, walk around the object and know how reduce works. Not all novice developers know these complex things. There are serializers / deserializers libraries, you can use them. In general, this is just working with data, but the objects are large.
And the back pain begins:
- Control nesting - include can be reached very far;
- The complexity of queries to the database - they are sometimes built automatically, and are very heavy;
- Security - you can climb into the jungle, especially if you connect some kind of library;
- The specification is hard to read. She is in English, and this scared away some, but gradually everyone got used to it;
- Not all libraries implement the specification well - this is an Open Source problem.
JSON API Pitfalls
A little hardcore.
The number of relationships in the issue is not limited. If we do include, we request articles, adding comments to them, then in response we will receive all the comments of this article. There are 10,000 comments - get all 10,000 comments: Thus, 5 MB was actually received in response to our request: “In the specification it is written that way - we need to correctly reformulate the request: We request comments with a filter on the article, say:“ 30 stuff, please "And we get 30 comments. This is the ambiguity. The same things can be ambiguously formulated : ● - we request an article with comments; ● - we request comments on the article; ●
GET /articles/1?include=comments НТТР/1.101. ...
02. "relationships": {
03. "comments": {
04. "data": [0 ... ∞]
05. }
06. }GET /comments?filters[article]=1&page[size]=30 HTTP/1.101. {
02. "data": [0 ... 29]
03. }GET /articles/1?include=comments HTTP/1.1GET /articles/1/comments HTTP/1.1GET /comments?filters[article]=1 HTTP/1.1 - we request comments with a filter on the article. This is the same thing - the same data, which is obtained in different ways, there is some ambiguity. This reef is not immediately visible.
One-to-many polymorphic links very quickly emerge into REST. On the back end there is a commentable polymorphic link - it comes out in REST. So it should happen, but it can be disguised. In JSON API you will not disguise - it will come out. Complicated "many to many" links with additional parameters . Also all the link tables come out:
01. GET /comments?include=commentable НТТР/1.1
02.
03. ...
04. "relationships": {
05. "commentable": {
06. "data": { "type": "article", "id": "1″ }
07. }
08. }01. GET /users?include=users_comments НТТР/1.1
02.
03. ...
04. "relationships": {
05. "users_comments": {
06. "data": [{ "type": "users_comments", "id": "1″ }, ...]
07. },
08. }Swagger
Swagger is an online documentation tool.
Suppose our backend developer was asked to write documentation for his API, and he wrote it. This is easy if the API is simple. If this is a JSON API, Swagger is not so easy to write.
Example: Swagger Animal Store. Each method can be opened, see the response and examples.
This is an example of a Pet model. Here is a cool interface, everything is easy to read.
And this is how the creation of the JSON API model looks like:
This is not so great anymore. We need data, in data something with relationships, included contains 5 types of model, etc. Swagger can be written, Open API is a powerful thing, but difficult.
Alternative
There is the OData specification, which appeared a bit later - in 2015. This is “The best way to REST”, as the official website assures. Looks like this:
01. GET http://services.odata.org/v4/TripRW/People HTTP/1.1- GET request; 02. OData-Version: 4.0 - special title with version; 03. OData-MaxVersion: 4.0 - the second special header with the Answer version looks like this: Here is the extended application / json and the object. We did not use OData, first, because it is the same as the JSON API, but it is not concise. There are huge objects there and it seems to me that everything is much worse read. OData is also released in Open Source, but it’s more complicated.
01. HTTP/1.1 200 OK
02. Content-Type: application/json; odata.metadata=minimal
03. OData-Version: 4.0
04. {
05. ’@odata.context’: ’http://services.odata.org/V4/
06. ’@odata.nextLink’ : ’http://services.odata.org/V4/
07. ’value’: [{
08. ’@odata.etag’: 1W/108D1D5BD423E51581′,
09. ’UserName’: ’russellwhyte’,
10. ...
What is with GraphQL?
Naturally, when we were looking for a new API format, we ran into this hyip.
● High entry threshold.
From the point of view of the frontend, everything looks cool, but a new developer will not be able to write GraphQL, because you first need to study it. It's like SQL - you can't immediately write SQL, you need to at least read what it is, go through the tutorials, that is, the input threshold increases.
● Big bang effect.
If there was no API in the project, and we began to use GraphQL, after a month we realized that it does not suit us, it will be too late. Have to write crutches. With JSON API or with OData, you can evolve - the simplest RESTful, progressively improving, turns into a JSON API.
● Hell on the back end.
GraphQL causes a hell on the backend - straightforwardly one-on-one, like a fully implemented JSON API, because GraphQL has full control over the queries, and this is the library, and you will need to solve a bunch of questions:
- nesting control;
- recursion;
- frequency limiting;
- access control.
Instead of conclusions
I recommend to stop arguing about the bike shed, and take the anti-bikeshedding tool as a specification and just make the API according to a good specification.
To find your standard for solving the problem of a bicycle shed, look at these links:
● http://jsonapi.org
● http://www.odata.org
● https://graphgl.org
● http: //xmlrpc.scripting. com
● https://www.jsonrpc.org
Contact Speaker Alexey Avdeev: alexey-avdeev.com and profile on github .
Colleagues, we opened the reception of reports on Frontend Conf , which will be held on May 27 and 28 in the framework of RIT ++ . Our program committee has begun work to assemble a classroom program in the next three months.
Do you have a story to tell? Want to share your experience with the community? Can your report make the life of many frontendders better? Are you an expert in a narrow but important topic and want to share your knowledge? Apply now !
Follow the progress of preparation through the newsletter , and ideas, who should be invited, what topic to talk about, write directly to the comments on the article.