The core of test automation in microservice architecture
Hello, Habr! My name is Dmitry Khimion, I head the Quality Assurance Department at Avito. Today I want to talk about test automation as part of working with microservice architecture. What can we offer development in order to facilitate quality control? Read under the cut.
To complete my story, let's start with the basics. To simplify, microservice architecture is a way to organize an application server. How does he work? Essentially, this is simply the answer of a service-oriented architecture to the emergence of practices such as DevOps. If SOA does not regulate the size of services and what exactly they should do, then there are some speculative limitations within the microservice architecture. A microservice is an entity that embodies one small functionality that it manages and provides some data to external services.
Sometimes they give information that a microservice is 500 lines of code. But this is optional; the point is that these services are quite small and form the same business processes as the monolithic back-end, which works on many projects. Functionally - the same thing, the differences - in the organizational structure.
What could be the problem here? Services are quickly becoming a lot, their connectivity is increasing. This complicates testing: checking for a change in one microservice entails the need to raise a fairly thick layer of infrastructure from the many services with which the mutable microservice interacts. At a certain point in the development of the project, the number of relationships and dependencies grows greatly and it becomes difficult to perform quick and isolated testing. We are starting to work more slowly. Development is slowing down. These and some other problems can be solved using test automation.
To begin, consider the transition from a monolith to a microservice architecture. In the case of a monolith, in order to replace any piece in this system, we cannot roll it out separately. You need to rebuild and completely update the back end. This is not always rational and convenient. What happens when switching to microservice architecture? We take the back-end and divide it into its component components, dividing them by functionality. We determine the interactions between them, and we get a new system with the same front-end and the same databases. Microservices interact with each other and provide the same business processes. For the user and system testing, everything remained as before, the internal organization has changed.
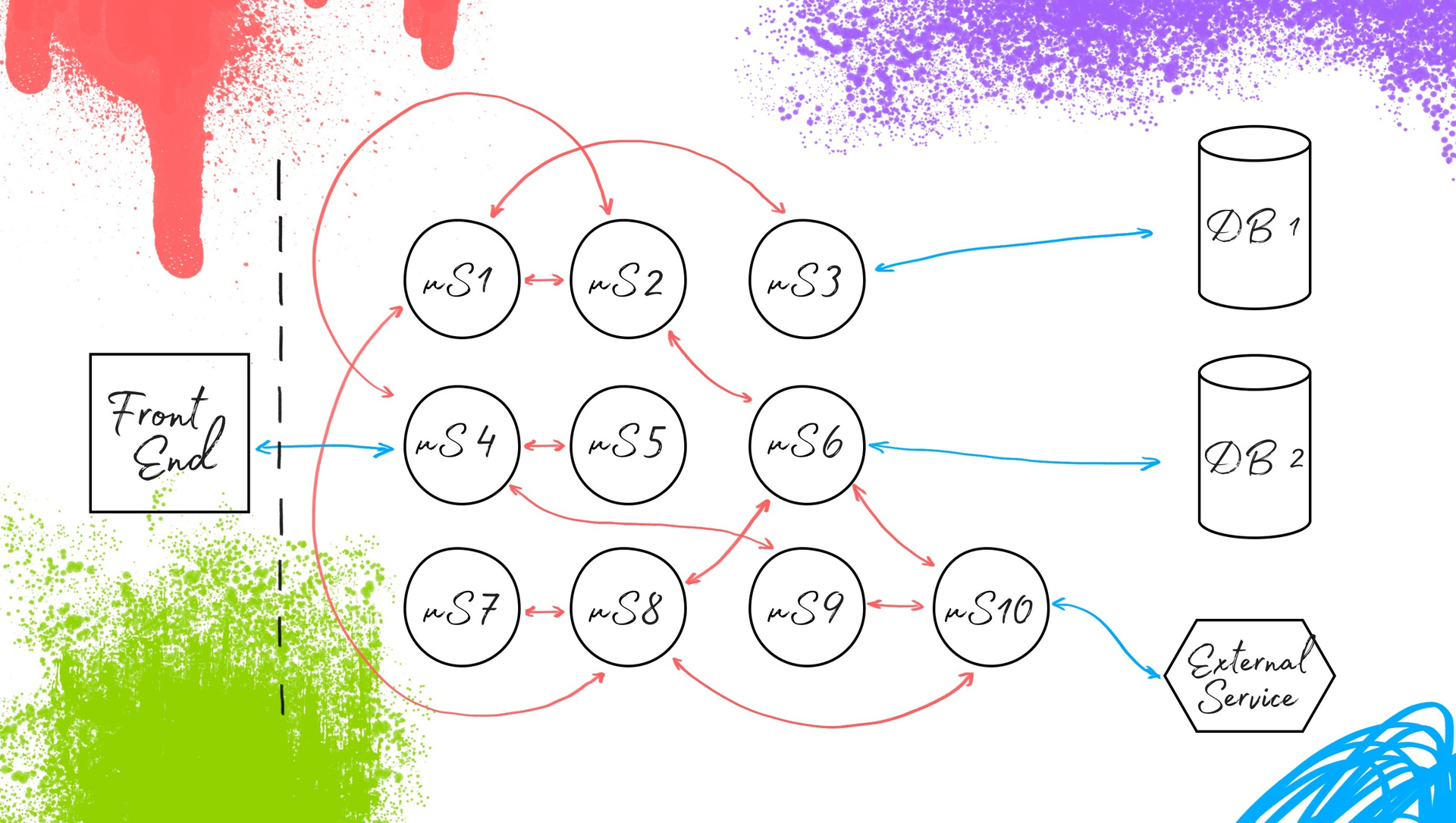
What does it give? You can make a change in the microservice X, which implements some of its functionality, and immediately roll it out to work. It all sounds very good. But, as always, there is a nuance: you need to check how microservices interact with each other.
Microservice interactions among themselves are implemented through contracts. What does this mean for service oriented architecture? A contract is a certain agreement that service developers create for external users to interact with each other. The developers of the service themselves decide that you can ask them for “X”, and they will provide you with “Y”. The service can provide apples, tomatoes, plutonium to external users, sell children's clothes or televisions - it does not declare a clear focus on functionality. Internal content is regulated only at the level of common sense. And accordingly, this service dictates to external users what they will receive and how to access it.
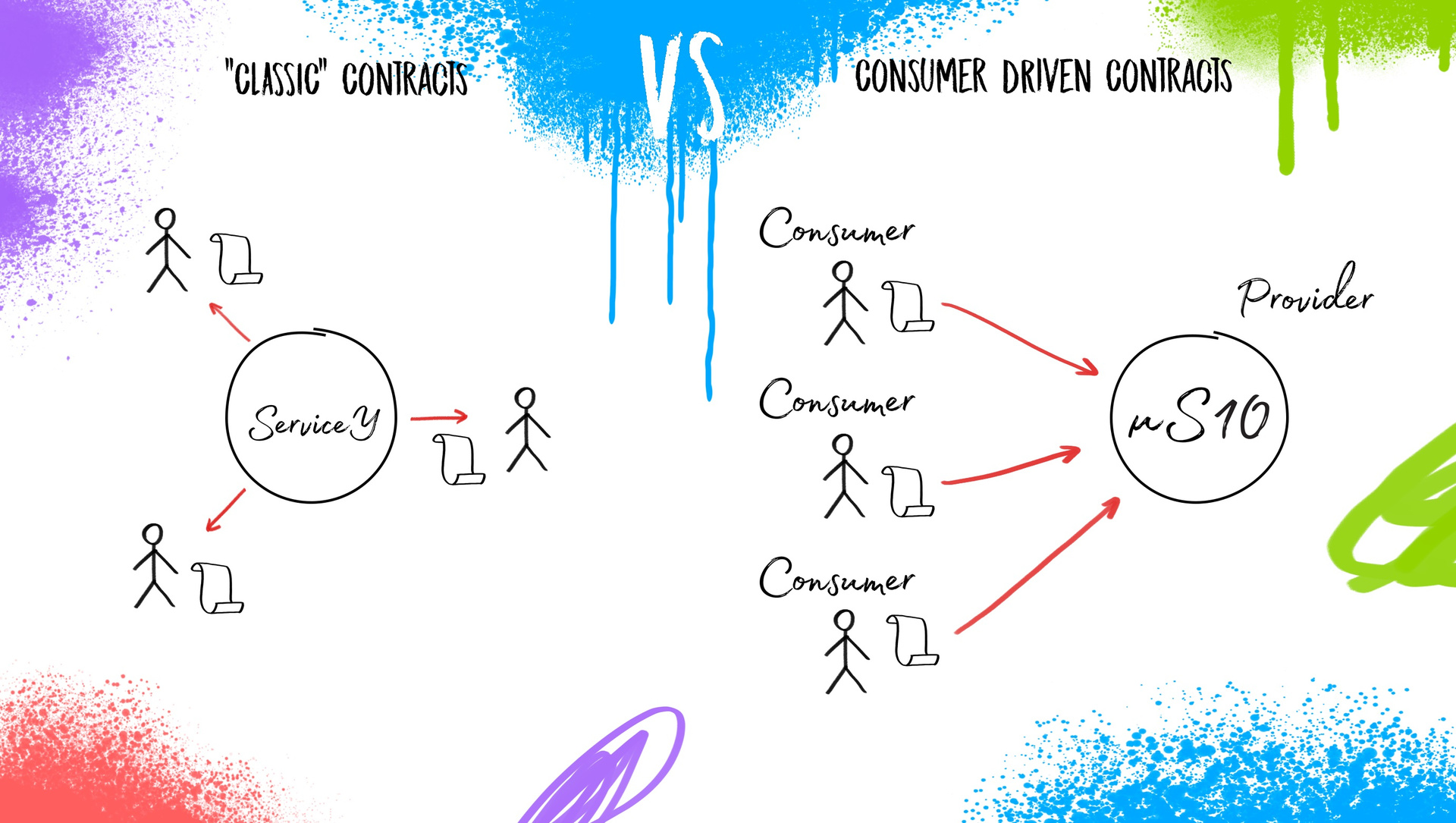
If we increase the complexity of this task, when there will be not dozens of services (10-20-50), but hundreds (200, 400 ... 2000), then the traditional, “classical” contracts will stop working in the functional sense. And then the need arises to modernize contracts for microservice architecture. A template has been developed for developers, in which they and the “end users” of the microservice are interchanged - this approach is called consumer driven contacts. Now requests are made by external users. This can be imagined as a conversation of this kind:
Thus, it turns out that users create contracts, set requirements and send them to the provider that implements them. What is the plus? Since each service has a rather limited number of consumers, it is much easier to get three specifications from each and to implement them, rather than trying to guess which “apples” to provide in each particular case and what else they may need in addition to these “fruits”.
For this approach, we, as a quality assurance department, must provide a worthy answer in the field of testing so as not to slow down the process of quickly rolling out microservices.
What can't start working on CDC-testing principles without? The first one. We will not be able to help if we see that the process of working under contracts is not followed in our development. The second thing is more technical: it is a post-commit system (post-PR, if you like) of hooks, which processes this communication flow between developers using contracts and signals our testing system about their updating, removal, and the appearance of new ones. Accordingly, the corresponding tasks are started in Jira, so that the automators have time to “digest” all this. Anything else can be added to this basic process - additional checks, process lotions, but without the control of changing the contracts of interaction between microservices it will be difficult to live. Having completed these two points in some way, we can proceed with the implementation.
Our test automation system will be based on such a solution as PACT frameworks. What do you need to know about them? This is a protocol interaction with the API: JSON over HTTP, there is nothing complicated about it. These solutions interact with our microservices and provide some additional functionality for isolation and testing organization. What else to say? I saw how this is implemented in one form or another in seven programming languages (Java, Javascript, Ruby, Python, Go, .NET, Swift). But if yours is not on this list, do not be alarmed: you can take the base library and make your own bike, or write something similar to what has already been implemented.
What else awaits us in almost 100% of cases? The first is the hacking of external services. The problem is that it is difficult to maintain the relevance of how the external service behaves, and to maintain this in all stubs. How to solve this problem? It depends on you. Most likely, it will be necessary to direct more resources to this or limit the coverage of tests. And second: sampled databases. It will be necessary to cut the combat databases in a lightweight form so that they contain all the necessary data for testing within our system. Then you get a clear relevant result.

We go further. The first thing I immediately wanted to do in this project was informative logging. Representative test results are always needed. A simple truth: if the results cannot be read and understood, nobody will watch them. I must say that the basic logging in PACT frameworks is very poorly implemented.
I would prefer to put it in a separate module, wrap it up and screw in what we need there. First of all, make a separation of errors according to the sources of their appearance. Further, everything that you can implement, for example, solutions like Allure (a solution from Yandex to increase the simplicity of analyzing test results). You can do anything, but the need for informative logs must be taken into account.
The next, possibly “captain's” moment is Config Reader. But as part of testing the microservice architecture, this can be a bit tricky thing. For Config Reader, we have two sources. The first is PACT files, and the second is State.

What is a .pact file? This is not some kind of encrypted binary, but a regular JSON file that has a specific structure. It distinguishes consumer, provider (i.e. who exactly and with whom interacts within the framework of this contract and in what role). The following describes the interactions (this is done by the developers): I am a consumer, and I want this service (provider) to give me “small green apples”; I am waiting for such and such a response code, status, header, body, and so on. There is a description field - this is just a description, an occasion to remind developers what was discussed in the contract, what was the meaning of it.
And the most interesting is the State Provider. What is it? In fact, this is the state in which the tested microservice should stay at the time of accessing it for a specific testing iteration, for a specific request. States can describe both SQL queries (or other mechanisms for bringing a service to a certain state), and the creation of some data in our sample database. States is a complex module that can contain all sorts of entities that bring our service to the proper state.
It is important to note that Suite runner appears here (see diagram below). This is the entity that will be responsible for running and configuring tests in a form convenient for the developer / tester. It may not be written, but I would still single out this point, since it is difficult to predict which tests will need to be run at one time or another on the project. As a result, we get such a core of testing automation for a microservice architecture:

Now, the most important thing is implementation. We must provide this scheme with the requirements for the presence of the described contracts to developers. What do we get after?
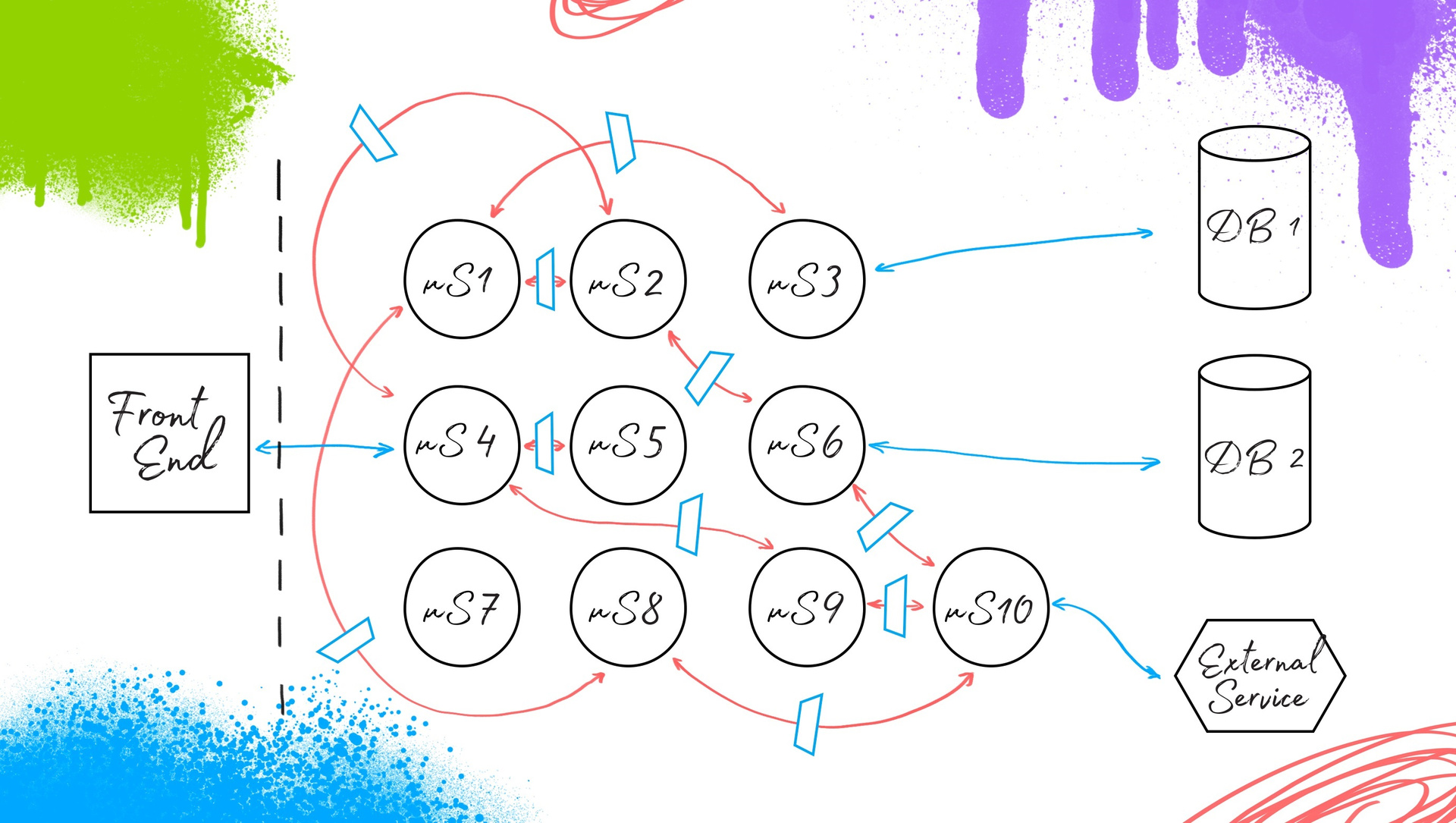
We have information on each service: about what it gives out and what it requests from its “neighbors”. Accordingly, with the help of our testing automation system, with the help of PACT files, we isolate our microservice to ensure isolation of its testing, regardless of the external services with which it is integrated. And we provide states through moki, stubs, sampled databases, or directly change the service somehow. We get, respectively, isolated testing. Voila: we have an answer to the question of what to do with test automation during the transition from a monolith to a microservice architecture.

What should be considered during implementation? The first is the use of containerization and virtualization in the build / deploy process of a microservice. And our test automation system is screwed into a container in the same way. How you will ensure the interaction of the microservice and the test automation system is not so important: it’s more convenient and do it.
The second is updating the contract requirements files. There is such a problem that the requirements of the consumer to the provider begin to pile up, and the developers are only doing what they urgently need now. Here you need to set the task at the level of test management or product management for developers: for example, work with this “tail” an hour a week so that it does not grow. Of course, these tests are quick, they can take a few seconds. But if their number is measured in thousands, this will complicate the actualization of testing. And for our part, through the commit hook system we will receive information and remove unnecessary autotests. In essence, CDC is documentation-driven development, so to speak.
Third: it is necessary to introduce the process of updating states and data suites to be introduced into this work. What is data suites? Developers in the development process write some basic interaction scenarios. For example: “I need such a request and such an answer.” And about everything else - in what framework it should exist, which parameter values are possible, and which - no, they forget. This must be verified. And here we must enter with our data-driven approach to testing, implementing this in our configurator: positive, borderline and negative tests, in order to ensure the fault tolerance of our microservice architecture on production. Without this, it is unlikely to work, any step to the right / left - and an interaction error.
Accordingly, when new pact files appear, through hook we get tasks and fill new / changed interactions with a large number of data sets in interactions, which is equal to a whole series of tests performed. We can fill and edit interactions manually, and we can make generators that will parameterize them and drive tests.
As for the States: if we take the automation of testing the web, then these are preconditions, setUps, FixTure; there is a problem for microservices - there is no ready-made mechanism: you need to consider how you will match the change of the name of the States in the PACT files in this module. The simplest mechanism is to use Aliases, essentially KDT (keyword driven testing), speaking the language of test automation. I’m not ready to talk about a more beautiful and elegant solution: I haven’t come up with it yet.

If you prefer not to read, but watch videos, then this information is available in the format of the report here . And in late August, Avito will host a thematic rally for testing professionals. Let's talk about the vectors of development of automation systems in general, discuss the application of applied tools and their impact on changing the testing infrastructure. If interested, stay tuned for updates on our FB page , or write in the comments: let us know when there will be details about the event.
Instead of joining
“An implementation should be conservative in its sending behavior, and liberal in its receiving behavior."
Jonathan Bruce Postel, computer scientist
What is microservice architecture?
To complete my story, let's start with the basics. To simplify, microservice architecture is a way to organize an application server. How does he work? Essentially, this is simply the answer of a service-oriented architecture to the emergence of practices such as DevOps. If SOA does not regulate the size of services and what exactly they should do, then there are some speculative limitations within the microservice architecture. A microservice is an entity that embodies one small functionality that it manages and provides some data to external services.
Sometimes they give information that a microservice is 500 lines of code. But this is optional; the point is that these services are quite small and form the same business processes as the monolithic back-end, which works on many projects. Functionally - the same thing, the differences - in the organizational structure.
What could be the problem here? Services are quickly becoming a lot, their connectivity is increasing. This complicates testing: checking for a change in one microservice entails the need to raise a fairly thick layer of infrastructure from the many services with which the mutable microservice interacts. At a certain point in the development of the project, the number of relationships and dependencies grows greatly and it becomes difficult to perform quick and isolated testing. We are starting to work more slowly. Development is slowing down. These and some other problems can be solved using test automation.
Transition to microservices
To begin, consider the transition from a monolith to a microservice architecture. In the case of a monolith, in order to replace any piece in this system, we cannot roll it out separately. You need to rebuild and completely update the back end. This is not always rational and convenient. What happens when switching to microservice architecture? We take the back-end and divide it into its component components, dividing them by functionality. We determine the interactions between them, and we get a new system with the same front-end and the same databases. Microservices interact with each other and provide the same business processes. For the user and system testing, everything remained as before, the internal organization has changed.
What does it give? You can make a change in the microservice X, which implements some of its functionality, and immediately roll it out to work. It all sounds very good. But, as always, there is a nuance: you need to check how microservices interact with each other.
Microservice Architecture Contracts
Microservice interactions among themselves are implemented through contracts. What does this mean for service oriented architecture? A contract is a certain agreement that service developers create for external users to interact with each other. The developers of the service themselves decide that you can ask them for “X”, and they will provide you with “Y”. The service can provide apples, tomatoes, plutonium to external users, sell children's clothes or televisions - it does not declare a clear focus on functionality. Internal content is regulated only at the level of common sense. And accordingly, this service dictates to external users what they will receive and how to access it.
If we increase the complexity of this task, when there will be not dozens of services (10-20-50), but hundreds (200, 400 ... 2000), then the traditional, “classical” contracts will stop working in the functional sense. And then the need arises to modernize contracts for microservice architecture. A template has been developed for developers, in which they and the “end users” of the microservice are interchanged - this approach is called consumer driven contacts. Now requests are made by external users. This can be imagined as a conversation of this kind:
User 1: “I heard you supply apples. I need small and green ones. ”
User 2: “And I need huge red apples.”
User N: “And I need you to bring three tons of apples.”
Thus, it turns out that users create contracts, set requirements and send them to the provider that implements them. What is the plus? Since each service has a rather limited number of consumers, it is much easier to get three specifications from each and to implement them, rather than trying to guess which “apples” to provide in each particular case and what else they may need in addition to these “fruits”.
For this approach, we, as a quality assurance department, must provide a worthy answer in the field of testing so as not to slow down the process of quickly rolling out microservices.
Predicates for CDC-testing (Consumer Driven Contracts)
What can't start working on CDC-testing principles without? The first one. We will not be able to help if we see that the process of working under contracts is not followed in our development. The second thing is more technical: it is a post-commit system (post-PR, if you like) of hooks, which processes this communication flow between developers using contracts and signals our testing system about their updating, removal, and the appearance of new ones. Accordingly, the corresponding tasks are started in Jira, so that the automators have time to “digest” all this. Anything else can be added to this basic process - additional checks, process lotions, but without the control of changing the contracts of interaction between microservices it will be difficult to live. Having completed these two points in some way, we can proceed with the implementation.
CDC Automation Implementation
Our test automation system will be based on such a solution as PACT frameworks. What do you need to know about them? This is a protocol interaction with the API: JSON over HTTP, there is nothing complicated about it. These solutions interact with our microservices and provide some additional functionality for isolation and testing organization. What else to say? I saw how this is implemented in one form or another in seven programming languages (Java, Javascript, Ruby, Python, Go, .NET, Swift). But if yours is not on this list, do not be alarmed: you can take the base library and make your own bike, or write something similar to what has already been implemented.
What else awaits us in almost 100% of cases? The first is the hacking of external services. The problem is that it is difficult to maintain the relevance of how the external service behaves, and to maintain this in all stubs. How to solve this problem? It depends on you. Most likely, it will be necessary to direct more resources to this or limit the coverage of tests. And second: sampled databases. It will be necessary to cut the combat databases in a lightweight form so that they contain all the necessary data for testing within our system. Then you get a clear relevant result.
We go further. The first thing I immediately wanted to do in this project was informative logging. Representative test results are always needed. A simple truth: if the results cannot be read and understood, nobody will watch them. I must say that the basic logging in PACT frameworks is very poorly implemented.
I would prefer to put it in a separate module, wrap it up and screw in what we need there. First of all, make a separation of errors according to the sources of their appearance. Further, everything that you can implement, for example, solutions like Allure (a solution from Yandex to increase the simplicity of analyzing test results). You can do anything, but the need for informative logs must be taken into account.
The next, possibly “captain's” moment is Config Reader. But as part of testing the microservice architecture, this can be a bit tricky thing. For Config Reader, we have two sources. The first is PACT files, and the second is State.
What is a .pact file? This is not some kind of encrypted binary, but a regular JSON file that has a specific structure. It distinguishes consumer, provider (i.e. who exactly and with whom interacts within the framework of this contract and in what role). The following describes the interactions (this is done by the developers): I am a consumer, and I want this service (provider) to give me “small green apples”; I am waiting for such and such a response code, status, header, body, and so on. There is a description field - this is just a description, an occasion to remind developers what was discussed in the contract, what was the meaning of it.
And the most interesting is the State Provider. What is it? In fact, this is the state in which the tested microservice should stay at the time of accessing it for a specific testing iteration, for a specific request. States can describe both SQL queries (or other mechanisms for bringing a service to a certain state), and the creation of some data in our sample database. States is a complex module that can contain all sorts of entities that bring our service to the proper state.
It is important to note that Suite runner appears here (see diagram below). This is the entity that will be responsible for running and configuring tests in a form convenient for the developer / tester. It may not be written, but I would still single out this point, since it is difficult to predict which tests will need to be run at one time or another on the project. As a result, we get such a core of testing automation for a microservice architecture:
Now, the most important thing is implementation. We must provide this scheme with the requirements for the presence of the described contracts to developers. What do we get after?
We have information on each service: about what it gives out and what it requests from its “neighbors”. Accordingly, with the help of our testing automation system, with the help of PACT files, we isolate our microservice to ensure isolation of its testing, regardless of the external services with which it is integrated. And we provide states through moki, stubs, sampled databases, or directly change the service somehow. We get, respectively, isolated testing. Voila: we have an answer to the question of what to do with test automation during the transition from a monolith to a microservice architecture.
What to consider when implementing?
What should be considered during implementation? The first is the use of containerization and virtualization in the build / deploy process of a microservice. And our test automation system is screwed into a container in the same way. How you will ensure the interaction of the microservice and the test automation system is not so important: it’s more convenient and do it.
The second is updating the contract requirements files. There is such a problem that the requirements of the consumer to the provider begin to pile up, and the developers are only doing what they urgently need now. Here you need to set the task at the level of test management or product management for developers: for example, work with this “tail” an hour a week so that it does not grow. Of course, these tests are quick, they can take a few seconds. But if their number is measured in thousands, this will complicate the actualization of testing. And for our part, through the commit hook system we will receive information and remove unnecessary autotests. In essence, CDC is documentation-driven development, so to speak.
Third: it is necessary to introduce the process of updating states and data suites to be introduced into this work. What is data suites? Developers in the development process write some basic interaction scenarios. For example: “I need such a request and such an answer.” And about everything else - in what framework it should exist, which parameter values are possible, and which - no, they forget. This must be verified. And here we must enter with our data-driven approach to testing, implementing this in our configurator: positive, borderline and negative tests, in order to ensure the fault tolerance of our microservice architecture on production. Without this, it is unlikely to work, any step to the right / left - and an interaction error.
Accordingly, when new pact files appear, through hook we get tasks and fill new / changed interactions with a large number of data sets in interactions, which is equal to a whole series of tests performed. We can fill and edit interactions manually, and we can make generators that will parameterize them and drive tests.
As for the States: if we take the automation of testing the web, then these are preconditions, setUps, FixTure; there is a problem for microservices - there is no ready-made mechanism: you need to consider how you will match the change of the name of the States in the PACT files in this module. The simplest mechanism is to use Aliases, essentially KDT (keyword driven testing), speaking the language of test automation. I’m not ready to talk about a more beautiful and elegant solution: I haven’t come up with it yet.
Summary
- As for post-commit-hooks, automation of monitoring, appearance and change, removal of contracts between services - all this needs to be automated, it is part of the system. I would say that this is a piece of the kernel that stands at the repository level.
- A CDC pattern for developers is required. This is the foundation, nothing will not work without it.
- You will notice a decrease in the tendency of the system to appear defects. In fact, all of its parts are shrouded in insulating testing. We quickly localize defects, they are quickly fixed, we have a high test coverage. If defects appear at the level of system testing, they are most likely to be associated with the front-end or some external services.
- You have the opportunity to get away from manually testing changes. Key points: fast and isolated testing. Then we will get profit from the fact that we can well localize the problem or defect.
PS
If you prefer not to read, but watch videos, then this information is available in the format of the report here . And in late August, Avito will host a thematic rally for testing professionals. Let's talk about the vectors of development of automation systems in general, discuss the application of applied tools and their impact on changing the testing infrastructure. If interested, stay tuned for updates on our FB page , or write in the comments: let us know when there will be details about the event.