garbage.collect ()
The browser needs a little memory to execute JavaScript, you need to store objects, primitives, functions that are created for all user actions somewhere. Therefore, the browser first allocates the necessary amount of RAM, and when objects are not used, it cleans it independently.
In theory, it sounds good. In practice, the user opens 20 tabs from YouTube, social networks, reads something, works, the browser eats memory, like Hummer H2 - gasoline. A garbage collector, like this monster with a mop, runs through memory and adds confusion, everything slows down and falls.

To prevent such situations from happening and the performance of our sites and applications did not suffer, the front-end developer should know how garbage affects applications, how the browser collects and optimizes memory management, and how this all differs from harsh reality. Just about this report by Andrei Roenko ( flapenguin ) at Frontend Conf 2018 .
We use the garbage collector (not at home - in front-end development) every day, but we don’t really think about what it is, what it costs us and what its capabilities and limitations are.
But so far it is not so, and we will talk about what is - about the assembly of unnecessary objects.
About the speaker : Andrei Roenko is developing the Yandex.Maps API , has been in the front end for six years, likes to create his own high abstractions and descend to the ground from strangers.
Why do we need garbage collection?
Consider the example of Yandex.Maps. Yandex.Maps is a huge and complex service that uses a lot of JS and almost all existing browser APIs, except multimedia, and the average session time is 5-10 minutes. The abundance of javascript creates many objects. Dragging a map, adding organizations, search results and many other events that occur every second creates an avalanche of objects. Add to this the React and objects becomes even more.
However, JS objects occupy only 30–40 MB on the map. For long sessions, Yandex.Maps and the constant allocation of new objects is not enough.
Today we will talk about garbage collection from four sides:
All statements are supported by examples of how you can and how not to do.
Garbage collection is an imperceptible thing for us, but knowing how it works you will:
Theory
Joel Spolsky once said:
A garbage collector is one big non-trivial abstraction that is patched from all sides. To our happiness, it flows very rarely.
Let's start with the theory, but without boring definitions. Let us analyze the work of the collector by the example of simple code:
Let's see how this code will behave if we run it this way:
Let us analyze the code and its components in more detail and begin with the class.
Class declaration

We can assume that classes in ECMAScript 2015 are just syntactic sugar for functions. All functions have:
Prototypes occupy a lot of space on the scheme, so let's remember that they are, but then we remove for simplicity.
Creating a class object
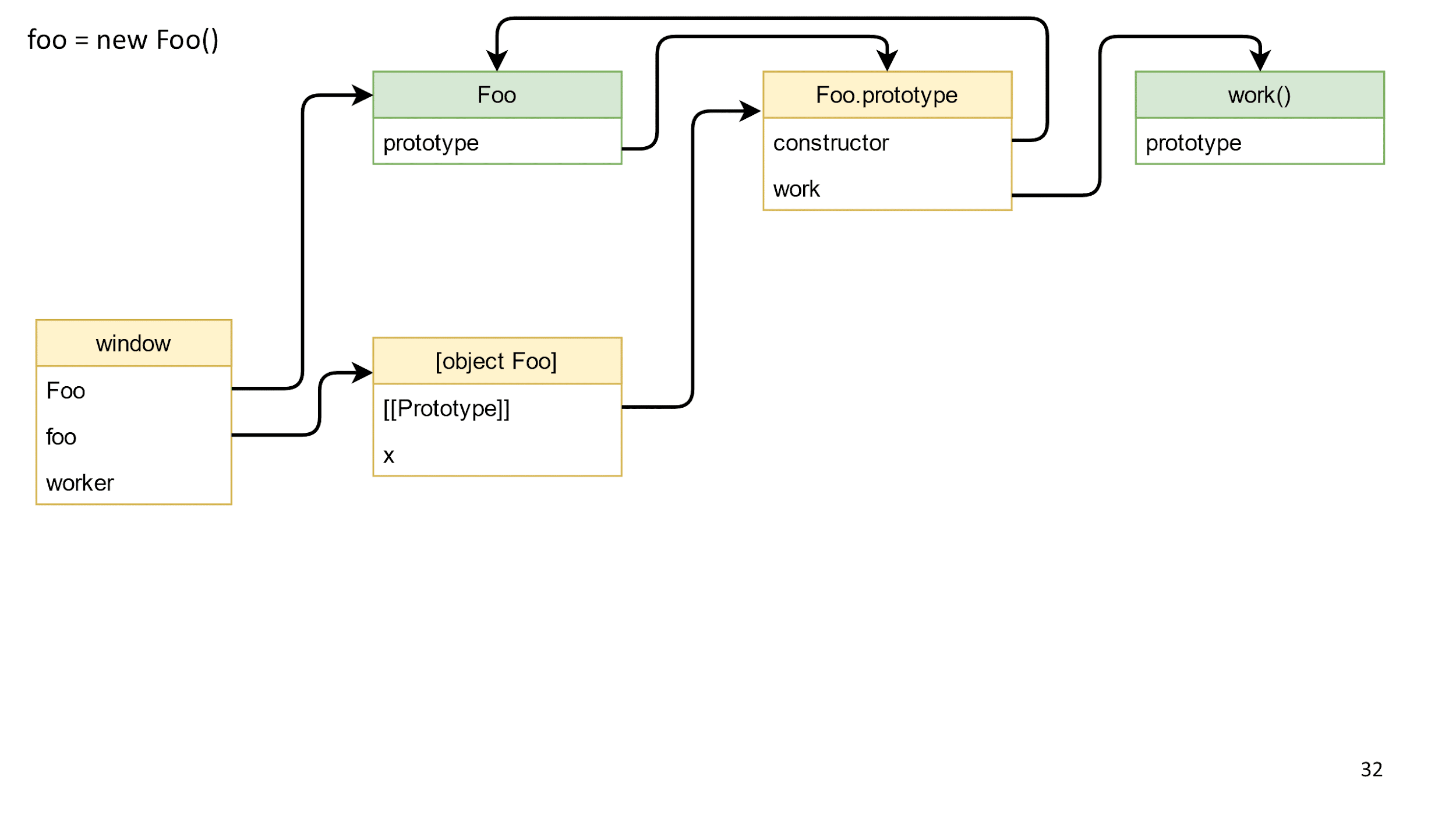
Here's what happened:
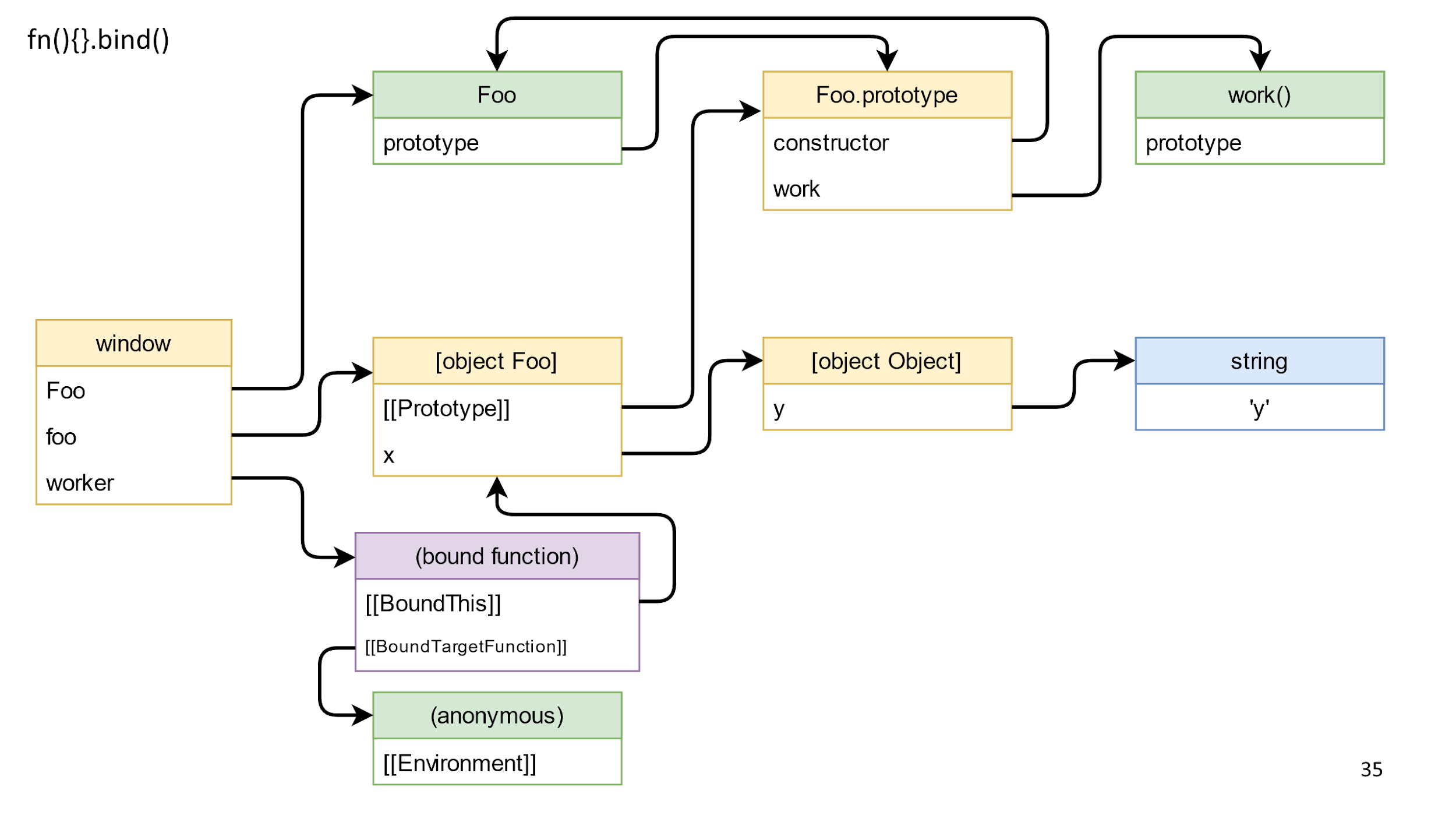
The method returns a bound function — this is such a special “magic” object in JS, which consists of the bound this and the function that needs to be called. The associated function also has a prototype and another prototype, but we are interested in the closure. By specification, the closure is stored in Environment. Most likely you are used to the word Scope, but in the specifications the field is called Environment .
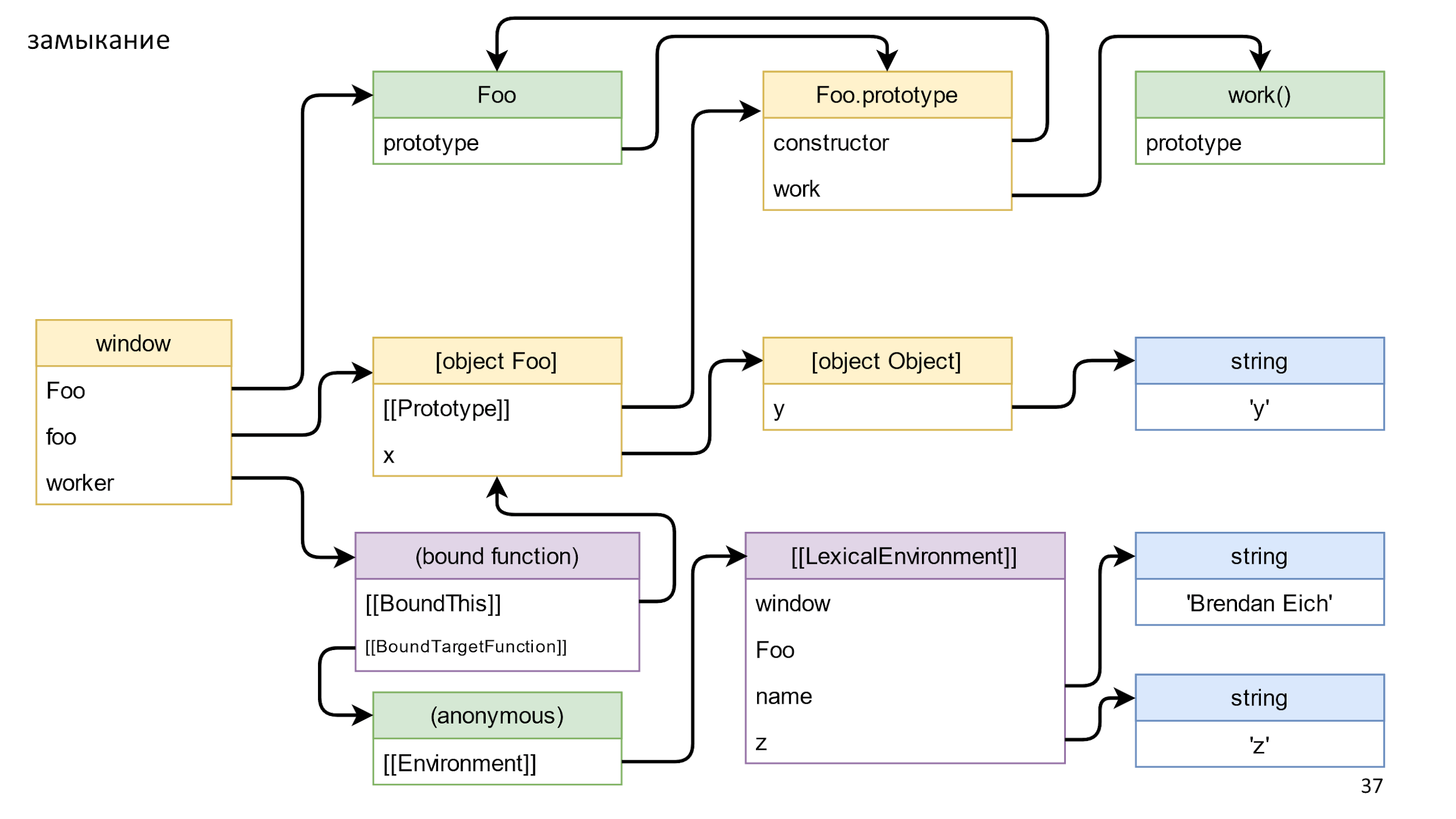
The Environment stores a link to LexicalEnvironment. This is a complex object, more complicated than the slide, it contains links to everything that can be accessed from a function. For example, window, foo, name, and z. There are also links even to what you clearly do not use. For example, you can apply eval and accidentally use unused objects, but JS should not break.
So, we have built all the objects and now we will destroy everything.
Remove the link to the object
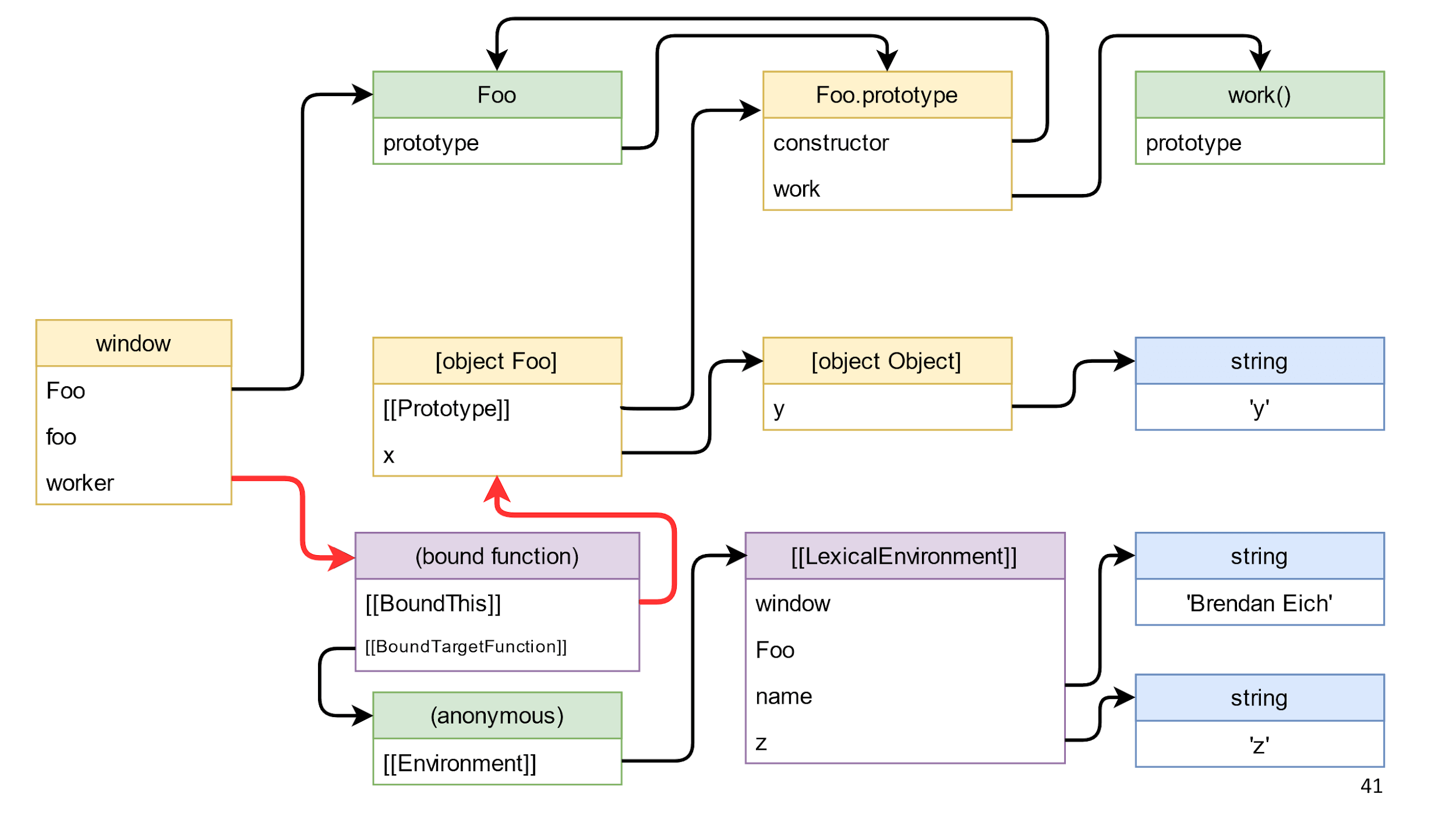
Let's start by removing the object link, this link in the diagram is highlighted in red.
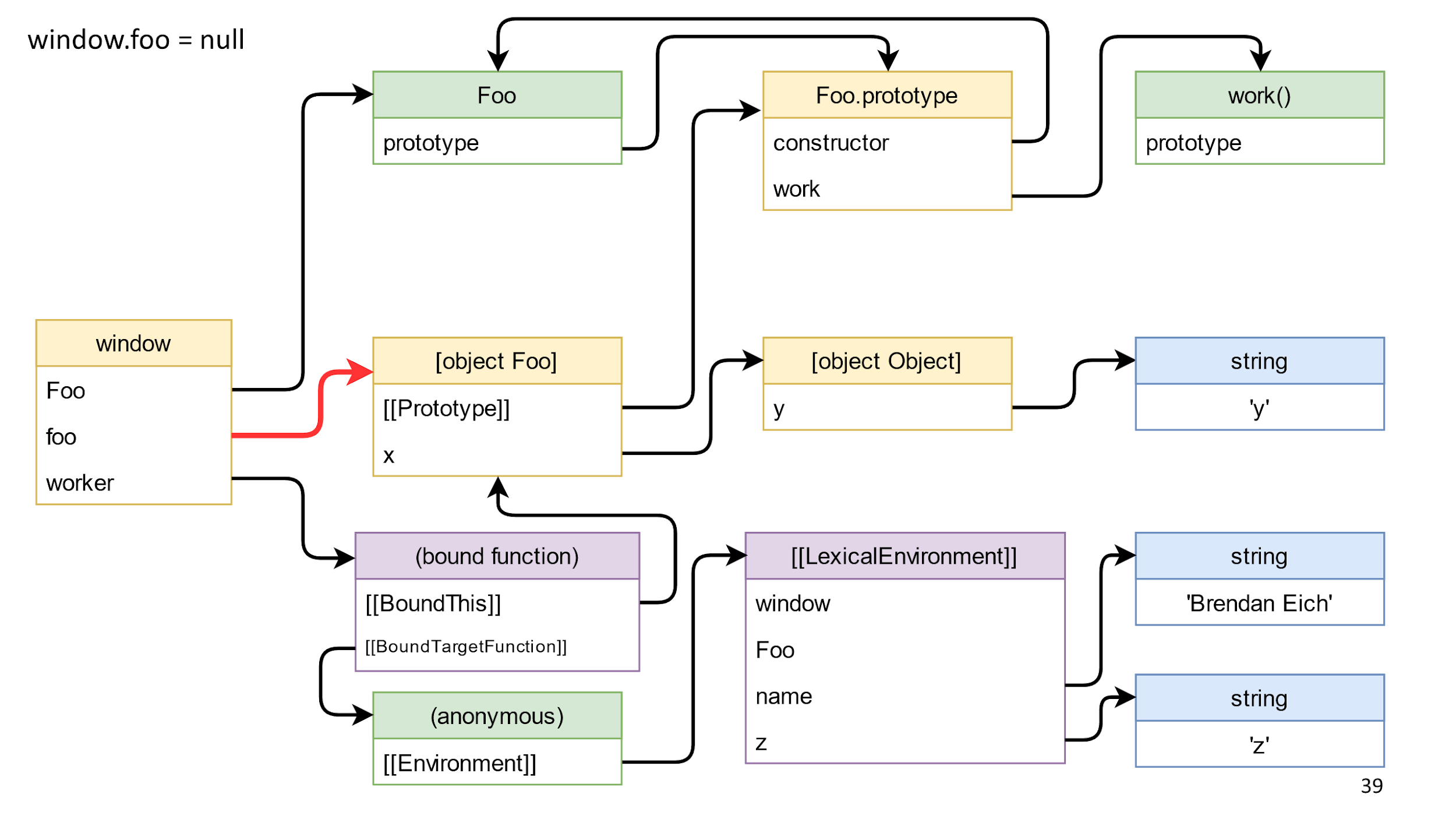
We delete and nothing happens, because from the window to the object there is a path through the bound function function.
This pushes us to a typical error.
A typical mistake is a forgotten subscription.
Occurs when you subscribe: using this, explicitly via bind or through switch functions; use something in closure. Then you forget to unsubscribe, and the lifetime of your object or of what is in the closure becomes the same as the lifetime of the subscription. For example, if this is a DOM element that you do not touch with your hands, then, most likely, this is the time until the end of the page’s life.
To solve this problem:
Remove class reference
Go ahead and try to remove the class reference highlighted in red.
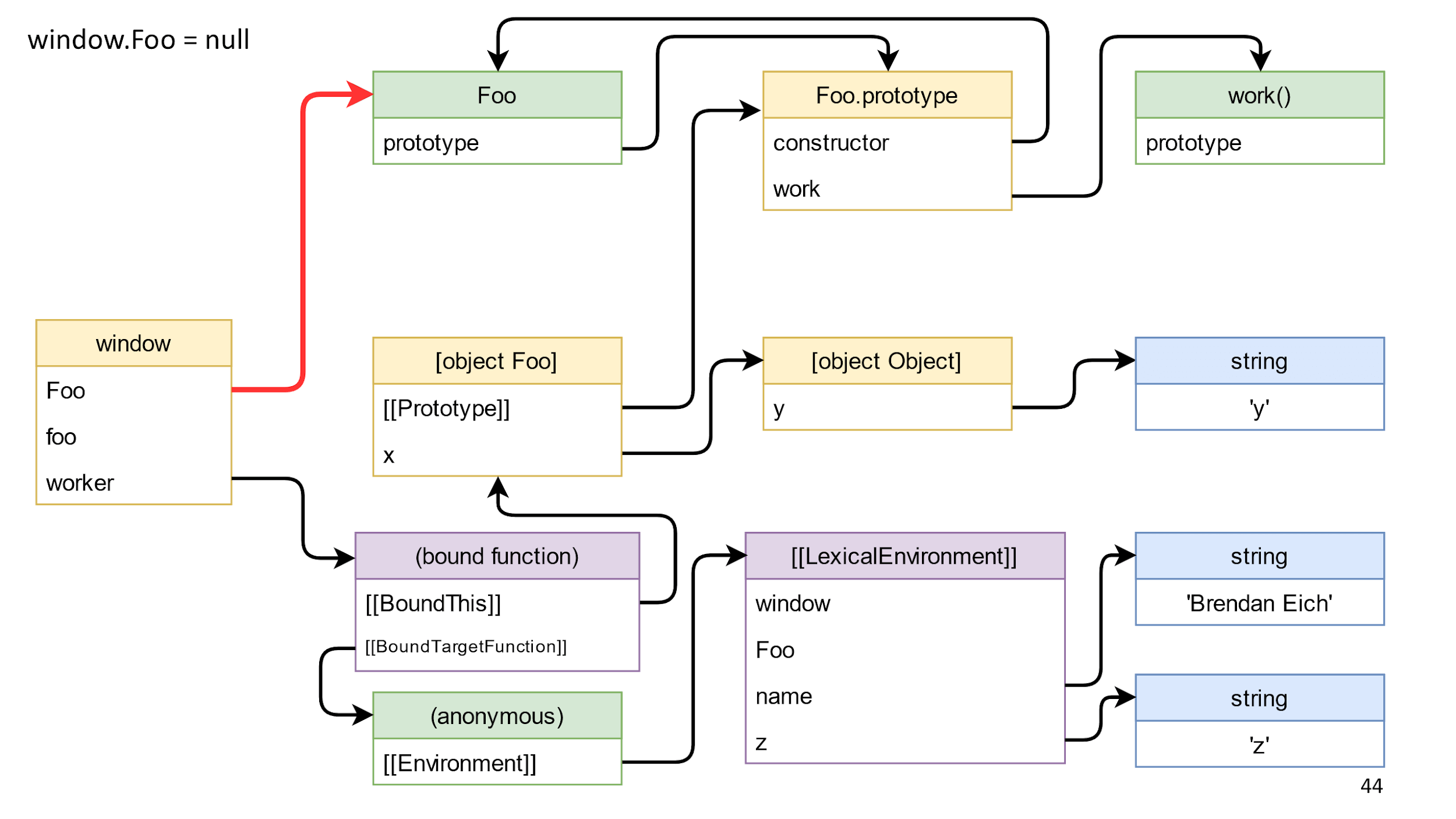
We delete the link and nothing changes here. The reason is that the class is available through BoundThis, which has a link to the prototype, and in the prototype there is a link back to the constructor.
Typical
Why do we need all these demonstrations? Because there is a downside of the problem when people take advice to nullify links too literally and nullify everything.
This is a pretty useless job. If an object consists only of references to other objects and there are no resources there, then no destroy () is needed. It is enough to lose the link to the object, and it will die by itself.
There is no universal council. When it is necessary - null, and when it is not necessary - do not null. Zanulenie not a mistake, but simply useless work.
Go ahead. Call the method bound function and it will remove the link from [object Foo] to [object Object]. This will lead to the fact that in the scheme there will appear objects that are alone in the blue rectangle.
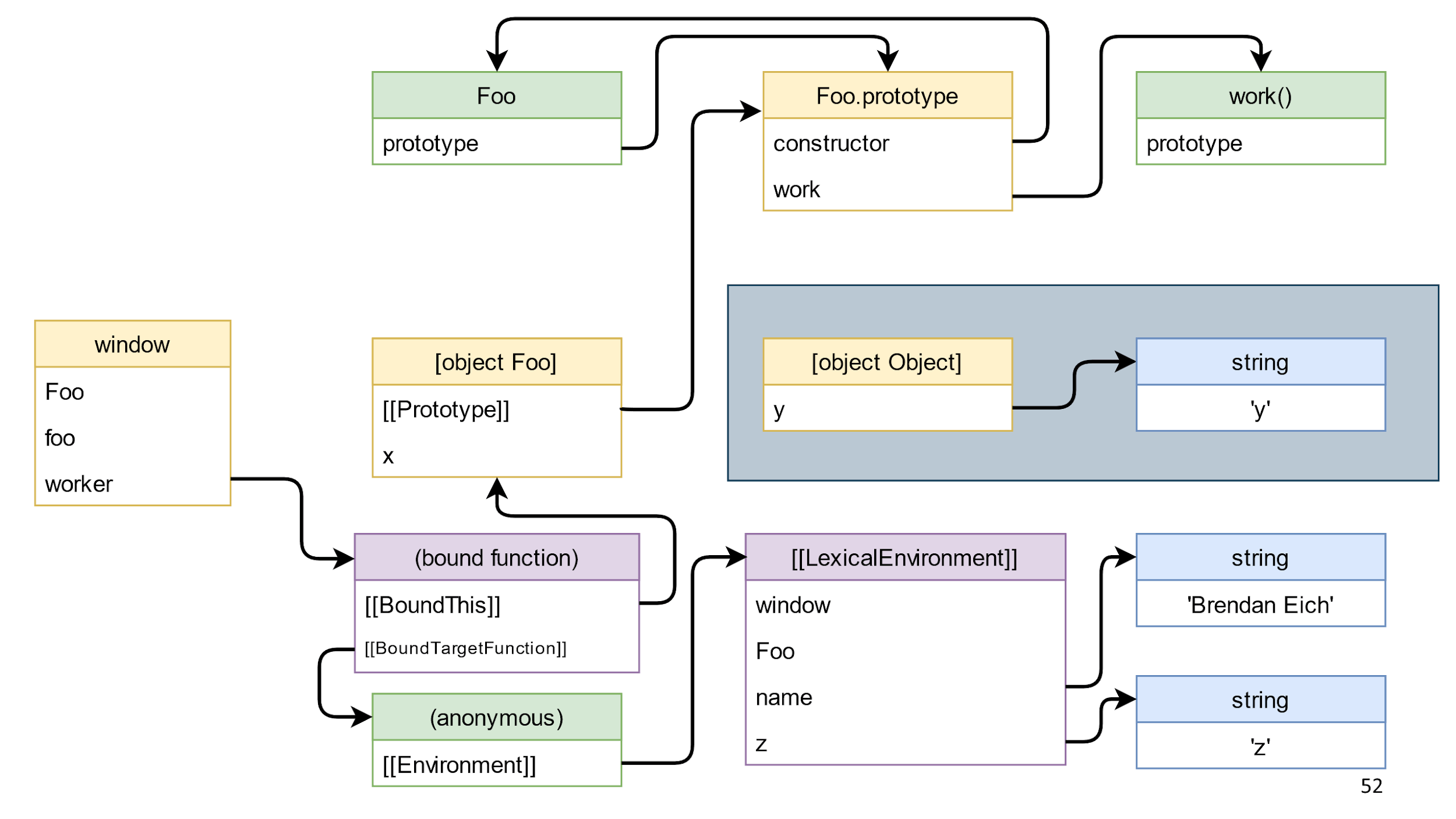
These objects are js trash. He is perfectly going. However, there is garbage that does not lend itself to the collector.
Garbage that is not going to
In many browser APIs you can create and destroy an object. If the object is not destroyed, then no collector can assemble it.
Objects with pair functions create / delete:
For example, if you forget to remove ObjectURL from a 200 MB video, then these 200 MB will be in memory until the end of the page’s life and even longer, because there is data exchange between the tabs. Similarly in WebGL, indexDb and other browser-based APIs with similar resources.
Fortunately, in our example in the blue rectangle just JavaScript objects, so this is just garbage that can be removed.
The next step is to clean the last link from left to right. This is a link to the method we received, to the associated function.
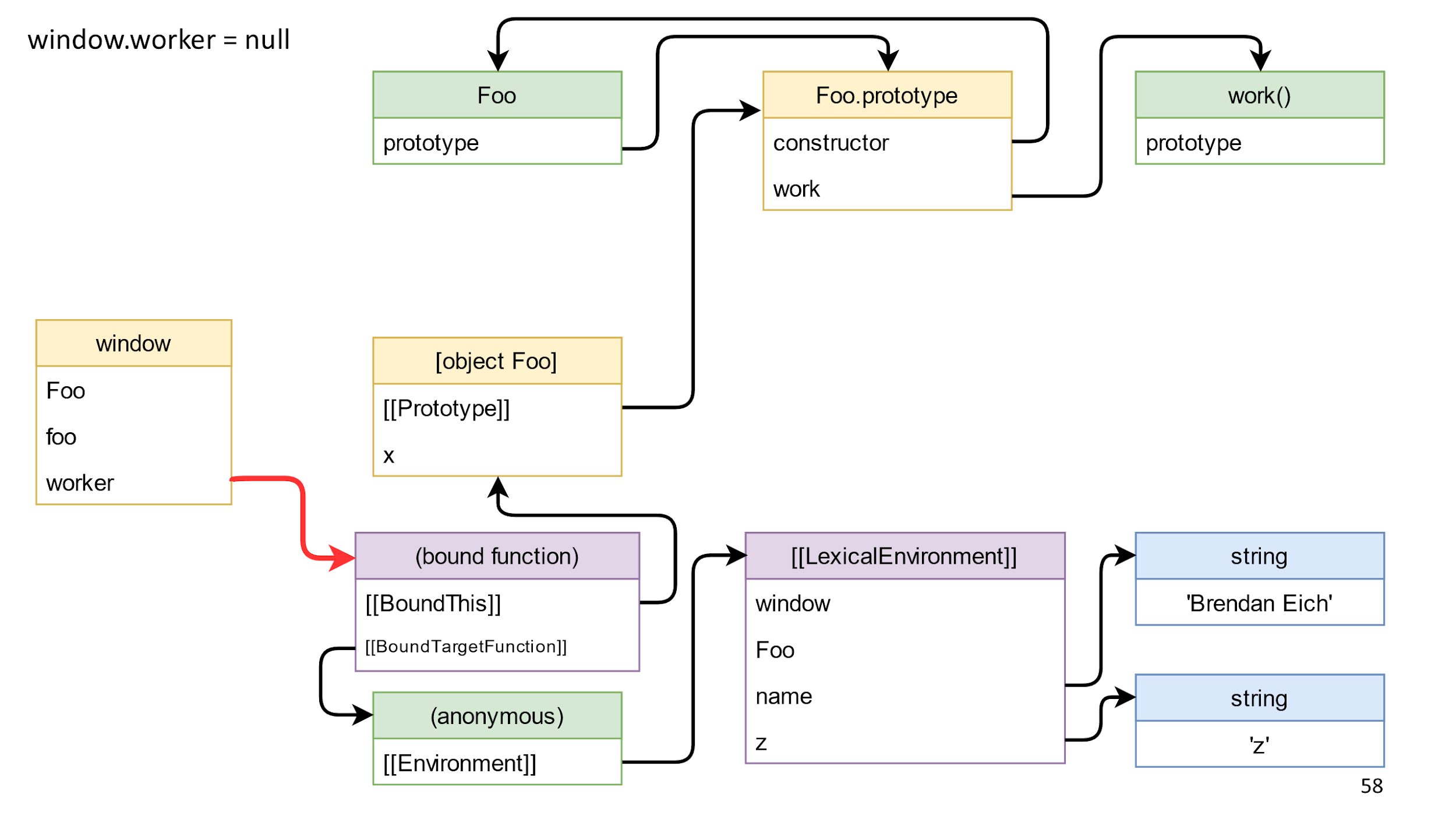
After its removal, we will not have links between the left and the right side? In fact, there are still references from the closure.
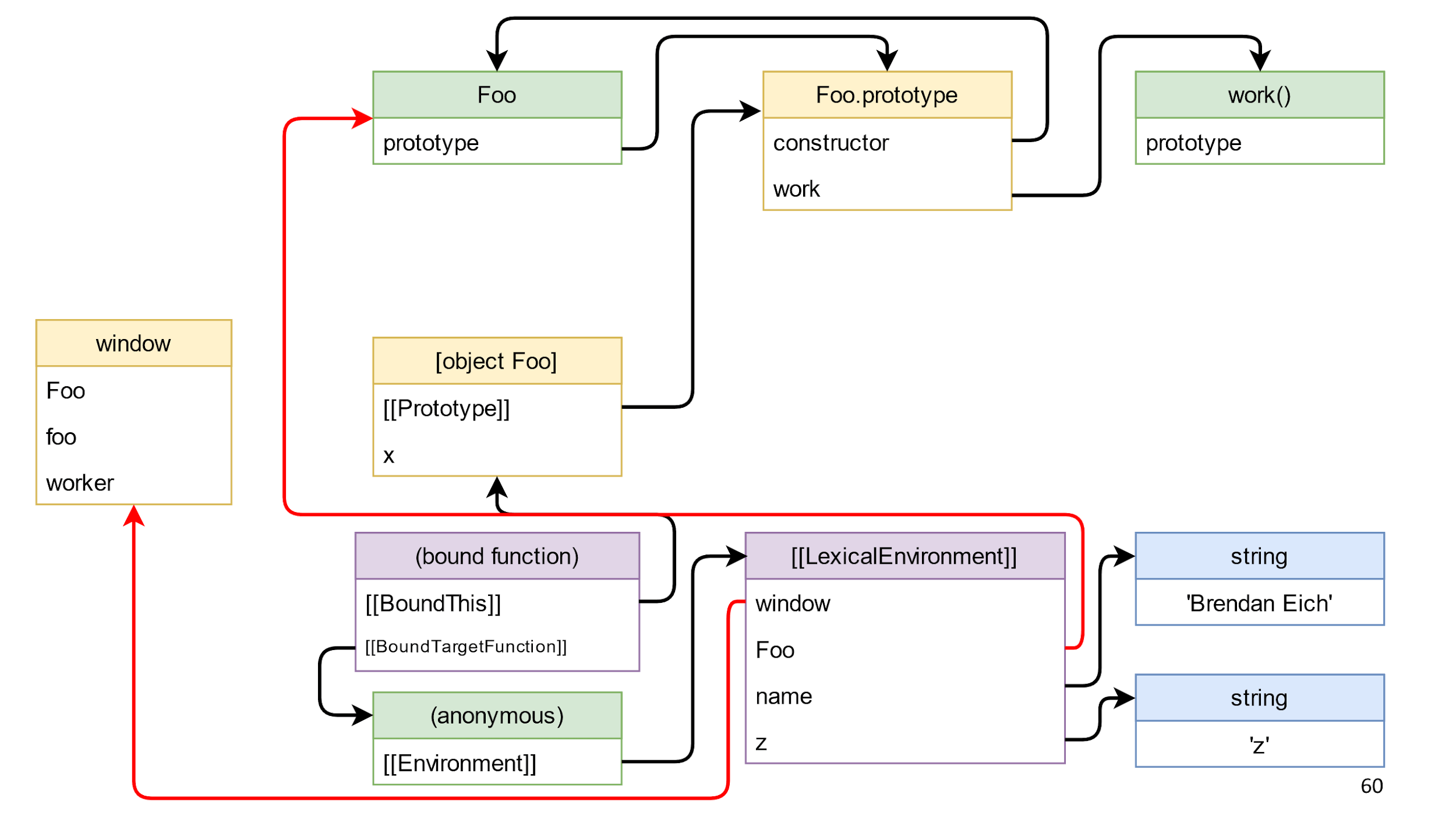
It is important that there are no links from left to right, therefore everything except window is garbage, and it will die.
Important note: there are circular references in the garbage, that is, objects that link to each other. The presence of such links does not affect anything, because the garbage collector does not collect individual objects, but all the garbage.
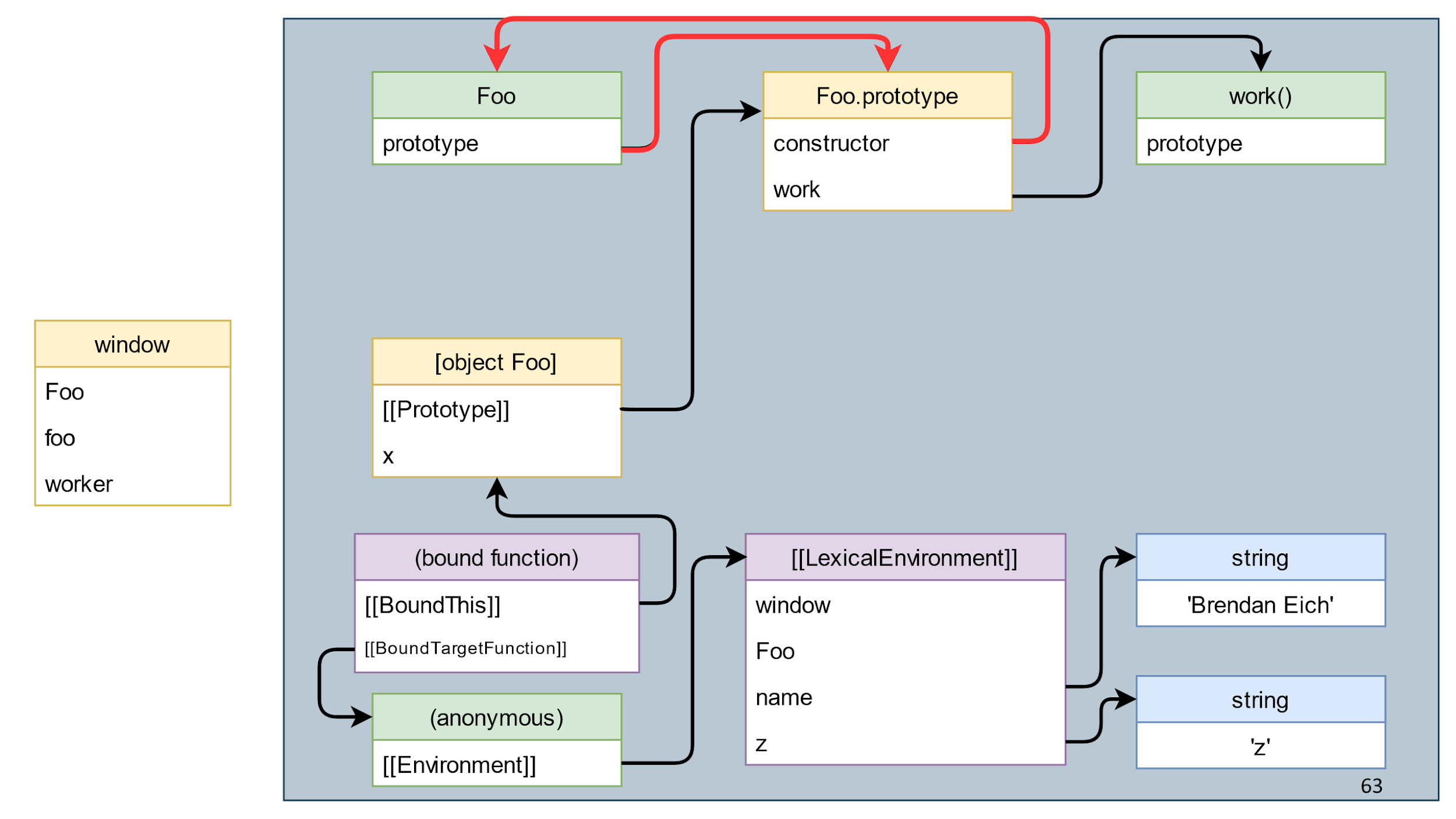
We looked at examples and now, at an intuitive level, we understand what rubbish is, but let's give a complete definition of the concept.
Everything became very clear. But what is a living object?
A living object is an object that can be reached by links from the root object.
Two new concepts appear: “follow the links” and “root object”. One root object we already know is window, so let's start with links.
What does it mean to follow the links?
There are many objects that are related to each other and link to each other. We will start a wave along them, starting with the root object.
We initialize the first step, and then we act according to the following algorithm: let's say that all that is on the crest of the wave are living objects and see what they refer to.
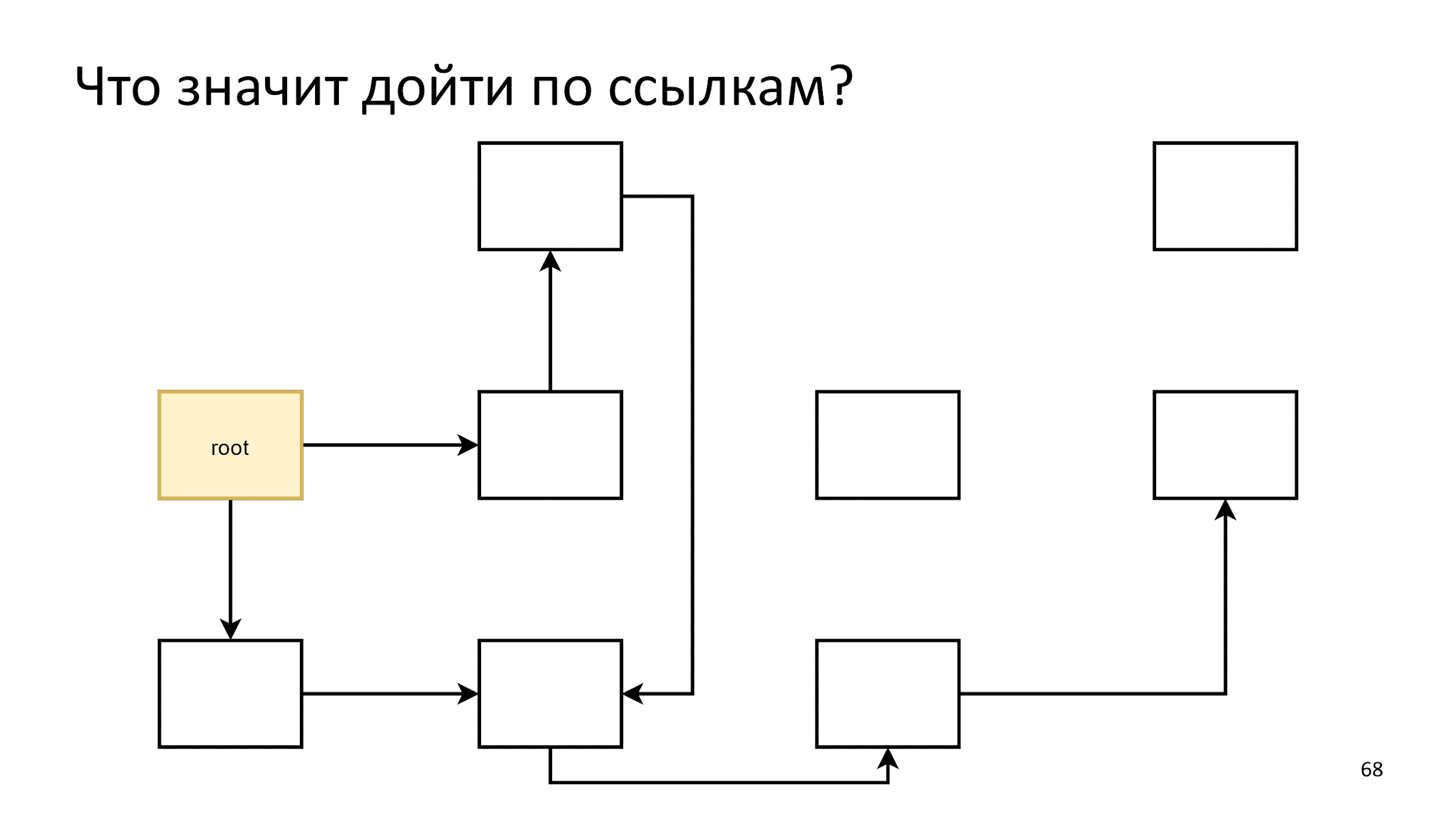
Initialize the first step. Then we will act according to the following algorithm: let's say that all the yellow on the crest of the wave are living objects and see what they refer to.
We will make what they refer to as a new crest of the wave:
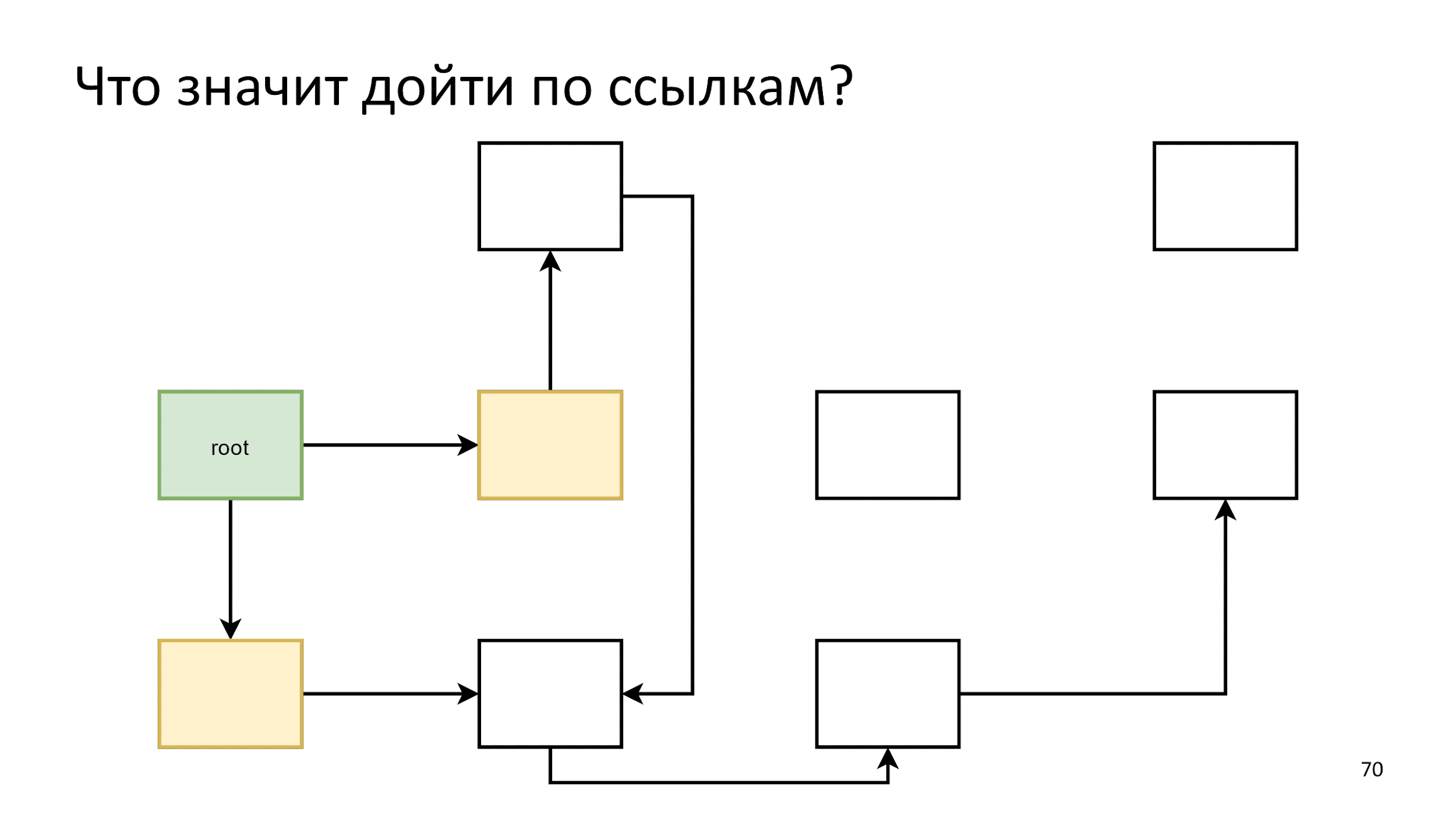
Finished and start anew:
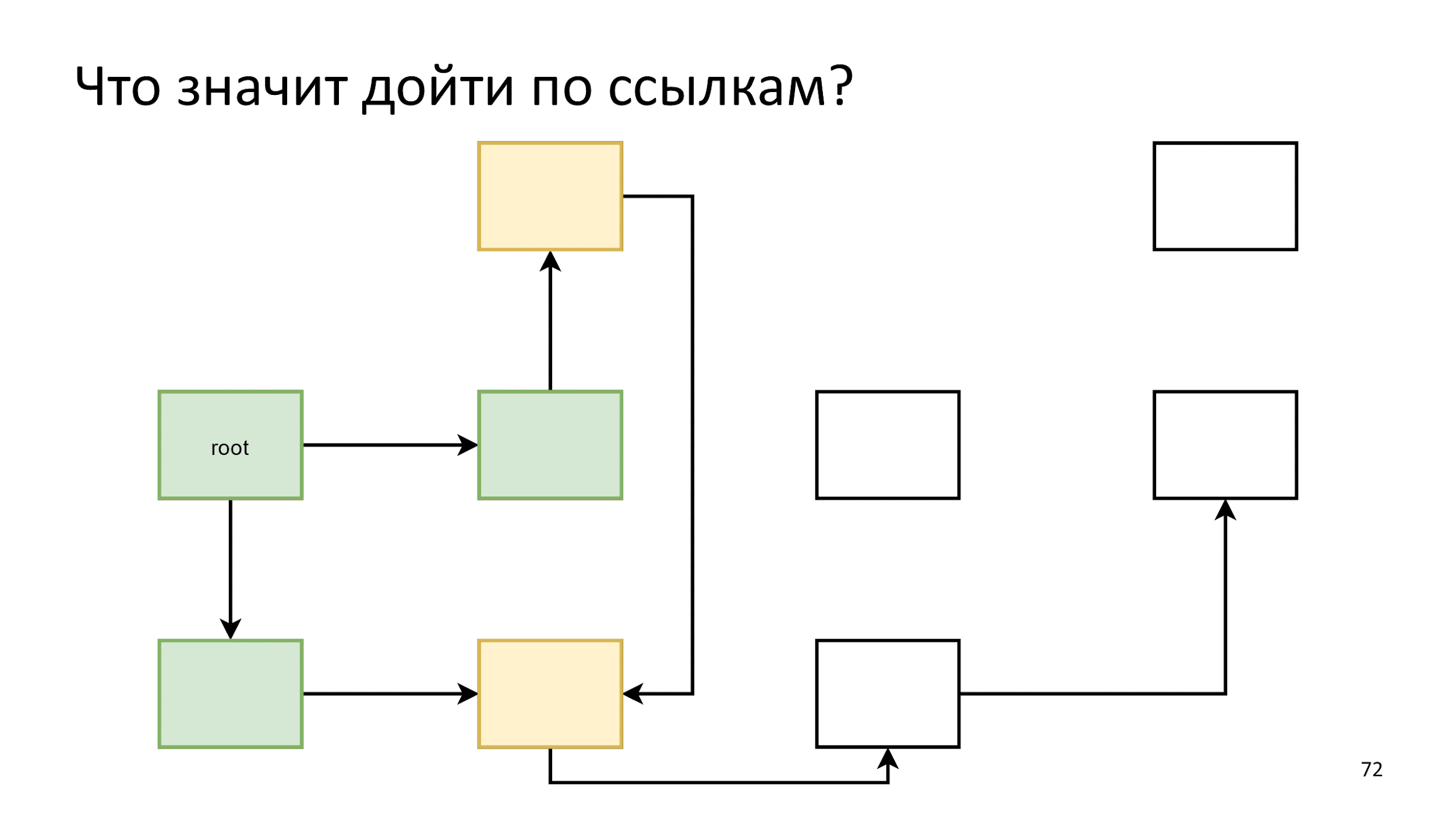
Noticing that one arrow points to an already living object, we simply do nothing. Further according to the algorithm, until the objects for traversing are finished. Then we say that we have found all the living objects, and all the rest is rubbish.
This process is called marking .
What does the root object mean?
Build may occur at any time. Every time braces or function appear, a new object is created. The memory may not be enough, and the collector will go looking for a free one:
In this case, the root objects will be all that is on the call stack. If you, for example, stop at line X and delete what Y refers to, then your application will crash. JS does not allow us such frivolities, so you cannot delete an object from Y.
If the previous part seemed difficult, then it will be even more difficult.
Harsh reality
Let's talk about the world of machines, in which we deal with iron, with physical carriers.
Memory is one big array in which just numbers lie, for example: new Uint32Array (16 * 2 ** 30).
Let's create objects in memory and add them from left to right. Create one, second, third - they are all different sizes. Along the way we put down the links.
On the seventh object the place is over, because we have 2 empty squares, but we need 5.
What can we do here? The first option is to crash. It's 2018 in the yard, everyone has the latest MacBooks and 16 GB of RAM. There are no situations when there is no memory!
However, letting things go bad is a bad idea, because on the web this leads to a screen like this:
This is not the behavior that we want from the program, but in general it is valid. There is a category of collectors called No-op .
No-op collector
Pros:
Minuses:
For the frontend, the no-op collector is irrelevant, but used on the backend. For example, having several servers behind balancers, the application is given 32 GB of RAM and then it is killed entirely. It's easier and productivity is only enhanced by simply restarting when memory becomes low.
In the web, it is impossible and you have to clean it.
Find and remove trash
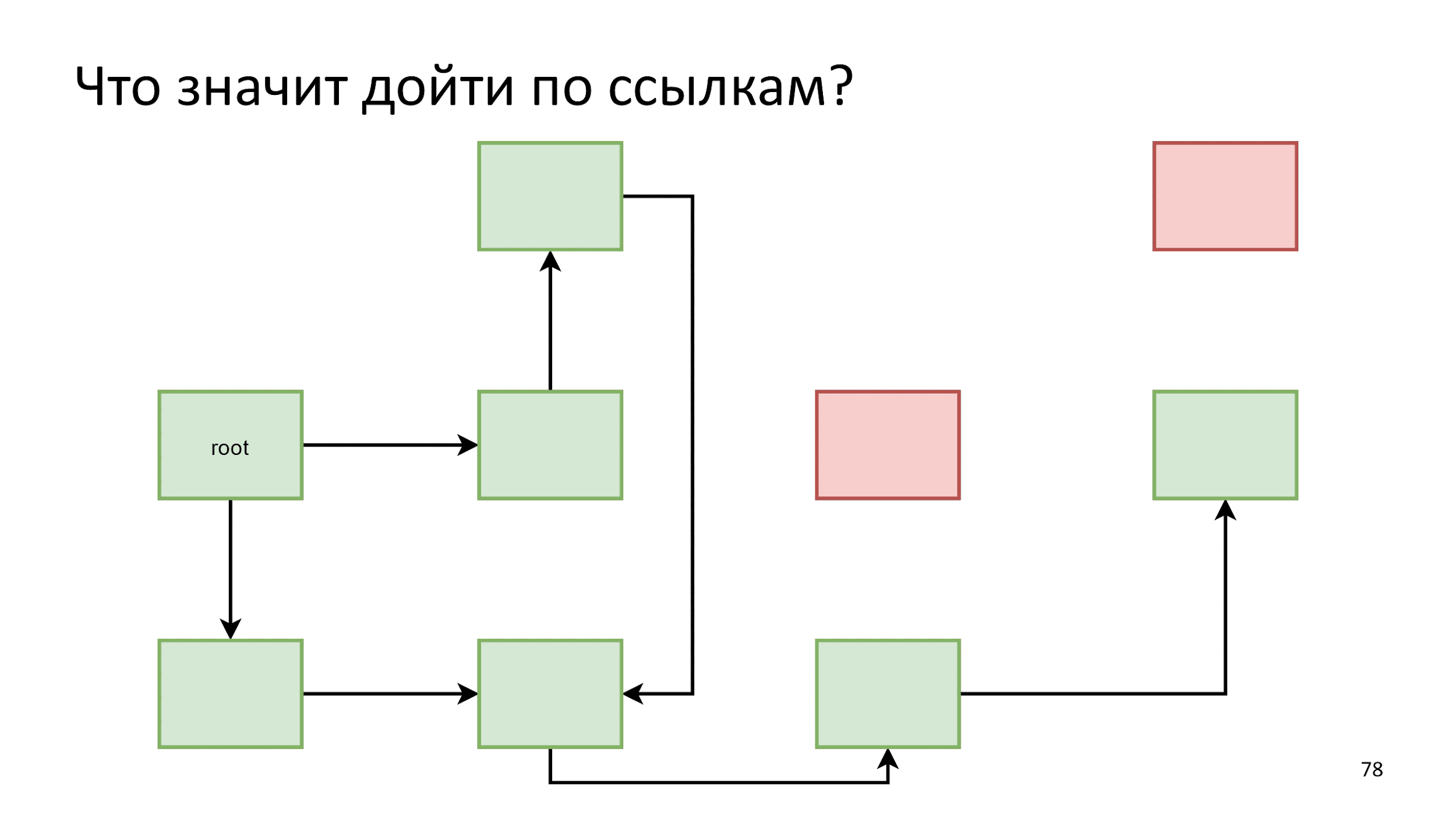
Let's start cleaning with trash search. We already know how to do this. Garbage - objects C and F in the previous scheme, because they can not be reached along the arrows from the root object.
We take this garbage, feed it to the garbage lover and is ready.
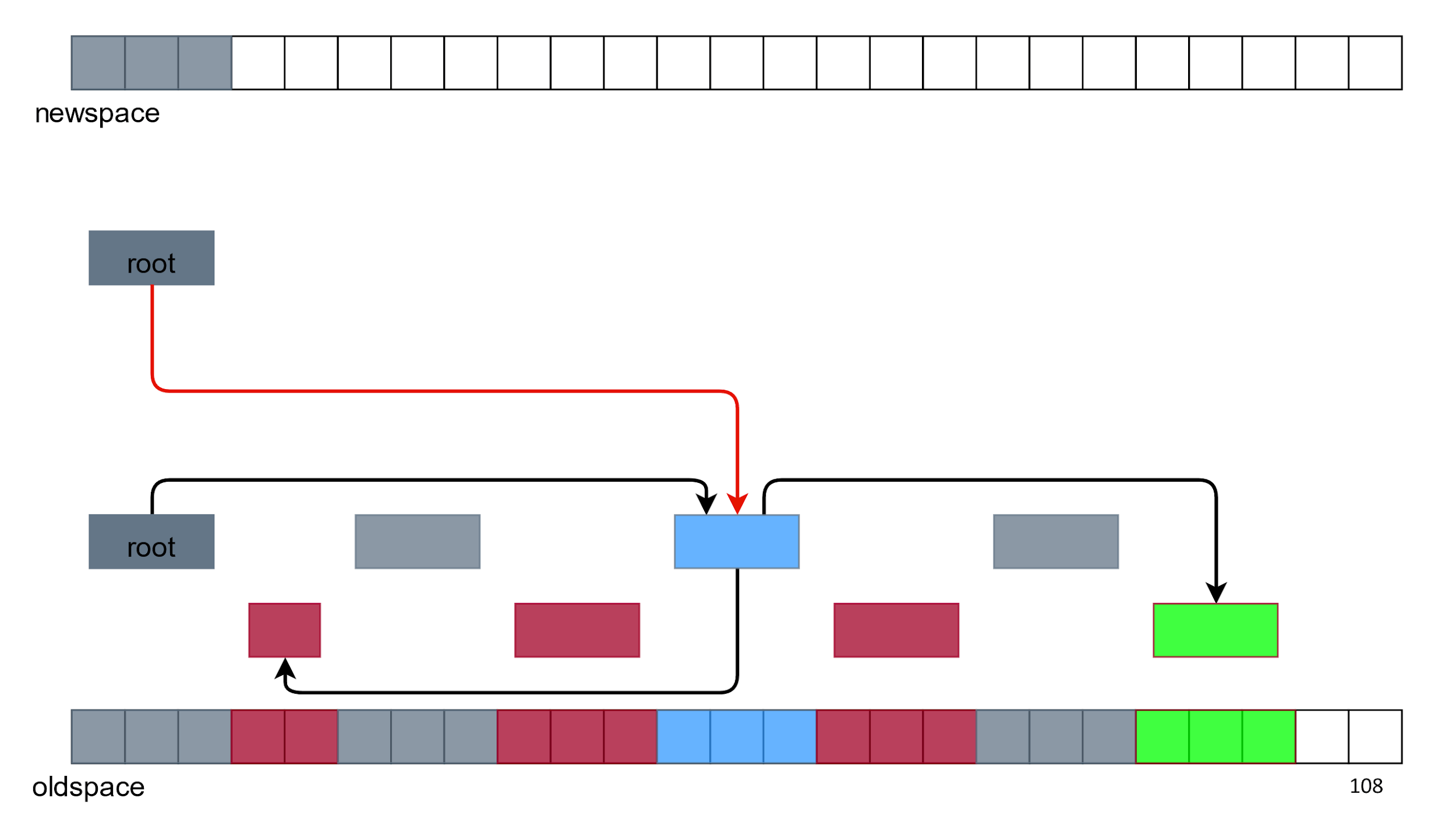
After cleaning, the problem is not solved, as there are holes in the memory. Please note that there are 7 free squares, but we still cannot select 5 of them. Fragmentation has occurred and the build is over. Such an algorithm with holes is called Mark and Sweep .
Mark and sweep
Pros:
Minuses:
We are looking for other ideas. If you look at the picture and think, then the first thought is to move everything to the left. Then to the right will remain one large and free piece, in which our object will easily fit.
Such an algorithm exists and it is called Mark and Compact .
Mark and Compact
Pros:
Minuses:
Here we come to another idea.
Garbage collection is not free
In High performance APIs like WebGL, WebAudio, and WebGPU, which is still in development, objects are created and deleted in separate phases. These specifications are written so that garbage collection is not in process. Moreover, there is not even a Promise there, but there is a pull () - you simply poll each frame: “Did something happen or not?”.
Semispace aka Lisp 2
There is another collector, about which I want to talk. What if you do not free the memory, and copy all the living objects somewhere in another place.
Let's try to copy the root object "as is", which is somewhere referenced.
And then all the rest.
There are no debris and holes in the memory above. Everything seems to be fine, but two problems arise:
With links, everything is solved with the help of a special algorithmic "magic", and with duplication of objects we cope with the removal of everything from below.
As a result, we still have free space, and on top only live objects in the normal manner. This algorithm is called Semispace , Lisp 2, or simply the “copy collector.”
Pros:
Minuses:
In the web, this is irrelevant, and in Node.js even very. If you are writing an extension in C ++, then the language does not know about all this, so there are double links that are called handle and look something like this: v8 :: Local <v8 :: String>.
Therefore, if you are going to write plugins for Node.js, then the information will be useful to you.
Summarize the different algorithms with their pros and cons in the table. It also has the Eden algorithm, but more about it later.

I really want an algorithm without cons, but there is no such thing. Therefore, we take the best of all worlds: we use several algorithms at the same time. In one piece of memory we collect garbage with one algorithm, and in the other with another algorithm.
How to understand the effectiveness of the algorithm in this situation?
We can use the knowledge of smart husbands from the 60s, who looked at all the programs and understood:
These they wanted to say that all programs do nothing but produce fruit. In an attempt to use knowledge, we will come to what is called "assembly by generations."
Assembly by generations
Create two pieces of memory that are unrelated: on the left of Eden, and on the right of the slow Mark and Sweep. In Eden we create objects. Lots of objects.
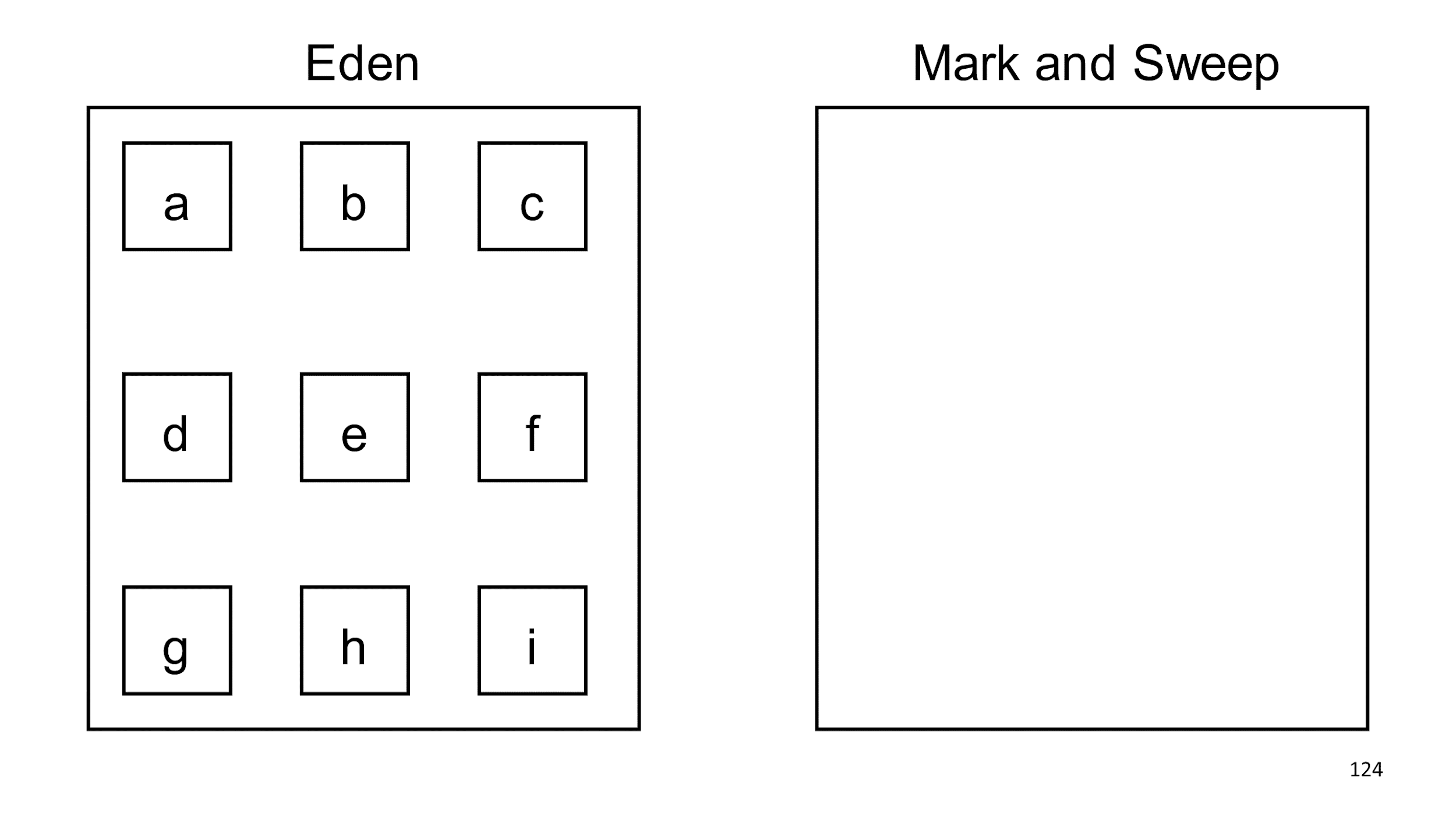
When Eden says it's filled, we run garbage collection in it. Find live objects and copy them to another collector.
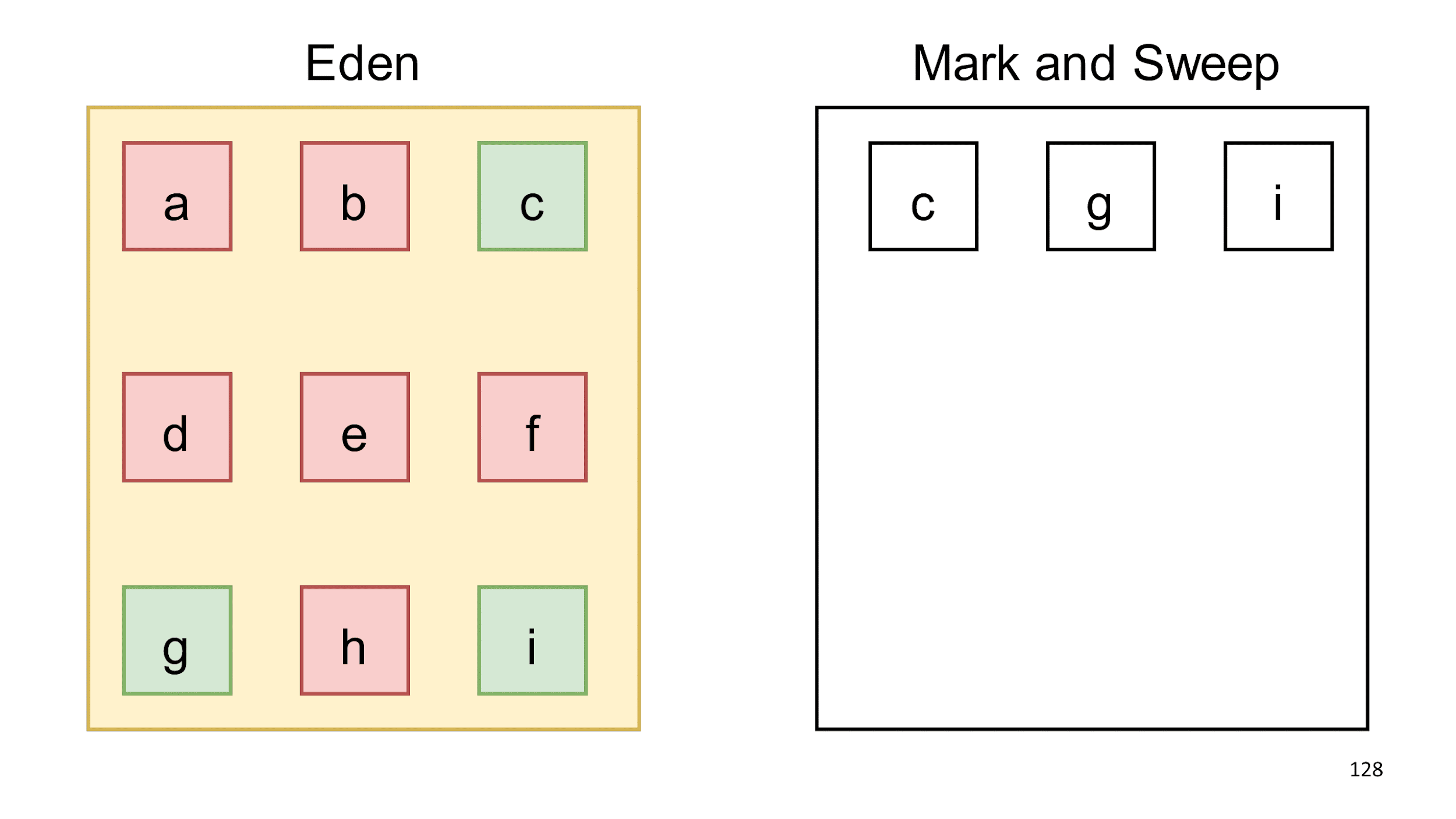
Eden itself is completely clear, and we can further add objects to it.
Relying on the hypothesis of generations, we decided that objects c, g, i most likely will live for a long time, and we can check them for rubbish less often. Knowing this hypothesis, you can write programs that cheat collector. You can do this, but I do not advise you, because this will almost always lead to undesirable effects. If you create a long-lived garbage, the collector will begin to assume that it is not required to collect.
A classic example of cheating is LRU-cache. The object is in the cache for a long time, the collector looks at it and believes that it will not collect it yet, because the object will live for a very long time. Then a new object gets into the cache, and the big old one is pushed out of it and it’s impossible to assemble this large object right away.
How to collect now we know. Talk about when to collect.
When to collect?
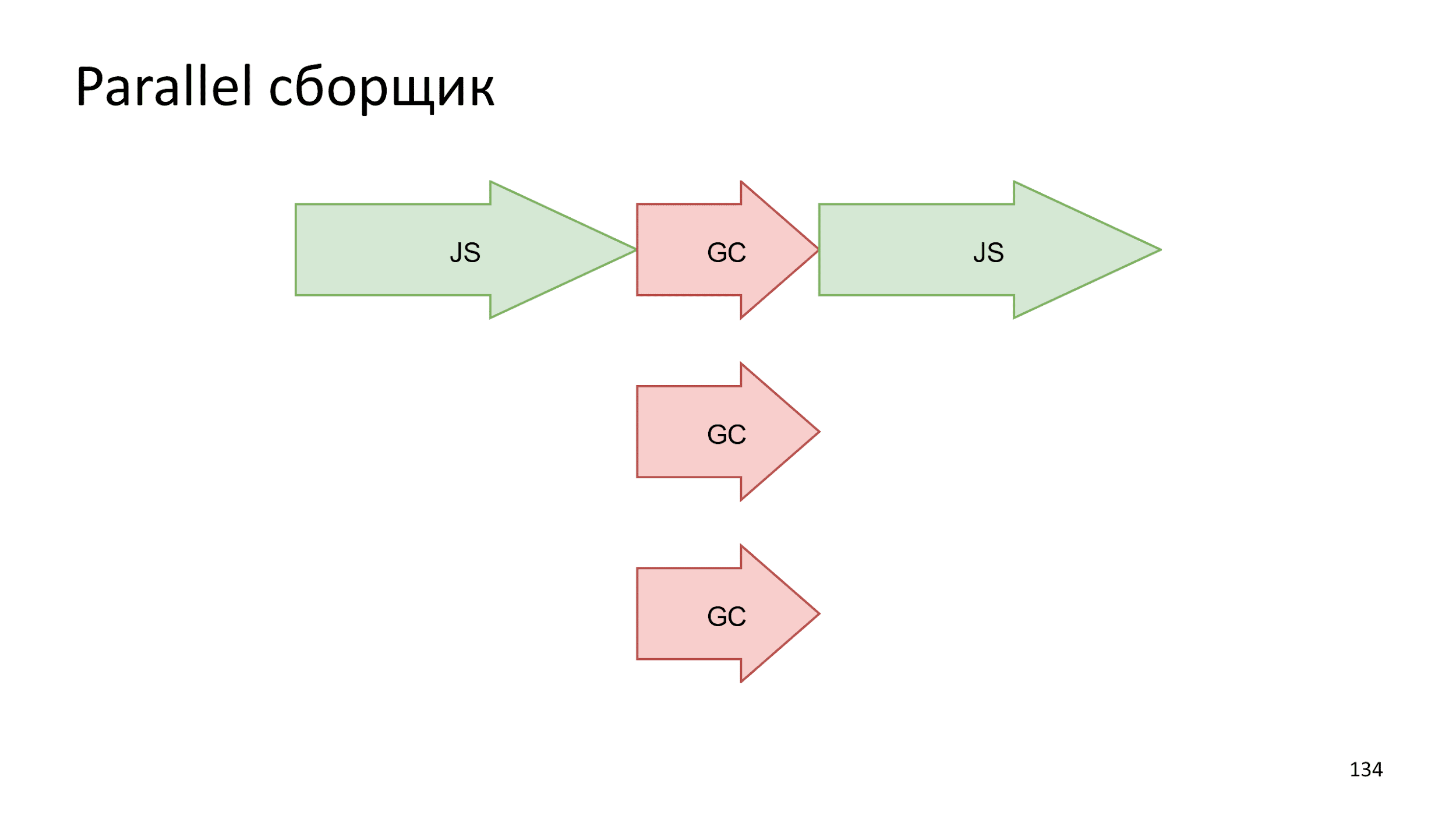
The easiest option is when we just stop everything , start the build, and then run the JS work again.
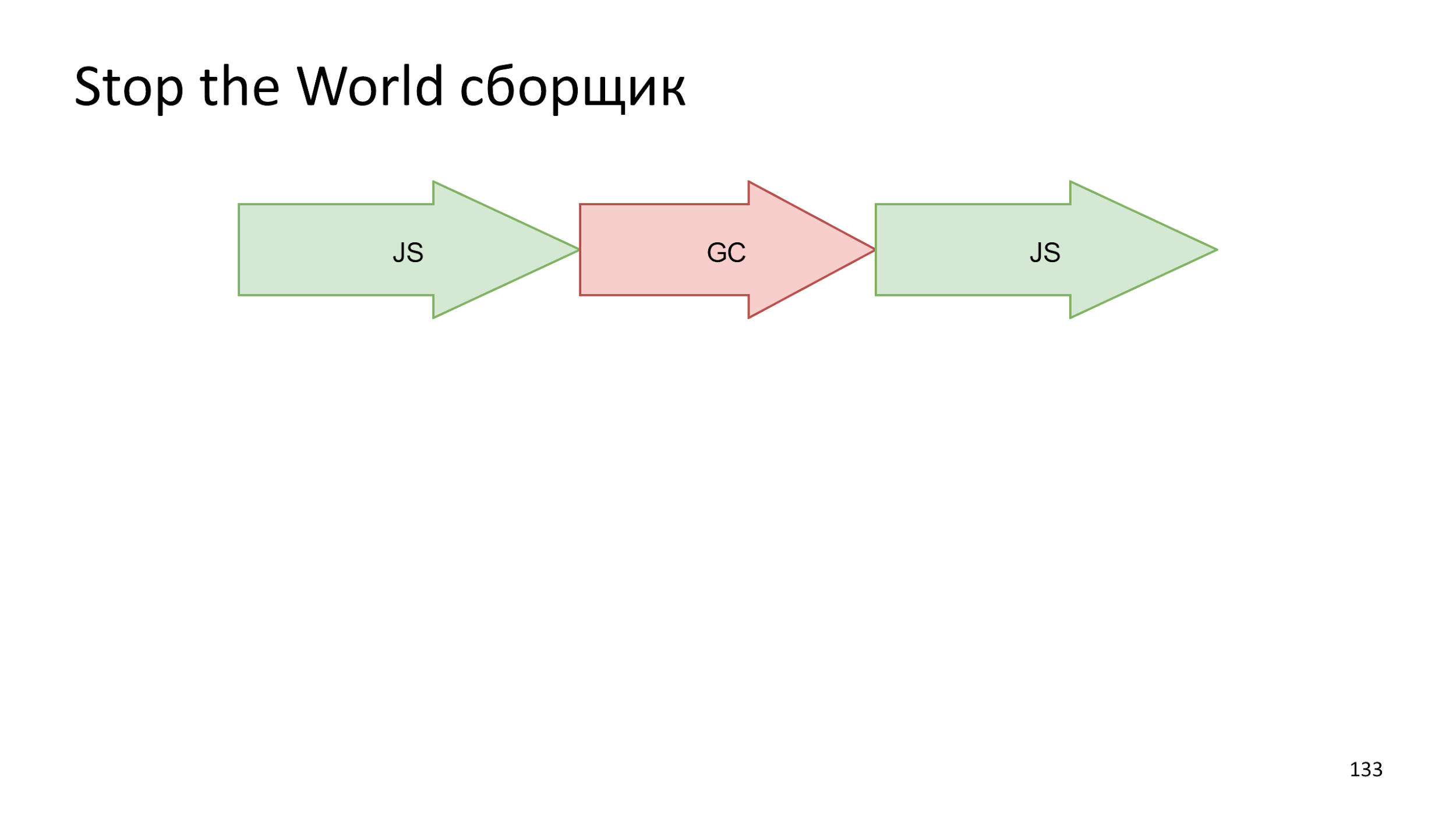
In modern computers, there is not a single thread of execution. On the web, this is familiar to Web Workers. Why not take and not parallelize the build process . Making several small operations at the same time will be faster than one big one.
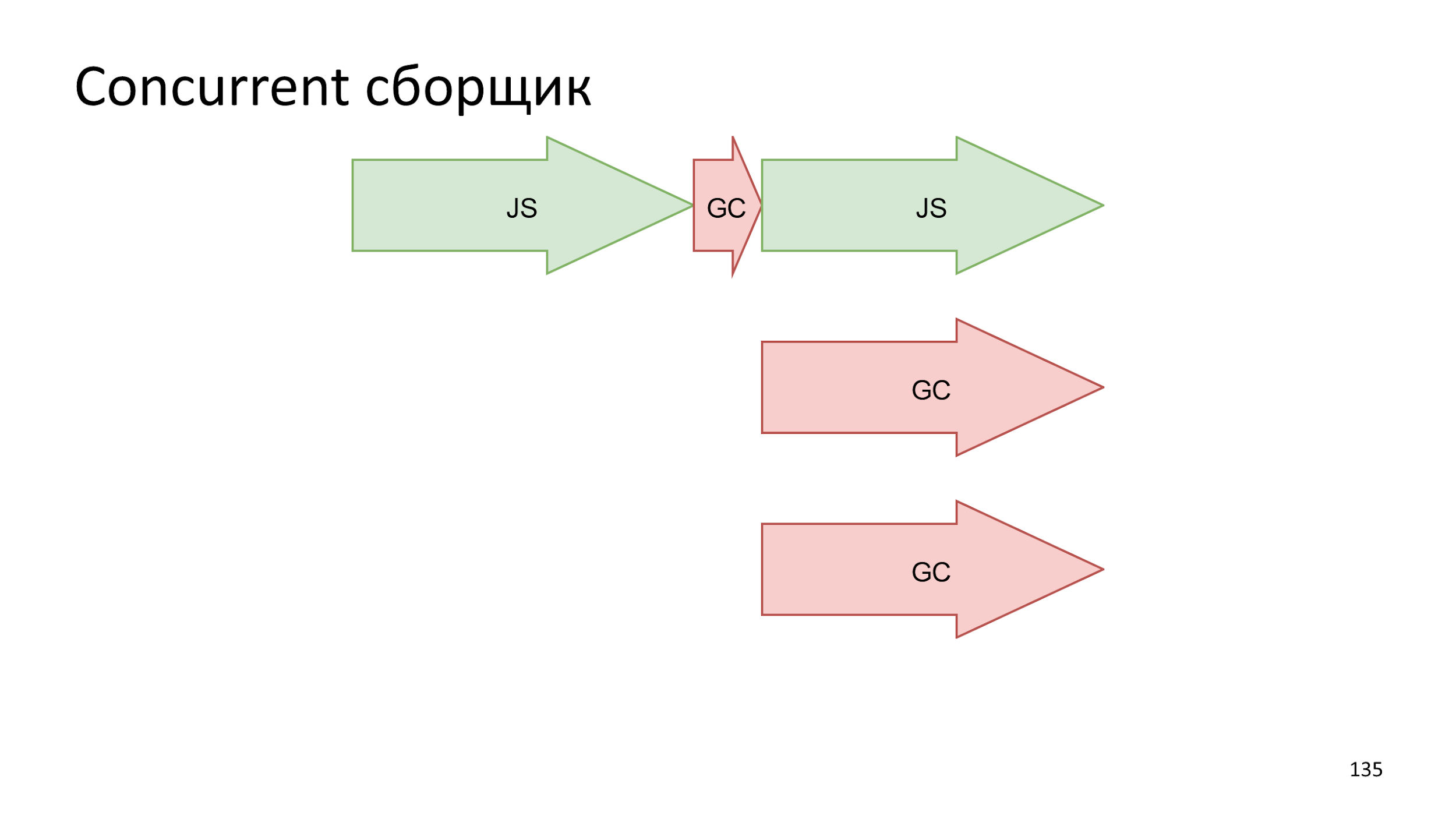
Another idea is to accurately make a cast of the current state, and build the assembly in parallel with JS execution .
Browser reality
Let's get to how browsers use everything we talked about.
IoT engines
Let's start not entirely with browsers, but with the Internet of Things engines: JerryScript and Duktape. They use Mark'n'sweep and Stop the world algorithms.
IoT engines run on microcontrollers, which means: the language is slow; second hang; fragmentation; and all this for a teapot with backlight :)
If you write Internet of Things in JavaScript, tell us in the comments? Is there any reason?
IoT-engines leave alone, we are interested in:

All engines are about the same, so we'll talk about the V8, as the most famous.
V8
In V8, assembly is used for generations.
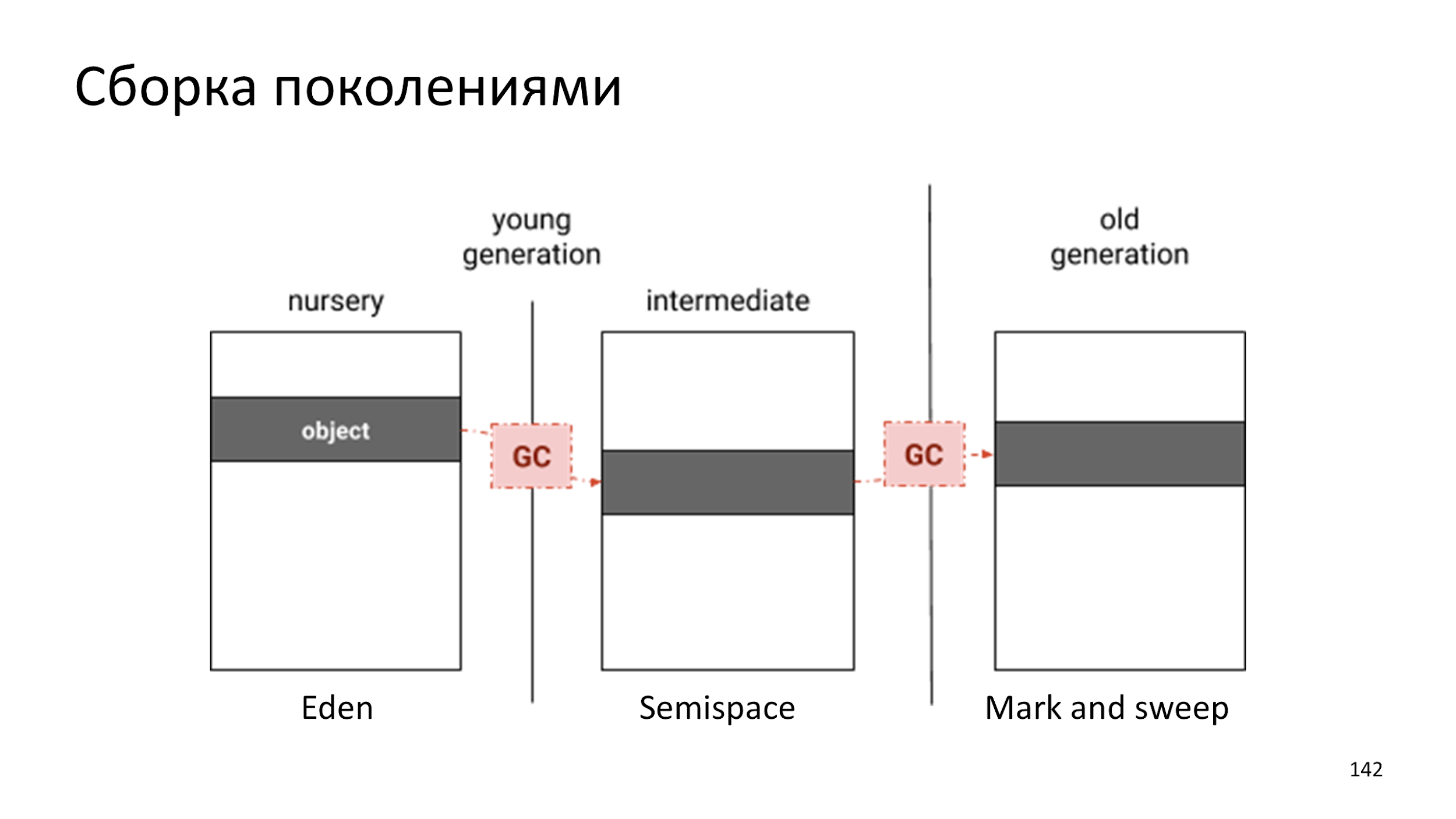
The only difference is that before we had two collectors, and now three:
Visually see how it looks like at memory trace .
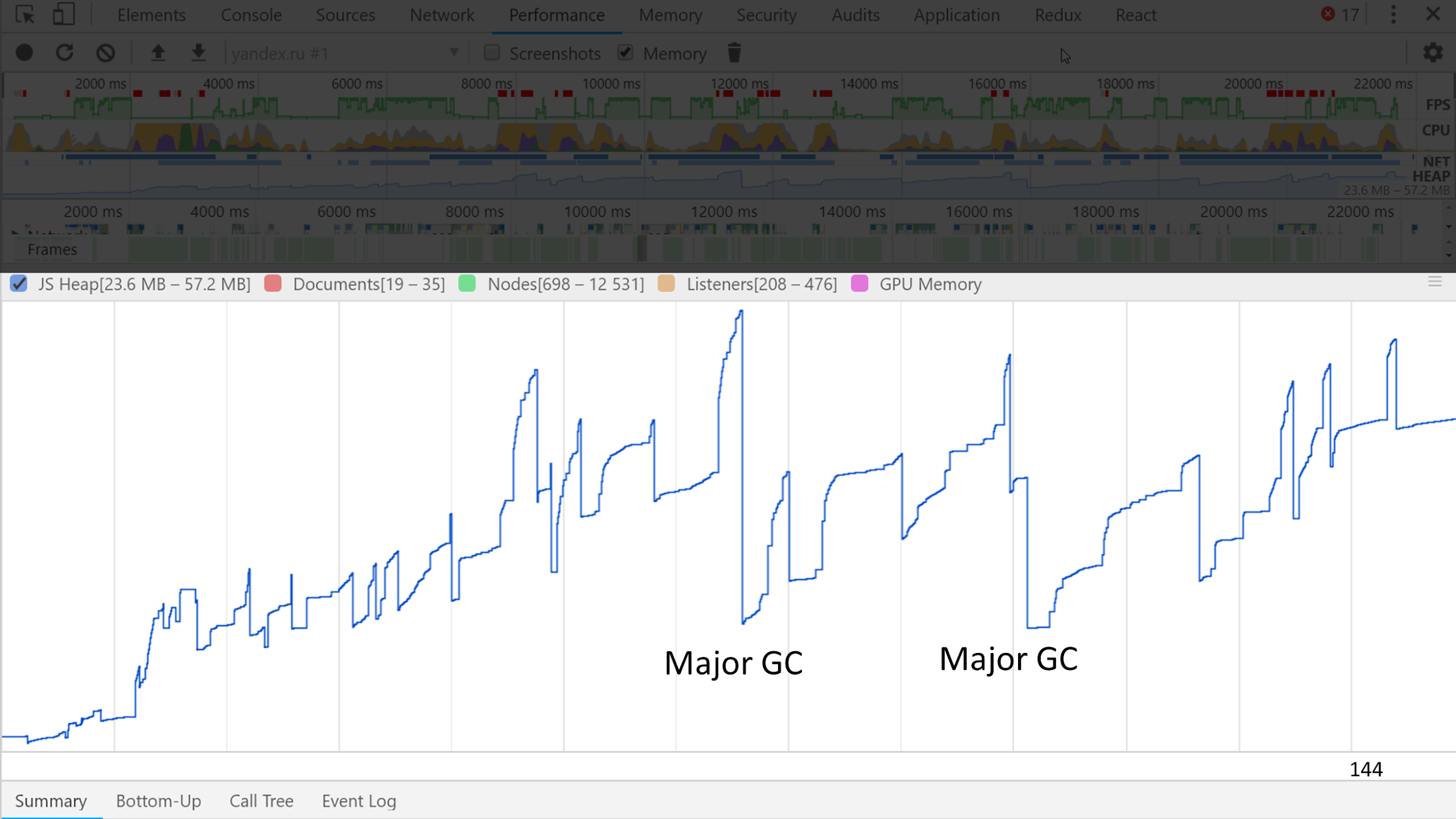
Several large waves with small waves are noticeable. Small ones are minor assemblies, and large ones are major ones.
The meaning of our existence, according to the hypothesis of generations, is to generate garbage, so the next mistake is the fear of creating garbage.
Parallel mark
Relatively recently, V8 developers have parallelized the search phase of living objects.
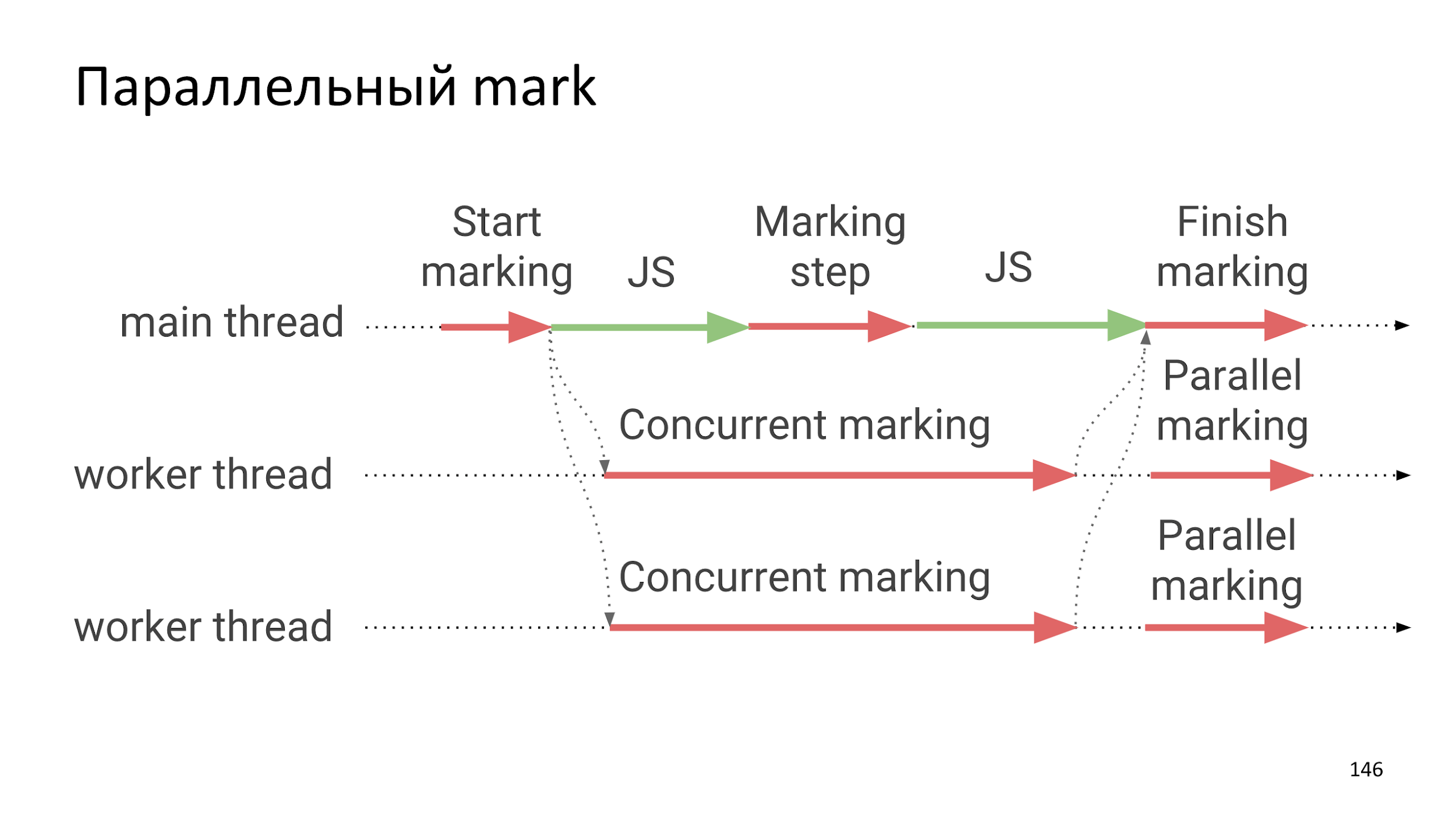
The assembly phase is still Stop the world, but most of the assembly is the search for living objects, which happens completely independently of JS execution, that is, it adds very, very small freezes.
How much is all this fun?
From 1 to 3%, which is not very much.
But 3% = 1/33 and that's a lot for GameDev. In GameDev 3% is 1 frame, which is already a noticeable lag. Therefore, GameDev tries not to use the garbage collector.
Instead of using a collector, 10,000 bullets are created in advance, for example, and these bullets are picked out and released by hand.
Another example is the particle system in games. If you have a fire or stars from a magic wand, then you can create thousands and tens of thousands of objects. This is a very large load on the collector, which will inevitably lead to a hang.
Waste Collector Statistics: Chromium
From the collector you can pull out some statistics, but, unfortunately, only in Chromium.
In Chromium, there is performance.memory and you can find out how much is currently reserved for the page, how much memory is used and how much Chromium is ready to allocate.
Spoiler: Chromium is ready to allocate 2 GB of memory for JavaScript.
Unfortunately, there is still no documentation and you can only read the source and blogpost.
Garbage Collector Statistics: Node
In Node.js, everything is standardized in process.memoryUsage , which returns roughly the same thing.
I hope that someday this information will be standardized and it will get into other browsers, but so far there is no hope. But there are thoughts to give developers greater control over garbage collection. This refers to weak links.
Future
Weak links are almost like normal ones, only they can be collected in case of a lack of memory. There is a proposal for this matter , but so far it is in the second stage.
If you have Node.js, then you can use node-weak and weak links, for example, for caching.
You can save a large object, for example, if you have video processing on JS. You can store caches in weak links and tell the builder that if there is not enough memory, then these objects can be deleted, and then checked for deletion.
In the future, we will have a collector in WebAssembly , but so far everything is foggy. In my opinion, a large number of problems are not solved in the current solution, and even when the developers finish it, the fog of uncertainty will be even denser, because no one knows how to use it.
How can all this be used in everyday life?
Daily routine
In everyday life there are DevTools and two great tabs: Performance and Memory . We will look at the tabs on the example of Chromium, because everyone uses it, and for Firefox and Safari everything is the same.
Performance tab
If you remove the Trace by clicking the "Memory" checkbox right below the Performance tab, a nice memory consumption graph will be recorded along with the JS impression.
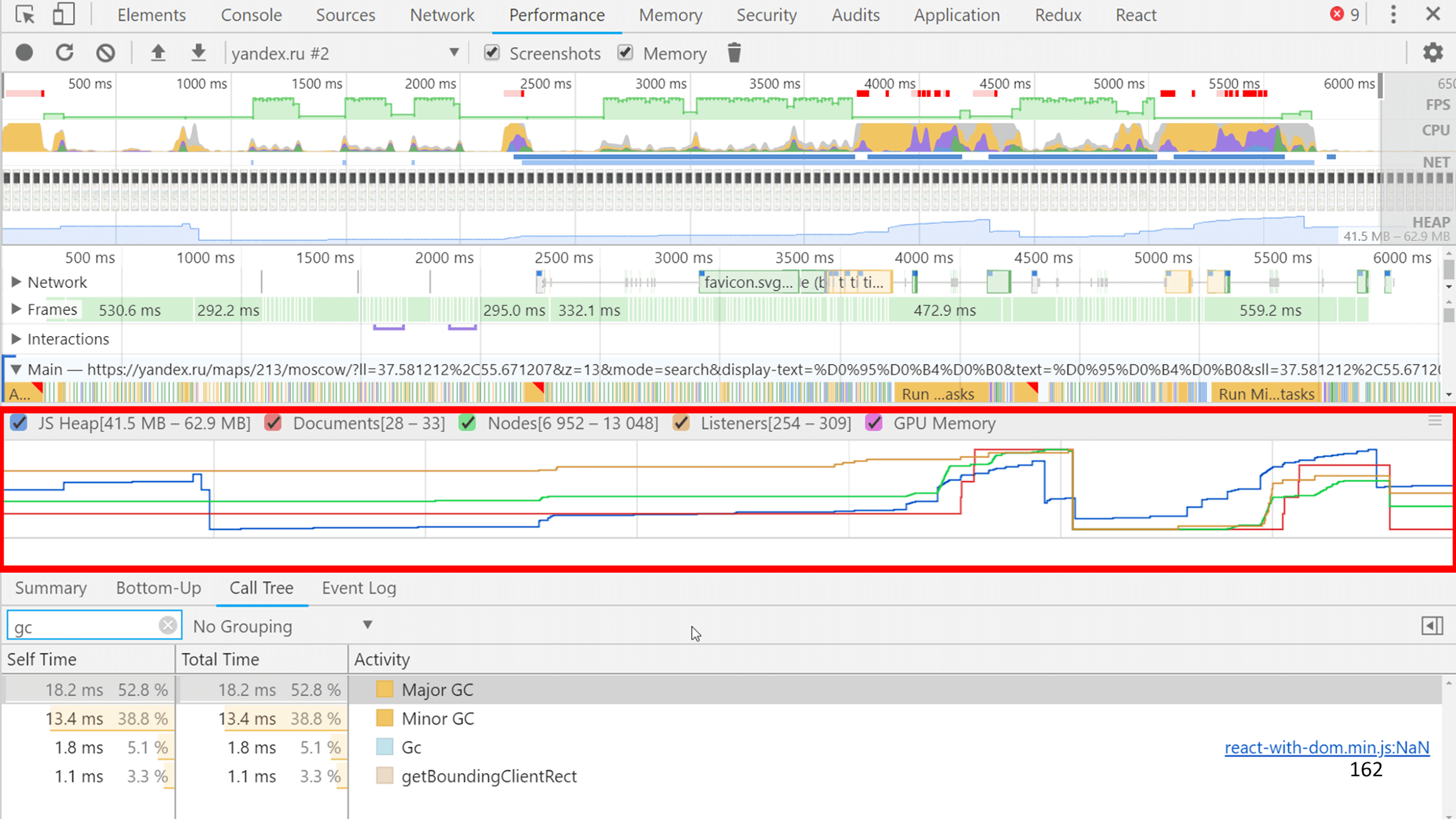
And along with JS, all internal events in V8 and all the information about how much the collector worked is recorded. You can see on the slide on the example of Yandex.Map that the GC worked for 30 ms out of 1200 ms of JS, that is, 1/40.
Memory Tab
On the tab, you can take a snapshot of the entire memory with all objects.
It looks like this.
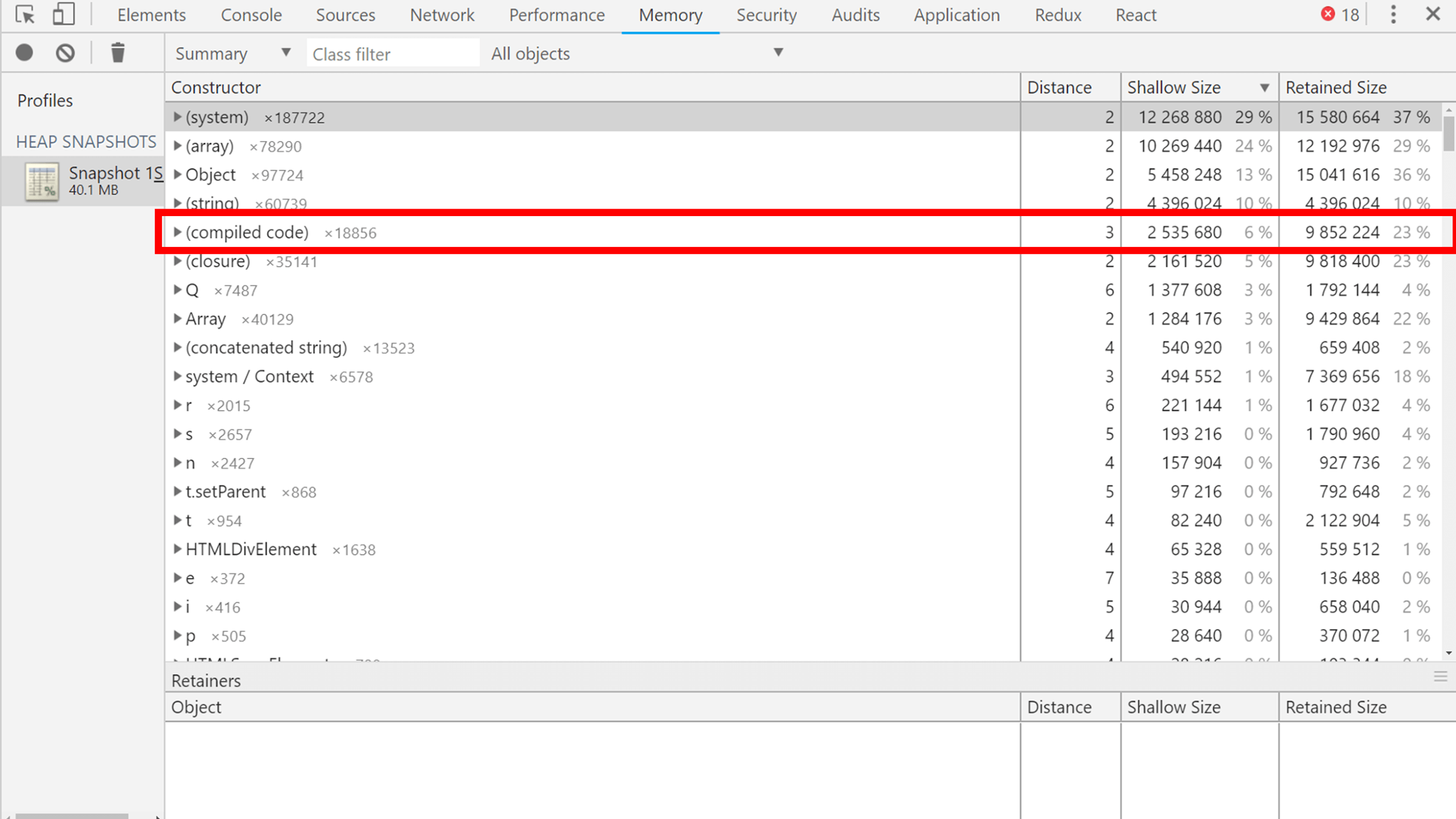
Objects can be sorted by size, by size of objects plus how much they pull other objects behind them. From interesting things you can see, for example, compiled code that V8 builds into machine code in order to run very, very quickly. He also lives in the collector, and the collector collects it.
For example, the Q object (two lines below the compiled code) is React in the minified Maps code. It takes a lot of space, but what to do?
If you want to see how much space your objects take, then give them the names for easy search in the cast or at minification keep what they are minified into.
You can also remove the cast of allocation, that is, the creation of objects.
This is about the same as the current state, only a lot of them, they are constantly being created and you have a process schedule. The graph shows that there are peaks - about 4 MB is created for one tick. You can see what is there.
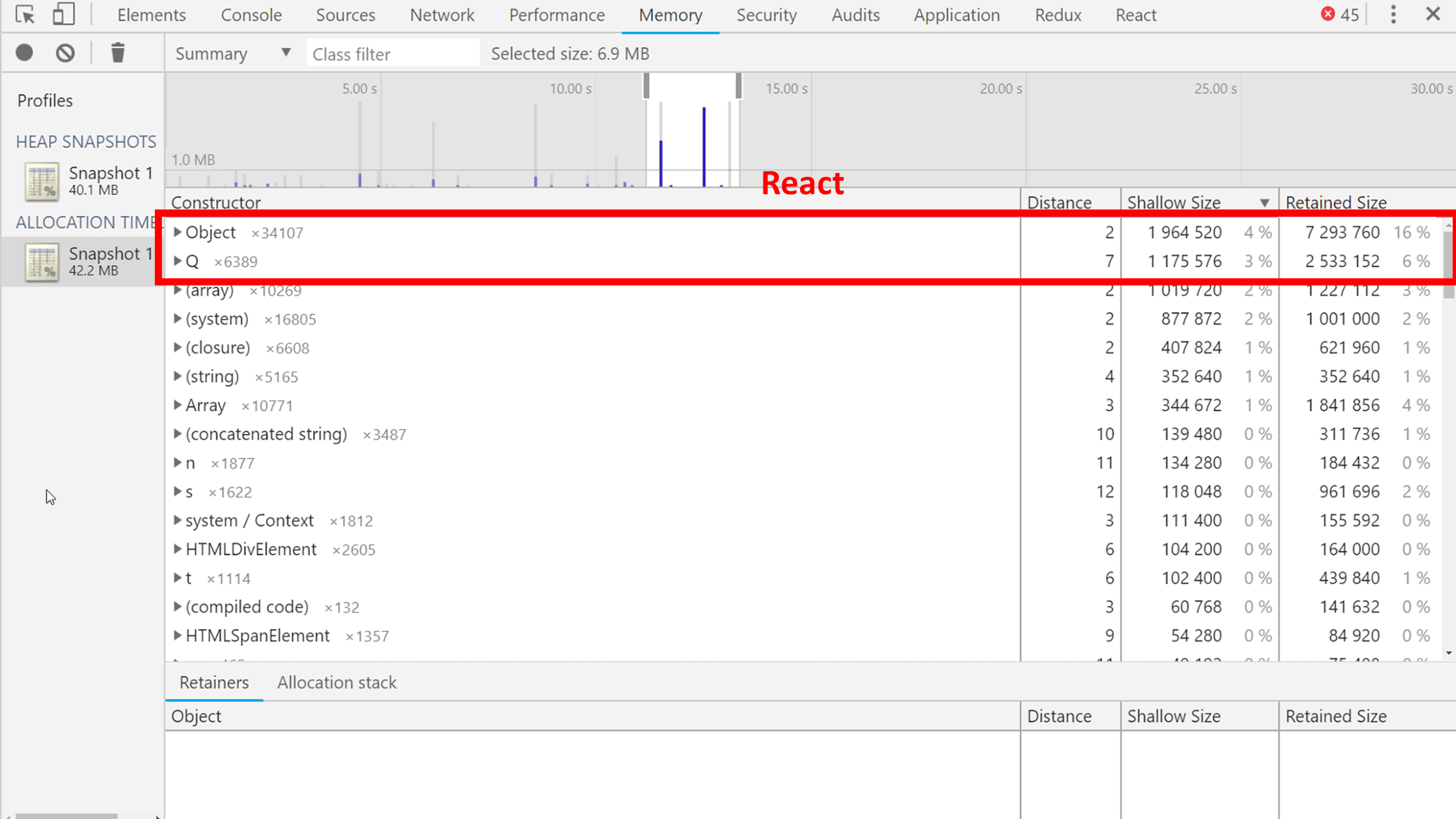
Different utilitarian objects and again React, because at that moment the map was redrawing something: a response came from the server and almost the entire interface was updated. Accordingly, a bunch of JSX was created.
If Performance and Memory are suddenly not enough, you can use:
Results
Contact speaker Andrei Roenko: flapenguin.me , Twitter , GitHub .
In theory, it sounds good. In practice, the user opens 20 tabs from YouTube, social networks, reads something, works, the browser eats memory, like Hummer H2 - gasoline. A garbage collector, like this monster with a mop, runs through memory and adds confusion, everything slows down and falls.
To prevent such situations from happening and the performance of our sites and applications did not suffer, the front-end developer should know how garbage affects applications, how the browser collects and optimizes memory management, and how this all differs from harsh reality. Just about this report by Andrei Roenko ( flapenguin ) at Frontend Conf 2018 .
We use the garbage collector (not at home - in front-end development) every day, but we don’t really think about what it is, what it costs us and what its capabilities and limitations are.
If garbage collection really worked in JavaScript, most npm modules would delete themselves immediately after installation.
But so far it is not so, and we will talk about what is - about the assembly of unnecessary objects.
About the speaker : Andrei Roenko is developing the Yandex.Maps API , has been in the front end for six years, likes to create his own high abstractions and descend to the ground from strangers.
Why do we need garbage collection?
Consider the example of Yandex.Maps. Yandex.Maps is a huge and complex service that uses a lot of JS and almost all existing browser APIs, except multimedia, and the average session time is 5-10 minutes. The abundance of javascript creates many objects. Dragging a map, adding organizations, search results and many other events that occur every second creates an avalanche of objects. Add to this the React and objects becomes even more.
However, JS objects occupy only 30–40 MB on the map. For long sessions, Yandex.Maps and the constant allocation of new objects is not enough.
The reason for the small amount of objects is that they are successfully collected by the garbage collector and the memory is reused.
Today we will talk about garbage collection from four sides:
- Theory . Let's start with her, to speak the same language and understand each other.
- Harsh reality. Ultimately, the computer is executed machine code, which does not have all the usual abstractions to us. Let's try to figure out how garbage collection works at a low level.
- Browser reality. Let's see how garbage collection is implemented in modern engines and browsers, and what conclusions we can draw from this.
- Daily - let's talk about the practical application of the knowledge gained in everyday life.
All statements are supported by examples of how you can and how not to do.
Why all this to know?
Garbage collection is an imperceptible thing for us, but knowing how it works you will:
- Have an idea about the tool that you use, which is useful in work.
- Understand where to optimize already released applications and how to design future ones so that they work better and faster.
- Know how not to make common mistakes and stop wasting resources on useless and harmful "optimization".
Theory
Joel Spolsky once said:
All nontrivial abstractions are holes.
A garbage collector is one big non-trivial abstraction that is patched from all sides. To our happiness, it flows very rarely.
Let's start with the theory, but without boring definitions. Let us analyze the work of the collector by the example of simple code:
window.Foo = classFoo{
constructor() {
this.x = { y: 'y’ };
}
work(name) {
let z = 'z';
return function () {
console.log(name, this.x.y, z);
this.x = null;
}.bind(this);
}
};
- There is a class in the code .
- The class has a constructor .
- The work method returns the associated function.
- Inside this function, this and a couple of variables from the closure are used.
Let's see how this code will behave if we run it this way:
var foo = new Foo(); //Cоздаем объекта классаwindow.worker = foo.work('Brendan Eich'); // Возьмем функцию полученную от bind, вызвав методwindow.foo = null; // Обнулим всеwindow.Foo = null; // Вызовем метод, который тоже что-то обнулитwindow.worker();
window.worker = null; // Обнулим вообще все, что осталосьLet us analyze the code and its components in more detail and begin with the class.
Class declaration
We can assume that classes in ECMAScript 2015 are just syntactic sugar for functions. All functions have:
- Function. [[Prototype]] is the real function prototype.
- Foo.prototype is a prototype for newly created objects.
- Foo.prototype has a backlink to the constructor via the constructor field. This is an object, so it inherits the Object.prototype .
- The work method is a separate function to which there is a reference, similar to the constructor, because they are both just functions. He can also set a prototype and call it via new, but rarely does anyone use this behavior.
Prototypes occupy a lot of space on the scheme, so let's remember that they are, but then we remove for simplicity.
Creating a class object
- We put our class in the window, because the classes do not get there by default.
- Create a class object.
- Creating an object automatically exposes a prototype to a class object in Foo.prototype. Therefore, when you try to call the work method on the object, it will know what kind of work it is.
- Our constructor creates an x field in the object from an object with a string.
Here's what happened:
The method returns a bound function — this is such a special “magic” object in JS, which consists of the bound this and the function that needs to be called. The associated function also has a prototype and another prototype, but we are interested in the closure. By specification, the closure is stored in Environment. Most likely you are used to the word Scope, but in the specifications the field is called Environment .
The Environment stores a link to LexicalEnvironment. This is a complex object, more complicated than the slide, it contains links to everything that can be accessed from a function. For example, window, foo, name, and z. There are also links even to what you clearly do not use. For example, you can apply eval and accidentally use unused objects, but JS should not break.
So, we have built all the objects and now we will destroy everything.
Remove the link to the object
Let's start by removing the object link, this link in the diagram is highlighted in red.
We delete and nothing happens, because from the window to the object there is a path through the bound function function.
This pushes us to a typical error.
A typical mistake is a forgotten subscription.
externalElement.addEventListener('click', () => {
if (this.shouldDoSomethingOnClick) {
this.doSomething();
}
})
Occurs when you subscribe: using this, explicitly via bind or through switch functions; use something in closure. Then you forget to unsubscribe, and the lifetime of your object or of what is in the closure becomes the same as the lifetime of the subscription. For example, if this is a DOM element that you do not touch with your hands, then, most likely, this is the time until the end of the page’s life.
To solve this problem:
- Unsubscribe.
- Consider the subscription lifetime and who owns it.
- If for some reason you can not unsubscribe, then nullify the links (whatever = null), or clear all the fields of the object. If an object leaks from you, it will be small and do not mind it.
- Use WeakMap, maybe it will help in some situations.
Remove class reference
Go ahead and try to remove the class reference highlighted in red.
We delete the link and nothing changes here. The reason is that the class is available through BoundThis, which has a link to the prototype, and in the prototype there is a link back to the constructor.
Typical mistake useless work
Why do we need all these demonstrations? Because there is a downside of the problem when people take advice to nullify links too literally and nullify everything.
destroy() {
this._x = null;
this._y = null;
// еще 10 this._foobar = null
}
This is a pretty useless job. If an object consists only of references to other objects and there are no resources there, then no destroy () is needed. It is enough to lose the link to the object, and it will die by itself.
There is no universal council. When it is necessary - null, and when it is not necessary - do not null. Zanulenie not a mistake, but simply useless work.
Go ahead. Call the method bound function and it will remove the link from [object Foo] to [object Object]. This will lead to the fact that in the scheme there will appear objects that are alone in the blue rectangle.
These objects are js trash. He is perfectly going. However, there is garbage that does not lend itself to the collector.
Garbage that is not going to
In many browser APIs you can create and destroy an object. If the object is not destroyed, then no collector can assemble it.
Objects with pair functions create / delete:
- createObjectURL (), revokeObjectURL ();
- WebGL: create / delete Program / Shader / Buffer / Texture / etc;
- ImageBitmap.close ();
- indexDb.close ().
For example, if you forget to remove ObjectURL from a 200 MB video, then these 200 MB will be in memory until the end of the page’s life and even longer, because there is data exchange between the tabs. Similarly in WebGL, indexDb and other browser-based APIs with similar resources.
Fortunately, in our example in the blue rectangle just JavaScript objects, so this is just garbage that can be removed.
The next step is to clean the last link from left to right. This is a link to the method we received, to the associated function.
After its removal, we will not have links between the left and the right side? In fact, there are still references from the closure.
It is important that there are no links from left to right, therefore everything except window is garbage, and it will die.
Important note: there are circular references in the garbage, that is, objects that link to each other. The presence of such links does not affect anything, because the garbage collector does not collect individual objects, but all the garbage.
We looked at examples and now, at an intuitive level, we understand what rubbish is, but let's give a complete definition of the concept.
Garbage is everything that is not a living object.
Everything became very clear. But what is a living object?
A living object is an object that can be reached by links from the root object.
Two new concepts appear: “follow the links” and “root object”. One root object we already know is window, so let's start with links.
What does it mean to follow the links?
There are many objects that are related to each other and link to each other. We will start a wave along them, starting with the root object.
We initialize the first step, and then we act according to the following algorithm: let's say that all that is on the crest of the wave are living objects and see what they refer to.
Initialize the first step. Then we will act according to the following algorithm: let's say that all the yellow on the crest of the wave are living objects and see what they refer to.
We will make what they refer to as a new crest of the wave:
Finished and start anew:
- We liven up.
- We look at what they refer to.
- Create a new wave crest, animate objects.
- We look at what they refer to.
Noticing that one arrow points to an already living object, we simply do nothing. Further according to the algorithm, until the objects for traversing are finished. Then we say that we have found all the living objects, and all the rest is rubbish.
This process is called marking .
What does the root object mean?
- Window.
- Almost all browser APIs.
- All promise.
- All that is put in Microtask and Macrotask.
- Mutation observers, RAF, Idle-callbacks. Everything that can be reached from what is in the RAF cannot be deleted, because if you delete an object that is used in the RAF, then surely something will go wrong.
Build may occur at any time. Every time braces or function appear, a new object is created. The memory may not be enough, and the collector will go looking for a free one:
functionfoo (a, b, c) {
functionbar (x, y, z) {
const x = {}; // nomem, run gc D:// …
}
while (whatever()) bar();
}
In this case, the root objects will be all that is on the call stack. If you, for example, stop at line X and delete what Y refers to, then your application will crash. JS does not allow us such frivolities, so you cannot delete an object from Y.
If the previous part seemed difficult, then it will be even more difficult.
Harsh reality
Let's talk about the world of machines, in which we deal with iron, with physical carriers.
Memory is one big array in which just numbers lie, for example: new Uint32Array (16 * 2 ** 30).
Let's create objects in memory and add them from left to right. Create one, second, third - they are all different sizes. Along the way we put down the links.
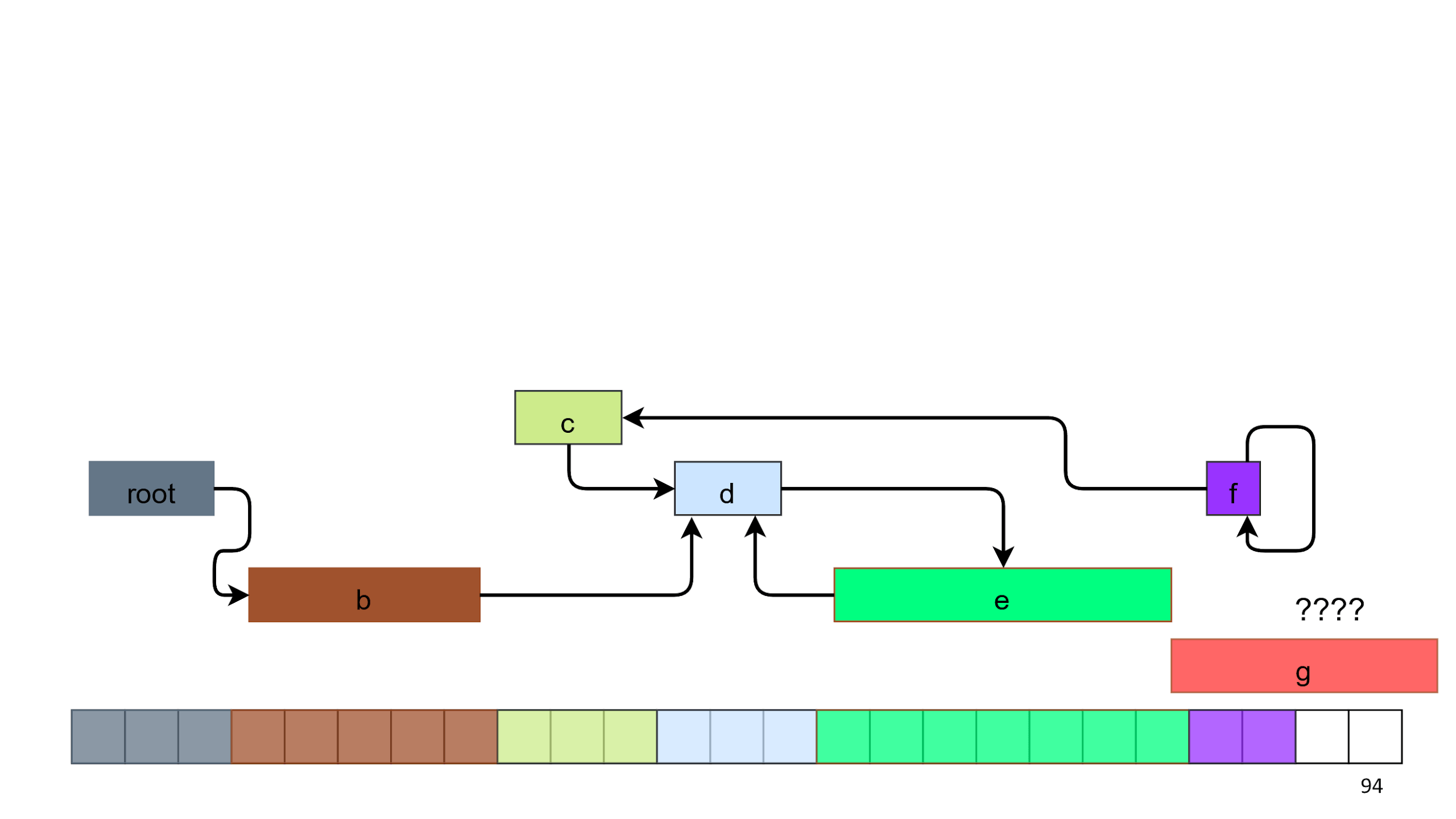
On the seventh object the place is over, because we have 2 empty squares, but we need 5.
What can we do here? The first option is to crash. It's 2018 in the yard, everyone has the latest MacBooks and 16 GB of RAM. There are no situations when there is no memory!
However, letting things go bad is a bad idea, because on the web this leads to a screen like this:
This is not the behavior that we want from the program, but in general it is valid. There is a category of collectors called No-op .
No-op collector
Pros:
- The collector is very simple.
- Garbage collection is simply not there.
- Do not write anything and think about memory.
Minuses:
- Everything falls so that it never rises again.
For the frontend, the no-op collector is irrelevant, but used on the backend. For example, having several servers behind balancers, the application is given 32 GB of RAM and then it is killed entirely. It's easier and productivity is only enhanced by simply restarting when memory becomes low.
In the web, it is impossible and you have to clean it.
Find and remove trash
Let's start cleaning with trash search. We already know how to do this. Garbage - objects C and F in the previous scheme, because they can not be reached along the arrows from the root object.
We take this garbage, feed it to the garbage lover and is ready.
After cleaning, the problem is not solved, as there are holes in the memory. Please note that there are 7 free squares, but we still cannot select 5 of them. Fragmentation has occurred and the build is over. Such an algorithm with holes is called Mark and Sweep .
Mark and sweep
Pros:
- Very simple algorithm. One of the first that you’ll learn about if you start exploring the Garbage collector.
- It works in proportion to the amount of garbage, but copes only when there is little garbage.
- If you have only living objects, then he does not waste time and simply does nothing.
Minuses:
- It requires a complex logic of searching for free space, because when there are a lot of holes in the memory, then you have to try on each object to understand whether it is suitable or not.
- Fragments the memory. It may happen that with free 200 MB, the memory is broken into small pieces and, as in the example above, there is no single piece of memory for the object.
We are looking for other ideas. If you look at the picture and think, then the first thought is to move everything to the left. Then to the right will remain one large and free piece, in which our object will easily fit.
Such an algorithm exists and it is called Mark and Compact .
Mark and Compact
Pros:
- Defragmenting memory.
- It works in proportion to the number of living objects, which means it can be used when there is practically no garbage.
Minuses:
- Difficult in work and implementation.
- Moves objects. We moved the object, copied it, now it is in a different place and the whole operation is rather expensive.
- It requires 2-3 passes through the entire memory, depending on the implementation - the algorithm is slow.
Here we come to another idea.
Garbage collection is not free
In High performance APIs like WebGL, WebAudio, and WebGPU, which is still in development, objects are created and deleted in separate phases. These specifications are written so that garbage collection is not in process. Moreover, there is not even a Promise there, but there is a pull () - you simply poll each frame: “Did something happen or not?”.
Semispace aka Lisp 2
There is another collector, about which I want to talk. What if you do not free the memory, and copy all the living objects somewhere in another place.
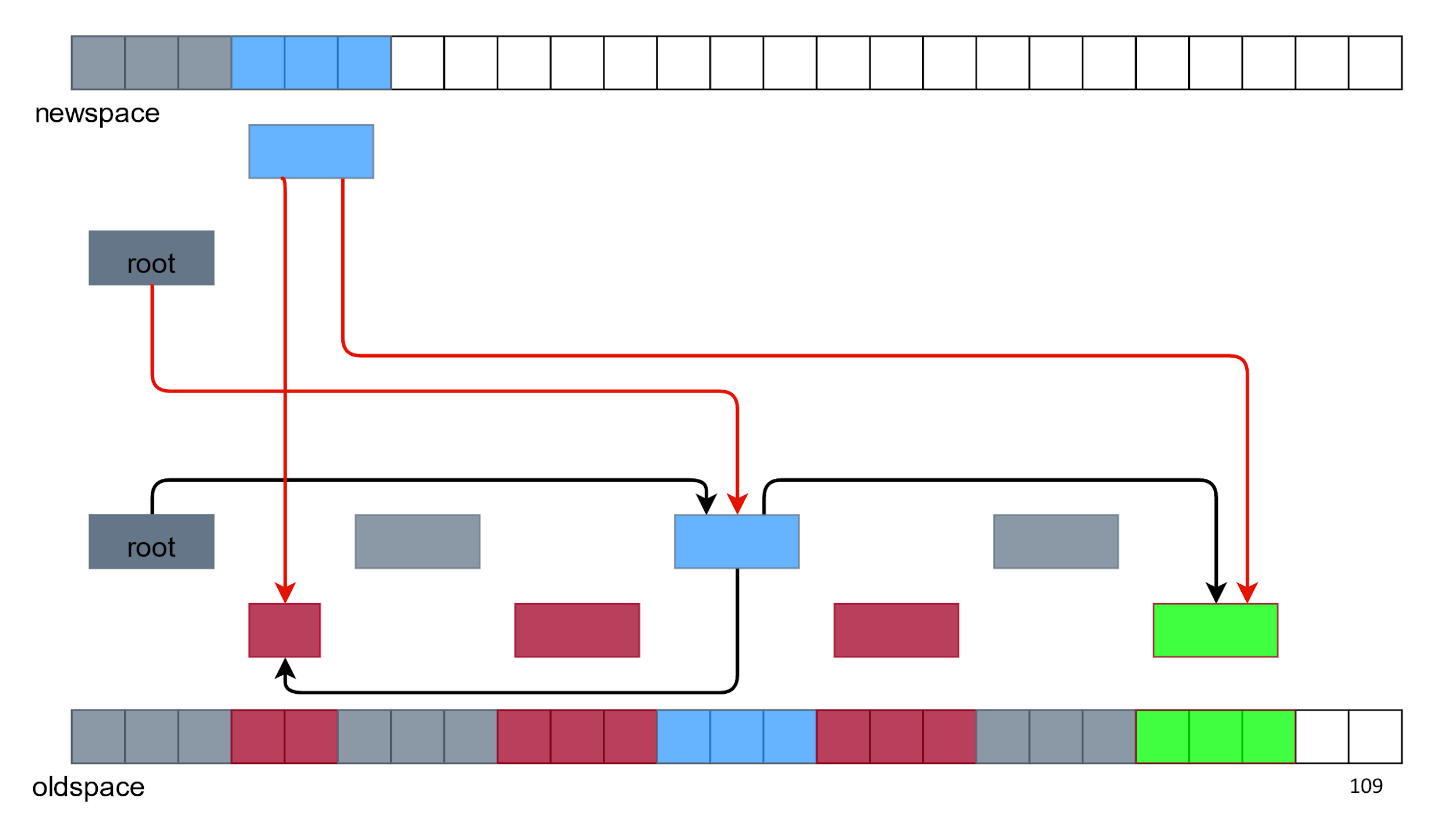
Let's try to copy the root object "as is", which is somewhere referenced.
And then all the rest.
There are no debris and holes in the memory above. Everything seems to be fine, but two problems arise:
- Duplication of objects - we have two green objects and two blue ones. Which one to use?
- Links from new objects lead to old objects, and not to each other.
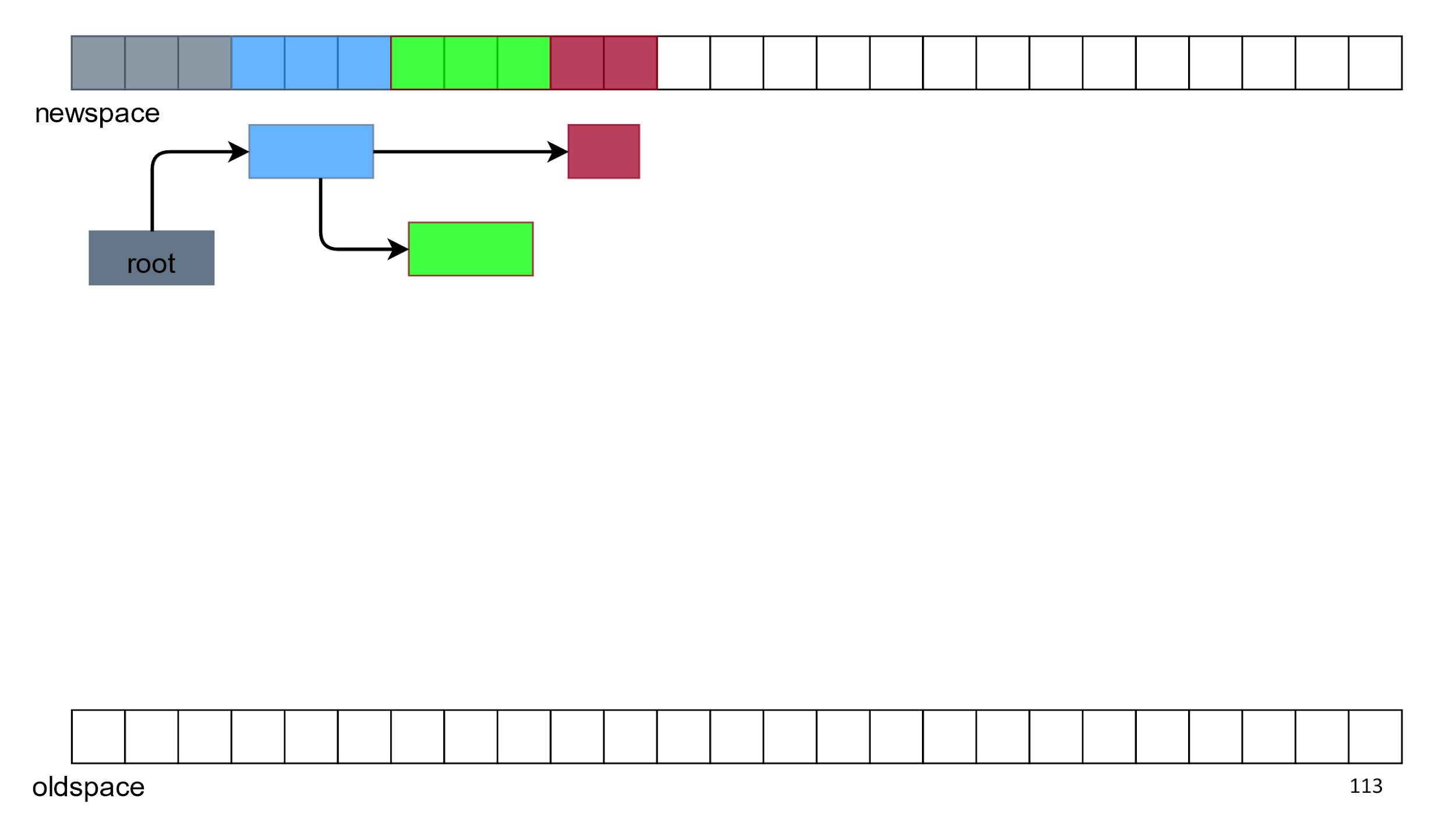
With links, everything is solved with the help of a special algorithmic "magic", and with duplication of objects we cope with the removal of everything from below.
As a result, we still have free space, and on top only live objects in the normal manner. This algorithm is called Semispace , Lisp 2, or simply the “copy collector.”
Pros:
- Defragmenting memory.
- Plain.
- Can be combined with the bypass phase.
- Works in proportion to the number of living objects in time.
- Works well when a lot of trash. If you have 2 GB of memory and there are 3 objects in it, then you will bypass only 3 objects, and the remaining 2 GB didn’t seem to be there.
Minuses:
- Double memory consumption. You use 2 times more memory than necessary.
- Moves objects - this is also not a very cheap operation.
Note: garbage collectors can move objects.
In the web, this is irrelevant, and in Node.js even very. If you are writing an extension in C ++, then the language does not know about all this, so there are double links that are called handle and look something like this: v8 :: Local <v8 :: String>.
Therefore, if you are going to write plugins for Node.js, then the information will be useful to you.
Summarize the different algorithms with their pros and cons in the table. It also has the Eden algorithm, but more about it later.
I really want an algorithm without cons, but there is no such thing. Therefore, we take the best of all worlds: we use several algorithms at the same time. In one piece of memory we collect garbage with one algorithm, and in the other with another algorithm.
How to understand the effectiveness of the algorithm in this situation?
We can use the knowledge of smart husbands from the 60s, who looked at all the programs and understood:
Weak hypothesis about generations: most objects die young.
These they wanted to say that all programs do nothing but produce fruit. In an attempt to use knowledge, we will come to what is called "assembly by generations."
Assembly by generations
Create two pieces of memory that are unrelated: on the left of Eden, and on the right of the slow Mark and Sweep. In Eden we create objects. Lots of objects.
When Eden says it's filled, we run garbage collection in it. Find live objects and copy them to another collector.
Eden itself is completely clear, and we can further add objects to it.
Relying on the hypothesis of generations, we decided that objects c, g, i most likely will live for a long time, and we can check them for rubbish less often. Knowing this hypothesis, you can write programs that cheat collector. You can do this, but I do not advise you, because this will almost always lead to undesirable effects. If you create a long-lived garbage, the collector will begin to assume that it is not required to collect.
A classic example of cheating is LRU-cache. The object is in the cache for a long time, the collector looks at it and believes that it will not collect it yet, because the object will live for a very long time. Then a new object gets into the cache, and the big old one is pushed out of it and it’s impossible to assemble this large object right away.
How to collect now we know. Talk about when to collect.
When to collect?
The easiest option is when we just stop everything , start the build, and then run the JS work again.
In modern computers, there is not a single thread of execution. On the web, this is familiar to Web Workers. Why not take and not parallelize the build process . Making several small operations at the same time will be faster than one big one.
Another idea is to accurately make a cast of the current state, and build the assembly in parallel with JS execution .
If you are interested, I advise you to read:
- The only and the main book on the assembly "Garbage Collection Handbook".
- Wikipedia as a universal resource.
- Site memorymanagement.org.
- Reports and articles by Alexander Shepelev . He talks about Java, but in terms of garbage, Java and V8 work in approximately the same way.
Browser reality
Let's get to how browsers use everything we talked about.
IoT engines
Let's start not entirely with browsers, but with the Internet of Things engines: JerryScript and Duktape. They use Mark'n'sweep and Stop the world algorithms.
IoT engines run on microcontrollers, which means: the language is slow; second hang; fragmentation; and all this for a teapot with backlight :)
If you write Internet of Things in JavaScript, tell us in the comments? Is there any reason?
IoT-engines leave alone, we are interested in:
- V8.
- SpiderMonkey. He really has no logo. Logo homemade :)
- JavaScriptCore, which is used in WebKit.
- ChakraCore, which is used in the Edge.
All engines are about the same, so we'll talk about the V8, as the most famous.
V8
- Almost all server-side JavaScript, because this is Node.js.
- Almost 80% of client javascript.
- The most sociable developers, a lot of information and good sources that are easiest to read.
In V8, assembly is used for generations.
The only difference is that before we had two collectors, and now three:
- An object is created in Eden.
- At some point, there is too much garbage in Eden and the object is transferred to Semispace.
- The object grows up and when the collector realizes that he is too old and boring, he throws it at Mark and Sweep, in which garbage collection is extremely rare.
Visually see how it looks like at memory trace .
Several large waves with small waves are noticeable. Small ones are minor assemblies, and large ones are major ones.
The meaning of our existence, according to the hypothesis of generations, is to generate garbage, so the next mistake is the fear of creating garbage.
Garbage can be created when it is really garbage. If you reuse the object, it will live much longer and the collector will decide that it should not be collected, so do not do so.
Parallel mark
Relatively recently, V8 developers have parallelized the search phase of living objects.
The assembly phase is still Stop the world, but most of the assembly is the search for living objects, which happens completely independently of JS execution, that is, it adds very, very small freezes.
How much is all this fun?
From 1 to 3%, which is not very much.
But 3% = 1/33 and that's a lot for GameDev. In GameDev 3% is 1 frame, which is already a noticeable lag. Therefore, GameDev tries not to use the garbage collector.
const pool = [new Bullet(), new Bullet(), /* ... */];
functiongetFromPool() {
const bullet = pool.find(x => !x.inUse);
bullet.isUse = true;
return bullet;
}
functionreturnToPool(bullet) { bullet.inUse = false; }
// Frameconst bullet = getFromPool();
// ...
returnToPool(bullet);
Instead of using a collector, 10,000 bullets are created in advance, for example, and these bullets are picked out and released by hand.
Another example is the particle system in games. If you have a fire or stars from a magic wand, then you can create thousands and tens of thousands of objects. This is a very large load on the collector, which will inevitably lead to a hang.
Waste Collector Statistics: Chromium
From the collector you can pull out some statistics, but, unfortunately, only in Chromium.
> performance.memory
MemoryInfo {
totalJSHeapSize: 10000000,
usedJSHeapSize: 10000000,
jsHeapSizeLimit: 2330000000
}
In Chromium, there is performance.memory and you can find out how much is currently reserved for the page, how much memory is used and how much Chromium is ready to allocate.
Spoiler: Chromium is ready to allocate 2 GB of memory for JavaScript.
Unfortunately, there is still no documentation and you can only read the source and blogpost.
Garbage Collector Statistics: Node
In Node.js, everything is standardized in process.memoryUsage , which returns roughly the same thing.
> process.memoryUsage()
{ rss: 22839296,
heapTotal: 10207232,
heapUsed: 5967968,
external: 12829 }
I hope that someday this information will be standardized and it will get into other browsers, but so far there is no hope. But there are thoughts to give developers greater control over garbage collection. This refers to weak links.
Future
Weak links are almost like normal ones, only they can be collected in case of a lack of memory. There is a proposal for this matter , but so far it is in the second stage.
If you have Node.js, then you can use node-weak and weak links, for example, for caching.
let cached = new WeakRef(myJson);
// 2 часа спустяlet json = cached.deref();
if (!json) {
json = await fetchAgain();
}
You can save a large object, for example, if you have video processing on JS. You can store caches in weak links and tell the builder that if there is not enough memory, then these objects can be deleted, and then checked for deletion.
In the future, we will have a collector in WebAssembly , but so far everything is foggy. In my opinion, a large number of problems are not solved in the current solution, and even when the developers finish it, the fog of uncertainty will be even denser, because no one knows how to use it.
There is nothing special to read about browsers: there is v8.dev and source codes for JS engines.
- github.com/v8/v8/tree/7.0.237/src/heap
- github.com/servo/mozjs/blob/master/mozjs/js/src/gc/
- github.com/WebKit/webkit/.../JavaScriptCore/heap/MarkedSpace.cpp
- github.com/Microsoft/ChakraCore/.../HeapAllocator.cpp
- github.com/svaarala/duktape/.../duk_heap_markandsweep.c
- github.com/jerryscript-project/jerryscript/.../ecma-gc.c
How can all this be used in everyday life?
Daily routine
In everyday life there are DevTools and two great tabs: Performance and Memory . We will look at the tabs on the example of Chromium, because everyone uses it, and for Firefox and Safari everything is the same.
Performance tab
If you remove the Trace by clicking the "Memory" checkbox right below the Performance tab, a nice memory consumption graph will be recorded along with the JS impression.
And along with JS, all internal events in V8 and all the information about how much the collector worked is recorded. You can see on the slide on the example of Yandex.Map that the GC worked for 30 ms out of 1200 ms of JS, that is, 1/40.
Memory Tab
On the tab, you can take a snapshot of the entire memory with all objects.
It looks like this.
Objects can be sorted by size, by size of objects plus how much they pull other objects behind them. From interesting things you can see, for example, compiled code that V8 builds into machine code in order to run very, very quickly. He also lives in the collector, and the collector collects it.
For example, the Q object (two lines below the compiled code) is React in the minified Maps code. It takes a lot of space, but what to do?
If you want to see how much space your objects take, then give them the names for easy search in the cast or at minification keep what they are minified into.
You can also remove the cast of allocation, that is, the creation of objects.
This is about the same as the current state, only a lot of them, they are constantly being created and you have a process schedule. The graph shows that there are peaks - about 4 MB is created for one tick. You can see what is there.
Different utilitarian objects and again React, because at that moment the map was redrawing something: a response came from the server and almost the entire interface was updated. Accordingly, a bunch of JSX was created.
If Performance and Memory are suddenly not enough, you can use:
- In Chromium: about: tracing.
- In Firefox: about: memory and about: performance, but they are difficult to read.
- Node flags are trace-gc, –expose-gc, require ('trace_events'). Through trace_events, you can programmatically collect statistics.
Results
- The garbage collector is smart, it was made by knowledgeable developers to collect the garbage that you produce.
- No one bothers you to deceive the assembler or to complicate his work and shoot himself in this way.
- Do not be afraid to create garbage. The collector collects garbage, so why take away his work?
- Keep track of performance, because you can accidentally do something wrong and get the consequences in an unexpected place.
- If you do not have a SPA, then you can do nothing, because winning 1 frame of a hang may not be worth the work that will be spent.
- Most of the errors, dubious places and useless work is due to a misunderstanding of the tool.
Contact speaker Andrei Roenko: flapenguin.me , Twitter , GitHub .
Our next conference for front-end developers will be held in May at the RIT ++ festival . In his expectation, subscribe to the newsletter and the YouTube channel of the
conference.
New materials, the best transcripts of speeches for 2018, announcements and news of a future conference are included in the newsletter. And on the channel there is a playlist with the best video recordings of reports of Frontend Conf 2018.
Subscribe and stay with us, it will be interesting :)