GIS and distributed computing
Hello! I will again talk about geographic information technologies. With this article, I am starting a series about technology at the junction of the worlds of classic GIS and the still trendy BigData trend. I’ll talk about the key features of applying distributed computing to working with geodata, and also give a brief overview of existing tools.
Today we are surrounded by a huge amount of unstructured data, which until recently was unthinkable to process. An example of such data is, for example, weather sensor data used for accurate weather forecasting. More structured, but no less massive datasets are, for example, satellite images (a number of articles from the OpenDataScience community are even devoted to image processing algorithms using machine learning). A set of high-resolution images, for example, across Russia takes several petabytes of data. Or the OpenStreetMap revision history is a terabyte of xml. Or laser scan data. Finally, data from a huge number of sensors, which are equipped with a lot of equipment - from drones to tractors (yes, I'm talking about IoT). Moreover, in the digital age, we ourselves create data, many of which contain location information. Mobile communications, applications on smartphones, credit cards - all this creates our digital portrait in space. Many of these portraits create truly monstrous sets of unstructured data.
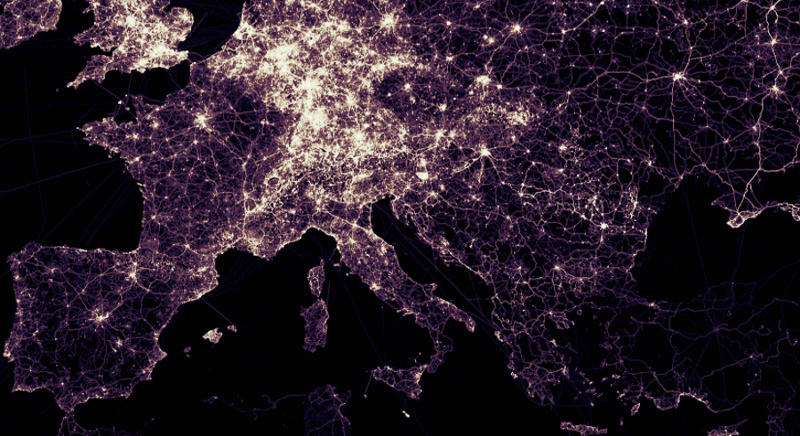
In the picture - visualization of OpenStreetMap tracks using GeoWave.
Where is the joint of GIS and distributed computing? What is big geodata? What tools will help us?
Here to the point to mention a little hackneyed, but still not meaningless, term BigData, Big Data. The decoding of this term often depends on the personal opinion of the decryptor, on what tools and in which area he uses. Often, BigData is used as an all-encompassing term to describe technologies and algorithms for processing large amounts of unstructured data. Often the main idea is the speed of data processing through the use of distributed computing algorithms.
In addition to the processing speed and amount of data, there is another aspect of the "complexity" of data. How to divide complex data into parts, "partitions" for parallel processing? Geodata was originally complex data, and with the transition to "big geodata" this complexity increases almost exponentially. Accordingly, it becomes important not just to process billions of records, but billions of geographic objects, which are not just points, but lines and polygons. In addition, the calculation of spatial relationships is often required.
Spatial indexing comes to our aid, and often the classical indexing methods are poorly applicable here. There are many approaches to indexing two-dimensional and three-dimensional spaces. For example, familiar to many geodetic networks, quadrant trees, R-trees:
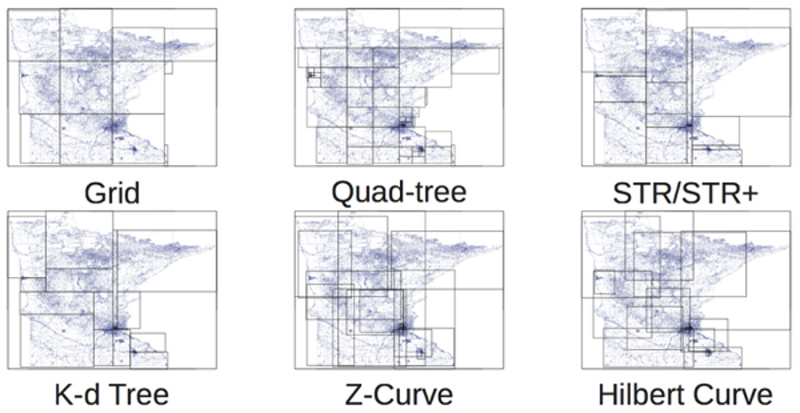
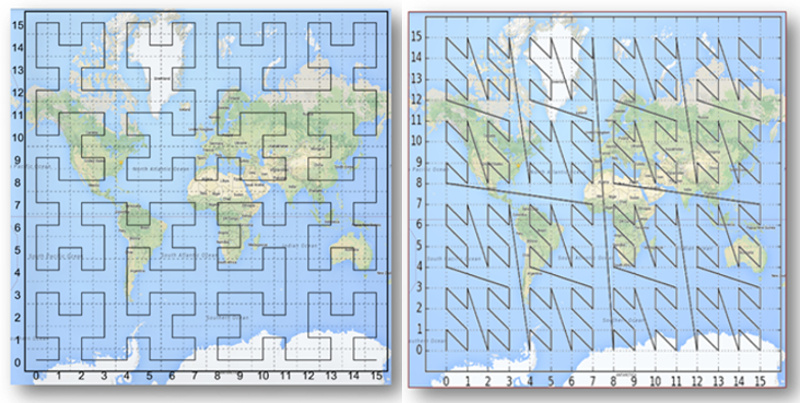
One of the most interesting methods is the variety of "space-filling curves", Z-Curve and Gilbert Curve in the figure above. The discoverer of these curves was Giuseppe Peano. The main idea is to turn multidimensional space into one-dimensional using a curve that fractally fills the whole space. Here, for example, is how a Hilbert curve fills a plane:

And this is how these curves look on the earth's surface:
By adopting these indexes, we can finally come to the partitioning of geodata. Do we need to reinvent the techniques? Fortunately not! Already existing frameworks come to the rescue. There are many of them, each of them has its own applicability and its own strengths. Below I will talk about the most noteworthy.

GeoJinni (formerly called SpatialHadoop) is an extremely interesting extension for Hadoop that adds geospatial functions to various layers and components of Hadoop for storing, processing and indexing large geodata. To be precise, the extension affects MapReduce and storage layers, and also adds its own operating layer.
At the very lowest level, a new data type is added, which allows storing and processing geodata as a key-value. It also adds tools for loading and unloading various geodata formats. In contrast to the classical structure (or rather, its absence) of the Hadoop repository, GeoJinni creates two layers of index space, local and global. The global index allows you to partition data by cluster nodes, while the local index is responsible for partitions on each node. This concept allows using three types of indexes - Grid, R-tree and R + -tree. All indexes are built at the user's request and are placed directly in HDFS.
GeoJinni is installed as an extension to an existing Hadoop cluster, which does not require reassembling the cluster. The extension can be installed without problems on various Hadoop distributions, such as Apache Hadoop, Cloudera or Hortonworks.
 GeoMesa is a set of tools created specifically for distributed processing, analysis and visualization of large spatio-temporal data, including streaming data. For example, IoT sensor data streams, social network data.
GeoMesa is a set of tools created specifically for distributed processing, analysis and visualization of large spatio-temporal data, including streaming data. For example, IoT sensor data streams, social network data.
The basis for storing massive data sets is distributed column storage types, such as Accumulo, HBase, Google Bigtable. This allows you to quickly access this data through queries using distances and areas. GeoMesa also allows you to process data in almost real time through a special layer for the Apache Kafka streaming message system.
Finally, by connecting to a GIS server, GeoServer GeoMesa provides access to its streaming services via OGC protocols WFS and WMS, which gives great scope for spatial-temporal analysis and visualization, from maps to graphs.
 GeoWave in its conception was conceived as an analogue of PostGIS, the spatial extension of PostgreSQL, but for Accumulo distributed column storage. It was limited for a long time to this repository, while remaining a closed-source project. Only recently has the code been transferred to the Apache Foundation. And HBase storage and the Mapnik map engine are already connected.
GeoWave in its conception was conceived as an analogue of PostGIS, the spatial extension of PostgreSQL, but for Accumulo distributed column storage. It was limited for a long time to this repository, while remaining a closed-source project. Only recently has the code been transferred to the Apache Foundation. And HBase storage and the Mapnik map engine are already connected.
Provides Accumulo with multi-dimensional indexes, standard geographic types and operations, and the ability to process PDAL point clouds. Data processing occurs through extensions to MapReduce, and visualization through a plugin to GeoServer.
It is very similar in its concept to GeoMesa, it uses the same repositories, but it focuses not on spatio-temporal samples, but on visualization of multidimensional data arrays.

GeoTrellis is different from its counterparts. It was conceived not as a tool for working with large geodata arrays, but as an opportunity to utilize distributed computing for the maximum processing speed of even standard geodata volumes. First of all, we are talking about processing rasters, but due to the effective partitioning system, it has become possible to perform spatial operations and data conversion. The main development tools are Scala and Akka, a distributed analytics tool - Apache Spark.
The global goal of the project is to provide responsive and rich tools at the web application level, which should change the user experience in using distributed computing systems. Ultimately, the development of an ecosystem of open geotechnologies, where GeoTrellis will complement PostGIS, GeoServer and OpenLayers. The development team sets the following goals:
GeoTrellis is a great developer framework designed to create responsive and simple REST services for accessing geoprocessing models. Optimization and parallelization is done by the framework itself.

Although Esri toolkits are formally open, their use makes sense primarily with Esri products. The concept is very similar to GeoJinni.
Tools are divided into three levels
Geodata has always been somewhere close to big data, and the advent of distributed computing tools allows you to do really interesting things, allowing not only geographers, but also data analysts (or, as they call it, Data Science) to make new discoveries in the field of data analysis. Instant modeling of flooding, creating horizon lines, spatial statistics, population analysis, creating three-dimensional models from point clouds, analysis of satellite images.
The following articles I will devote to the tools and their scope. Your comments can help us in developing topics for the following articles.
Today we are surrounded by a huge amount of unstructured data, which until recently was unthinkable to process. An example of such data is, for example, weather sensor data used for accurate weather forecasting. More structured, but no less massive datasets are, for example, satellite images (a number of articles from the OpenDataScience community are even devoted to image processing algorithms using machine learning). A set of high-resolution images, for example, across Russia takes several petabytes of data. Or the OpenStreetMap revision history is a terabyte of xml. Or laser scan data. Finally, data from a huge number of sensors, which are equipped with a lot of equipment - from drones to tractors (yes, I'm talking about IoT). Moreover, in the digital age, we ourselves create data, many of which contain location information. Mobile communications, applications on smartphones, credit cards - all this creates our digital portrait in space. Many of these portraits create truly monstrous sets of unstructured data.
In the picture - visualization of OpenStreetMap tracks using GeoWave.
Where is the joint of GIS and distributed computing? What is big geodata? What tools will help us?
Here to the point to mention a little hackneyed, but still not meaningless, term BigData, Big Data. The decoding of this term often depends on the personal opinion of the decryptor, on what tools and in which area he uses. Often, BigData is used as an all-encompassing term to describe technologies and algorithms for processing large amounts of unstructured data. Often the main idea is the speed of data processing through the use of distributed computing algorithms.
In addition to the processing speed and amount of data, there is another aspect of the "complexity" of data. How to divide complex data into parts, "partitions" for parallel processing? Geodata was originally complex data, and with the transition to "big geodata" this complexity increases almost exponentially. Accordingly, it becomes important not just to process billions of records, but billions of geographic objects, which are not just points, but lines and polygons. In addition, the calculation of spatial relationships is often required.
Spatial partitioning
Spatial indexing comes to our aid, and often the classical indexing methods are poorly applicable here. There are many approaches to indexing two-dimensional and three-dimensional spaces. For example, familiar to many geodetic networks, quadrant trees, R-trees:
One of the most interesting methods is the variety of "space-filling curves", Z-Curve and Gilbert Curve in the figure above. The discoverer of these curves was Giuseppe Peano. The main idea is to turn multidimensional space into one-dimensional using a curve that fractally fills the whole space. Here, for example, is how a Hilbert curve fills a plane:
And this is how these curves look on the earth's surface:
By adopting these indexes, we can finally come to the partitioning of geodata. Do we need to reinvent the techniques? Fortunately not! Already existing frameworks come to the rescue. There are many of them, each of them has its own applicability and its own strengths. Below I will talk about the most noteworthy.
GeoJinni (formerly SpatialHadoop)
GeoJinni (formerly called SpatialHadoop) is an extremely interesting extension for Hadoop that adds geospatial functions to various layers and components of Hadoop for storing, processing and indexing large geodata. To be precise, the extension affects MapReduce and storage layers, and also adds its own operating layer.
At the very lowest level, a new data type is added, which allows storing and processing geodata as a key-value. It also adds tools for loading and unloading various geodata formats. In contrast to the classical structure (or rather, its absence) of the Hadoop repository, GeoJinni creates two layers of index space, local and global. The global index allows you to partition data by cluster nodes, while the local index is responsible for partitions on each node. This concept allows using three types of indexes - Grid, R-tree and R + -tree. All indexes are built at the user's request and are placed directly in HDFS.
GeoJinni is installed as an extension to an existing Hadoop cluster, which does not require reassembling the cluster. The extension can be installed without problems on various Hadoop distributions, such as Apache Hadoop, Cloudera or Hortonworks.
Geomesa
The basis for storing massive data sets is distributed column storage types, such as Accumulo, HBase, Google Bigtable. This allows you to quickly access this data through queries using distances and areas. GeoMesa also allows you to process data in almost real time through a special layer for the Apache Kafka streaming message system.
Finally, by connecting to a GIS server, GeoServer GeoMesa provides access to its streaming services via OGC protocols WFS and WMS, which gives great scope for spatial-temporal analysis and visualization, from maps to graphs.
Geowave
Provides Accumulo with multi-dimensional indexes, standard geographic types and operations, and the ability to process PDAL point clouds. Data processing occurs through extensions to MapReduce, and visualization through a plugin to GeoServer.
It is very similar in its concept to GeoMesa, it uses the same repositories, but it focuses not on spatio-temporal samples, but on visualization of multidimensional data arrays.
GeoTrellis
GeoTrellis is different from its counterparts. It was conceived not as a tool for working with large geodata arrays, but as an opportunity to utilize distributed computing for the maximum processing speed of even standard geodata volumes. First of all, we are talking about processing rasters, but due to the effective partitioning system, it has become possible to perform spatial operations and data conversion. The main development tools are Scala and Akka, a distributed analytics tool - Apache Spark.
The global goal of the project is to provide responsive and rich tools at the web application level, which should change the user experience in using distributed computing systems. Ultimately, the development of an ecosystem of open geotechnologies, where GeoTrellis will complement PostGIS, GeoServer and OpenLayers. The development team sets the following goals:
- Create scalable high-performance web geoservices
- Creation of distributed geo services for processing "large geodata"
- Maximum parallelization of data processing processes
GeoTrellis is a great developer framework designed to create responsive and simple REST services for accessing geoprocessing models. Optimization and parallelization is done by the framework itself.
GIS Tools for Hadoop
Although Esri toolkits are formally open, their use makes sense primarily with Esri products. The concept is very similar to GeoJinni.
Tools are divided into three levels
- Esri Geometry API for Java. Library for extending Hadoop with geospatial abstractions and operations
- Spatial Framework for Hadoop. Extension for using geospatial queries in the Hive Query Language
- Geoprocessing Tools for Hadoop. Direct integration of Hadoop and ArcGIS, allowing you to perform distributed spatial analysis operations in desktop and server applications.
What's next?
Geodata has always been somewhere close to big data, and the advent of distributed computing tools allows you to do really interesting things, allowing not only geographers, but also data analysts (or, as they call it, Data Science) to make new discoveries in the field of data analysis. Instant modeling of flooding, creating horizon lines, spatial statistics, population analysis, creating three-dimensional models from point clouds, analysis of satellite images.
The following articles I will devote to the tools and their scope. Your comments can help us in developing topics for the following articles.
- Which of the frameworks would you like to read about first?
- What application of distributed computing would you like to learn more about?