On the road with clouds. Relational Databases in a New Technological Context
Hello, Habr! We are thinking about publishing an unusual book, the author of which wants to present a very interesting interpretation of the modern technological landscape, covering databases and Big Data processing technologies. The author believes that without the active use of clouds, there’s nowhere to go, and he talks about this landscape from this perspective.
About the author:
Alexander Vasilievich Senko , Ph.D. in physical and mathematical sciences in the field of computer modeling and optimization of powerful microwave instruments.
The author has Microsoft certificates in the field of creating applications in the Microsoft Azure environment: Microsoft Certified Professional and Microsoft Specialist: Developing Microsoft Azure Solutions. In 2008 he graduated from the Belarusian State University of Informatics and Radioelectronics (BSUIR) with a degree in Modeling and Computer Design of Radioelectronic Facilities. From 2007 to 2012, the author works at the BSU Nuclear Problems Research Institute as a technician, laboratory assistant, or engineer. From 2013 to the present, the author has been working at ISSoft Solutions as a software developer and DevOps with a specialization in creating cloud applications based on the Microsoft stack
Under the cut you can appreciate the ideas and style of the author. Feel free to vote and comment - and welcome to the cut!
Introduction or why this article should have been written.
Currently, cloud services allow developers and system administrators to quickly create an application infrastructure and get rid of it just as quickly when it is no longer needed. The fee is charged for the time the cloud resources are used and for their level of performance, also called the "price level" - pricing tier. You can create resources very quickly, “play around” with them, “touch” them, master them, and you don’t have to worry about buying / administering servers, reading documentation on installing the required software, etc. In cloud environments, all common administration and monitoring tasks compiled into a convenient API or user interface of the web portal management. But here one difficulty arises - if a person does not understand or does not fully understand how cloud environments work, the task “what do I need to do to get the database and connect to it from my application” is puzzling at first. The abundance of cloud services and various "price levels" for each service complicates the task of choice even more. This article provides a brief overview of one of the most popular cloud services - relational database services.
Relational databases are a traditional data warehouse. Information in them can be represented as a set of tables consisting of rows. These tables are connected with each other using “keys” - special integrity constraints that put the rows of one table in correspondence with the rows of another. “Big data” is often more convenient to store and faster to process in a non-relational form (for example, in key / value databases), but data stored in the form of interconnected tables allows efficient analysis in any dimension - along rows of related tables and throughout the table, which for the case of NoSQL databases is fraught with great difficulties. In addition, for relational databases, there is a very efficient query language - SQL. In cloud environments, relational databases are presented in two forms - SQL as a Service and in the form of ready-made images for virtual machines. Databases hosted on virtual machines, in fact, are little different from database servers hosted on traditional virtual and physical hosts. At the same time, the choice of the type of virtual machine, virtual disks, cloud storage for their placement and network interfaces significantly affect its performance, but this is the topic of a separate chapter, and possibly a book. Database servers hosted on virtual machines in the clouds have significant limitations associated with scaling, availability, and fault tolerance. For example, Azure virtual machines have a service level agreement (SLA) of 99.95% only when using a cluster of at least two machines, placed in one common availability group (Availability Set), while they will be physically separated network interfaces and power supplies. In order to reach the level of 99.99, it is necessary to configure a cluster of several Always On virtual machines.
At the same time, SQL has an SLA of 99.99 without the additional hassle of configuring clusters. HIPPA standards, on the other handmatch SQL servers hosted on virtual machines, but not an Azure SQL service. Otherwise, cloud-based SQL Server has unrivaled capabilities in terms of scalability, availability and ease of administration (replication, backup, export, analysis of the performance of executed queries). In addition, in some cases SQL as a Service is significantly cheaper than a server with a similar performance hosted on a virtual machine (the author realizes that this is a very controversial statement, especially considering the resource usage features in SQL as a Service and SQL on virtual machines). SQL as a Service does not support all the capabilities of traditional database servers. For example, executing queries from tables in one database inside another in the case of SQL service is fraught with a number of difficulties and limitations.
Microsoft Azure SQL Relational Database Service
Microsoft's SQL-As-A-Service implementation is a cloud-based relational database service based on the Microsoft SQL Server engine and is called Azure SQL. Azure SQL Query Language implements a subset of the T-SQL features. Azure SQL service instances, which are direct analogues of MS-SQL databases, are logically grouped into Azure SQL Server “servers”. Each Azure SQL server must have a unique URL, credentials (username and password), as well as a set of valid IP addresses that can have access to it (this list is created in the server’s firewall and regulates the rules for access to it).
Physically, Azure SQL Server resides in a data center located in a specific geographic region. The same region hosts all instances of Azure SQL databases. Geographic replication of databases in several regions is also possible according to the Primary-Secondary or Primary-ReadOnly Replica scheme (primary server is a read-only replica). With extensive T-SQL support in Azure SQL, you can directly migrate databases from Microsoft SQL Server to Azure SQL. Of course, direct migration from one type of database to another is far from an easy and quick task, but in this case it is fundamentally possible and directly supported using special programs from Microsoft, Red Gate, etc. However, it should be borne in mind that this software in some cases simply “cuts out” incompatible database objects, without trying to adapt them. And it may turn out that after such a migration the database has “risen”, but happy developers can “suddenly” miss a number of database objects in Azure SQL. Each database instance has a certain “price level” —pricing tier — which is characterized by its performance, limitations in size, number of recovery points, and replication capabilities. All possible price levels are divided into the following levels: basic (“Basic”), standard (“Standard”) and premium (“Premium”). The most important difference in price levels is manifested in the different values of DTU - a generalized parameter characterizing database performance. What is this parameter? DTU (eDTU) is a generalized database performance metric that includes CPU performance metrics, memory, input-output devices and network interface. This metric determines the kind of “volume” that Azure SQL performance can take up. If a query is currently running in the database, then this query consumes a certain amount of resources that occupy part of this allowed amount (see Figure 1). It should be borne in mind that not only the volume is limited, but also the specific values of each indicator (that is, it will not be possible to "exchange" extremely small CPU usage for an extremely large memory value). This is manifested in particular in the fact that one “curve” query can cause reuse of one of the resources and eventually weigh the entire database (an instance of the Azure SQL Database service but not Azure SQL Server) and the exact same query will normally work in a traditional database Microsoft SQL Server
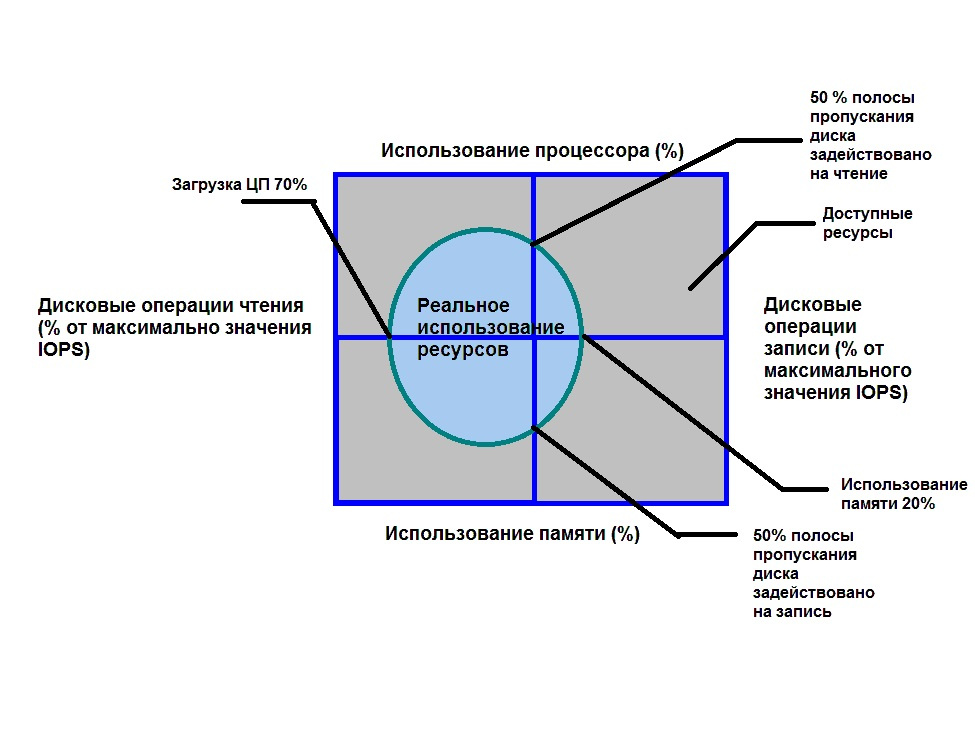
So, Azure SQL consists of Azure SQL Database instances, which are actually relational information stores with certain size and maximum DTU values; instance of Azure SQL Server, which groups the Azure SQL Database, providing them with a common connection string (access string), the access rules prescribed in the firewall and in some cases providing a common elastic resource pool (Elastic Database Pool, which is described below).
Now let's get acquainted with the Elastic Database Pool. This service is built into Azure SQL Server and is used to combine databases into a single pool and assign shared resources to all of them. Why is this needed? Let's consider an example of a SaaS application created to provide certain services to users registered in it (for example, it is a “cloud-based” CRM system). Each registered user of such a system is allocated its own database of a certain level of performance, expressed by a specific DTU value. Each level of performance has a certain monthly cost, which will ultimately affect the profit of the owner of SaaS - it will be equal to the total monthly fee of all users minus the cost of cloud services that underlie the architecture of the system. Now suppose user activity, expressed in the use of DTU of each base, is uncorrelated in nature, i.e. they load their bases at various random time intervals. This leads to the fact that there are times when the use of the DTU database of a particular user is very small, and moments when it is large. Thus, at the time of small use of DTUs, the bases are “idle” - but Azure charges for them. But what if we take several such databases that the intervals of activity of each coincide with the intervals of the underload of others, and combine them into a common pool of databases and distribute common DTU resources between the databases so that the total load is uniform in time; the fee for the price level will be substantially less than the total fee for all databases. It is precisely this idea that underlies the Azure Elastic Database Pool service. In addition, ElasticDatabasePool allows you to implement scripts for splitting one large database into smaller ones, but to execute queries in this database divided into “shards” (shard) as if it were one monolithic database.
Consider now the case when it is still necessary to query the data located in different databases. If there is just a set of databases without fragmentation, you need to select one parent database and create external data sources and external tables (reference tables) in it, which are “reflections” of real tables located in other databases. You can also not use a specialized parent database, but create tablesin each instance of Azure SQL Database. The drawback of this approach is that when changing table schemas in databases, it is necessary to synchronously change the schemes in external tables (if there is no host database, then a lot of work needs to be done to change the scheme in all external tables in all the databases where they are present) . In addition, the T-SQL implementation in Azure SQL has restrictions on data types for external tables (for example, they do not support Foreign Key and the nvatrchar (max) type) and currently there are a number of restrictions on the execution of such queries and databases. where these queries will be executed - for example, it is impossible to export the database to a BACPAC file if there are links to external tables in it. Well, we should not forget about the decrease in performance for such requests. But what does it all look like?
Let's assume for definiteness that we have two databases — the First database and the Second database. Now suppose that from the Second database we need to execute a query to the First database. To do this, credentials must be created in the Second database, which will serve to access the First database:
Then, in the Second database, create an external data source that will be used to communicate with the tables of the external database:
After that, in the Second database, you need to create an “External Table” - a table that is a “reflection” of a similar table located in the First database:
And that’s all! Now we can query the Second database in the Second database as a regular table located in the Second database. It should be borne in mind that these tables are only related by data - any changes to the schema in one database will not affect the table schema in another.
Another possible case of querying various databases is to use Elastic Database jobs . The essence of this technology is that a group of databases is combined and managed centrally from a common specialized VM head server. By interacting with this server programmatically or through the Azure Portal, you can manage all connected databases by creating jobs. These tasks may be of the following nature:
The Elastic Database jobs service contains the following components (Figure 2):

Setting up, using and administering this entire system is a rather complicated topic and will not be considered in detail. Those interested can familiarize themselves with the topic here .
In addition to single databases, the AzureSQL service allows you to create more complex relational repositories - fragmented databases - Sharded Databases and relational repositories with broad support for massively parallel query execution - Azure SQL DWH.
Consider fragmented databases first. The need for database fragmentation arises when its size becomes excessively large to fit on a single Azure SQL instance (currently more than 1 TB for Premium pricing tier). Of course, you can split a large database into smaller databases logically by analyzing its structure (schema). As stated earlier, Azure SQL Server is a logical grouping of Azure SQL Database instances, not a physical join on a single server. And direct queries to database objects from another database are possible only if these objects are External table or these databases are combined in the Elastic Database Pool, and Elastic Database Query queries or Elastic Transactions are used. In this case, you must apply database sharding.
About the author:
Alexander Vasilievich Senko , Ph.D. in physical and mathematical sciences in the field of computer modeling and optimization of powerful microwave instruments.
The author has Microsoft certificates in the field of creating applications in the Microsoft Azure environment: Microsoft Certified Professional and Microsoft Specialist: Developing Microsoft Azure Solutions. In 2008 he graduated from the Belarusian State University of Informatics and Radioelectronics (BSUIR) with a degree in Modeling and Computer Design of Radioelectronic Facilities. From 2007 to 2012, the author works at the BSU Nuclear Problems Research Institute as a technician, laboratory assistant, or engineer. From 2013 to the present, the author has been working at ISSoft Solutions as a software developer and DevOps with a specialization in creating cloud applications based on the Microsoft stack
Under the cut you can appreciate the ideas and style of the author. Feel free to vote and comment - and welcome to the cut!
Introduction or why this article should have been written.
Currently, cloud services allow developers and system administrators to quickly create an application infrastructure and get rid of it just as quickly when it is no longer needed. The fee is charged for the time the cloud resources are used and for their level of performance, also called the "price level" - pricing tier. You can create resources very quickly, “play around” with them, “touch” them, master them, and you don’t have to worry about buying / administering servers, reading documentation on installing the required software, etc. In cloud environments, all common administration and monitoring tasks compiled into a convenient API or user interface of the web portal management. But here one difficulty arises - if a person does not understand or does not fully understand how cloud environments work, the task “what do I need to do to get the database and connect to it from my application” is puzzling at first. The abundance of cloud services and various "price levels" for each service complicates the task of choice even more. This article provides a brief overview of one of the most popular cloud services - relational database services.
Relational databases are a traditional data warehouse. Information in them can be represented as a set of tables consisting of rows. These tables are connected with each other using “keys” - special integrity constraints that put the rows of one table in correspondence with the rows of another. “Big data” is often more convenient to store and faster to process in a non-relational form (for example, in key / value databases), but data stored in the form of interconnected tables allows efficient analysis in any dimension - along rows of related tables and throughout the table, which for the case of NoSQL databases is fraught with great difficulties. In addition, for relational databases, there is a very efficient query language - SQL. In cloud environments, relational databases are presented in two forms - SQL as a Service and in the form of ready-made images for virtual machines. Databases hosted on virtual machines, in fact, are little different from database servers hosted on traditional virtual and physical hosts. At the same time, the choice of the type of virtual machine, virtual disks, cloud storage for their placement and network interfaces significantly affect its performance, but this is the topic of a separate chapter, and possibly a book. Database servers hosted on virtual machines in the clouds have significant limitations associated with scaling, availability, and fault tolerance. For example, Azure virtual machines have a service level agreement (SLA) of 99.95% only when using a cluster of at least two machines, placed in one common availability group (Availability Set), while they will be physically separated network interfaces and power supplies. In order to reach the level of 99.99, it is necessary to configure a cluster of several Always On virtual machines.
At the same time, SQL has an SLA of 99.99 without the additional hassle of configuring clusters. HIPPA standards, on the other handmatch SQL servers hosted on virtual machines, but not an Azure SQL service. Otherwise, cloud-based SQL Server has unrivaled capabilities in terms of scalability, availability and ease of administration (replication, backup, export, analysis of the performance of executed queries). In addition, in some cases SQL as a Service is significantly cheaper than a server with a similar performance hosted on a virtual machine (the author realizes that this is a very controversial statement, especially considering the resource usage features in SQL as a Service and SQL on virtual machines). SQL as a Service does not support all the capabilities of traditional database servers. For example, executing queries from tables in one database inside another in the case of SQL service is fraught with a number of difficulties and limitations.
Microsoft Azure SQL Relational Database Service
Microsoft's SQL-As-A-Service implementation is a cloud-based relational database service based on the Microsoft SQL Server engine and is called Azure SQL. Azure SQL Query Language implements a subset of the T-SQL features. Azure SQL service instances, which are direct analogues of MS-SQL databases, are logically grouped into Azure SQL Server “servers”. Each Azure SQL server must have a unique URL, credentials (username and password), as well as a set of valid IP addresses that can have access to it (this list is created in the server’s firewall and regulates the rules for access to it).
Physically, Azure SQL Server resides in a data center located in a specific geographic region. The same region hosts all instances of Azure SQL databases. Geographic replication of databases in several regions is also possible according to the Primary-Secondary or Primary-ReadOnly Replica scheme (primary server is a read-only replica). With extensive T-SQL support in Azure SQL, you can directly migrate databases from Microsoft SQL Server to Azure SQL. Of course, direct migration from one type of database to another is far from an easy and quick task, but in this case it is fundamentally possible and directly supported using special programs from Microsoft, Red Gate, etc. However, it should be borne in mind that this software in some cases simply “cuts out” incompatible database objects, without trying to adapt them. And it may turn out that after such a migration the database has “risen”, but happy developers can “suddenly” miss a number of database objects in Azure SQL. Each database instance has a certain “price level” —pricing tier — which is characterized by its performance, limitations in size, number of recovery points, and replication capabilities. All possible price levels are divided into the following levels: basic (“Basic”), standard (“Standard”) and premium (“Premium”). The most important difference in price levels is manifested in the different values of DTU - a generalized parameter characterizing database performance. What is this parameter? DTU (eDTU) is a generalized database performance metric that includes CPU performance metrics, memory, input-output devices and network interface. This metric determines the kind of “volume” that Azure SQL performance can take up. If a query is currently running in the database, then this query consumes a certain amount of resources that occupy part of this allowed amount (see Figure 1). It should be borne in mind that not only the volume is limited, but also the specific values of each indicator (that is, it will not be possible to "exchange" extremely small CPU usage for an extremely large memory value). This is manifested in particular in the fact that one “curve” query can cause reuse of one of the resources and eventually weigh the entire database (an instance of the Azure SQL Database service but not Azure SQL Server) and the exact same query will normally work in a traditional database Microsoft SQL Server
So, Azure SQL consists of Azure SQL Database instances, which are actually relational information stores with certain size and maximum DTU values; instance of Azure SQL Server, which groups the Azure SQL Database, providing them with a common connection string (access string), the access rules prescribed in the firewall and in some cases providing a common elastic resource pool (Elastic Database Pool, which is described below).
Now let's get acquainted with the Elastic Database Pool. This service is built into Azure SQL Server and is used to combine databases into a single pool and assign shared resources to all of them. Why is this needed? Let's consider an example of a SaaS application created to provide certain services to users registered in it (for example, it is a “cloud-based” CRM system). Each registered user of such a system is allocated its own database of a certain level of performance, expressed by a specific DTU value. Each level of performance has a certain monthly cost, which will ultimately affect the profit of the owner of SaaS - it will be equal to the total monthly fee of all users minus the cost of cloud services that underlie the architecture of the system. Now suppose user activity, expressed in the use of DTU of each base, is uncorrelated in nature, i.e. they load their bases at various random time intervals. This leads to the fact that there are times when the use of the DTU database of a particular user is very small, and moments when it is large. Thus, at the time of small use of DTUs, the bases are “idle” - but Azure charges for them. But what if we take several such databases that the intervals of activity of each coincide with the intervals of the underload of others, and combine them into a common pool of databases and distribute common DTU resources between the databases so that the total load is uniform in time; the fee for the price level will be substantially less than the total fee for all databases. It is precisely this idea that underlies the Azure Elastic Database Pool service. In addition, ElasticDatabasePool allows you to implement scripts for splitting one large database into smaller ones, but to execute queries in this database divided into “shards” (shard) as if it were one monolithic database.
Consider now the case when it is still necessary to query the data located in different databases. If there is just a set of databases without fragmentation, you need to select one parent database and create external data sources and external tables (reference tables) in it, which are “reflections” of real tables located in other databases. You can also not use a specialized parent database, but create tablesin each instance of Azure SQL Database. The drawback of this approach is that when changing table schemas in databases, it is necessary to synchronously change the schemes in external tables (if there is no host database, then a lot of work needs to be done to change the scheme in all external tables in all the databases where they are present) . In addition, the T-SQL implementation in Azure SQL has restrictions on data types for external tables (for example, they do not support Foreign Key and the nvatrchar (max) type) and currently there are a number of restrictions on the execution of such queries and databases. where these queries will be executed - for example, it is impossible to export the database to a BACPAC file if there are links to external tables in it. Well, we should not forget about the decrease in performance for such requests. But what does it all look like?
Let's assume for definiteness that we have two databases — the First database and the Second database. Now suppose that from the Second database we need to execute a query to the First database. To do this, credentials must be created in the Second database, which will serve to access the First database:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<пар0ль>';
CREATE DATABASE SCOPED CREDENTIAL FirstDBQueryCred -- Это имя учетной записи
WITH IDENTITY = '<ИмяПользователя>',
SECRET = '<пар0ль>';
Then, in the Second database, create an external data source that will be used to communicate with the tables of the external database:
CREATE EXTERNAL DATA SOURCE FirstDatabaseDataSource WITH
(
TYPE = RDBMS,
LOCATION = '.database.windows.net',
DATABASE_NAME = 'First',
CREDENTIAL = FirstDBQueryCred
)
After that, in the Second database, you need to create an “External Table” - a table that is a “reflection” of a similar table located in the First database:
CREATE EXTERNAL TABLE [dbo].[TableFromFirstDatabase]
( [KeyFieldID] [int] NOT NULL,
[DataField] [varchar](50) NOT NULL
)
WITH ( DATA_SOURCE = FirstDatabaseDataSource)And that’s all! Now we can query the Second database in the Second database as a regular table located in the Second database. It should be borne in mind that these tables are only related by data - any changes to the schema in one database will not affect the table schema in another.
Another possible case of querying various databases is to use Elastic Database jobs . The essence of this technology is that a group of databases is combined and managed centrally from a common specialized VM head server. By interacting with this server programmatically or through the Azure Portal, you can manage all connected databases by creating jobs. These tasks may be of the following nature:
- administrative (coordinated schema change, recompilation of indexes);
- Periodically updating data or collecting data for BI systems, including to perform analysis of large amounts of data.
The Elastic Database jobs service contains the following components (Figure 2):
- The host server hosted on the Azure Cloud Service Worker Role instance. In fact, this is specialized software hosted (as of now) on the Azure Cloud Service virtual machine. To ensure high availability, it is recommended to create at least 2 VM instances;
- management database. This is an Azure SQL instance used to store metadata for all connected databases;
- An Azure Service Bus instance that combines and synchronizes all components
- An Azure Storage Account cloud storage instance used to store system-wide logs.
Setting up, using and administering this entire system is a rather complicated topic and will not be considered in detail. Those interested can familiarize themselves with the topic here .
In addition to single databases, the AzureSQL service allows you to create more complex relational repositories - fragmented databases - Sharded Databases and relational repositories with broad support for massively parallel query execution - Azure SQL DWH.
Consider fragmented databases first. The need for database fragmentation arises when its size becomes excessively large to fit on a single Azure SQL instance (currently more than 1 TB for Premium pricing tier). Of course, you can split a large database into smaller databases logically by analyzing its structure (schema). As stated earlier, Azure SQL Server is a logical grouping of Azure SQL Database instances, not a physical join on a single server. And direct queries to database objects from another database are possible only if these objects are External table or these databases are combined in the Elastic Database Pool, and Elastic Database Query queries or Elastic Transactions are used. In this case, you must apply database sharding.
Only registered users can participate in the survey. Please come in.
The relevance of the book
- 52.1% Very interesting, I would like to read the whole book 12
- 21.7% Thanks for the article, but limited to studying the documentation 5
- 26% Uninteresting 6