Client Application Architecture (Structuring Mechanisms)
First story
Some time ago, I worked for a gaming company run by a German. Creating games was not the main business of this German. He received the main income from the sale of cosmetics and from the rental of commercial real estate. Having a gaming company was a way to stand out among your business friends.
The German gaming company developed 3 types of games:
- Flash games for mobile phones with J2ME technology support.
- Educational games for the Nintendo DS handheld game console. The customers of these games were European publishers, and the buyers were parents whose children had problems with learning in mathematics, English or German. The Nintendo DS games division has released many games. Although they did not become AAA titles, they paid for their development and brought a small profit.
- Games for the Nintendo Wii platform.
The last team was me. The team was supposed to develop a game for little girls on the children's brand. The brand was well-known in Germany (it was the main market) and in a number of other European countries: in France and in the UK.
From the very beginning, only the general outline of the game was understood. A little fairy walks in the garden, meets her friends (other fairies), talks to them and invites them to a party. Preparing for this party takes a significant part of the game: a fairy decorates the garden, picks apples, makes a holiday cake from them. The party is fun: the fairy and her friends play musical instruments, and then they dance.
The game was supposed to be a sequence of mini-games. Each mini-game is dedicated to a specific topic: decorating the garden, picking apples, making a holiday cake, playing music and dancing. Despite the fact that the themes of mini-games were understandable, their details were not clear. There was no game designer on the team.
At first, two programmers and one 3D-modeler worked on the game. When I joined the team, there was no elaborate game design (or the person responsible for it), nor a platform on which to make the game.
On the second day after I got a job, the owner of the company approached me and asked: “When will the game be ready?”. By that time, I had experience in the gaming industry and, according to this experience, the development of such a simple game by a team of 3-4 people took about a year. So I said that it would take about a year.
To this the German replied to me: “There is no such term. The game must be made in 3 months. ” Fucking a little, I asked: “Why in three months?” To which the German replied to me: “I will have a birthday, and it is necessary that the game be done by my birthday.”
There were objective prerequisites for such a strict deadline requirement. The German had a contract with a publishing house, according to which he received a fixed amount of development money plus a percentage of sales. But he received a percentage of sales only if the game was completed on time. And the deadline for the game coincided with his birthday.
After adding the 4th programmer to the team, the question arose about choosing bosses. How do they usually form a project team? According to the right approach, first a manager is sought, and then he already hires the rest of the staff. Here, the opposite was done. First, employees were found, and then the authorities began to look which of them could be the leader. It would be nice if professional skills would be paramount when choosing a leader.
But as the leader they chose a man who promised to make the game in 3 months.
After the appointment of the team leader, work began on the game. Problems with game design and lack of technology have not been resolved. Therefore, the work did not move. This greatly angered the newly appointed leader. A frequent dialogue between him and the programmer:
Manager: “Where is the game about apples?”
Programmer: “Not yet done.”
Leader: “When will it be done?”
Programmer: “I don’t know. I don’t understand what to program. ”
Leader: “Well, you are a programmer! Come up! ”
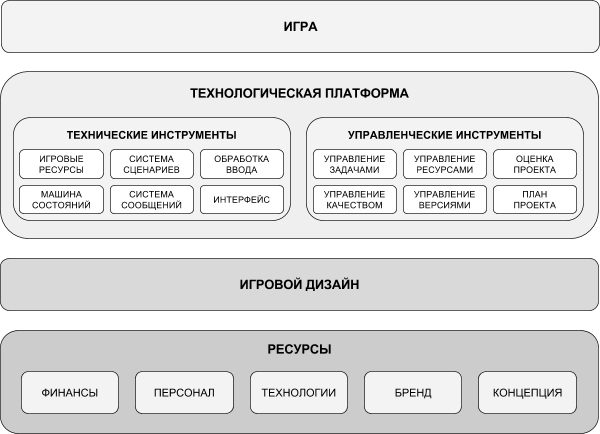
The game development system in the game studio can be represented as a hierarchy of 4 system levels.
The first system level is the resource level. These include: finance, employees (who are available either on the market or within the company), the brand (if the game is created by brand), the initial concept of the game. This level sets the foundation for the entire project.
The second system level is game design. It should not represent a “game design in a vacuum”. On the contrary, it should rely on available resources.
For example, the budget of the mentioned game for girls was insignificant. In addition, only half of the amount could be spent on development, as the second half was intended for the purchase of equipment (computers, televisions, devkits, test kits) and licensing of programs for artists and programmers. The small development budget and platform limitations precluded the possibility of using realistic graphics and realistic physics in the game. There was no money to purchase a license for a technologically advanced engine, and the game console did not allow the use of shaders. I had to use what was already there - a free NintendoWare 3D engine from Nintendo.
The use of a physical engine gives the player freedom of movement. The player can move along the game level in any direction until he encounters an obstacle. But the support of physics requires certain costs both from the side of designers who need to place collision boxes on the stage, and from the side of programmers who have to handle collisions. All this affects the development time. Therefore, we decided to limit ourselves to the use of physics in only one main scene and implement mini-games exclusively using animations.
The third system level is the technology platform. The platform allows you to create games according to the existing game design, or rather, certain types of games. To achieve this, she uses the available resources of the first system level.
The platform includes certain technical and managerial tools. The following are the technical tools:
- game resource management system;
- a game state machine, or a game flow control system;
- scripting system
- message distribution and processing system;
- input processing system (for example, in the case of the Nintendo Wii game console, it can detect the movements of the Wii Remote controller);
- user interface;
- system for loading assets (surfaces, static and dynamic objects, scripts);
- system for loading and saving user data;
- etc.
Management tools include:
- task management system;
- quality management system;
- resource management system;
- version control system;
- project evaluation;
- project plan;
- etc.
The fourth system level is the game itself or a series of similar games.
Breakdown into system levels allows you to deal with complexity. There is a difference whether a programmer makes a mini-game according to a certain design and using a specific platform, on which he can ask questions to other experienced programmers working in the same company, or “pours code” on a low-level API. The difficulty of implementing the same mini-game in both cases will be unequal.
For example, after the game design of each mini-game was invented and described and the platform was implemented, one programmer could implement one mini-game in draft quality in 3 working days. Another 2 days were required in order to add multiplayer to the mini-game and bring some prettiness. Thus, the creation of one mini-game in the final quality cost 5 man-days. Meanwhile, until this moment (with the lack of design and technological platform), weeks passed, and work did not move.
Second story
Once I was invited to an interview at one startup. The project was not very interesting for me, but it bribed me that the company was literally five minutes walk from my house. I thought that for the first time in my career I could not spend time on the road to work.
The interview in the startup was conducted on Skype, and the questions were quite adequate. Basically, they dealt with my previous experience. What I did? What did you do? What tasks did you face?
The selection process for startup candidates was a two-step process. I passed the interview successfully, so after a while the startup manager contacted me and offered to complete the test task.
The test task was as follows:
Develop a text online editor similar to what is used in Google Docs.
It was necessary to support the following features:
- breaking text into paragraphs;
- automatic distribution of text on pages;
- text formatting;
- the ability to simultaneously edit multiple users;
- display and marking of all changes made by different users;
- document storage in the cloud.
A week was allocated for the test task.
It is not necessary to say that I did not perform such a test task, but, politely thanking the leader, I did not contact him anymore.
Subtotals
Summing up, it can be argued that in both stories the same mistake was made - skipping the system level [6].
In the first story, when working on a game for girls, the “game design level” and “technological platform level” were missed, which led to a stalled work on the project and an increase in development time. Work on the project was unlocked only after the missing levels were added: the game design was worked out and a (albeit lightweight) platform was implemented.
The second story also skipped system levels. The proposed task looks clearly more complicated than a regular test task. To combat complexity, the solution should be presented in the form of a hierarchical system, where the lower layers provide the work of the layers located above. But such work requires considerable labor costs and places excessive demands on the qualifications of an engineer. It should be understood literally in all areas: in network protocols, in text editors. Therefore, it is more accessible to the company than to one person.
Hierarchy of system levels
The system level approach can be used in designing applications. Of course, when it comes to writing some simple program, then splitting into levels is not necessary. A layered (or layered) architecture makes sense if you are developing a complex application or an application of medium complexity.
Identifying system levels is the first step in developing an architecture. If you read a book on object-oriented analysis and design, you must have seen more than once the author asks the question: “How to find candidates for classes?”. Perhaps in programming, you yourself asked the same question.
The process of structuring an application should not begin with identifying classes. A class is too small an element of abstraction. If we draw an analogy with construction, then the class is like a separate brick. And the construction of a skyscraper is unlikely to start with the question of how to build it out of bricks.
Three layer architecture
Fowler [7] and the Microsoft application architecture design guide [5] identify three system levels (in other words, three layers of abstraction) into which the developed application can be divided.

Note: The original version of the diagram can be viewed on the Microsoft website.
The first layer of abstraction is the data access layer. The tasks of this layer include abstracting from the database. SQL queries to the database in which the application data is stored are hidden behind the facade that uses the business layer.
The second layer of abstraction is the business logic layer. It contains objects of the subject area, as well as functions for working with them. These functions and implement this business logic.
The third layer of abstraction is the user interaction layer. This layer includes user interface components.
The three-layer architecture described in the Microsoft manual is operational. The only thing I get misunderstood is some thing related to the interaction of the business logic layer with the data access layer.
According to my understanding, domain classes should belong to the layer of business logic. On the other hand, the main task of the data access layer is to get data from the database and copy this received data into business objects.
It turns out a contradiction:
- On the one hand, business objects must be declared at the level of business logic, because logically relate to it.
- On the other hand, business objects must be accessible at the data access level so that they can copy the data read from the database.
Seeing this contradiction, I would like to propose a slightly different approach to dividing the application into system levels.
Five tier architecture
The approach I propose involves dividing the client application into 5 system levels. The key of the proposed five levels are only two. This means that the client application, at least, can consist of two system levels. Using all 5 layers is an optional and perhaps more desirable option.
Limitations
The proposed architecture has a number of limitations:
Firstly, it was tested by me and colleagues when creating 5 clean client applications. Those. there was no server component, no DBMS was used, and applications were run on desktop computers and mobile devices .
Four applications are designed to create and edit various game resources. The fifth application is a service program designed to provide services.
Secondly, the developed applications were intended for creating and editing documents. They possessed minimal business logic (for example, they should not have made payments), but a rich interface - it contained many different controls (controls) for creating and editing data (track editors, function graphs, property editors, etc.).
Description

The first level can be called infrastructural. It is called so because it contains infrastructure, i.e. libraries, modules, classes and methods that are used throughout the application.
If application development is conducted in the C ++ programming language, then, as a rule, the infrastructure level includes:
- raster image libraries;
- XML and JSON parsers;
- libraries of data compression and encryption;
- libraries of containers and various auxiliary classes (STL, boost);
- Utilities written by application developers.
The infrastructure level is a kind of “dump” of various useful utilities and utility classes. The presence of such a layer allows one to get rid of entropy in the higher layers. Everything that is useful, but difficult to streamline, needs to be placed at the infrastructure level.
The second level can be called a data model. This level is the key, because at least one client application can hardly do without it.
The name “data model” echoes the name “data access layer” from the Microsoft application design guide. Despite the fact that the tasks of this level approximately coincide with the tasks of the data access layer, there is a significant difference:
The data model is combined with a data source , which uses files in XML or JSON formats. For data storage, no DBMS is used.
A data model is an object model of a domain [7, p. 140] and consists of self-serializing classes whose objects load themselves from the file and save themselves to the file.
The data model contains business objects that, according to the guidelines, should be included in the business logic layer.
These objects either do not contain any logic or have some minimal logic associated, for example, with data verification. The number of methods that these objects possess is also small. As a rule, they either provide simplified access to other objects associated with the former, or are responsible for serializing and deserializing the object itself.
According to Fowler [7, p. 140] the object model of the subject area relates to business logic. Therefore, conducting a direct comparison of the proposed five-level model with the classical three-layer architecture [5], it is difficult to correlate which layer of abstraction corresponds to the data model. It turns out some mix between the data source, the data access layer and part of the business logic. It is justified when there is no need to distribute data storage (DBMS) and their processing (application server) by physical levels (tires).
In a program for creating visual effects and in a program for creating animated blueprints, data model objects serialize themselves in XML. These are self-sustaining objects. The data model includes both objects in memory in the form of class instances and serialized XML files on the hard disk.
In a GPS navigator, the data model is a little more complicated. It consists of several specialized databases and a layer of code that provides access to data.
The combination of the object model of the subject area, the data access layer and data sources in one system level allows you to use the approach “design based on the subject area” and create a single solution space that is used to organize data both within the application and during storage.
A similar approach can be applied if the application does not need to operate with a large array of data and / or use a DBMS. Otherwise, the level of the data model will still have to be divided.

Figure “Comparison of classic three-layer and five-level architectures”
The third level is the level of services or services. From my point of view, this particular layer corresponds to the layer of business logic from the Microsoft management. However, such a correspondence is formal, because in the case of editing programs, it is difficult to understand what business logic is. If the user just needs to create and / or edit a document (for example, a visual effect or an animated blueprint), then what is considered business logic? The editing process itself? In editor applications there are no financial entries and there is no production process management system. Business logic could include an object model of a subject area. But it is already at the data model level.
Such questions show that the mechanical comparison of the three-layer architecture outlined in the Microsoft manual and the five-level architecture proposed in this article is not correct outside of the consideration of application-specific architectures.
The service level is a set of functional modules. Each module is responsible for the implementation of any one operation performed on the data model.
There may be many such business functions in some client applications. In some, few. And in some - they are completely absent. Therefore, for a number of applications, the service level may be skipped.
For example, in the visual effects editor, each effect can be saved in XML format. However, in order for this visual effect to be used in the game, it must be converted to a binary format. The compiler is involved in such a conversion. This compiler is a separate service.
There are more services in the GPS navigator. Because this application is intended to provide services to users. These services include:
- drawing a map of the area where the user is located;
- laying a route to a given point;
- route navigation;
- search for coordinates by address.
The modules responsible for the provision of services are located at the service level. Services are independent or weakly dependent on each other. They can be placed in different modules and avoid excessive connectivity between them.
The fourth level is responsible for editing. This level is typical for editors. It contains sample components or sample editor architectures. First of all, I mean:
- Document / View Architecture (also known from the MFC Class Library) [1]
- Undo / Redo Management [3]
The Document / View architecture binds a specific file extension to a specific type of document, and also attaches a specific type of document to a specific view, which is responsible for its visualization.
Undo / Redo Management provides support for undoing an operation. Due to this feature, the user can edit an erroneously performed operation at any time when editing a complex document. As a result, editing becomes error-resistant and not scary for humans. This functionality has become the de facto standard for various editing programs.
The editing layer is part of the presentation layer of the classic three-layer architecture [5]. Its selection in a separate layer is due to the fact that it defines the wireframe for editing.. In addition, the architectural concepts used to organize the editing level are independent of data visualization .
The fifth level is also the key. Not a single client application can do without it. This level contains the components responsible for data visualization and user interaction.
Despite the fact that this level is called exactly the same as the layer from the classical three-layer model, nevertheless, it has slightly less responsibilities. The exclusion of components responsible for editing from it allows the developer to focus on data visualization and writing a variety of controls .
The separation between the editing level and the presentation level may not be physical, but mental. The components of both layers can be located in one module.
Connection with the design template “Model - View - Controller”
The concept “Model - View - Controller” was formulated by the Norwegian Trygve Reenskaug in 1978 / 79th during his work in the Xerox PARC laboratory [8]. It involves dividing the structure of the application into three components:
- Model. Describes the data. Not involved in data conversion. Does not contain code for their visualization.
- View. Responsible for rendering the Model.
- Controller. Modifies the Model, as a rule, as a result of user actions.
One of the most controversial components is the Controller . In various implementations, the design pattern "Model - View - Controller" component controller performs various duties. For example, in the APIs of the Mac OS and iOS operating systems, there is a view controller that is responsible for managing views, and the Microsoft Foundation Classes library for programming for Windows uses the Document-View architecture , in which the Model refers to the Document and the Controller is missing .
In a number of interpretations under the Controllerunderstand the processing of commands from input devices (such as mice and keyboards). In other cases, visual input elements displayed on the screen (for example, menu) are added to input devices [8].
Some interpretations identify the Controller with the business logic of the application [8].
Although the concept “Model - View - Controller” does not have an established view of the Controller element , nevertheless, it involves the separation of data from their visualization.
In this regard, we can say that both the three-layer architecture described in the Microsoft manual [5] and the five-level architecture described in this article, to one degree or another, correspond to the concept “Model - View - Controller”. The criteria used to divide the application into system levels partially overlap with the criteria used in the “Model - View - Controller” to highlight its components.
The organization of the selected elements in the form of layers uniquely sets their subordination and eliminates various questions on the topic “Should the Controller know about the View?” or “Should the Model update the View when it changes?” .
Separation of architecture into layers determines not only the logic of component allocation, but also clearly specifies the dependencies between them. The data model knows nothing about the level of services, nor about the level of editing. However, it can be converted by them. The service layer knows nothing about model rendering. However, the presentation layer uses both the model and the services.
Also, the proposed architecture lacks such an ambiguous component as the Controller . Instead, a service level, an editing level, and a presentation level are added, whose responsibilities and position in the hierarchy are clearly specified.
At the editing level , the Document-View architecture is used , which is a subspecies of the design pattern“Model - View - Controller” . This architecture involves the separation of the classes Document (responsible for storing and transforming data and, in fact, is a wrapper over classes from the data model) and View (responsible for visualizing data and processing commands from the user).
Using the “Document - View” architecture allows you to specify the interaction between the model and the view (view), add the ability to edit the data model and support the ability to cancel operations.
Example 1. All Sparks Editor
Overview
All Sparks Editor is an application for creating visual effects. In appearance, this application resembles an audio editor. There is a justification for this: like sound, the visual effect has a certain duration. Therefore, the visual effect editing window contains a timeline located horizontally. Under the time axis are tracks that are also oriented horizontally. User can add and delete tracks.

The main window of the All Sparks editor
. Components are placed on tracks. The user can select these components from the Component List and drag them onto the tracks.
The components are:
- particles;
- billboards;
- three-dimensional models;
- sources of light;
- music and sounds;
- various forces, for example:
- gravitational force;
- air resistance force;
- turbulence force;
- etc.
Force components act on particle components. If you place the “particle” component on the same track and place the “gravitational force” component under it, then gravity will act on the flying particles during the playback of the effect. Gradually, the particles will fall down.

Components are located on tracks.
Each component is represented as a rectangle. Since a component can occupy space on only one track, the height of the component coincides with the height of the track. The length of the component determines the duration of its existence, and the beginning is the moment of its appearance when the effect is reproduced.
In order for the user to quickly identify the type of component, each type of component has its own color.
After placing the component on the track, the user can set its various properties. Component properties are displayed in the property editor, which is located at the bottom of the editing window.

Property
Editor The property editor is a table of two columns and many rows. The left column shows the property names, and the right column values.
The user can look at what the visual effect looks like in the preview window. This window is located on the left side of the main program window. In order to reproduce the effect, the user must press the Play button. After that, the effect is compiled into a binary format and transferred to the game engine for playback.

Visual effect in the viewport
Architecture
The architecture of the visual effects editor can be represented as a hierarchy of 5 system levels:

The first system level is infrastructure. It is a collection of helper classes. As a rule, these classes contain some mathematical methods that are not available in the standard Math class, or some additional operations with strings and file names. The infrastructure level is very small.
The second system level is the data model. The data model describes the structure of the visual effect: tracks, components on them, properties of the components.

Each data model class has Load and Save methods that are designed to load and save an object from / to XML. For reading and writing XML, LINQ to XML is used.
public class Component
{
public Dictionary Properties { get; } = new Dictionary();
public Component Load(XElement item)
{
if (item == null)
{
throw new ArgumentNullException(nameof(item));
}
// Loading logic
return this;
}
public XElement Save()
{
return new XElement("component",
Properties.Values.Select(prop => prop.Save()).ToArray()
);
}
}
The third system level is the level of services and services. Currently, this layer contains only one service. This is a compiler. The compiler converts the effect to a binary format, which can then be used by the engine.
Some time ago, the visual effects editor was not integrated with the game engine. These were two different applications. And in order for the visual effect to be able to see how it looks, there was another service that allowed the exchange of data between the client program (visual effects editor) and the server, which was the viewing program. This service was called a communicator.
Thus, previously there were two services. And now, since the integration of the visual effects editor with the game engine has taken place, the need for a communicator has disappeared, and only one service remains - the compiler.
The fourth system level is the editing level. It implements two architectures:
- Document / View architecture, which allows you to open visual effects files in the original format and create various types for editing and display.
- Undo / Redo Management, which is a stack of commands that can be executed or canceled when editing an effect.
The fifth system level is the level of user interaction , which contains various controls. In our case, such controls are the timeline, tracks, property editor, etc.
Example 2. Genome Editor
Overview
The second application, the architecture of which I want to consider, is the editor of animated blueprints. Blueprint is a software module that implements certain functionality, but not written in a programming language, but presented in the form of a graph. It turns out that the blueprint editor is a visual programming tool.
Blunts were first implemented in the Unreal Engine 4 engine [2]. They are used for various purposes, including for “programming” the logic of the game scene or character behavior.
In modern video games, 3D-animators have to make a lot of different animations to create high-quality pictures. If we are talking about creating a humanoid character, then you need to animate a lot of movements: gait, run, jump, squat, raise arms (together and each arm individually), etc.
Often, the character’s behavior cannot be reduced to playing one of the animations or to playing some predetermined sequence of these animations. Sometimes animations need to be combined. For example, a character can walk while carrying a cup of hot coffee in her right hand. Without stopping, he can bring this cup to his mouth to take a sip.
Modern 3D engines allow you to mix various character animations, i.e. play them at the same time. This is required for a smooth transition from one animation to another or when one animation is played on one part of the character’s skeleton, and the other on the other. In order to set the logic for such a mixture, the editor of animated blueprints is used. He first appeared in the Unreal Engine 4. And since it seemed convenient to our 3D animators, we needed to create a similar editor with us.

Main window of the editor Genome
Animation blueprint is a graph. It consists of nodes and connecting lines. Lines can be drawn not to an arbitrary place on the node, but to a specific socket. Each node of the graph may contain one or more sockets.
Nodes are various operations, for example, comparison, addition, subtraction, loop, branching, etc.

Examples of operation nodes
There are more complex nodes such as a state machine. Complex nodes contain nested graphs. For example, a state machine contains a state graph, each node of which denotes a certain state, and connecting lines - conditional transitions. States also contain nested graphs.

State Machine
To enter the embedded graph, the user must double-click on the node with the mouse. The embedded graph can be edited in the same way as the parent. It also consists of nodes and connecting lines.
Each node can have one or more sockets. Sockets are located on the left and right sides of the node. Sockets that are located on the left are called input, and sockets on the right are called output. Input data or control signals arrive at the input sockets, and the results of the operation for which the node is responsible can be obtained from the output sockets.

Nodes with different input and output sockets
Sockets are typed, as are the connecting lines between them. There are sockets for integers and real numbers, for Boolean values and strings. Typing sockets allows you to avoid errors when an output socket of one type is connected to an input socket of another type, for example, a string with an integer. Directly such a connection is impossible, only through the auxiliary node, which performs the type conversion operation.
Trunks between sockets define data flows and control flows. To organize control flows, there are specialized sockets, which are called animation pose in the animation graph and exec in the event graph.
You can read more about blueprints, nodes, and sockets inBlueprints Visual Scripting from the Unreal Engine 4 Documentation [2]. Genome has taken a similar approach.
Architecture
The architecture of the animation blueprint editor can be represented by a hierarchy of 5 system levels. This hierarchy is similar to the one used in the visual effects editor. Names of levels, their purpose, individual components practically coincide. But there are differences that I would like to draw your attention to.
The differences are due to the fact that the editor of animated blueprints is based on the graph editor. The task was set to reuse this editor when rewriting other applications: the material editor and the dialog editor.
This means that you cannot limit yourself to a single data model that will represent graphs for animated blueprints. We need some basic data model for all possible graphs. And you need some framework for creating and editing graphs. This framework should be used by specific editors: an editor of animated blueprints, an editor of dialogs, an editor of materials, etc.

The infrastructural level of the animation blueprint editor is practically no different from the similar level of the visual effects editor, with one exception. Since the control for graph visualization is implemented using WPF technology, the infrastructure layer contains all sorts of auxiliary classes that facilitate working with WPF, as well as styles for the controls used. Styles are used not only in the Genome editor, but also in other applications. Therefore, they are located at the infrastructure level.
The data model is divided into two parts. The first part is a generalized data model for any graph and any blueprint. It is a hierarchical graph. The graph contains nodes and connecting lines. Some nodes may contain other graphs.

The second part is a data model for animated blueprints. It contains classes that describe the nodes of an animated blueprint. Such nodes include mathematical operations, comparison operations, type conversion operations, animation mixing operations, etc. Separate classes represent sockets and trunks.

On top of the data model is the service layer . As in the case with the visual effects editor, this level contains only one service - the compiler. The compiler converts the animation blueprint in its original format to a binary format that is played by the engine.
The editing level is divided into three parts. The first part is a library that contains the base classes for the Document / View architecture and for managing Undo / Redo. This library is used both in the animation blueprint editor and in the visual effects editor.
The second library is responsible for editing graphs. It allows the user to create nodes, arrange them in the editing window, connect nodes to connectors of various types, and also to delete nodes and switch between nested graphs. However, this library deals with a generalized graph model and knows nothing about specific nodes for the animated blueprint editor.
The third library is for editing animated blueprints. It allows you to create, delete, edit specific nodes of the animated blueprint.
User interaction levelalso divided into three parts. The first part contains the basic components of the user interface. The second part contains the interface components used for editing graphs. And the third part contains user interface components used to edit animated blueprints.
In general, the architectures of the visual effects editor and the animation blueprint editor are very similar and consist of the same system levels. However, there are differences that are caused by the need to create a generalized library for editing graphs. These differences result in the fact that, first of all, the data model is divided into two parts:
- a generalized data model that describes a generalized graph;
- and a specific data model that describes a graph of a particular kind - an animated bluetooth.
Together with the data model, the same separation occurs both at the editing level and at the level of user interaction.
Example 3. GPS Navigator
Overview
In the third example, I would like to consider creating a GPS navigation application for a smartphone. This program differs from the applications discussed in the previous two examples: the visual effects editor and the animation blueprint editor.
The main difference is that the editors are aimed at creating and editing documents while the GPS navigator is designed to provide services.
These services include:
- Help the user in orientation on the ground. This service is carried out by drawing a map of the area and indicating the location of the user. When the user moves, the direction of this movement is also shown.
- Building a route to a given point. Destination can be specified either by indicating a point on the map, or by searching.
- Search for a specific address or intersection of two roads.
- Search for nearby points of interest: cafes, gas stations, ATMs, etc.
Despite the focus of the navigation system on the provision of services, nevertheless, it also allows you to create and edit some simple documents. These include:
- user profile
- Search history for points of interest and addresses
- editing the list of favorites (home address, address of the place of work and others).
Architecture
The architecture of the GPS navigator can be represented by a hierarchy already known to us from 5 system levels.

The first, lowest, infrastructure level consists of libraries and utilities that are used end-to-end throughout the application. Since the navigation system was developed using the programming languages C and C ++, these libraries included:
- stlport library, which contains a set of standard containers and algorithms and is built for different platforms;
- zlib library, which allows you to compress and decompress data using the deflate algorithm;
- libpng and libjpeg libraries for working with raster graphics in png and jpeg formats;
- aes library for encrypting data and creating electronic signatures;
- expat xml parser library for reading and parsing xml files.
The level of the data model is the most complex compared to similar levels in other considered applications. The fact is that the speed of many navigation algorithms is determined by the speed of access to the necessary data. Therefore, the data must be organized in such a way that the access speed is high.
The data contains cartographic information, which is then used to draw maps, plot a route, and search for coordinates by address.
The data model level can be divided into two sublevels:
- database;
- data access layer.
The database contains navigation data: maps, zip codes, points of interest, travel history, a list of favorite places.
The data access layer receives data from the database and provides it to a higher level in the form of corresponding data structures.
Initially, the cards in the original format are input to the compiler, which converts them into an intermediate format. As a rule, GDF 3.0 acts as the initial format. This is a text file with specific markup. Often, one card, introduced in GDF 3.0, "weighs" more than one gigabyte. To present the UK road network, 7 such maps are needed. The binary format acts as an intermediate, which allows you to present complete information in a compact form.
Next, the cards in an intermediate format are input to five compilers, which convert them into specialized databases.
The first specialized database contains the information needed to render a map. It includes not only roads, but also various areas such as parks, ponds, forests. The main requirement for it is quick access to all elements that are in a given area.
The second specialized database stores the information needed to build a route. Unlike the database for drawing, it contains information only about the road. To build a route you do not need to know anything about water bodies, forests, parks and the geometry of road elements. Only the length of the road element, maximum speed and direction of travel are required. The main requirement for it is quick access to neighboring road elements.
The third specialized database contains addresses. The main requirement for it is a quick search of the address by the entered text and the road element by address.
The fourth specialized database contains information about zip codes. The main requirement for it is a quick search for the coordinates of the area by zip code.
The fifth database contains information about various points of interest (restaurants, cafes, gas stations, ATMs, etc.). The main requirement for it is to quickly find points of interest within a specific area.
To access map data, a data access layer is used.
Thus, the data model for a GPS navigator includes:
- cards in the original (text) format;
- a compiler for converting maps from text format to intermediate binary;
- five specialized compilers that form specialized databases:
- database for drawing maps;
- database for building a route;
- a database for finding coordinates by address;
- zip code database
- database of points of interest;
- a data access layer that provides access to data from specialized databases.
On top of the data model is the service layer . Since the GPS-navigator is a service-oriented application, this level includes several function-oriented modules. Each module is responsible for any one key function or a group of similar key functions of the navigation system.
The following modules can be distinguished:
- Card rasterizer. Generates a two-dimensional or three-dimensional representation of the map in a given area.
- Routing module. It is responsible for laying the route from the current location to a given point.
- Address Search Module. Responsible for finding coordinates by address.
- Index search module. Responsible for finding coordinates by zip code.
- Point of interest search module. Responsible for finding points of interest within a given area.
- Navigator. Responsible for the formation and issuance of navigation directions when moving along a route.
The editing level is small enough and does not contain too much code. The reason for this is that the navigation system is designed to provide user services and is not intended to create and edit any documents.
There are 3 main functions that can be delegated to the editing level:
- работа с профилями пользователей (у навигационной системы могут быть несколько пользователей, и данные каждого пользователя должны сохраняться в отдельном профиле);
- создание и управление списком мест-фаворитов;
- сохранение истории поездок (в простейшем случае — сохранение точек назначения).
In principle, a GPS navigator can safely do without an editing layer. But if you want to support profiles, then work with them can be delegated to such a layer.
The level of interaction with the user is responsible for the presentation of information for the user on the screen or on the sound card of the device, as well as for processing input from the user. It contains various screens and controls. The level of user interaction can support skins, if there is a need to make the interface convenient when working on different devices.
Summary
To summarize the consideration of the architectures of the three applications.
- The architecture of the client application can be represented by a hierarchy of five system levels:
- The infrastructure layer contains libraries that are used throughout the application.
- Уровень модели данных содержит классы, описывающие предметную область.
- Уровень сервисов предоставляет услуги для пользователя. К таким услугам относятся: компиляция, прокладка маршрута, поиск координат по адресу и т.д. Каждая услуга помещается в отдельный модуль, который называется сервисом.
- Уровень редактирования предназначен для создания и редактирования документов. Он также поддерживает возможность отмены операции.
- Уровень взаимодействия с пользователем отвечает за представление данных в удобном для пользователя виде, а также — за обработку ввода. Он содержит различные органы управления.
- Каждый уровень может содержать один или несколько модулей, или же быть пустым. В последнем случае он остается в пятиуровневой модели только из общесистемных соображений.
- Количество модулей, расположенных на уровне, зависит от типа приложения. Если разрабатывается приложение, предназначенное для редактирования различных документов, то будут насыщенными уровни редактирования и взаимодействия с пользователем. Если же создается приложение, нацеленное на оказание услуг пользователю, то будет насыщенным уровень сервисов в то время, как уровень редактирования будет небольшим.
- Сложность модели данных зависит от объема данных и от требований по производительности. В ряде случаев модель данных можно реализовать в виде самосериализуемых в XML классов. И этого будет достаточно. В других случаях потребуется создать базы данных со сложными структурами данных, оптимизированные для произвольного доступа. При использовании таких баз данных потребуется разработка программ-компиляторов, которые тоже относятся к модели данных.
- Если требуется разработать линейку приложений, позволяющих редактировать или отображать однотипные данные (например, графы), то необходимо разделить модель данных на одну обобщенную и несколько специализированных (по числу разрабатываемых приложений). Такое разделение пройдет и через вышестоящие уровни: уровень редактирования и уровень взаимодействия с пользователем.
Литература
- Document/View Architecture
- Blueprint Visual Scripting/Unreal Engine 4 Documentation
- Introduction to Undo Architecture
- Gregory, Jason. Game Engine Architecture
- Руководство Microsoft по проектированию архитектуры приложений, 2-е издание
- Лебедев К.А., Сычев С.В. О потерянном уровне
- Фаулер, Мартин. Архитектура корпоративных программных приложений. – Пер. с англ. – М.: Издательский дом «Вильямс», 2006. – 544 с.: ил.
- @cobiot. The hunt for the mythical MVC. Overview, a return to the source and how to analyze and display patterns yourself
- @cobiot. The hunt for the mythical MVC. User interface building
The author thanks his colleagues for their help in preparing the article.