Operators for Kubernetes: How to Run Stateful Applications
Kubernetes stateful problem
The configuration, launch and further scaling of applications and services is simple, if we are talking about cases classified as stateless, i.e. without saving data. It’s convenient to run such services in Kubernetes using its standard APIs, because everything happens out of the box: according to standard configurations, without involving any specifics and magic.
Simply put, to start another five copies of the backend in the cluster from containers in PHP / Ruby / Python, you only need to raise the new server 5 times and copy the sources. Since both the source code and the init script are in the image, scaling the stateless application becomes quite elementary. As lovers of containers and microservice architecture are well aware, difficulties begin for stateful applications., i.e. with saving data, such as databases and caches (MySQL, PostgreSQL, Redis, ElasticSearch, Cassandra ...). This applies to software that independently implements a quorum cluster (for example, Percona XtraDB and Cassandra), and software that requires separate control utilities (such as Redis, MySQL, PostgreSQL ...).
Difficulties arise because the source code and starting the service is not enough - you need to perform some more actions. At a minimum, copy data and / or join a cluster. More specifically, these services require an understanding of how to properly scale, update and reconfigure them without losing data or temporarily unavailable. Taking these needs into account is called “operational knowledge”.
CoreOS Operators
In order to “program” operational knowledge, at the end of last year, the CoreOS project introduced a “new class of software” for the Kubernetes platform - Operators (from English “operation”, ie “operation”).
Operators, using and expanding the basic capabilities of Kubernetes (including StatefulSets , see the difference below), allow DevOps specialists to add operational knowledge to the application code.
Operator Goal- provide the user with an API that allows you to manage many entities of the stateful application in the Kubernetes cluster, without worrying about what is under the hood (what data and what to do with it, which commands still need to be executed to maintain the cluster). In fact, the Operator is called upon to simplify the work with the application within the cluster as much as possible, automating the performance of operational tasks that previously had to be solved manually.
How Operators Work
ReplicaSets in Kubernetes allow you to specify the desired number of running hearths, and controllers make sure that their number is maintained (creating and deleting hearths). The Operator works the same way, which adds to the standard resource and the Kubernetes controller a set of operational knowledge that allows performing additional actions to maintain the required number of application entities.
How does this differ from StatefulSets for applications requiring the cluster to provide them with stateful resources such as data storage or static IP? For such applications, Operators can use StatefulSets (instead of ReplicaSets ) as a basis, offering additional automation: perform the necessary actions in case of crashes, make backups, update the configuration, etc.
So how does all this work? The operator is a control daemon that:
- Subscribes to the event API in Kubernetes
- receives from it data about the system (about its ReplicaSets , Pods , Services , etc.);
- receives data on Third Party Resources (see examples below);
- reacts to the appearance / change of Third Party Resources (for example, to resize, version change, and so on);
- responds to changes in the state of the system (about its ReplicaSets , Pods , Services , etc.);
- the most important thing:
- calls the Kubernetes API to create everything you need (again, your ReplicaSets , Pods , Services ...),
- performs some magic (for simplicity, one may think that the Operator goes into the pods themselves and calls commands, for example, to join a cluster or to upgrade the data format when updating the version).
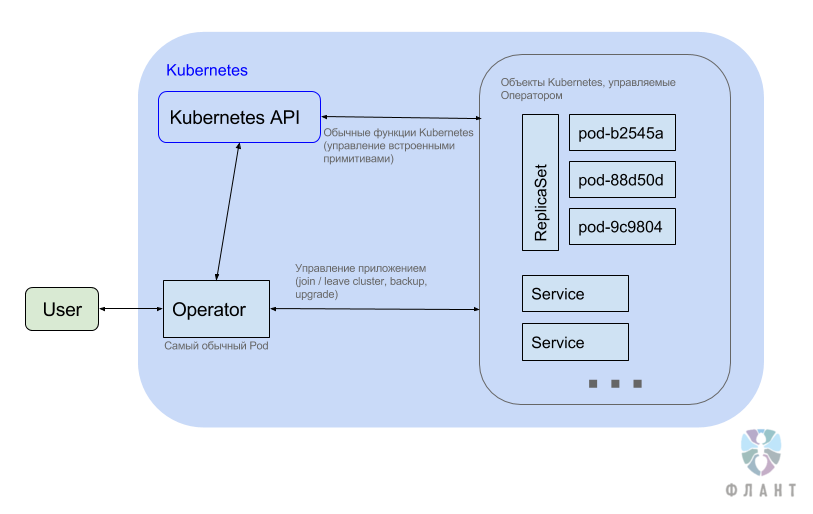
In fact, as can be seen from the picture, Kubernetes just adds a separate application (the usual Deployment with ReplicaSet ), which is called the Operator. It lives in the usual hearth (usually the only one) and, as a rule, is responsible only for its Namespace . This operator application implements its API - though not directly, but through Third Party Resources in Kubernetes.
Thus, after we created the Operator in the Namespace , we can add Third Party Resources to it .
An example for etcd (see details below) :
apiVersion: etcd.coreos.com/v1beta1
kind: Cluster
metadata:
name: example-etcd-cluster
spec:
size: 3
version: 3.1.0
Example for Elasticsearch:
apiVersion: enterprises.upmc.com/v1
kind: ElasticsearchCluster
metadata:
name: example-es-cluster
spec:
client-node-replicas: 3
master-node-replicas: 2
data-node-replicas: 3
zones:
- us-east-1c
- us-east-1d
- us-east-1e
data-volume-size: 10Gi
java-options: "-Xms1024m -Xmx1024m"
snapshot:
scheduler-enabled: true
bucket-name: elasticsnapshots99
cron-schedule: "@every 2m"
storage:
type: gp2
storage-class-provisioner: kubernetes.io/aws-ebs
Requirements for Operators
CoreOS formulated the basic patterns obtained by engineers while working on Operators. Despite the fact that all Operators are individual (they are created for a specific application with their own characteristics and needs), their creation should be based on a kind of framework that presents the following requirements:
- Installation should be done through a single Deployment : kubectl create -f SOME_OPERATOR_URL / deployment.yaml - and not require additional actions.
- When installing the Operator in Kubernetes, a new third-party type (ThirdPartyResource) must be created . The user will use this type to launch application instances (cluster instances) and further manage them (version upgrade, resizing, etc.).
- Whenever possible, you must use the Kubernetes built-in primitives, such as Services and ReplicaSets , in order to use well-tested and clear code.
- Backward compatibility of Operators and support of old versions of resources created by the user are required.
- When the Operator is deleted, the application itself should continue to function without changes.
- Users should be able to determine the desired version of the application and orchestrate updates to the version of the application. The lack of software updates is a frequent source of operational and safety problems, therefore Operators should help users in this matter.
- Operators should be tested with a tool such as Chaos Monkey, which identifies potential failures in pods, configurations, and networks.
etcd Operator
An example implementation of the Operator is etcd Operator, prepared for the day of the announcement of this concept. Cluster configuration etcd can be complicated due to the need to maintain a quorum, the need for reconfiguration of cluster membership, backups, etc. For example, manually scaling the etcd cluster means that you need to create a DNS name for the new member of the cluster, launch a new entity etcd, notify the cluster of a new member ( etcdctl member add ). In the case of the Operator, it will be enough for the user to change the cluster size - everything else will happen automatically.
And since etcd was also created in CoreOS, it was logical to see the appearance of its Operator first. How does he work? Operator Logic etcd defined by three components:
- Observation (Observe). The operator monitors the status of the cluster using the Kubernetes API.
- Analysis (Analyze). Finds differences between the current status and the desired one (defined by the user configuration).
- Action (Act). Eliminates detected differences using the etcd service API and / or Kubernetes.
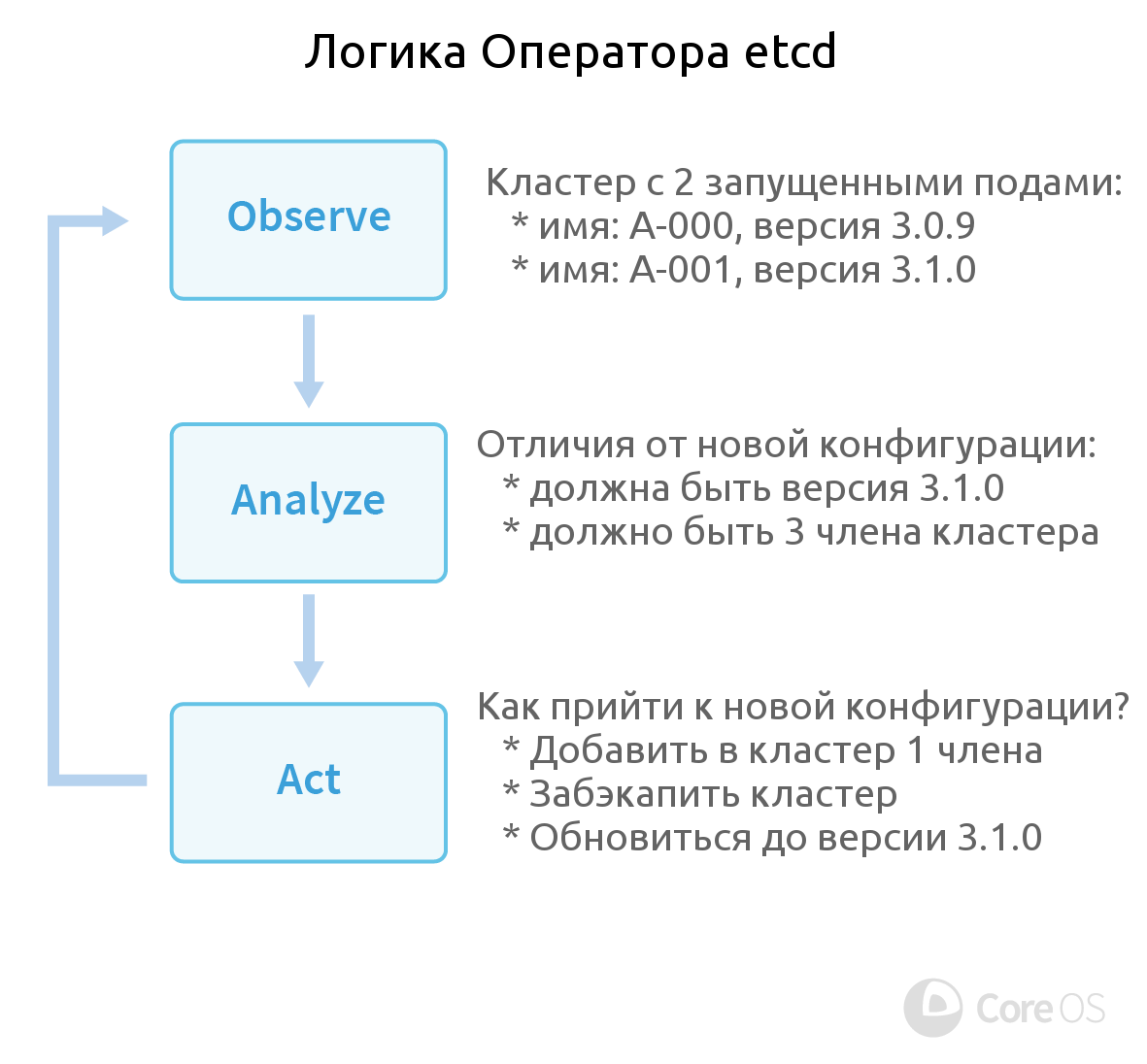
To implement this logic, the Operator has prepared the Create / Destroy (create and delete cluster members etcd) and Resize (change the number of cluster members) functions . Checking the correctness of its operability was checked using a utility created in the likeness of Netflix's Chaos Monkey, i.e. killing pods etcd randomly.
For the full operation of etcd, the Operator provides additional features: Backup (automatic and inconspicuous for users to create backup copies - in the config it’s enough to determine how often to store them and how many to store, and then restore data from them) and Upgrade (updating etcd installations without just me).
What does the work with the Operator look like?
$ kubectl create -f https://coreos.com/operators/etcd/latest/deployment.yaml
$ kubectl create -f https://coreos.com/operators/etcd/latest/example-etcd-cluster.yaml
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
etcd-cluster-0000 1/1 Running 0 23s
etcd-cluster-0001 1/1 Running 0 16s
etcd-cluster-0002 1/1 Running 0 8s
etcd-cluster-backup-tool-rhygq 1/1 Running 0 18s
The current status of etcd Operator is a beta version that requires Kubernetes 1.5.3+ and etcd 3.0+ to work. Source code and documentation (including instructions for use) are available on GitHub .
Another example of implementation from CoreOS, the Prometheus Operator , was created, but so far it is in the alpha version (not all planned functions are implemented).
Status and Prospects
5 months have passed since the announcement of Kubernetes Operators. Only two implementations are still available in the official CoreOS repository (for etcd and Prometheus). Both have not yet reached their stable versions, but commits in them are observed daily.
Developers expect "a future in which users install Postgres Operators, Cassandra Operators, or Redis Operators in their Kubernetes clusters and work with the scalable entities of these applications as easily as today with the deployment of replicas of stateless web applications." The first Operators from third-party developers really began to appear:
- Elasticsearch Operator from UPMC Enterprises;
- PostgreSQL Operator from Crunchy Data (announced at the end of March 2017.);
- Rook Operator from the authors of Ceph-based distributed storage system (Rook is in alpha status);
- Openstack Operators from SAP CCloud.
At the largest European free software conference FOSDEM, held in Brussels in February 2017, Josh Wood from CoreOS announced the Operators in a report (video available here!), Which should contribute to the popularity of this concept in the wider Open Source community.
PS Thank you for your interest in the article! Subscribe to our hub in order not to miss new materials and recipes for DevOps and GNU / Linux system administration - we will publish them regularly!