Accelerate unacceptable or get acquainted with SIMD
There is a class of tasks that cannot be accelerated by optimizing algorithms, but it is necessary to accelerate. In this almost deadlock situation, we are come to the aid of the developers of processors who have made teams that allow performing operations on a large amount of data in one operation. In the case of x86 processors, these are instructions made in the MMX, SSE, SSE2, SSE3, SSE4, SSE4.1, SSE4.2, AVX, AVX2, AVX512 extensions.
As a “guinea pig”, I took the following task:
In this form, the benchmark shows the following results:
Under the cut, I'll show you how to speed it up 5+ times.
For tests, I used a laptop with a processor
SIMD (Single Instruction, Multiple Data) - a single stream of commands, a multiple data stream. In x86 compatible processors, these commands were implemented in several generations of SSE and AVX processor extensions. Quite a lot of teams, a complete list of Intel can be found on the page software.intel.com/sites/landingpage/IntrinsicsGuide . In AVX desktop processors, extensions are not available, so let's focus on SSE.
To work with SIMD in C / C ++, you need to add to the code
It is also necessary for the compiler to say that it is necessary to use extensions, otherwise there will be errors of the form
It would be nice to reduce the number of iterations and make a comparison with several elements at once in one cycle. We open the site from Intel, select only the SSE extensions and the category "Compare". First on the list is a family of functions
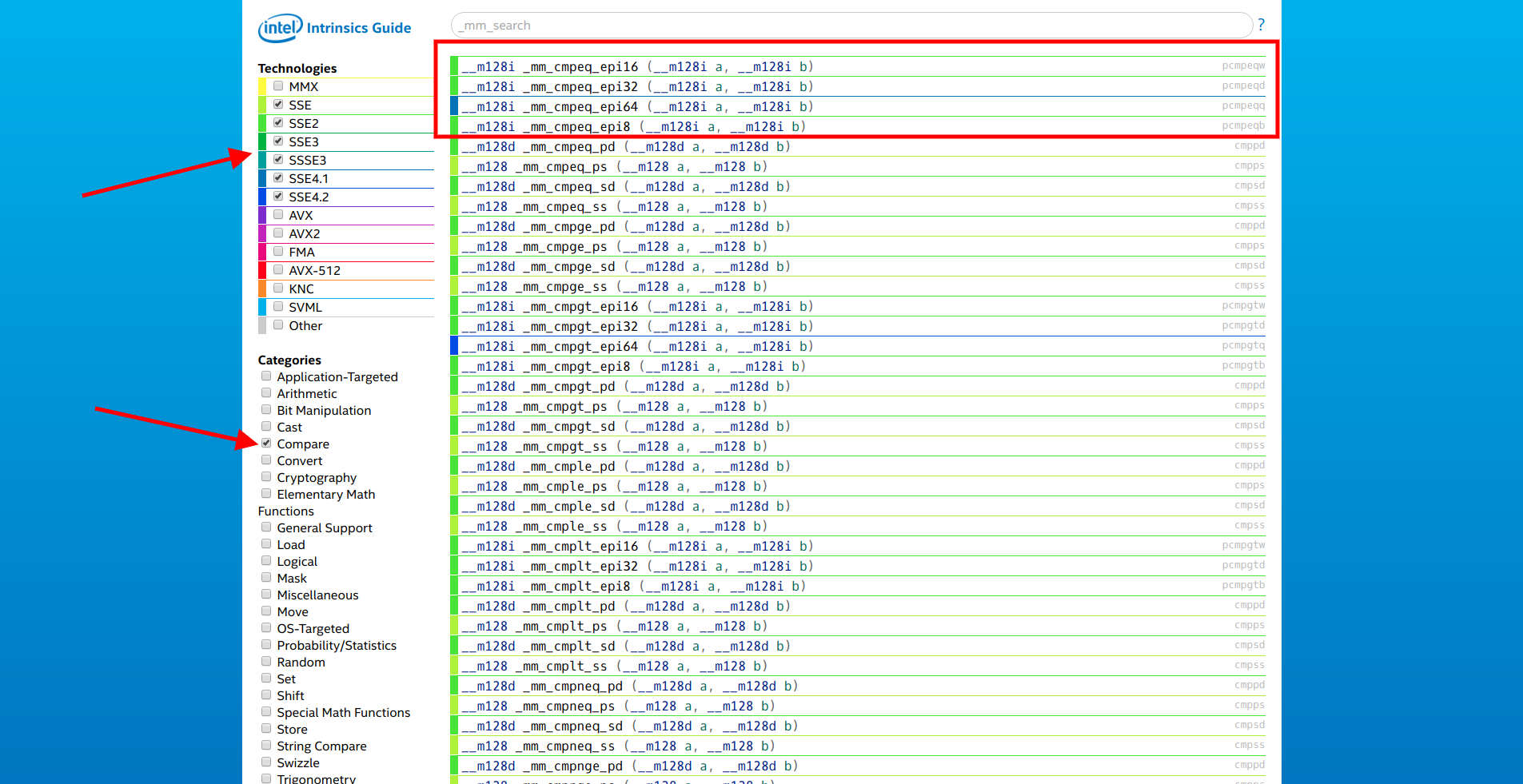
Open the documentation of the first of them and see:
So, the function
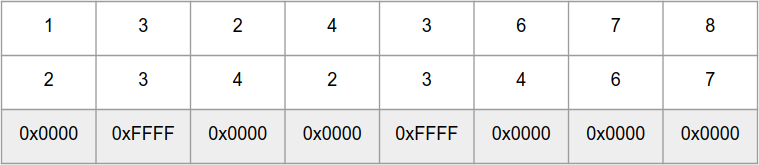
For a quick count of the number of bits in a number, there are functions
Now there is everything to start testing SIMD.
The benchmark showed the following results:
Only 2 times faster, and I promised in 5+.
In order to understand where there may be bottlenecks, you will have to go down to the assembly level.
It can be seen that a lot of processor commands take up copying the elements of the array in
Instead of the function
Benchmark showed an improvement of ~ 2 times:
The machine code looks like this:
SSE instructions work with 16 bytes of aligned memory. The _mm_loadu_si128 function avoids this restriction, but if you allocate memory for an array using a function
Such optimization gives a little more performance boost:
This was due to the savings of 3 instructions:
All of the above assembler listings were obtained after compiling with -O0. If you include -O3, the compiler optimizes the code quite well and there will be no such separation in time:
Part 2
As a “guinea pig”, I took the following task:
There is an unordered arr array with numbers of type uint16_t. It is necessary to find the number of occurrences of the number v in the array arr.A classic solution that works in linear time looks like this:
int64_t cnt = 0;
for (int i = 0; i < ARR_SIZE; ++i)
if (arr[i] == v)
++cnt;
In this form, the benchmark shows the following results:
------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------
BM_Count 2084 ns 2084 ns 333079
Under the cut, I'll show you how to speed it up 5+ times.
Test environment
For tests, I used a laptop with a processor
Intel(R) Core(TM) i7-8750H CPU @ 2.20GHz. As the compiler was clang version 6.0.0. To measure performance, I chose Google's libbenchmark . I took the size of the array 1024 elements, so as not to consider the rest of the elements in the classical way.What is SIMD
SIMD (Single Instruction, Multiple Data) - a single stream of commands, a multiple data stream. In x86 compatible processors, these commands were implemented in several generations of SSE and AVX processor extensions. Quite a lot of teams, a complete list of Intel can be found on the page software.intel.com/sites/landingpage/IntrinsicsGuide . In AVX desktop processors, extensions are not available, so let's focus on SSE.
To work with SIMD in C / C ++, you need to add to the code
#include<x86intrin.h>It is also necessary for the compiler to say that it is necessary to use extensions, otherwise there will be errors of the form
always_inline function '_popcnt32' requires target feature 'popcnt', but .... This can be done in several ways:- List all necessary features, for example
-mpopcnt - Specify the target processor architecture supporting the necessary feature, for example
-march=corei7 - To give the compiler the ability to use all the extensions of the processor on which the build takes place:
-march=native
What can be accelerated in the code of 3 lines?
for (int i = 0; i < ARR_SIZE; ++i)
if (arr[i] == v)
++cnt;
It would be nice to reduce the number of iterations and make a comparison with several elements at once in one cycle. We open the site from Intel, select only the SSE extensions and the category "Compare". First on the list is a family of functions
__m128i _mm_cmpeq_epi* (__m128i a, __m128i b). Open the documentation of the first of them and see:
Compare the results in dst.What you need! It remains only to turn
[]int16_tin __m128i. For this purpose, functions from the categories “Set” and “Load” are used. So, the function
_mm_cmpeq_epi16compares 8 int16_tnumbers in parallel in “arrays” aand b, and returns an “array” of numbers 0xFFFF - for identical elements and 0x0000 - for different: For a quick count of the number of bits in a number, there are functions
_popcnt32and _popcnt64that work with 32 and 64 bit numbers respectively. But, unfortunately, there is no function that can result _mm_cmpeq_epi16in a bit mask, but there is a function _mm_movemask_epi8that performs a similar operation for an “array” of 16 int8_tnumbers. But _mm_movemask_epi8it can be used for an “array” of 8 int16_tnumbers, just at the end the result will have to be divided by 2.Now there is everything to start testing SIMD.
Option 1
int64_t cnt = 0;
// Превращаем искомое значение в "массив" из 8 одинаковых элементовauto sseVal = _mm_set1_epi16(VAL);
for (int i = 0; i < ARR_SIZE; i += 8) {
// Для каждого блока из 8 элементов помещаем в переменную для сравненияauto sseArr = _mm_set_epi16(arr[i + 7], arr[i + 6], arr[i + 5], arr[i + 4], arr[i + 3], arr[i + 2], arr[i + 1], arr[i]);
// Получаем количество совпадений * 2
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
}
// Делим на 2
cnt >>= 1;
The benchmark showed the following results:
------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------
BM_Count 2084 ns 2084 ns 333079
BM_SSE_COUNT_SET_EPI 937 ns 937 ns 746435
Only 2 times faster, and I promised in 5+.
In order to understand where there may be bottlenecks, you will have to go down to the assembly level.
--------------- Копирование 8 элементов в sseArr ---------------
auto sseArr = _mm_set_epi16(arr[i + 7], arr[i + 6], arr[i + 5], arr[i + 4], arr[i + 3], arr[i + 2],
40133a: 48 8b 05 77 1d 20 00 mov 0x201d77(%rip),%rax # 6030b8 <_ZL3arr>
arr[i + 1], arr[i]);
401341: 48 63 8d 9c fe ff ff movslq -0x164(%rbp),%rcx
auto sseArr = _mm_set_epi16(arr[i + 7], arr[i + 6], arr[i + 5], arr[i + 4], arr[i + 3], arr[i + 2],
401348: 66 8b 54 48 0e mov 0xe(%rax,%rcx,2),%dx
40134d: 66 8b 74 48 0c mov 0xc(%rax,%rcx,2),%si
401352: 66 8b 7c 48 0a mov 0xa(%rax,%rcx,2),%di
401357: 66 44 8b 44 48 08 mov 0x8(%rax,%rcx,2),%r8w
40135d: 66 44 8b 4c 48 06 mov 0x6(%rax,%rcx,2),%r9w
401363: 66 44 8b 54 48 04 mov 0x4(%rax,%rcx,2),%r10w
arr[i + 1], arr[i]);
401369: 66 44 8b 1c 48 mov (%rax,%rcx,2),%r11w
40136e: 66 8b 5c 48 02 mov 0x2(%rax,%rcx,2),%bx
auto sseArr = _mm_set_epi16(arr[i + 7], arr[i + 6], arr[i + 5], arr[i + 4], arr[i + 3], arr[i + 2],
401373: 66 89 55 ce mov %dx,-0x32(%rbp)
401377: 66 89 75 cc mov %si,-0x34(%rbp)
40137b: 66 89 7d ca mov %di,-0x36(%rbp)
40137f: 66 44 89 45 c8 mov %r8w,-0x38(%rbp)
401384: 66 44 89 4d c6 mov %r9w,-0x3a(%rbp)
401389: 66 44 89 55 c4 mov %r10w,-0x3c(%rbp)
40138e: 66 89 5d c2 mov %bx,-0x3e(%rbp)
401392: 66 44 89 5d c0 mov %r11w,-0x40(%rbp)
401397: 44 0f b7 75 c0 movzwl -0x40(%rbp),%r14d
40139c: c4 c1 79 6e c6 vmovd %r14d,%xmm0
4013a1: 44 0f b7 75 c2 movzwl -0x3e(%rbp),%r14d
4013a6: c4 c1 79 c4 c6 01 vpinsrw $0x1,%r14d,%xmm0,%xmm0
4013ac: 44 0f b7 75 c4 movzwl -0x3c(%rbp),%r14d
4013b1: c4 c1 79 c4 c6 02 vpinsrw $0x2,%r14d,%xmm0,%xmm0
4013b7: 44 0f b7 75 c6 movzwl -0x3a(%rbp),%r14d
4013bc: c4 c1 79 c4 c6 03 vpinsrw $0x3,%r14d,%xmm0,%xmm0
4013c2: 44 0f b7 75 c8 movzwl -0x38(%rbp),%r14d
4013c7: c4 c1 79 c4 c6 04 vpinsrw $0x4,%r14d,%xmm0,%xmm0
4013cd: 44 0f b7 75 ca movzwl -0x36(%rbp),%r14d
4013d2: c4 c1 79 c4 c6 05 vpinsrw $0x5,%r14d,%xmm0,%xmm0
4013d8: 44 0f b7 75 cc movzwl -0x34(%rbp),%r14d
4013dd: c4 c1 79 c4 c6 06 vpinsrw $0x6,%r14d,%xmm0,%xmm0
4013e3: 44 0f b7 75 ce movzwl -0x32(%rbp),%r14d
4013e8: c4 c1 79 c4 c6 07 vpinsrw $0x7,%r14d,%xmm0,%xmm0
4013ee: c5 f9 7f 45 b0 vmovdqa %xmm0,-0x50(%rbp)
4013f3: c5 f9 6f 45 b0 vmovdqa -0x50(%rbp),%xmm0
4013f8: c5 f9 7f 85 80 fe ff vmovdqa %xmm0,-0x180(%rbp)
4013ff: ff
--------------- Подсчёт совпавших элементов ---------------
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
401400: c5 f9 6f 85 a0 fe ff vmovdqa -0x160(%rbp),%xmm0
401407: ff
401408: c5 f9 6f 8d 80 fe ff vmovdqa -0x180(%rbp),%xmm1
40140f: ff
401410: c5 f9 7f 45 a0 vmovdqa %xmm0,-0x60(%rbp)
401415: c5 f9 7f 4d 90 vmovdqa %xmm1,-0x70(%rbp)
40141a: c5 f9 6f 45 a0 vmovdqa -0x60(%rbp),%xmm0
40141f: c5 f9 6f 4d 90 vmovdqa -0x70(%rbp),%xmm1
401424: c5 f9 75 c1 vpcmpeqw %xmm1,%xmm0,%xmm0
401428: c5 f9 7f 45 80 vmovdqa %xmm0,-0x80(%rbp)
40142d: c5 f9 6f 45 80 vmovdqa -0x80(%rbp),%xmm0
401432: c5 79 d7 f0 vpmovmskb %xmm0,%r14d
401436: 44 89 b5 7c ff ff ff mov %r14d,-0x84(%rbp)
40143d: 44 8b b5 7c ff ff ff mov -0x84(%rbp),%r14d
401444: f3 45 0f b8 f6 popcnt %r14d,%r14d
401449: 49 63 c6 movslq %r14d,%rax
40144c: 48 03 85 b8 fe ff ff add -0x148(%rbp),%rax
401453: 48 89 85 b8 fe ff ff mov %rax,-0x148(%rbp)
It can be seen that a lot of processor commands take up copying the elements of the array in
sseArr.Option 2
Instead of the function
_mm_set_epi16, you can use _mm_loadu_si128. Function Description:Load 128-bits of integer data from unaligned memory into dstA pointer to memory is expected at the input, which hints at more optimal copying of data into a variable. Check:
int64_t cnt = 0;
auto sseVal = _mm_set1_epi16(VAL);
for (int i = 0; i < ARR_SIZE; i += 8) {
auto sseArr = _mm_loadu_si128((__m128i *) &arr[i]);
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
}
Benchmark showed an improvement of ~ 2 times:
------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------
BM_Count 2084 ns 2084 ns 333079
BM_SSE_COUNT_SET_EPI 937 ns 937 ns 746435
BM_SSE_COUNT_LOADU 454 ns 454 ns 1548455
The machine code looks like this:
auto sseArr = _mm_loadu_si128((__m128i *) &arr[i]);
401695: 48 8b 05 1c 1a 20 00 mov 0x201a1c(%rip),%rax # 6030b8 <_ZL3arr>
40169c: 48 63 8d bc fe ff ff movslq -0x144(%rbp),%rcx
4016a3: 48 8d 04 48 lea (%rax,%rcx,2),%rax
4016a7: 48 89 45 d8 mov %rax,-0x28(%rbp)
4016ab: 48 8b 45 d8 mov -0x28(%rbp),%rax
4016af: c5 fa 6f 00 vmovdqu (%rax),%xmm0
4016b3: c5 f9 7f 85 a0 fe ff vmovdqa %xmm0,-0x160(%rbp)
4016ba: ff
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
4016bb: c5 f9 6f 85 c0 fe ff vmovdqa -0x140(%rbp),%xmm0
4016c2: ff
4016c3: c5 f9 6f 8d a0 fe ff vmovdqa -0x160(%rbp),%xmm1
4016ca: ff
4016cb: c5 f9 7f 45 c0 vmovdqa %xmm0,-0x40(%rbp)
4016d0: c5 f9 7f 4d b0 vmovdqa %xmm1,-0x50(%rbp)
4016d5: c5 f9 6f 45 c0 vmovdqa -0x40(%rbp),%xmm0
4016da: c5 f9 6f 4d b0 vmovdqa -0x50(%rbp),%xmm1
4016df: c5 f9 75 c1 vpcmpeqw %xmm1,%xmm0,%xmm0
4016e3: c5 f9 7f 45 a0 vmovdqa %xmm0,-0x60(%rbp)
4016e8: c5 f9 6f 45 a0 vmovdqa -0x60(%rbp),%xmm0
4016ed: c5 f9 d7 d0 vpmovmskb %xmm0,%edx
4016f1: 89 55 9c mov %edx,-0x64(%rbp)
4016f4: 8b 55 9c mov -0x64(%rbp),%edx
4016f7: f3 0f b8 d2 popcnt %edx,%edx
4016fb: 48 63 c2 movslq %edx,%rax
4016fe: 48 03 85 d8 fe ff ff add -0x128(%rbp),%rax
401705: 48 89 85 d8 fe ff ff mov %rax,-0x128(%rbp)
Option 3
SSE instructions work with 16 bytes of aligned memory. The _mm_loadu_si128 function avoids this restriction, but if you allocate memory for an array using a function
aligned_alloc(16, SZ), you can directly pass the address to the SSE instruction:int64_t cnt = 0;
auto sseVal = _mm_set1_epi16(VAL);
for (int i = 0; i < ARR_SIZE; i += 8) {
auto sseArr = *(__m128i *) &allignedArr[i];
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
}
Such optimization gives a little more performance boost:
------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------
BM_Count 2084 ns 2084 ns 333079
BM_SSE_COUNT_SET_EPI 937 ns 937 ns 746435
BM_SSE_COUNT_LOADU 454 ns 454 ns 1548455
BM_SSE_COUNT_DIRECT 395 ns 395 ns 1770803
This was due to the savings of 3 instructions:
auto sseArr = *(__m128i *) &allignedArr[i];
40193c: 48 8b 05 7d 17 20 00 mov 0x20177d(%rip),%rax # 6030c0 <_ZL11allignedArr>
401943: 48 63 8d cc fe ff ff movslq -0x134(%rbp),%rcx
40194a: c5 f9 6f 04 48 vmovdqa (%rax,%rcx,2),%xmm0
40194f: c5 f9 7f 85 b0 fe ff vmovdqa %xmm0,-0x150(%rbp)
401956: ff
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
401957: c5 f9 6f 85 d0 fe ff vmovdqa -0x130(%rbp),%xmm0
40195e: ff
40195f: c5 f9 6f 8d b0 fe ff vmovdqa -0x150(%rbp),%xmm1
401966: ff
401967: c5 f9 7f 45 d0 vmovdqa %xmm0,-0x30(%rbp)
40196c: c5 f9 7f 4d c0 vmovdqa %xmm1,-0x40(%rbp)
401971: c5 f9 6f 45 d0 vmovdqa -0x30(%rbp),%xmm0
401976: c5 f9 6f 4d c0 vmovdqa -0x40(%rbp),%xmm1
40197b: c5 f9 75 c1 vpcmpeqw %xmm1,%xmm0,%xmm0
40197f: c5 f9 7f 45 b0 vmovdqa %xmm0,-0x50(%rbp)
401984: c5 f9 6f 45 b0 vmovdqa -0x50(%rbp),%xmm0
401989: c5 f9 d7 d0 vpmovmskb %xmm0,%edx
40198d: 89 55 ac mov %edx,-0x54(%rbp)
401990: 8b 55 ac mov -0x54(%rbp),%edx
401993: f3 0f b8 d2 popcnt %edx,%edx
401997: 48 63 c2 movslq %edx,%rax
40199a: 48 03 85 e8 fe ff ff add -0x118(%rbp),%rax
4019a1: 48 89 85 e8 fe ff ff mov %rax,-0x118(%rbp)
Conclusion
All of the above assembler listings were obtained after compiling with -O0. If you include -O3, the compiler optimizes the code quite well and there will be no such separation in time:
------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------
BM_Count 129 ns 129 ns 5359145
BM_SSE_COUNT_SET_EPI 70 ns 70 ns 9936200
BM_SSE_COUNT_LOADU 49 ns 49 ns 14187659
BM_SSE_COUNT_DIRECT 53 ns 53 ns 13401612
Benchmark code
#include<benchmark/benchmark.h>#include<x86intrin.h>#include<cstring>#define ARR_SIZE 1024#define VAL 50static int16_t *getRandArr(){
auto res = newint16_t[ARR_SIZE];
for (int i = 0; i < ARR_SIZE; ++i) {
res[i] = static_cast<int16_t>(rand() % (VAL * 2));
}
return res;
}
staticauto arr = getRandArr();
static int16_t *getAllignedArr(){
auto res = aligned_alloc(16, sizeof(int16_t) * ARR_SIZE);
memcpy(res, arr, sizeof(int16_t) * ARR_SIZE);
returnstatic_cast<int16_t *>(res);
}
staticauto allignedArr = getAllignedArr();
staticvoidBM_Count(benchmark::State &state){
for (auto _ : state) {
int64_t cnt = 0;
for (int i = 0; i < ARR_SIZE; ++i)
if (arr[i] == VAL)
++cnt;
benchmark::DoNotOptimize(cnt);
}
}
BENCHMARK(BM_Count);
staticvoidBM_SSE_COUNT_SET_EPI(benchmark::State &state){
for (auto _ : state) {
int64_t cnt = 0;
auto sseVal = _mm_set1_epi16(VAL);
for (int i = 0; i < ARR_SIZE; i += 8) {
auto sseArr = _mm_set_epi16(arr[i + 7], arr[i + 6], arr[i + 5], arr[i + 4], arr[i + 3], arr[i + 2],
arr[i + 1], arr[i]);
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
}
benchmark::DoNotOptimize(cnt >> 1);
}
}
BENCHMARK(BM_SSE_COUNT_SET_EPI);
staticvoidBM_SSE_COUNT_LOADU(benchmark::State &state){
for (auto _ : state) {
int64_t cnt = 0;
auto sseVal = _mm_set1_epi16(VAL);
for (int i = 0; i < ARR_SIZE; i += 8) {
auto sseArr = _mm_loadu_si128((__m128i *) &arr[i]);
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
}
benchmark::DoNotOptimize(cnt >> 1);
}
}
BENCHMARK(BM_SSE_COUNT_LOADU);
staticvoidBM_SSE_COUNT_DIRECT(benchmark::State &state){
for (auto _ : state) {
int64_t cnt = 0;
auto sseVal = _mm_set1_epi16(VAL);
for (int i = 0; i < ARR_SIZE; i += 8) {
auto sseArr = *(__m128i *) &allignedArr[i];
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
}
benchmark::DoNotOptimize(cnt >> 1);
}
}
BENCHMARK(BM_SSE_COUNT_DIRECT);
BENCHMARK_MAIN();
Part 2