A simple explanation of simplicity. Chapter 1: Theoretically Easy
- Tutorial
Simple explanation of simplicity

KDPV with areas which we should visit to answer the MAIN question.
Foreword
I often heard the advice: make it easier.
What does simple mean? When we say that object X is simple, what are our expectations for X? When we say that something is simpler than the other - how do we evaluate it?
Which is simpler:
“A small sentence of five words” or the word “deoxyribonucleic”?
“6 * 5” or “481”?
Or this:
You have a settings screen. Five of them refer to the chart, the other five to notifications. Do you need to create separate items "schedule" and "notification" in the main menu? Or leave all 10 points on one screen? What will be easier for the user?
You can say it is subjective. That this is determined by a certain “sense of simplicity”, that for one person something can be simple, and for another, difficult.
Okay, then tell me, why does the teacher spend time trying to explain something easier? Why edit the text, trying to make it easier? Why do programmers spend time reviewing code trying to figure out which solution is easier to understand and extend?
If simplicity somehow correlates with our assessment, then the best strategy is persuasion. Let's make readers believe that the text is simple. Or colleagues, believed that our solution is not difficult.
Will this qualitatively change their interaction with the result of our work?
Not.
Your text will not be easier to read because it is considered simple. It will not be easier to work with your code, even if everyone around you thinks that its complexity is the same as that of a stool.
If you were told at the interview that the company has clean code and good documentation and you believe it, then it will not affect the simplicity of working with the code.
Moreover, even if the entire department believes that the code is written well and the docks are there, this will not affect the result either. Their belief about their code may be wrong.
If the code was spaghetti, it would be spaghetti. If the “documentation” is comments of the format “here I have added 2 numbers” - the code has no documentation.
And no desires, confidence, etc. will not help here.
This does not work for about the same reason (ru , en ) , according to which you cannot give 5 to your friends on 1 cupcake, if you have only 2 boxes of 2 cupcakes in each. Even if you will meditate for a year with the whole company on the fact that 2 + 2 = 5, the sad situation with cupcakes will not change it.
Again. There is an object, and some of its characteristics may make you think ( ru ) that it is simple. And if tomorrow your assessment changes and stops at the “difficult” mark, the object will not care.
It can be concluded that simplicity or complexity does not depend on our expectations. Rather, the object determines what characteristic we give it.
I wanted to understand what object I expect to see in reality, if I am convinced (ru ) that it is simple. Conversely, what characteristics of a real object make me think that it is simple.
What for? Well, maybe this will make my life easier?)
If you are reading for the first time
Statistics
Время чтения: ~30 минут.
Количество знаков: ~ 25k.
Количество знаков: ~ 25k.
Как читать статью
Общее
У меня нет никакого авторитета(ru) в ваших глазах. Я намеренно не указываю информацию о себе. Я бы хотел, чтобы вы читали эту статью так, будто ее написал студент первого курса. В каком-то смысле так и есть.
Если вы нашли непонятный или спорный момент — напишите об этом. Так вы поможете улучшить эту статью.
И ни в коем случае не верьте мне. Я не хочу, чтобы мои слова убеждали вас в моей правоте. Я хочу, чтобы их смысл убедил вас в его истинности.
Если вы нашли непонятный или спорный момент — напишите об этом. Так вы поможете улучшить эту статью.
И ни в коем случае не верьте мне. Я не хочу, чтобы мои слова убеждали вас в моей правоте. Я хочу, чтобы их смысл убедил вас в его истинности.
Об условных обозначениях
- Оглавление. Каждая глава будет начинаться с него. В нем кратко перечислены вопросы, которые рассматриваются в главе, и даны ссылки для навигации на соответствующие подразделы.
- Ссылки на внешние ресурсы. Они представлены в виде *слово или фраза*(ссылки с laguage code) или обычных ссылок. Я старался сделать так, чтобы у вас был выбор, читать русский или английский источник. К сожалению, у меня не всегда получалось найти оба. Особенно это будет заметно во второй главе. Рунет беден на актуальную информацию по нейробиологии.
- Спойлер «Кратко». Находится сразу после названия подраздела главы. Его предназначение — упростить работу со статьей в случае, если вы ее уже прочитали. Вы можете использовать его для того, чтобы быстро ознакомиться со статьей. Но будьте осторожны! Во-первых, вы можете не понять, что там написано, без прочтения самого подраздела. Это сжатый тезиз, а не путь(ru, en) до него. Во вторыx, что еще более опасно — вам может показаться, что вы все поняли. Что такое ложное понимание и почему оно возникает будет объяснено в следующих главах.
- Спойлер «IT'S MATHEMATICS TIME». Используется, чтобы не пугать вас математическими выкладками. Он дублирует информацию, которая до него была представлена в виде текста, но более формальным образом.
Общая информация
О серии
Простое объяснение просты — это серия статей, объединенных общим вопросом: «Что такое „просто“ с точки зрения человека?»
На данный момент планируется 3 главы:
Это не полный список вопросов, на которые я бы хотел найти ответ. Но начать я хочу с них.
Отдельно выйдет статья о том, почему я вообще занимаюсь этим вопросом. Скажем так, о мотивации автора, и о том, как он видит эту серию. Эта статья будет написана после первых трех глав.
На данный момент планируется 3 главы:
- Теоретически просто — эта глава посвящена формулировке вопроса и основным определениям с ним связанным. Вы находитесь здесь.
- Machine Ex Homo — глава, в которой мы посмотрим на наше сознание, начиная с верхнего поведенческого уровня и заканчивая нейронными связями в нашем мозгу. Глава написана и проходит редактуру.
- Просто чтение — посвящена чтению людьми любых моделей, будь то схемы, код, графы, текст. Это будет первая практическая глава в нашей серии, здесь мы будем применять наши знания, и смотреть на то, как должна быть структурирована информация для облегчения ее понимания. Глава в процессе написания.
Это не полный список вопросов, на которые я бы хотел найти ответ. Но начать я хочу с них.
Отдельно выйдет статья о том, почему я вообще занимаюсь этим вопросом. Скажем так, о мотивации автора, и о том, как он видит эту серию. Эта статья будет написана после первых трех глав.
Почему эта статья появилась?
Я много раз встречал такие фразы: «Напиши текст проще» или «Сделай решение проще».
Иногда я слышал слово «просто» в качестве аргумента в споре: «Я сделал так, потому что это проще!». Очень часто оппоненты пытались доказать, что «У нихбольше проще», и приводили к этому какие-то странные аргументы.
Но когда я спрашивал людей, что по их мнению значит «просто», я слышал:
«Это субъективно». Или «Это common sense». Или «Ну, для каждого человека по-разному».
Меня приводило в замешательство то, что довольно умные люди очень долго спорят о вещи, которую они не могут точно определить и считают субъективной. Ведь если это вкусовщина, как например музыкальные предпочтения, то зачем они тратят на это время? Повторюсь, это были умные люди, и на холивары о музыкальных предпочтениях друг друга они время не тратили.
Я много об этом думал, и спустя год мне пришла в голову одна простая мысль: что если простота — это характеристика объекта, которую все же можно измерить? Это бы могло разрешить все споры и сэкономить огромное количество времени. И заверте…
Иногда я слышал слово «просто» в качестве аргумента в споре: «Я сделал так, потому что это проще!». Очень часто оппоненты пытались доказать, что «У них
Но когда я спрашивал людей, что по их мнению значит «просто», я слышал:
«Это субъективно». Или «Это common sense». Или «Ну, для каждого человека по-разному».
Меня приводило в замешательство то, что довольно умные люди очень долго спорят о вещи, которую они не могут точно определить и считают субъективной. Ведь если это вкусовщина, как например музыкальные предпочтения, то зачем они тратят на это время? Повторюсь, это были умные люди, и на холивары о музыкальных предпочтениях друг друга они время не тратили.
Я много об этом думал, и спустя год мне пришла в голову одна простая мысль: что если простота — это характеристика объекта, которую все же можно измерить? Это бы могло разрешить все споры и сэкономить огромное количество времени. И заверте…
Почему твое простое объяснение занимает 3 главы? Нельзя было покороче?
Потому что реальность — сложна. И сложность этой статьи напрямую зависит от сложности той части реальности, которую она описывает.
Эта серия — результат тысяч часов работы по поиску и объединению информации. А так же сотен тысяч часов, потраченных людьми, чьи работы я для нее использовал.
На прочтение всей серии вы потратите пару часов. Десяток, если честно будете переходить по всем ссылкам.
Я уменьшил количество времени и сил, которое вы потратите для получения ответа на наш вопрос в сотни раз. И сэкономил вам время, которое ушло на то, чтобы правильно его задать.
Я не уверен, что это самое лучшее объяснение из возможных. Моя работа еще не закончена. Возможно, в процессе я пойму как его улучшить. На данный момент — это самое простое объяснение которое у меня есть.
Эта серия — результат тысяч часов работы по поиску и объединению информации. А так же сотен тысяч часов, потраченных людьми, чьи работы я для нее использовал.
На прочтение всей серии вы потратите пару часов. Десяток, если честно будете переходить по всем ссылкам.
Я уменьшил количество времени и сил, которое вы потратите для получения ответа на наш вопрос в сотни раз. И сэкономил вам время, которое ушло на то, чтобы правильно его задать.
Я не уверен, что это самое лучшее объяснение из возможных. Моя работа еще не закончена. Возможно, в процессе я пойму как его улучшить. На данный момент — это самое простое объяснение которое у меня есть.
Chapter 1. Theoretically easy
In this chapter, we will look at the following topics:
- How to ask questions, and why is it important? ( A sequence of questions )
- How are the objects, actions and their performers? ( Simplicity in action , Objective subjectivism )
- How to determine the complexity of the action? ( Simplicity in action . Probably simple. )
- What are systems and their models and why is this a convenient way to describe objects? ( Systematics Modeling )
At the end of the chapter we will talk a little about Occam's Razor ( Blade Runner ). An article on simplicity would look weird without mentioning this principle.
1.1 The sequence of questions
Briefly
Questions that do not limit possible answers are useless.
The “simple” characteristic can have two meanings:
1) Elementary
2) Simple for some actions
We are interested in the second.
Our next question: How to evaluate the complexity of the action and how to connect it with the object?
The “simple” characteristic can have two meanings:
1) Elementary
2) Simple for some actions
We are interested in the second.
Our next question: How to evaluate the complexity of the action and how to connect it with the object?
Our research begins with a question. To ask a question correctly is very important. A small digression:
- Okay, Deep Thought, what is the MAIN CONDITION of SIMPLICITY?
- Need to think.
...
...
N million years later ...
-

// Based on one beautiful book
. We have an answer, but it gives nothing. All information about him is in the question, and the question was not too specific. We cannot prove that
 - really the main condition and we can not show the opposite.
- really the main condition and we can not show the opposite. The question should limit the scope of possible answers.
“What is simple?” Is not a very specific question. Let's clarify it. At the beginning of the article we have already done a part of this path:
When we say that object X is simple, what do we expect from it?
According to my observations there are two main cases:
- X is an object that does not break into its component parts. Here the word "simple" can be replaced by the word "elementary."

This is a brick. And, in a sense, he is simple. - X is easy to do with the action we want. For example - a sofa is simple if we want to lie on it, and difficult if we need to raise it to the ninth floor.
The case when the object is elementary is understandable. But what if we are interested in complexity in the context of action?
Let's think about it. We perform actions with the object.
There are three main entities in this sentence:
- Actions - a description of what is happening.
- Performers actions - hiding under the word we.
- Objects are what the action is done with.
Then we are interested in the following questions:
- How to evaluate the simplicity of the action depending on the object with which it is performed?
- What is the relationship between an action and its performer?
We will answer them below.
1.2 Simplicity in action
Briefly
Мы действуем по аналогии с алгоритмической сложностью.
Сложность нашего действия — сумма сложностей вложенных в него действий.
Последовательность действий называется алгоритмом.
У действия есть результат — это изменение состояния системы, в которой было совершено действие.
Действия и объекты можно связать между собой с помощью понятия интерфейса. Интерфейс — это объект, который хранит информацию о том, какие действия возможны с объектом, его реализующим.
В отличии от алгоритмической сложности, мы не можем просто найти элементарные операции, и нам придется учитывать исполнителя наших действий.
Наш следующий вопрос — каково влияние исполнителя на действия?
Сложность нашего действия — сумма сложностей вложенных в него действий.
Последовательность действий называется алгоритмом.
У действия есть результат — это изменение состояния системы, в которой было совершено действие.
Действия и объекты можно связать между собой с помощью понятия интерфейса. Интерфейс — это объект, который хранит информацию о том, какие действия возможны с объектом, его реализующим.
В отличии от алгоритмической сложности, мы не можем просто найти элементарные операции, и нам придется учитывать исполнителя наших действий.
Наш следующий вопрос — каково влияние исполнителя на действия?
Let's look at the action.
Ease of action is something that depends on its complexity. The more complex the action, the less simple it is - this is obvious. We come to the following question:
How to determine the complexity of the action?
What can we do with the action? We can break it into a sequence of others! The action “read the article” can be divided into: “read the first paragraph”, “read the second”, etc. They, in turn, should be decomposed as “read the first sentence”, “read the second” ...

In a similar way, we get to actions whose difference in complexity will not be important for us and will not depend on the object with which it is performed (for example, read the letter). We call such actions elementary.
Then the complexity of the action for a particular object can be measured in elementary actions into which it is divided.
Actions are equivalent when they are broken up into identical sequences of actions.
What else characterizes the action?
Algorithm
Description of the sequence of actions that represent another action, I will call it an algorithm ( ru , en ) .
The algorithm can be described collectively, for example:
Reading: read sentences until the text runs out.
In this form, reading is applicable to many texts.
However, as you understand, the number of actions “read sentences” will depend on the number of sentences in the text.
Result
Actions are performed for a reason; they lead to something. So let our actions have results!
The result is a change in the state of the system in which the action took place. You have pressed the switch, and its transition to the “on” state and the lights in the kitchen are the result of this action. You have read the word, and the result is a change in the state of your brain.
Different actions can lead to the same result.
Connection with objects
Let's go back to the objects. As we have said, you can perform different actions with them. We need a way to understand for which actions this or that entity is “intended”.
I will start with an example.
- And how do I carry this suitcase?
- He has a pen on the side!
The handle is a strip of leather on the outside of the suitcase, which was nailed with rivets. But in this case we do not care. We are worried that there is an object on the suitcase that can be held.
All such objects we will call handles. They can be at the cup, door, suitcase or bucket.
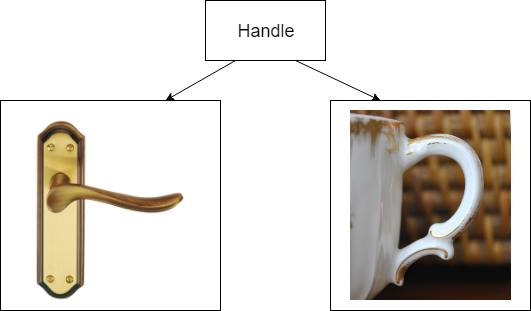
We have come to the conclusion that we have two descriptions of the handle from the example:
- Like strips of leather, riveted on a suitcase.
- As a concept of the subject for which you can take.
The first is the implementation description ( en ) .
The second is the interface description.
An interface is an object that stores information about how you can interact with an object that implements it.
What are they needed for? It's simple: most often we are not interested in how the object is implemented.
When we want to turn on the light - we are looking for the switch, and for us it doesn’t matter how it works, we only care that we can switch its on / off state.
When we see a button, we already know that it can be pressed.
When we are told that there is a pen somewhere, we already know that we can take it.
And it is very convenient.
Results
An action is a sequence of other actions that define its algorithm. The result of the action is some kind of system change.
The complexity of the action is equal to the number of elementary actions of its algorithm for a particular object.
The relationship between objects and actions defines the object's interface. It stores information about what actions you can take with the object.
Our next question:
What is the connection between an action and its performer?
1.3 Objective subjectivism
Briefly
Чтобы правильно оценить сложность объекта в ситуации с разными исполнителями действий, мы можем для каждого конкретного исполнителя или группы исполнителей задать свои действия.
Наш следующий вопрос — как теперь считать сложность?
Наш следующий вопрос — как теперь считать сложность?
You may reasonably note:
“But if you perform the same actions, the results may be different! If a professor of physics can fluently read an article on string theory and understand everything, then I will not achieve anything with the same approach. And to get a similar result, I’ll have to search for definitions through the word, read other articles and spend a lot more action. ”
This is a good point. I have an answer for it.
Like any task, ours have initial conditions. If you change them - you change the task itself. And this leads to the fact that its implementation requires different actions.
You are reading an article. Suppose that after reading a couple of pages, you put it off. Now, in order for the article to be read, you need to spend less action. But did this change the complexity of the article itself? Not. Changed the action that you will do with it. It was: “to read the article,” it became: “to scroll through the article to the point where I finished, and to finish reading to the end.
What should we do with actions then? We will fix the desired result. As we remember, you can come to him in different ways.
Further, we can break the performers into approximately identical groups. There are a limited number of such groups if we do not have an infinite number of performers.
Now for each group, we describe the actions that will lead it to the desired result.
We received a set of actions for each of the groups of performers. But now what to do with the complexity?
1.4 Probably easy
Briefly
We have a set of actions. Each of them belongs to a specific group of performers. We know how to calculate the complexity of each of these actions for each specific object.
But what if we try to set the probability of the performer hitting one of the groups?
The task turns into a classical task on a theorever.
We have the magnitude of the complexity of action. We have probabilities of performing each of the actions by a random person.
We can find the “mean” of our complexity. This is the so-called mathematical expectation ( ru ) . For this, we need to multiply each complexity of the action with the object by the probability of its occurrence.
Where to get these probabilities and how to break the performers into groups, if you don’t know yet who exactly will perform the actions with the object? Good question!
His consideration is beyond the scope of this article, but I will give one interesting example in my opinion.
You are the author. And your task is to write an article on the site which has thematic sections. When you post an article, it will be displayed in the general tape and the tape of the “own” section. The sections have subscribers, they make up a certain percentage of the site’s audience. General tape is shown to all. We will assume that the section subscribed understands its topic, and those not signed do not.
Let our paper be on physics. We analyzed the audience and know that the “physics” section was signed by 3% of the site’s audience. We learned that the probability that the subscriber of this section will go into an article from it is 80%. We also learned that the probability of visiting an article from a general tape is 5%.
Who is our potential reader and should we “optimize” an article for a person who is not subscribed to the “physics” section? In other words, what is the likelihood that our article is read by a person versed in physics?
So, attention, this probability is equal to ... About 33%.
Slightly more than two thirds of our potential readers do not understand physics, and we should take this into account.
How did it happen? In short: a high probability of visiting an article by a person versed in physics is compensated for by their small amount. A small chance of visiting the article from the general tape begins to play a significant role in our assessment. Want to know more about this? Here is a link to a good article about the Bayes theorem ( ru , en ) .
If you want to check:
IT'S MATHEMATICS TIME:
На раздел физика подписано 3% аудитории, 80% из них посетит нашу статью. Следовательно вероятность посещения статьи физиком — 0.03*0.8 = 0.024 = 2.4%.
Вероятность того, что какой-то человек посетит статью = вероятность посещения из общей ленты плюс вероятность посещения статьи из раздела. В общей ленте так же находятся наши «оставшиеся» физики, не посетившие статью в разделе. Тогда мы получаем, что вероятность посещения статьи физиком из общей ленты = 0.05*0.03*0.2 = 0.0003, или 0.03%.
Всего из общей ленты было 5% посетителей, значит из них не физиков 4.97%
Теперь находим отношение физиков к общему числу посетителей. Для этого делим всех физиков (2.4% + 0.03%) на общее число посетителей.
(2.4+0.03)/(2.4+4.97+0.03) = 0.328.
Ответ: ~33%
Вероятность того, что какой-то человек посетит статью = вероятность посещения из общей ленты плюс вероятность посещения статьи из раздела. В общей ленте так же находятся наши «оставшиеся» физики, не посетившие статью в разделе. Тогда мы получаем, что вероятность посещения статьи физиком из общей ленты = 0.05*0.03*0.2 = 0.0003, или 0.03%.
Всего из общей ленты было 5% посетителей, значит из них не физиков 4.97%
Теперь находим отношение физиков к общему числу посетителей. Для этого делим всех физиков (2.4% + 0.03%) на общее число посетителей.
(2.4+0.03)/(2.4+4.97+0.03) = 0.328.
Ответ: ~33%
We talked about the actions and those who perform them. Time to go to the last question.
We often used the word object, but it does not give us any information about it. We need some kind of description, abstract enough so that we can apply it to many entities, and informative enough so that we can work with it.
How to describe the objects with which we work?
1.5 Systematization modeling
Briefly
Мы вводим понятие системы и модели системы.
Система — это совокупность компонент, которыми могут быть определенные заранее элементы и построенные с их помощью подсистемы.
Модель — это отображение системы, базирующееся на другом множестве элементов (терминов модели).
Система — это совокупность компонент, которыми могут быть определенные заранее элементы и построенные с их помощью подсистемы.
Модель — это отображение системы, базирующееся на другом множестве элементов (терминов модели).
I decided to try to summarize texts, tables, charts ... etc. But how to do that?
Let's go back a step and see how their “creation” happens, maybe it will help us.
We write the text. We have a certain idea, we formulate it in words and write it down. In this case, the idea can be not only in the form of other words. We can describe a picture, music, mathematical objects.
I am writing code. I have requirements that I “translate” into code. They can be expressed verbally or represent an image, such as a sketch of the interface.
We make the scheme. We have some objects, the relationship between which we describe this scheme.
There is something in common in these processes. We have some kind of system. We translate it into another system, without necessarily using the same “terms”.
It seems to me that the word “Modeling” is suitable for describing this process.
So, a model is a system that describes another system using specified notation (terms).
This definition pushes a reasonable question:
What is a system?
A system is a collection of some components. It is given by the set of their possible states and their current state. Components of the system I will often call objects.
They can be elements (something defined in advance) and other systems consisting of these elements. There are still such things as connections — they appear when we want to limit or determine the possible states of one object depending on others.
Example:
There is a system of 2 coins. One of them is “eagle”, the other is “tails”.
"Eagle" and "tails" are the elements of our system.
A coin is a subsystem that consists of the elements "tail" and "tails" and can be in one of these states. For the first coin:
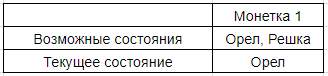
Suppose that we cannot throw coins and thus make changes to the system. In this case, our system can be described as:

If we can throw coins, then our system is described as:

There are dependencies between some systems. Suppose the state of the second coin cannot be equal to the state of the first one.
Then the set of possible states of coin 2, taking into account our limitation, is all previous possible states, besides the one in which coin 1 is located.

In this case we can say that the state of coin 2 determines the state of coin 1.
Now let's see what happens if we change many possible states of coins by adding an “edge” there.
We can make all the pairs for the states of coins 1 and 2.
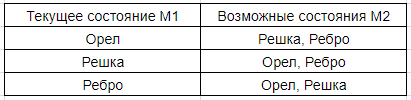
In this case, we are talking about limiting the possible states of the coin 2.
UPDATE:
I created a java coin implementation example. Here is the repository . In addition, it shows how to count the difficulty if you take the coin toss for an elementary action.
IT'S MATHEMATICS TIME: — система.
— система.
 — состояние системы.
— состояние системы.
 — множество возможных состояний.
— множество возможных состояний.
 — текущее состояние.
— текущее состояние.
Статический случай:
Если — элемент, то он остается как есть, т.к. по определению не разбивается.
— элемент, то он остается как есть, т.к. по определению не разбивается.
Динамический случай: .
.
Про связи.
Функция состояния некоторой системы от других систем может быть однозначной, и тогда мы говорим о том, что состояние определено состояниями других систем, или многозначной и тогда мы говорим об ограничении состояний системы.
Переводя в теорию множеств:
Есть некоторое множество систем состояние которых определяет множество возможных состояний
состояние которых определяет множество возможных состояний  .
.
Возьмем декартово произведение — мы получим множество упорядоченных наборов состояний
— мы получим множество упорядоченных наборов состояний  .
.
Положим .
.
Возьмем множество упорядоченных пар .
.
Если для одинаковых одинаковы
одинаковы  — состояние определено .
— состояние определено .
Если для одинаковых возможны различные , то состояние ограничено.
P.S.
Кстати, можно доказать, что имея всего лишь два элемента (0 и 1, например), вы можете описать любую систему, количество объектов которой — счетно. При условии, что вы можете неограниченно создавать последовательности элементов. На мой взгляд это интересный факт.
Я вдохновлялся статьями по теории систем(ru) и абстрактными автоматами(ru). Этот вариант математического описания понятия «система» чуть короче, чем найденные мною.
— система. — состояние системы. — множество возможных состояний. — текущее состояние. Статический случай:
Если
— элемент, то он остается как есть, т.к. по определению не разбивается.Динамический случай:
. Про связи.
Функция состояния некоторой системы от других систем может быть однозначной, и тогда мы говорим о том, что состояние определено состояниями других систем, или многозначной и тогда мы говорим об ограничении состояний системы.
Переводя в теорию множеств:
Есть некоторое множество систем
состояние которых определяет множество возможных состояний . Возьмем декартово произведение
— мы получим множество упорядоченных наборов состояний . Положим
. Возьмем множество упорядоченных пар
. Если для одинаковых
одинаковы — состояние определено . Если для одинаковых
возможны различные , то состояние ограничено.P.S.
Кстати, можно доказать, что имея всего лишь два элемента (0 и 1, например), вы можете описать любую систему, количество объектов которой — счетно. При условии, что вы можете неограниченно создавать последовательности элементов. На мой взгляд это интересный факт.
Я вдохновлялся статьями по теории систем(ru) и абстрактными автоматами(ru). Этот вариант математического описания понятия «система» чуть короче, чем найденные мною.
Back to the models
Model we call another system, which is the first display. In general, it can be built from other elements. The system model is a map, the system itself is a territory ( en ) . No one bothers to build models of other models. You can draw a map card ( en ) .
Let's try building models.
Let's start with the classics: black box.
You have: “input”, “exit” and box. You designate the components you would like to change to get the result as “input”, the components representing the result as “output”, and the rest as a black box. Such a model does not describe the internal dependencies of the system, but hides them. We do not know how the result is.
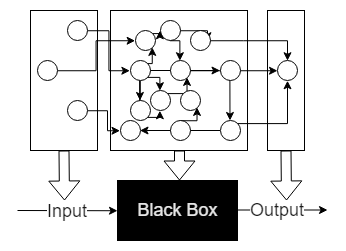
This approach is often used in cases where we want to study the work of a system, but at the same time we cannot “open” it. For example in psychology. We give people testiki, they solve them. We do not know what happens at the moment in people's heads. But, having collected enough data, it is possible to describe the device of a box which will give similar results. In the Machine Ex Homo section, we look at this in more detail.
Now we will build a model that displays the entire set of components and their possible states.
You live in ancient Greece. Your neighbor Zeno ( ru ) already got you. This Aidov son breaks into your house every night with another brain-mystery ( ru )and after that you spend a sleepless night thinking. You need to sleep and for this you need to shut him up for at least a couple of days.
He last ran with the story of Achilles running after a tortoise ( ru ) . During this night, your eyes fell on one of the buckets. An interesting thought came to mind: to consider its aporia in a more detailed way, using buckets and stones.
You want to make sure that you have the opportunity to find out the position of Achilles and the tortoise in relation to the starting point, for each step of the tortoise. We have: a tortoise that walks, Achilles, which is 10 times faster than a turtle. And their initial positions: 1000 steps and 0 steps.
Our model does not yet know how to represent numbers. And it is absolutely impossible to discern where Achilles, where the turtle, where the path.
With the representation of natural numbers is simple : take a bucket, set the number of stones equal to this number.
Now we can describe the speed and the path. In the bucket that indicates the speed of Achilles will be 10 stones. In the bucket for the speed of the turtle - one stone. We now turn to the "buckets of the way . " In the turtle we will put a thousand stones, leave Akhillesovo empty. When the turtle takes a step, we will shift the stones from speed to go. Is it done?
Not yet. We have no paint to sign the buckets. Only stones. How to handle this?
Alternatively, we can put a turtle bucket "speed" to the right of its "bucket path." Do the same with the buckets of Achilles. And push back the buckets of the turtle. Now we know that in the “two buckets” combination - the right bucket is speedy, and the left one is the track bucket.
You are looking at two groups of two buckets. In order to find out which of the Achilles groups is you have to go, look in the bucket, count the stones in it, remember that Achilles’s speed is 10 steps, and conclude that Achilles has a bucket. And if we want to make some changes and make the speed of Achilles equal to the speed of the turtle? Then our way of checking for Achilles will stop working altogether!
Therefore, in front of buckets of speed and path, we put a "bucket of the name." Now it has become the most right. And let our rule look like this: if the bucket of a name is empty, then the buckets following it are turtles. And if there is a stone, then this group of buckets denotes Achilles.
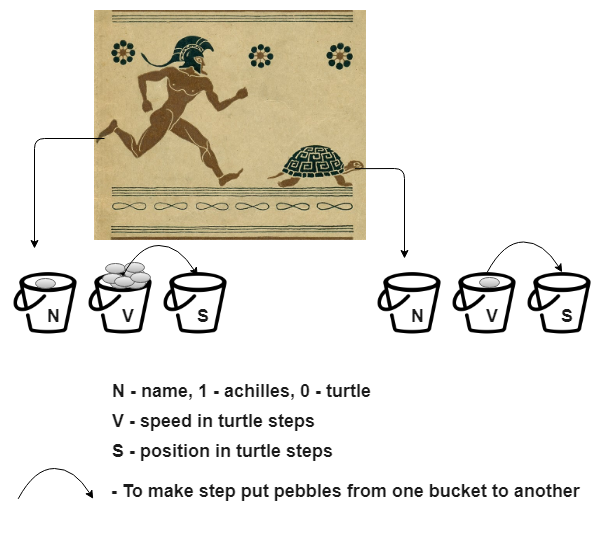
I did not draw stones in S, but I think it is clear that for the first step the Achilles bucket is empty, and the turtle contains 1000 stones.
You are rejoicing. Now, Zeno will have to seriously think about why he decided that he could continue the stone-cutting process forever. At least you hope so.
Unfortunately, it did not help you improve sleep. Zeno didn’t really come the next evening, but now you yourself are deep in thought. Will the moment come when stones cannot be divided ( ru ) ?
Look, for each step we received some kind of state of each of the objects we considered. The position of Achilles corresponds to one bucket, turtles - another. For speeds the situation is similar. Our model fully describes all possible states of all objects of the simulated system.
Text is also a model of the system. The terms in this case are words. They are determined by their meaning, or set of meanings, which is limited depending on the context.
Our sensations are also a model that our brain creates on the basis of information coming from outside.
In short, the models you constantly face.
Do you still remember why we all did it? Just in case: we gave a definition for the model, then to calculate its complexity. The time has come, let's see how this can be applied.
You are a UX designer. Your task: to make the application settings page. You know that they will not change in the future. There are ten of them: five graphic and five notification settings.
You can leave them all on one screen. You also have an idea of what can be done on the first screen with the “graphics” and “notifications” items, and a transition to the corresponding screen with five settings.
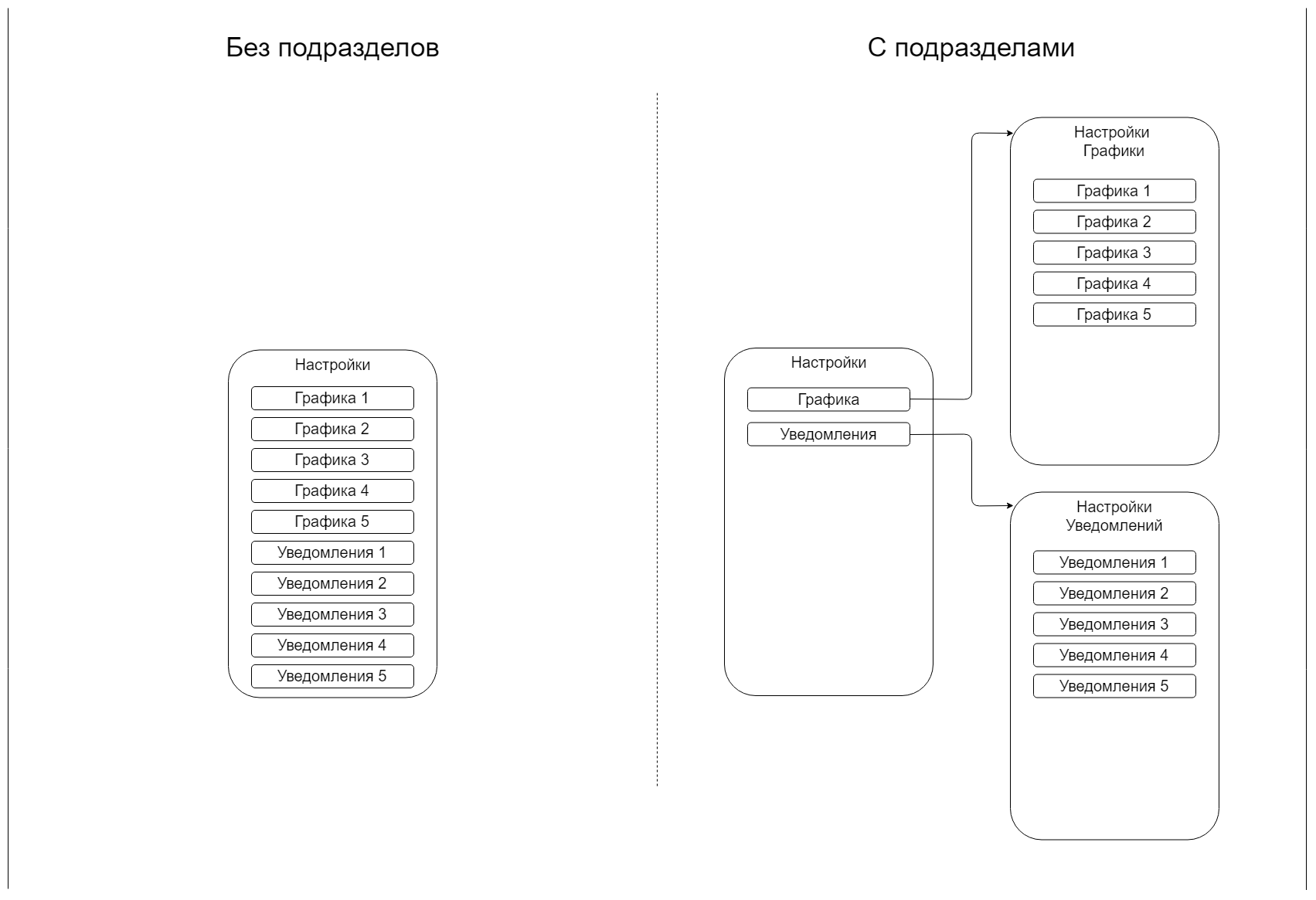
Let's assume that our user has a very bad memory and a habit of reading from top to bottom. But at the same time, he is still smart enough not to make a mistake with the section, in the case when we have grouped the options. He does not read the names of the screens and goes directly to the menu items.
We have only 10 settings, they can be displayed on the screen with a list, and the user simply sticks to the desired item. We believe that the user does not need to scroll the sheet in this case. On the other hand, if the user needed the settings from the end, it would be easier for him to find them, because he would not have to read the entire list, he would be able to skip half of the items he did not need.
Which model will give us a simpler interaction?
Actions that a user can take with a list item: read and poke into it. If you translate into the language of interfaces: the menu item has the properties of readability and poking ability. All the points are short, so the difference in the difficulty of their reading is neglected. We assume that the actions "to push" and "read" are elementary in our context. Their complexity 1.
We expect the user to be equally likely to need any of the items. There is no sense in bringing up some of them.
Of course, you already have some guess about the answer. I suggest you write it down, as well as write down your confidence that your answer is correct. For example, on a scale from 1 to 10, where 10 is absolutely certain, 1 is not at all sure. You will need this data in order to compare them with the result. Under the spoiler "Solution" will be a poll. Unfortunately, Habr does not allow you to do polls anywhere in the text, so the link leads to Google form. There you can go through it and see the statistics on the overall results.
I advise you to take a pen, a piece of paper, open a calculator and calculate the complexity yourself. And only after that open the spoiler.
Decision:
Если пользователю потребовался второй пункт, алгоритм его действий выглядит так:
Прочитать первый пункт -> прочитать второй -> ткнуть пальцем, а сложность соответственно: 2+1 = 3.
Чтобы найти среднюю сложность нам потребуется найти сложность навигации до каждого из пунктов, сложить их и поделить на 10.
Для пунктов на одном экране: ((1+1)+(2+1)+(3+1)+(4+1)+(5+1)+(6+1)+(7+1)+(8+1)+(9+1)+(10+1))/10 = 6.5
Теперь перейдем к сложности варианта с разбиением на подменю. Для того, чтобы найти нужную опцию, сначала нам надо выбрать нужный раздел и ткнуть на него. Для первого пункта действия выглядят так:
Прочитать название первого раздела -> ткнуть -> прочитать название первого пункта -> ткнуть.
Сложность 4.
Давайте честно посчитаем:
((2+1+1)+(2+2+1)+(2+3+1)+(2+4+1)+(2+5+1)+(3+1+1)+(3+2+1)+(3+3+1)+(3+4+1)+(3+5+1))/10 = (4+5+6+7+8+5+6+7+8+9)/10 = 6.5
Они одинаковы?!
…
…
…
Честно говоря, когда я придумал этот пример, я ожидал другого ответа. Мне казалось, что способ с группировками в этой задаче лучше.
Как я и обещал, вы можете поучаствовать в опросе и посмотреть статистику по ответам. И пожалуйста, не пользуйтесь тем, что можете отправить несколько ответов. Я не хочу заставлять вас логиниться в гугл аккаунт, чтобы вам было удобнее отвечать и смотреть результат, а в обмен прошу не мешать собирать статистику.
Так, а если мы оставим пример таким же, но рассмотрим другое количество пунктов? 4 и 4, 3 и 3, 6 и 6?
Я снова предлагаю вам сделать все самостоятельно. Подсказка: прочитайте про сумму арифметической прогрессии и составьте уравнение, в зависимости от общего количества пунктов.
Ниже находится только ответ, так что, если вы хотите знать, как он получился, вам придется немного поработать.
Прочитать первый пункт -> прочитать второй -> ткнуть пальцем, а сложность соответственно: 2+1 = 3.
Чтобы найти среднюю сложность нам потребуется найти сложность навигации до каждого из пунктов, сложить их и поделить на 10.
Для пунктов на одном экране: ((1+1)+(2+1)+(3+1)+(4+1)+(5+1)+(6+1)+(7+1)+(8+1)+(9+1)+(10+1))/10 = 6.5
Теперь перейдем к сложности варианта с разбиением на подменю. Для того, чтобы найти нужную опцию, сначала нам надо выбрать нужный раздел и ткнуть на него. Для первого пункта действия выглядят так:
Прочитать название первого раздела -> ткнуть -> прочитать название первого пункта -> ткнуть.
Сложность 4.
Давайте честно посчитаем:
((2+1+1)+(2+2+1)+(2+3+1)+(2+4+1)+(2+5+1)+(3+1+1)+(3+2+1)+(3+3+1)+(3+4+1)+(3+5+1))/10 = (4+5+6+7+8+5+6+7+8+9)/10 = 6.5
Они одинаковы?!
…
…
…
Честно говоря, когда я придумал этот пример, я ожидал другого ответа. Мне казалось, что способ с группировками в этой задаче лучше.
Как я и обещал, вы можете поучаствовать в опросе и посмотреть статистику по ответам. И пожалуйста, не пользуйтесь тем, что можете отправить несколько ответов. Я не хочу заставлять вас логиниться в гугл аккаунт, чтобы вам было удобнее отвечать и смотреть результат, а в обмен прошу не мешать собирать статистику.
Так, а если мы оставим пример таким же, но рассмотрим другое количество пунктов? 4 и 4, 3 и 3, 6 и 6?
Я снова предлагаю вам сделать все самостоятельно. Подсказка: прочитайте про сумму арифметической прогрессии и составьте уравнение, в зависимости от общего количества пунктов.
Ниже находится только ответ, так что, если вы хотите знать, как он получился, вам придется немного поработать.
Ответ:
Если у вас 5 пунктов в каждом разделе — сложности сравняются.
При 6 и больше будет выигрывать вариант с разбиением.
При 4 и меньше будет выигрывать вариант с одним списком.
При 6 и больше будет выигрывать вариант с разбиением.
При 4 и меньше будет выигрывать вариант с одним списком.
I inserted this example into the article at the stage of final edits. It was important for me to summarize what we were talking about. Link the information from previous chapters in an understandable form. So that you can easily imagine it and try to use what we talked about.
I was wrong. When I wrote this example, I thought I knew what the answer would be. And now I am pretty surprised. No that's not true. When I honestly did all the calculations, the result hit me very hard.
Something like this happened in my head: - * The choir * WE'RE MISTAKED ?!
And wrap ...
— *Голос 1* Что? Как так! Я, твою мать, разработчик мобильных приложений! И судя по отзывам моих коллег я хороший разработчик! Моя компетенция в этом вопросе не вызывает у меня особых сомнений!
— *Голос 2* Ну, да. И что с того?
— *Голос 1* Да я эти приложения днями и ночами вижу. Я кучу гайдлайнов прочитал. Я этих списков уже сотни сделал. У меня достаточно квалификации в моей области, чтобы поправлять ошибки наших же дизайнеров!
— *Голос 2* Ага, а дальше то что?
— *Голос 1* Я эту гребаную статью написал! Большая часть моей работы состоит в том, чтобы другим людям было проще взаимодействовать с моими решениями! Я занимаюсь этим годы! Не только в рабочее время, но и почти все свободное. Мой опыт давно перевалил за банальные 10к часов!
— *Голос 2* Парень, я вообще-то тоже ты. Ты не сказал ничего нового, перейди к сути.
— *Голос 1* Я делаю вывод, что мой пример синтетический. Он не отображает реальность, в ней все будет по другому, и поэтому ответ, который я предположил первым, будет правильным. Мой опыт позволил мне учесть намного больше, чем было в этом примере.
*Включаются сирены и красные лампы*
— *Голос из громкоговорителей* Говорит та часть твоего сознания, которою мы настроили для обнаружения ошибочных шаблонов в мышлении. Замеченные ошибки: эффект сверхуверенности, предвзятость подтверждения, селективное восприятие. Был распознан шаблон апелляции к авторитету, но эта информация пока проверяется. В связи с опасностью самообмана вам приказано дышать глубже и выпить чаю.
— *Голос 1* Самообмана нет! Вы знаете, что все, что я сказал мы считаем правдой!
— *Голос 2* А ты знаешь, что есть большая разница между реальностью и твоим мнением насчет того, какая она должна быть.
— *Голос 1* Ну блииииииин, опять эти лекции.
— *Голос 2* Представь, что ты поверил в то, что люди умеют летать. Спасет ли тебя это при прыжке с крыши?
— *Голос 1* Не могу. Я же вижу, что другие люди не летают, значит не буду делать о себе такой идиотский вывод. И вообще, ты гиперболизируешь.
— *Голос 2* Ты сошел с ума. Или тебя накачали наркотиками. Или на тебя надели идеальный костюм виртуальной реальности, ты провел в ней 5 лет и все люди там летали, ты сам умел летать, твой мозг приспособился и «знает» как это делать. Наши мысли, ощущения, ожидания и вообще весь мы — это состояние нашего мозга. По крайней мере, такова наша рабочая гипотеза. И мы знаем, что есть ситуации, намного более странные, чем уверенность в возможности полета. Вспомни книгу «Человек который принял жену за шляпу».
— *Голос 1* Ладно, мозги действительно могут сбоить, а в твоем примере я действительно упаду, даже если буду в полете думать, что лечу. Если у меня хватит времени, я замечу что лечу не туда, но будет уже поздно.
— *Голос 2* Окей, а теперь вернемся к разбору полетов. Хех, клевый каламбурчик. Ты придумал этот пример. Ты знал о его правилах. Ты знал, что ты сильно его упрощаешь, в сравнении с реальностью. Ты знал, как его решать. И ты ошибся в своем изначальном предположении.
— *Голос 1* Это не я! Я сделал выбор интуитивно, ты знаешь как это работает!
— *Голос 2* А ты знаешь, что это часто работает неправильно. И вот тебе еще одно доказательство.
— *Голос 1* А что с моим последним аргументом? Ведь это и правда приближение, и в реальности все будет по другому.
— *Голос 2* Этот аргумент — истинный. В реальности все будет по другому. Только из него не следует, что ты был прав.
Представь: ты начинаешь приближать пример к реальности. Ты честно считаешь отношения сложностей действий «ткнуть» и «прочитать», ты проводишь исследование, как люди смотрят на экран, какой части названия в этом списке им достаточно, чтобы понять, что это не тот пункт.
Ты дополняешь этот пример огромным количеством условий, он становится в сотни раз сложнее.
Прости, но в этом случае вероятность того, что ты получил правильный ответ «потому что интуиция» намного ниже, чем ~50% которые есть у случайного выбора.
Ты так уверен, что реальность встанет на твою сторону? Почему? Докажи.
— *Голос 1* Да не уверен я! Просто…
— *Голос 2* Сложно. Сложно признать, что ты ошибался, я знаю. Но ты понимаешь, почему нам это нужно. То, что эта ситуация произошла говорит лишь о том, что мы — тормоз и обучаемся медленнее, чем нам хотелось бы. Но мы знаем что надо делать.
— *Голос 1* Simple truth перечитать, что ли?
— *Голос 2* Очень хороший вариант. Нас это всегда успокаивает в таких ситуациях. Еще ты можешь глубоко подышать. И да, мы разобрались с этой ситуацией меньше чем за 1,5 минуты. Видал как быстро сработала система обнаружения ошибки? Мне кажется, мы заслужили пирожок. Его нет на полке, там гребаное Потенциальное Ведро, но мы его себе купим.
— *Голос 1* И все же интересно, что будет в реальности…
— *Голос 2* Ты что, забыл зачем мы пишем статью?!
— *Голос 2* Ну, да. И что с того?
— *Голос 1* Да я эти приложения днями и ночами вижу. Я кучу гайдлайнов прочитал. Я этих списков уже сотни сделал. У меня достаточно квалификации в моей области, чтобы поправлять ошибки наших же дизайнеров!
— *Голос 2* Ага, а дальше то что?
— *Голос 1* Я эту гребаную статью написал! Большая часть моей работы состоит в том, чтобы другим людям было проще взаимодействовать с моими решениями! Я занимаюсь этим годы! Не только в рабочее время, но и почти все свободное. Мой опыт давно перевалил за банальные 10к часов!
— *Голос 2* Парень, я вообще-то тоже ты. Ты не сказал ничего нового, перейди к сути.
— *Голос 1* Я делаю вывод, что мой пример синтетический. Он не отображает реальность, в ней все будет по другому, и поэтому ответ, который я предположил первым, будет правильным. Мой опыт позволил мне учесть намного больше, чем было в этом примере.
*Включаются сирены и красные лампы*
— *Голос из громкоговорителей* Говорит та часть твоего сознания, которою мы настроили для обнаружения ошибочных шаблонов в мышлении. Замеченные ошибки: эффект сверхуверенности, предвзятость подтверждения, селективное восприятие. Был распознан шаблон апелляции к авторитету, но эта информация пока проверяется. В связи с опасностью самообмана вам приказано дышать глубже и выпить чаю.
— *Голос 1* Самообмана нет! Вы знаете, что все, что я сказал мы считаем правдой!
— *Голос 2* А ты знаешь, что есть большая разница между реальностью и твоим мнением насчет того, какая она должна быть.
— *Голос 1* Ну блииииииин, опять эти лекции.
— *Голос 2* Представь, что ты поверил в то, что люди умеют летать. Спасет ли тебя это при прыжке с крыши?
— *Голос 1* Не могу. Я же вижу, что другие люди не летают, значит не буду делать о себе такой идиотский вывод. И вообще, ты гиперболизируешь.
— *Голос 2* Ты сошел с ума. Или тебя накачали наркотиками. Или на тебя надели идеальный костюм виртуальной реальности, ты провел в ней 5 лет и все люди там летали, ты сам умел летать, твой мозг приспособился и «знает» как это делать. Наши мысли, ощущения, ожидания и вообще весь мы — это состояние нашего мозга. По крайней мере, такова наша рабочая гипотеза. И мы знаем, что есть ситуации, намного более странные, чем уверенность в возможности полета. Вспомни книгу «Человек который принял жену за шляпу».
— *Голос 1* Ладно, мозги действительно могут сбоить, а в твоем примере я действительно упаду, даже если буду в полете думать, что лечу. Если у меня хватит времени, я замечу что лечу не туда, но будет уже поздно.
— *Голос 2* Окей, а теперь вернемся к разбору полетов. Хех, клевый каламбурчик. Ты придумал этот пример. Ты знал о его правилах. Ты знал, что ты сильно его упрощаешь, в сравнении с реальностью. Ты знал, как его решать. И ты ошибся в своем изначальном предположении.
— *Голос 1* Это не я! Я сделал выбор интуитивно, ты знаешь как это работает!
— *Голос 2* А ты знаешь, что это часто работает неправильно. И вот тебе еще одно доказательство.
— *Голос 1* А что с моим последним аргументом? Ведь это и правда приближение, и в реальности все будет по другому.
— *Голос 2* Этот аргумент — истинный. В реальности все будет по другому. Только из него не следует, что ты был прав.
Представь: ты начинаешь приближать пример к реальности. Ты честно считаешь отношения сложностей действий «ткнуть» и «прочитать», ты проводишь исследование, как люди смотрят на экран, какой части названия в этом списке им достаточно, чтобы понять, что это не тот пункт.
Ты дополняешь этот пример огромным количеством условий, он становится в сотни раз сложнее.
Прости, но в этом случае вероятность того, что ты получил правильный ответ «потому что интуиция» намного ниже, чем ~50% которые есть у случайного выбора.
Ты так уверен, что реальность встанет на твою сторону? Почему? Докажи.
— *Голос 1* Да не уверен я! Просто…
— *Голос 2* Сложно. Сложно признать, что ты ошибался, я знаю. Но ты понимаешь, почему нам это нужно. То, что эта ситуация произошла говорит лишь о том, что мы — тормоз и обучаемся медленнее, чем нам хотелось бы. Но мы знаем что надо делать.
— *Голос 1* Simple truth перечитать, что ли?
— *Голос 2* Очень хороший вариант. Нас это всегда успокаивает в таких ситуациях. Еще ты можешь глубоко подышать. И да, мы разобрались с этой ситуацией меньше чем за 1,5 минуты. Видал как быстро сработала система обнаружения ошибки? Мне кажется, мы заслужили пирожок. Его нет на полке, там гребаное Потенциальное Ведро, но мы его себе купим.
— *Голос 1* И все же интересно, что будет в реальности…
— *Голос 2* Ты что, забыл зачем мы пишем статью?!
...
...
...
I apologize for such a large digression and example. Perhaps you are not ready to read further, and you want to think everything over again. And this is a good choice.
At the beginning there is a table of contents, you can bookmark the article and quickly return to this place.
Have you decided to continue? Then, we have the last topic of those that I wanted to raise.
1.6 Blade Runner
Briefly
Occam's razor and probability hypothesis.
Occam's razor on the simplicity side of the system.
Denote the complexity of the change for the complexity of the system is up to how and after how
the complexity of the system is up to how and after how  .
.
 .
.
If a greater than 1 is a good change.
greater than 1 is a good change.
If aless than 1 is a valid, but not payback change.
If aless than 0 is a very bad change.
If we assume that the complexity grows with the number of objects in the model, and that we already have a certain set of models, we get that the best option is a model with a minimum number of objects, which is very similar to the formulation of Occam's Razor.
Occam's razor on the simplicity side of the system.
Denote the complexity of the change for
the complexity of the system is up to how and after how .. If a
greater than 1 is a good change. If a
less than 1 is a valid, but not payback change. If a
less than 0 is a very bad change. If we assume that the complexity grows with the number of objects in the model, and that we already have a certain set of models, we get that the best option is a model with a minimum number of objects, which is very similar to the formulation of Occam's Razor.
Most likely you know Occam's razor, but just in case, I remind you:
“You shouldn’t attract new entities unless absolutely necessary.”
In general, this principle is interpreted as follows: all of the hypotheses is most likely the one that describes the shortest routine (or to put it simply - the one that is shorter) ( ru , en1 , en2 ) .
How it looks in real life:
If you turn on the light and the light bulb comes on , then the hypotheses may be:
- The switch closed the electrical circuit and the current went through the light bulb.
- The switch kicked a little gnome who connected the wires, causing the circuit to close and the current to go through the light bulb.
- The switch kicked the little gnome who pushed the trolley in which sat a small dragon, who, frightened by the fiendish flame, which melted the solder, which connected the wires, caused the circuit to close and the current went through the light bulb.
Of these hypotheses, one that contains fewer entities, without a gnome, is preferable. If you turn on the light bulb when you hear a silent curse from the switch, the second hypothesis is preferable, because the former does not explain why the switch curses and the latter contains redundant entities.
I will be honest. When I first heard of Occam's Razor, I did not think about hypotheses. And her vague wording in verbal form led me to the idea that this is a general principle - reduce the number of entities that are in your system and everything will be cool.
I was very wrong .
But when I had a description of the simplicity of the system, I understood how to correct my misinterpretation of this principle. And make something useful out of it.
We have a system before and after some change.
If the difference between the difficulties before and after is greater than the complexity of the change process itself - this change is justified. It is understood that the change did not affect the result (at least on the part of it that we need). Call it ... a prerequisite for simplification.
Once again: The
expected simplification of the system after the change should be greater than the complexity of the change itself.
If we denote the complexity of the change for
the complexity of the system is up to how and after how then we get:  .
. We can also express a certain analogue of efficiency for our change.
 .
. If a
greater than one is a good, kosher change that meets the necessary simplification condition. If a
less than 1, but more than 0 - this means that you simplify the system, but spend more time on it than get a profit. If a
less than 0, then it tells you that such a change is not worth doing. You complicate. Why is it needed? Well, for example, you act in conditions where you have limited time and you would like to prioritize the changes you want to make. Changes with great
should be considered first. Example:
We have two texts, one with an example the other without.
On the one hand, we have increased the volume of the text, thereby complicating it. But on the other hand, thanks to this, some readers will not go into Google “an example of an Occam's razor,” which is more complicated than just reading. If, by our estimation, there will be many such readers, then the introduction of an example will simplify our article.
We should not forget about the fact that we also did some actions to describe it, and they had their own difficulty. If we spent too much action, and the simplification was not enough - the introduction of our essence “does not pay off”.
Hmm, how is this all connected with Occam's razor?
Let's assume that we already have several systems. And their complexity directly depends on the number of entities (in the real world this is not always true, as we have already found out). The results of actions with these systems suit us.
Since the systems already exist,
 (you do not need to do anything in order to make changes to the system). Let's take a system with a minimum number of entities, and calculaterelative to other systems. We will get thatwill be equal to minus infinity. From the point of view of simplicity, in such conditions, choose a system that is different from the one that contains the smallest number of objects - an infinitely foolish solution. This tells us that from all systems we should choose the one that contains the smallest number of objects. Hm Suspiciously similar to Occam's Razor.
(you do not need to do anything in order to make changes to the system). Let's take a system with a minimum number of entities, and calculaterelative to other systems. We will get thatwill be equal to minus infinity. From the point of view of simplicity, in such conditions, choose a system that is different from the one that contains the smallest number of objects - an infinitely foolish solution. This tells us that from all systems we should choose the one that contains the smallest number of objects. Hm Suspiciously similar to Occam's Razor. What else can be described using this condition?
For example, you can evaluate when it is worthwhile to apply various practices of improving code, and when it is meaningless.
In fact, if you write a task in a higher education institution, the code of which will be read once (or not read at all, but simply see how it works), then you should not worry about it so that it is well read.
But if you write for the OpenSource project, and hundreds of people will work with your code, or you write your project that you plan to develop, you should take care of its quality.
If you are writing a synopsis, you should evaluate whether you will need it in the future. If the teacher will check only its availability, and all the information is easier to find in Google, then why complicate it?
If you are writing an article - determine how you see the interaction with it. For example, this article is intended not only for a single reading. I tried to optimize it for a quick search. That is why under each part there is a “Short” spoiler and a table of contents at the beginning.
Eh, if we had a way to somehow describe how a person would read our model, and find the complexity of this model for reading. We could tell exactly how our actions will affect the complexity of this process and apply our theory in a huge number of practical problems.
Unfortunately, for this you need to create a general algorithm for people to read any model. If it seemed to you that this is a very difficult task - you are right.
Fortunately, I have already done some of this work.
In the next chapter, which will be called Machine Ex Homo, we will analyze how our brain works with information. We will talk about understanding and how information that we already know affects the perception of a new one. Let's look at the research of psychologists and neurobiologists in the field of studying human memory and create their own model of memory based on them. With its help, we will explain some interesting psychological effects, such as the effect of word frequency, edge effect, optical illusions. And there will be a lot more pictures.
In short - it will be interesting, I promise.
PS
Вы дочитали эту статью до конца.
Во первых, знайте — вы большой молодец. И я хочу сказать вам спасибо, потому что для меня важно, что вы ее прочитали.
И я хотел бы попросить о помощи.
Вернее не так: я потратил огромное количество времени, чтобы создать эту статью. Если она вам понравилась, вы сочли ее полезной или интересной, то мне кажется честным попросить у вас что-то взамен.
Нет, не деньги, все не настолько тривиально. Мне нужно ваше время.
Как я уже говорил, мне важно, чтобы мою статью читали. И мне важно качество моей статьи.
И, если вам не сложно, пробегитесь по публикации и сообщите об ошибках или идеях для ее упрощения. К сожалению, мое время ограничено, и я физически не могу сделать все идеально.
Если у вас появились другие идеи, как вы можете мне помочь, напишите их на почту simple.explanation.of.simple@gmail.com. То же самое вы можете сделать, если у вас просто появилось такое желание, но вы пока не придумали как. Расскажите о себе, и мы вместе подумаем, возможно найдется что-то, чем вам будет интересно заняться.
Во первых, знайте — вы большой молодец. И я хочу сказать вам спасибо, потому что для меня важно, что вы ее прочитали.
И я хотел бы попросить о помощи.
Вернее не так: я потратил огромное количество времени, чтобы создать эту статью. Если она вам понравилась, вы сочли ее полезной или интересной, то мне кажется честным попросить у вас что-то взамен.
Нет, не деньги, все не настолько тривиально. Мне нужно ваше время.
Как я уже говорил, мне важно, чтобы мою статью читали. И мне важно качество моей статьи.
И, если вам не сложно, пробегитесь по публикации и сообщите об ошибках или идеях для ее упрощения. К сожалению, мое время ограничено, и я физически не могу сделать все идеально.
Если у вас появились другие идеи, как вы можете мне помочь, напишите их на почту simple.explanation.of.simple@gmail.com. То же самое вы можете сделать, если у вас просто появилось такое желание, но вы пока не придумали как. Расскажите о себе, и мы вместе подумаем, возможно найдется что-то, чем вам будет интересно заняться.
License:
CC BY-NC-SA 4.0