Offline mode on iOS and features of its implementation on Realm
- Tutorial

Author: Ekaterina Semashko, Strong Junior iOS Developer, DataArt
A little about the project: a mobile application for the iOS platform, written in Swift. The purpose of the application is the possibility of sharing discount cards between employees of the company and their friends.
One of the goals of the project was to study and try out popular technologies and libraries in practice. Realm was chosen for storing local data, Alamofire was used for working with the server, Google Sign-In was used for authentication, and PINRemoteImage was used for uploading images.
The main functions of the application:
- adding a map, editing and deleting it;
- view other cards;
- Search cards by store name / user name;
- Add cards to your favorites list for quick access.
The ability to use the application without connecting to the network was assumed from the very beginning, but only in read mode. Those. we could view information about the maps, but we could not modify them without the Internet. For this, the application has always had a copy of all the maps and brands of the database from the server, plus a list of favorites for the current user. The search was also implemented locally.
Later we decided to expand offline by adding a recording mode. Information about the changes made by the user was saved and synchronized with the appearance of the Internet connection. The implementation of such a read-write offline mode will be discussed.
What is needed for full offline mode in a mobile application? We need to remove the user's dependence on the quality of the Internet connection, in particular:
- Remove the dependence of responses to the user on his actions in the UI from the server. First of all, the request will interact with the local storage, then it will be sent to the server.
- Mark and store local changes.
- Implement the synchronization mechanism - when the Internet connection appears, you need to send the changes to the server.
- Show the user what changes are synchronized, which are not.
Offline-first approach
First of all, I had to change the existing mechanism of interaction with the server and database. The goal was that the user did not feel dependent on the presence or absence of the Internet. First of all, it should interact with the local data storage, and requests to the server should go in the background.
In the previous version there was a strong connection between the data storage layer and the network layer. The mechanism of working with data was as follows: first a request was sent to the server through the NetworkManager class, we waited for the result, after that the data was saved to the database via the Repository class. Then the result was given to the UI, as shown in the diagram.
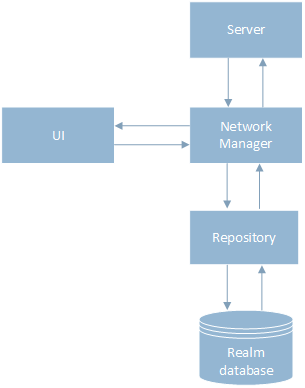
To implement the offline-first approach, I separated the data storage layer and the network layer by introducing a new class Flow, which controlled the order of the call NetworkManager and Repository. Now, the data is first saved to the database via the Repository class, then the result is sent to the UI, and the user continues working with the application. In the background, a request is sent to the server, after the response, the information in the database and the UI are updated.
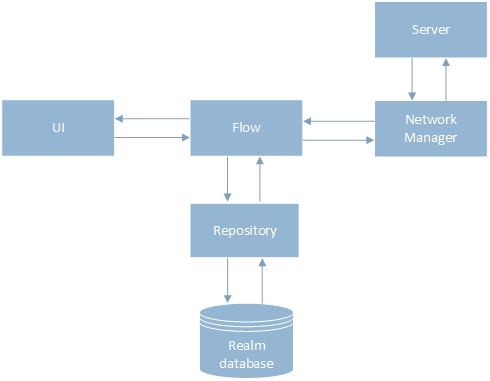
Work with object identifiers
With the new architecture, several new tasks have appeared, one of which is working with id objects. Previously, we received them from the server when creating an object. But now the object was created locally, respectively, it was necessary to generate the id and after synchronization, update them with the current ones. Then I encountered the first Realm constraint: after creating an object, its primary key cannot be changed.
The first option was to drop the primary key in the object, to make id the usual field. But at the same time, the advantages of using the primary key were lost: indexing of Realm, which speeds up the fetch of the object, the ability to update the object with the create flag (create an object if it does not exist), observance of the uniqueness of the object.
I wanted to save the primary key, but it could not be the object id from the server. As a result, the working solution was to have two identifiers, one of them is server-side, an optional field, and the second is local, which would be the primary key.
As a result, the local id is generated on the client when the object is created locally, and in the case when the object came from the server, it is equal to the server id. Since the single source of truth application is a database, when receiving data from the server, the object is supplied with the actual local identifier, and it only works with it. When sending data to the server, the server identifier is transmitted.
Storing Unsynchronized Changes
Changes to objects that have not yet been sent to the server must be stored locally. This can be implemented in the following ways:
- adding fields to existing objects;
- storing non-synchronized objects in separate tables;
- storing individual field changes in some format.
I do not use Realm objects directly in my classes, but rather make them mapping onto my own to avoid problems with multithreading. Auto-update of the interface is done with the help of auto-updating results of samples, where I subscribe to update requests. Only the first approach worked with my current architecture, so the choice fell on adding fields to existing objects.
The map object has undergone the most changes:
- synced - is there any data on the server;
- deleted - true, if the map is deleted only locally, synchronization is required.
Identifiers, which were discussed in the previous section:
- localId - the primary key of the entity in the application, either equal to the server id, or generated locally;
- serverId - id from the server.
Separately worth mentioning is the storage of images. In essence Attachment, a diskURL field was added to the serverURL field of the image on the server, storing the address of the local unsynchronized image. When you synchronize the image, the local one was deleted so as not to clutter up the device’s memory.
Synchronization with the server
For synchronization with the server, work with Reachability was added, so that when the Internet appeared, a synchronization mechanism was launched.
First, it checks if there are any changes in the database that need to be sent. Then a request is sent to the server to get the actual data snapshot, and as a result, changes that do not need to be sent out on the client (for example, changing an object that has already been deleted on the server) are eliminated. The remaining changes form a queue of requests to the server.
To send changes, you could implement bulk updates, sending changes to the array, or make a large request to synchronize all the data. But by that time, the backend developer was already busy in another project, and he only helped us in his spare time, so for each type of change, a request is created.
I implemented the queue through OperationQueue and wrapped each request into an asynchronous Operation. Some operations depend on each other, for example, we cannot load a map image before creating a map, so I added a dependency image operation to a map operation. Also, the operation of uploading images to the server was given a lower priority than all the others, and I added them to the queue as the last because of their heaviness.
When planning offline mode, the big issue was resolving server conflicts during synchronization. But when we came to this in the course of implementation, we realized that the case when the user changes the same data on different devices is very rare. So we just need to implement the last writer wins mechanism. When synchronizing, priority is always given to unsent changes on the client; they are not overwritten.
Error handling is still in its infancy, if synchronization fails, the object will be added to the change queue the next time the Internet appears. And then if it hangs unsynchronized after merge, the user decides whether to leave it or delete it.
Additional workaround when working with Realm
When working with Realm encountered several problems. Perhaps this experience will also be useful to someone.
When sorting by string, the order goes according to the order of characters in UTF-8, there is no support for case-insensitive search. We are faced with a situation where the names in lower case go after the names in upper case, for example: Magnet, Pyaterochka, Ribbon. If the list is very large, all the names in lower case will be at the bottom, which is very unpleasant.
To preserve the sort order regardless of the register, it was necessary to enter a lowercasedName field, update it when updating the name, and sort by it.
Also, a new field was added for sorting by the presence of a map in the favorites, since, in fact, this requires a subquery on the object links.
When searching in Realm, there is a CONTAINS [c]% @ method for case-insensitive search. But, alas, it works only with Latin. For Russian brands, we also had to create separate fields and search for them. But later it turned out to be in our hands to exclude special characters when searching.
As you can see, for mobile applications it is possible to implement offline mode with saving changes and synchronization with little blood, and sometimes even with minimal changes on the backend.
Despite some difficulties, you can use Realm for its implementation, while receiving all the advantages in the form of live updates, zero-copy architecture and user-friendly API.
So there is no reason to deny your users the ability to access data at any time, regardless of the quality of the connection.