REST API Design for High Performance Systems

Alexander Lebedev expresses all the non-triviality of the REST API design. This is a transcript of the report Highload ++ 2016.
Hello everyone!
Raise your hand those who are the front-end developer in this room? Who is the mobile developer? Who is the backend developer?The backend of developers is the majority in this room now, which is joyful. Secondly, almost everyone woke up. Great news.
A few words about yourself
Who am i? What am I doing?
I’m the front-end team lead of New Cloud Technologies. For the last 5 years I have written a web frontend that works with the REST API and which should work quickly for the user. I want to share experience on what APIs should be that allow this to be achieved.
Despite the fact that I will talk from the front end, the principles - they are common more or less for everyone. I hope both the backend developers and the developers of mobile applications will also find useful things for themselves in this story.
A few words about why it is important to have a good API for fast applications.
Firstly, it is performance from the point of view of the client. That is, not from the point of view of supporting us a million customers who came at the same time - but from the point of view that for each of them the application would work quickly separately. A little later, I will illustrate the case in this report, when changes in the API made it possible to speed up data acquisition on the client by about 20 times and made it possible to turn unhappy users into satisfied users.
Secondly - in my practice there was a case when, after a very short period of time, I had to write the same functional practically to two different systems.One had a convenient API, the other had an inconvenient API. How do you think the complexity of writing this functionality was different? For the first version - 4 times. That is, with a convenient API, we wrote the first version in two weeks, with an uncomfortable one in two months. The cost of ownership, the cost of support, the cost of adding something new - it also differed significantly.
If you do not deal with the design of your REST API, then you can not guarantee that you will not find yourself on the wrong side of this range. Therefore, I want the REST API approach to be reasonable.
Today I will talk about simple things, because they are more or less universal - they are applicable to almost all projects. How correctly complex cases require hotel analysis, they are specific to each project, and therefore not so interesting in terms of exchange of experience.
Simple things are interesting to almost everyone.
Let's start by looking at the overall situation. In what environment does the REST API exist that we need to do well?
In the cases with which I worked, the following generalization can be made:

We have a certain backend - conditionally, from the point of view of the frontend, it is one. In fact, everything is complicated there. Probably everyone saw a caricature where a mermaid acts as a frontend, and some nightmarish sea monster acts as a backend. This might work just as well. It is important that we have a single backend in terms of front - we have a single API, there are several clients to it.
A fairly typical case: we have a web, and we have two of the most popular mobile platforms. What can be immediately taken from this picture? One backend, several clients. This means that many times in the design code of the API there will be choices where to take the complexity. Either a little more work to be done on the backend, or a little more work to be done at the front.
You need to understand that in such a situation, work at the front will be multiplied by 3. Each product will have to contain the same logic. It will also be necessary to make additional efforts not even during development, but during further testing and maintenance, so that this logic does not disperse and remains the same on all clients.
You need to understand that assigning some kind of logic to the front-end is expensive and must have its own reasons; it should not be done “just like that”. I also want to note that the API in this picture is also single, also for a reason.
As a rule, if we say that we want to develop efficiently and we want to make the application fast, I really want to, despite the fact that the backend may have a zoo of systems (enterprise integration of half a dozen systems with different protocols, with different APIs). From the point of view of communication with the frontend, this should be a single API, preferably built on the same principles, and which can be changed more or less holistically.
If this is not the case, then talking about some meaningful design of the API will become sharply more difficult, the number of decisions about which you have to say: "well, we were forced to, this is such a limitation." I want to not have to get into this situation. We would like to be able to, at least in terms of what API we provide for client applications, control it all.
Another point - let's add people to this scheme.

What do we get
It turns out we have one or more backend teams, one or more front-end teams. You need to understand that if we want to have a good API, it is a common property. All teams work with him. This means that API decisions should be made preferably not in one team, but together. Most importantly, decisions must be made in the interests of all these teams.
If I, as a lead front-end, come up with an API to implement some functionality on the web and go to agree with the backend developers on how to implement it, I must take into account not only the interests of the web, not only the interests of the backend, but also the interests of mobile teams. Only in this case will not have to painfully redo.
Or, I must immediately clearly understand that I am doing some kind of temporary prototype, which then will need to cover the range from which we collect the requirements, including the rest of the team in it and redo it. If I understand this, then we can proceed from the interests of a separate team. Otherwise, one must proceed from the interests of the system as a whole. All these people have to work together for the API to be good.
In such circumstances, I managed to ensure that the API was convenient - so that it was convenient to write a good frontend to it.
Let's talk a little more about general ideas before moving on to the specifics.
Three main principles that I want to highlight
What I have already talked a little about in relation to the human key for technical solutions is also important. API technical decisions should be made based on their entire system, and not on the basis of a vision of any particular part of it.
Yes. This is hard. Yes, this requires some additional information when you need to do it right now, but it pays off.
Secondly, measuring performance is more important than optimizing it.
What does it mean? Until you start measuring how fast your frontend is working, how fast your backend is, it’s too early for you to optimize them. Because, almost always - in this case, not that will be optimized. I will talk about a couple of such cases later.
Finally, what I already touched the edge. Complex cases - they are unique for each project.
Simple principles are more or less universal, so I want to tell you about a few simple mistakes, some of which are known from personal experience. Almost any project may not repeat these errors.
A small section on how to measure performance. In fact, this is a very serious topic - there is a lot of hotel literature on it, a lot of hotel materials, as well as specialists who do just that.
What am I going to tell
I’m going to tell you where to start if you don’t have anything at all. Some cheap and angry recipes that will help you begin to change the performance of the web frontend and begin to measure the performance of the backend, so that later you can accelerate them. If you already have something - great. Most likely it is better than what I offer.
Backend performance.
We measure through what clients work with - through the REST API. At the same time, it is advisable to recreate more or less exactly how the user works with this API.
We measure UI performance through automated front-end testing. That is, in each case, we are not measuring some internal elements - we are measuring exactly the interface with which the next layer works.
That is, the REST API for the backend and the UI for the user.
What you need to understand to measure
Firstly, the closer our environment is to what will work in production, the more accurate are our numbers. It is very important that we have data similar to the real one.
Often it turns out, when we develop, we don’t have any test data at all. The developer creates something on his machine - usually one record, in order to cover each scenario that was thought of during the analysis and he gets 5-10 records. All is well.
And then it turns out that real users work with 500 records, in the same interface, in the same system. Brakes and problems begin. Or the developer creates 500 records, but they are all the same and are created by a script. With different data from real life, all sorts of anomalies can begin.
If you have data from production, the best test data is to take a sample of data from production, remove all sensitive information from it, which is the private domain of specific clients. On this we develop, on this we test. If we can do this, then this is wonderful, because you do not need to think about what kind of data should be.
If we still have an early stage in the life of the system and we can’t do this, we have to wonder how users will use the system, how much data, what data. Typically, these proposals will be very different from real life, but they are still 100 times better than the approach "what has grown has grown."
Then, the number of users. Here we are talking about the backend, because the user is usually alone on the frontend. There is a temptation, when we test performance, to let a small number of users with very intensive requests. We say: “100 thousand people will come to us, they will make new requests on average once every 20 seconds.
Let's replace this with 100 bots that will make new requests every 20 milliseconds. "
It would seem that the total load would be the same. However, it immediately turns out that in this case we almost always measure not the system performance, but the performance of the cache somewhere on the server or the performance of the database cache or the performance of the application server cache. We can get numbers that are much better than real life. It is desirable that the number of users - the number of simultaneous sessions, is also close to what we expect in real life.
How users work with the system
It is important that we figure out how many times each element will be used in the middle session. I had a case when we implemented the load testing scenario simply by writing a script that touches all the important parts of the system, once. That is, a person enters, uses each important function once and leaves.
And it turned out that we have two of the slowest points. We began to heroically optimize. If we thought or looked at statistics that were not there at that time, we would find out that the first slowest point is used in 30% of sessions, and the second slowest point is used in 5% of sessions.
First of all, this would allow us to optimize them differently. Where 30% is more important. And secondly, it would make it possible to draw attention to the fact that there is a functional that, despite the fact that it does not work so slowly, is always used.
If a session starts with logging in and viewing some kind of dashboard, then 100% of users feel the performance of this login and the performance of this dashboard.
Therefore, even if these are not the slowest places, it still makes sense to optimize them. Therefore, it is important to think about how the typical user will be perceived by the system, and not what functionality we have or what functionality needs to be checked for performance.
At the backend - how do we measure the performance of the REST API?
The approach that I personally used, which works pretty well as a first approximation, is that we should have a use case. We do not have a use case, we write them.
We estimate the percentage of using the system functions in each session. We shift this into requests to the REST API. We make sure that we have data similar to real for test users. We write scripts that generate them. Then we upload all this to JMeter or any other tool that allows us to arrange trips to the REST API with a large number of parallel users and test it. As a first solution - nothing complicated.
For the front end - all about the same degree of oakiness.

We fill the key places in the code with calls to the console functions that take the time, print to the console, everything is enough for the developer.
He can start the debugging assembly, see how much time this or that piece was shown, how much time passed between certain user actions - everything is fine.
If we want to do this automatically, we write a Selenium script. Console functions are not very suitable for Selenium - they write a primitive wrapper that takes exactly the time windows.performance.now () and passes it to some global object, from where it can then be taken. In this case, we can drive the same scenario on different versions and monitor how our system performance changes over time.
Now I want to move on to the main part - recipes learned from personal experience.
How to and how not to do the API
Let's start with one rather curious case: I said that at the API level you can optimize processing speed by 20 times.
Now I will show how exactly this scenario was arranged.

We have a backend. It aggregates the data of their three different systems and displays it to the user. In normal life, the response time looks something like this:

Three parallel requests go away - the backend aggregates them. Time in seconds. Everywhere the answer is less than a second. 100 milliseconds are added to parallelize the aggregation request. We give the data to the front end and everyone is happy.
It would seem that all is well, what could go wrong?
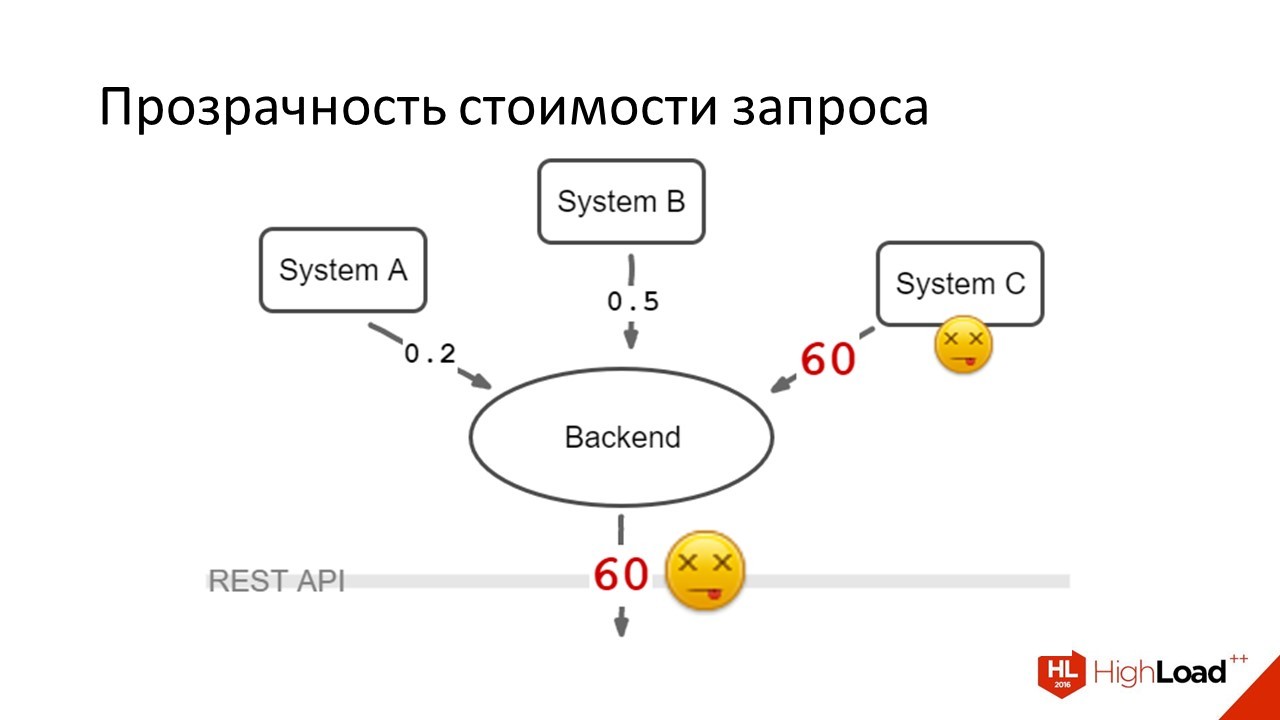
One of the systems suddenly dies - moreover, it dies in a rather nasty way, when instead of immediately honestly answering that the system is unavailable, it hangs by timeout.
This happens in those days when the load on the system as a whole - when we have the most users. Users joyfully see that their loading spinner does not disappear, they press F5, we send new requests, everything is bad.
What did we do in this case
The first thing we did was lower the timeouts. It became like this:
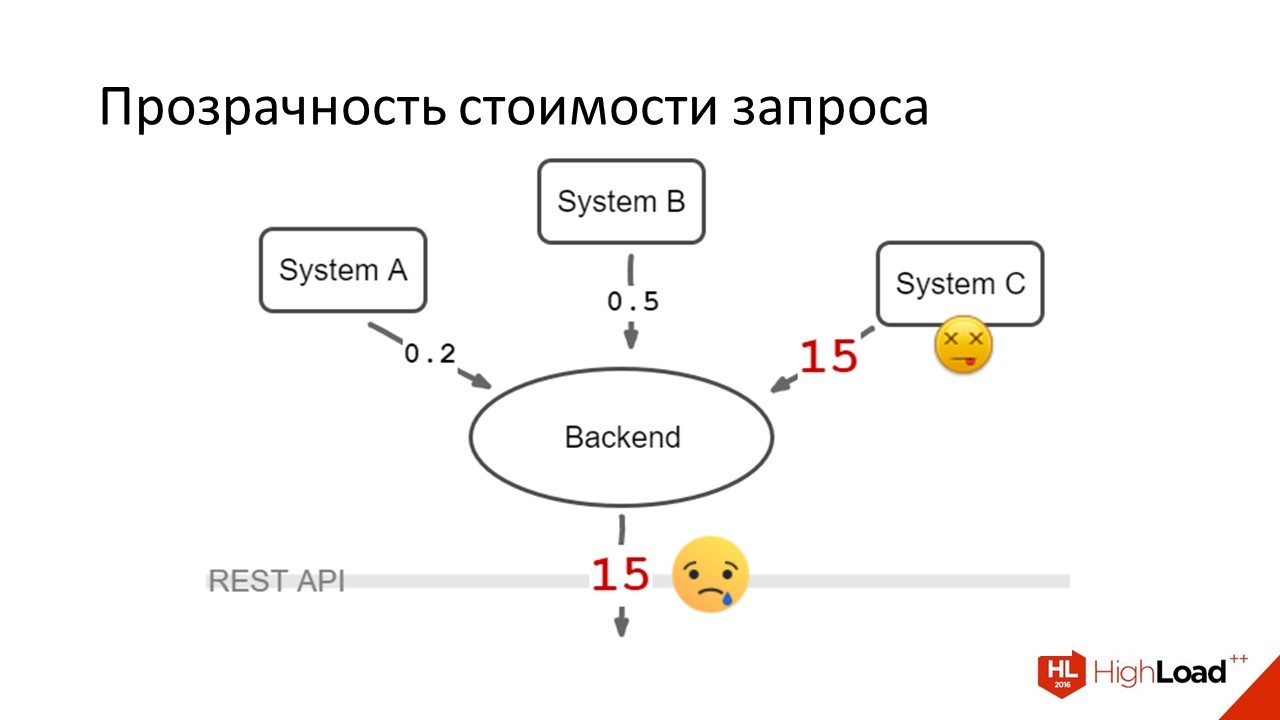
Users began to wait on average for their answers, but still they were very unhappy. Because 15 seconds where there used to be one is extremely difficult. The problem was rolling. System C worked at normal speed, then went to bed, then worked again.
It was not possible to lower the timeouts below this figure, because there were situations when it normally answered 10-12 seconds. It was rare.
But if we lowered the timeout, we would also make unhappy the users who fell into this tail of the response time.
The first decision was made on the same day. It improved the situation, but still it remained bad. What was the right global solution?
We did like this:
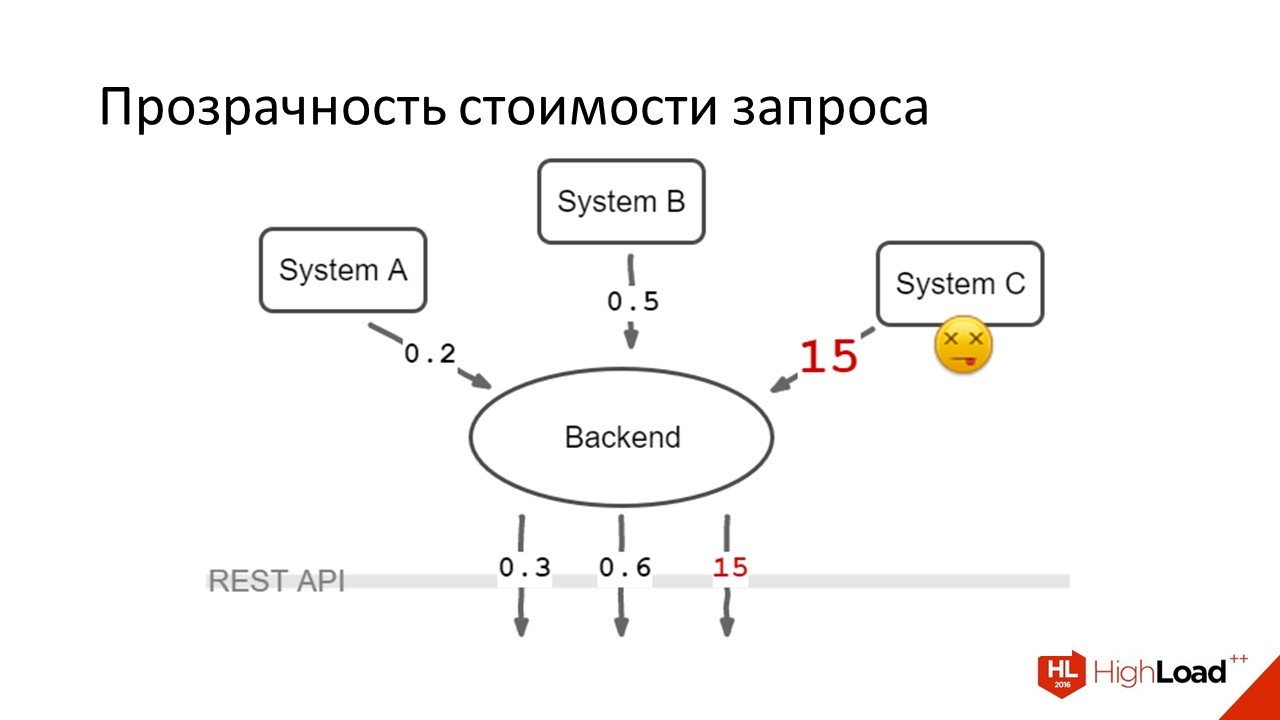
Through the REST API, requests were sent in which it was written: the client sent the data from which system he wants to receive, three requests were sent in parallel, the data was aggregated on the client. It turned out that those 80% of users who had enough data from system A and B to work, they were happy. Those users (20%) who also needed data from system C - they continued to suffer. But suffering 20% is much better than suffering absolutely everyone.
What ideas would you like to illustrate with this case
This is the case when it was possible for everyone to accelerate very much.
Firstly, optimization is often an additional work, it is a deterioration of the code. From the point of view of complexity, it is clear that it is more difficult to aggregate data on the front end - you need to make parallel requests, you need to handle errors, you need to multiply the business logic for data aggregation into all our front-ends.
In the case when we are working with a difficult scenario, where productivity is critical for the user, this is sometimes necessary. That is why it is so important to measure performance, because if you begin to perform such heroism anywhere where it will be a little slower, you can spend a lot of effort in vain. That was the first thought.
Second thought.There is a wonderful principle of encapsulation, which says that "we must hide insignificant details behind the API and not show them to the client."
If we want to have a fast system, we should not encapsulate the cost of operations. In a situation where we have an abstract API that returns only all the data at once and it can only do this very expensively and we want to have a fast client. We had to break the principle of encapsulation in this place and make it so that we had the opportunity to send cheap requests and there was the possibility of an expensive request. These were different parameters of one call.
I would like to tell you a few thoughts about using Pagination, about the pros / cons, the experience gained.
In the era of web 1.0, there were a lot of places where you could see interfaces that show 10-20-50 entries and endless page listing: search engines, forums, whatever.
Unfortunately, this thing crawled into a very large number of APIs. Why "Unfortunately? Despite the fact that the solution is old and proven - they all more or less know how to work with it, there are problems that I want to talk about.
First, remember the Yandex issuing screen, which says that there were 500 thousand results in 0.5 seconds.

Figures from the air - I'm sure Yandex is faster.
One of the cases that I saw when in order to show the first page, a data sample cost 120 milliseconds - and calculating the total amount of data that fit into the search criteria cost 450 milliseconds. Attention question: for the user, is it true that there are n results in all - is it 4 times more important than the data on the first page?
Almost always not. I would like it if the data is not very important for the user, then their receipt was either as cheap as possible, or this data should be excluded from the interface.
Here you can significantly improve this case by refusing to show the total number of results - writing a lot of results. Suppose there was a case when we are in this situation, instead of writing that “100 results out of 1200 are shown,” we began to write that “the total number of results is more than 100, please specify the search criteria if you want to see something else” .
This is not the case in all systems, so measure before changing anything.
What other problems are there
From the point of view of usability, even when we don’t go to the server for the next page - all the same, in well-arranged user interfaces, it is not often that the user needs to go somewhere far for data.
For example, going to the second page of Google and Yandex personally, I only come from despair, when I searched, I didn’t find, tried to formulate it differently, I also didn’t find it, I tried the third, fourth option - and here I can already get on the second page of these search options, but I don’t remember when I last did it.
Who in the last month at least once visited the second page of Google or Yandex? A lot of people.
In any case, the first or second page. It may be necessary to simply show more data at once, but there is no reason why your user may need to go to the 50th page in a normally made interface. There are issues with usability in pagination.
Another very painful problem. What will you do if the data set falling into the sample has changed between page requests?
This is especially true for applications that do not have such a reliable network or frequent offline.
On mobile, it's generally hard. On the web, which is sharpened by the ability to work offline, is also not easy. There begins a very curly and peculiar logic on how we can invalidate the data of previous pages - what should we do if the data of the first page is partially shown on the second, how can we sew these pages. It's complicated.
There are many articles on how to do this and there is a solution. I just want to warn that if you go this way - know this problem and evaluate in advance what its solution will be for you. It is rather unpleasant.
In all cases where I had to work, we usually refused pagination at the design stage, or did a rough prototype, and then remade it for something. I managed to get away from the problem before we began to face it.
To summarize
I want to say that pagination, especially in the form of endless scrolling, is quite appropriate in a number of situations. For example, we are doing some kind of news feed. VKontakte feed, where a user winds it up and down for entertainment purposes, without trying to find something specific, is just one of those cases where pagination, with endless scrolling, will work great.
If you have some kind of business interface, and there we are not talking about the flow of events - but it is about finding objects with which you need to interact, objects more or less long-term living. Most likely there is another UI solution that allows you not to have these problems with the API and which allows you to make a more convenient interface.
Want to go towards pagination? Think about what it will cost to choose the total number of elements and whether it is possible to do without them. And think about how you deal with synchronization issues that change between data pages.
Let's talk about the next problem - it is very simple.
We have 10 interface elements that we show the user:

In the normal case, we will make 1 request, get all the data, show.
What will happen if we did not think?
We will make 1 request for the list, then we go separately for each element of the list, we will cut this data on the client and show it.
The problem is very old - it came back from SQL databases, perhaps before SQL it existed somewhere too. She continues to exist now.
There are two very simple reasons why this is happening.
Either we made an API and didn’t think about what the interface would be and therefore we didn’t include enough data in the API or we, while making the interface, didn’t think what data the API could give us and included too much. The solutions are also quite simple.
We either add data to the request and learn to get what we need to display with one request, or we remove some data on individual objects either in the details page, or do some kind of right panel where you select the item and are loaded and shown to you data.
There are no cases when it makes sense to work like this and make lists more than one request for data.
Let's imagine that we have added a lot of data. We will immediately encounter the following problem:

We have a list. To display it, we need one amount of data, but we actually load 10 times more. Why it happens?
Very often, the API is designed according to the principle that we give exactly the same representations of objects to lists as with a detailed request. We have some page detail of the object on 10 screens, with a bunch of attributes, and all this we get in one request. In the list of objects we use the same representation. Why is this bad?
The fact that such a request can be more expensive and the fact that we download a lot of data over the network, which is especially true for all kinds of mobile applications.
How personally I struggled with this
An API is being made that allows you to give two versions for each object of this type: short and full. The list request in the API gives short versions and this is enough for us to draw the interface. For the detail page we request full.
It is important here that in every object there is a sign of whether it represents a multiple or full version. Because, if we have a lot of optional fields, the business logic by definition, “do we already have a full version of the object or should it be requested” can become quite curly. This is not necessary.
You just need a field that you can check.
Let's talk about how to cache?
In general, for the ecosystem that I described: backend, REST API, frontend. There are three levels of caching. Something caches the server, something can be cached at the HTTP level, something can be cached on the client.
From the point of view of the developer’s frontend, there is no server cache. This is just some tricky magic that server developers use to make the backend work fast.
Let's talk about what we can influence.
HTTP cache. How is he good?
It is good because it is an old generally accepted standard that everyone knows, which implements almost all customers. We get a ready-made implementation both on the client and on the server, without the need to write some code. The maximum that can be required is to tune something.
What is the problem
The HTTP cache is quite limited in that there are standards and if your case is not provided for in it, then sorry, you won’t do it. It must be done programmatically in this case.
Another feature. Data invalidation in the HTTP cache occurs through a server request, which can slow down the work somewhat, especially on mobile networks. Basically, when you have your own cache you don't have this problem.
A number of keywords you need to know about how the HTTP cache works. I don’t have much time. Just say - read the specification, everything is there.
About client cache. He has the pros / cons of exactly the opposite. This is the fastest response time, the most flexible cache - but it needs to be written. It must be written so that it works in more or less the same way on all your clients. In addition - there is no finished specification where everything is written, you need to come up with something.
General recommendation
If an HTTP cache is suitable for your scenario, use it - if not, then cache on the client with a clear understanding that these are some additional costs.
Some simple client-side caching methods that you personally had to use.
All that can be calculated by a pure function can be cached by a set of arguments and used as a key to the calculated value. Lodash has a memoize () function, very convenient, I recommend it to everyone.
Further - there is an opportunity at the transport level. That is, you have some kind of library that makes REST requests and provides you with a data abstraction layer. There is an opportunity at its level to write a cache, in the background to add data to memory or local storage and at the next request do not go after them if they are there.
I do not recommend doing this, because in my experience it turned out that we essentially duplicate the HTTP cache and write the additional code ourselves, without any advantages - but having a bunch of problems, bugs, incompatible versions of the cache, problems with invalidation and a bunch of other amenities . Moreover, such a cache, if it is transparent and is done at the transport level, it does not give anything regarding HTTP.
A makeshift software cache that lets you ask if it has data allows you to disable something — a good thing. It requires some effort in implementation, but allows you to do everything very flexibly.
Finally, the thing that I highly recommend. This is an In-memory database - when your data is not just randomly scattered in the front-end application, but there is some kind of single storage that provides you with only one copy of all the data and which allows you to write some simple queries. Also very comfortable. Also works well as a caching strategy.
A few words on how to invalidate the client cache.
First, the usual TTL. Each record has a lifetime, the time is over - the record is dead.
You can pick up web sockets and listen to server events. But we must remember that this web socket can fall off, and we will not know about it right away.
And finally - you can listen to some interface things to listen to. For example, if we paid in a web bank for a mobile phone from a card, probably the cache in which the balance of this card is stored can be disabled.
These things also allow you to invalidate the client cache.
One thing to keep in mind: it's all unreliable! True data live only on the server!
Do not try to play master replication while developing front-end applications.
This produces a lot of problems. Remember that the data on the server makes your life easier.
A few simple things that didn't go elsewhere
What prevents the frontend from the point of view of the API faster?
Dependence of requests when we cannot send the next requests without results from the previous. That is, in the place where we could send three requests in parallel - we are forced to get the result from the first, process, from them we will collect the url of the second request, send, process, collect the url of the third request, send, process.
We got triple latency - where there could be a single. Out of the blue. No need to do this.
Data in any format except JSON. I must say right away that this applies only to the web - on mobile applications everything can be more complicated. There is no reason on the web to use non-JSON data in the REST API.
Finally, some things when we break the semantics of HTTP caching. For example, we have the same resource with several different addresses in different sessions, so caching does not work for us. If this is not all, then we do not have a number of simple problems and can spend more time on making our application better.
Let's summarize
How to make API good?
- A good API is designed by all teams using and developing it. Given their common interests.
- We first measure the speed of the application, and then we are engaged in optimization.
- We allow you to do through the API not only expensive - abstract requests, but also cheap concrete ones.
- We design the data structure of the API based on the structure of the UI so that there is enough data, but not much superfluous.
- We use caches correctly and we don’t make any simple mistakes that I talked about.
That's all. Ask questions?