Overview of AI & ML solutions in 2018 and forecasts for 2019: Part 1 - NLP, Computer Vision
- Transfer
Hello! I present to you a translation of the article Analytics Vidhya with an overview of events in the field of AI / ML in 2018 and trends in 2019. The material is quite large, so it is divided into 2 parts. I hope that the article will interest not only profile specialists, but also those interested in the topic of AI. Enjoy reading!Article NavigationЧасть 1
— Natural Language Processing (NLP)
— Тренды в NLP на 2019 год
— Компьютерное зрение
— Тренды в машинном зрении на 2019 год
Часть 2
— Инструменты и библиотеки
— Тренды в AutoML на 2019 год
— Reinforcement Learning
— Тренды в Reinforcement Learning на 2019 год
— AI для хороших мальчиков – движение к “этичному” AI
— Этические тренды в AI на 2019 год
Introduction
The last few years for AI enthusiasts and machine learning professionals have been in pursuit of a dream. These technologies are no longer niche, have become mainstream and are already affecting the lives of millions of people right now. AI ministries have been created in different countries [ more here - approx. trans.] and allocated budgets to keep up with this race.
The same is true for data science professionals. A couple of years ago, you could feel comfortable knowing a couple of tools and techniques, but this time has passed. The number of recent events in data science and the amount of knowledge that is required to keep up with the times in this area are astounding.
I decided to take a step back and look at developments in some key areas in the field of artificial intelligence from the point of view of data science experts. What breakthroughs have occurred? What happened in 2018 and what to expect in 2019? Read this article to get answers!
PS As in any forecast, my personal conclusions are presented below, based on attempts to combine the individual fragments into the whole picture. If your point of view is different from mine, I will be glad to know your opinion about what else might change in data science in 2019.
Areas that we will address in this article:
- Natural Language Proces (NLP)
- Computer vision
- Tools and libraries
- Reinforcement Learning
- Ethics problems in AI
Natural Language Processing (NLP)
Making cars to make out words and sentences always seemed like an impossible dream. There are a lot of nuances and peculiarities in languages that are sometimes difficult to understand even for people, but the year 2018 has become a real turning point for NLP.
We saw one stunning breakthrough after another: ULMFiT, ELMO, OpenAl Transformer, Google BERT, and this is not a complete list. The successful application of transfer learning (the art of applying pre-trained models to data) has opened the doors to the application of NLP in a variety of tasks.
Transfer learning - allows you to adapt a previously trained model / system to your specific task using a relatively small amount of data.Let's look at some of these key developments in more detail.
ULMFiT
Designed by Sebastian Ruder and Jeremy Howard (fast.ai), ULMFiT was the first framework to receive transfer learning this year. For the uninitiated, the abbreviation ULMFiT means “Universal Language Model Fine Tuning”. Jeremy and Sebastian rightly added the word “universal” in ULMFiT - this framework can be applied to almost any NLP task!
The best thing about ULMFiT is that you don’t need to train models from scratch! Researchers have already done the most difficult thing for you - take it and use it in your projects. ULMFiT exceeded other methods in six text classification tasks.
You can read tutorial from Pratik Joshi [Pateek Joshi - approx. Trans.] on how to start applying ULMFiT for any task on text classification.
ELMo
Guess what ELMo stands for? Short for Embeddings from Language Models [attachments from language models - approx. trans.]. And ELMo attracted the attention of the ML community immediately after the release.
ELMo uses language models to get attachments for each word, and also takes into account the context in which the word fits into a sentence or paragraph. Context is the most important aspect of NLP, in the implementation of which most developers have previously failed. ELMo uses bidirectional LSTM to create attachments.
Long short-term memory (LSTM) is a type of recurrent neural network architecture proposed in 1997 by Sepp Hochreiter and Jürgen Schmidhuber. Like most recurrent neural networks, an LSTM network is universal in the sense that, with a sufficient number of network elements, it can perform any calculation that a regular computer is capable of, which requires an appropriate matrix of weights, which can be considered as a program. Unlike traditional recurrent neural networks, the LSTM network is well adapted to learning on the tasks of classifying, processing and predicting time series in cases where important events are separated by time lags with indefinite duration and boundaries.Like ULMFiT, ELMo qualitatively improves performance in solving a large number of NLP tasks, such as analyzing text moods or answering questions.
- source. Wikipedia
Google BERT
Quite a few experts say that the release of BERT marked the beginning of a new era in the NLP. Following the ULMFiT and ELMo BERT took the lead, demonstrating high performance. As the original announcement reads: “BERT is conceptually simple and empirically powerful.”
BERT showed outstanding results in 11 NLP tasks! View SQuAD test results:
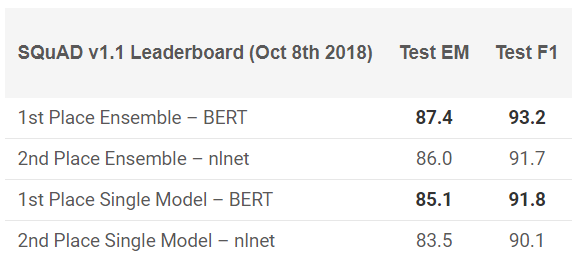
Want to try? You can use reimplementation on PyTorch, or TensorFlow code from Google and try to repeat the result on your machine.
PyText from Facebook
How could Facebook stay away from this race? The company offers its own open-source NLP framework called PyText. As follows from a study published by Facebook, PyText increased the accuracy of interactive models by 10% and reduced training time.
PyText actually stands behind several Facebook proprietary products, such as Messenger. So working with it will add a good item to your portfolio and the invaluable knowledge that you will undoubtedly receive.
You can try it yourself, download the code from GitHub .
Google duplex
It’s hard to believe that you haven’t heard about Google Duplex yet. Here is a demo, which has long flashed in the headlines:
Since this is a Google product, there is a small chance that sooner or later the code will be published for everyone. Of course, this demonstration raises many questions: from ethical to privacy issues, but we'll talk about this later. For now, just enjoy how far we have come from ML in recent years.
Trends in the NLP for 2019
Who better than Sebastian Ruder himself can give an idea of where the NLP is heading in 2019? Here are his conclusions:
- The use of pre-trained language attachment models will become ubiquitous; Advanced models without support will be very rare.
- Pre-trained views appear that can encode specialized information that complements the nesting of the language model. We will be able to group different types of pre-trained representations depending on the requirements of the task.
- There will be more work in the field of multilingual applications and multilingual models. In particular, based on interlanguage attachments of words, we will see the emergence of deep pre-trained interlanguage representations.
Computer vision

Today, computer vision is the most popular area in the field of deep learning. It seems that the first fruits of technology have already been received and we are at the stage of active development. Regardless of whether this image or video, we are seeing the emergence of a variety of frameworks and libraries that easily solve the problem of computer vision.
Here is my list of the best decisions that could be seen this year.
Exit BigGANs
Ian Goodfellow designed GANs in 2014, and the concept spawned many diverse applications. Year after year we observed how the original concept was being finalized for use on real-life cases. But one thing remained the same until this year - computer-generated images were too easily distinguishable. There was always some inconsistency in the frame, which made the difference very obvious.
In recent months, there have been shifts in this direction, and, with the creation of BigGAN , such problems can be solved once and for all. Look at the images generated by this method:

Not armed with a microscope, it is difficult to say what is wrong with these images. Of course, everyone decides for himself, but there is no doubt that the GAN changes the way that digital images (and video) are perceived.
For reference: these models were first trained on the ImageNet data set, and then on the JFT-300M, to demonstrate that these models are well transferred from one dataset to another. Here is a link to a page from the GAN mailing list explaining how to visualize and understand the GAN.
Fast.ai model learned on ImageNet in 18 minutes
This is a really cool implementation. There is a widespread belief that, to perform deep learning tasks, you will need terabytes of data and large computational resources. The same is true for learning a model from scratch on ImageNet data. Most of us thought the same way before several people on fast.ai could not prove to everyone the opposite.
Their model yielded 93% accuracy with an impressive 18 minutes. The hardware that they used, described in detail in their blog , consisted of 16 public AWS cloud instances, each with 8 NVIDIA V100 GPUs. They built an algorithm using fast.ai and the PyTorch library.
The total cost of assembly was only 40 dollars! In more detail, Jeremy described their approaches and methods here . This is a common victory!
NVIDIA's vid2vid
In the past 5 years, image processing has achieved great success, but what about the video? Methods for converting from a static frame to a dynamic frame turned out to be a bit more complicated than expected. Can you take a sequence of frames from a video and predict what will happen in the next frame? Such studies have been before, but the publications were vague at best.

NVIDIA decided to make its decision publicly available at the beginning of this year [2018 - approx. lane], which was positively appreciated by society. The goal of vid2vid is to deduce the display function from a given input video to create an output video that transmits the content of the input video with incredible accuracy.
You can try their implementation on PyTorch, take it to GitHub here .
Trends in machine vision for 2019
As I mentioned earlier, in 2019 we will rather see the development of trends in 2018, rather than new breakthroughs: self-driving cars, face recognition algorithms, virtual reality, and more. You can not agree with me, if you have another point of view or additions, share it, what else can we expect in 2019?
The issue of drones, awaiting the approval of politicians and the government, can finally get the green light in the United States (India is far behind in this matter). Personally, I would like more research to be done in real-world scenarios. Conferences like CVPR and ICML highlight recent advances in this area, but how close to reality projects are is not very clear.
“Visual question answering” and “visual dialog systems” can finally come up with a long-awaited debut. These systems are not able to generalize, but it is expected that we will soon see an integrated multimodal approach.
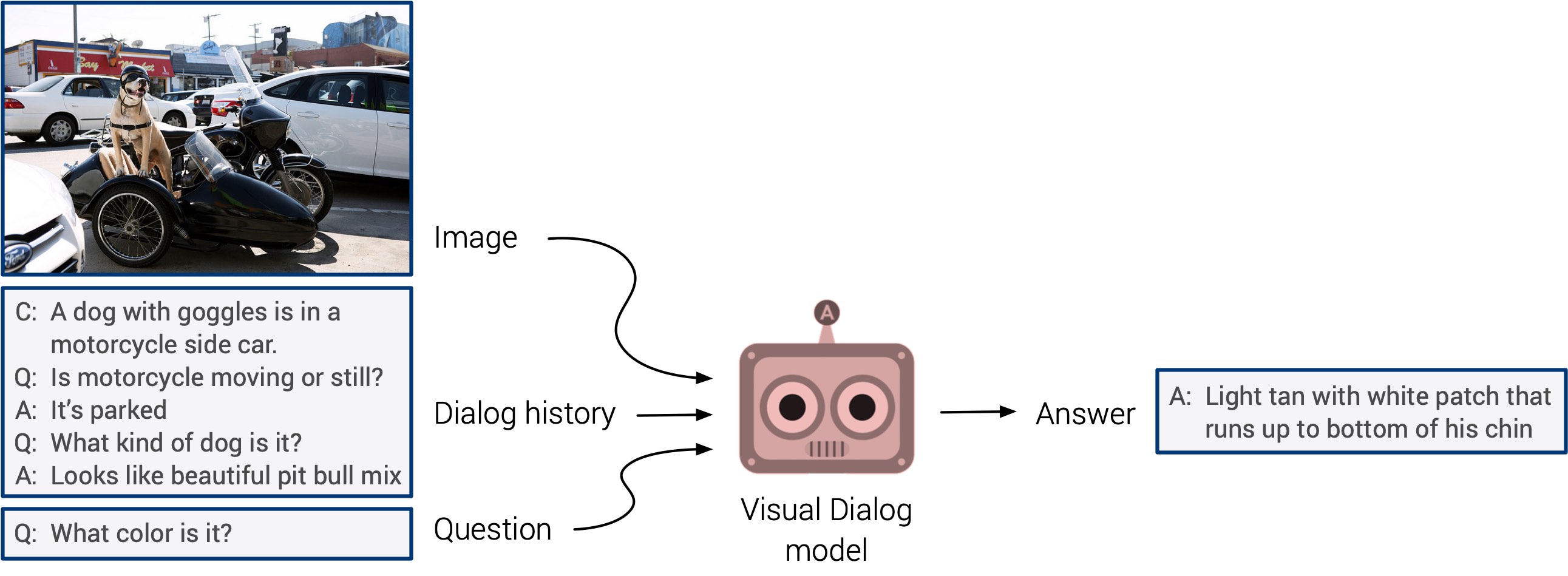
Self-study came to the fore this year. I can argue that next year it will find application in much more research. This is a really cool direction: the signs are determined directly from the input data, instead of wasting time manually marking the images. Keep your fingers crossed!