Cognitive Services & LUIS: Introduction to Natural Language Recognition
- Transfer
In this article, we’ll talk about understanding the language (linguistic computing, such as labeling, parsing, and so on) and pay special attention to two APIs: Linguistic Analysis API and Intelligent Speech Recognition Service (LUIS). If you like English as much as Russian and are fond of learning artificial intelligence, welcome to cat.

First, a little help. Service of the Microsoft Services the Cognitive (developed by Microsoft Research unit) make it easy to work with intelligent algorithms. Even specialists unfamiliar with data mining theory can easily use ready-made APIs for application analytics.
The processing of linguistic information covers speech recognition, translation, analysis of the emotional coloring of statements, summary (possibly also in Microsoft Word), language formation, and so on. Microsoft Cognitive Services offers over 20 APIs designed to meet these challenges.
We hope this article helps you understand how speech recognition technologies work in Microsoft Cognitive Services.
Note. This article does not explain how to use these interfaces. For instructions, see the official documentation ( Linguistic Analysis API , LUIS ).
This API provides fundamental language parsing capabilities. It returns the result of parsing the original sentences in json format after performing the following operations.
Three types of linguistic analyzers are currently available.
This is the simplest analyzer that breaks sentences into tokens.
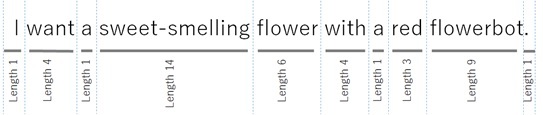
Below is the result of assigning tokens in the sentence I want a sweet-smelling flower with a red flowerbot ("I need a fragrant flower in a red pot") .
A lot of useful information has been missed in it, but this analyzer can be used together with others (by specifying several analyzers in one API call) and get the missing data from the general results.
A sentence is not only divided by spaces and punctuation marks, but is also divided into tokens according to context. For example, the API can correctly token the phrase what's your name? (same as what is your name? ), Mr. Williams (this is not a punctuation mark) and so on.
To extract keywords and analyze a sentence, you usually need to identify parts of speech (noun, verb, and so on). For example, if you want to highlight keywords with emotional coloring and evaluate the emotional background, the adjective should be the key word.
The parser analyzer detects these tags. Below is the result of the analyzer processing the entered sentence I want a sweet-smelling flower with a red flowerbot .

For more information, see Penn Treebank - Penn Speech Tags (University of Pennsylvania) .
A tag is assigned not only by words, but also by context. For example, the word dog usually acts as a noun, but is used as a verb in the next sentence (an example is taken from the Wikipedia section “ Part-time markup ”). The markup analyzer is suitable for this example. Simple markup errors are allowed in markup analysis.
The sailor dogs the hatch.
Suppose you own a flower online store and have an intelligent search engine configured in it. Buyers may enter the following queries.
"I want a red fragrant flower" (I want a red and sweet-smelling flower).
“I want a sweet-smelling flower except for red flowers.”
“I want a sweet-smelling flower with a red flowerbot.”
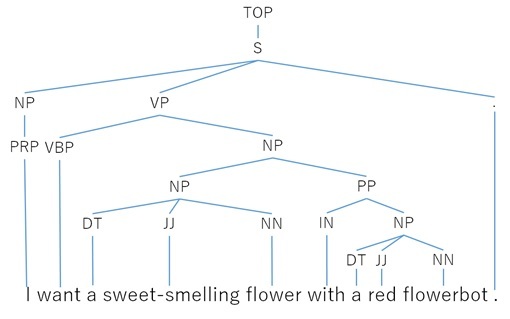
We see that in each sentence completely different objects are described. But if you use a parser analyzer (previous), you will not notice the difference. In this case, you will need an analyzer of the grammar of the components. Below is the result of the analyzer processing the same sentenceI want a sweet-smelling flower with a red flowerbot ("I need a fragrant flower in a red pot") .
For more information, see the article “ Penn Treebank II Tags - MIT ”.
As we see, the result is a tree structure. For example, “in a red pot” is a subordinate phrase for “fragrant flower” .
The grammar analyzer (previous) provides a lot of useful information, but it will still be difficult for you to understand the tree structure in the program code.
The Intelligent Speech Recognition Service (LUIS) is not only for parsing, like the Linguistic Analysis API. It gives a direct answer to some application scripts related to understanding the language, and allows you to use your program code in the business logic of the application.
Suppose, for example, that you have an application for booking airline tickets. Its interface contains a form with the fields “Departure point”, “Point of arrival” and “Date / time”. Using LUIS, you can extract the entered values from sentences in a natural language (for example, “I need a flight from Yekaterinburg to Moscow on July 23”) LUIS is perfect for language comprehension tasks. For example, this service allows you to directly extract the following values (point of departure, point of arrival, date / time), enclosed in brackets.
Note. As we see, in the second example, the value “point of departure” is not entered. But in this case, you can understand what parameters are missing (you need to enter them) for processing using LUIS, and ask the user to add the necessary information.
When using LUIS, you first need to register the scenarios (“intention”), for example, “Book a flight”, “Find out the weather” and so on. Next, for each intention, you should register sample sentences ("expressions") and train the result. (When you click the Teach button, LUIS examines the template.)
Now you can use the endpoint of the REST LUIS call. REST will produce in json format the result that matches the registered intent.
Note.LUIS is actively learning, so you can correct unallocated sentences.
LUIS understands not only words, but also the context of a sentence. For example, if you enter “Book a flight there and there on October 29,” the word there and there will be analyzed as the destination. At LUIS, you need to get a registered intention in advance. Therefore, this service is not suitable for solving specific problems, for example, searching in the natural language, answers to special questions (special correspondence), and so on. Moreover, LUIS only extracts the target key phrases, but does not analyze them. Consider the following example.
“I need a red pot that matches red flowers for my mom.”
LUIS can extract the phrase “a pot that blends with red flowers” as key, but it's not the same as “a pot and red flowers.” If you want to analyze this phrase, that is, examine the needs of a particular client, use the Linguistic Analysis API.
Note.The name of the text analysis API in Microsoft Cognitive Services is reminiscent of a parsing language, but this API simply evaluates the emotional coloring (satisfaction or dissatisfaction of a person). Remember that this interface does not analyze emotions (joy, sadness, anger, etc.), as the emotions API does (also from Microsoft Cognitive Services), and as a result we get a scalar value (degree of emotional coloring). You can also extract a key phrase that affects emotional coloring. For example, if you record a customer’s voice and want to find out what he doesn’t like about your services, you can find out the probable reasons for dissatisfaction by highlighting key phrases (“premises”, “employees”, and so on).
By the way, a few days ago the news came outabout updates in Cognitive Services and two cases of their application: Human Interact uses CRIS and LUIS, so that people can communicate in the virtual world; Prism Skylab uses the Computer Vision API to analyze images from security cameras to identify specific events.
1. Development on R: secrets of cycles .
2. How to choose algorithms for machine learning Microsoft Azure (recall that Azure can be tried for free ).
3. A series of articles "Deep Learning" .
If you see an inaccuracy in the translation, please report this in private messages.
First, a little help. Service of the Microsoft Services the Cognitive (developed by Microsoft Research unit) make it easy to work with intelligent algorithms. Even specialists unfamiliar with data mining theory can easily use ready-made APIs for application analytics.
The processing of linguistic information covers speech recognition, translation, analysis of the emotional coloring of statements, summary (possibly also in Microsoft Word), language formation, and so on. Microsoft Cognitive Services offers over 20 APIs designed to meet these challenges.
We hope this article helps you understand how speech recognition technologies work in Microsoft Cognitive Services.
Note. This article does not explain how to use these interfaces. For instructions, see the official documentation ( Linguistic Analysis API , LUIS ).
Linguistic Analysis API
This API provides fundamental language parsing capabilities. It returns the result of parsing the original sentences in json format after performing the following operations.
- Search for available analyzers (call REST API).
- Perform analysis (parsing) through the selected analyzer (REST API call).
Three types of linguistic analyzers are currently available.
Token Analyzer (PennTreebank3 - Regular Expressions)
This is the simplest analyzer that breaks sentences into tokens.
Below is the result of assigning tokens in the sentence I want a sweet-smelling flower with a red flowerbot ("I need a fragrant flower in a red pot") .
A lot of useful information has been missed in it, but this analyzer can be used together with others (by specifying several analyzers in one API call) and get the missing data from the general results.
{
"analyzerId": "08ea174b-bfdb-4e64-987e-602f85da7f72",
"result": [
{
"Len": 52,
"Offset": 0,
"Tokens": [
{
"Len": 1,
"NormalizedToken": "I",
"Offset": 0,
"RawToken": "I"
},
{
"Len": 4,
"NormalizedToken": "want",
"Offset": 2,
"RawToken": "want"
},
{
"Len": 1,
"NormalizedToken": "a",
"Offset": 7,
"RawToken": "a"
},
{
"Len": 14,
"NormalizedToken": "sweet-smelling",
"Offset": 9,
"RawToken": "sweet-smelling"
},
{
"Len": 6,
"NormalizedToken": "flower",
"Offset": 24,
"RawToken": "flower"
},
{
"Len": 4,
"NormalizedToken": "with",
"Offset": 31,
"RawToken": "with"
},
{
"Len": 1,
"NormalizedToken": "a",
"Offset": 36,
"RawToken": "a"
},
{
"Len": 3,
"NormalizedToken": "red",
"Offset": 38,
"RawToken": "red"
},
{
"Len": 9,
"NormalizedToken": "flowerbot",
"Offset": 42,
"RawToken": "flowerbot"
},
{
"Len": 1,
"NormalizedToken": ".",
"Offset": 51,
"RawToken": "."
}
]
}
]
}A sentence is not only divided by spaces and punctuation marks, but is also divided into tokens according to context. For example, the API can correctly token the phrase what's your name? (same as what is your name? ), Mr. Williams (this is not a punctuation mark) and so on.
Frequency Partitioning Analyzer (PennTreebank3 - cmm)
To extract keywords and analyze a sentence, you usually need to identify parts of speech (noun, verb, and so on). For example, if you want to highlight keywords with emotional coloring and evaluate the emotional background, the adjective should be the key word.
The parser analyzer detects these tags. Below is the result of the analyzer processing the entered sentence I want a sweet-smelling flower with a red flowerbot .
{
"analyzerId": "4fa79af1-f22c-408d-98bb-b7d7aeef7f04",
"result": [
[
"PRP",
"VBP",
"DT",
"JJ",
"NN",
"IN",
"DT",
"JJ",
"NN",
"."
]
]
}PRP : personal pronoun.
VBP : verb.
DT : defining word.
JJ : adjective.
NN : a noun in the singular or plural.
IN : preposition or subordinate conjunction.
For more information, see Penn Treebank - Penn Speech Tags (University of Pennsylvania) .
A tag is assigned not only by words, but also by context. For example, the word dog usually acts as a noun, but is used as a verb in the next sentence (an example is taken from the Wikipedia section “ Part-time markup ”). The markup analyzer is suitable for this example. Simple markup errors are allowed in markup analysis.
The sailor dogs the hatch.
Component Grammar Analyzer (PennTreebank3 - SplitMerge)
Suppose you own a flower online store and have an intelligent search engine configured in it. Buyers may enter the following queries.
"I want a red fragrant flower" (I want a red and sweet-smelling flower).
“I want a sweet-smelling flower except for red flowers.”
“I want a sweet-smelling flower with a red flowerbot.”
We see that in each sentence completely different objects are described. But if you use a parser analyzer (previous), you will not notice the difference. In this case, you will need an analyzer of the grammar of the components. Below is the result of the analyzer processing the same sentenceI want a sweet-smelling flower with a red flowerbot ("I need a fragrant flower in a red pot") .
{
"analyzerId": "22a6b758-420f-4745-8a3c-46835a67c0d2",
"result": [
"(TOP (S (NP (PRP I)) (VP (VBP want) (NP (NP (DT a) (JJ sweet-smelling) (NN flower)) (PP (IN with) (NP (DT a) (JJ red) (NN flowerbot))))) (. .)))"
]
}S : a simple narrative sentence.
NP : nominal phrase.
VP : verbal phrase.
PRP : personal pronoun.
VBP : verb.
PP : prepositional phrase.
DT : defining word.
JJ : adjective.
NN : a noun in the singular or plural.
IN : preposition or subordinate conjunction.
For more information, see the article “ Penn Treebank II Tags - MIT ”.
As we see, the result is a tree structure. For example, “in a red pot” is a subordinate phrase for “fragrant flower” .
Intelligent Speech Recognition Service (LUIS)
The grammar analyzer (previous) provides a lot of useful information, but it will still be difficult for you to understand the tree structure in the program code.
The Intelligent Speech Recognition Service (LUIS) is not only for parsing, like the Linguistic Analysis API. It gives a direct answer to some application scripts related to understanding the language, and allows you to use your program code in the business logic of the application.
Suppose, for example, that you have an application for booking airline tickets. Its interface contains a form with the fields “Departure point”, “Point of arrival” and “Date / time”. Using LUIS, you can extract the entered values from sentences in a natural language (for example, “I need a flight from Yekaterinburg to Moscow on July 23”) LUIS is perfect for language comprehension tasks. For example, this service allows you to directly extract the following values (point of departure, point of arrival, date / time), enclosed in brackets.
- Book a flight from {Ekaterinburg} to {Moscow} on 10/29/2016.
- Book me a flight to {Moscow} on October 29th.
- I need a flight from {Yekaterinburg} to {Moscow} {next Saturday}.
- Etc.
Note. As we see, in the second example, the value “point of departure” is not entered. But in this case, you can understand what parameters are missing (you need to enter them) for processing using LUIS, and ask the user to add the necessary information.
When using LUIS, you first need to register the scenarios (“intention”), for example, “Book a flight”, “Find out the weather” and so on. Next, for each intention, you should register sample sentences ("expressions") and train the result. (When you click the Teach button, LUIS examines the template.)
Now you can use the endpoint of the REST LUIS call. REST will produce in json format the result that matches the registered intent.
Note.LUIS is actively learning, so you can correct unallocated sentences.
LUIS understands not only words, but also the context of a sentence. For example, if you enter “Book a flight there and there on October 29,” the word there and there will be analyzed as the destination. At LUIS, you need to get a registered intention in advance. Therefore, this service is not suitable for solving specific problems, for example, searching in the natural language, answers to special questions (special correspondence), and so on. Moreover, LUIS only extracts the target key phrases, but does not analyze them. Consider the following example.
“I need a red pot that matches red flowers for my mom.”
LUIS can extract the phrase “a pot that blends with red flowers” as key, but it's not the same as “a pot and red flowers.” If you want to analyze this phrase, that is, examine the needs of a particular client, use the Linguistic Analysis API.
Note.The name of the text analysis API in Microsoft Cognitive Services is reminiscent of a parsing language, but this API simply evaluates the emotional coloring (satisfaction or dissatisfaction of a person). Remember that this interface does not analyze emotions (joy, sadness, anger, etc.), as the emotions API does (also from Microsoft Cognitive Services), and as a result we get a scalar value (degree of emotional coloring). You can also extract a key phrase that affects emotional coloring. For example, if you record a customer’s voice and want to find out what he doesn’t like about your services, you can find out the probable reasons for dissatisfaction by highlighting key phrases (“premises”, “employees”, and so on).
By the way, a few days ago the news came outabout updates in Cognitive Services and two cases of their application: Human Interact uses CRIS and LUIS, so that people can communicate in the virtual world; Prism Skylab uses the Computer Vision API to analyze images from security cameras to identify specific events.
Latest Articles
1. Development on R: secrets of cycles .
2. How to choose algorithms for machine learning Microsoft Azure (recall that Azure can be tried for free ).
3. A series of articles "Deep Learning" .
If you see an inaccuracy in the translation, please report this in private messages.