Caching data in web applications. Using memcached
- Tutorial

Yuri Krasnoshchek (Delphi LLC, Dell)
I'll tell you a little about caching. Caching, in general, is not very interesting, you take and cache, so I’ll also tell you about memcached, quite intimate details.

About caching, let's start by asking you to develop a factory for the production of omnonium torsiometers. This is a standard task, the main thing is to make a boring face and say: "Well, we will apply a typical scheme for the development of a factory."
In general, it is closer to factory production, i.e. where did the problem come from? The factory works very fast, it produces our torsiometers. And for calibrating each device, you need a clean omnonium, for which you need to fly somewhere far away and, accordingly, while we are in the process of extracting this omnonium, the devices are not calibrated, and, in fact, all production stops. Therefore, we are building a warehouse near the factory. But it is not free.

We pass to terminology. Just for us to talk about caching in one language, there is a fairly well-established terminology.

The source is called origin ; warehouse volume, i.e. cache size - cache size ; when we go to the warehouse for a sample of the desired shape, and the storekeeper gives out what we requested - this is called cachehit , and if he says: “There is no such thing”, it is called cache miss .

Data - our omnonium - has freshness , literally - it's freshness. Fresheness is used everywhere. As soon as the data loses its natural freshness, it becomes stale data .

The process of checking the data for validity is called validation , and the moment we say that the data is unusable and discard it from the warehouse is called invalidation .

Sometimes such an offensive situation happens when we have no space left, but we better keep a fresh omnonium, so we find the oldest one by some criteria and throw it away. This is called eviction .
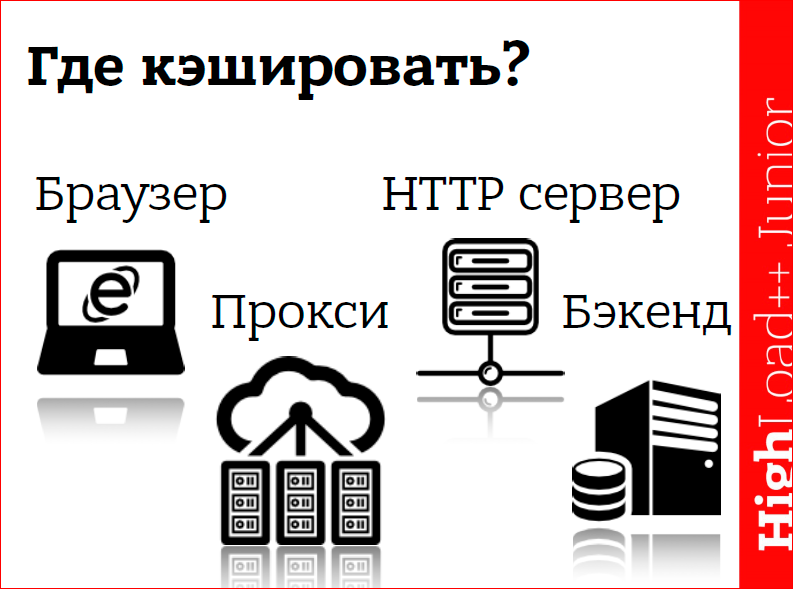
The scheme is such that from our browser to the backend there are a lot of links in the chain. Question: where to cache? In fact, you have to cache absolutely everywhere. And, whether you want it or not, the data will be cached, i.e. the question, rather, is how can we influence this?

First you need to find good data for caching. Due to the fact that we are doing some kind of cache, we have another intermediate link in the chain, and it is not necessary that the cache speeds up something. If we select data poorly, then, in the best case, it will not affect the speed, and in the worst, it will also slow down the process of production, the entire system.
It makes no sense to cache data that changes frequently. You need to cache data that is used frequently. The size of the data matters, i.e. if we decide to cache a movie in the blu-ray memory - it's cool, we will get it out of memory very quickly, but most likely we will then have to pump it somewhere over the network, and it will be very slow. Such a large amount of data is not commensurate with the speed of delivery, i.e. it makes no sense for us to keep such data in our memory. We can keep the disk, but you need to compare in speed.
By the way, you can google programming latencies. There, on the site, all standard delays are given very well, for example, the speed of access to the CPU cache, the speed of sending Round Trip packets in the data center. And when you design, pretend to be something, it’s good to look, it is very clearly shown there how much time and in comparison with what it takes.
These are ready-made recipes for caching:

These are relevant HTTP Headers:

I will talk a little about some, but, actually, I need to read about it. Basically, on the web, the only way we can influence caching is by correctly installing these headers.

Expires used before. We set freshness for our data, we literally say: “That's it, this content is valid until such a date.” And now this header needs to be used, but only as fallback, because there is a newer header. Again, this chain is very long, you can get on some kind of proxy that understands only this header - Expires.
The new header, which is now responsible for caching, is Cache-Control:

Here you can specify immediately the freshness, the validation mechanism, and the invalidation mechanism, indicate whether this is public data or private, how to cache them ...
By the way, no-cache is very interesting. By name, it’s obvious that we say: cache everywhere, please cache as you like, if we say no-cache. But every time we use some data from this content, for example, we have a form, and we submit in this form, we say that in any case all your cached data is not relevant, you need to double-check it.
If we want, in general, to turn off caching for content, then we say "no-store":

These "no-cache", "no-store" are very often used for authentication forms, i.e. we don’t want to cache unauthenticated users so that we don’t get weird, that they don’t see too much or there is no misunderstanding. And by the way, about this Cache-Control: no-cache ... If, for example, the Cache-Control header is not supported, then its behavior can be simulated. We can take header Expires and set some date in the past.
These all headers, including even Content-Length, are relevant for the cache. Some caching proxies may simply not even cache if there is no Content-Length.
Actually, we come to memcached, to the cache on the backend side.

Again, we can cache in different ways, i.e. we got some data from the database, we do something in the code with them, but, in fact, it’s a cache — we got it once to reuse it many times. We can use some kind of component in the code, a framework. This component for caching is needed because we must have reasonable limits on our product. It all starts with the fact that some kind of operating engineer comes and says: "Explain to me the requirements for your product." And you must tell him that it will be so much RAM, so much disk space, such and such predicted growth of the application ... Therefore, if we cache something, we want to have limitations. Suppose the first restriction that we can easily provide is by the number of elements in the cache. But if we have elements of different sizes, then we want to close it with a fixed amount of memory. Those. we say some cache size - this is the most important limit, the most important boundary. We use a library that can do such a thing.

Well, or we use a separate caching service, generally stand-alone. Why do we need some kind of separate caching service? Most often, the backend is not something so monolithic, it is one process. We have some disparate processes, some scripts, and if we have a separate caching service, that is, the entire backend infrastructure can see this cache and use the data from it. It's great.
The second point - we have the opportunity to grow. For example, we put one service, we run out of cash, we put another service. Naturally, this is not free, i.e. “And today we decided to scale” cannot happen. It is necessary to plan such things in advance, but a separate caching service gives such an opportunity.

The cache also gives us availability almost for free. Suppose we have some data in the cache, and we are trying to get this data from the cache. Something falls somewhere in us, and we pretend that nothing fell, we give data from the cache. It may at this time be lifted somehow, and there will even be availability.
Actually, we got to memcached. Memcached is a typical noSQL.

Why is noSQL caching good?
By structure. We have a regular hash table, i.e. we get low latency. In the case of memcached and similar key-value storage, it's not just low latency, but in big-O notation, we have the complexity of most operations - this is a constant from one. And so we can say that we have some kind of temporary constraint. For example, a request takes no more than 10 ms., I.e. you can even agree on some kind of contract based on these latency. It's good.
Most often, we cache whatever is horrible - pictures mixed up with CCS'om with JS'om, some fragments of forms rendered, something else. It is not clear what data, and the key-value structure makes it pretty easy to store. We can make a notation that we have account.300.avatar - this is a picture, and it works there. 300 is the account ID in our case.
An important point is that the code of storage itself is simplified if we have no-key key-value, because the worst thing that can be is that we will somehow mess up or lose data. The less code that works with data, the less chance there is to spoil it, so a simple cache with a simple structure is good.

About memcached key-value. Can be specified with expiration data. Supported work in a fixed amount of memory. You can set 16-bit flags with a value arbitrarily - they are transparent for memcached, but most often you will work with memcached from some client, and most likely, this client has already grabbed these 16 bits for itself, i.e. he uses them somehow. There is such an opportunity.
memcached can work with vikshins support, i.e. when we run out of space, we push the oldest data, add the newest. Or we can say: “Do not delete any data”, then when adding new data it will return an out of memory error - this is the “-M” flag.

There is no structured unified documentation for memcached, it is best to read the protocol description. Basically, if you type in “memcached protocol” on Google, this will be the first link. The protocol describes not only the formats of the commands - sending what we send, what comes in response ... It describes that this command, it will behave like this, like that, i.e. there are some corner cases.
Briefly on the commands:

get - get data;
set / add / delete / replace - how do we build this data, i.e.:
- set is to save, add new, or replace,
- add is add only if there is no such key,
- delete - delete;
- replace - replace only if there is such a key, otherwise - an error.
It is in an environment when we have a shard. When we have a cluster, this does not guarantee us any consistency. But with one instance, consistency can be supported by these commands. It is more or less possible to build such constraints.
prepend / append - we take this and insert some piece before our data or insert some piece after our data. They are not very efficiently implemented inside memcached, i.e. you will still have a new piece of memory allocated, there is no functional difference between them and set .
We can according to retain, specify any expiration and then we can move the data command touch , and we will prolong the lives specifically here to this key, ie, he will not be deleted.
There are increment and decrement commands - incr / decr . It works as follows: you erase some number as a string, then says incr and give some value. It sums up. Decrement is the same, but subtracts. There is an interesting point, for example, 2 - 3 = 0, from the point of view of memcached, i.e. it automatically handles the underflow, but it does not allow us to make a negative number, in any case, zero will return.

The only command with which you can make some kind of consistency is cas (this is an atomic compare and swap operation). We compare two of some values, if these values coincide, then we replace the data with new ones. The value we are comparing is the global counter inside
memcached, and every time we add data there, this counter increments, and our key-value pair gets some value. With the gets command we get this value and then in the cas command we can use it. This team has all the same problems that ordinary atoms have, i.e. you can make a bunch of raise conditions interesting, especially since memcached has no guarantees on the order in which commands are executed.
Memcached has a “-C” key - it turns off cas . Those. what's happening? This counter disappears from the key-value pair, if you add the “-C” key, then you save 8 bytes, because it is a 64-bit counter at each value. If your values are small, the keys are small, then this can be a significant savings.
How to work with memcached efficiently?

It is designed to work with many sessions. Many are hundreds. Those. starts from hundreds. And the fact is that in terms of RPS - request per second - you won’t get much out of memcached using 2-3 sessions, i.e. in order to rock it, you need a lot of connections. Sessions should be long-playing, because creating a session inside memcached is a rather expensive process, so you hooked once and that’s it, you need to keep this session.
Requests must be batch, i.e. we must send requests in batches. For the get-command, we have the opportunity to transfer several keys, this should be used. Those. we say get and key-key-key. For the rest of the teams there is no such possibility, but we can still do batch, i.e. we can form a request at ourselves, locally, on the client side using several commands, and then send this request as a whole.
memcached is multithreaded, but it is not very multithreaded. She has a lot of locks inside, quite ad-hoc, so more than four threads cause very strong contention inside. I don’t need to believe, you need to double-check everything yourself, you need to do some experiments with live data, on a live system, but a very large number of threads will not work. We need to play around, pick up some optimal number with the “-t” key.
memcached supports UDP. This is a patch that was added to memcached by facebook. The way facebook uses memcached - they make all the sets, i.e. all data modification over TCP, and they get get's over UDP. And it turns out, when the data volume is significantly large, then UDP gives a serious gain due to the fact that the packet size is smaller. They manage to pump more data through the grid.
I told you about incr / decr - these commands are ideal for storing backend statistics.

Statistics in HighLoad is an irreplaceable thing, i.e. you won’t be able to understand what, how, where a particular problem comes from, if you don’t have statistics, because after half an hour of work “the system behaves strangely” and that’s all ... To add specifics, for example, every thousandth request is fails, we need some then statistics. The more statistics there are, the better. And even, in principle, in order to understand that we have a problem, we need some statistics. For example, the backend returned a page in 30 ms, started in 40, it is impossible to distinguish with a look, but our performance slipped by a quarter - it's terrible.
Memcached itself also supports statistics, and if you are already using memcached in your infrastructure, then memcached statistics are part of your statistics, so you need to look there, look there to understand if the backend uses the cache correctly, whether it caches data well .
First, there are hits and misses for each team. When we turned to the cache and the data was given to us, hit on this command was increased. For example, we made a delete key, we will have delete hits 1, so for each command. Naturally, it is necessary that hits were 100%, misses were not at all. Must watch. Let's say we can have a very high miss ratio. The most banal reason is that we are simply climbing the wrong data. It may be that we allocated a little memory for the cache, and we constantly reuse the cache, i.e. we added some data, added, added, at some point there the first data fell out of the cache, we climbed after them, they are no longer there. We climbed after the others, they are not there either. And that's how it goes. Those. either from the backend side it is necessary to reduce the load on memcached, or you can increase the memory size with the “-m” parameter,
Evictions is a very important point. The situation I'm talking about, it will be visible from the fact that the evictions rate will be very high. This is the amount when suitable data is not expired, i.e. they are fresh, good are ejected from the cache, then the number of evictions grows.
I said that batch should be used. How to choose the size of batch'a? There is no silver bullet, it is necessary to select all this experimentally. Everything depends on your infrastructure, on the network you use, on the number of instances and other factors. But when we have a very large batch ... Imagine that we are doing a batch, and all the other connections are standing and waiting for the batch to complete. This is called starvation - fasting, i.e. when the rest of the endors are starving and waiting for one fatty one to complete. To avoid this, there is a mechanism inside memcached that interrupts the execution of batch by force. This is implemented rather rudely, there is a key “-R”, which says how many teams can execute one connection in a row. The default value is 20. And when you look at the statistics, if your conn_yields stat is somehow very high, it means that you use batch more than memcached can chew, and it has to forcibly often switch the context of this connection. Here you can either increase the size of the batch with the “-R” key, or not use such batch from the backend side.
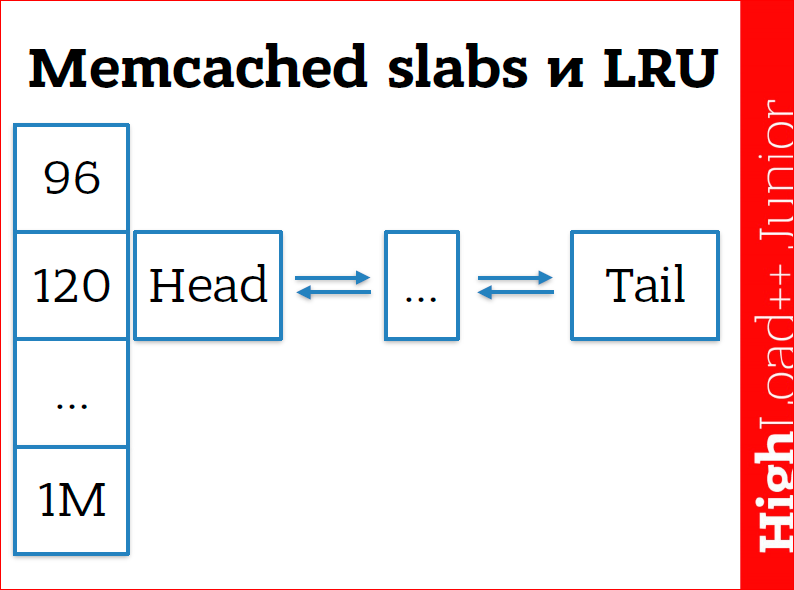
I also said that memcached erases the oldest data from memory. So, I lied. This is actually not the case. Memcached has its own memory manager to work effectively with this memory in order to throw away these atoms. It is designed in such a way that we have slabs (literally "stub"). This is an established term in programming memory managers for some piece of memory, i.e. we just have some big chunk of memory, which in turn is divided into pages. Pages inside memcached is MB, so you cannot create there key-value data of more than one MB. This is a physical limitation - memcached cannot create data more than one page. And, in the end, all pages are beaten into chunks, this is what you see in the picture at 96, 120 - they are of a certain size. Those. 96 MB pieces go, then 120 pieces go, with a coefficient of 1.25, from 32 to 1 Mb. There is a doubly linked list within this piece. When we add some new value, memcached looks at the size of this value (this is the key + value + expiration + flags + system information that memcached is needed (about 24-50 bytes)), selects the size of this chunk and adds ours to the doubly linked list data. She always adds data to head. When we access some data, memcached takes them out of the doubly linked list and throws them into head again. Thus, those data that are not used much creep into tail, and as a result they are deleted. which memcached is needed (about 24-50 bytes)), selects the size of this chunk and adds our data to the doubly linked list. She always adds data to head. When we access some data, memcached takes them out of the doubly linked list and throws them into head again. Thus, those data that are not used much creep into tail, and as a result they are deleted. which memcached is needed (about 24-50 bytes)), selects the size of this chunk and adds our data to the doubly linked list. She always adds data to head. When we access some data, memcached takes them out of the doubly linked list and throws them into head again. Thus, those data that are not used much creep into tail, and as a result they are deleted.
If we do not have enough memory, then memcached starts to delete memory from the end. The list recently used mechanism works within the same chunk, i.e. these lists are allocated for some size, this is not a fixed size - this is a range from 96 to 120 will fall into the 120th chunk, etc. We cannot influence this mechanism from the memcached side, only from the backend side we need to select this data.

You can see the statistics for these slabs. It’s easiest to look at memcached statistics - the protocol is completely textual, and we can connect with Telnet, type stats, Enter, and it will throw out a “sheet”. In the same way, we can type stats slabs, stats items - this is basically similar information, but stats slabs gives a picture that is more blurred in time, there are stats - what happened, what happened over the entire period that memcached worked, and stat items - there is more about what we have now, how much is what. In principle, both of these things need to be looked at, and taken into account.

So we got to scaling. Naturally, we set up another memcached server - great. What do we do? Somehow you have to choose. Either we decide on the client side which server we will join and why. If we have availability, then everything is simple - they wrote down there, wrote down here, read from somewhere, it doesn’t matter, you can Round Robin, whatever you like. Or we put some kind of broker, and for the backend, it turns out that it looks like one memcached instance, but in fact, a cluster is hidden behind this broker.
What is the broker used for? To simplify the backend infrastructure. For example, we need to transport servers from the data center to the data center, and all clients should be aware of this. Or we can make a hack for this broker, and everything will be transparent for the backend.
But latency grows. 90% of requests are network round trip, i.e. memcached internally processes the request in microseconds - this is very fast, and data travels over the network for a long time. When we have a broker, we have another link, i.e. still takes longer. If the client immediately knows which memcached cluster he should go to, then he will get the data quickly. And, actually, how does the client find out which memcached cluster it should go to? We take, consider the hash from our key, take the remainder from dividing this hash by the number of instances in memcached and go to this cluster - the easiest solution.
But we have added another cluster to the infrastructure, which means that now we need to crash the entire cache, because it has become inconsistent, not valid, and re-calculating everything is bad.

There is a mechanism for this - a consistent hashing ring. Those. what are we doing? We take a hash of the value, all possible hash values, for example int32, take all the possible values and place it as if on the watch dial. So. we can configure - say, hashes from such-and-such to such-and-such go to this cluster. We configure the ranges and configure the clusters that are responsible for these ranges. Thus, we can shuffle the server as we like, i.e. we will need to change this ring in one place, regenerate it, and the servers, clients or router, broker - they will have a consistent idea of where the data is.
I would also like to say a little about data consistency. As soon as we have a new link, as soon as we cache somewhere, we have duplicate data. And we have a problem so that this data is consistent. Because there are many such situations - for example, we write data to the cache - local or remote, then we go and write this data to the database, at this moment the database falls, we lost the connection with the database. In fact, logically, we do not have this data, but at the same time, clients read them from the cache - this is a problem.
memcached is not suitable for consistancy of some solutions, i.e. it is more of a solution for availability, but at the same time, there are some possibilities with cas for something to farm.
Contacts
" Cachelot@cachelot.io
" http://cachelot.io/
This report is a transcript of one of the best presentations at a training conference of developers of highly loaded systems HighLoad ++ Junior .
Also, some of these materials are used by us in an online training course on the development of highly loaded systems HighLoad. Guide is a chain of specially selected letters, articles, materials, videos. Already in our textbook more than 30 unique materials. Get connected!
Well, the main news is that we started preparing the spring festival " Russian Internet Technologies ", which includes eight conferences, including HighLoad ++ Junior .
Only registered users can participate in the survey. Please come in.
How is it all right - through E or E?
- 62.9% Caching (via E) 143
- 37% Caching (through E) 84