About C language and performance
- Transfer

If a programmer is well acquainted only with high-level languages, such as PHP, then it is not so easy for him to master some ideas that are characteristic of low-level languages and are critical for understanding the capabilities of information and computing processes. For the most part, the reason is that in low- and high-level languages we solve different problems.
But how can you consider yourself a professional in any (high-level) language, if you don’t even know how the processor works, how it performs calculations, or in an efficient way? Today, automatic memory management is becoming the main problem in most high-level languages, and many programmers come to its solution without a sufficient theoretical base. I am sure that knowledge of low-level processes helps a lot in developing effective high-level programs.
The programs of many school programming courses still begin with the development of the basics of assembler and C. This is extremely important for future programmers who will find this knowledge very useful in their future careers. High-level languages are constantly and strongly changing, and the intensity and frequency of changes in low-level languages is an order of magnitude lower.
I believe that in the future there will be a bunch of applications for low-level programming. Since it all starts with the basics, there will be no need for people creating these fundamentals so that others can build new levels on them, as a result of creating complete, useful and effective products.
Do you really think that the Internet of things will be developed in high-level languages? And what about future video codecs? VR apps? Networks? Operating Systems? Games? Automotive systems like autopilots, collision warning systems? All this, like many other products, is written in low-level languages like C or immediately in assembler.
You can observe the development of "new" architectures, for example, very interesting ARM processors, which are in 98% of smartphones. If today you use Java to create Android applications, it is only because Android itself is written in Java and C ++. And the Java language - like 80% of modern high-level languages - is written in C (or C ++).
Language C intersects with some related languages. But they use an imperative paradigm, and therefore they are not widespread or not so developed. For example, Fortran, belonging to the same “age group” as C, is more productive in some specific tasks. A number of specialized languages can be faster than C in solving purely mathematical problems. But still, C remains one of the most popular, universal, and effective low-level languages in the world.
Let's get started
For this article, I will use a machine with an X86_64 processor running Linux. We will look at a very simple C program that sums 1 billion bytes from a file in less than 0.5 seconds. Try this in any of the higher-level languages - you won’t get any performance closer to C. Even in Java, using JIT, with parallel computing and a good model of memory usage in user space. If programming languages do not directly access machine instructions, but are some kind of intermediate form (definition of high-level languages), then they will not be compared in performance with C (even using JIT). In some areas, the gap can be reduced, but in general, C leaves rivals far behind.
First, we will analyze the task in detail using C, then consider the X86_64 instructions and optimize the program using SIMD, a type of instruction in modern processors that allows you to process large amounts of data with one instruction in several cycles (several nanoseconds).
Simple C program
To demonstrate the capabilities of the language, I will give a simple example: open the file, read all bytes from it, sum them, and compress the resulting amount into one unsigned byte (i.e., there will be an overflow several times). And that’s it. Oh yes, and we will try to do all this as efficiently as possible - faster.
Go:
#include
#include
#include
#include
#include
#define BUF_SIZE 1024
int main(int argc, char **argv)
{
int f, i;
ssize_t readed;
unsigned char result = 0;
unsigned char buf[BUF_SIZE] = {0};
if (argc != 2) {
fprintf(stderr, "Использование: %s \n", argv[0]);
exit(-1);
}
f = open(argv[1], O_RDONLY);
if (f == -1) {
perror("Не могу открыть файл");
}
while ((readed = read(f, buf, sizeof(buf))) > 0) {
for (i=0; i < readed; i++) {
result += buf[i];
}
}
close(f);
printf("Чтение завершено, сумма равна %u \n", result);
return 0;
} For our example, take a 1 GB file. To create such a file with random data, we just use
dd:> dd if=/dev/urandom of=/tmp/test count=1 bs=1G iflag=fullblockNow we will transfer the file to our program (let's call it file_sum) as an argument:
> file_sum /tmp/file
Read finished, sum is 186You can add bytes in a variety of ways. But for efficiency you need to understand:
- How the CPU works and what it can do (what calculations it can do).
- How does the kernel of the OS (kernel) work.
In short: some knowledge of electronics and the low level of the OS on which our program is running is needed.
Remember the core
Here we will not delve into the core. But remember that we will not ask the processor to interact with the disk on which our file is stored. The fact is that in the yard is 2016, and we are creating the so-called user space programs (PPP). One definition says that such programs CANNOT directly access the equipment. When it becomes necessary to use equipment (access the memory, disk, network, card reader, and so on), the program using system callsasks the operating system to do this for her. System calls are OS features available for the RFP. We will not ask the disk if it is ready to process our request, ask it to move the head, read the sector, transfer data from the cache to main memory, and so on. All this is done by the OS kernel along with the drivers. If we needed to deal with such low-level things, then we would write a program of “kernel space” - in fact, a kernel module.
Why is that? Read my article on memory allocation . It explains that the kernel controls the simultaneous execution of several programs, not allowing them to crash the system or go into an irreversible state. With any instructions. To do this, the kernel puts the processor into the third protection ring mode. And in the third ring, the program cannot access the hardware mapped memory. Any such instructions will throw exceptions in the processor, like all attempts to access memory beyond completely specific boundaries. The kernel responds to an exception in the processor by running an Exception code. It returns the processor to a stable state and terminates our program with some kind of signal (possibly SIGBUS).
The third defense ring is the lowest privilege mode. All IFRs are executed in this mode. You can try it by reading the first two bits of the CS register in your X86 processor:
gdb my_file
(gdb) p /t $cs
$1 = 110011The first two bits (the least significant) indicate the current level of the protection ring. In this case, the third.
User processes operate in a strictly limited isolated environment, configured by the kernel, which itself runs in the zero ring (full privileges). Therefore, after the destruction of the user process, a memory leak is not possible. All data structures related to this are not directly accessible to user code. The kernel takes care of them at the end of the user process.
Let's get back to our code. We cannot control the performance of reading from disk, since the kernel, low-level file system, and hardware drivers are responsible for this. We will take advantage of the challenges
open()/read()and close(). I did not take the functions from libc ( fopen(), fread(),fclose()), mainly because they are wrappers for system calls. These wrappers can both improve and degrade overall performance: it all depends on what code is hidden behind these instructions and how they are used by the program itself. LibC is a beautifully designed and high-performance library (some of its key functions are written in assembler), but all these I / O functions need a buffer that you do not control, and they call read () as they see fit. And we need to completely control the program, so we turn directly to system calls. The kernel most often responds to a system call by calling the
read()file system, giving the hardware driver an I / O command. All these calls can be traced using Linux tracers, for example perf. For programs, system calls are costly because they result in a context switch - a transition from user space to kernel space. This should be avoided, since transitions require a significant amount of work from the kernel. But we need system calls! The slowest of them is read(). When it is done, the process will most likely be taken out of the execution queue on the CPU and put into I / O standby mode. When the operation completes, the kernel will return the process to the execution queue. This procedure can be controlled using flags passed to the open () call . As you can know, the kernel implements a buffer cache, which stores the recently read from the disk chunks of data from files. This means that if you run one program several times, then for the first time it may work most slowly, especially if it involves active I / O operations, as in our example. So to measure the time spent we will take data, for example, starting from the third or fourth launch. Or you can average the results of several runs.
Get to know your hardware and compiler better
So we know that it is not able to completely manage the performance of the three system calls:
open(), read()and close(). But let's trust the developers of the kernel space here. In addition, today many people use SSDs, so we can safely assume that our one-gigabyte file is considered fast enough. What else slows down the code?
A way to add bytes. It might seem that a simple summation cycle is enough for this. But I want to answer: get to know better how your compiler and processor work.
Let's compile the code head-on, without optimizations, and run it:
> gcc -Wall -g -O0 -o file_sum file_sum.cThen we profile using the command
time:> time ./file_sum /tmp/big_1Gb_file
Read finished, sum is 186
real 0m3.191s
user 0m2.924s
sys 0m0.264sRemember to run several times to warm up the kernel page cache. After several runs, it took me 3.1 seconds to sum one gigabyte with an SSD. Notebook processor - Intel Core i5-3337U @ 1.80 GHz, OS - Linux 3.16.0-4-amd64. As you can see, the most common X86_64 architecture. For compilation, I used GCC 4.9.2.
According to the data
time, most of the time (90%) we spent in user space. The time when the kernel does something on our behalf is the time it takes to make system calls. In our example: opening a file, reading and closing. Pretty fast, right? Note: the read buffer size is one kilobyte. This means that for a one gigabyte file you have to call
read()1024 * 1024 = 1,048,576 times. And if you increase the buffer to reduce the number of calls? Take 1 MB, then we will only have 1,024 calls. We’ll make the changes, recompile, run several times, profile:#define BUF_SIZE 1024*1024
.
> gcc -Wall -g -O0 -o file_sum file_sum.c
> time ./file_sum /tmp/big_1Gb_file
Read finished, sum is 186
real 0m3.340s
user 0m3.156s
sys 0m0.180sExcellent, it was possible to reduce from 264 to 180 ms. But do not get carried away by increasing the cache: the speed
read()has a certain limit, and the buffer is on the stack. Do not forget that the maximum stack size in modern Linux systems is 8 MB by default (can be changed). Try to call the kernel as little as possible. Programs that make heavy use of system calls typically delegate I / O calls to a dedicated thread and / or program I / O for asynchronous operation.
Faster, stronger (and not so much harder)
Why is byte addition taking so long? The problem is that we are asking the processor to execute it in a very inefficient way. Let's disassemble the program and see how the processor does it.
C is nothing without a compiler. This is only a human computer programming language. And to convert C code to low-level machine instructions, a compiler is required. Today, for the most part, we use C to create systems and solve low-level problems, because we want to be able to port code from one processor architecture to another without rewriting. That is why C. was developed in 1972.
So, without a compiler, C is an empty place. A poor compiler or its improper use can lead to poor performance. The same is true for other languages compiled into machine code, such as Fortran.
The processor executes machine code, which can be represented in the form of assembly language instructions . Using a compiler or debugger, assembler instructions are easily extracted from a C program.
Assembler is easy to master. It all depends on the architecture, and here we will consider only the most common version with X86 (for 2016 - X86_64).
The X86_64 architecture is also nothing complicated. It just has a HUGE amount of instructions. When I took the first steps in assembler (under Freescale 68HC11), then used several dozen instructions. And in X86_64 there are already thousands of them. The manuals at that time were the same as today: incomprehensible and verbose. And since there was no PDF then, I had to carry huge books with me.
Here, for example, Intel manuals for X86_64 . Thousands of pages. This is the primary source of knowledge for kernel developers and the lowest-level developers. And you thought that it would be possible to improve your online PHP manuals?
Fortunately, there is no need for our little program to read all of these digital tomes. The 80/20 rule applies here - 80% of the program will be done using 20% of the total number of instructions.
Here is the C code and the disassembled part that interests us (starting with the while () loop) compiled without optimizations using GCC 4.9.2:
#define BUF_SIZE 1024
int main(int argc, char **argv)
{
int f, i;
ssize_t readed;
unsigned char result = 0;
unsigned char buf[BUF_SIZE] = {0};
if (argc != 2) {
fprintf(stderr, "Использование: %s \n", argv[0]);
exit(-1);
}
f = open(argv[1], O_RDONLY);
if (f == -1) {
perror("Не могу открыть файл");
}
while ((readed = read(f, buf, sizeof(buf))) > 0) {
for (i=0; i < readed; i++) {
result += buf[i];
}
}
close(f);
printf("Чтение закончено, сумма равна %u \n", result);
return 0;
}
00400afc: jmp 0x400b26 < main+198>
00400afe: movl $0x0,-0x4(%rbp)
00400b05: jmp 0x400b1b < main+187>
00400b07: mov -0x4(%rbp),%eax
00400b0a: cltq
00400b0c: movzbl -0x420(%rbp,%rax,1),%eax
00400b14: add %al,-0x5(%rbp)
00400b17: addl $0x1,-0x4(%rbp)
00400b1b: mov -0x4(%rbp),%eax
00400b1e: cltq
00400b20: cmp -0x18(%rbp),%rax
00400b24: jl 0x400b07 < main+167>
00400b26: lea -0x420(%rbp),%rcx
00400b2d: mov -0xc(%rbp),%eax
00400b30: mov $0x400,%edx
00400b35: mov %rcx,%rsi
00400b38: mov %eax,%edi
00400b3a: callq 0x4005d0 < read@plt>
00400b3f: mov %rax,-0x18(%rbp)
00400b43: cmpq $0x0,-0x18(%rbp)
00400b48: jg 0x400afe < main+158>
00400b4a: mov -0xc(%rbp),%eax
00400b4d: mov %eax,%edi
00400b4f: callq 0x4005c0 < close@plt>See how inefficient the code is? If not, let me briefly tell you about assembler under X86_64 with comments on the dump above.
Assembler basics for X86_64
Here we will go upstairs, and for details refer to materials one , two and three .
We will operate with bytes and degrees 2 and 16.
- Each instruction is stored in memory at a specific address listed in the left column.
- Each instruction is unique and has a name (mnemonic): LEA - MOV - JMP and so on. There are several thousand instructions in modern X86_64 architecture.
- X86_64 is a CISC architecture. One instruction can be converted in the pipeline into several lower-level instructions, each of which sometimes requires several processor cycles (clock cycles) (1 instruction! = 1 cycle).
- Each instruction can accept a maximum of 0, 1, 2, or 3 operands. Most often 1 or 2.
- There are two main assembler models: AT&T (also called GAS) and Intel.
- At AT&T, you read INSTR SRC DEST.
- At Intel, you read INSTR DEST SRC.
- There are a number of other differences. If your brain is trained, then you can easily switch from one model to another. This is just the syntax, nothing more.
- More often used by AT&T, someone prefers Intel. For X86, AT&T uses GDB by default. Learn more about the AT&T model .
- X86_64 uses byte order from low to high (little-endian), so get ready to translate addresses as you read. Always group bytes.
- X86_64 does not allow memory-to-memory operations. To process the data you need to use some kind of register.
- $ means a static immediate value (for example, $ 1 is the value '1').
- % means access to the register (% eax - access to the EAX register).
- Parentheses - access to memory, an asterisk in C dereferences a pointer (record (% eax) means access to the memory area whose address is stored in the EAX register).
Registers
Registers are areas of fixed size memory in the processor chip. This is not RAM! Registers work much faster than RAM. If access to the RAM is performed in about 100 ns (bypassing all levels of the cache), then access to the register is done in 0 ns. The most important thing in programming a processor is to understand a scenario that repeats itself over and over again:
- Data is loaded from the RAM into the register: now the processor "has" a value.
- Something is done with the register (for example, its value is multiplied by 3).
- The contents of the register are sent back to RAM.
- If you want, you can move data from the register to another register of the same size.
I remind you that in X86_64 you cannot perform memory-to-memory accesses: you must first transfer data to the register.
There are dozens of registers. The most commonly used registers are “general purpose” - for calculations. The following “universal” registers are available in the X86_64 architecture: a, b, c, d, di, si, 8, 9, 10, 11, 12, 13, 14, and 15 (the set is different in 32-bit X86).
All of them are 64-bit (8 bytes), but they can be accessed in four modes: 64-, 32-, 16- and 8-bit. It all depends on your needs.
Register A - 64-bit access. RAX is 64-bit. EAX is 32-bit. AX is 16-bit. Low part: AL, high part: AH.
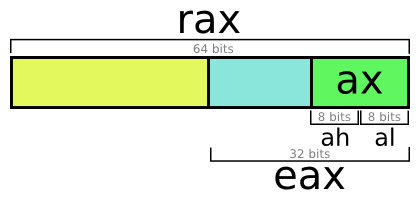
Everything is very simple. The processor is a stupid piece of silicon, it performs only the simplest operations with tiny portions of bytes. In general registers, you can access at least the byte, not the bit. Brief Dictionary:
- One byte = 8 bits, this is the least amount of information available. It is designated as BYTE.
- Double byte = 16 bits, denoted as WORD.
- Double double byte = 32 bits, denoted as DWORD (double WORD).
- 8 contiguous bytes = 64 bits, denoted as QWORD (quadruple WORD).
- 16 contiguous bytes = 128 bits, denoted as DQWORD (double quadruple WORD).
More information on the X86 architecture can be found at http://sandpile.org/ and the Intel / AMD / Microsoft websites. I remind you: X86_64 works a little differently than X86 (32-bit mode). Also read selected Intel manuals.
X86_64 code analysis
00400afc: jmp 0x400b26 JMP is an unconditional jump. Let's go to the address 0x400b26:
00400b26: lea -0x420(%rbp),%rcx
00400b2d: mov -0xc(%rbp),%eax
00400b30: mov $0x400,%edx
00400b35: mov %rcx,%rsi
00400b38: mov %eax,%edi
00400b3a: callq 0x4005d0 < read@plt>This code makes a system call
read(). If you read the call convention in X86_64 , you will see that most parameters are passed not in the stack, but in registers. This improves the performance of each function call in X86_64 Linux compared to 32-bit mode, when a stack is used for each call. According to the kernel system call table , the
read(int fd, char *buf, size_t buf_size)first parameter (file descriptor) should be passed to RDI, the second (buffer to fill) to RSI, and the third (buffer size to fill) to RDX.Consider the above code. It uses RBP (Register Base Pointer). RBP remembers the very beginning of the space of the current stack, while RSP (Register Stack Pointer, pointer to the register stack) remembers the top of the current stack, in case we need to do something with this stack. The stack is just a big chunk of memory allocated for us. It contains local function variables, variables
alloca(), return address, may contain function arguments, if there are several of them. The stack contains local variables of the function
main()that we are currently in:00400b26: lea -0x420(%rbp),%rcxLEA (Load Effective Address) is stored in RBP minus 0x420, right up to RCX. This is our buffer variable
buf. Note that LEA does not read the value after the address, only the address itself. Under GDB, you can print any value and perform calculations:> (gdb) p $rbp - 0x420
$2 = (void *) 0x7fffffffddc0Using
info registerscan display any register:> (gdb) info registers
rax 0x400a60 4196960
rbx 0x0 0
rcx 0x0 0
rdx 0x7fffffffe2e0 140737488347872
rsi 0x7fffffffe2c8 140737488347848
... ...We continue:
00400b2d: mov -0xc(%rbp),%eaxPut the value at the address specified in RBP minus 0xc - in EAX. This is most likely our variable
f . This can be easily confirmed:> (gdb) p $rbp - 0xc
$1 = (void *) 0x7fffffffe854
> (gdb) p &f
$3 = (int *) 0x7fffffffe854Move on:
00400b30: mov $0x400,%edxWe put in the EDX value 0x400 (1024 in decimal). This is
sizeof(buf): 1024, the third parameter read().00400b35: mov %rcx,%rsi
00400b38: mov %eax,%edi
00400b3a: callq 0x4005d0 < read@plt>Write the contents of RCX to RSI, the second parameter
read(). Write the contents of EAX to EDI, the third parameter read(). Then call the function read(). At each system call, its value is returned to register A (sometimes also to D).
read()returns a value ssize_tthat weighs 64 bits. Therefore, to read the return value, we need to analyze the entire register A. To do this, we will use RAX (64-bit reading of register A):00400b3f: mov %rax,-0x18(%rbp)
00400b43: cmpq $0x0,-0x18(%rbp)
00400b48: jg 0x400afe < main+158>Write the return value
read()from RAX to the address specified in RBP minus 0x18. A quick check confirms that this is our readedC-code variable . CMPQ (Compare Quad-Word, comparison of the quad WORD). Compare the value
readedwith the value 0. JG (Jump if greater, the transition by the condition "more"). Go to the address 0x400AFE. This is just a loop comparison
while()from our C code. We continue to read the buffer and go to the address 0x400AFE, this should be the beginning of the cycle
for().00400afe: movl $0x0,-0x4(%rbp)
00400b05: jmp 0x400b1b < main+187>MOVL (Move a Long, copy a long integer). We write LONG (32 bits) of value 0 to the address indicated in RBP minus 4. This
iis an integer variable in the C code, 32 bits, that is 4 bytes. Then it will be saved as the very first variable in the stack frame main()(represented by RBP). We go to the address 0x400B1B, there should be a continuation of the cycle
for().00400b1b: mov -0x4(%rbp),%eax
00400b1e: cltq
00400b20: cmp -0x18(%rbp),%rax
00400b24: jl 0x400b07 We write in EAX the value indicated in RBP minus 4 (probably an integer).
CLTQ (Convert Long To Quad). CLTQ works with register A. It extends EAX to a 64-bit integer value obtained by RAX.
CMP (Compare value). Compare the value in RAX with the value indicated at the address in RBP minus 0x18. That is, we compare the variable
ifrom the loop for()with the variable readed. JL (Jump if Lower, transition by the condition "less"). Go to the address 0x400B07. We are at the first stage of the cycle
for(), so yes, we are moving on.00400b07: mov -0x4(%rbp),%eax
00400b0a: cltq
00400b0c: movzbl -0x420(%rbp,%rax,1),%eax
00400b14: add %al,-0x5(%rbp)
00400b17: addl $0x1,-0x4(%rbp)
00400b1b: mov -0x4(%rbp),%eax
00400b1e: cltq
00400b20: cmp -0x18(%rbp),%rax
00400b24: jl 0x400b07 < main+167>And now for the fun part.
We write (MOV)
iin EAX (as mentioned above, ithis is –0x4 (% rbp)). Then we do CLTQ: expand to 64 bits. MOVZBL (MOV Zero-extend Byte to Long). Add zero byte to the long integer stored at the address (1 * RAX + RBP) minus 0x420, and write to EAX. It sounds complicated, but it's just math ;-) It turns out the calculation
buf[i]with a single instruction. This is how we illustrated the power of pointers in C: buf[i] — это buf + i*sizeof(buf[0])bytes. The resulting address is easily calculated in assembler, and compilers perform a bunch of mathematical calculations to generate such an instruction. By loading the value into EAX, we add it to
result:00400b14: add %al,-0x5(%rbp)Remember: AL is the low byte of an 8-byte RAX (RAX and AL are case A) - this
buf[i]is because it bufis of type char and weighs one byte. resultlocated at –0x5 (% rbp): one byte after i, located at a distance of 0x4 from RBP. This confirms that it resultis a char weighing one byte.00400b17: addl $0x1,-0x4(%rbp)ADDL (Add a long, add a long integer - 32 bits). Add 1 to
iAnd again we return to instruction 00400b1b: the loop
for().Brief summary
Are you tired? This is because you have no experience in assembler. As you can see, the decoding of assembler is just arithmetic at the elementary school level: add, extract, multiply, divide. Yes, assembler is simple, but very verbose. Feel the difference between “hard” and “verbose”?
If you want your child to become a good programmer, then do not make mistakes and do not limit him to studying mathematics with just reason 10. Train him to switch from one basis to another. Fundamental algebra can be fully understood only when you can imagine any quantities with any basis, especially 2, 8 and 16. I recommend using soroban for teaching children .
If you are not very confident in mathematics, it is only because your brain has always been trained only for operations with base 10. Switching from 10 to 2 is difficult, because these degrees are not multiple. And switching between 2 and 16 or 8 is easy. With practice, you can calculate most of the addresses in your mind.
So, our loop
for()needs six memory addresses. It was converted as is from the source C-code: a loop is executed for each byte with byte summation. For a one-gigabyte file, the cycle has to be performed 0x40000000 times, that is, 1,073,741,824.Even at 2 GHz (in CISC, one instruction! = One cycle), running a cycle 1,073,741,824 times takes up enough time. As a result, the code is executed for about 3 seconds, because the byte summation in the read file is extremely inefficient.
Let's vectorize everything with SIMD
SIMD - Single Instruction Multiple Data, single instruction, multiple data stream. That says it all. SIMD is a special instruction that allows the processor to work not with one byte, one WORD, one DWORD, but with several of them within the same instruction.
Meet SSE - Streaming SIMD Extensions, a streaming SIMD extension. You are likely familiar with abbreviations such as SSE, SSE2, SSE4, SSE4.2, MMX or 3DNow. So, SSEs are SIMD instructions. If the processor can work with multiple data at one time, then this significantly reduces the overall duration of the calculations.

When buying a processor, pay attention not only to the number of cores, cache sizes and clock speed. The set of supported instructions is also important. Which do you prefer: add each byte one byte after another, or add 8 bytes to 8 every two nanoseconds?
SIMD instructions can greatly speed up computations in the processor. They are used wherever parallel processing of information is allowed. Some of the applications are:
- The matrix calculations underlying graphics (but the GPU does it an order of magnitude faster).
- Data compression, when several bytes are processed at a time (formats LZ, GZ, MP3, Divx, H264 / 5, JPEG FFT and many others).
- Cryptography.
- Speech and music recognition.
Take, for example, Motion Estimation using Intel SSE 4 . This critical algorithm is used in every modern video codec. It allows you to predict the frame F + 1 based on motion vectors calculated from the base frame F. Thanks to this, you can only program the movement of pixels from one picture to another, and not encode the whole picture. A striking example is the wonderful H264 and H265 codecs, they have open source code, you can study it (just read about MPEG first).
Let's test:
> cat /proc/cpuinfo
processor : 2
vendor_id : GenuineIntel
cpu family : 6
model : 58
model name : Intel(R) Core(TM) i5-3337U CPU @ 1.80GHz
(...)
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm ida arat epb xsaveopt pln pts dtherm tpr_shadow vnmi flexpriority ept vpid fsgsbase smep ermsAll of these flags are for the most part supported by my processor instructions and instruction sets.
Here you can see sse, sse2, sse4_1, sse4_2, aes, avx.
AES is the foundation of AES encryption! Directly to the CPU using a bunch of specialized instructions.
SSE4.2 allows you to calculate the CRC32 checksum with one instruction, and with a few instructions to compare string values. The latest features
str()in the libC library are based on SSE4.2 , so you can grab a word from giant text so quickly.SIMD will help us
It's time to improve our C program with SIMD and see if it gets faster.
It all started with MMX technology, which added 8 new 64-bit registers, from MM0 to MM7. MMX appeared in the late 1990s, and partly because of it, the Pentium 2 and Pentium 3 were very expensive. Now this technology is completely irrelevant.
Different versions of SSE, up to the last SSE4.2, appeared in processors from about 2000 to 2010. Each subsequent version is compatible with previous ones.

Today the most common version is SSE4.2. It added 16 new 128-bit registers (in X86_64): from XMM0 to XMM15. 128 bits = 16 bytes. That is, by filling in the SSE register and doing some calculation with it, you will process 16 bytes at once.
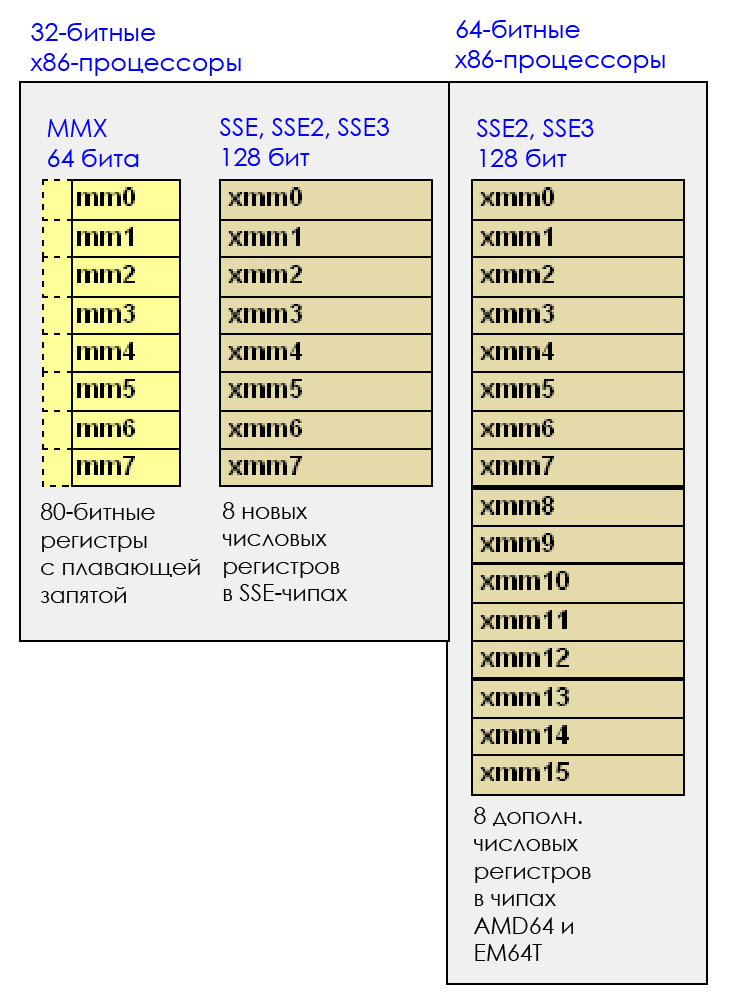
And if you process two SSE-registers, then this is 32 bytes at a time. It becomes interesting.
With 16 bytes per register, we can store (LP64 sizes):
- 16 bytes: sixteen C characters.
- Two 8-byte values: two long values from C or two numbers with double precision (double precision float).
- Four 4-byte values: four integer or four numbers with single precision (single precision float).
- Eight 2-byte values: eight short values from C.
For example:
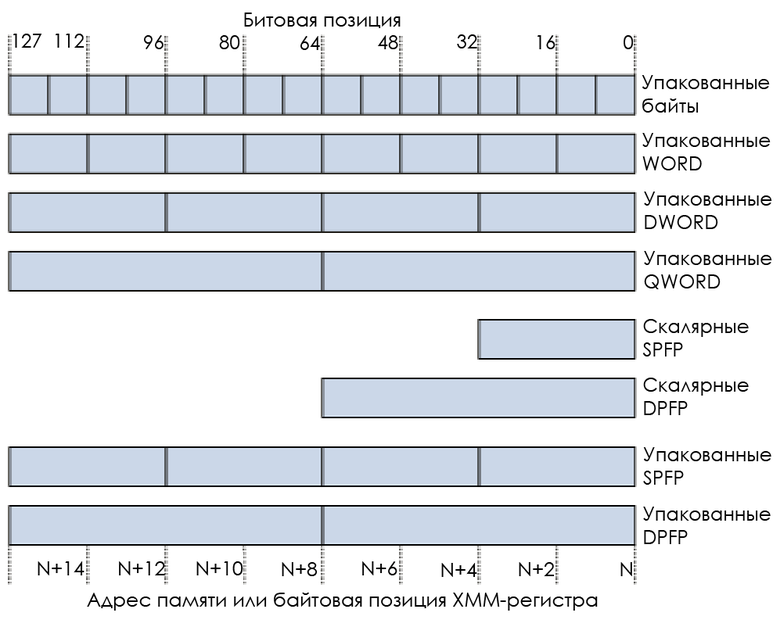
SIMDs are also called “vector” instructions because they work with a “vector” - an area filled with various tiny objects. A vector instruction simultaneously processes different data, while a scalar instruction processes only one piece of data.
In our program, you can implement SIMD in two ways:
- Write assembler code that works with these registers.
- Use Intel Intrinsics - an API that allows you to write C code, which when compiled is converted to SSE instructions.
I will show you the second option, and you will do the first as an exercise.
Patch our code:
#include
#include
#include
#include
#include
#include
#define BUF_SIZE 1024
int main(int argc, char **argv)
{
int f, i;
ssize_t readed;
__m128i r = _mm_set1_epi8(0);
unsigned char result = 0;
unsigned char buf[BUF_SIZE] __attribute__ ((aligned (16))) = {0};
if (argc != 2) {
fprintf(stderr, "Использование: %s \n", argv[0]);
exit(-1);
}
f = open(argv[1], O_RDONLY);
if (f == -1) {
perror("Не могу открыть файл");
}
while ((readed = read(f, buf, sizeof(buf))) > 0) {
for (i=0; i < readed; i+=16) {
__m128i a = _mm_load_si128((const __m128i *)(buf+i));
r = _mm_add_epi8(a, r);
}
memset(buf, 0, sizeof(buf));
}
for (i=0; i<16; i++) {
result += ((unsigned char *)&r)[i];
}
close(f);
printf("Чтение завершено, сумма равна %u \n", result);
return 0;
}
See the new tmmintrin.h header ? This is an Intel API. There is excellent documentation for him .
To store the summation result (cumulative), I decided to use only one SSE register and fill it with a line from memory. You can do otherwise. For example, take 4 registers (or all) at once, and then you will add 256 bytes in 16 operations: D
Remember the sizes of SSE registers? Our goal is to sum bytes. This means that we will use 16 separate bytes in the register. If you read the documentation, you will find out that there are many functions for “packing” and “unpacking” values in registers. They will not be useful to us. In our example, we do not need to convert 16 bytes to 8 WORD or 4 DWORD. We just need to calculate the amount. And in general, SIMD provides much more features than described in this article.
So now, instead of byte addition, we will add 16 bytes each.
In one instruction, we will process much more data.
__m128i r = _mm_set1_epi8(0);The previous expression prepares an XMM register (16 bytes) and fills it with zeros.
for (i=0; i < readed; i+=16) {
__m128i a = _mm_load_si128((const __m128i *)(buf+i));
r = _mm_add_epi8(a, r);
}Each cycle
for()should now increase the buffer not by 1 byte, but by 16. That is i+=16. Now we turn to the memory buffer
buf+iand point it to the pointer __m128i*. Thus, we take from the memory of a portion of 16 bytes. Using _mm_load_si128()write these 16 bytes to a variable a. Bytes will be written to the XMM register as “16 * one byte”. Now with the help we
_mm_add_epi8()add a 16-byte vector to our battery r. And we start to run in cycles of 16 bytes. At the end of the loop, the last bytes remain in the register. Unfortunately, there is no easy way to add them horizontally. This can be done for WORD, DWORD, and so on, but not for bytes! For example, take a look at
_mm_hadd_epi16(). So we will work manually:
for (i=0; i<16; i++) {
result += ((unsigned char *)&r)[i];
}Done.
We compile and profile:
> gcc -Wall -g -O0 -o file_sum file_sum.c
> time ./file_sum /tmp/test
Read finished, sum is 186
real 0m0.693s
user 0m0.360s
sys 0m0.328sAbout 700 ms. C 3000 ms with the classic byte summation, we fell to 700 when adding 16 bytes.
Let's disassemble the loop code
while(), because the rest of the code has not changed:00400957: mov -0x34(%rbp),%eax
0040095a: cltq
0040095c: lea -0x4d0(%rbp),%rdx
00400963: add %rdx,%rax
00400966: mov %rax,-0x98(%rbp)
0040096d: mov -0x98(%rbp),%rax
00400974: movdqa (%rax),%xmm0
00400978: movaps %xmm0,-0x60(%rbp)
0040097c: movdqa -0xd0(%rbp),%xmm0
00400984: movdqa -0x60(%rbp),%xmm1
00400989: movaps %xmm1,-0xb0(%rbp)
00400990: movaps %xmm0,-0xc0(%rbp)
00400997: movdqa -0xc0(%rbp),%xmm0
0040099f: movdqa -0xb0(%rbp),%xmm1
004009a7: paddb %xmm1,%xmm0
004009ab: movaps %xmm0,-0xd0(%rbp)
004009b2: addl $0x10,-0x34(%rbp)
004009b6: mov -0x34(%rbp),%eax
004009b9: cltq
004009bb: cmp -0x48(%rbp),%rax
004009bf: jl 0x400957Need to clarify? Noticed
%xmm0and %xmm1? These are the SSE registers used. What will we do with them? We run MOVDQA (MOV Double Quad-word Aligned) and MOVAPS (MOV Aligned Packed Single-Precision). These instructions do the same thing: move 128 bits (16 bytes). Why then two instructions? I cannot explain this without a detailed review of the CISC architecture, superscalar engine, and internal pipeline.
Next, we perform PADDB (Packed Add Bytes): we add two 128-bit registers with each other in one instruction!
The goal is achieved.
About AVX
AVX (Advanced Vector eXtension) is the future of SSE. You can think of AVX as something like SSE ++, like SSE5 or SSE6.
The technology appeared in 2011 along with Intel Sandy Bridge architecture. And as the SSE replaced the MMX, now the AVX is replacing the SSE, which is turning into the "old" technology inherent in processors, from the decade 2000-2010.
AVX enhances SIMD capabilities by expanding XMM registers to 256 bits, i.e. 32 bytes. For example, the XMM0 register can be accessed as YMM0. That is, the registers remained the same, they were simply expanded.

AVX instructions can be used with XMM registers from SSE, but then only the lower 128 bits of the corresponding YMM registers will work. This allows you to comfortably transfer code from SSE to AVX.
AVX also introduced a new syntax: for one destination, opcodes can take up to three source arguments. The destination may differ from the source, while in SSE it was one of the sources, which led to “destructive” calculations (if the register was later to become the destination for the opcode, you had to save the contents of the register before performing calculations on it ) For instance:
VADDPD %ymm0 %ymm1 %ymm2 : Прибавляет числа с плавающей запятой с двойной точностью из ymm1 в ymm2 и кладёт результат в ymm0AVX also allows in the MNEMONIC DST SRC1 SRC2 SRC3 formula to have one SRC or DST (but not more) as a memory address. Consequently, many AVX instructions (not all) can work directly from memory, without intermediate loading data into the register, and many are able to work with three sources, not just two.
Finally, AVX has some great FMA instructions. FMA ( Fused Multiply Add ) allows one instruction to perform such calculations: A = (B * C) + D.
About AVX2
In 2013, AVX2 technology came along with Haswell architecture. It allows you to add bytes to 256-bit registers. Just what you need for our program. Unfortunately, this is not the case with AVX1. When working with 256-bit registers, AVX can only perform operations with floating point numbers (with half, single or double precision) and with integer numbers. But not with single bytes!
Let's patch our program to use AVX2 and the new VPADDB instruction that adds bytes from YMM registers (to add 32 bytes each). Do it yourself, because my processor is too old and does not support AVX2.
AVX and AVX2 manuals can be downloaded here .
About the AVX-512
As of the end of 2016, AVX-512 technology is designed for “professional” Xeon-Phi processors. It is likely that by 2018 it will fall on the consumer market.
The AVX-512 again expands the AVX registers, from 256 to 512 bits, i.e. 64 bytes. Also, 15 new SIMD registers are added, so that 32 512-bit registers become available in total. The higher 256 bits can be accessed through new ZMM registers, half of which is available to YMM registers from AVX, and half of the volume of YMM registers is available to XMM registers from SSE.
Information from Intel .
Today we can predict the weather 15 days in advance thanks to calculations on supervector processors .
SIMD everywhere?
SIMD has disadvantages:
- It is necessary to perfectly align the data in the memory area.
- Not every code allows this parallelization.
First about alignment. How can a processor access a memory area to load 16 bytes if the address is not divisible by 16? No way (in one instruction like MOV).
The Lego constructor provides a good illustration of the concept of data alignment in computer memory.
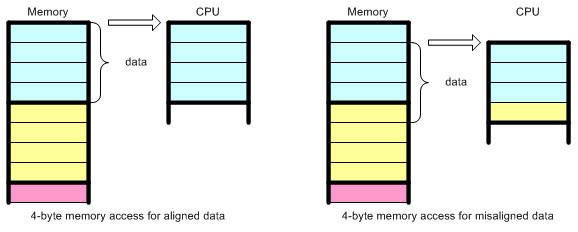
See the problem? Therefore, I use in C code:
unsigned char buf[BUF_SIZE] __attribute__ ((aligned (16))) = {0};so that the computer stored
bufon the stack at an address that is divided by 16. SIMD can also be used with uneven data, but you will have to pay so much for it that it is better not to resort to SIMD at all. You ask the processor to load data at address X, then at address Y, then delete bytes from X, then from Y, then insert two memory areas next to it. Doesn’t climb into any gates.
More about alignment:
Please note that aligning data in memory is also recommended when working with “classic” C. We use this technique in PHP as well. Any author of a serious C-program pays attention to alignment and helps the compiler generate better code. Sometimes the compiler can “guess” and align the buffers, but it often involves dynamic memory (heap), and then you have to clean up if you are worried about a drop in performance with every memory access. This is especially true for the development of C-structures.
Another problem with SIMD is that your data must be suitable for parallelization. The application must transfer data to the processor in parallel threads. Otherwise, the compiler will generate classic registers and instructions, without using SIMD. However, not every algorithm can be so parallelized.
In general, a certain price will have to be paid for SIMD, but it is not too high.
Fighting the compiler: turn on optimization and auto-vectorization
At the beginning of the article, I talked about half a second for summing bytes. But now we have 700 ms, this is not 500!
There is one trick.
Remember how we compiled our C code. We disabled optimizations. I will not go into details about them, but in an article related to PHP I talked about how the OPCache extension can cling to a PHP compiler and perform optimization passes in the generated code.
Everything is the same here, but it’s too difficult to explain. Optimizing the code is not easy, it is a huge topic. Google some terms and get a rough idea.
Simplified: if you tell the compiler to generate optimized code, then it will probably optimize it better than you. Therefore, we use a higher level language (in this case, C) and a compiler.
C compilers have been around since the 1970s. They were honed for about 50 years. In some very rare and specific cases, you can optimize better, but nothing more. In this case, you have to perfectly understand assembler.
However, you need to know how the compiler works in order to understand whether your code can be optimized. There are many recommendations that help the compiler generate better code. Start exploring the question from here .
We will compile the first version of our program - byte addition without using Intrinsics - with full optimization:
> gcc -Wall -g -O3 -o file_sum file_sum.c
> time ./file_sum /tmp/test
Read finished, sum is 186
real 0m0.416s
user 0m0.084s
sys 0m0.316sThe total time is only 416 ms, and the sum of the bytes took only 84 ms, while as much as 316 ms were spent on system calls and disk access.
Hmm.
Disassemble. The full code can be found here .
An interesting piece:
00400688: mov %rcx,%rdi
0040068b: add $0x1,%rcx
0040068f: shl $0x4,%rdi
00400693: cmp %rcx,%rdx
00400696: paddb 0x0(%rbp,%rdi,1),%xmm0
0040069c: ja 0x400688
0040069e: movdqa %xmm0,%xmm1
004006a2: psrldq $0x8,%xmm1
004006a7: paddb %xmm1,%xmm0
004006ab: movdqa %xmm0,%xmm1
004006af: psrldq $0x4,%xmm1
004006b4: paddb %xmm1,%xmm0
004006b8: movdqa %xmm0,%xmm1
004006bc: psrldq $0x2,%xmm1
004006c1: paddb %xmm1,%xmm0
004006c5: movdqa %xmm0,%xmm1
004006c9: psrldq $0x1,%xmm1
004006ce: paddb %xmm1,%xmm0
004006d2: movaps %xmm0,(%rsp)
004006d6: movzbl (%rsp),%edx
(...) (...) (...) (...)Analyze it yourself. Here the compiler uses a lot of tricks to increase the efficiency of the program. For example, it reverses (unroll) loops, in a certain way distributes bytes into registers, passing one byte and shifting others.
But here SIMD instructions are precisely generated, since our cycle can be “vectorized” - turned into vector SIMD instructions.
Try to analyze the whole code, and you will see how smartly the compiler approached the solution to the problem. He knows the price of each instruction. He can arrange them to get the best code possible. Here you can read about each optimization performed by GCC at each level.
The most difficult level is O3, it includes “tree-loop vectorization”, “tree-slp vectorization”, andbreaks the cycles .
By default, only O2 is used, because due to very too aggressive O3 optimization, programs may exhibit unexpected behavior. There are also bugs in compilers, as well as in processors . This can lead to bugs in the generated code or to unexpected behavior, even in 2016. I have not encountered this, but I recently found a bug in GCC 4.9.2 that affects PHP with -O2. I also recall a bug in managing FPUs .
Take PHP as an example. Compile it without optimization (-O0) and run the benchmark. Then compare with -O2 and -O3. The benchmark should simply overheat due to aggressive optimizations.
However, -O2 does not activate auto-vectorization. In theory, when using -O2, GCC should not generate SIMD. It is annoying that every program in the form of a Linux package is compiled with -O2 by default. It is like having very powerful equipment, but not using its full capabilities. But we are professionals. Do you know that commercial Linux distributions can be distributed with programs that, when compiled, are highly optimized for the equipment with which they are distributed? So do many companies, including IBM and Oracle.
You can also compile them yourself from the source code using -O3 or -O2 with the necessary flags. I use -march = native to create even more specialized code, more productive, but less portable. But it sometimes works unstable, so test it carefully and get ready for surprises.
In addition to GCC, there are other compilers, such as LLVM or ICC (from Intel). At gcc.godbolt.org you can test all three online. The Intel compiler generates the best code for Intel processors. But GCC and LLVM are quickly catching up, in addition, you may have your own ideas regarding the methodology for testing compilers, different scripts and code bases.
Working with free software, you are free. Do not forget: no one will cheer you up.
You do not buy a commercial superprogram that is not known how to compile it, and if you disassemble it, you can go to jail, because it is prohibited in many countries. Or did you do it all the same? Oh.
Php?
What does PHP have to do with it? We do not code PHP in assembler. When generating code, we rely entirely on the compiler, because we want the code to be ported to different architectures and the OS, like any C program.
However, we try to use well-proven tricks so that the compiler generates more efficient code:
- Many data structures in PHP are aligned. The memory manager that performs heap allocations always flattens the buffer at your request. Details .
- Мы используем alloca() только там, где она работает лучше кучи. Для старых систем, не поддерживающих alloca(), у нас есть собственный эмулятор.
- Мы используем встроенные команды GCC. Например, __builtin_alloca(), __builtin_expect() и __builtin_clz().
- Мы подсказываем компилятору, как использовать регистры для основных обработчиков виртуальной машины Zend Virtual. Подробности.
In PHP, we do not use JIT (not yet developed). Although we plan. JIT is a way to generate assembly code "on the fly" as you execute some machine instructions. JIT improves the performance of virtual machines, such as in PHP (Zend), but the improvements concern only repeating computational patterns. The more you repeat low-level patterns, the more useful JIT. Since PHP programs today consist of a large variety of PHP instructions, JIT only optimizes heavy processes that process large amounts of data per second over time. But for PHP, this behavior is uncharacteristic because it tries to process requests as soon as possible and delegate "heavy" tasks to other processes (asynchronous). So PHP can benefit from implementing JIT, but not as much as Java itself. At least not as a web technology, but when used as a CLI. CLI scripts will greatly improve, unlike Web PHP.
When developing PHP, we rarely pay attention to generated assembler code. But sometimes we do this, especially when faced with “unexpected behavior” that is not related to C. This may indicate a compiler bug.
I almost forgot about Joe's SIMD extension for PHP . Do not rush to condemn: this is a test of the concept, but a good test.
I have a lot of ideas regarding PHP extensions related to SIMD. For example, I want to port part of the math-php project to C and implement SIMD. You can make an extension with public structures that allow PHP users to use SIMD for linear algebraic calculations. Perhaps this will help someone create a full-fledged video game in PHP.
Conclusion
So, we started by creating a simple program in C. We saw that compiling without optimizations led to the generation of very understandable and GDB-friendly assembler code, while being extremely inefficient. The second level of optimization by default in GCC does not imply the inclusion of auto-vectorization, and therefore does not generate SIMD instructions. Using -O3, GCC outperformed the results from our SIMD implementation.
We also saw that our SIMD implementation is just a concept check. To further improve performance, we could resort to AVX and a number of other registers. Also, when accessing the file, one could use mmap (), but in modern kernels this would have no effect.
By creating code in C, you assign the work to the compiler, because it will do it better than you. Deal with it. In some cases, you can take the reins in your own hands and write assembly code directly or using the Intel Intrinsics API. Each compiler also accepts "extensions" from the C language, which help generate the desired code. List of GCC Extensions .
Someone prefers to use Intel Intrinsics, someone writes assembly code himself and believes that it is easier. It is really easy to embed assembler instructions in a C program; each compiler allows this. Or you can write one project file in assembler, others in C.
In general, C is a really cool language. He is old and has not changed much in 45 years, which proves its stability, which means that our iron works on a solid foundation. C has competitors, but it rightfully occupies the lion's share of the market. It contains all the low-level systems that we use today. Yes, now we have more threads, several cores and a number of other problems like NUMA. But processors still process the same way as before, and only incredibly talented Intel and AMD engineers manage to follow Moore's law: now we can use very specialized instructions while processing a lot of data.
I wrote this article because I recently met talented professionals who are completelyignore everything that is written here. I thought that they miss a lot and do not even understand this. So I decided to share my knowledge about how low-level computing is performed.
As users of higher-level languages, do not forget that you create your products on the foundation of millions of lines of C-code and billions of processor instructions. A problem that you will encounter at a high level can be resolved at a lower level. The processor does not know how to lie, it is very stupid and performs simple operations with tiny amounts of data, but with great speed and not at all like our brain does.
Useful links:
- Intel: The significance of SIMD, SSE and AVX
- NASM
- GCC SIMD switches
- Online JS based X86 compilers
- ARM Processor Architecture
- Modern X86 Assembly Language Programming: 32-bit, 64-bit, SSE, and AVX
- X86 Opcode and Instruction Reference
- Dragon book
- X264 Assembly with SIMD
- LAME MP3 quantizer SIMD
- Mandelbrot Set with SIMD Intrinsics
- ASM.js
- Joe's PHP SIMD