Computer vision, cloud development and competition

A sudden horse from Spatial Memory for Context Reasoning in Object Detection (presented at ICCV 2017)
We have some news, but it’s boring to write just about a contest in which you can win a camera for the house or about the vacancy of our cloud team. Therefore, we will start with information that will be interesting to everyone (ok, almost everyone - we will talk about video analytics).
Recently, the largest conference on computer vision technologies, the International Conference on Computer Vision 2017, ended. At it, teams of scientists and representatives of the research departments of various corporations presented developments for improving photos, generating images by description, looking around the corner using light analysis, etc. We will talk about several interesting solutions that can find application in the field of video surveillance.
“DSLR” quality photos on mobile devices

The matrices of CCTV cameras and smartphones are improving from year to year, but it seems they will never catch up with SLR cameras. And there is one reason - the physical limitations of mobile devices.
Researchers from the Swiss Federal Institute of Technology in Zurich presented an algorithm that converts an image received on a camera of not the highest quality, correctly “straightening” details and colors. The algorithm cannot create what is not there in the picture, but it can help improve photos not only by adjusting brightness and contrast.
Photo processing is carried out using a scanning neural network, which improves both color reproduction and image sharpness. The grid was trained on objects that were photographed simultaneously on a smartphone camera and on a digital camera. Understanding what quality is optimal for a conditional object, the grid seeks to change the parameters of the image so that it most closely matches the "ideal" image.
The sophisticated image error perception function combines color, tonality, and texture data. The study shows that improved images demonstrate a quality comparable to photographs taken with SLR cameras, while the method itself can be applied to any type of digital camera.
The current version of the image quality improvement algorithms can be tested at phancer.com - just upload any image.
Create photorealistic images from scratch

A large team of scientists - 7 people on two continents from Rutgers University, Likhai University, Hong Kong University of China and Baidu Research - proposed a way to use grids to create photo-realistic images based on text descriptions. In some ways, the method is similar to the work of a real artist who creates a picture based on the images in his head - first a rough sketch appears on the canvas, and then more and more precise details.
The computer first makes the first attempt to create an image based on the textual description of the given objects (and the knowledge base of the images known to it), and then a separate algorithm evaluates the resulting picture and makes suggestions for improving the image. At the entrance, for example, there is a "green bird", a base of flowers and a base of famous birds. There are a large number of images that correctly correspond to this text description - and this is one of the problems.
To generate images from text descriptions, several folded generative contention networks (SGANs) are used. GAN Stage-I sketches a primitive sketch and adds the primary colors of objects based on text description data. GAN Stage-II takes Stage-I results and text descriptions as input and generates high-resolution images with photorealistic details. GAN Stage-II is able to correct defects and add interesting details. Samples created by StackGAN are more believable than those generated by other existing approaches.
Because GAN Stage-I generates sketches for objects and for the background, GAN Stage II only needs to focus on the details and fix the defects. GAN Stage-II learns to process textual information that GAN Stage-I did not take, and draws more detailed information about the object.
Handling complex, interconnected events in a video
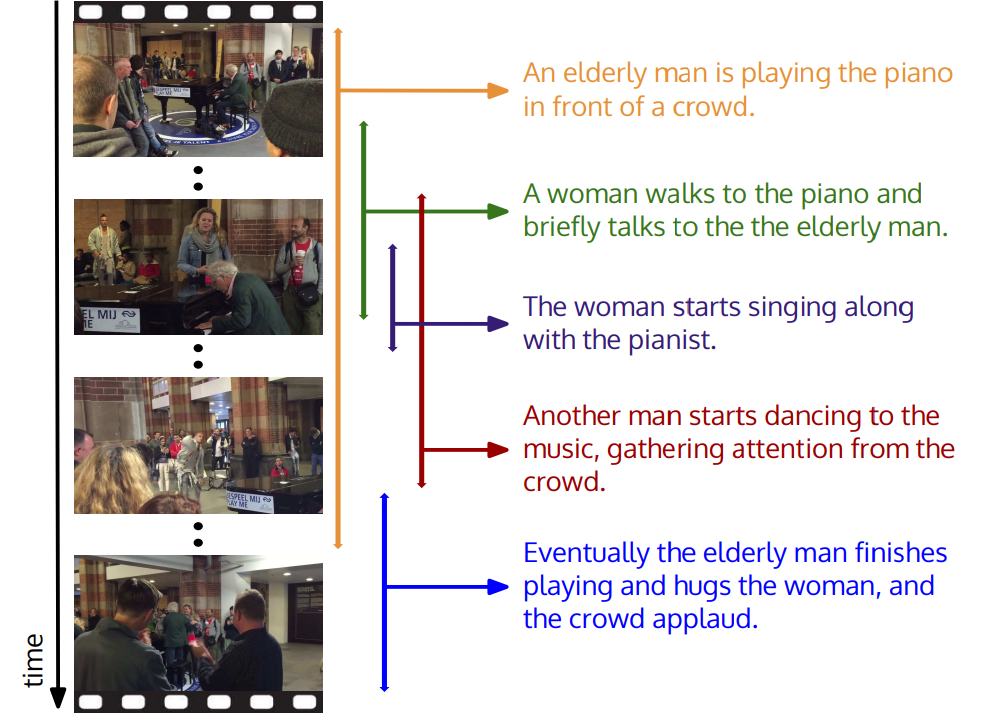
At Stanford University, they thought that too many events were happening in the commercials. For example, in the video “a person plays the piano”, the video may also contain “a dancing person” or “a cheering crowd of people”. A new study proposed a model that allows you to identify all events and give them a description in natural language.
The model is based on spatio-temporal descriptions . In fact, the computer was first trained on thousands of videos containing detailed context descriptions.
Interestingly, in DeepMind, we went a different way to solve a similar problem .and began to correlate the video sequence with sound in order to recognize objects without first understanding what is in the frame. The Google algorithm consists of three parts: the first neural network processes images taken from the video, the second - the audio corresponding to these images, the third part learns to correlate images with a certain sound.
Similar technologies in video surveillance can be used for convenient and quick search in the data archive.
Description of natural language images

Which of the two descriptions of the top photo seems more human to you: “A cow standing in a field with houses” or “A gray cow walking in a large green field in front of houses”? Last, probably. But computers do not have any natural understanding of what makes a person intuitively choose the right (from our point of view) option.
In the Towards Diverse and Natural Image Descriptions via a Conditional GAN project, one neural network creates a description of the scene in the image, while the other compares this description with human-created ones and evaluates elements that better match our own style of speech.
A system was proposed that included several generative adversarial neural networks, one of which selected a description for the image, and the second evaluated how well the description corresponded to the visual content. It was possible to achieve such a level of recognition of objects and the relationships between them that the context of the processed events did not matter. Although the system has never seen a cow drinking milk through a straw, it can recognize this image because it has an idea of what a cow looks like, milk, a straw, and what it means to “drink”.
The camera peeks around the corner.

A few years ago, engineers and physicists from Scotland created a camera that literally allowed you to look around the corner and track the movements of people and objects behind it.
The solution was a set of two devices - the "photon gun", which scientists fired at the floor and the wall, located on the opposite side of the corner, and a special photosensitive matrix based on avalanche photodiodes that can recognize even single photons.
Photons from the beam of the gun, reflected from the surface of the wall and floor, collide and reflect from the surface of all objects that are behind the wall. Some of them fall into the detector, reflected once more from the wall, which allows, based on the time of the beam, to determine the position, shape and appearance of what is hiding around the corner.
The system worked extremely slowly - it took about three minutes to form the initial image. In addition, the result was displayed in the form of an image of 32 by 32 pixels, which in fact did not allow us to make out anything other than a rough silhouette in the picture.
There have been several attempts to improve quality, but the solution came from an unexpected angle. MIT and Google Research experts suggestedLook around the corner with reflected light. Looking VERY carefully at the light that is visible from different angles, you can get an idea of the color and spatial arrangement of objects hidden around the corner.
It looks like a scene from an American procedure. The new image processing system does not require any special equipment, it will even work with a smartphone camera, using only reflected light to detect objects or people and to measure their speed and trajectory - all in real time.
Most objects reflect a small amount of light on the ground in your line of sight, creating a fuzzy shadow called penumbra. Using video partial shade, the CornerCameras system can stitch a number of images, eliminating excess noise. Despite the fact that the objects are not actually visible on the camera, you can see how their movements affect the penumbra to determine where they are and where they are going.
***
If you are interested in these projects, have your own ideas or want to get acquainted with our developments - come yourself or bring your friends. We need new people in the Cloud team to work on products based on cloud-based video surveillance and computer vision.
We give iPhone X for a successful recommendation after registering the developer for the state. And if the developer will also go to paintball with us, then there’s also a protective glass for the iPhone! ;) Read more about the vacancy (respond in the same place).
And the last for today: until November 19 (inclusive) follow the link. You need to answer one question, leave your mail, throw a link to the contest on any social network and wait - a random number generator based on the entropy of atmospheric noise will select several participants whom we will reward with an Oco2 home Wi-Fi camera.