Uncensored Asynchronous Replication

Oleg Tsarev ( zabivator )
There is a master, the master unexpectedly fell, but the system continues to work. Customers migrate to second base. It is necessary to make backup copies of the database. If we make backups on the main database, we can get some kind of performance problems, an increase in response time. This is bad. Therefore, a fairly common example of asynchronous replication is the removal of a backup from a slave. Another example is the migration of heavy queries from master to slave, from the main database to the second. For example, building reports.
Sometimes it is necessary that the application can receive all updates from the database, and preferably in real time. This is done by the open source library called libslave.
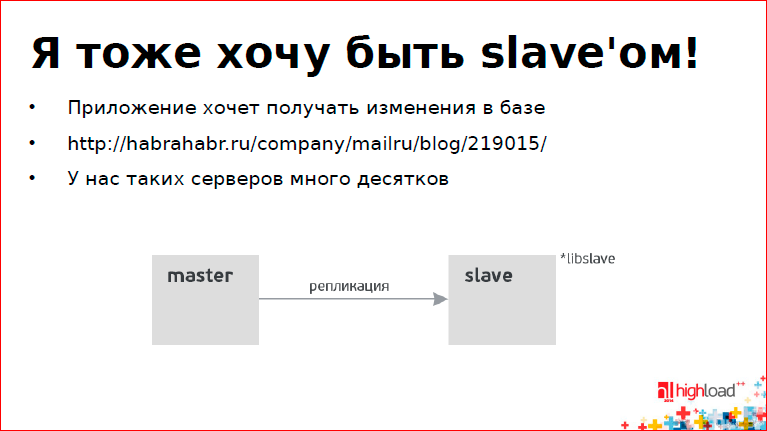
This article is a transcript of the report of Oleg Tsarev ( zabivator ), a year after reading Oleg published another article on this subject - PostgreSQL vs MySQL .
Follow the link on the slide , read - a great article.
If we put everything together, we get something like this:
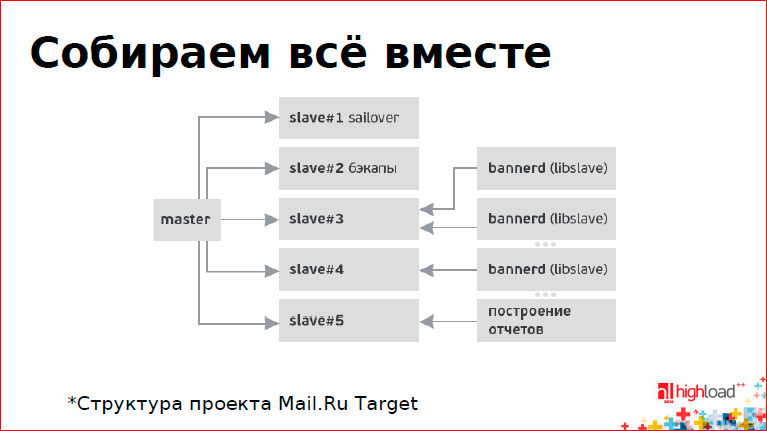
We have one master and a bunch of slaves - a seilover for backup, if the master crashed, a slave for backups, a slave for building reports, and several slaves that relay the changes to a thing called bannerd (this is the name of the daemon, and it works through libslave). There are many of them, so there are such proxies.
We have a fairly large project with a sufficiently large database, while we always work, our service does not fall. We distribute advertisements, and we have a fairly serious load, replication is used everywhere.
The main property of the database is that it guarantees the principle of "all or nothing", i.e. changes occur either entirely or not at all. How is this done, how does the database guarantee data integrity?
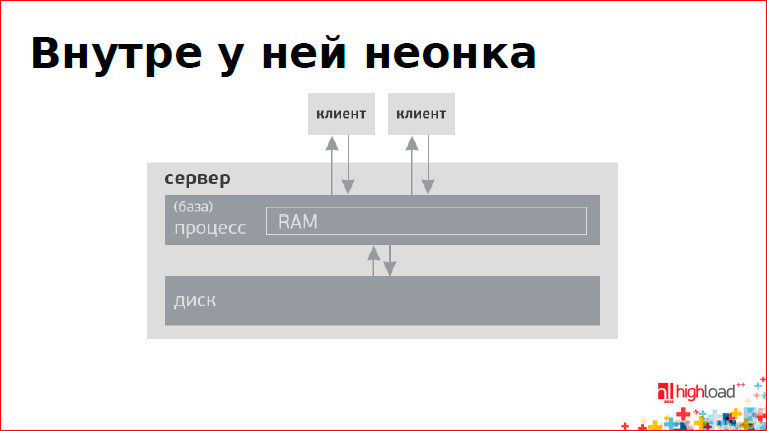
There is a server, RAM, disk, clients that go to the database. The memory is organized in the form of pages. When some kind of request for updating data arrives, the page is modified first in RAM, then it gets to disk.
The problem is that the principle of "all or nothing" on the modern hardware is not possible. These are the physical limitations of the world. Even with RAM - transactional memory appeared only recently at Intel. And it’s not clear how to live with this ... The solution is the magazine:
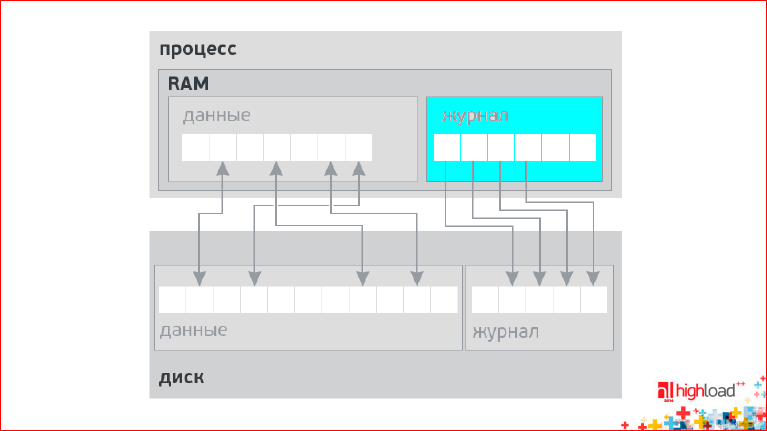
We write in a separate place - in a journal - what we want to do. We first write all the data to the log, and after the log is fixed on the disk, we change the data itself in memory. Then, perhaps much later, this data will end up on disk. Those. the magazine solves a lot of problems. Data consistency is just one of the features.
This algorithm is called Point In Time Recovery or PITR. I propose to read the information on the links:

This is very informative.
The main questions that arise for the developer of any database:
- How to organize a magazine?
- how to write it?
- how to write it less?
- how to make it work faster?
- what does replication have to do with it?
A direct way to do replication is to copy the log from the master to the slave and apply it to the slave. The journal is used to guarantee data consistency. The same mechanism can be applied to the slave. And we get replication, essentially adding almost nothing to our system.
PostgreSQL does just that. His log is called Write-Ahead Log, and physical changes get into it, i.e. page updates. There is a page in memory, it contains some data, we did something with it - we write this difference into the log, and then it leaves for the slave.
How many logs are in MySQL? Let's get it right. Initially, MySQL did not have any logs at all. There was a MyISAM engine, but there is no magazine in it.
In the picture you can see a thing called Storage Engines:
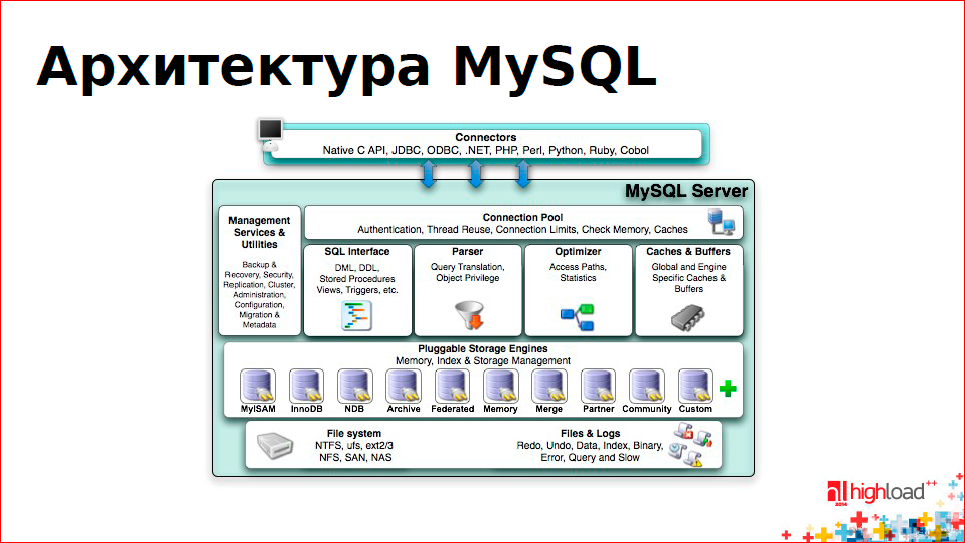
Storage Engine is such an entity that deals with issues of how to write data to disk and how we can read it from there, how to look for it, etc.
Then we screwed up the replication. Replication is one line in the upper left box - Management Services & Utilites.
Replication required a journal. He began to write. It is called Binary Log. Nobody thought about using it in any other way, they just did it.
Around the same time, MySQL presented a new Storage Engine called InnoDB. This is a widely used thing, and InnoDB has its own magazine. It turned out two magazines - InnoDB and Binary Log. This moment became a point of no return, after which there were problems that are very difficult to solve.
Binary Log is not used for Point In Time Recovery, and InnoDB Undo / Redo Log is not used in replication. It turned out that PostgreSQL has one journal, and MySQL has two, as it were, but Binary Log, which is needed for replication, has two or three formats (types).
The very first type that came up, which was the easiest to make, is Statement-based Binary Log. What it is? It’s just a file that writes transaction by transaction sequentially. It looks something like this:

The transaction indicates the database on which these updates are made, the timestamp of the transaction start time is indicated, and then the transaction itself goes.
The second type is called Row-based replication. This is a journal in which not the requests themselves are written, but the lines that they change. It consists of two parts - BEFORE image and AFTER image:
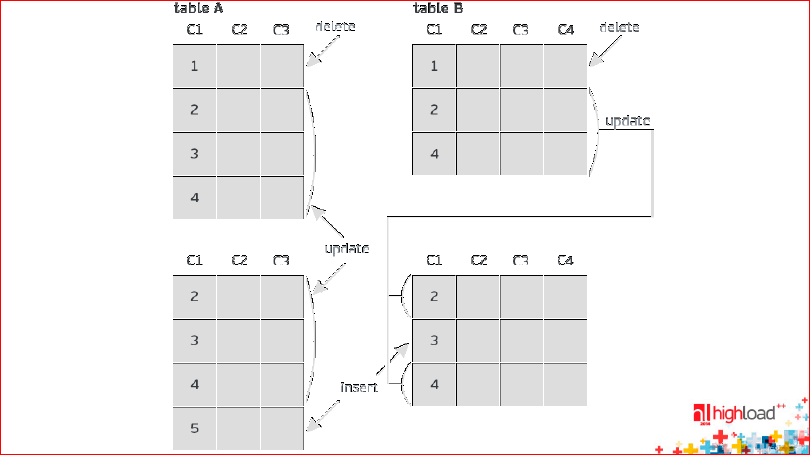
In the picture, BEFORE image is above, and AFTER image is below.
In the BEFORE image, those lines were placed that were before the transaction. The lines that are deleted are marked in red:
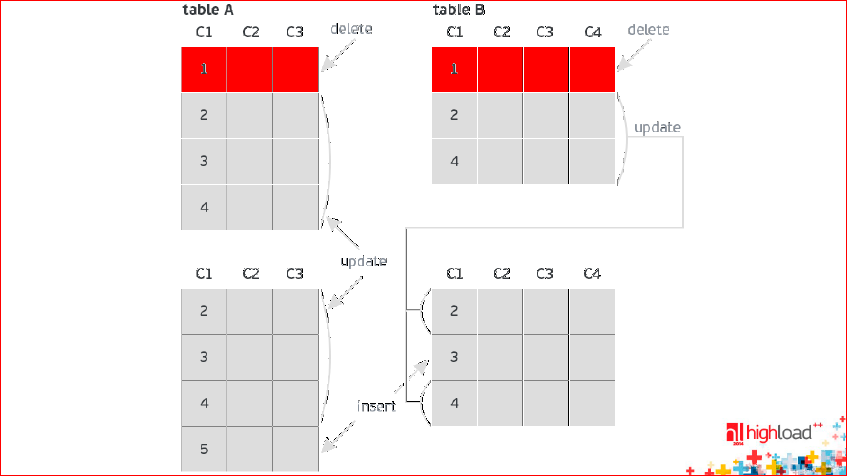
They are from the BEFORE image at the top, but they are not at the bottom - in the AFTER image, that means they are deleted.
In the next picture, the lines that were added are marked in green:
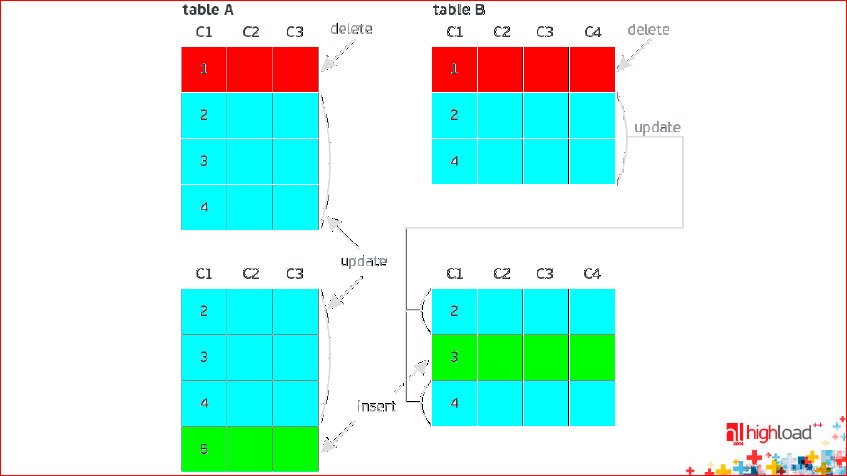
Blue UPDATEs are in both the BEFORE image and the AFTER image. These are updates.
The problem with this solution is that until recently, in Row-based replication, all columns were written to log, even if we updated one. In MySQL 5.6, this was repaired, and it should be easier with that.
There is another type of Binary Log'a - Mixed-based. It works either as Statement-based or Row-based, but it is not widely distributed.
Which of these magazines is better?
First, let's talk about relational tables. It is often thought that a relational table is an array. Some even think that this is a two-dimensional array. In fact, this is a much more complicated thing. This multiset is a set of a certain sort of tuples over which no order is specified. There is no order in the SQL table. It is important. And, as a result, when you make SELECT * from the database (scan all the records), the result of the query can change - the lines can be in one order, or they can be in another. You need to remember this.
Here is an example of a query that will not work correctly in Statement-based replication:

We removed primary_key from the table and added a new one - auto-incremental. The master and slave have different order of stitches. So we got inconsistent data. This is a feature of Statement-based replication, and not much can be done with this.
This is a quote from the official MySQL documentation:

You need to create another table, pour data into it, and then rename it. This feature can "shoot" in the most unexpected places.
Perhaps the next slide is one of the most important in the report on how replication can be classified:

Work at the storage level, as PostgreSQL does, is called physical replication - we work directly with pages. And Row-based replication, where we store a set of tuples before and after a transaction, is logical.
And Statement-based replication is generally at the request level. They don’t do it, but it’s done ... From here follows an important interesting property: when Row-based replication works for us, i.e. logical replication, it does not know exactly how the data is stored on disk. It turns out that in order for replication to work, you need to perform some operations in memory.
It also turns out that physical replication (PostgreSQL, InnoDB) rests mainly on the disk, and MySQL replication rests mainly on the slave, both Row-based and Statement-based. Row-based, you just need to find the lines and make an update, but with Statement-based everything is much worse - you need to complete the request for it. If the request on the master was executed, for example, half an hour, then it will be executed on the slave for half an hour. This is replication, but rather unsuccessful.
In addition, PostgreSQL writes to disk in two places - in the data warehouse and in the log. MySQL has three such places - storage (tablespace), log (undo / redo log), and Binary Log, which is used in replication, i.e. you need to write to disk 1.5 times more. MySQL is a great architecture, but there are often problems with it.
Many have seen lagging MySQL replicas. How to find the reason for replica braking? Diagnosing is difficult. There is a diagnostic tool in MySQL called log slow queries. You can open it, find the top of the most difficult queries and fix them. With replication, this does not work. It is necessary to carry out statistical analysis - to read statistics - which tables have become more often used. Manually doing this is very difficult.
In MySQL 5.6 / 5.7, SLAVE PERFORMANCE SCHEMA appeared, based on which it is easier to carry out such diagnostics. We usually open the commit log in puppet and see what we rolled out at a time when replication started to lag. Sometimes even this does not help, you have to go to all the developers and ask what they did, whether they broke the replication. It's sad, but you have to live with it.
In asynchronous replication, there is a master where we write, and there is a slave from which we are only reading. Slave should not influence the master. And in PostgreSQL it does not affect. In MySQL, this is unfortunately not the case. In order for Statement-based replication, which replicates requests, to work correctly, there is a special flag. In InnoDB, note, i.e. our architecture shares replication above and storage engine below. But the storage engine, in order for replication to work, must, roughly speaking, slow down insertions into the table.
Another problem is that the wizard executes queries in parallel, i.e. at the same time, and the slave can apply them sequentially. The question arises - why can't a slave apply them in parallel? In fact, this is not easy. There is a transaction serialization theorem that tells us when we can execute queries in parallel, and when sequentially. This is a separate complex topic, understand it if you are interested and need, for example, by reading the link - http://plumqqz.livejournal.com/387380.html .
In PostgreSQL, replication rests primarily on the disk. The disk does not parallel, and somehow we do not care about one stream, anyway, we are sitting mainly in the disk. We hardly consume CPU.
In MySQL, replication rests on the processor. This is a beautiful picture - a large, powerful server, 12 cores. One core works, at the same time is busy with replication. Because of this, the replica is suffocating. It is very sad.
In order to execute requests in parallel, there is a grouping of requests. InnoDB has a special option that controls how we group transactions, how we write them to disk. The problem is that we can group them at the InnoDB level, and a higher level - at the replication level - this functionality was not. In 2010, Christian Nelsen of MariaDB implemented a feature called Group Binary Log Commit - we will talk about it a little later. It turns out that we are repeating the journal (and this is a rather complicated data structure) at two levels - the Storage Engine and replication, and we need to drag features from one level to another. This is a complex mechanism. Moreover, we need to simultaneously write consistently in two logs at once - two-phase-commit. This is even worse.
In the following picture we see two graphs:

The blue graph shows how InnoDB scales when we add threads to it. We distribute threads - the number of transactions that it processes increases.
The red line indicates when replication is enabled. We enable replication and lose scalability. Because the log in Binary Log is written synchronously, and Group Binary Log Commit solves this.
It’s sad that we have to do this because of the separation - the Storage Engine is at the bottom, replication is at the top. This is all bad. In MySQL 5.6 and 5.7, this problem is resolved - there is a Group Binary Log Commit, and the wizard now does not lag behind. Now they are trying to use this for replication parallelism, so that on a slave, requests from the same group can be launched in parallel. Then I wrote that you need to twist from this:

Since October 2013, since we have a lot of data, replication is constantly lagging, everyone is upset, I tried to see this parallelism. Perhaps I didn’t understand something yet, I configured something wrong, there were many attempts, and the results look something like this: The
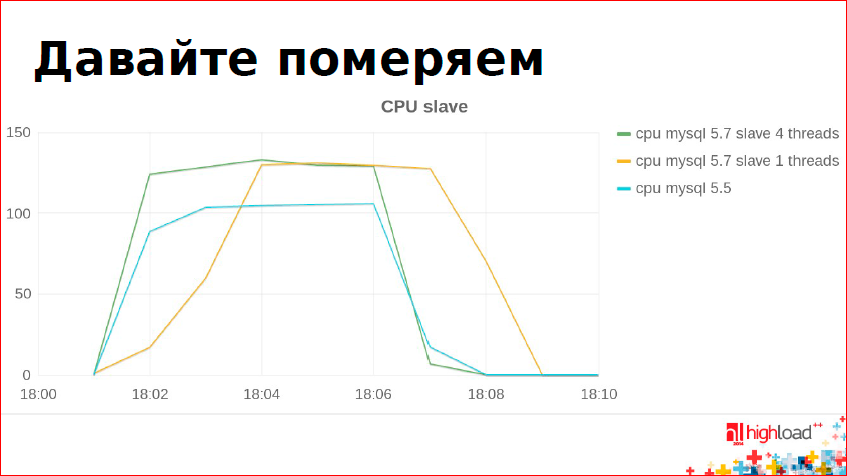
blue graph is MySQL 5.5.
On the y-axis - the processor consumption on the slave. The X axis is time.
In this graph, we can see when replication began to catch up with the master and when it finished. It turns out an interesting picture - that 5.5 in one thread works in much the same way as parallel replication in 5.7 in four threads. Those. CPU is consumed more (green line), and works on time the same. There are four threads, four threads. If you make one thread in 5.7, it will work worse. This is some kind of regression, in 5.7.5 they wanted to fix it, but I checked - the problem is still relevant. On my benchmarks, this is so, this is so on tests with production, this is a given. I hope they fix it.
What else is the problem - in order to migrate without stopping the service, at one moment in time MySQL 5.5 will be launched on the wizard, and 5.7 on the slave. In 5.5 there is no Group Binary Log Commit, which means 5.7 can only work in one thread. This means that our replica at 5.7 will begin to lag and will never catch up. As long as there is a regression with single-threaded 5.7 replication, we will not be able to migrate, we are sitting at 5.5, we have no choice.
Now the most interesting part is that I will summarize everything that I said and what was left out of the report because of the time limit (I have three hours of material).
Firstly, architecturally there are three types of magazines; there is replication at the physical level and at the logical level. The physical layer is pages. PostgreSQL is powerful because everything goes through its log — updating tables, creating triggers, creating stored procedures — and therefore there are fewer problems with it. At MySQL, depending on what type of replication we have enabled, we get either logical replication or query-level replication.
In principle, any of these magazines has its pros and cons, so you need to choose carefully.
Why are they strong / weak:

Costs * in the first line. I will explain - to the slave, anyway, you need to copy the log from the master, plus the slave may ask the master for some reason not to delete the log.
There are two serious penalties in MySQL, threads, how replication affects the wizard:
- an option in InnoDB for Statement-based replication to work;
- without Group Binary Log Commit, we don’t get scaling.
Row-based replication in MySQL works better, but there are problems.
Next, slave. PostgreSQL rests on the disk, MySQL on the processor.
In terms of disk consumption, it’s more interesting here. For example, in Row-based replication in MySQL (in PostgreSQL it will be approximately the same) dozens of terabytes of logs are obtained per day, we simply do not have so many disks to store this, so we are sitting on Statement-based. This is also important - if the replica is behind, we need to store the log somewhere. In this sense, PostgreSQL looks worse than Statement-based replication.
With a slave processor, it’s important for us to build good indexes on the slave so that the strings are easy to find, so that the queries work well. This is a rather strange metric. We optimize the slave in terms of replication efficiency, i.e. we want a slave in order to build reports, but we still have to configure so that the slave not only builds reports, but also has time to catch up. MySQL parallel slave 5.6 / 5.7 - we are really looking forward to seeing it work well, until it meets expectations.
Another important topic is data consistency.
PostgreSQL replica is a binary copy of the wizard. Those. literally - if you stop recording on the master, let the replication reach the end on the slave, stop the process on the master and slave and make a binary comparison of the PostgreSQL master and PostgreSQL slave, you will see that they are the same. In MySQL, this is not so. Row-based replication, which works with a logical representation, with tuples - in it all updates, inserts and delete work correctly, everything is fine with them.
In Statement-based replication, this is no longer the case. If you misconfigure the wizard and run certain tricky queries, you may get different results. With queries that work with the database schema — creating tables, building indexes, etc. — it’s still sadder, they always go as raw queries ... You need to constantly remember the features of Statement-based replication.
With mixed-based, the story is even more interesting - it is either this or the other, everything needs to be watched.
Flexibility. MySQL is really better at the moment because replication is more flexible. You can build different indexes on the master and slave, you can even change the data scheme - sometimes it is necessary, but now there is no such possibility in PostgreSQL. In addition, there is libslave in MySQL - this is a very powerful thing, we love it very much. Our demons pretend to be MySQL-slaves and they constantly get updates in real time. We have a delay of about 5 seconds. - the user saw the banner or clicked on it, the demon aggregated it, wrote it down to the database, after 5 seconds. the demon who distributes the banners found out about it. In PostgreSQL there is no such tool.
However, PostgreSQL plans the following. Firstly, there is such a thing as Logical Log Streaming Replication - this is a way to transform Write-Ahead Log. For example, we do not want to replicate all the tables from this database, but only want to replicate a part. Logical Log Streaming Replication allows the wizard to explain which tables will leave for the slave.
There is also Logical Decoding - a way to visualize what is in the PostgreSQL Write-Ahead Log. In fact, if we can print in some form what is happening on the slave, or rather, what came to us through the Write-Ahead Log, this means that we can programmatically implement everything that libslave does. We got insert, update, delete, we “jerked” the desired callback, we learned about the changes. This is Logical Decoding.
The conclusion from this is quite interesting - it’s best to make a normal journal. PostgreSQL has a normal log, all data updates, all changes to the schema, in general, all get there. This gives a bunch of goodies, for example, replication that works correctly, replication that rests only on the disk, not the processor. Having such a magazine, it is already possible to add a certain set of patches to the engine itself, for the master, for the slave, which allows you to increase flexibility, i.e. filter tables, have other indexes.
And for historical reasons, MySQL turned out to have a bad log, i.e. MySQL is a hostage to its historical development. To solve MySQL problems with performance, correctness, you need to rewrite the entire architecture that is associated with the Storage Engine, and this is unrealistic.
It will take quite a while, I think, and PostgreSQL will catch MySQL by features.
And finally. Even if you don’t understand a lot of things from the whole report or you need to understand, but in any case, remember the two most important conclusions:
- Replication is not a backup (backup).
- A table is not a two-dimensional array, but a homogeneous multiset of tuples. So it is correct from the point of view of computer science.
This report helped me make a lot of people:

Contacts
zabivator
This report is a transcript of one of the best speeches at the conference of developers of highly loaded systems HighLoad ++ . Now we are actively preparing the 2016 conference - this year HighLoad ++ will be held in Skolkovo on November 7 and 8.
The topic of replication is eternal :) This year, we will one way or another touch upon it in two reports.
- How we prepare MySQL / Nikolay Korolev (Badoo);
- Effective debugging of MySQL / Sveta Smirnov replication (Percona);
Also, some of these materials are used by us in an online training course on the development of highly loaded systems HighLoad. Guide is a chain of specially selected letters, articles, materials, videos. Already in our textbook more than 30 unique materials. Get connected!