The logic of consciousness. Part 6. Cortex as a space for calculating meanings
 What is information, how to find the meaning hidden in it, what generally makes sense? In most interpretations, information is compared with a message or with data, using these words as synonyms. The message usually implies a specific form. For example, spoken language, text message, traffic signal and the like. The term “message” is more often used when talking about information in connection with its transmission. Data usually means information for which the form of its storage or transmission is defined. For example, we talk about data when we mention records in a database, arrays in computer memory, network packets, and the like. We prefer to use the term “information” when it is not necessary to focus on the way it is transmitted or on the form of presentation.
What is information, how to find the meaning hidden in it, what generally makes sense? In most interpretations, information is compared with a message or with data, using these words as synonyms. The message usually implies a specific form. For example, spoken language, text message, traffic signal and the like. The term “message” is more often used when talking about information in connection with its transmission. Data usually means information for which the form of its storage or transmission is defined. For example, we talk about data when we mention records in a database, arrays in computer memory, network packets, and the like. We prefer to use the term “information” when it is not necessary to focus on the way it is transmitted or on the form of presentation.Information must be interpreted in order to be used. For example, a red traffic light can be interpreted as a ban on driving, a smile as a signal of good location and the like. The specific interpretation is called the meaning of the information. At least, this interpretation is adhered to by the international standardization organization : “knowledge concerning objects, such as facts, events, things, processes, or ideas, including concepts, that within a certain context has a particular meaning”.
Different interpretations may exist for the same information. The interpretation of the message “computer power button is pressed” depends on the state in which it was turned on or not before the computer was pressed. Depending on this, information can be interpreted as either “on” or “off”.
The circumstances that determine how this or that information should be interpreted are usually called context. Interpretation of information exists only in a certain context. Accordingly, the meaning found in the information also refers to a specific context.
The same information can make sense in different contexts. For example, all aphorisms are built on this: “You can close the window into the world with a newspaper,” “It's easy to make a chain out of zeros,” “They say that a person who has lost his teeth has a slightly freer tongue” (Stanislav Jerzy Lets ).
What interpretation will be chosen by a person for this or that information is largely determined by his personal experience. Someone can see one thing, someone else: “when a fool is shown at the stars, a fool sees only a finger” (the film “Amelie” , 2001).
The above correlation of information, context and meaning of information is intuitive enough and is in good agreement with our everyday experience. In the previous part I tried to show how all this can be transferred to a formal model with simple rules:
- The subject has a finite set of concepts;
- Any description is a set of concepts;
- Context is a set of rules for translating one concept into another;
- Interpretation is a new description obtained in the context after applying the transformation rules;
- The context space is the set of all contexts available to the subject;
- Sense is a set of interpretations that have a plausible appearance. That is, those that are in a certain way consistent with the memory of the subject.
Winston Churchill said: "There are no facts, there is only their interpretation." Information that has been correctly interpreted makes sense. From the obtained interpretations, it is possible to form the memory of the subject.
If there are examples of source messages and their correct interpretations, then we can distinguish the interpretation rules applied in each of the cases of interpretation. It’s like translating from one language to another. One and the same word in different circumstances can be translated in different ways, but for a specific sentence and its translation you can always see which option was used.
If we analyze what the choice of this or that interpretation depends on, then it turns out that there is a finite set of circumstances that affects this choice. Such circumstances are contexts. Within the same context, there are consistent interpretation rules for all concepts at once. In language translation, this corresponds to how the subject or subject area determines which translation option is more appropriate.
A set of contexts can be obtained automatically from clustering pairs of “initial description - correct interpretation”. If we combine pairs into classes whose interpretation rules do not contradict each other, then the resulting classes will correspond to the contexts, and the rules collected from all pairs of the class will be the interpretation rules for this context.
If contexts are formed, then the search for meaning in information is the determination of which context is best suited for its interpretation. In inappropriate contexts, interpretations look “crooked” and only in the right context does the “correct” interpretation appear. One can understand how right or wrong the interpretation looks by how similar it is to the “correct” interpretations already stored in the memory.
Two main ideas related to the selection of contexts can be distinguished. The first is that, using contexts, we get the opportunity to give reasonable interpretations of the information that we have never encountered before. So when translating, when we know both languages well, we still do not store in our memory all possible sentences and their translations. Understanding the context of the conversation, we select those options for translating individual words that are most suitable for this context. The second idea is that memory, that is, previous experience, allows you to determine which context in this situation creates the most correct interpretation.
A small example: suppose we are dealing with geometric shapes. They showed us a triangle, and then showed a circle. We remember these descriptions. Then they showed us the same triangle, but with an offset. Descriptions did not match. If we want to recognize a triangle at any offset, then we can try to remember its descriptions at all possible offsets. But this does not help us later, seeing the circle again, to recognize it in the offset. But you can learn the rules by which the descriptions of figures change at certain offsets. Moreover, these rules will be uniform and will not depend on a specific figure. Then it will be enough for us to see any figure once, in order to immediately immediately recognize it at any offset.
An algorithm for determining the meaning of information has been proposed. The initial description in each of the contexts that make up the context space gets its own interpretation. That is, as many possible interpretation hypotheses are constructed as there are possible contexts. If in some context the resulting interpretation turns out to be similar to the contents of the memory, then such an interpretation gets a chance to become the meaning of the information.
For geometric shapes, this means that each context stores rules for changing descriptions for a particular offset. The number of contexts is determined by the number of possible offsets. Having seen the square in the upper right, we will have to apply our displacement to it in each context and get all possible options for its location. If earlier we saw a similar square, for example, in the center, then in one of the contexts the current interpretation coincides with what was previously remembered.
A computational scheme was proposed. Each context is served by its own computing module. The same description goes to the input of each module. The memory of each module contains rules for converting concepts for its context. In each context, an interpretation is obtained that is compared with memory. According to the degree of correspondence of interpretation and memory, it is determined whether there are contexts in which information takes on a meaningful form.
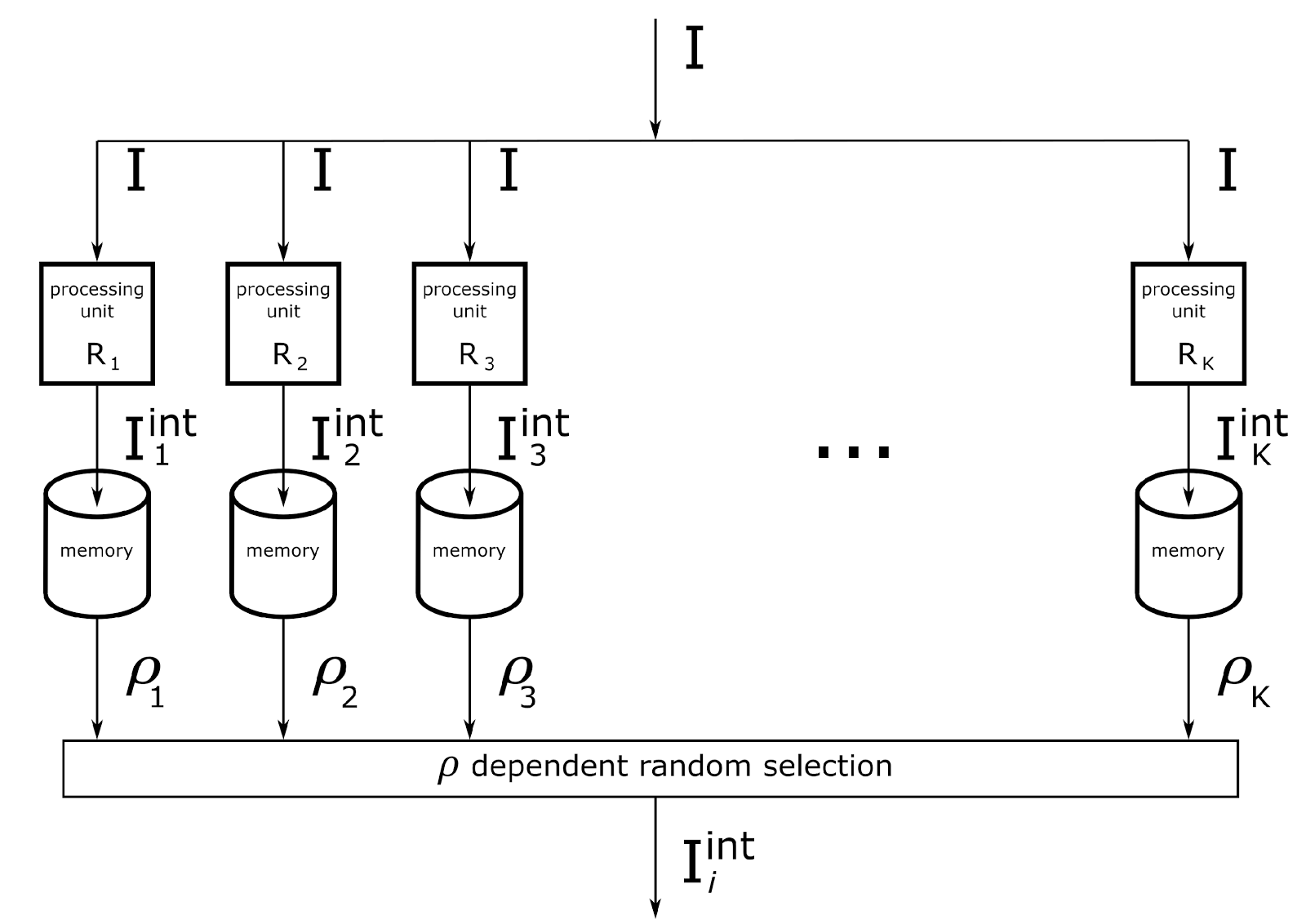
In the previous part, it was shown that many types of information that a person encounters come down to a similar computational scheme.
For the operation of contextual computing modules, it is required that:
- Information was presented as a set of discrete concepts.
- Each context module received the same information;
- Each context module had a memory of its own rules for transforming initial concepts into their interpretations;
- Each context module could, independently of the others, access a memory that stores all previous experience and evaluate the reliability of its interpretation hypothesis.
What in the cerebral cortex can be such a computational element with its own autonomous memory? So, it seems the time has come to talk about cortical minicolumns.
Brain
Let us refresh the memory of the general structure of the brain. Basically, it consists of an ancient brain, cortex, white matter and cerebellum.
The ancient brain is in the center and occupies a relatively small volume. It is called ancient for the reason that it is very similar in many living creatures and, apparently, determines the main evolved evolutionary basic functions common to all of them.

Ancient brain, white matter and cerebral cortex
The outer surface of the brain consists of a thin layer of neurons and glial cells. This layer is called the cerebral cortex. The higher the biological species stands at a higher stage of evolutionary development, the more developed is its bark.
When the bark reaches a large area, for example, as in humans, it begins to form folds. The task of the folds is to fit a large bark surface into a relatively small volume of the cranium.
It is known that the cortex acquires its functions in the learning process. The following fact confirms this, for example. If any part of the cortex is damaged, for example, during a stroke, removal, or injury, the functions associated with this place are lost. But over time, these functions may recover. Either the remaining part of the same region of the cortex can learn again the lost skills, or the symmetrically located region of the other hemisphere takes on this substitution function.
The area of the cortex that is responsible for a particular functional is called the cortical zone. The entire crust is divided into many such zones.
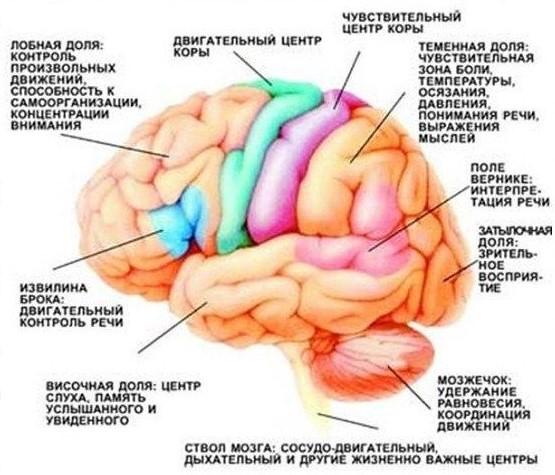
One of these areas - the motor zone of the cortex, is responsible for our motor activity. But the teams that this zone issues are of a general nature. Exact motility, that is, a detailed implementation of these commands into signals to the muscles, is performed by a separate organ - the cerebellum.
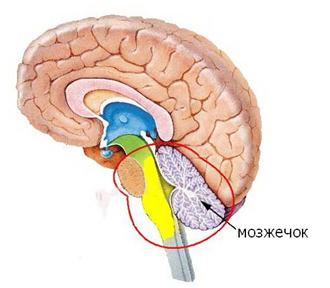
The cerebellum got its name for what it looks like a miniature brain. By the way, it is not always miniature, for example, sharks have more cerebellum in volume than the main brain. It is noteworthy that the outer surface of the cerebellum is also the cortex. The cerebral cortex is somewhat different from the cerebral cortex, but it is very likely that the ideology of its work should be very close to the work of the cerebral cortex.

The space between the cerebral cortex and the ancient brain and inside the cerebellum is filled with white matter. This is nothing more than axons of neurons that transmit signals from one part of the brain to another (figure below).
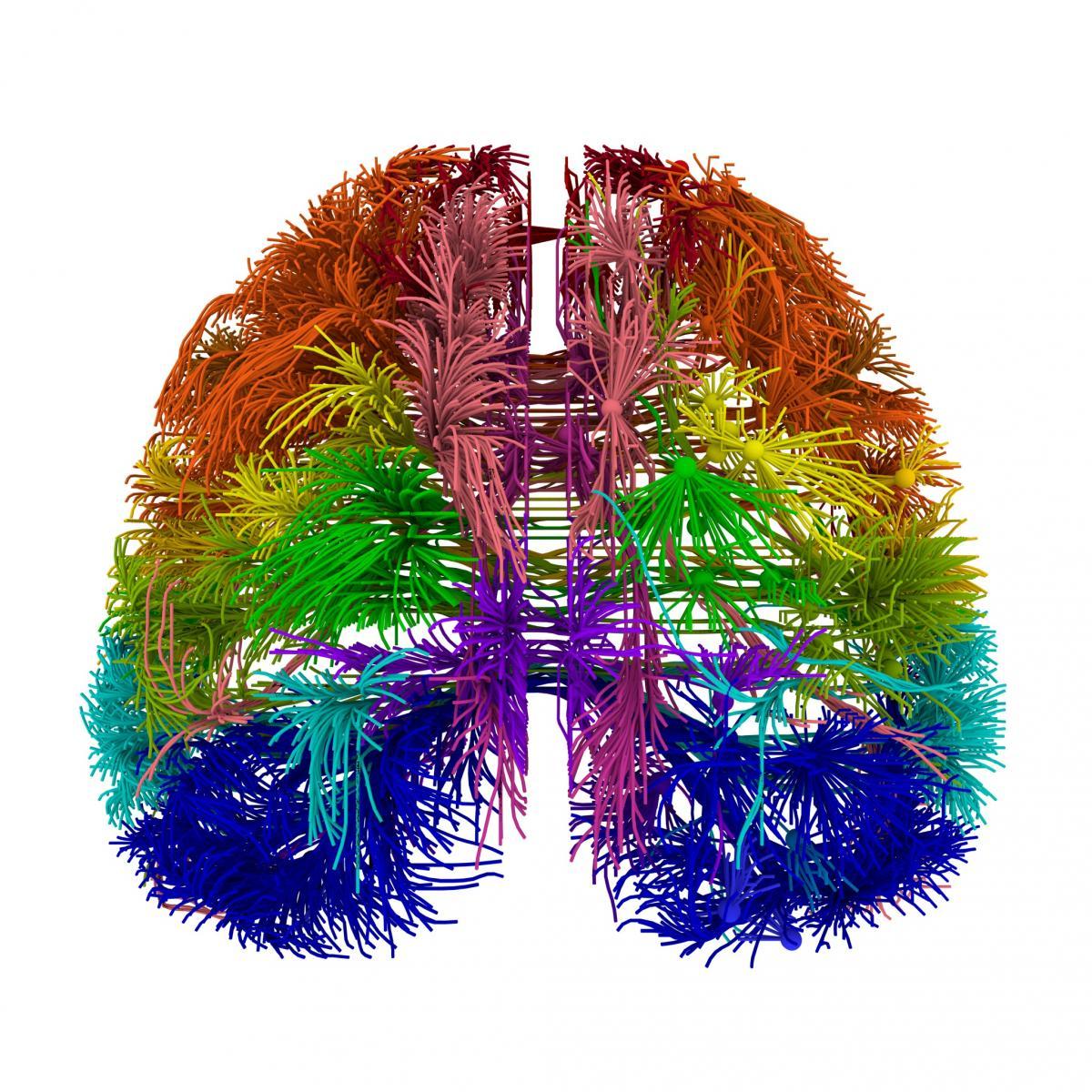
Projection connections of the real brain. Separate “strings” correspond to bundles of nerve fibers (Allen Institute for Brain Science).
These connections are well studied. They are not just a continuous projection medium, but something much more interesting.
In artificial neural networks using deep learning, information is transferred from level to level. Usually, a level has a layer of input neurons, hidden layers and an output layer.
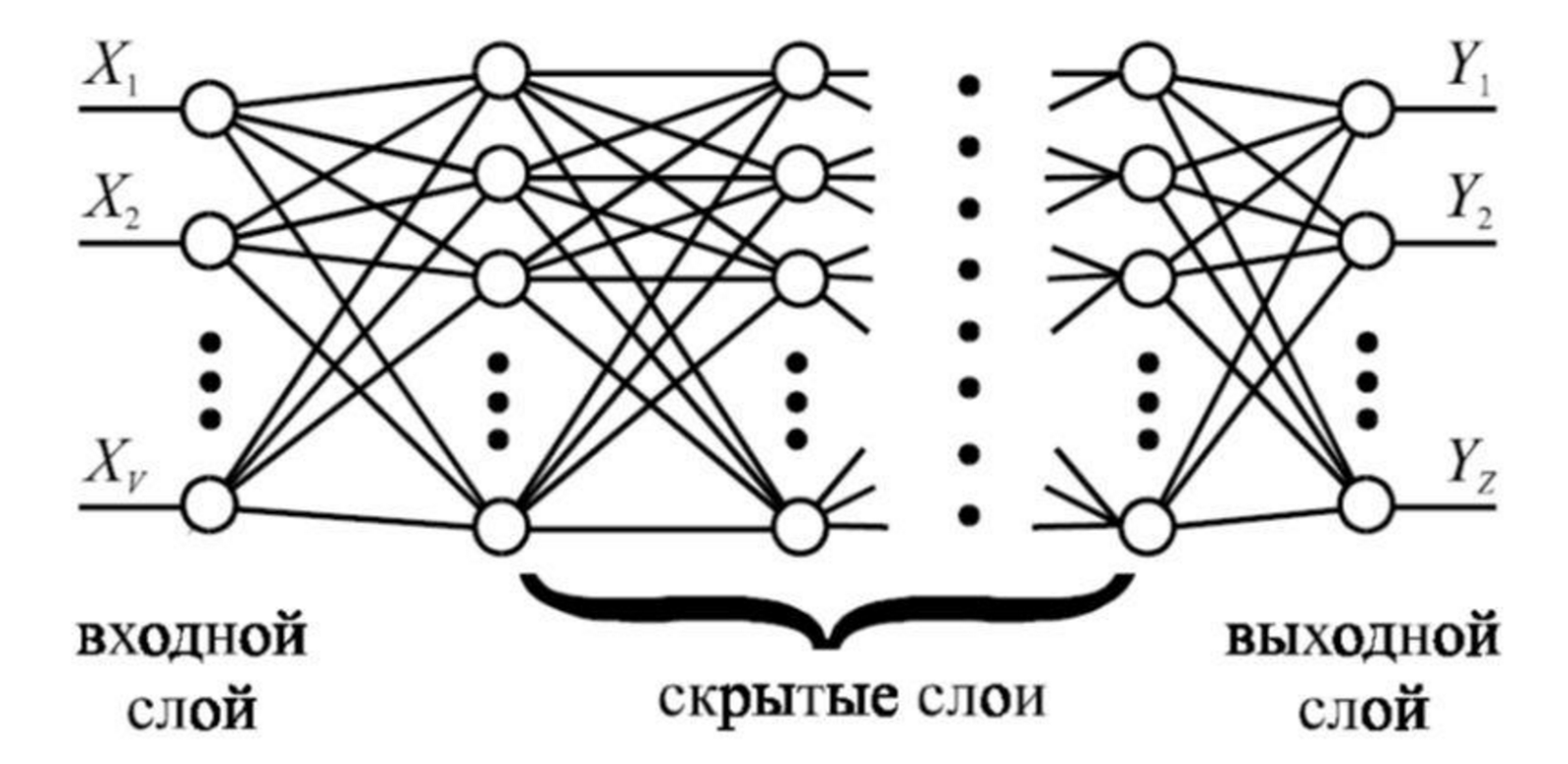
Example of a direct distribution network
The figure above shows one of the possible options, but, in general, the level can be quite complicated inside. For example, a layer can perform convolution operations and have a completely different architecture. But the common thing at all levels is that they have an input and output layer on which information is encoded by a set of features. One neuron is one sign. The set of layer neurons is an indicative description. About each neuron of the input and output layer, we can say that it corresponds to “own grandmother”.
To transfer the state of one network layer to another, it is necessary to transfer the state of all neurons of the output layer of the initial layer to the neurons of the input layer of the next level.
The very transmitted description is obtained by a long vector consisting of binary signs. In this approach, the number of signs is limited by the number of neurons in the output layer, and transmission from level to level requires as many “fiber bonds” as transmitting neurons.
So, there’s nothing even close similar in the system of connections of the real brain. Zones of the cortex are connected with each other and with the structures of the ancient brain by thin bundles of fibers. The fibers that make up the bundle point out from one place and point in another point. Each bundle contains only a few hundred fibers. In the figure above, each visible “thread” is this bundle.
It can be assumed that information on such bundles is transmitted not by a feature description, where one fiber is one feature, but by a code (figure below), when the fiber activity pattern encodes some transmitted concept.
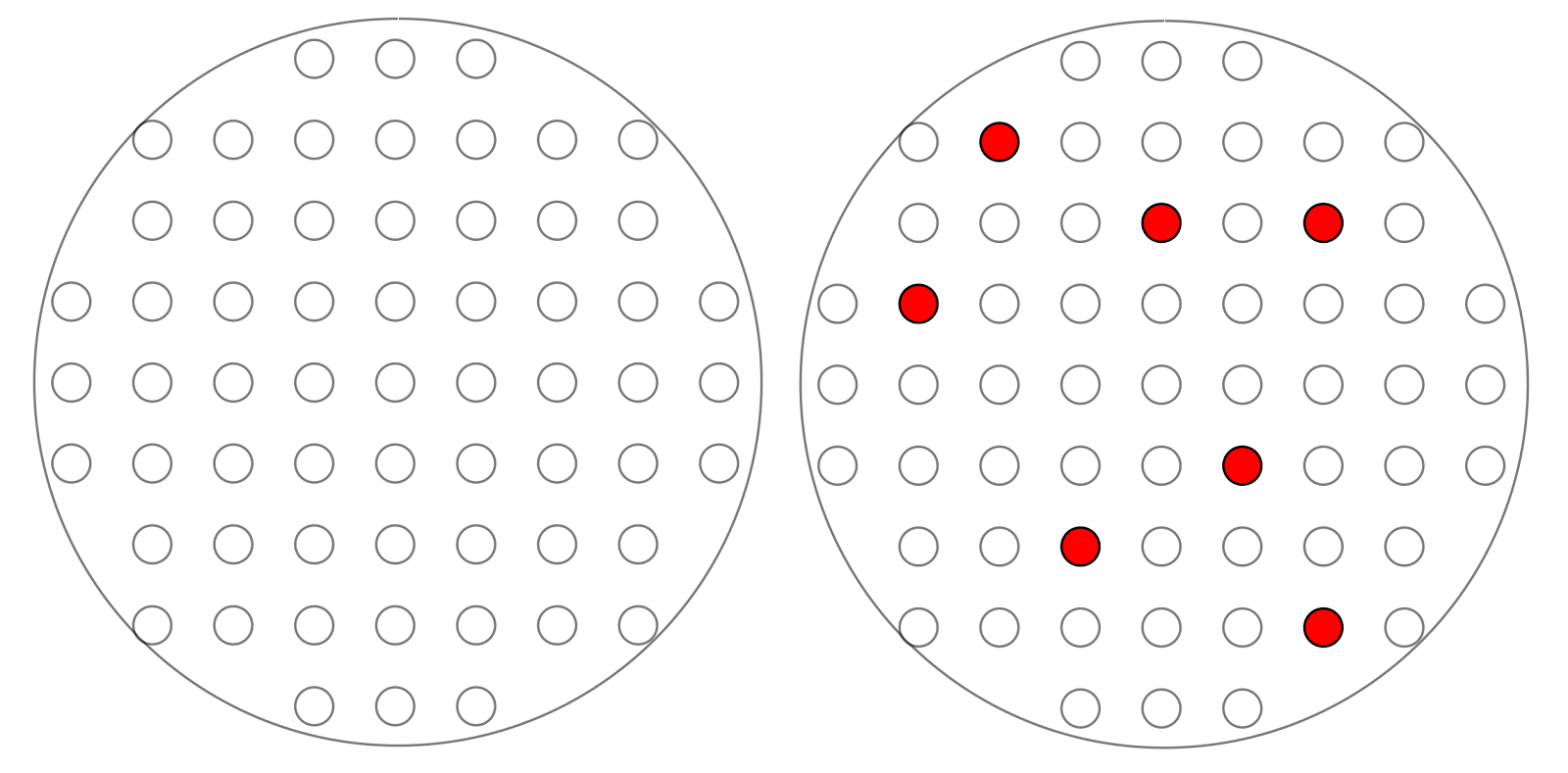
A bundle of nerve fibers (left) and an example code (right)
Using the projection system as an example, we can clearly see the difference between the proposed model and models with neuron detectors. The signal of a neuron, if it is a “grandmother's neuron,” implies an indication of whether there is a grandmother or not in the current description. In our model, neuron activity is just a bit in binary code.
When it is discovered that any real neuron stably responds to a specific stimulus, one cannot conclude from this that the neuron and the stimulus correspond. The same neuron can successfully respond to other stimuli.
The transmission of information over projection beams can be compared with the transmission of binary signals over computer data buses. This is a fairly accurate analogy. Somewhat later, using the example of the visual system, I will give fairly strong evidence of the validity of this assumption.
Summarizing the said:
- The brain does not operate with feature descriptions in which the activity of neurons corresponds to any “grandmothers”, but “digital” codes of discrete concepts;
- For learning, information processing, memory is responsible for the cortex;
- The bark consists of zones that perform specific functions. At the same time, regardless of what functions this or that zone performs and what information it works with, the architecture of the cortex remains practically unchanged. So it can be assumed that in all places of the cortex, the same principles of working with information are used, whether it is the cortex of the cerebral hemispheres or the cerebellar cortex.
Mini-columns of the cortex
On the cut, the bark looks as shown in the figure below. A fairly thin layer, about one and a half millimeters from the surface, is filled with neurons and glial cells, then a white matter consisting of axons begins.
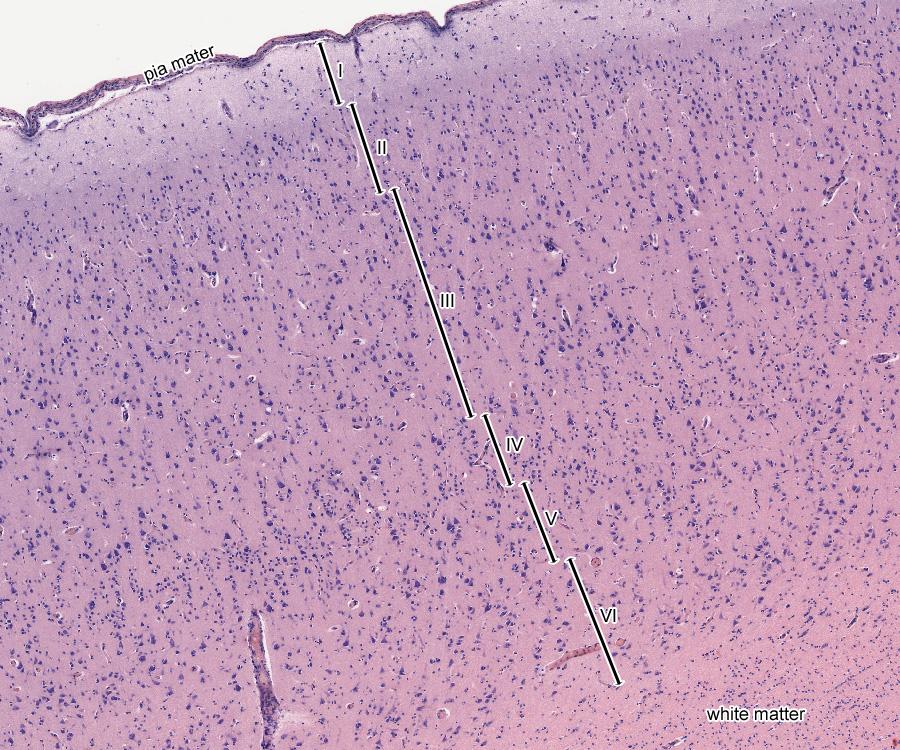
A section of the cerebral cortex. The total thickness of all six levels is approximately one and a half millimeters.
The bark is conditionally divided into six layers. The upper first layer of the cortex mainly contains horizontal axonal bonds and is similar to white matter. In the remaining layers, axon bonds mainly propagate vertically. As a result, it turns out that neurons vertically located under each other turn out to be much more connected than with neighboring neurons located to their left and right. This leads to the fact that the cortex "breaks up" into separate vertical columns of neurons. What an individual neuron, column and group of columns looks like is shown in the figure below.

A separate pyramidal neuron (left), a cortical minicolumn (in the middle), a fragment of the cortex consisting of many minicollars (right) (BBP / EPFL 2014 modeling) A
group of neurons located vertically one below the other is called a cortical minicolumn. Vernon Mountcastle hypothesized (W. Mountcastle, J. Edelman, 1981) that for the brain, the cortical column is the main structural unit of information processing.
One mini-column contains from 80 to 120 neurons depending on the cortical zone; in the primary visual cortex, the mini-columns contain up to 200 neurons (Figure below).
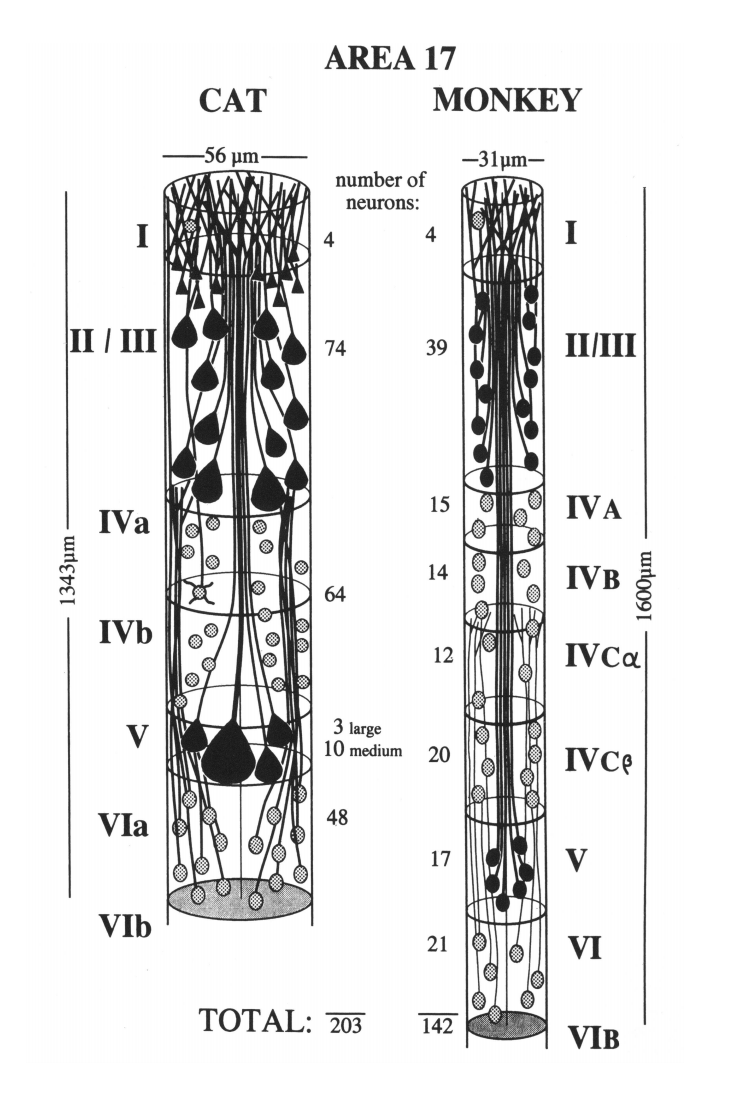
Mini-columns of the primary visual cortex of a cat (left) and a monkey (right) (Peters and Yilmaze, 1993)
The distance between the centers of mini-columns in the brain in humans or macaques varies from 20 to 80 microns depending on the zone. The transverse diameter of the mini-columns is on average about 50 μm (Brain (1997), 120, 701–722, The columnar organization of the neocortex, Vernon B. Mountcastle). As I have already said, microcolumns are characterized by a large number of vertical connections. Correspondingly, a significant part of the synaptic contacts inside the mini-columns falls on neurons belonging to the same mini-columns.
To understand what the mini-columns are capable of, for a start let's try to evaluate the memory capacity of one mini-column.
Memory capacity of one mini-column
Neurons have branched dendritic trees, consisting of many branches. We suggested that information can be transmitted along the cortex in the form of the distribution of interconnected patterns. The patterns themselves are, presumably, patterns formed by the electrical activity of dendritic branches. One pattern evokes continuation patterns associated with it. This process is repeated. As a result, a wave with a unique internal pattern rolls along the cortex. Each pattern corresponds to a concept.
Earlier, a memory formation scheme was shown based on the interference of two wave patterns. The first pattern defines the elements that must preserve the memory. The second pattern sets the key of remembrance.
The pattern of activity of dendritic branches inside one minicolumn causes a signal response of neurons of this minicollum. This answer looks like a picture of synchronous spikes. This neuron signal is a hash code for the original dendritic signal.
A hash conversion from a “long” dendritic key pattern creates a short memory key on neurons. When a neural code appears, spikes begin to propagate along the axons of the neurons entering this code.
The axons of the neurons of one mini-column form many synapses within its mini-column. A cocktail of neurotransmitters is released from each synapse belonging to an active neuron. A complex picture of the volume distribution of signal substances is obtained.
Since neurotransmitters are ejected beyond the boundaries of synapses, this picture is available for observation to all receptors that are nearby. Receptors are special molecules located on the surface of neurons and glial cells. Receptors can respond to the appearance of a certain combination of chemicals and trigger various processes within the neuron. In addition, receptors can change their state and become sensitive or insensitive to certain signals.
Each mini-column neuron activity code creates a unique three-dimensional picture of the distribution of neurotransmitters. We have shown that due to changes in metabotropic receptors, any segment of the dendrite can remember and subsequently recognize with high accuracy any picture of the volume distribution of neurotransmitters. Moreover, the number of paintings that one branch of dendrite can remember is determined by the number of receptors and amounts to tens and hundreds of thousands.
So that the signal of neurons can be remembered by the dendritic branch, there must be a place on it selected in relation to this signal. That is, such a place where a significant part of the axons of active neurons intersect. It was shown that for any signal on any dendritic branch with at high probability there is at least one such place.
A single cortical minicolumn satisfies all the conditions necessary to preserve and reproduce memories. The diameter of the mini-column corresponds to the elementary volume necessary for the formation of a spatial signal. Mini-column neurons with their activity can form a binary key, the length of which is sufficient for the unambiguous identification of any information. Axon and dendritic collaterals inside the minicollum form a structure suitable for the appearance of selected sites.
A rough estimate of how much memory a single mini-column can store can be made from the following considerations. The amount of information in one description is approximately determined by the capacity of the binary code arising from the activity of the dendritic sections of the mini-column. The total number of dendritic sections N dsin the minicolumn, it is approximately 100 * 30 = 3000 (both dendrites of the minicollar's own neurons and dendrites of the neurons of adjacent minicollars enter the minicolumn). If we assume that a complex description encodes the activity of N sig elements, then the amount of information in one description according to Shannon will be
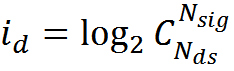
With N sig = 150, this is 854 bits or about 100 bytes. To encode one description, under the assumptions made, it is necessary to change the state of 150 receptive clusters. Thus, information per one cluster
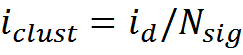
The amount of information per cluster is not very dependent on N sig (table below) and is about 6 bits.
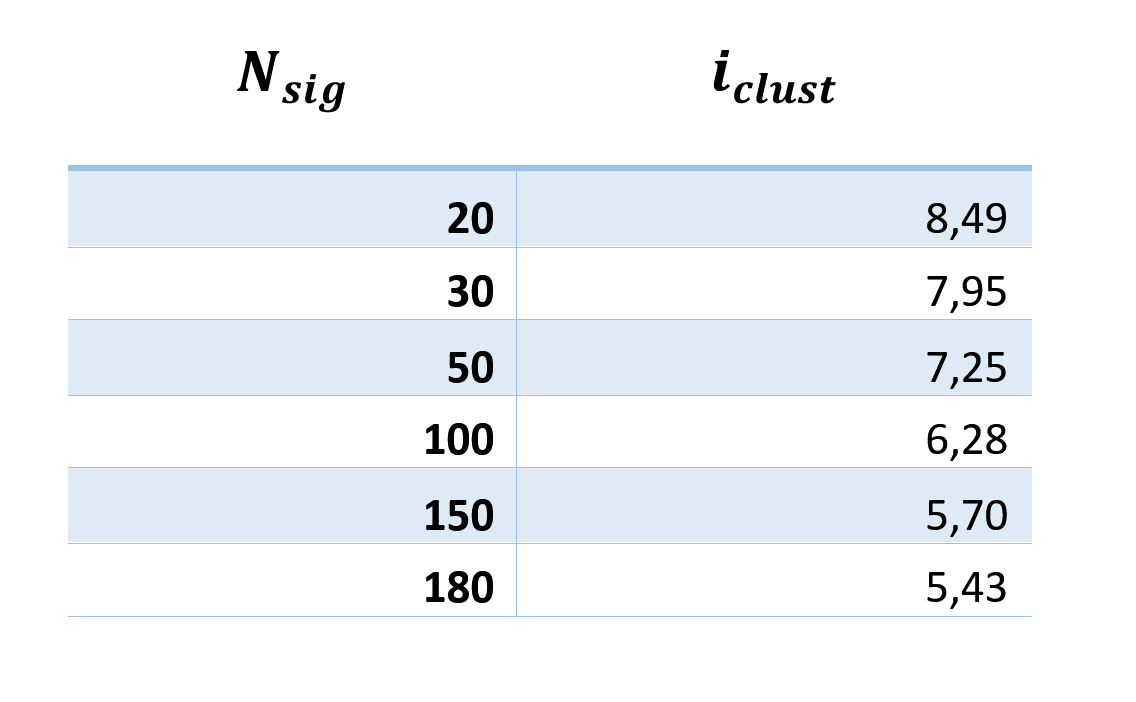
Thus, the information capacity of the mini-column can be estimated
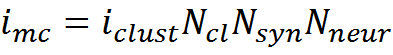
Where N cl is the number of receptive clusters per synapse, N syn is the number of synapses in one neuron (8000), N neur is the number of neurons in the mini- column (100).
The number of receptors per synapse implies, mainly, extrasynaptic receptors surrounding the synapse. Potentially, their number may vary over time. That is, hypothetically, the accumulation of memories may be accompanied by an increase in the total number of receptors.
Measurement of the density of AMPA receptors at the synapse showed a value of 1600 receptors per square meter. microns. The diameter of the monomeric ATX receptor is 9 nm, the distance between the centers of the receptors in the dimer is 9.5 nm. On the surface of the spine and the adjacent surface of the dendrite, potentially, hundreds and thousands of receptors can freely fit.
In our approach, the maximum reasonable number of receptive clusters near the synapse is limited by the number of possible combinations of the activity of the surrounding sources of neurotransmitters. With 15 sources, the choice of 5 active ones gives about 3,000 possible combinations.
Based on the foregoing, we take N cl equal to 500, assuming that such a number of receptors can accumulate in the process of memorization over many years of life. Then the mini-column memory capacity will be 2.3x109 bits or approximately 300 megabytes. Or 3 million semantic memories with information content of 100 bytes each.
An approach based on the plasticity of synapses as the main element of memory gives a much more modest result. The minicolumn contains about 800,000 synapses. Even assuming that the synapse, by changing the level of plasticity, encodes several bits of information, a value is calculated in the hundreds of kilobytes. An increase in memory capacity by three orders of magnitude gives a quantum leap in the information capabilities of the mini-column. Since the information stored in the mini-column has a nature close to semantic, 300 megabytes turn out to be quite sufficient to save, for example, all the memories of a person that accumulate in the course of his life.
An uncompressed 500-page book takes about 500 kilobytes. The mini-column allows you to store a library of memories, consisting of 600 volumes. About that for a month of life or 15 pages per day. It seems that this is enough to accommodate a semantic description of everything that happens to us.
Again, since each zone of the cortex has its own specialization, the mini-columns of each zone do not need to store the entire memory of our brain, they just need to have a memory of their subject.
Three hundred megabytes of mini-column memory should not be compared with the gigabyte sizes of photographic libraries or film libraries. It seems that when images are stored in memory, they are not stored in photographic form, but in the form of short semantic descriptions consisting of concepts corresponding to the image. At the moment of recollection, the image is not reproduced, but reconstructed anew, creating the illusion of a photographic memory. This can be compared with how a portrait of a person can be restored quite close to a photograph only by its verbal description.
The real memory of the mini-column can be many times higher if we assume that the receptors of glial cortical cells are also carriers of the information code. Contextual computing modules require storing two main types of memory: memory of past interpretations and memory of transformation rules. It is possible that these types of memory are shared between neurons and plasma astrocytes.
At the first moment, the idea that only 100 neurons of the mini-column can store memories of their entire lives seems absurd, especially for those who are used to believing that memory is distributed throughout the space of the cortex. Moreover, the duplication of many millions of mini-columns of the same information in traditional information approaches seems to be pointless waste of resources. But the ideology of defining meaning in the space of contexts allows us to bring a serious justification for just such an architecture of the cortex.
Basic computing functions of a cortical minicolumn
The basic idea that determines the operation of the mini-column is quite simple (figure below). Consider one cycle of the cortex. Information that carries the current description is distributed over the cortical zone, consisting of many mini-columns. Each mini-column sees this information as patterns of a certain activity passing through it, presumably the activity of dendritic segments. Each mini-column stores the transformation memory and is responsible for its own context of information perception. Each context implies its own, different from others, rules for converting source descriptions into their interpretations. The memory of transformations of a mini-column is a mechanism for translating patterns of the original concepts that make up the description into patterns of concepts corresponding to the interpretation in the context of a particular mini-column.
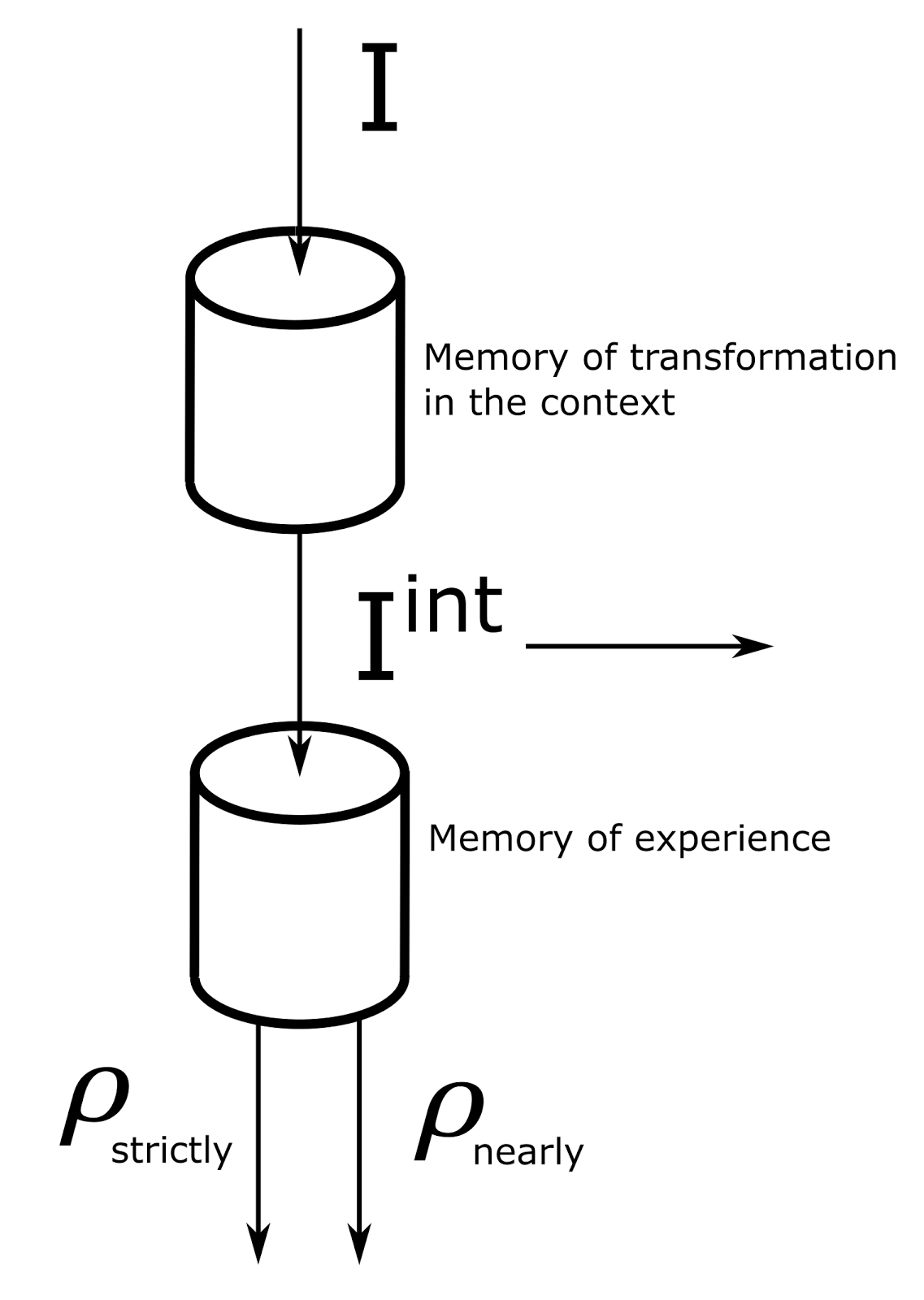
Scheme of basic calculations of a mini-column of a cortex.
Concepts that make up one description arrive at a mini-column sequentially one after another. Each of them is, in fact, a binary code. The minicolumn replaces the code of the original concept with the memorized code of the interpretation of this concept in the context of this minicolumn.
Binary interpretation codes of individual concepts accumulate on dendritic segments. Let me remind you that discharged binary codes can be added logically bit by bit. The addition results in a vector similar to the Bloom filter - a single binary vector that preserves the completeness of the description.
After all the waves of individual concepts from the description have passed, their interpretations will arise and add up, a binary code will appear on the dendritic segments corresponding to the interpretation of the initial information in the context of a mini-column.
It can be assumed that there are mechanisms that allow the transformed information and the original description to exist together without interfering with each other. It is possible that different layers of the cortex are responsible for such separate processing.
The combination of the activity of dendritic segments leads to the appearance of spike activity of the neurons of the minicolumn. A code composed of neuron activity can be interpreted as a hash function of the information description corresponding to the interpretation of the source information.
It was previously shown that a combination of neuronal activity can be a key, according to which the previous experience associated with such a key or one similar to it can be extracted from memory. The memory of each mini-column stores all previously occurred events. Previous experience, presumably, is stored in the form of pairs “hash from the information description - identifier” and pairs “hash from the identifier - information description”.
This is where the need for distributed duplicate memory becomes clear. Cloning the same memory to all mini-columns is necessary so that each mini-column can compare its interpretation with all previous experience independently, without interfering with the rest of the mini-columns. If the memory were shared and stored somewhere in one place, the verification of a million hypotheses could only be carried out sequentially one after another. Real parallelization requires not only the availability of parallel computing power, but also the corresponding parallel access to memory. A similar problem is solved when computing on video cards. When each processor requires quick access to memory, there is nothing left to do but provide each of them with its own memory.
It can be assumed that the result of comparing the interpretation of the current description and memory is the calculation of the correspondence functions. The first matching function indicates that there is an exact match between the interpretation and some memory elements. The second function evaluates the general similarity of the interpretation and experience stored in memory. Later, when the generalization procedure is described, one more type of correspondence will be shown - the correspondence of the interpretation to the factors highlighted due to previous experience.
The signals of the correspondence functions can potentially be encoded by changing the membrane potential of individual neurons or neural groups.
The correspondence functions allow us to judge how appropriate the mini-column context is for interpreting current information, that is, how much the interpretation obtained in this context corresponds to previous experience.
As a result, each mini-column has its own hypothesis of interpretation of the current description and an assessment of how meaningful this interpretation is. Having made a comparison between the mini-columns in a certain way, you can select the mini-column, the context of which is best suited for the interpretation of current information.
The interpretation obtained on the “successful” mini-column is based on concepts common to the entire cortical zone. Interpretation can be distributed in a pattern-wave fashion throughout the cortical zone and is remembered by all cortical minicolumns. To do this, the corresponding memory identifier must be submitted to the cortical zone. New experience will be saved in each mini-column. Moreover, not the own interpretation of the mini-column will be saved, but the correct interpretation obtained in a different, “correct” context. It is with this interpretation that the subsequent information will be compared. And if subsequently in some context an interpretation arises, the meaning of which we will be familiar with in a different context, this will not prevent us from learning this meaning in a new context for this meaning.
Recognition of a familiar meaning in another context new to that meaning is very important. Perhaps this is a key point in understanding the basic idea of the described architecture of the brain. For example, for the image, its meaning is that image that it was possible to recognize on it. Visual contexts can be various options for displacement. Then see in one place, and then find out in another - this is to find the old meaning in a new context.
Another example. When a person sleeps, his breathing slows down and you know it. When you see the first time in your life that the indicator light is slowly turning on and off on the computer, you immediately realize that the computer is in sleep mode.
Most of the information comes to us not in the form of an exact repetition of something familiar, but in a form where we can potentially find an analogy with something known. The main point of the Turing test is precisely to check how far the computer’s ability to understand such contextual transfers of meaning extends.
Let's go back to the mini-columns. On the elements of the winning mini-column, depending on what is required, you can reproduce either the appropriate interpretation of the current information, or the memory most suitable for the current description from previous experience, or any other information stored in the mini-column. The reproduced information can spread over the cortex, and can also be projected onto other zones for further processing.
If the source information allows for multiple interpretations, then all of them can be obtained sequentially one after another. To do this, after determining the first interpretation, it is enough to suppress the activity of the corresponding context and repeat the procedure for selecting the context. So one after another, you can isolate all possible semantic interpretations of the analyzed information.
Most likely, the choice of interpretations, which may be the meaning of the information, does not occur sequentially in terms of compliance, but by a probabilistic method. The correlation of the correspondence functions allows one to determine the probability of each of the interpretations. Subsequent selection can be made randomly, based on the resulting probabilities. Such an approach allows in similar situations not always to focus on the same stereotypical interpretations, but from time to time to get new, sometimes unexpected interpretations.
The mini-column of the cortex in our approach looks like a universal module that performs both autonomous calculations and interaction with the surrounding mini-columns. But different zones are faced with different information tasks. In some tasks, the number of contexts and the smaller amount of internal memory of mini-columns is of greater importance, in others, on the contrary, with fewer contexts, it may be more important to increase the internal memory and, as a result, increase the capacity of the internal hash code, i.e. the number of neurons in the mini-column. The optimal configuration of universal computing modules for the tasks of a particular zone of the cortex can go in two ways. First, for different zones of the cortex, the number of neurons in the minicolumn can vary, which is especially evident in the example of the primary visual cortex. Secondly, It is potentially possible to combine several vertical columns of neurons into one computational module. The range of axon and dendritic neuron trees, which is about 150 microns in diameter, allows you to combine several columns into one computer system without changing the general principles of operation described above.
In addition, it can be assumed that a full copy of the memory does not have to fit into a single mini-column, but can be distributed in the space of several neighboring mini-columns. Since the diameter of the dendritic tree is about 300 μm, potentially such a space is available to each mini-column for working with memory.
So far, a very approximate model has been given, allowing you to understand the basic principles of work with meaning. To make this model truly workable, a few more key elements are missing. I will try to describe them in the following parts.
Alexey Redozubov
P.S. The saga continues with the translation. Together , the materials are translated into English (coordinator - Dmitry Shabanov) American colleagues from Duke University are doing the final editing. But you need to translate to the level when they understand the meaning. The deadlines are incredibly tight. If there is an opportunity and desire to translate several paragraphs, then join.
The logic of consciousness. Entry
Logic of consciousness. Part 1. Waves in a cellular automaton.
Logic of consciousness. Part 2. Dendritic waves.
Logic of consciousness. Part 3. Holographic memory in a cellular automaton.
Logic of consciousness. Part 4. The secret of brain memory.
Logic of consciousness. Part 5. A semantic approach to the analysis of information.
Logic of consciousness. Part 6. The cerebral cortex as a space for calculating meanings.
Logic of consciousness. Part 7. Self-organization of context space
The logic of consciousness. Explanation "on the fingers"
The logic of consciousness. Part 8. Spatial maps of the cerebral cortex.
Logic of consciousness. Part 9. Artificial neural networks and mini-columns of the real cortex.
Logic of consciousness. Part 10. The task of generalization. The
logic of consciousness. Part 11. Natural coding of visual and sound information.
Logic of consciousness. Part 12. Search for patterns. Combinatorial space