It's not so easy to zero out arrays in VC ++ 2015
- Transfer
 What is the difference between these two definitions of initialized C / C ++ local variables?
What is the difference between these two definitions of initialized C / C ++ local variables?char buffer[32] = { 0 };
char buffer[32] = {};One difference is that the first is valid in C and C ++, and the second only in C ++.
Well then, let's focus on C ++. What do these two definitions mean ?
The first one says: the compiler must set the value of the first element of the array to zero and then (roughly speaking) initialize the remaining elements of the array with zeros. The second means that the compiler must initialize the entire array with zeros.
These definitions differ slightly, but in fact there is only one result - the entire array must be initialized with zeros. Therefore, according to the “as-if” rule in C ++, they are the same. That is, any sufficiently modern optimizer should generate identical code for each of these fragments. Right?
But sometimes the differences in these definitions do matter. If (hypothetically) the compiler takes these definitions very literally, then for the first case the following code will be generated:
алгоритм 1: buffer[0] = 0;
memset(buffer + 1, 0, 31);while for the second case the code will be like this:
алгоритм 2: memset(buffer, 0, 32);And if the optimizer does not notice that these two statements can be combined, then the compiler can generate less efficient code for the first definition than for the second.
If the compiler literally implemented algorithm 1, then a zero value will be assigned to the first byte of data, then (if the processor is 64-bit) three write operations of 8 bytes will be performed. To fill the remaining seven bytes, 3 more write operations may be required: first write 4 bytes, then 2 and then 1 more byte.
Well, this is hypothetically . This is exactly how VC ++ works. For 64-bit assemblies, the typical code generated for "= {0}" looks like this:
xor eax, eax
mov BYTE PTR buffer$[rsp+0], 0
mov QWORD PTR buffer$[rsp+1], rax
mov QWORD PTR buffer$[rsp+9], rax
mov QWORD PTR buffer$[rsp+17], rax
mov DWORD PTR buffer$[rsp+25], eax
mov WORD PTR buffer$[rsp+29], ax
mov BYTE PTR buffer$[rsp+31], alGraphically, it looks like this (almost all write operations are not aligned):

But if you omit zero, VC ++ will generate the following code:
xor eax, eax
mov QWORD PTR buffer$[rsp], rax
mov QWORD PTR buffer$[rsp+8], rax
mov QWORD PTR buffer$[rsp+16], rax
mov QWORD PTR buffer$[rsp+24], raxWhich looks something like this:

The second sequence of commands is shorter and faster. The difference in speed is usually difficult to measure, but in any case you should give preference to a more compact and faster code. The size of the code affects performance at all levels (network, disk, cache), so extra code bytes are undesirable.
This is generally not important, probably it will not even have any noticeable effect on the size of real programs. But personally, I find the code generated for "= {0};" quite funny. Equivalent to the constant use of "eee" in public speaking.
I first noticed this behavior and reported it six years ago, and recently discovered that this problem is still present in VC ++ 2015 Update 3. I was curious, and I wrote a small Python script to compile the code below using various array sizes and different optimization options for x86 and x64 platforms:
void ZeroArray1()
{
char buffer[BUF_SIZE] = { 0 };
printf(“Не оптимизируйте пустой буфер.%s\n”, buffer);
}
void ZeroArray2()
{
char buffer[BUF_SIZE] = {};
printf(“Не оптимизируйте пустой буфер.%s\n”, buffer);
}The graph below shows the size of these two functions in one specific platform configuration - size optimization for a 64-bit build - in comparison with BUF_SIZE values ranging from 1 to 32 (when the BUF_SIZE value exceeds 32, the sizes of the code variants are the same):

In cases where the value BUF_SIZE is 4, 8 and 32, the memory savings are impressive - the code size is reduced by 23.8%, 17.6% and 20.5%, respectively. The average amount of memory saved is 5.4%, and this is quite significant, considering that all these functions have a common epilogue, prolog and printf code .
Here i would likerecommend that all C ++ programmers, when initializing structures and arrays, give preference to "= {};" instead of = "= {0};". In my opinion, it is better from an aesthetic point of view, and seems to almost always generate shorter code.
But it’s almost. The results above demonstrate that there are several cases where “= {0};” generates a more optimal code. For single and double byte formats, “= {0};” immediately writes zero to the array (according to the command), while “= {};” zeroes the register and only then creates such a record. For a 16-byte format, “= {0};” uses the SSE register to reset all bytes at once - I don’t know why this method is not used more often in compilers.
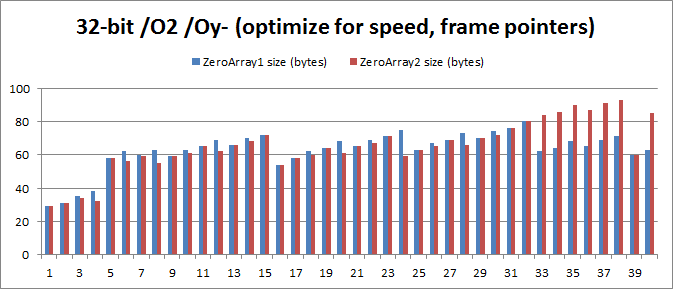
So, before recommending anything, I considered it my duty to test various optimization settings for 32-bit and 64-bit systems. Key results:
32-bit with / O1 / Oy-: Average memory savings from 1 to 32 are 3.125 bytes, 5.42%.
32-bit s / O2 / Ou: Average memory savings of 1 to 40 are 2.075 bytes, 3.29%.
32-bit s / O2: Average memory savings of 1 to 40 are 1,150 bytes, 1.79%.
64-bit s / O1: Average memory saving from 1 to 32 is 3.844 bytes, 5.45%
64-bit s / O2: Average memory saving from 1 to 32 is 3.688 bytes, 5.21%.
The problem is that the result for 32-bit / O2 / Ou, where “= {};” is on average 2.075 more bytesthan with "= {0};". This is true for values from 32 to 40, where the code "= {};" is usually 22 bytes larger! The reason is that the code “= {};” uses the commands “movaps” instead of “movups” to nullify the array. This means that he has to use a lot of commands only to ensure that the stack is aligned on 16 bytes. This is bad luck.
conclusions
Nevertheless, I recommend that C ++ programmers give preference to “= {};”, although somewhat conflicting results show that the advantage provided by this option is negligible.
It would be nice if the VC ++ optimizer generated identical code for these two components, and it would be great if this code was always perfect. Maybe someday it will be so?
I would like to know why the VC ++ optimizer is so inconsistent in deciding when to use 16-byte SSE registers for zeroing memory. On 64-bit systems, this register is used only for 16-byte buffers initialized with "= {0};", although more compact code is usually generated with SSE.
I think these difficulties with code generation are also characteristic of a more serious problem related to the fact that adjacent aggregate initializers are not combined. However, I have already devoted quite a lot of time to this issue, so I will leave it at the theoretical level.
Here I reported this bug, and a Python script can be found here .
Please note that the code below, which should also be equivalent, in any case generates even worse code than ZeroArray1 and ZeroArray2.
char buffer[32] = “”;Although I did not test myself, I heard that the gcc and clang compilers did not fall into the trap of “= {0};”.
In earlier versions of VC ++ 2010, the problem was more serious. In some cases, the memset call was used, and “= {0};” under any circumstances guaranteed incorrect address alignment. In earlier versions of VC ++ 2010 CRT, misalignment caused the last 128 bytes of data to be written four times slower (the stosb command instead of stosd). This was quickly fixed.
Translated by ABBYY LS