Accelerate SQLAlchemy for architectural astronauts

Habr, this is a report by software engineer Alexey Starkov at the Moscow Python Conf ++ 2018 conference in Moscow. Video at the end of the post.Hello! My name is Alexey Starkov - I, in my best years, work at the plant.
Now I work at Qrator Labs. Basically, all my life, I have been involved in C and C ++ - I love Alexandrescu, “Gang of Four”, the principles of SOLID - that’s all. Which makes me an architectural astronaut. The last couple of years I've been writing in Python, because I like it.
Actually, who are the “architectural astronauts”? The first time I met this term was Joel Spolsky, you probably read it. He describes "astronauts" as people who want to build an ideal architecture, who hang an abstraction, above an abstraction, above an abstraction that is becoming more and more common. In the end, these levels go so high that they describe all possible programs, but they do not solve any practical problems. At this point, the "astronaut" (this is the last time this term is surrounded by quotes) ends the air and he dies.
I also have a tendency towards architectural astronautics, but in this report I will tell you a little about how it bit me and did not allow me to build a system with the necessary performance. The main thing - how I overcame it.
The summary of my report: was / became.

An increase of thousands and millions of times. When I made this slide, the only thought I had was: “How?”

Where could I mess up so much? If you do not want to mess up just like me - read on.

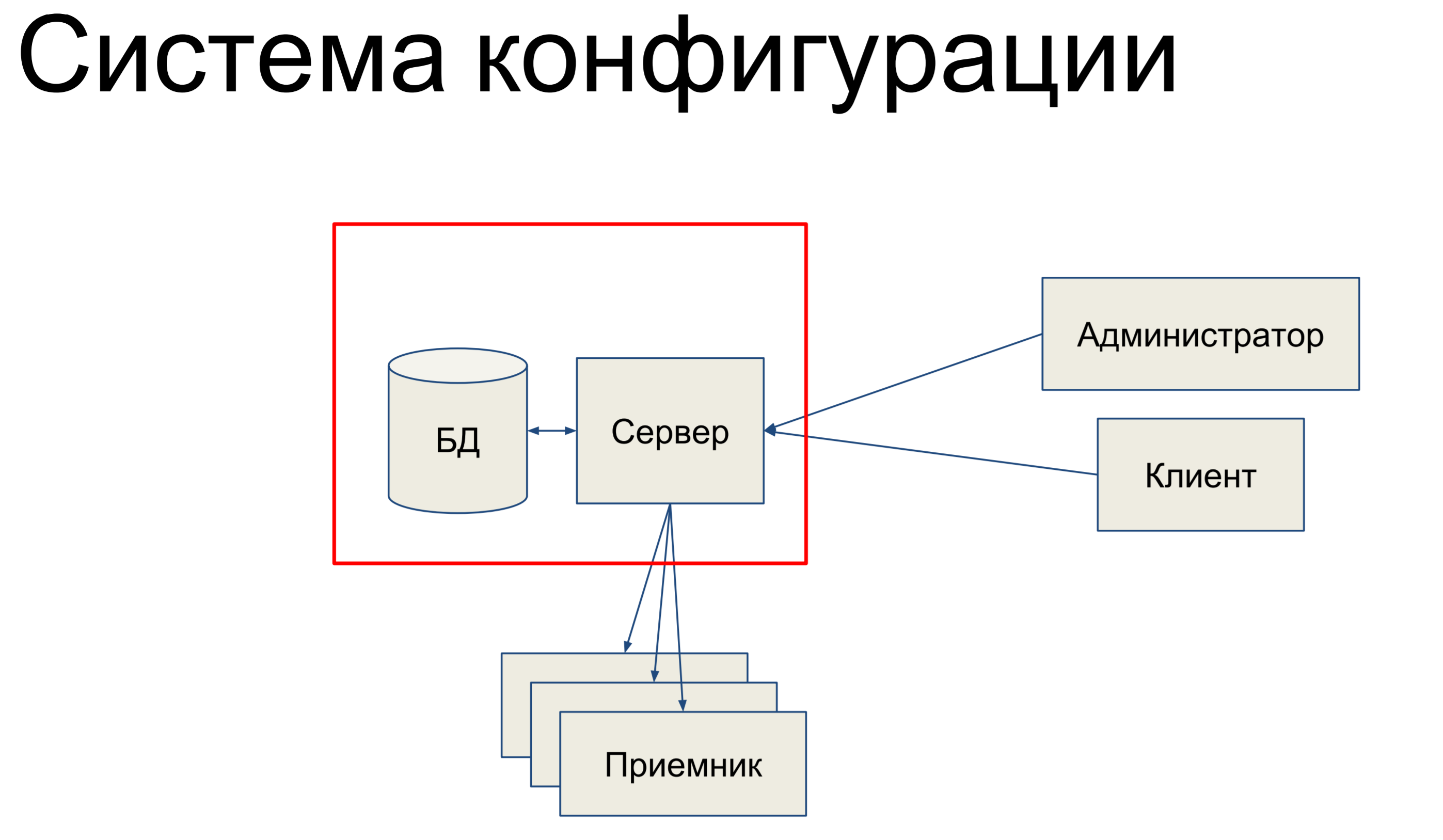
I will talk about the system configuration. The configuration system is an internal tool in Qrator Labs that stores the configuration for Software Defined Network (SDN), our filtering network. It is committed to synchronizing the configuration between components and keeping track of its state.

What does it briefly consist of? We have a database that stores a replica of our configuration for the entire network, and there is a server that processes the commands that come to it and in some way changes the configuration.
Our technical administrators and clients come to this server and use the console, through endpoint API endpoints, REST API, JSON RPC and other issues commands to the server, as a result of which it changes our configuration.
Teams can be very simple and more difficult. Then, we have a certain set of receivers that make up our SDN and the server pushes the configuration to these receivers. Sounds pretty simple. Basically, I will talk about this part here.
Since it is she who is related to the database and to alchemy.

What is the peculiarity of this system? It is quite small - mediocre. Hundreds of thousands, to millions, of entities are stored in this database. The peculiarity is that the graph of relations between entities is rather complicated. There are several hierarchies of inheritance between entities, there are inclusions, there are simply dependencies between them. All these restrictions are due to business logic and we must comply with them.
The ratio of write requests to read requests is approximately 15: 1. Here it is clear: many commands come to change the configuration and once in a long period of time we push the configuration to the end points.
MySQL is used internally - it is available in other products of our company, we have quite a serious expertise on this database, there are people who know how to work with it: build a data scheme, design queries and everything else. Therefore, we took MySQL as a universal relational database.

What was the problem after we designed this system? The execution of one command took from one to thirty seconds, depending on the complexity of the command. Accordingly, the delay in execution reached five minutes. One team came - 30 seconds, the second and so on, a pile of accumulated - a delay of 5 minutes.
The delay in applying the configuration is up to ten minutes. It was decided that this is not enough for us and it is necessary to carry out optimization.

The first is that before any optimization is carried out, it is necessary to investigate and find out what the matter is.

As it turned out, we lacked the most important component to investigate - we did not have telemetry. Therefore, if you are designing a system, first, at the design stage, lay telemetry into it. Even if the system is initially small, then a little more, then even more - as a result, everyone comes to a situation where you need to watch the traces, but there is no telemetry.
What can be done next if you do not have telemetry? You can analyze the logs. Here, quite simple scripts go through our logs and turn them into such a table, illustrating the fastest, slowest and average command execution time. Starting from here, we already see in which places we have gaps: which commands are executed longer, which ones are faster.

The only thing that should be noted - analyzing the logs, we consider only the execution time of these commands on the server. This is the first stage - the one that is marked as t2. t1 is how the client sees the execution time of our team: getting into the queue, waiting, execution on the server. This time will be longer, so we optimize the time t2, and then use the time t1 to determine whether we have reached the goal.
t1 is the metric of the quality of our speed.

Respectively, this is how we all teams repurposed - that is, we took a log from the server, drove it through our scripts, looked at it and identified the components that work most slowly. The server is built quite modularly, a separate component is responsible for each command, and we can profile the components individually - and make benchmarks for them. We had such a class - for each problem component we wrote, in which we did some activity in code_under_test (), depicting the combat use of the component. And there were two methods: profile () and bench (). The first one calls cProfile, showing how many times what was called, where the bottlenecks were.
bench () was run several times and considered us different metrics - this is how we evaluated the performance.
But it turned out that the problem is not that!

The main problem was in the number of queries to the database. There were a lot of requests and in order to understand why there were so many of them - let's look at how everything was organized.
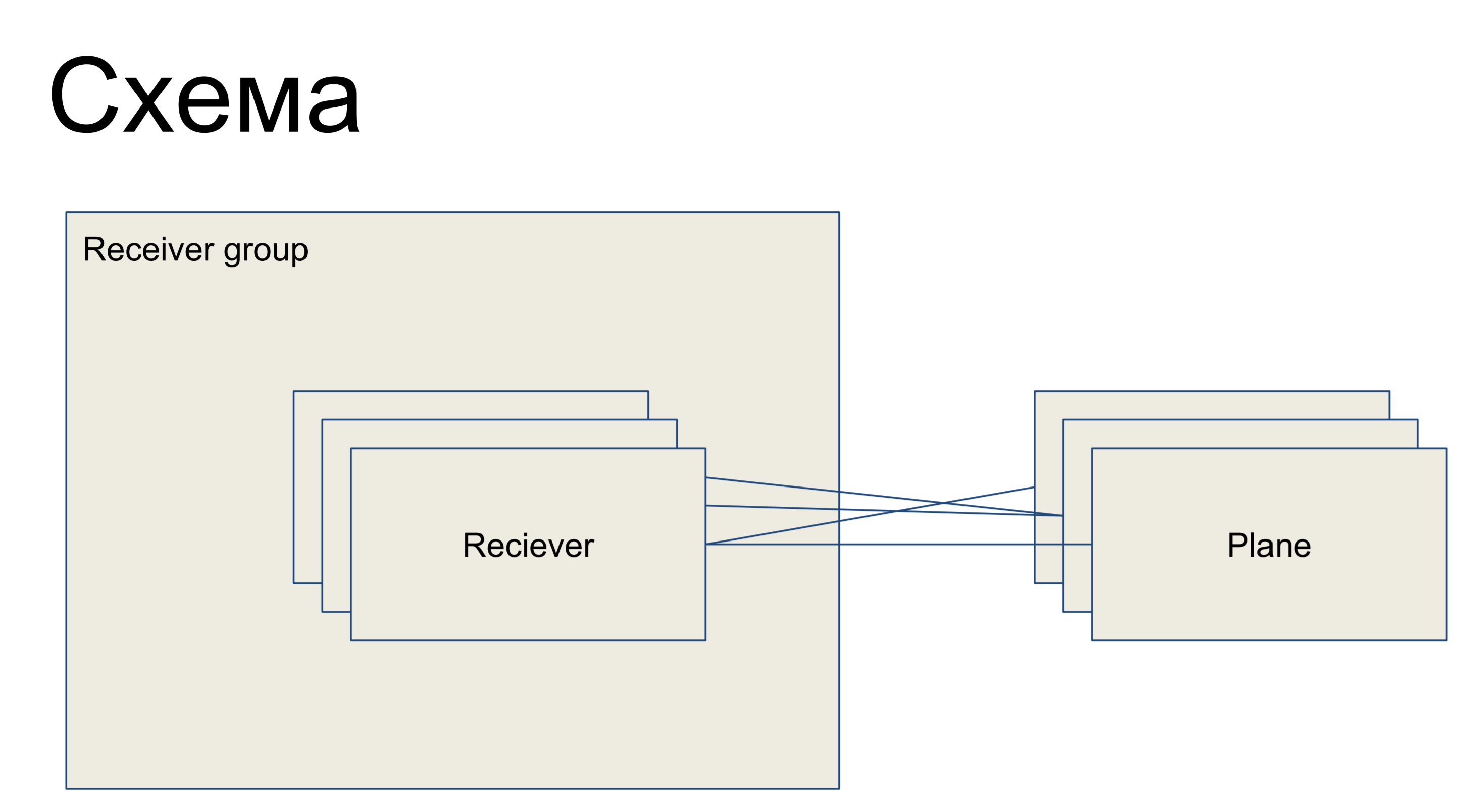
Before us is a piece of a simple circuit representing our receivers, represented in the form of the Reciever class. They are united in some group - receiver group. And, accordingly, there are some configuration patterns - configuration slices, which are a subset of configurations that are responsible for one “role” of this receiver. For example, for routing - the routing plane. Plains with receivers can be connected in any order - that is, this attitude is “many to many”.
This is a piece of a large scheme, which I give here so that further examples are clear.
What does every architectural astronaut want to do when he sees someone else's API? He wants to hide it, to abstract and write its own interface, in order to be able to remove this API, or rather hide it.
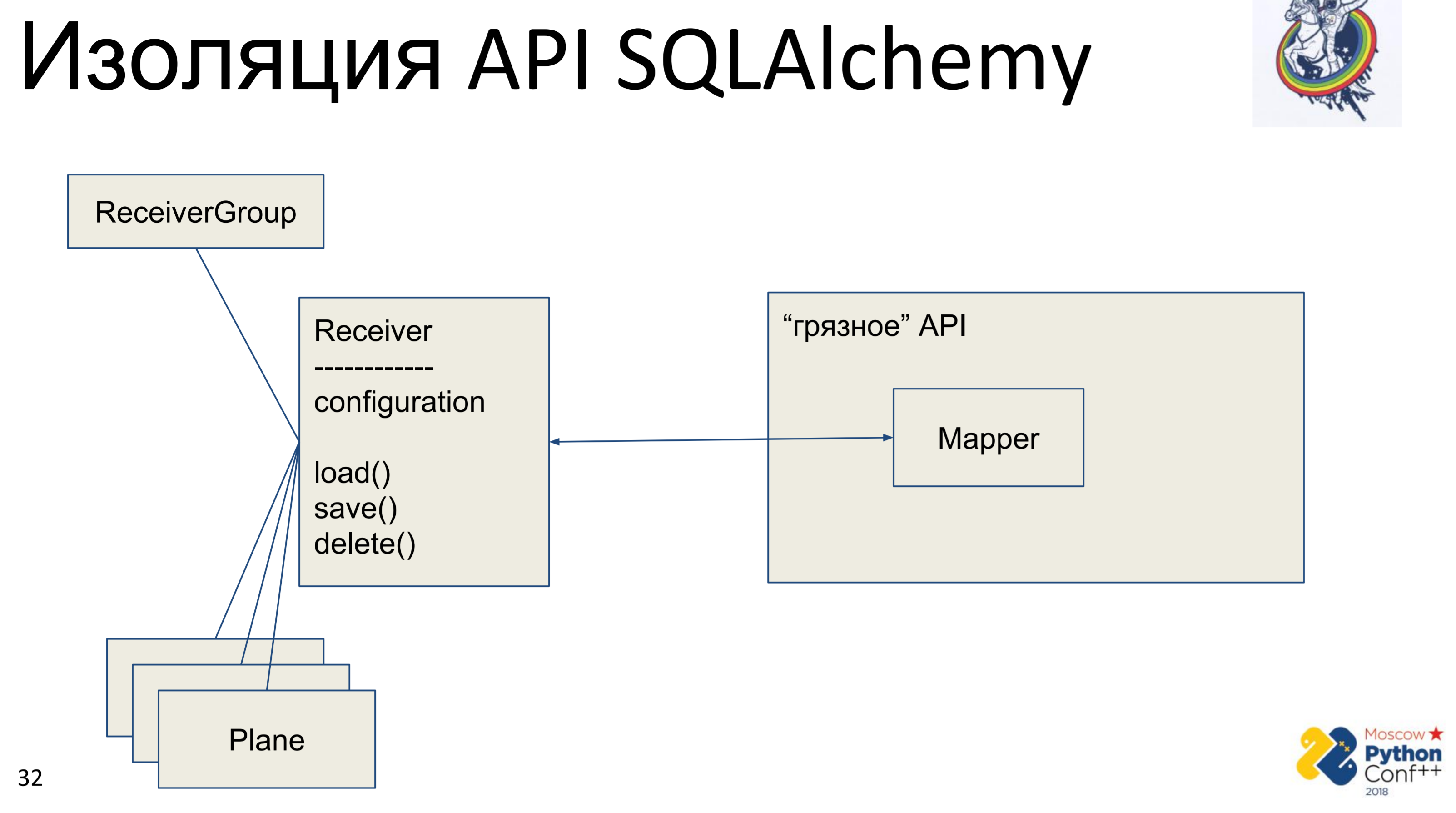
Accordingly, there is a “dirty” API of alchemy, in which there are, in fact, mappers and our “clean” class - Receiver, in which some configuration is stored and there are methods: load (), save (), delete (). And all the other related classes. We have a graph of Python objects that are somehow related to each other - each of them has a load (), save (), delete () method, which refers to the mapper of alchemy, which, in turn, refers to the API.

The implementation here is very simple. We have a load method that makes a query into the database and for each received object creates its own Python object. There is a save method that does the reverse operation — it looks if there is an object in the database, using the primary key, if not, it creates, adds, and then we save the state of this object. delete on the primary key gets and deletes an object from the database.

The main problem is immediately visible - this is mapping. At first we do it once from the Python object to the mapper, then the mapper mappit to the base. Additional mapping is one or two calls that may not be so scary. The main problem was the manual synchronization. We have two objects of our “clean” interface and one of them has an attribute change - how do we see that the attribute has changed in the other? No It is necessary to merge the changes into the database and get the attribute in another object. Of course, if we know that objects are present in the same context, we can somehow track this. But if we have two sessions in different places - only through the base, or to base the base in memory, which we did not do.
This load / save / delete is another mapper that completely duplicates the guts of alchemy, which is well written, tested. This tool has been around for many years, a lot of help is available on the Internet and duplicating it is also not very good.
See the icon in the upper right corner? So I will mark the slides, on which something is done for "purity", to increase the level of abstraction, for architectural cosmonautics. That is, slides without this icon are pragmatic and boring, uninteresting and can be not read.
What to do if a lot of requests are slow. How many? Actually a lot. Imagine the chain of inheritance: one object, it has one parent, and that one has another parent. We synchronize the child object - in order to do this, you first need to synchronize the parents. In order to synchronize the parent, you need to synchronize and its parent. Well, all synchronized. Actually, depending on how the graph is constructed here, we could walk and synchronize all these objects a hundred times - hence a large number of requests.
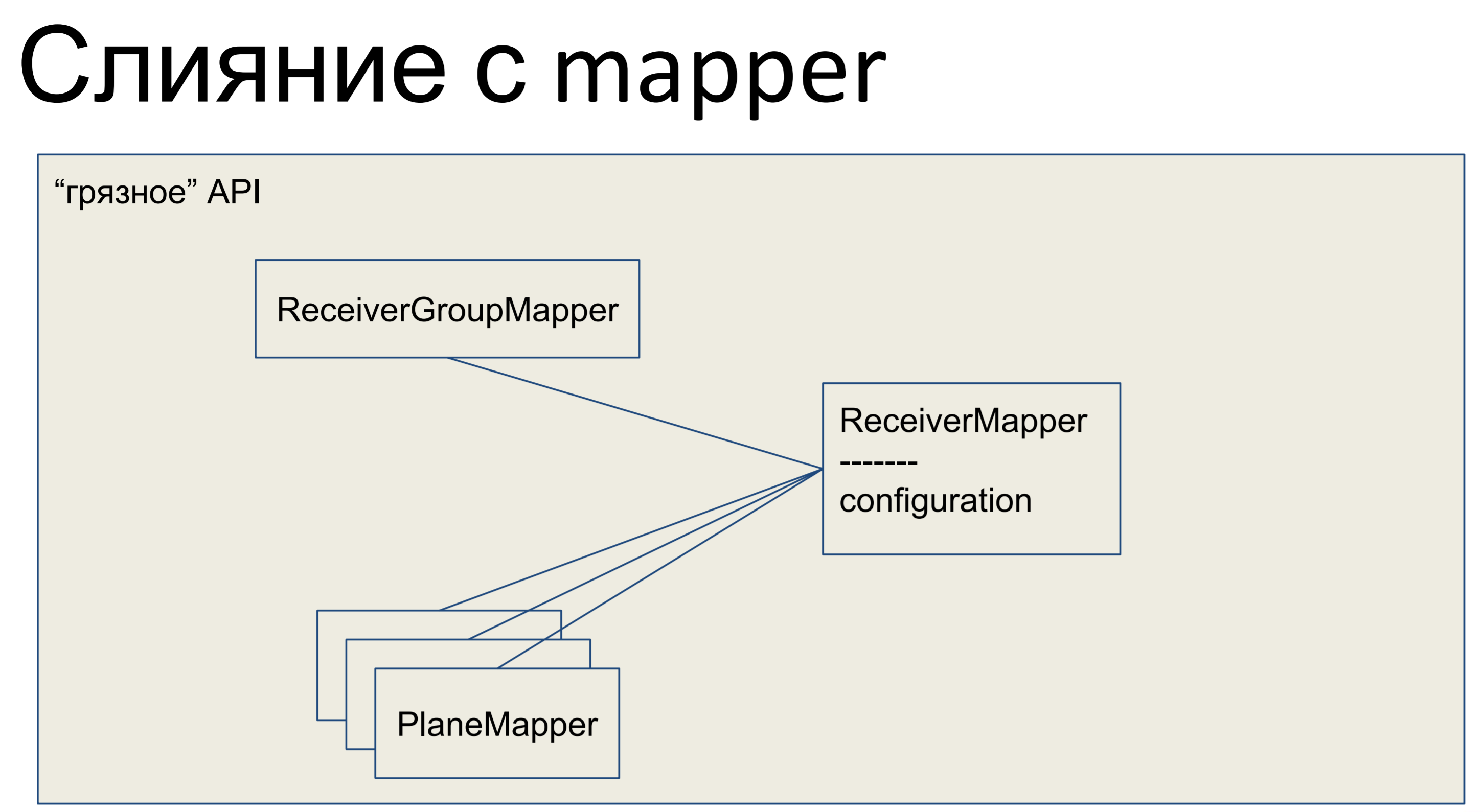
What have we done? We took all our business logic and put it in the mapper. All other objects we have also merged with mappers and all of our API, the entire data abstraction layer, turned out to be "dirty."

This is how it looks in Python - our mapper has some kind of business logic, and there is a declarative description of this table. Columns are listed, relationships. Here is such a class.

Of course, from the point of view of any astronaut, a dirty API is a disadvantage. Business logic in the declarative description of the database. Schemes mixed with business logic. Fu Ugly.
The description of the scheme is cluttered. This is actually a problem - if we do not have two lines of business logic, but a larger volume, then we have to scroll or search for a long time in this class in order to get to specific descriptions. Before that, everything was beautiful: in one place the description of the base, the declarative description of the schemes, in another place the business logic. And then the scheme is cluttered.
But, on the other hand, we immediately get the mechanisms of alchemy: the unit of work, which allows us to track which objects are dirty and which relays need to be updated; we receive the relationship, allowing to get rid of additional questions in a database, without watching that the corresponding collections were filled; and the identity map that helped us the most. The Identity map ensures that two Python objects are the same Python object if they have a primary key.
Accordingly, we immediately dropped the complexity to linear.

These are intermediate results. The speed immediately increased 10 times, the number of queries to the database dropped about 40-80 times and the RPS rose to 1-5. Oh well. But the API is dirty. What to do?
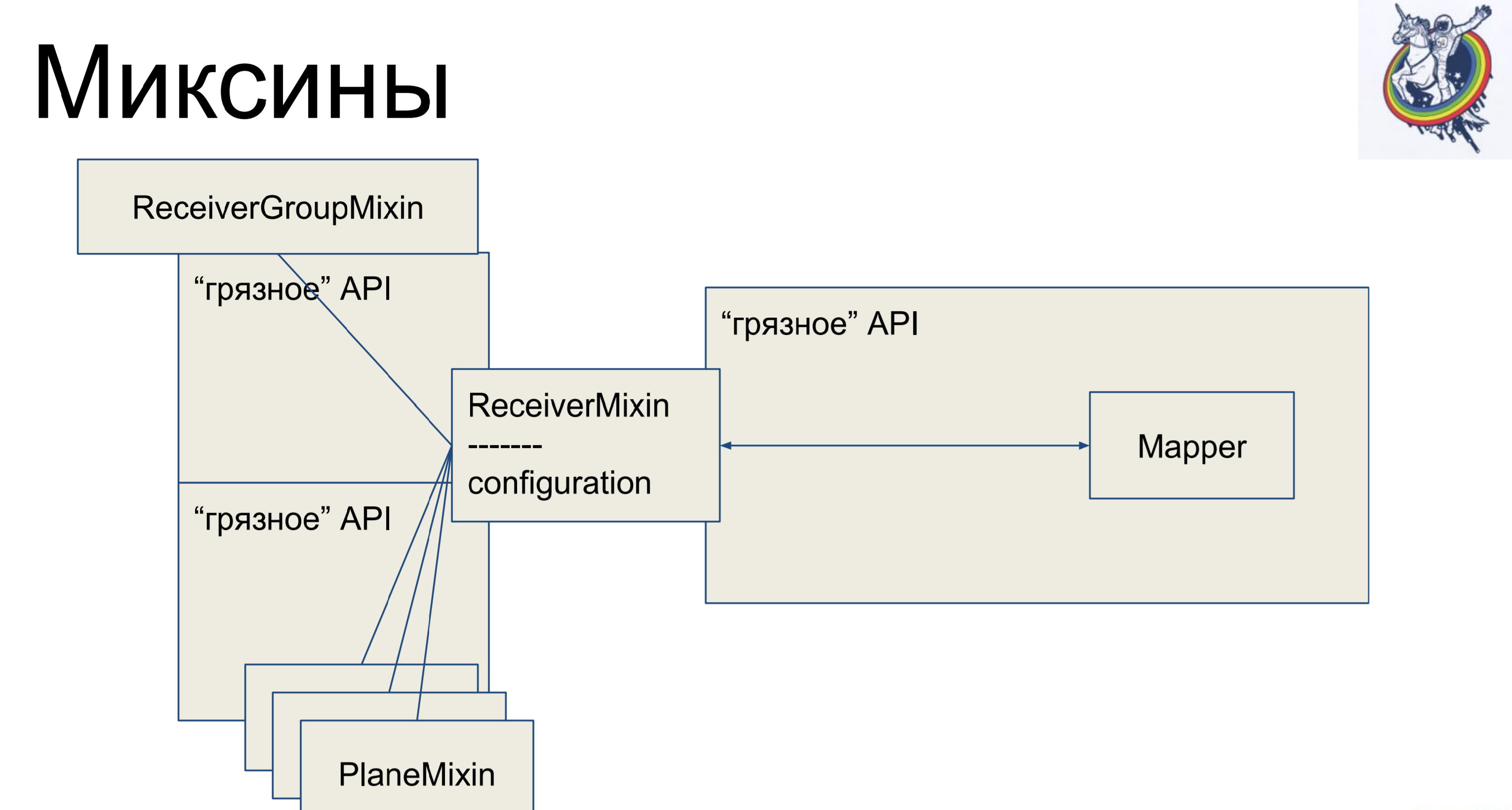
Mixins We take business logic, again we take it out of our mapper, but so that again there is no mapping, we will inherit our mapper inside alchemy from our mixin. Why not in the opposite direction? In alchemy, this will not work, she will curse and say: "You have two different classes referring to one tablet, there is no polyformism - go here." Is that allowed.
Thus, we have a declarative description in the mapper, which is inherited from the mixin and gets all the business logic. Very comfortably. And the rest of the classes are exactly the same. It would seem - cool, everything is clean. But there is one nuance - connections and relays remain inside alchemy, and when we have, say, join through an intermediate table secondary table, then the mapper of this label will somehow be present in the client code, which is not very nice.
Alchemy would not be such a good, well-known, framework if it did not give an opportunity to compete with it.

What does mixin look like? He has business logic, mappers separately, a declarative description of the table. Connections remain inside alchemy, but business logic is separate.
What does the general scheme look like?
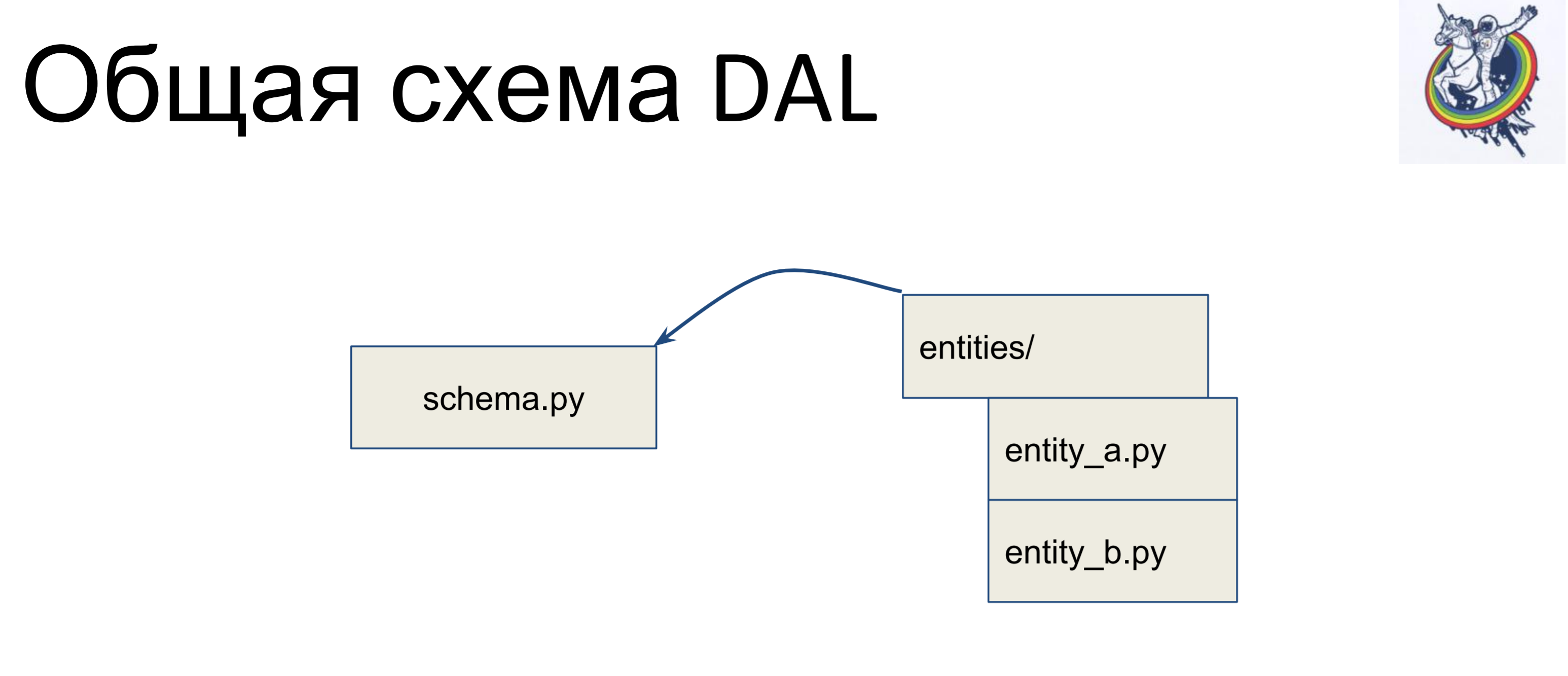
We have a schema file that contains all of our declarative classes — let's call it schema.py. And we have entities in business logic, separately. And, the entity data is inherited inside the schema file — we write a separate class for each entity, and inherit it in the schema. Thus, the business logic lies in one pile, the scheme is in the other, and they can be independently changed.
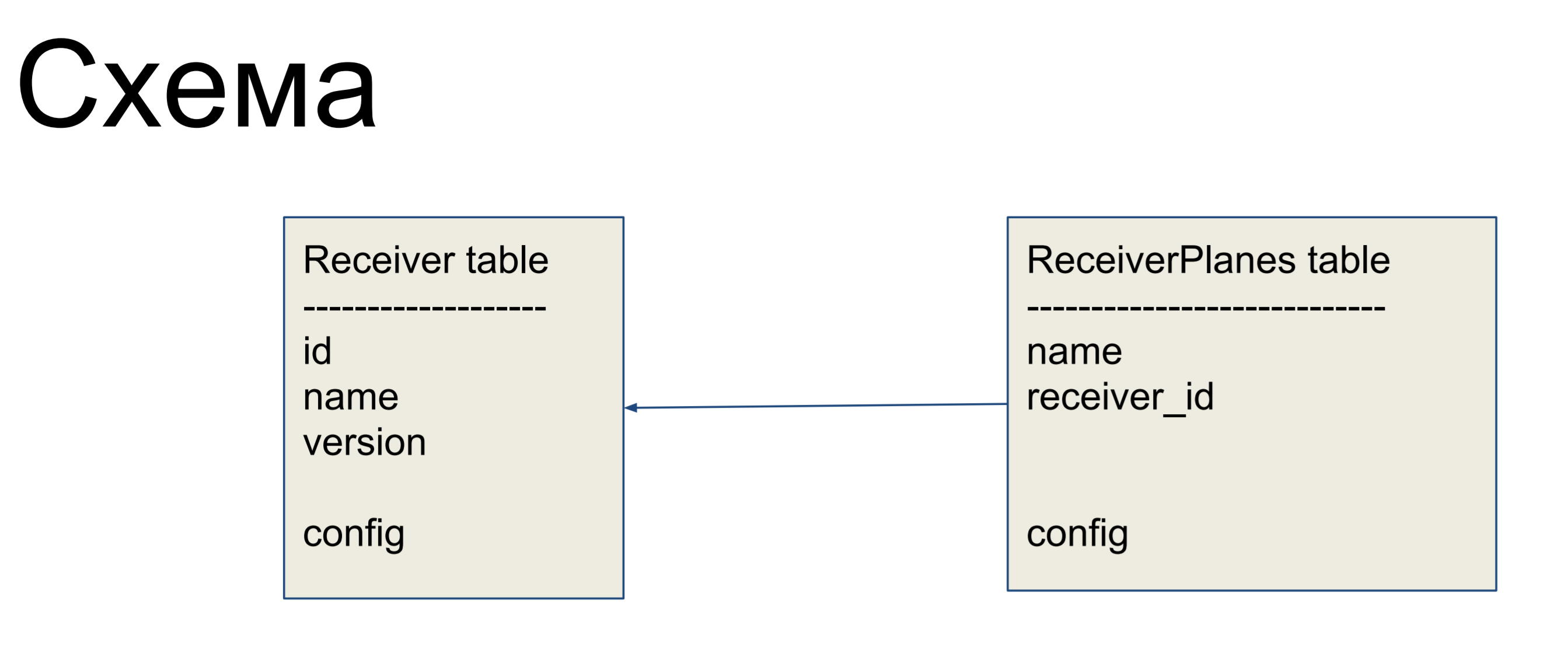
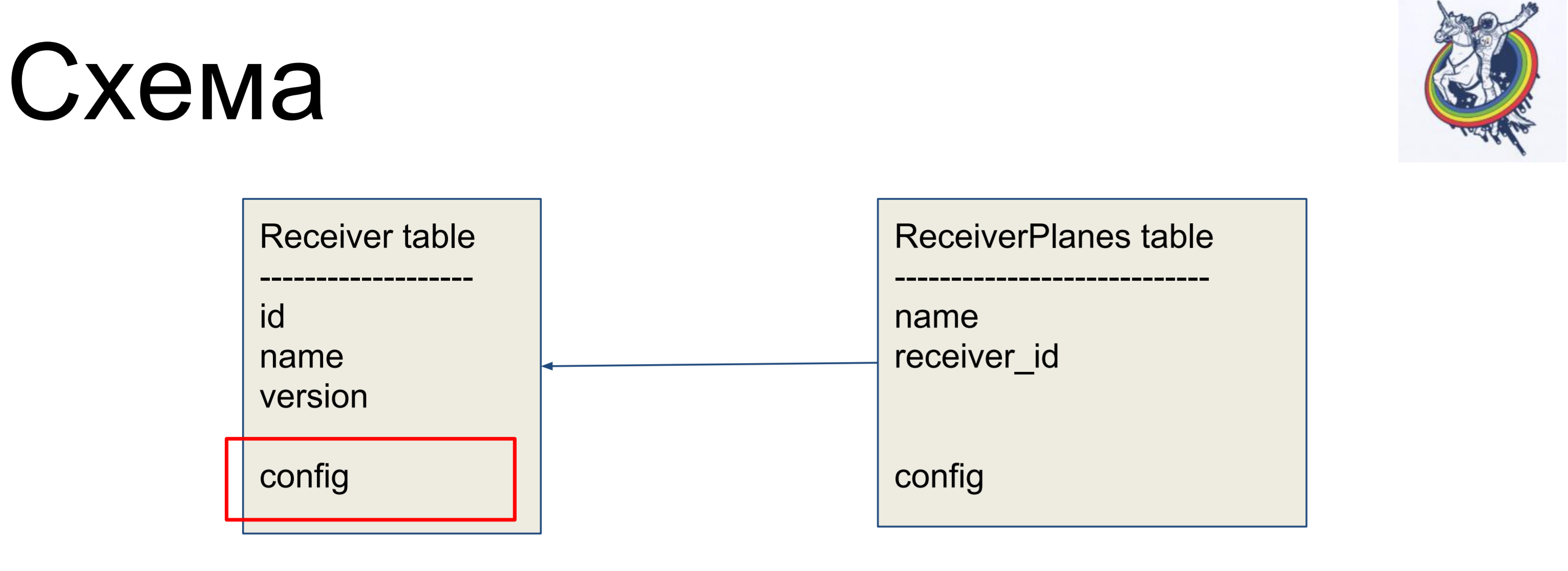
As an example of improvement, we will consider a simple scheme of two plates: receivers (Receiver table) and configuration slices (ReceiverPlanes table). The configuration slices with the many-to-one relationship are associated with the receivers label. There is nothing especially complicated.
In order to hide relationships inside the “dirty” interface of alchemy, we use relationships and collections.

They allow us to hide our mappers from client code.

In particular, two very useful collections are association_proxy and attribute_mapped_collection. We use them together. How a classic relationship works in alchemy: we have a relationship - this is a kind of collection, list, mappers. Mappers objects are the far end of the relationship. Attribute_mapped_collection allows you to replace this list with a dict, the keys in which are some of the attributes of the mappers, and the values are the mappers themselves.
This is the first step.
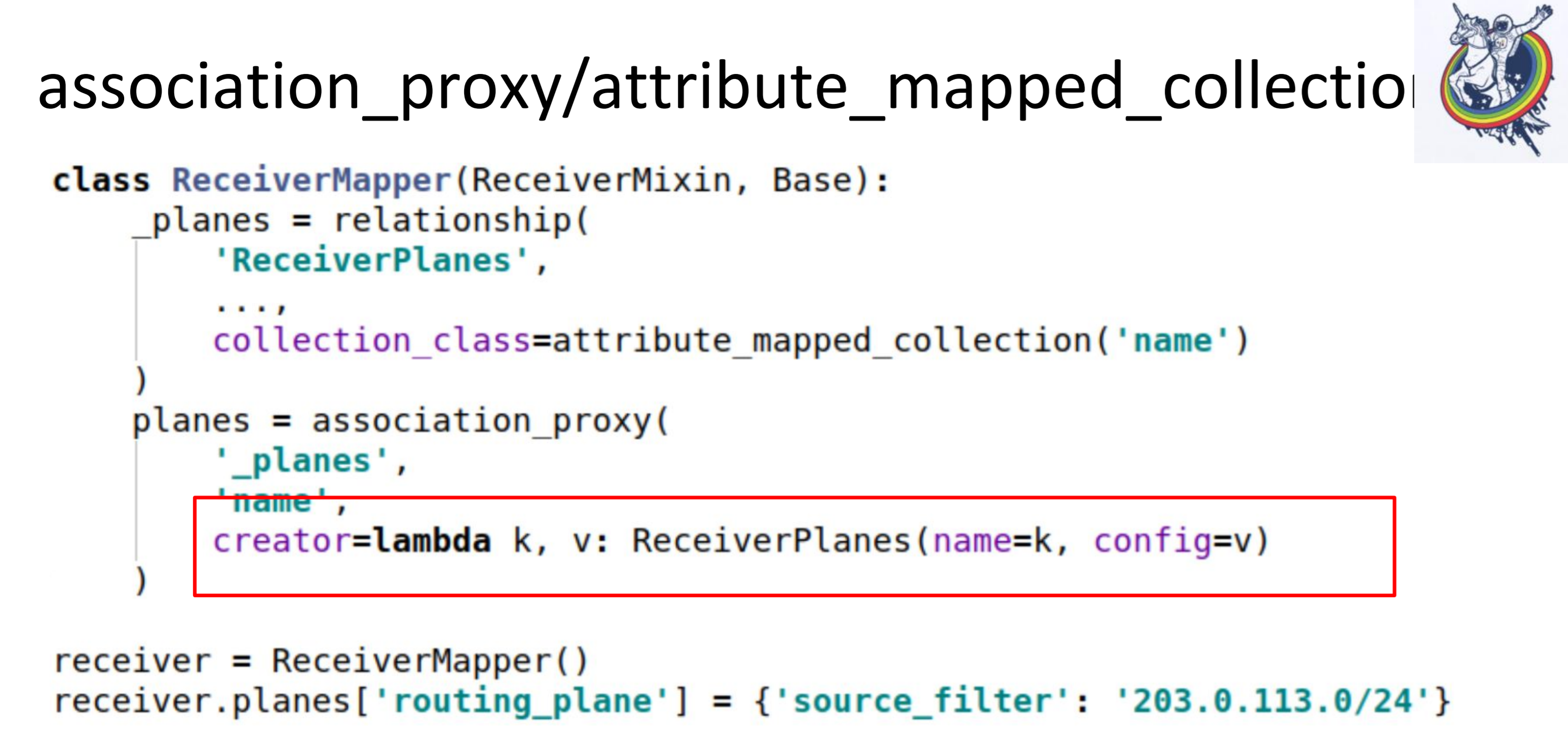
The second step, we are doing association_proxy over this relation. It allows us not to transfer the mapper to the collection, but to transfer some value that will later be used to initialize our mapper, ReceiverPlanes.
Here we have a lambda, in which we give the key and value. The key turns into the name of the configuration slice, and the value becomes the value of the configuration slice. As a result, in the client code, everything looks like this.

We just put a dictation in some dictionary. Everything works: no mappers, no alchemy, no databases.
True, there are pitfalls.

If we assign two different keys to the same key, or even one, two values — for each such set item lambda is called, an object is created — a mapper. And, depending on how the scheme is arranged, this can lead to different consequences, from “just violation of constraints” to unpredictable consequences. For example, you sort of object deleted from the collection, but he still remained there: you only deleted one. When I first started, I killed a lot of time for such things.
And a bit implicit sync. Association_proxy and attribute_mapped_collection may be slightly delayed: when we create a mapper object, it is added to the database, but it is not yet present in the collection attribute. It will appear there only when the attribute expires in this session. When it is expired, a new synchronization with the database will occur and it will get there.
To fight this, we used our own, self-written, collections. This is not even alchemy - you can simply create your own collection to overcome all this.
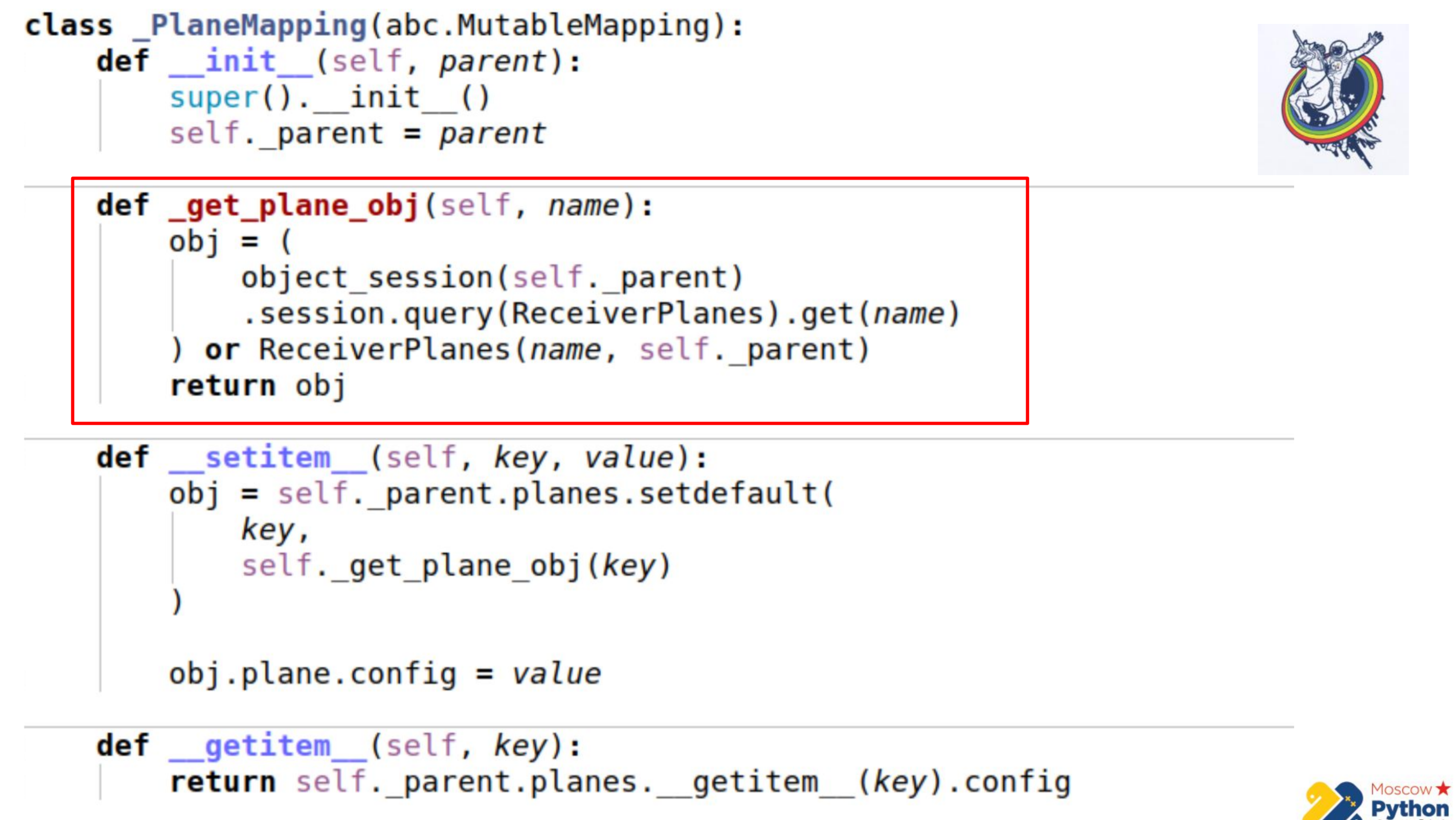
There is more code and the most important section is highlighted. We have a certain collection that inherits from muteble mapping - this is a dictation, in the keys of which you can change values. And there is the _get_plane_obj method - to get the configuration slice object.
Here we do simple things - we try to get it by name, by some primary key and, if not, then we create and return this object.
Next, we override only two methods: __setitem__ and __getitem__
In __setitem__, we add these objects to our collection, to a relationship. The only thing is that we assign the value at the very end. Thus, we implement the same mechanism as association_proxy - we pass there a value, a dict, and it is assigned to the corresponding attribute.
__getitem__ does reverse manipulation. It receives a key from an object from a relay and returns its attribute. There is also a small underwater stone here - if you cache a collection inside our mapping, it is possible to slightly out of sync. Because when alchemy has a collection attribute, then the collection is replaced with another one after it expires. Therefore, we can save the reference to the old collection and not know that the old has expired and a new one has already appeared. Therefore, in the last part we go straight to the alchemy instance, again we get the collection through __getattr__ and we do __getitem__ from it. That is, we cannot cache the Planes collection here.
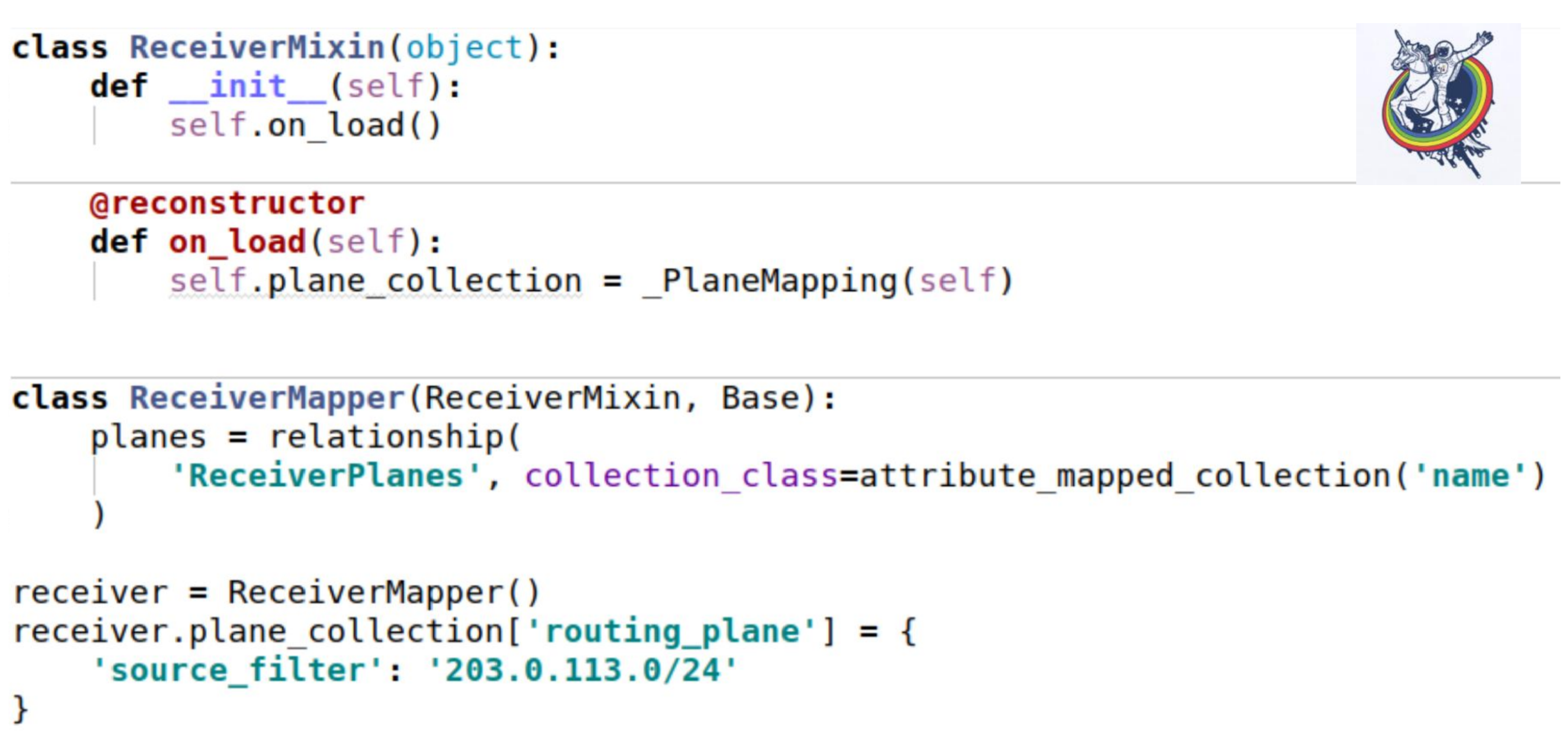
How does this collection spike on our mixins? As usual - we get a collection attribute. The only interesting place is that when we load an instance from the database, the __init__ method is not called. All attributes are substituted after the fact.
Alchemy gives the standard decorator reconstructor, which allows you to mark a method as callee after loading an object from the base. And just at boot time, we need to initialize our collection. Self - just this instance. The use is exactly the same as in the previous example.
But we still have the database ears visible in the schema - this is the configuration. What type of configuration? Is it varchar or is it a blob? In fact, the client is not interested. He has to work with abstract entities of his level. For this alchemy provides type decoration.

A simple example. Our database stores IPAddress as a varchar. We use the TypeDecorator class, which is included in alchemy, which allows, first, to specify which underlying database type will be used for this type and, second, to define two parameters: process_bind_param that converts the value to the database type and process_result_value, when we value from the database type we convert to a Python object.
The attribute from address gets as if the Python type IPAddress. And we can both call methods of this type and assign objects of this type to it and everything works for us. And the database is stored ... I do not know what is stored, varchar (45), but we can replace that line and the blob will be stored. Or if some native type supports IP addresses, then you can use it.
The client code does not depend on it, it does not need to be rewritten.
Another interesting thing is that we have a version. We want to immediately increase the version as soon as we change our object. We have some version counter, we have changed the object - it has changed, the version has increased. We do this automatically, so as not to forget.

For this we used the event. Events are events that occur at different stages of the mapper's life and they can be triggered when attributes change, when an entity transitions from one state to another, for example, “created”, “saved to base”, “loaded from base”, “deleted”; and also - at session level events, before the sql-code is issued to the database, before the commit, after the commit, also after the rollback.
Alchemy allows us to assign handlers for all these events, but the order of execution of handlers for the same event is not guaranteed. That is, it is certain, but it is not known what. Therefore, if the order of execution is important to you, then you need to make a registration mechanism.
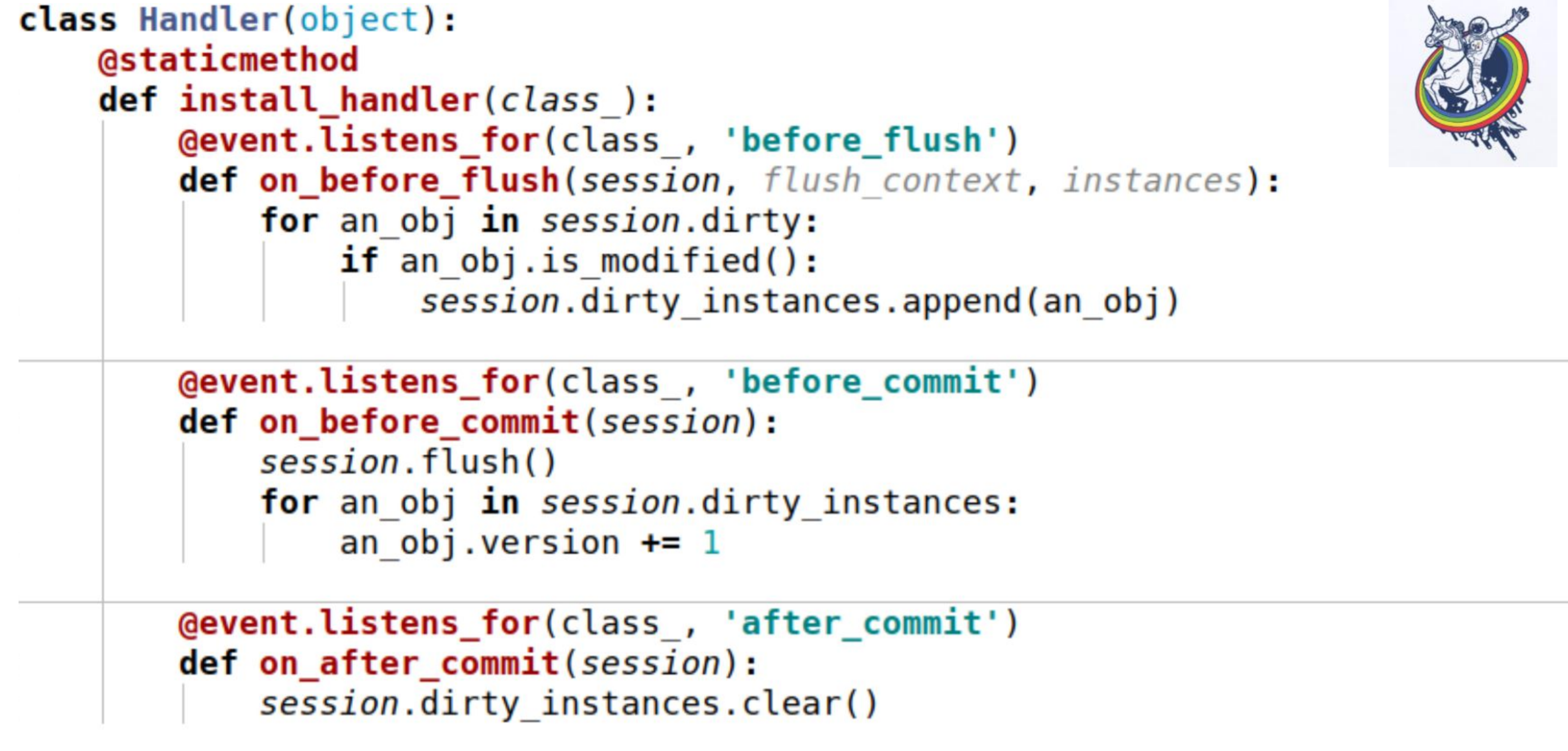
Here is an example. Three events are used here:
on_before_flush - before the sql-code is emitted to the database, we go through all the objects that alchemy marked as dirty in this session and check if this object is modified or not. Why is this necessary if alchemy has already marked everything? Alchemy marks an object as dirty as soon as an attribute has changed. If we assign this attribute the same value that it had - it will be marked as dirty. For this, there is a session method is_modified - it is used internally, I have not drawn it. Further, from the point of view of our semantics, from the point of view of our business logic, even if the attribute has changed - the object can still remain unmodified. For example, there is a certain list, in which two elements were swapped - from the alchemy point of view, the attribute has changed, but for business logic it doesn’t matter if the list contains, say,
And, as a result, we call another method specific to each object in order to understand whether the object is actually modified or not. And we add them to a certain variable associated with the session that we created ourselves - this is our dirty_instances variable, to which we add this object.
The next event happens before the commit - before_commit. Here, too, there is a small pitfall: if for the entire transaction we did not have a single flush, then flush will be called before the commit — in my case, the handler before the commit was called before the flush.
As you can see, what we have done in the previous paragraph may not help us and session.dirty_instances will be empty. Therefore, inside the handler, we once again do the flush, so that all the handlers before the flush volunteer and simply increment the version by one.
after_commit, after_soft_rollback - after a commit just clean, so that next time there are no excesses.
So you see, this install_handler method installs handlers for three events at once. As a class, we pass the session here, as this is an event of its level.

Here you go. I will remind you what we have achieved - the speed of 30-40 seconds for complex and large teams. Not at all, some were performed in a second, others in 200 milliseconds, as you can see from the RPS. Requests in the database began to number in the hundreds.

The result was a fairly balanced system. There was, however, one nuance. Some requests come from us in batches, emissions. That is, 30 requests arrive, and each of them is such! (speaker shows thumb)
If we process them in one second, then the last request in the queue will work for 30 seconds. The first is one, the second is two, and so on.

Therefore, we need to accelerate. What do we do?
In fact, alchemy consists of two parts. The first is an abstraction over the sql database called SQLAlchemy Core. The second is the ORM, the actual mapping between the relational database and the object representation. Accordingly, the alchemy core approximately one to one coincides with the sql - if you know the latter, then you will not have problems with the core. If you do not know sql - learn sql.
In addition, the core represents the smallest overhead. There is practically no pumping - requests are generated using a request generator, and then executed. Overhead over dbapi minimum.
We can build queries of any complexity, of any type, we can optimize them for the task. That is, if in the general case ORM doesn’t care how we build the database schema, there is a certain description of the tables, it generates some queries, not knowing what in this case will, for example, optimally remove from here, in the other - from there, here apply a filter, and there it is another, then we can make requests for the task.
The disadvantage is that we again came to manual synchronization. All events, relays - all this in the core does not work. We made a select, objects came to us, we did something with them, then an update, an insert ... the version needs to be incremented by hand, the constraints are checked independently. Core does not allow all this to be done conveniently, at a high level.
Well, we are not living the first day.

A simple example of use. Each mapper inside contains an __table__ object that is used in the core. Next, you see - we take the usual select, we list the columns, join two plates, indicate the left and right, indicate by what condition we join it, well, add the buy by order for taste. Next we feed this generated query into the session and it returns us an iterable, in which the tap-like objects are indexed both by the column name and by number. The number corresponds to the order in which they are listed in the select.

It became much better. The speed in the worst case dropped to 2-4 seconds, the most complex and longest query contained 14 teams and RPS 10-15. Solid.

What I would like to say in conclusion.
Do not procreate entities where they are not needed - do not wind up your own where there is a ready.
Use SQLA ORM is a very convenient tool that allows you to track events at a high level, respond to various events associated with the database, hide all the ears of alchemy.
If all else fails, the speed is not enough - use SQLA Core. This is still better than using pure raw SQL, because it provides a relational abstraction over the database. It automatically escapes the parameters, does the binding correctly, it doesn’t matter what database is under it - you can change it and Core supports different dialects. It is very convenient.
That's all I wanted to tell you today.