Archiving as a response to the "Spring package"

One of the main news sensations of recent days is the signing of the so-called “ Spring package ”. The highlight of the program is the requirement to store traffic for up to six months and metadata for three years. This legislative initiative has turned into full-fledged laws that will have to be respected. In fact, we are talking about the widespread creation of constantly updated archives, which requires the solution of various issues, including those related to the selection of suitable storage systems.
Archiving traffic and metadata does not imply the need for quick access. This information will not be used in the daily activities of companies, it should only be stored in case of a request from the authorities. This greatly facilitates the task of creating archives, making it possible to simplify their architecture.
In general, the archive should perform five main functions:
- Saving data for future use.
- Ensuring continuous user access to stored data.
- Ensuring confidentiality of access.
- Reducing the load on working systems by transferring static data to the archive.
- Use of data storage policies.
Traffic transmitted by users and metadata are characterized by a wide variety and lack of structure. Add to this the huge volume and speed of information growth, which is especially characteristic of large companies and services, and you get the classic definition of big data. In other words, changes in legislation require a massive solution to the problem of storing big data that constantly and with great speed arrives in archival systems. Therefore, archives should not only be high-performance, but also have excellent horizontal scalability, so that if necessary it would be relatively easy to increase the storage capacity.
Big Data Archiving
The EMC InfoArchive platform is designed to solve such problems ; we wrote about it a year ago. It is a flexible and powerful enterprise-class archiving platform, which is a combination of storage systems (NAS or SAN) and a software archiving platform.
The benefits of InfoArchive include:
- Support for international standards, including open XML and OAIS (Open Archival Information System) standards
- high security of stored data,
- the convenience of managing large volumes of structured and unstructured data,
- as well as extensive configuration and scaling capabilities.
InfoArchive consists of the following components:
- Web application : the main application that provides easy access to most of the settings and functions of the system.
- Server : archiving services for Web Server.
- XML Repository (xDB) : Storage services for InfoArchive Server. The xDB database is included in the InfoArchive distribution and is automatically installed as part of the system kernel.
- Shell [optional] : a command-line tool for performing administrative tasks, adding data, managing and querying objects.
- The framework for adding data [optional] .
High-Level InfoArchive Architecture:
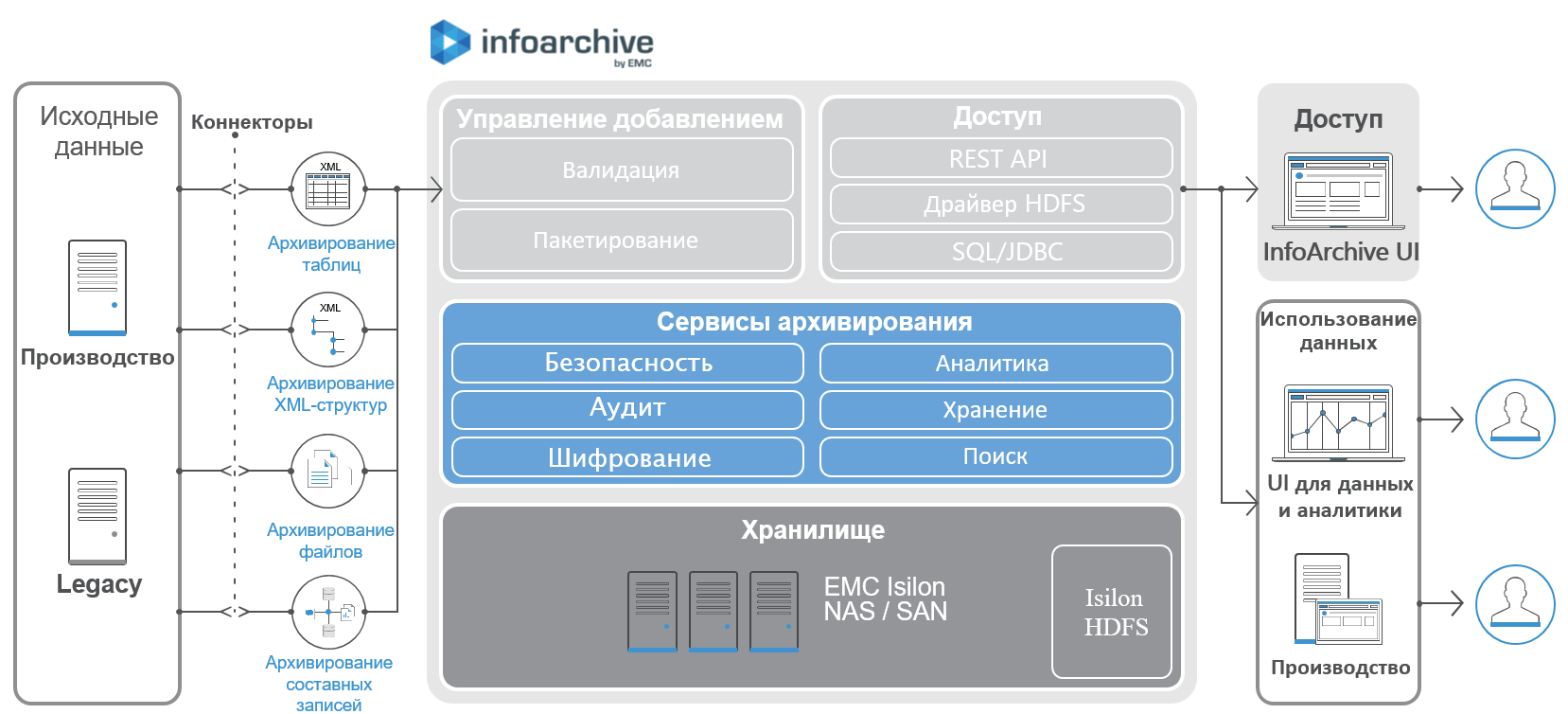
Depending on security, licensing, and other considerations, InfoArchive can be installed on a single host, or distributed across multiple hosts. But in general, when creating a repository, it is recommended to use the simplest architecture, this allows to reduce the delay in data transfer.
The logical architecture of InfoArchive is as follows:
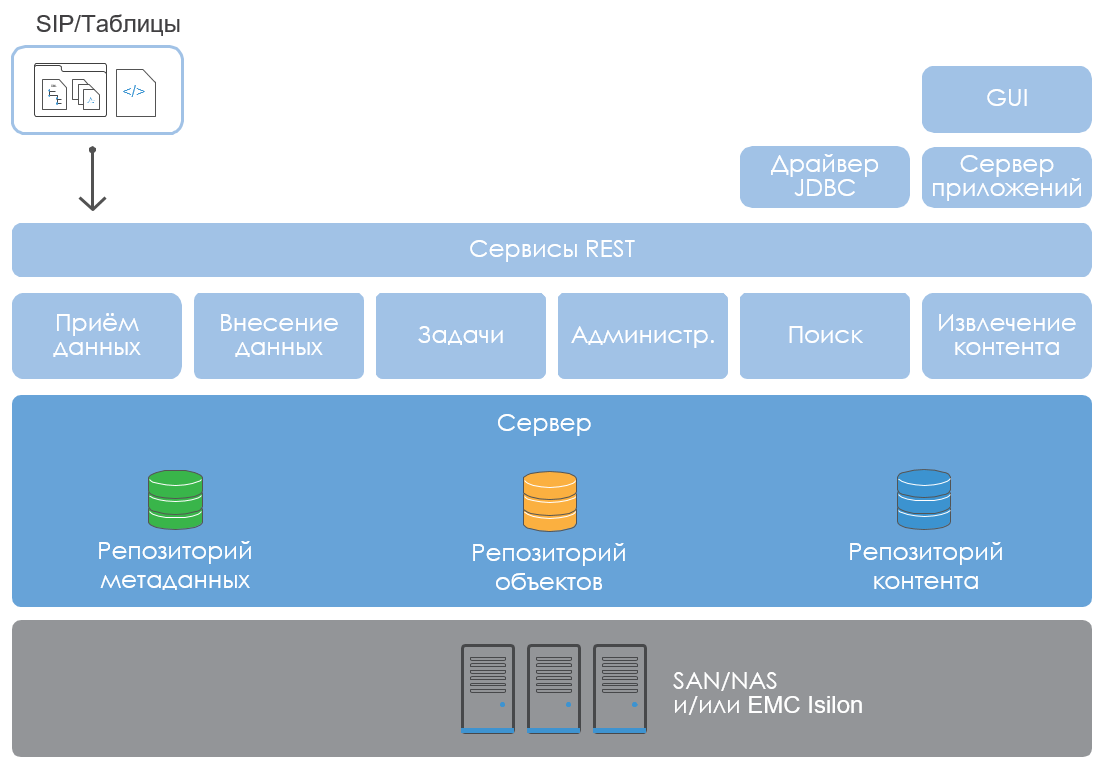
Servers can scale vertically, or "specialize" in different functions of REST services - adding data, searching, administering, etc. This allows you to implement any degree of scalability, increasing the archive in accordance with the needs. And load balancing is easily done using the "classic" HTTP balancer.
xDB
One of the key components of InfoArchive is the automatically deployed xDB database engine. Its properties largely determine the capabilities of the entire system, so let's take a closer look at this component.
In xDB, XML documents and other data are stored in an integrated, scalable, high-performance, object-oriented database. This DBMS is written in Java and allows you to save and manipulate very large amounts of data with high speed. The xDB transaction system complies with ACID rules : atomicity, consistency, isolation, and durability.
Physically, each database consists of one or more segments . Each segment is distributed in one or several files., and each file consists of one or more pages .
The relationship between the physical and logical structures of xDB:
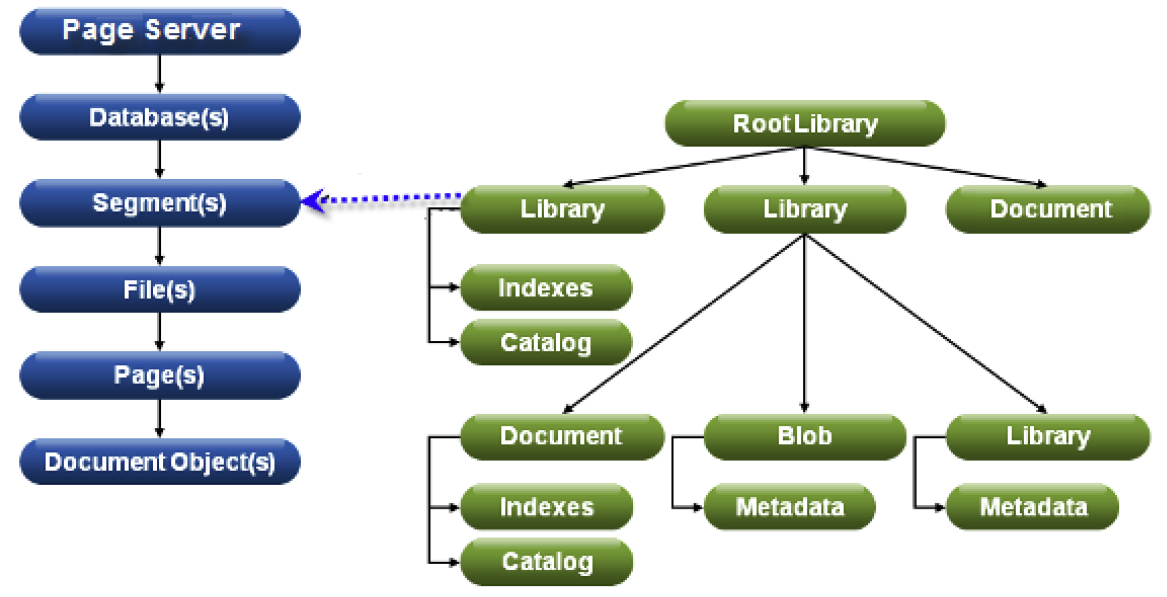
The so-called page server acts as the backend application server in xDB , which transfers data pages to front-end applications (client applications). In environments where the database is accessed from a single application server, performance is usually better if the page server runs inside the same JVM along with the application server.
If the page server also performs other tasks, then it is called an internal server . And if no additional tasks are assigned to the page server, then it is called a dedicated server(dedicated server). A dedicated server in combination with a TCP / IP connection between it and the clients has better scalability compared to the internal server. The larger the archive, the more different front-end applications that access the page server, the more arguments there are for making it a dedicated server.
XDB Clustering
xDB can be deployed both on a single node and on a cluster - using a shared-nothing architecture using Apache Cassandra . You do not have to understand Cassandra, although knowing its basics will make it easier to configure and manage the cluster.
Clustering xDB is done using horizontal scaling, in which data is physically distributed across multiple servers (data nodes). They do not have a common file system and interact with each other over the network. Clusters also use configuration nodes containing complete information about the structure of the cluster.
Both a single node and a cluster act as a logical database container. A page server operates with a node's data directory — a structure containing one or more databases. Each node contains its own page server, and all these servers are clustered through a configuration node.
Thanks to xDB clustering, InfoArchive users can work with big data coming at high speed. This is especially true for the permanent recording of user traffic of large web services and telecom providers: a single node can rest against the processor and / or the capacity of the disk subsystem.
Cluster example:
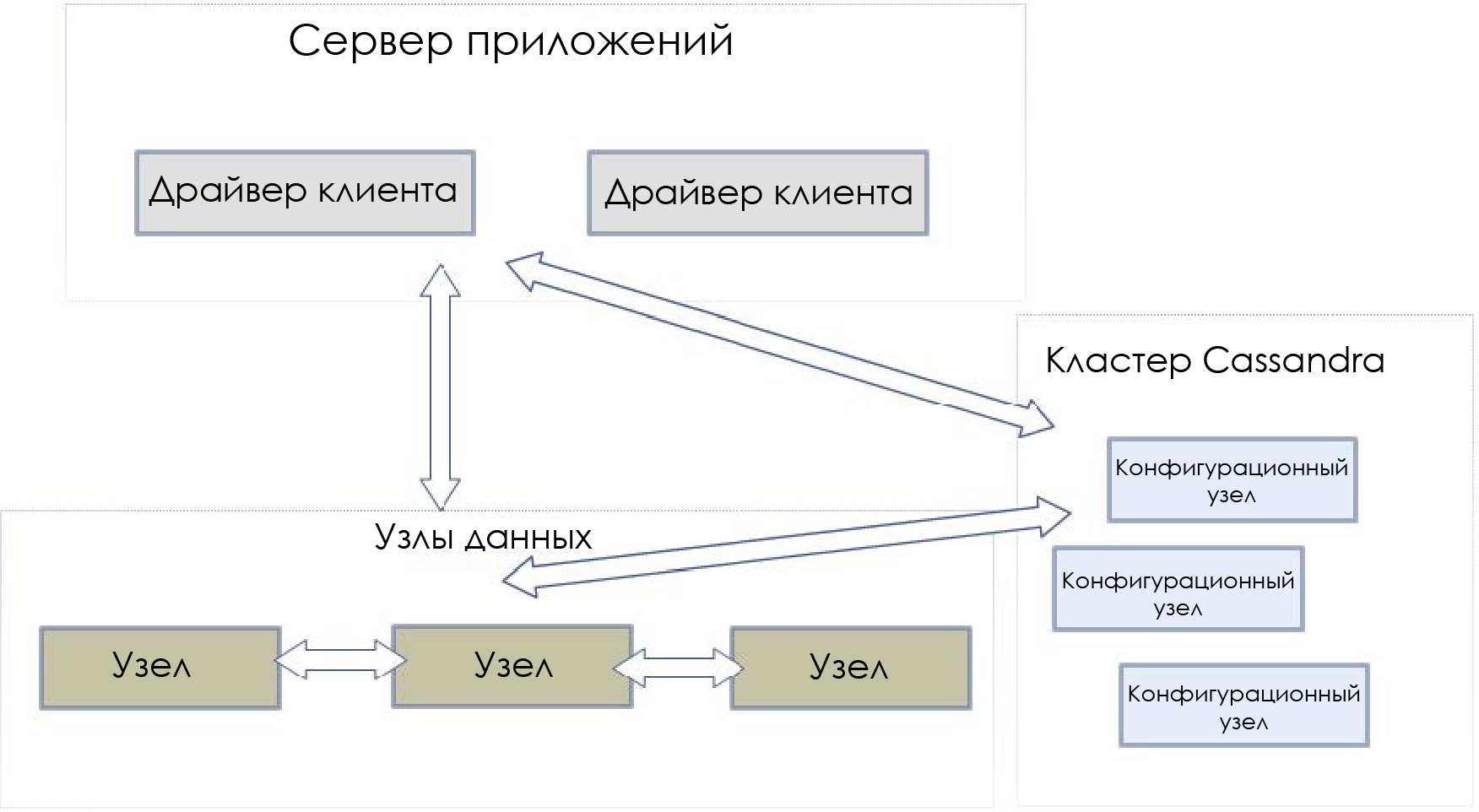
xDB-cluster consists of three types of components:
- Data nodes . Information repositories. Each node acts as a separate backend server, listening and able to accept requests from other members of the cluster. The driver (s) of the client allows you to present the cluster as if it consists of a single node. In this case, the driver should not be connected directly to data nodes, only through configuration nodes.
- Configuration Nodes . They store metadata containing information about all data nodes: databases, segments, files, users, groups, and data distribution by node. If the configuration nodes fail, the cluster dies. Therefore, the contents of these nodes should be duplicated.
- Drivers customers . Remote xDB drivers initialized using bootstrap URL with one of the configuration nodes. Applications interact with the cluster through the client driver, for example, to create new databases, move information between nodes, add new XML documents, etc. The client driver automatically sends data requests to the corresponding data nodes, focusing on the information from the configuration nodes.
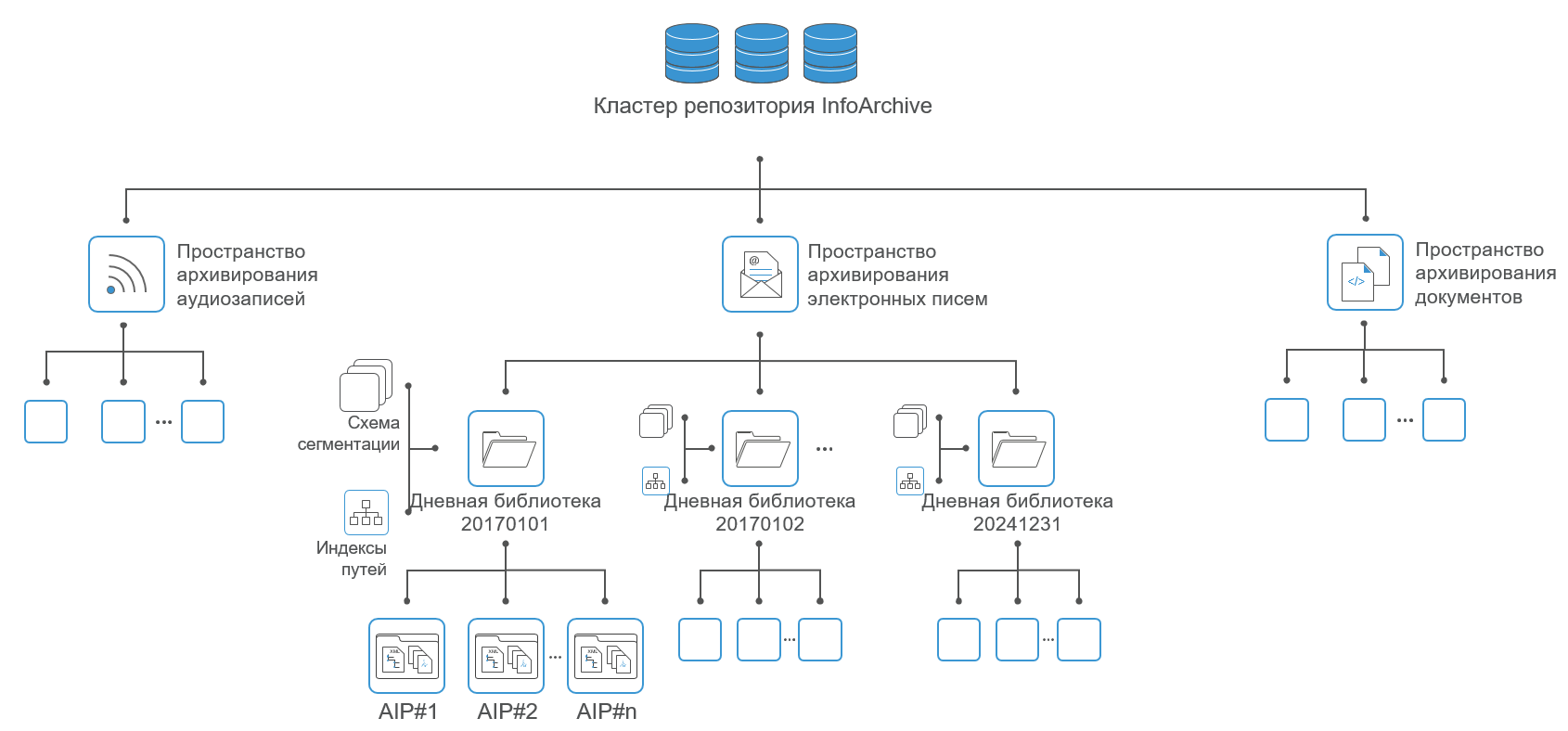
Data partitioning
The distribution of data in xDB is carried out at the level of detachable libraries. A disconnected library is a data block that is moved within a cluster. They are usually used for partitioning. Each library is stored or bound always to any one data node. At the same time, a node can store libraries linked to other nodes.
Disabled libraries also allow you to combat the imbalance in cluster performance. For example, if some data nodes in the cluster are overloaded, then some libraries may be transferred to other nodes.
Possible application of data partitioning in InfoArchive:
Using EMC Isilon for EMC InfoArchive
You can use EMC Isilon as a storage system for InfoArchive, a horizontally scalable network storage system that provides the functionality of the entire enterprise and allows you to effectively manage the growing volumes of archive data. The cluster architecture underlying EMC Isilon allows you to combine ease of use and reliability in one system, as well as provide linear growth in volume and system performance.
Initially, the system can be relatively small, but over time its size can increase significantly. The EMC Isilon-based solution allows you to start building a system from 18 TB and grow up to 50 PB in a single file system. With the growth of volumes, only the number of nodes in the cluster grows. A single point of administration and a single file system are maintained. Thus, EMC Isilon can be effectively used as a single consolidated storage system and used throughout the entire life cycle of information storage. This approach avoids the use of various storage systems, which simplifies the implementation, maintenance, expansion and modernization of the system. As a result, the cost of operation and maintenance of a single EMC Isilon solution is significantly lower than that of a solution consisting of several traditional systems.
In this way, EMC Isilon storage effectively complements the InfoArchive archive platform.
Main advantages:
- Integration with SmartLock software provides compatibility with a single write, multiple read (WORM) scheme at the database and storage levels to prevent inadvertent, premature or malicious modification or deletion of data.
- Cost reduction and infrastructure optimization. Isilon's horizontally scalable NAS delivers more than 80% storage utilization, while Isilon SmartDedupeTM reduces storage requirements by an additional 35%.
- EMC Isilon, based on EMC Federated Business Data Lake, supports HDFS, so all data types in InfoArchive can be provided for all kinds of Hadoop.
- EMC Isilon enables you to quickly add storage resources without downtime, manually migrating data, or reconfiguring application logic, which saves valuable IT resources and reduces operational costs.
Life examples
At the end of the article, we give a couple of examples of using InfoArchive to create responsible archiving systems.
Example 1 . The company processes financial transactions, the data is archived in compressed XML, in 12 simultaneous streams, about 20 million operations per day (about 320 GB XML), 3.6 million / 56 GB per hour, 1017 operations / 16 MB per give me a sec.
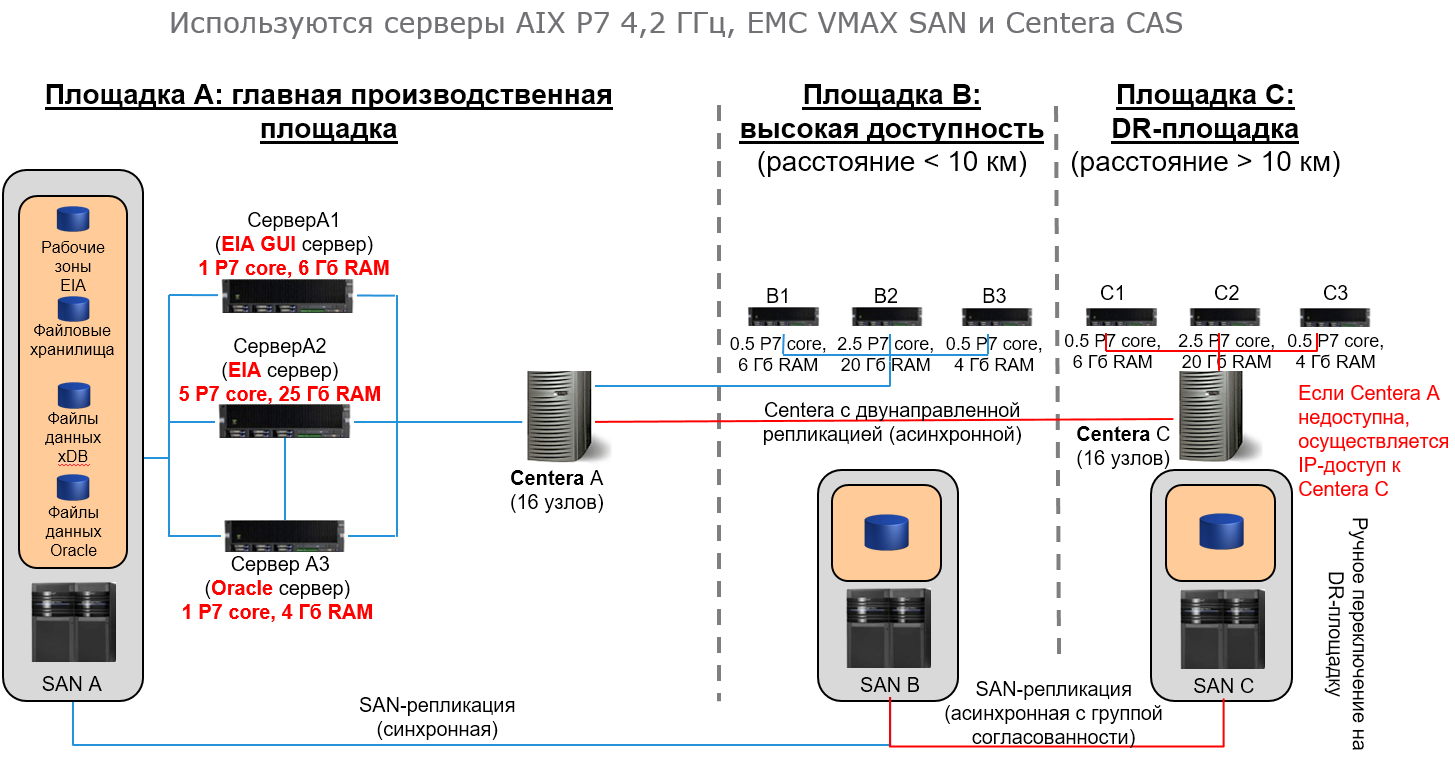
The load on adding data and search performance are independent of the number of already archived objects. Processing a discriminant request takes about 1 second (1 result), non discriminant - 4 seconds (200 results).
Example 2 . At another customer, the data is archived in the form of AFP documents, structured and unstructured data.
Average / peak load per day:
- 0.5 / 4 million documents
- 20/60 million records
- 50,000 / 70,000 search operations
System performance when adding data to the archive:
- 1.5 million documents per hour in 12 simultaneous streams (about 60% of the time is spent converting from AFP to PDF)
- or 45 million structured records per hour in 10 simultaneous streams.
This represents less than 0.5% of the theoretical maximum performance of EMC Centera storage systems used in the project.

- The average document search time is 0.5 seconds.
- The average time to receive a document is 1.5 seconds.
- The average search time for structured data among 1 billion records is 2.5 seconds.
- Up to 15,000 searches per hour.
Conclusion
The signing of the “Spring Package” is a difficult test for the entire IT and telecom sector. Nevertheless, the difficult task of creating numerous high-speed and voluminous archives can be solved with the help of EMC InfoArchive - a bunch of storage systems and a software platform based on xDB DBMS, which has ample opportunities for scaling and configuration.