Best Machine Learning Packages in R, Part 1
- Transfer
One of the most common questions that data processing and analysis experts face is “What programming language is best used to solve machine learning problems?” The answer to this question always leads to a difficult choice between R, Python and MATLAB. Generally speaking, no one can give an objective answer, which programming language is better. Of course, the language that you choose for machine learning depends on the limitations of a particular task and data, the preferences of the specialist and the machine learning methods that need to be applied. According to a survey on Kaggle 's favorite tool for users , R prefer 543 out of 1714 to solve data analysis problems.
Now 8341 packages are available in CRAN . Except CRAN, there are other repositories with lots of packages. The syntax for the installation of any of them is simple:
Here are a few packages, without which you hardly will manage, as a specialist in data analysis:
If you need to decide what to do with the missing values, MICE is exactly what you need. When the problem of missing values arises, the most common way to solve it is simple substitutions: zeros, mean, mode, etc. However, none of these methods is flexible and can lead to inconsistencies in the data.
The MICE package will help replace missing values using a variety of techniques, depending on the data you are working with.
Let's look at an example of using MICE.

So, we created a random data block, intentionally introducing several missing values into it. Now you can look at the work of MICE and stop worrying about them.

In the MICE example, we used the default values, but you can read about each of the parameters and change them according to your requirements.
2. Package
A package
Function
rpart is an abbreviation that stands for Recursive Partitioning and Regression Trees (recursive partitioning and regression trees). Using rpart, you can apply both regression and classification. Speaking of syntax, it is pretty simple:
Let's look at a data array

Let's say our goal is to predict Species from a decision tree; this can be implemented with one line of code:
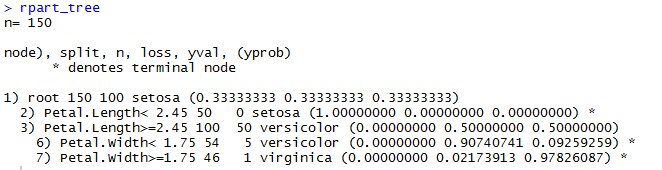
Here you can see the separation of different vertices and the predicted class.
To forecast based on a new data array, you can use a simple function
3
The package
Let's build a tree using the same example as above.
Here's what the constructed tree will look like:

This package also has a forecasting function, it is good to use it to predict classes using new input data.
4
The package
The construction of forecasting models can be facilitated thanks to special built-in functions for splitting data, selecting important features, preprocessing data, evaluating the importance of variables, setting up the model through re-sampling and visualization.
The package
After installing the package,
To build forecasting models,
The package
In short, this is a must-have package R that will satisfy all your requirements for building forecasting models.
Now 8341 packages are available in CRAN . Except CRAN, there are other repositories with lots of packages. The syntax for the installation of any of them is simple:
install.packages(“Name_Of_R_Package”). Here are a few packages, without which you hardly will manage, as a specialist in data analysis:
dplyr, ggplot2, reshape2. Of course, this is not a complete list. In this article, we will dwell on the packages used in machine learning.1. MICE package - take care of missing values
If you need to decide what to do with the missing values, MICE is exactly what you need. When the problem of missing values arises, the most common way to solve it is simple substitutions: zeros, mean, mode, etc. However, none of these methods is flexible and can lead to inconsistencies in the data.
The MICE package will help replace missing values using a variety of techniques, depending on the data you are working with.
Let's look at an example of using MICE.
dataset <- data.frame(var1=rnorm(20,0,1), var2=rnorm(20,5,1))
dataset[c(2,5,7,10),1] <- NA
dataset[c(4,8,19),2] <- NA
summary(dataset)
So, we created a random data block, intentionally introducing several missing values into it. Now you can look at the work of MICE and stop worrying about them.
install.pckages(“mice”)
require(mice)
dataset2 <- mice(dataset)
dataset2<-complete(dataset2)
summary(dataset2)
In the MICE example, we used the default values, but you can read about each of the parameters and change them according to your requirements.
2. Package rpart: let's share the data
A package
rpartin the R language is used to build classification and regression models using a two-step procedure, and the result is presented in the form of binary trees. The easiest way to build a regression or classification tree with an application rpartis to call a function plot(). The function itself plot()may not give a pretty beautiful result, so there is an alternative - prp()a powerful and flexible function. prp()The package is rpart.plotoften called a real Swiss knife for building regression trees. Function
rpart()allows you to establish the relationship between dependent and independent variables to show the variance of the dependent variable based on independent. For example, if a company providing online training wants to know how their sales (dependent variable) are affected by promotion in social networks, newspapers, referral links, word of mouth, etc., rpartthere are several functions that can help with an analysis of this phenomenon. rpart is an abbreviation that stands for Recursive Partitioning and Regression Trees (recursive partitioning and regression trees). Using rpart, you can apply both regression and classification. Speaking of syntax, it is pretty simple:
rpart(formula, data=, method=,control=)
Let's look at a data array
iristhat looks like this: Let's say our goal is to predict Species from a decision tree; this can be implemented with one line of code:
rpart_tree <- rpart(formula = Species~., data=iris, method = ‘class’)
summary(rpart_tree)
plot(rpart_tree)
Here you can see the separation of different vertices and the predicted class.
To forecast based on a new data array, you can use a simple function
predict(tree_name,new_data)that will produce predicted classes as a result.3 PARTY.: let's share the data again
The package
PARTYin R is used for recursive separation and displays continuous improvement of ensemble methods. PARTY- Another package for constructing decision trees based on the conditional inference algorithm. ctree()- The main function of the package PARTY, it is widely used and reduces training time and possible deviations. PARTYhas a syntax similar to other predictive analytics functions in R, i.e.ctree(formula,data)
Let's build a tree using the same example as above.
party_tree <- ctree(formula=Species~. , data = iris)
plot(party_tree)
Here's what the constructed tree will look like:
This package also has a forecasting function, it is good to use it to predict classes using new input data.
4 CARET.: Classification And REgression Training (classification and regression training)
The package
CARET- Classification And REgression Training (classification and regression training) - is designed to combine training models and forecasting. The package has several algorithms suitable for different tasks. A data analysis specialist cannot always say for sure which algorithm is best for solving a given problem. The package CARETallows you to select the optimal parameters for the algorithm using controlled experiments. The cross-search method implemented in this package searches for parameters by combining various methods for evaluating model performance. After enumerating all possible combinations, the cross-search method finds the combination that gives the best results.The construction of forecasting models can be facilitated thanks to special built-in functions for splitting data, selecting important features, preprocessing data, evaluating the importance of variables, setting up the model through re-sampling and visualization.
The package
CARETis one of the best in R. The developers of this package understood how difficult it is to choose the most suitable algorithm for each task. There are cases when a specific model is used, and there are doubts about the quality of the data, but still, most often the problem is in the selected algorithm. After installing the package,
CARETyou can run names(getModelInfo())and see a list of 217 available methods. To build forecasting models,
CARETuses a function train(). Its syntax looks like this:train(formula, data, method)
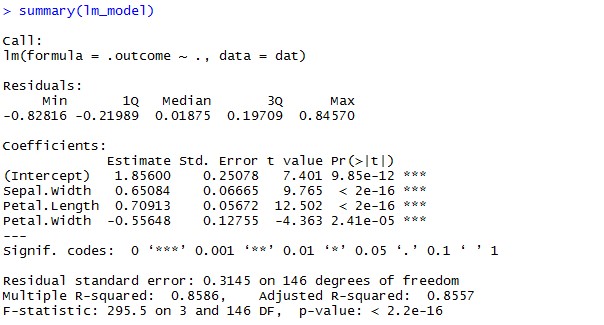
Lm_model <- train(Sepal.Length~Sepal.Width + Petal.Length + Petal.Width, data=iris, method = “lm”)
summary(lm_model)
The package
CARETnot only builds models, but also splits the data into test and training, performs the necessary transformations, etc. In short, this is a must-have package R that will satisfy all your requirements for building forecasting models.