Optimization of the web service hints for mailing addresses and name
In this article, I would like to share the experience of developing a web service in C ++. In my opinion, this is quite an interesting topic, since the use of C ++ for web development is a rare thing and often puzzles IT circles. There are many arguments on the Internet that are not in favor of this approach. The use of pointers, memory leaks, segfaults, lack of support for web standards out of the box - this is an incomplete list of what we had to familiarize ourselves with before deciding on the choice of this technology.
The development in question in this article was completed in 2015, but the prerequisites for it appeared much earlier. It all started with the fact that in 2008 we had the idea to develop a web service for standardizing and correcting user contact information, such as mail addresses and phone numbers. The web service was supposed to receive through the REST API the contact data that a certain user specified in an arbitrary text form, and put this data in order. In fact, the service was supposed to solve the problem of recognizing user contact data in an arbitrary text string. In addition, during such processing, the service had to correct typos in the addresses, restore missing address components, and also bring the processed data to a structured form. The service was developed for the needs of business users for whom the correctness of client contact information is a critical factor. First of all, these are online stores, delivery services, as well as CRM and MDM systems of large organizations.
In terms of computing, the task was quite difficult, since unstructured text data is subject to processing. Therefore, all processing was implemented in C ++, while the applied business logic was written in Perl and framed as a FastCGI server.
For six years, this service worked successfully until we faced a new task that forced us to reconsider the architecture of the solution. The new task was to generate real-time prompts for user-entered email addresses, last names, first names and patronymics.
The formation of real-time prompts implies that the service receives a new HTTP request from the user whenever he enters the next character of the mailing address or name in the process of filling out some form with contact information. As part of the request, the service receives a text string entered by the user so far, analyzes it and generates several most likely options for its completion. The user sees the prompts received from the service and either selects the appropriate option or continues to enter. In reality, it should look something like this.

This task differs from the standardization of already entered contact data, for which the service was originally designed, in that the same user during the filling out of the form generates an order of magnitude more requests. Moreover, the speed of processing these requests should exceed the speed with which the user types the input data on the keyboard. Otherwise, the user will have time to enter all the data manually and will not need any prompts.
To evaluate an acceptable response time, we performed a series of experiments with adjustable delay. As a result, they came to the conclusion that the hints cease to be useful when the response time begins to exceed 150 ms. Our original architecture of the service allowed 40 users to remain within this framework while working simultaneously (these indicators were obtained for a server with two cores and 8GB of RAM). To increase this number, it is necessary to increase the number of processors in server hardware. And since the hint functions for mail addresses and name were developed for everyone to use them freely, we understood that much more processors and servers would be required. Therefore, the question arose of whether it is possible to optimize the processing of requests by changing the architecture of the service.
The service architecture that needed to be improved was as follows.
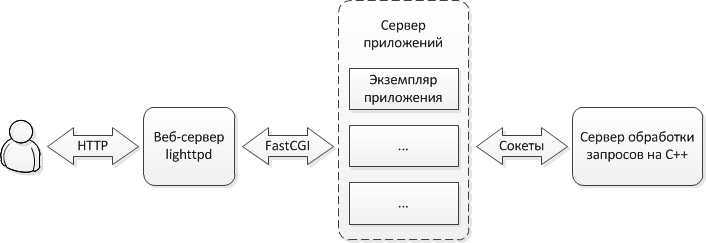
According to this scheme, a user application (for example, a web browser) generates HTTP requests that the web server receives (in our case, the lightweight lighttpd web server is used). If the requests are not dealing with static, then they are transmitted to the application server, which is connected to the web server via the FastCGI interface (in our case, the application server is written in Perl). If the requests relate to the processing of contact data, they are passed on to the processing server. Sockets are used to interact with the processing server.
You may notice that if you replace the processing server with a database server in this scheme, you will get a fairly common scheme used in traditional web applications developed using popular frameworks for Python or Ruby, as well as for PHP running php_fpm.
This architecture seemed very successful, because it allows you to easily scale the service while increasing the load, for this, new processing servers are simply added. But since the performance left much to be desired, it was decided to measure the time that the service spends at different stages of request processing. The result is the following diagram.
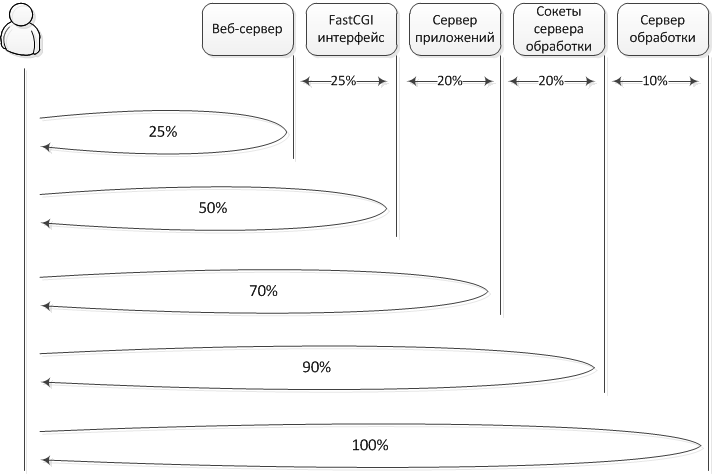
This illustration shows how much time it takes in percentage terms from the moment the request is sent to the moment the web client receives the response, in case the request passes through the entire processing chain or only some fragment of it. During this experiment, the client and server were located on the same local network.
For example, the first number in the diagram indicates that 25% of the time is spent sending a request from the web client, passing it through the web server path and returning the response to the web client. Similarly, all other stages take into account both the passage of the request in the forward direction and the return of the response along the same chain in the opposite direction. Namely, with further advancement of the request, it arrives through the FastCGI interface to the application server. Passing through this interface takes another 25% of the time.
Next, the request passes through the application server. An additional 20% of the time is spent on this. In our case, no processing of the request by the application server is performed. The application only parses the HTTP request, passes it on to the processing server, receives a response from it, and passes it back to the FastCGI interface. In fact, 20% of the time is spent on request parsing and interpreter costs, since the application is implemented in a scripting language.
Another 20% of the time is spent passing data through the socket interface, which is used to connect the application with the processing server. This interface works a little faster compared to FastCGI (20% versus 25%), since the corresponding protocol and its implementation are much simpler. The processing of the request itself, which consists in the formation of prompts for the data entered by the user, takes up only 10% of the total time (the tests used one of the most difficult requests from the point of view of processing).
I would like to emphasize that all the specifics of our task in the experiments performed is manifested only at the last stage and this stage, from the point of view of productivity, raises the least questions. The remaining steps are very standard. So, we use an event web server, which simply extracts the received request from one socket associated with the HTTP port being listened to and puts this data into the FastCGI socket. Similarly, the application server - extracts data from the FastCGI socket and transfers it to the processing server socket. In the application itself, there is nothing to optimize by and large.
A depressing picture, in which only 10% of the response time is attributable to useful actions, made us think about a change in architecture.
To eliminate the overhead in the original architecture, it is ideally necessary to get rid of an application in an interpreted language, as well as eliminate socket interfaces. In this case, it is necessary to maintain the ability to scale the service. We considered the following options.
As part of this option, the possibility of implementing an event application server, for example, on Node.js or Twisted, was considered. In this implementation, the number of socket interfaces through which requests pass remains the same, since each request arrives at a balancing web server, it passes it to one of the application server instances, which in turn transmits the request to the processing server. The total request processing time remains the same. However, the number of simultaneously processed requests increases due to the asynchronous use of sockets. Roughly speaking, while one request is in the process of moving through the socket interface, another request can go through the business logic of the application within the same instance.
We had to abandon this implementation option, since we considered it unjustified to implement a fully asynchronous application just to eliminate one bottleneck in the old architecture - the socket interface between the application and the processing server. The rest of the I / O operations, such as logging, fixing user statistics, sending mail and interacting with other services in the old application were carried out deferred in separate threads, so they did not require asynchrony. In addition, this architecture does not allow to reduce the processing time for a single request, so that user applications that work with the service through the API will not receive a performance gain.
Here we examined the implementation of the application as a Java servlet or .Net application, which is directly called by the web server. In this case, it is possible to get rid of the FastCGI interface, and at the same time the interpreted language. The socket interface with the processing server is saved.
The decision-making not in favor of this approach was affected by the binding of the entire solution to a specific web server, which should support the selected technology. For example, Tomcat for Java servlets or Microsoft IIS when using .Net. We wanted to keep the application compatible with lighttpd and nginx servers.
In this case, there is no binding to a specific web server, since the FastCGI interface is saved. The application is implemented in C ++ and integrated with the processing server. Thus, we are avoiding the use of an interpreted language, as well as eliminating the socket interface between the application and the processing server.
The disadvantage of this approach is the lack of a framework that is quite popular and tested on large projects. Of the candidates, we considered CppCMS, TreeFrog, and Wt. For the first part, we had concerns about the future support of the project by its developers, since there were no fresh updates on the project website for a long time. TreeFrog is based on Qt. We actively use this library in offline projects, however, we consider it redundant and not reliable enough for the task. In terms of Wt, the framework has a great emphasis on the GUI, whereas in our case, the GUI is a secondary thing. An additional factor in the rejection of the use of these frameworks was the desire to minimize the risks associated with the use of third-party libraries, without which, in principle, you can do without,
However, the very fact of the existence of such projects has led to the idea that the development of web applications in C ++ is not so hopeless. Therefore, it was decided to conduct a study of existing libraries that could be used in developing a C ++ web application.
To interact with the web server, the application must implement one of the HTTP, FastCGI, or SCGI protocols supported by the web server. We settled on FastCGI and its implementation as libfcgi.
The cgicc library came up for parsing HTTP requests and generating HTTP responses. This library takes care of all the parsing of HTTP headers, retrieving request parameters, decoding the body of a received message, as well as generating an HTTP response.
Xerces was chosen to parse XML requests that may come from service users within the framework of the REST API.
In C ++, there is no Unicode support "out of the box", so for working with text, it was decided to use standard STL strings, provided that the internal agreement is mandatory that all string data should always be represented in UTF-8.
To interact with external services and mail servers, it was decided to use libcurl, and to generate hashes - openssl.
To generate html views, we needed a simple template engine. In the old service implementation, HTML :: Template was used for these purposes, so when switching to C ++, we needed a template engine with similar syntax and similar capabilities. We tried to work with CTPP, Clearsilver and Google-ctemplate.
CTPP turned out to be inconvenient to use, because before using the template it is necessary to transfer it to binary code, and then create a virtual machine that will execute it. All these difficulties make the code unreasonably cumbersome.
At Clearsilver, the entire interface is implemented in pure C, and to use it, it was necessary to write an impressive object wrapper. Well, Google-ctemplate did not cover all the features of HTML :: Template that were used in the old version of the service. For its full use, it would be necessary to change the logic responsible for the formation of representations. Therefore, in the case of the template engine, I had to develop my own bike, which was done.
The development of our own C ++ template engine took about three days, while we spent twice as much time searching and studying the ready-made solutions mentioned above. In addition, its template engine allowed expanding the HTML :: Template syntax by adding the “else if” construct, as well as operators for comparing variables with predefined values in the template.
Session management also had to be implemented independently. The specifics of the developed service affected here, since the session in our case stores quite a lot of information that reflects user behavior in real time. The fact is that in addition to processing data through the REST API, ordinary users often access the service as a reference service, for example, when they need to find out the zip code for a given address. From time to time, users appear among those who decide to automate the standardization of their contact information by developing a web bot that mimics the work of a person in a browser, instead of using the REST API intended for this. Such bots create a useless load on the service, which affects the work of other users. To combat bots, the service accumulates information reflecting user behavior within sessions. This information is subsequently used by a separate service module, which is responsible for recognizing bots and blocking them.
Perhaps the key standard that we had to implement on our own is JSON. In C ++, there are quite a few of its open implementations that we analyzed before creating another one. The main reason for creating your own implementation is the use of JSON in conjunction with a non-standard memory allocator, which was used on the processing server to speed up the operations of dynamic allocation and freeing of memory. This allocator works 2-3 times faster than the standard one in mass operations of allocating / releasing small blocks. Since working with JSON fits into this pattern, we wanted to get a free performance boost on all operations related to parsing and building JSON objects.
The architecture of the final solution that we have is shown in the following diagram.
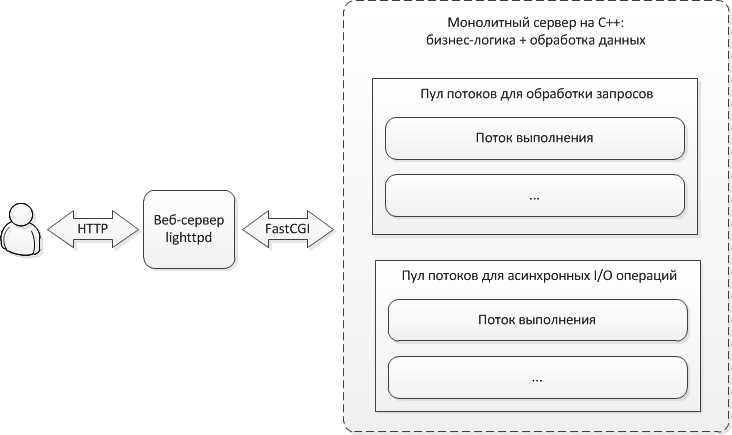
Within the framework of a monolithic server, both the application logic and the processing of contact data are integrated. To process incoming requests, the server provides a pool of execution threads. All I / O operations that must be performed during the processing of API requests are delayed. For these purposes, a separate pool of threads is created on the server that is responsible for performing asynchronous I / O. Such operations include, for example, updating user statistics, as well as writing off money, in the case of using paid API functions. In both cases, you need to record in the database, the execution of which in the main thread would lead to its blocking.
This architecture allows you to scale the service by running additional instances of a monolithic server, in which case the web server is given the additional role of a balancer.
According to the diagram given earlier, when switching to a new architecture, the response time of a service when processing a single request should have been reduced by about 40%. Real experiments showed that the reduction occurred by 43%. This can be explained by the fact that the monolithic solution has become more efficient use of RAM.
We also conducted stress testing to determine the number of users that the new service can serve while using prompts, while providing a response time of no more than 150 ms. In this mode, the service was able to provide simultaneous operation of 120 users. Let me remind you that for the old implementation this value was 40. In this case, a three-fold increase in productivity is explained by a decrease in the total number of processes involved in servicing the request flow. Previously, requests were processed by several instances of the application (in the experiments, the number of instances varied from 5 to 20), while in the new version of the service all requests are processed as part of a single multi-threaded process. While each instance works with its own separate memory, collectively, they compete for one processor cache, which becomes less efficient. In the case of one monolithic process, there is no such competition.
This article examined a non-standard approach to developing web services when it is required to provide real-time request processing. An example of a task for generating prompts demonstrates an unusual situation for web services when increasing the response time makes the service’s functionality practically useless for the user. An example shows that the appearance of such requirements can lead to significant changes in the architecture.
To improve performance, we had to combine the application server and the data processing server into a single monolithic server implemented in C ++. This solution halved the response time when processing single requests, and also increased the service performance by three times with mass use.
In addition to solving the main problem, a pleasant bonus to the work done was the simplification of refactoring, since strict typing allows you to not strain about renaming in the code, because the project simply will not be assembled in case of errors. Also, the resulting project has become easier to maintain as a whole, since we have the only server that has business logic and data processing logic written in one language.
The development in question in this article was completed in 2015, but the prerequisites for it appeared much earlier. It all started with the fact that in 2008 we had the idea to develop a web service for standardizing and correcting user contact information, such as mail addresses and phone numbers. The web service was supposed to receive through the REST API the contact data that a certain user specified in an arbitrary text form, and put this data in order. In fact, the service was supposed to solve the problem of recognizing user contact data in an arbitrary text string. In addition, during such processing, the service had to correct typos in the addresses, restore missing address components, and also bring the processed data to a structured form. The service was developed for the needs of business users for whom the correctness of client contact information is a critical factor. First of all, these are online stores, delivery services, as well as CRM and MDM systems of large organizations.
In terms of computing, the task was quite difficult, since unstructured text data is subject to processing. Therefore, all processing was implemented in C ++, while the applied business logic was written in Perl and framed as a FastCGI server.
For six years, this service worked successfully until we faced a new task that forced us to reconsider the architecture of the solution. The new task was to generate real-time prompts for user-entered email addresses, last names, first names and patronymics.
Real time processing
The formation of real-time prompts implies that the service receives a new HTTP request from the user whenever he enters the next character of the mailing address or name in the process of filling out some form with contact information. As part of the request, the service receives a text string entered by the user so far, analyzes it and generates several most likely options for its completion. The user sees the prompts received from the service and either selects the appropriate option or continues to enter. In reality, it should look something like this.
This task differs from the standardization of already entered contact data, for which the service was originally designed, in that the same user during the filling out of the form generates an order of magnitude more requests. Moreover, the speed of processing these requests should exceed the speed with which the user types the input data on the keyboard. Otherwise, the user will have time to enter all the data manually and will not need any prompts.
To evaluate an acceptable response time, we performed a series of experiments with adjustable delay. As a result, they came to the conclusion that the hints cease to be useful when the response time begins to exceed 150 ms. Our original architecture of the service allowed 40 users to remain within this framework while working simultaneously (these indicators were obtained for a server with two cores and 8GB of RAM). To increase this number, it is necessary to increase the number of processors in server hardware. And since the hint functions for mail addresses and name were developed for everyone to use them freely, we understood that much more processors and servers would be required. Therefore, the question arose of whether it is possible to optimize the processing of requests by changing the architecture of the service.
Source architecture
The service architecture that needed to be improved was as follows.
According to this scheme, a user application (for example, a web browser) generates HTTP requests that the web server receives (in our case, the lightweight lighttpd web server is used). If the requests are not dealing with static, then they are transmitted to the application server, which is connected to the web server via the FastCGI interface (in our case, the application server is written in Perl). If the requests relate to the processing of contact data, they are passed on to the processing server. Sockets are used to interact with the processing server.
You may notice that if you replace the processing server with a database server in this scheme, you will get a fairly common scheme used in traditional web applications developed using popular frameworks for Python or Ruby, as well as for PHP running php_fpm.
This architecture seemed very successful, because it allows you to easily scale the service while increasing the load, for this, new processing servers are simply added. But since the performance left much to be desired, it was decided to measure the time that the service spends at different stages of request processing. The result is the following diagram.
This illustration shows how much time it takes in percentage terms from the moment the request is sent to the moment the web client receives the response, in case the request passes through the entire processing chain or only some fragment of it. During this experiment, the client and server were located on the same local network.
For example, the first number in the diagram indicates that 25% of the time is spent sending a request from the web client, passing it through the web server path and returning the response to the web client. Similarly, all other stages take into account both the passage of the request in the forward direction and the return of the response along the same chain in the opposite direction. Namely, with further advancement of the request, it arrives through the FastCGI interface to the application server. Passing through this interface takes another 25% of the time.
Next, the request passes through the application server. An additional 20% of the time is spent on this. In our case, no processing of the request by the application server is performed. The application only parses the HTTP request, passes it on to the processing server, receives a response from it, and passes it back to the FastCGI interface. In fact, 20% of the time is spent on request parsing and interpreter costs, since the application is implemented in a scripting language.
Another 20% of the time is spent passing data through the socket interface, which is used to connect the application with the processing server. This interface works a little faster compared to FastCGI (20% versus 25%), since the corresponding protocol and its implementation are much simpler. The processing of the request itself, which consists in the formation of prompts for the data entered by the user, takes up only 10% of the total time (the tests used one of the most difficult requests from the point of view of processing).
I would like to emphasize that all the specifics of our task in the experiments performed is manifested only at the last stage and this stage, from the point of view of productivity, raises the least questions. The remaining steps are very standard. So, we use an event web server, which simply extracts the received request from one socket associated with the HTTP port being listened to and puts this data into the FastCGI socket. Similarly, the application server - extracts data from the FastCGI socket and transfers it to the processing server socket. In the application itself, there is nothing to optimize by and large.
A depressing picture, in which only 10% of the response time is attributable to useful actions, made us think about a change in architecture.
New service architecture
To eliminate the overhead in the original architecture, it is ideally necessary to get rid of an application in an interpreted language, as well as eliminate socket interfaces. In this case, it is necessary to maintain the ability to scale the service. We considered the following options.
Event Server Application
As part of this option, the possibility of implementing an event application server, for example, on Node.js or Twisted, was considered. In this implementation, the number of socket interfaces through which requests pass remains the same, since each request arrives at a balancing web server, it passes it to one of the application server instances, which in turn transmits the request to the processing server. The total request processing time remains the same. However, the number of simultaneously processed requests increases due to the asynchronous use of sockets. Roughly speaking, while one request is in the process of moving through the socket interface, another request can go through the business logic of the application within the same instance.
We had to abandon this implementation option, since we considered it unjustified to implement a fully asynchronous application just to eliminate one bottleneck in the old architecture - the socket interface between the application and the processing server. The rest of the I / O operations, such as logging, fixing user statistics, sending mail and interacting with other services in the old application were carried out deferred in separate threads, so they did not require asynchrony. In addition, this architecture does not allow to reduce the processing time for a single request, so that user applications that work with the service through the API will not receive a performance gain.
Application and web server integration
Here we examined the implementation of the application as a Java servlet or .Net application, which is directly called by the web server. In this case, it is possible to get rid of the FastCGI interface, and at the same time the interpreted language. The socket interface with the processing server is saved.
The decision-making not in favor of this approach was affected by the binding of the entire solution to a specific web server, which should support the selected technology. For example, Tomcat for Java servlets or Microsoft IIS when using .Net. We wanted to keep the application compatible with lighttpd and nginx servers.
Application Integration with Processing Server
In this case, there is no binding to a specific web server, since the FastCGI interface is saved. The application is implemented in C ++ and integrated with the processing server. Thus, we are avoiding the use of an interpreted language, as well as eliminating the socket interface between the application and the processing server.
The disadvantage of this approach is the lack of a framework that is quite popular and tested on large projects. Of the candidates, we considered CppCMS, TreeFrog, and Wt. For the first part, we had concerns about the future support of the project by its developers, since there were no fresh updates on the project website for a long time. TreeFrog is based on Qt. We actively use this library in offline projects, however, we consider it redundant and not reliable enough for the task. In terms of Wt, the framework has a great emphasis on the GUI, whereas in our case, the GUI is a secondary thing. An additional factor in the rejection of the use of these frameworks was the desire to minimize the risks associated with the use of third-party libraries, without which, in principle, you can do without,
However, the very fact of the existence of such projects has led to the idea that the development of web applications in C ++ is not so hopeless. Therefore, it was decided to conduct a study of existing libraries that could be used in developing a C ++ web application.
Existing libraries
To interact with the web server, the application must implement one of the HTTP, FastCGI, or SCGI protocols supported by the web server. We settled on FastCGI and its implementation as libfcgi.
The cgicc library came up for parsing HTTP requests and generating HTTP responses. This library takes care of all the parsing of HTTP headers, retrieving request parameters, decoding the body of a received message, as well as generating an HTTP response.
Xerces was chosen to parse XML requests that may come from service users within the framework of the REST API.
In C ++, there is no Unicode support "out of the box", so for working with text, it was decided to use standard STL strings, provided that the internal agreement is mandatory that all string data should always be represented in UTF-8.
To interact with external services and mail servers, it was decided to use libcurl, and to generate hashes - openssl.
Recording Components
To generate html views, we needed a simple template engine. In the old service implementation, HTML :: Template was used for these purposes, so when switching to C ++, we needed a template engine with similar syntax and similar capabilities. We tried to work with CTPP, Clearsilver and Google-ctemplate.
CTPP turned out to be inconvenient to use, because before using the template it is necessary to transfer it to binary code, and then create a virtual machine that will execute it. All these difficulties make the code unreasonably cumbersome.
At Clearsilver, the entire interface is implemented in pure C, and to use it, it was necessary to write an impressive object wrapper. Well, Google-ctemplate did not cover all the features of HTML :: Template that were used in the old version of the service. For its full use, it would be necessary to change the logic responsible for the formation of representations. Therefore, in the case of the template engine, I had to develop my own bike, which was done.
The development of our own C ++ template engine took about three days, while we spent twice as much time searching and studying the ready-made solutions mentioned above. In addition, its template engine allowed expanding the HTML :: Template syntax by adding the “else if” construct, as well as operators for comparing variables with predefined values in the template.
Session management also had to be implemented independently. The specifics of the developed service affected here, since the session in our case stores quite a lot of information that reflects user behavior in real time. The fact is that in addition to processing data through the REST API, ordinary users often access the service as a reference service, for example, when they need to find out the zip code for a given address. From time to time, users appear among those who decide to automate the standardization of their contact information by developing a web bot that mimics the work of a person in a browser, instead of using the REST API intended for this. Such bots create a useless load on the service, which affects the work of other users. To combat bots, the service accumulates information reflecting user behavior within sessions. This information is subsequently used by a separate service module, which is responsible for recognizing bots and blocking them.
Perhaps the key standard that we had to implement on our own is JSON. In C ++, there are quite a few of its open implementations that we analyzed before creating another one. The main reason for creating your own implementation is the use of JSON in conjunction with a non-standard memory allocator, which was used on the processing server to speed up the operations of dynamic allocation and freeing of memory. This allocator works 2-3 times faster than the standard one in mass operations of allocating / releasing small blocks. Since working with JSON fits into this pattern, we wanted to get a free performance boost on all operations related to parsing and building JSON objects.
Final result
The architecture of the final solution that we have is shown in the following diagram.
Within the framework of a monolithic server, both the application logic and the processing of contact data are integrated. To process incoming requests, the server provides a pool of execution threads. All I / O operations that must be performed during the processing of API requests are delayed. For these purposes, a separate pool of threads is created on the server that is responsible for performing asynchronous I / O. Such operations include, for example, updating user statistics, as well as writing off money, in the case of using paid API functions. In both cases, you need to record in the database, the execution of which in the main thread would lead to its blocking.
This architecture allows you to scale the service by running additional instances of a monolithic server, in which case the web server is given the additional role of a balancer.
According to the diagram given earlier, when switching to a new architecture, the response time of a service when processing a single request should have been reduced by about 40%. Real experiments showed that the reduction occurred by 43%. This can be explained by the fact that the monolithic solution has become more efficient use of RAM.
We also conducted stress testing to determine the number of users that the new service can serve while using prompts, while providing a response time of no more than 150 ms. In this mode, the service was able to provide simultaneous operation of 120 users. Let me remind you that for the old implementation this value was 40. In this case, a three-fold increase in productivity is explained by a decrease in the total number of processes involved in servicing the request flow. Previously, requests were processed by several instances of the application (in the experiments, the number of instances varied from 5 to 20), while in the new version of the service all requests are processed as part of a single multi-threaded process. While each instance works with its own separate memory, collectively, they compete for one processor cache, which becomes less efficient. In the case of one monolithic process, there is no such competition.
Conclusion
This article examined a non-standard approach to developing web services when it is required to provide real-time request processing. An example of a task for generating prompts demonstrates an unusual situation for web services when increasing the response time makes the service’s functionality practically useless for the user. An example shows that the appearance of such requirements can lead to significant changes in the architecture.
To improve performance, we had to combine the application server and the data processing server into a single monolithic server implemented in C ++. This solution halved the response time when processing single requests, and also increased the service performance by three times with mass use.
In addition to solving the main problem, a pleasant bonus to the work done was the simplification of refactoring, since strict typing allows you to not strain about renaming in the code, because the project simply will not be assembled in case of errors. Also, the resulting project has become easier to maintain as a whole, since we have the only server that has business logic and data processing logic written in one language.